MSML-BERT模型的层级多标签文本分类方法研究
2022-08-09刘贵全
黄 伟,刘贵全
1.中国科学技术大学 大数据学院,合肥 230027
2.中国科学技术大学 计算机科学与技术学院,合肥 230027
3.中国科学技术大学 大数据分析与应用安徽省重点实验室,合肥 230027
文本是当今世界最重要的信息载体之一,文本数据有很多来源,包括:网络数据、电子邮件、日常聊天、社交媒体、票证和用户评论等[1]。然而在信息爆炸的时代,由于文本的非结构化性质,人工处理和分类大量文本数据既耗时又具有挑战性。此外,采用人工的方式分类文本很容易受到外界因素的影响,比如疲劳作业和缺乏专业知识。因此,随着工业应用中文本数据规模的逐渐扩大,自动文本分类技术变得越来越重要[2]。多标签文本分类(multi-label text classification,MTC)是自然语言处理领域中重要且经典的问题,旨在为句子、段落和文档等文本单元分配一个或多个标签,比如一段新闻文本,可能同时具有“财经”“体育”和“足球”等标签[3]。
本文所要研究的是层级多标签文本分类(hierarchical multi-label text classification,HMTC)任务,可以视为是MTC的一个特殊的子任务,但是比普通的MTC任务更具有挑战性[4]。对于HMTC任务,文本对应的多个标签可以组织成树状的层级结构。如图1(a)所示,该图展示了随机的一条文本对应的层级标签结构,图中所有的圆圈代表语料库中所有的标签构成的总体标签结构,而其中有颜色的圆圈代表该条文本对应的标签构成了总体标签结构中的一个子结构,即该条文本对应的标签有“News”“Sports”“Football”“Features”“Arts”和“Movie”。本文聚焦于多路径(Multi-path)、强制性(Mandatory)的HMTC任务,这是现实应用中最常见的场景,其中多路径表示文本的多个标签在层级标签结构中具有一条或多条标签路径,同时强制性指不同标签路径的长度相等[5-6]。HMTC被广泛地应用于问答系统[7]、电子商务中的产品归类[8]和付费搜索营销中的竞价策略[9]等,在这些场景中文本的多个标签通常都被组织成层级结构。
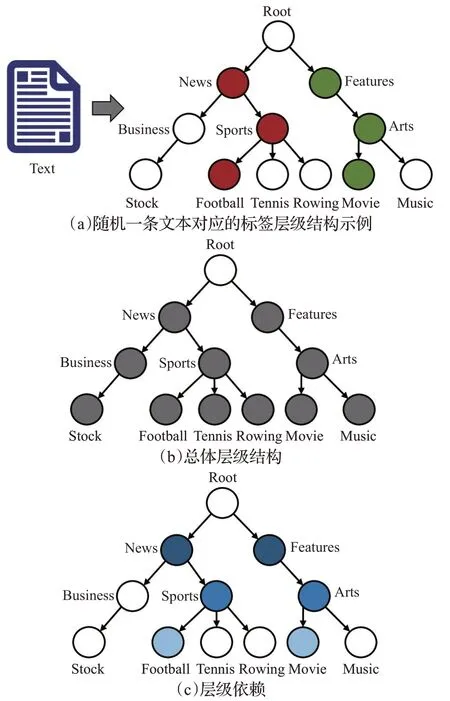
图1 标签层级结构以及层级建模方式Fig.1 Label hierarchy and hierarchy modeling
如何有效地利用层级结构信息是HMTC任务中最关键的问题[4]。许多研究在处理HMTC问题的过程中完全或者部分忽略了这种层级结构信息,导致模型整体的性能较低,尤其是在对较低层级标签的预测上面表现不佳[10]。现有研究证明,引入层级结构信息可以提高对层级标签的预测能力,从而提高HMTC任务的整体性能[11-12]。许多研究提出构建一系列独立训练并且按顺序预测的局部分类器来解决HMTC问题,但是这种方式仅能实现局部最优并且会造成误差的传播[13-14]。最近一些研究通过引入各种结构(比如双向树形长短期记忆网络或图卷积网络[15]、基于注意力的递归神经网络[16]等)来设计端到端的全局模型,这些模型往往使用相同的模型结构来预测不同层级的标签,忽略了不同层级和粒度的标签之间的差异性和多样性,影响了各层级标签的预测性能。另外,这些模型在利用标签结构时通常采用编码总体层级结构信息(如图1(b)所示)的方法,但是他们并没有显式和充分地建模层级依赖关系(如图1(c)所示)以及引入了不必要的噪音,进而导致对较低层级长尾标签的预测性能较差,并且会造成标签不一致(Label Inconsistency)问题(一个标签节点被预测出来,但是其对应的父节点标签没有被预测出来,不符合现实应用场景)[5]。
因此当前HMTC方法面临的两大问题为:(1)使用相同的模型结构来预测不同层级的标签,忽略了不同层级和粒度的标签之间的差异性和多样性,导致对各层级标签的预测性能较差;(2)没有显式和充分地建模层级依赖关系以及引入了不必要的噪音,造成对下层长尾标签的预测性能尤其差,并且会导致标签不一致问题。针对以上问题,本文创造性地将多任务学习(multi-task learning,MTL)架构引入HMTC任务中,并基于此提出了MSML-BERT(multi-scale multi-layer BERT)模型。该模型将标签结构中每一层的标签分类网络视为一个学习任务,通过任务间知识的共享和传递,提高HMTC任务的总体性能。
在多任务架构的基础之上,针对问题(1),本文设计了多尺度特征抽取模块(multi-scale feature extraction module,MSFEM)用于捕捉不同尺度和粒度的特征,形成不同层级分类任务所需要的各种知识,以提高各层任务的预测性能;进一步,针对问题(2),本文设计了多层级信息传播模块(multi-layer information propagation module,MLIPM),用于充分建模层级依赖,并将上层的特征表示中关键的信息传播到下层特征表示中去,从而利用上层任务的知识来帮助下层的预测任务,以提高对底层长尾标签的预测性能,并降低预测的标签不一致性。在该模块中,本文设计了层次化门控机制(hierarchical gating mechanism),为了过滤不同层级任务之间的知识流动,保留有效知识而丢弃无效知识。最终,将MSML-BERT模型与目前主流的展平、局部和全局模型在经典的文本分类数据集RCV1-V2、NYT和WOS上进行了大量的对比实验,结果显示该模型显著地超过其他模型。另外,通过分层表现分析,证明了该模型在所有层级的表现上均显著地优于其他模型,尤其是对下层长尾标签具有更好的性能。然后,通过标签一致性分析,证明了该模型在具有强大的HMTC性能的同时,仍然保持较低的不一致比率,更加满足现实场景的应用需求。并且,通过消融实验证明了各个模块的有效性。
综上,本文的具体贡献如下:
(1)首次将多任务学习架构引入HMTC任务中,提出MSML-BERT模型,通过各层级任务之间知识的共享和传递,提高HMTC任务的总体性能。
(2)设计了多尺度特征抽取模块(MSFEM),用于捕捉不同尺度和粒度的特征,以形成不同层级任务所需要的各种知识,以提高各层级任务的表现。
(3)设计了多层级信息传播模块(MLIPM),用于建模层级依赖,在不同层级之间传递知识,以提升对下层长尾标签的预测表现,并降低预测的标签不一致性。在该模块中,设计了层次化门控机制(HGM),用于过滤不同层级任务之间的知识流动。
(4)在数据集RCV1-V2、NYT和WOS上与当前的主流方法进行了大量的对比实验,结果表明本文的方法显著超过了其他方法。分层分析表明该方法在各层级标签尤其是下层的长尾标签上的表现显著超过其他方法。通过标签一致性分析表明该方法能保持较低的标签不一致比率。
1 相关工作
1.1 层级多标签文本分类
在步入大数据时代之后,随着实际应用中将标签体系组织成层级结构的场景越来越多,HMTC任务也因此获得了广泛的关注[1]。根据探索层级标签结构方式的不同,HMTC方法主要可以分为:展平方法、局部方法和全局方法[4]。
展平方法是处理HMTC问题最简单的方法,这种方法假设层级结构中的所有标签都是独立的,并统一地对所有层级的标签进行展平的分类[10]。有些展平方法采用普通MTC的方式展平地预测所有层级的标签,而有些展平方法只预测叶子节点标签并启发式地添加它们的祖先节点标签,这是不合理的,因为层级结构信息都在一定程度上被忽略了。最近,一些神经网络方法在文本分类任务上取得了成功。RCNN[17]模型通过使用循环神经网络(recurrent neural network,RNN)来引入上下文信息进行后续的文本分类。Text-CNN[18]模型利用卷积神经网络(convolutional neural network,CNN)的特征抽取能力,使用不同尺寸的卷积核提取不同粒度的特征进行后续分类。Bi-BloSAN[19]模型将文本序列分成多个块,并分别使用块内注意力机制和块间注意力机制来捕捉局部和全局的上下文相关性。Peng等[20]通过修改以上经典的RCNN、Text-CNN和Bi-BloSAN等模型的输出层结构,并将它们应用于HMTC任务。Liu等[21]修改了Text-CNN模型的结构并提出了XML-CNN模型,通过增加瓶颈隐层和动态最大池化操作,用于解决HMTC任务。
局部方法训练一系列独立运行的局部分类器,并且预测通常以自上而下的顺序进行,因此在某一层产生的错误分类将会向下传播,这很容易让模型的预测产生偏差。Cai等[11]将支持向量机(support vector machine,SVM)扩展成为层级分类方法,该方法以反映层级标签结构的方式构建判别函数,称为HSVM模型。Ruiz等[22]提出HME模型,采用分而治之的原则,为标签结构的每一层单独构建分类器来处理。Bi等[23]提出CSSA模型,通过贝叶斯最优化的方式进行预测以降低总体风险,但是该模型仍然是以局部的方式进行训练的。Cerri等[24]提出HMC-LMLP模型,该模型通过增量训练的方式训练一组神经网络,每个神经网络负责预测给定层级的标签类别。
全局方法使用单个分类器并且更显式地对标签层次结构进行建模,模型通常采用端到端的方式训练并且对所有标签进行一次性地预测。Vens等[12]提出了Clus-HMC模型,该模型基于树方法,使用单个决策树(decision tree)来处理整个标签层级结构。Borges等[25]提出使用竞争性神经网络(competitive neural network)来解决多标签分类,称为MHC-CNN模型。Huang等[16]提出HARNN模型,通过使用分层注意力机制来捕捉文本和标签层级结构之间的关联,逐层地预测文本的多个标签。Zhou等[15]利用双向树形长短期记忆网络(bidirectional tree long short-term memory,Bi-TreeLSTM)和图卷积网络(graph convolutional network,GCN)结构来建模层次关系,并且对层级的标签进行展平化的预测。Peng等[20]提出HE-AGCRCNN模型,通过联合使用CNN、RNN、GCN和Capsule network结构来建模层次关系,进而提高HMTC任务的性能。
1.2 多任务学习
多任务学习受到人类学习过程的启发,旨在用有限的标记数据,借助于公共知识来提高多个相关任务的泛化性能[26-27]。
随着深度学习的蓬勃发展,近期的多任务学习方法主要分为两类:硬参数共享方法和软参数共享方法。其中,在硬参数共享方法中,每个任务的模型由共享层和任务特定层两个部分组成,共享层用于学习和共享通用的知识和表征,而任务特定层用于弥补不同任务之间的差异以及提高不同任务的泛化性[28]。而在软参数共享方法中,不同的任务拥有独立的模型,并且使用正则化的方法作用于不同模型参数之间的距离上,以使得相似任务的模型参数也相似[29]。
多任务学习在现实世界的任务中有很多的应用,比如在自然语言处理领域[30]、计算机视觉领域[31]等。多任务学习还与其他领域的知识相结合,产生了多任务多视角学习[32]、多任务强化学习[33]等。由于在HMTC任务中,不同层级的分类任务之间往往既存在共性又存在差异性,因此本文首次提出将多任务学习方法应用于HMTC任务中,将标签层级结构中每一层的标签分类问题都视为一个单独的任务去处理。本文采取的多任务学习方法是硬参数共享方法,模型包括共享层和任务特定层。本文提出的MSML-BERT模型借助于多任务学习的优势,以提高不同层分类任务的表现,同时提高HMTC任务整体的性能和泛化性。
2 基于MSML-BERT模型的层级多标签文本分类方法
首先,给出HMTC任务的问题定义:语料库中的所有标签组织成一个总体的标签层级结构,将该结构定义为T,一共有L层。语料库中所有标签组成一个标签集合S。任意一条文本作为模型的输入,定义为X。该条文本对应的标签集合定义为Y,该条文本对应的不同层的标签子集合分别定义为Y1,Y2,…,Y L。HMTC任务的目的是:设计一个模型,在给定任意一条文本输入X的情况下,预测出该条文本对应的标签集合Y,并且该标签集合Y中的多个标签要尽量满足标签结构T的约束。在MSML-BERT模型中,将任意一个神经网络定义为f(θ),其中θ为待估参数。
如图2所示,MSML-BERT模型是一个多任务学习的架构,包括共享层和任务特定层。其中BERT模型充当了整体模型的共享层,用于学习和共享通用的特征和知识。而不同层级的标签分类网络构成了不同的任务特定层,用于弥补不同任务之间的差异,并且学习每一个任务特定的特征表示。
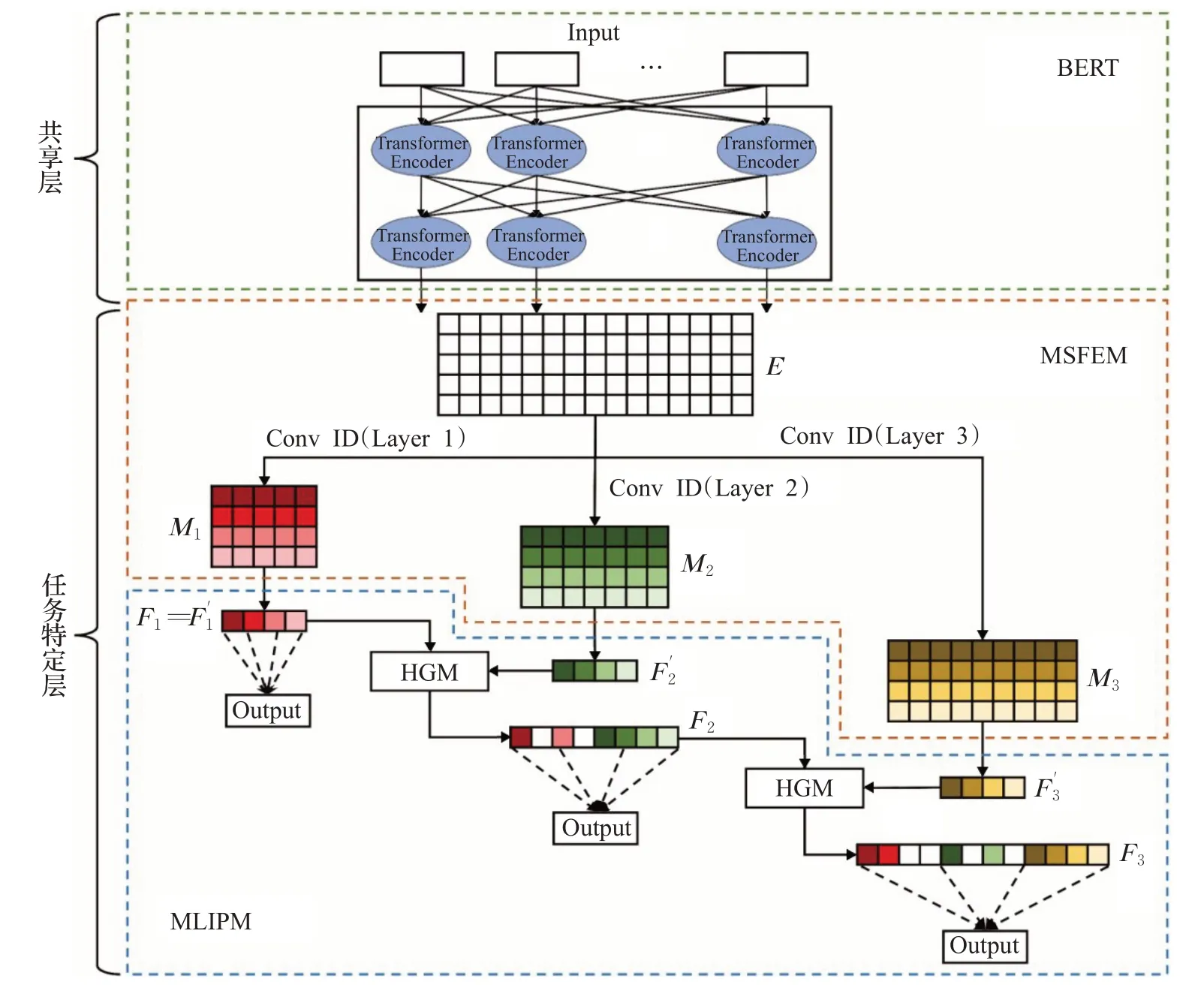
图2 MSML-BERT模型的总体结构Fig.2 Entire architecture of MSML-BERT
进一步地,任务特定层包括了多尺度特征抽取模块(MSFEM)和多层级信息传播模块(MLIPM)。
其中MSFEM用于根据不同层分类任务的需求,捕捉不同尺度的特征。而MLIPM用于将上层特征表示中有价值的信息传递到下层表示,帮助下层的标签分类任务,进而提升HMTC任务的整体性能。
2.1 模型共享层(Shared Layer)
本文采用预训练BERT[34]模型来作为MSML-BERT模型的共享层部分。BERT模型由堆叠了12层的Transformer Encoder[35]结构组成。Transformer Encoder结构主要包括两个子层:多头自注意力机制(multi-head self-attention mechanism)和前馈网络(feed-forward networks)。并且为了使模型能够有效地训练和加速收敛,在每个子层后面采用了残差连接(residual connection)和层归一化(layer normalization)的操作。通过多个Transformer Encoder结构的不断堆叠,BERT最终能够输出一个结合上下文信息的高级语义表征。然后,会将该语义表征传入后续不同的任务特定层进行处理,以用于不同层的分类任务。
2.1.1 Transformer Encoder结构
Transformer Encoder结构是BERT模型的基本组成单元,其基本结构如图3所示。每个Transformer Encoder结构包含两个子层:多头自注意力机制和前馈网络。同时,为了模型能够有效地训练和加速收敛,每个子层后面还采用了残差连接和层归一化的操作。
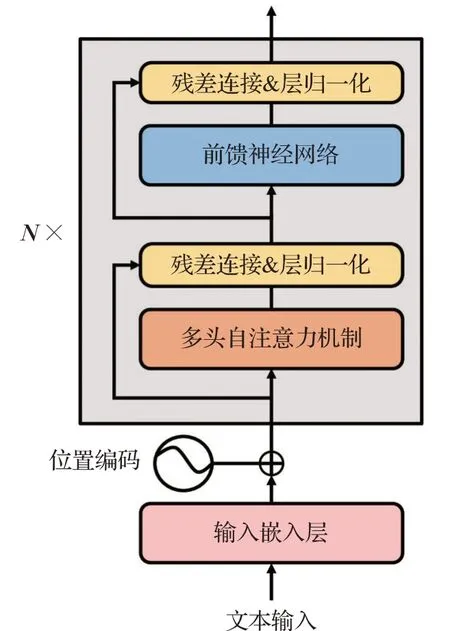
图3 Transformer Encoder结构Fig.3 Structure of Transformer Encoder
2.1.2 多头自注意力机制
在文本分类中,自注意力机制是一种非常有效的方法,通过分配不同的权重来突出文本语义表征中的不同部分。首先,将输入的文本X分别映射为矩阵Q、K和V,然后自注意力机制计算如下:

公式(1)是单头自注意力机制的计算过程,然而通常使用多头自注意力机制进行并行计算,用于捕捉不同维度的文本特征,计算方式如下:
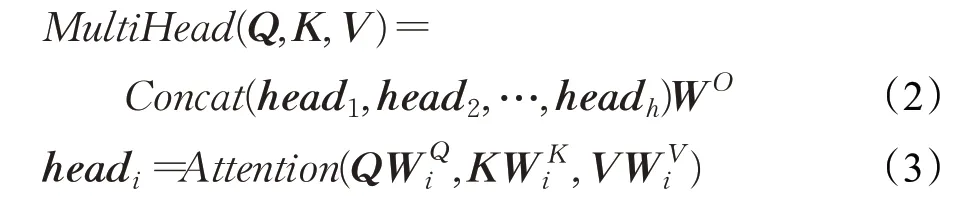
其中W Qi、W Ki、W Vi和W O都是系数矩阵,head i表示第i头的自注意力计算结果。
2.1.3 前馈网络
除了多头注意力机制,Transformer Encoder结构还包括前馈网络子层。该子层由两个线性变换组成,并且在两次线性变换中间穿插一个relu激活函数:
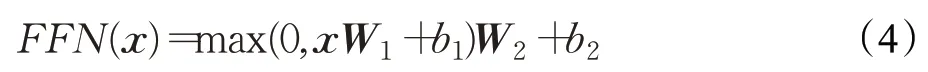
其中,W1和W2为系数矩阵,b1和b2为偏置项。前馈网络能够增强Transformer Encoder的非线性拟合能力。
2.1.4 残差连接和层归一化
残差连接最先由计算机视觉领域提出,用于解决深层神经网络的梯度消失问题[36]。层归一化是跨特征维度进行归一化计算,为了让深层神经网络的数据分布更加稳定[37]。
因为BERT模型是由多层堆叠的Transformer Encoder构成的,并且每层结构中又包括多头注意力机制和前馈网络子层,因此BERT的模型结构非常深,所以采用了残差连接和层归一化操作来防止梯度消失,同时也避免每一层数据分布不稳定的情况。公式如下:

其中,Sublayer表示自注意力机制或者前馈网络子层,Layer Norm表示层归一化操作,x表示子层的输入,y表示经过残差连接和层归一化操作之后的输出。
2.2 任务特定层(Task-specific Layers)
共享层的BERT模型输出一个通用的高级语义表示,随后会将该语义表示传入后续不同的任务特定层进行处理,以用于不同层的分类任务。根据层级标签结构的层数构建任务特定层,将每一层的标签分类问题都视为一个单独的任务。
任务特定层包括了MSFEM和MLIPM。一方面,MSFEM采用不同尺寸的CNN来捕捉多尺度的深层次结构特征,然后不同尺度的特征将用于不同层的标签的分类任务。并且CNN的计算可以并行化,运算速度快,将CNN用在不同的任务特定层中以提高各层任务的分类性能。另一方面,受到用于优化推荐任务的个性化特征门控机制的启发[38],本文设计了一个层次化门控机制(hierarchical gating mechanism,HGM)。MLIPM通过使用HGM,将上层任务中有价值的信息和有用的特征传递到下层任务中,同时丢弃那些冗余的特征。
2.2.1 多尺度特征抽取模块(MSFEM)
已知任意一条文本X经过共享的BERT层,得到该条文本的通用特征表示E∈ℝn×d,其中n表示输入文本的长度,d表示文本中每一个字向量的维度。

其中,E i∈ℝd表示文本中第i个字对应的字向量,E i:i+j表示字向量E i,E i+1,…,E i+j的拼接。
在通用文本表征E的基础上,MSFEM为不同层级的分类任务抽取多尺度的特征。该模块针对层级结构的不同层次,采用不同尺寸的一维卷积核作用于通用文本表征E,一维卷积核的高度与字向量的维度d相同,但是不同层级对应的一维卷积核的宽度不同。第l层的一维卷积核的宽度为h l(1≤l≤L),且满足h1>…>h l>…>h L。对于较上的层级采用较宽的一维卷积核提取粗粒度特征,对于较下的层级采用较窄的一维卷积核提取细粒度特征。
对于标签结构的第l层,采用K个宽度为h l的一维卷积核作用于文本表征E上以提取特征图M l,具体过程如公式(7)~(9)所示:

其中,W lk是标签结构中第l层所对应的第k个(1≤k≤K)一维卷积核权重矩阵,该一维卷积核作用于字向量窗口E i:i+hl-1产生一个新特征r i,其中b是偏置项,relu是激活函数。一维卷积核作用于每一个可能的字向量窗口上得到特征向量R,多个特征向量组合得到第l层对应的特征图M l。
最大池化操作作用于特征图M l中的每一个特征向量R i,得到相应最显著的特征r̂i。最终,将所有显著的特征拼接,得到对应层级结构中第l层的独立特征表示为F′l,具体公式如下:

至此,MSFEM为层级结构的每一层产生一个独立的特征表示F′l,用于该层的分类任务。
2.2.2 多层级信息传播模块(MLIPM)
上文通过MSFEM学习的文本在各个层级的特征表示F′l是相互独立的。根据文献[6]可知,同属于一个父类的类别共享某些公共的特征和信息,低层级的特征表示应该包含某些高层级的表示信息。因此,本文设计了MLIPM,将上层特征表示中有价值的信息传递到下层,通过将上层的某些特征信息与本层特征信息融合以产生本层的层次化表征,用于本层的分类任务。MLIPM块中采用了一个层次化门控机制(HGM),用来决定哪部分上层特征表示被保留到下层表示中,同时决定哪部分上层特征表示被舍弃。因此,第l层最终的层次化特征表示F l,应该由本层的独立特征表示F′l和上一层的层次化特征表示F l-1联合决定,具体计算过程如下:

其中,HGM表示层次化门控机制(hierarchical gating mechanism)。
具体来说,对于上层的层次化特征表示F l-1,下层的独立特征F′l表示只关注其中的有效特征部分,而忽略其他没有价值的信息。因此,HGM可以根据本层独立特征表示F′l的需求来量身定制地选择继承上层的层次化特征表示F l-1中有价值的那部分信息。如图4所示,HGM以上一层的层次化特征表示F l-1和本层的独立特征表示F′l作为输入,以本层最终的层次化特征表示F l作为输出。其中H Gating表示层次化门控单元,⊗表示逐元素乘法,⊕表示拼接操作。

图4 HGM的结构Fig.4 Structure of HGM
HGM的具体计算过程如下:
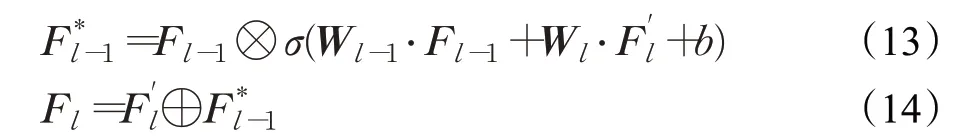
其中,W l-1和W l为权重参数矩阵,b为偏置项,σ为sigmoid激活函数。通过将W l-1和W l分别作用于F l-1和F′l并且通过sigmoid激活函数得到相应的门控分数。进一步,上层的层次化特征表示F l-1在门控分数的作用下生成中间表示F*l-1。最后,将上层对应的中间表示F*l-1与本层的独立的特征表示F′l拼接,从而得到最终的第l层的层次化特征表示F l。
2.2.3 模型输出
本文采用多任务学习的框架来处理HMTC任务,将每一层的多标签分类视为是一个任务。对于第l层的多标签分类任务,层次化特征表示F l首先被送入一个全连接层,如下公式所示:

其中,Wo表示全连接层的系数矩阵,b o表示偏置项,relu表示非线性激活函数,O l表示第l层对应的全连接层的输出。
最后,将第l层的全连接层输出O l逐元素地送入sigmoid激活函数进行输出,如下:

其中,σ表示sigmoid激活函数,表示层级结构中第l层的第j个类别的输出概率。
因此,第l层的损失函数可以定义为:

其中,ylj是层级结构中第l层的第j个类别的期望输出,|l|表示层次结构中第l层的总的类别数目。
MSML-BERT模型的总损失Ltotal为所有层的分类任务的损失之和,如下所示:
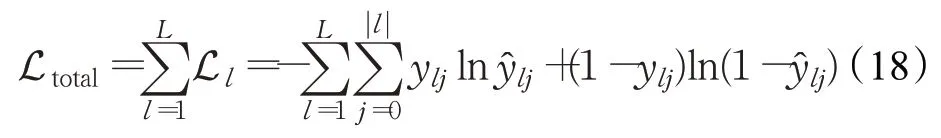
3 实验
3.1 实验准备
3.1.1 数据集和数据预处理
选择了三个经典的文本分类公开数据集用于HMTC实验,包括:RCV1-V2(reuters corpus volume I)数据集[39]、NYT(the New York Times annotated corpus)数据集[40]和WOS(Web of science)数据集[14]。其中,RCV1-V2数据集和NYT数据集都是新闻文本语料库,而WOS数据集包括来自Web of Science的已经发表论文的摘要。这些数据集的标签都组织成树状的层级结构。
根据前文,专注于多路径和强制性场景的HMTC任务,因此需要对这几个数据集做一定的预处理[6]。对于RCV1-V2和NYT数据集,选择满足多路径和强制性要求的那部分数据,即层级标签结构具有一条或者多条路径,并且不同路径的长度都等于3。由于WOS数据集本身就满足强制性需求,不需要对其进行预处理,但是需要注意WOS数据集对应的层级标签结构中路径的长度为2。然后随机地将这些数据集划分成训练集、验证集和测试集。相关数据的统计信息详见表1。

表1 数据集的统计信息Table 1 Statistics of datasets
3.1.2 评价指标
选取用于HMTC任务中常用的评价指标Micro-F1值和Macro-F1值[15],来衡量各个模型的表现。
(1)Micro-F1值
Micro-F1值是考虑到所有标签的整体精确率和召回率的F1值。用TPt、FP t、FN t分别表示总体标签集合S中第t个标签的真阳性、假阳性、假阴性。那么Micro-F1值的计算如下所示:

(2)Macro-F1值
Macro-F1值是另一种F1值,它计算标签结构中所有不同的类别标签的平均F1值。Macro-F1赋予每个标签相同的权重。形式上,Macro-F1值定义如下:

总的来说,Micro-F1值对所有的样本进行均等加权,而Macro-F1值对所有的标签进行均等加权。由于Micro-F1值对出现更频繁的标签赋予更大的权重,Macro-F1对所有标签赋予相同的权重,因此Macro-F1值对更难预测的底层标签更加敏感。
3.1.3 实验设置
MSML-BERT模型中共享层部分采用的是BERTbase模型[34]。BERT-base中包含的参数量约为109×106。BERT-base中有12层Transformer Encoder结构,每层的嵌入维度为768,前向层维度为3 072,注意力头数为12。在训练(training)和推理(inference)阶段,BERT编码器的最大长度设置为300。MSML-BERT模型在训练阶段的总损失是每个层级任务的损失之和,每个任务的损失的系数均设置为0.3。本文在训练MSML-BERT模型时选择Adam优化器,并将学习率设置为3×10-4,将batch size设置为15。其他的一些诸如dropout比率,权重衰减率等超参数的设置与原始预训练模型保持一致。本文使用Pytorch框架来实现MSML-BERT模型,并在GeForceRTX 2080 TiGPU上面进行实验。
3.2 实验结果
本文提出的MSML-BERT模型与其他目前主流的模型在RCV1-V2、NYT和WOS数据集上进行了详细的实验对比,具体的实验结果如表2和表3所示。选择的基线方法包括展平方法、局部方法和全局方法。其中展平方法包括RCNN模型[17]、Text-CNN模型[18]、Bi-BloSAN模型[19]和XML-CNN模型[21],局部方法包括HSVM模型[11]、HME模型[22]、CSSA模型[23]和HMC-LMLP模型[24],全局方法包括Clus-HMC模型[12]、MHC-CNN模型[25]、HARNN模型[16]、HiAGM模型[15]和HE-AGCRCNN模型[20]。为了更加明确地对比不同方法的性能,表2和表3中的每一类方法都按照性能由低到高的顺序排列。
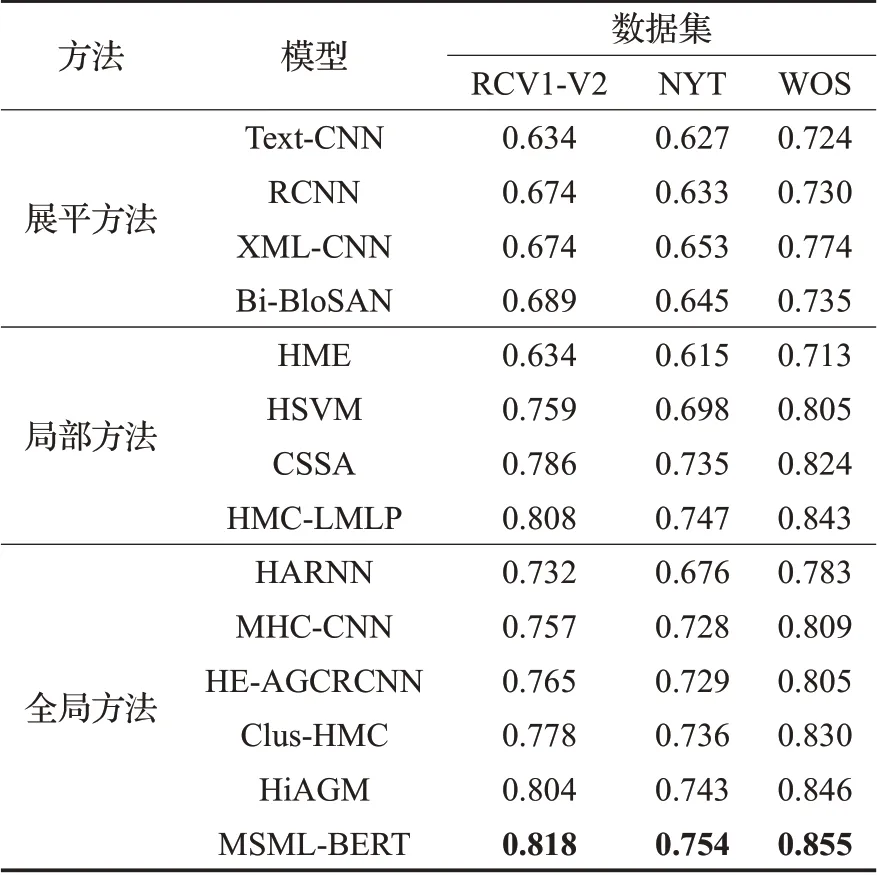
表2 Micro-F1指标上的表现Table 2 Performanceon Micro-F1
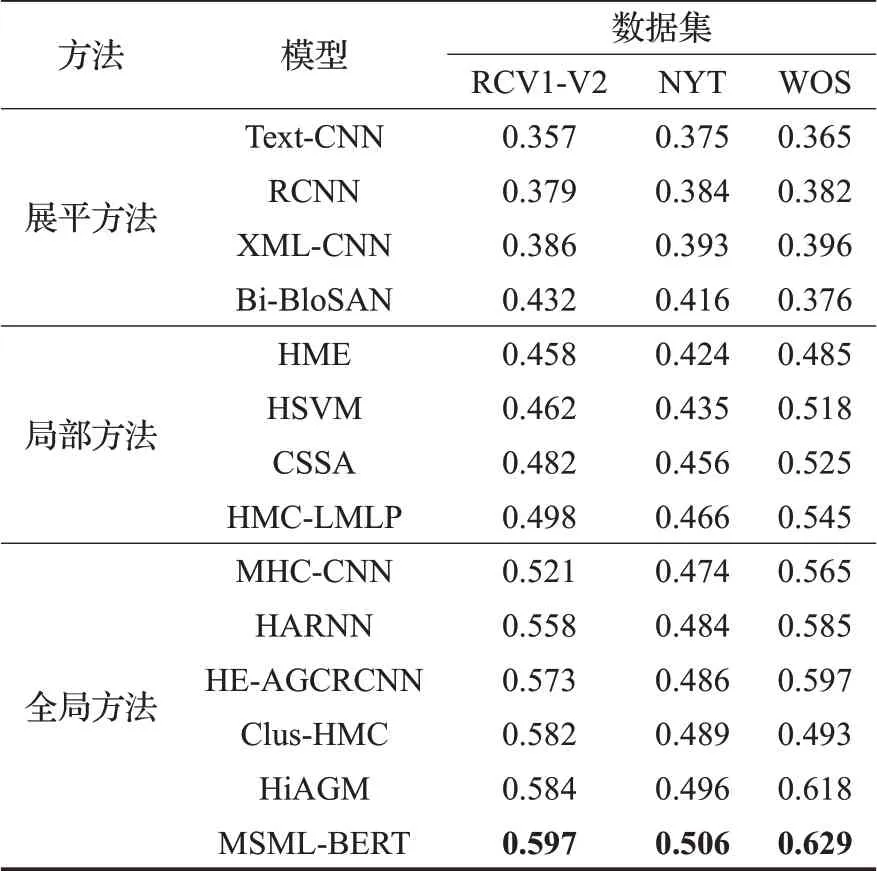
表3 Macro-F1指标上的表现Table 3 Performance on Macro-F1
所有模型在Micro-F1指标上的实验结果如表2所示,在三个文本分类公开数据集上,本文提出的MSMLBERT模型相比其他所有的展平方法、局部方法和全局方法均取得了更好的表现,这体现了MSML-BERT模型在解决HMTC问题上的优越性。MSML-BERT模型在RCV1-V2、NYT和WOS数据集上面取得的最好的Micro-F1值表现分别为81.8%、75.4%和85.5%,这说明了MSMLBERT模型在充分挖掘了层级标签结构,通过建模层次依赖有效地提升了HMTC任务的整体性能。
所有模型在Macro-F1指标上的实验结果如表3所示,取得了与Micro-F1指标上相一致的结论,即MSMLBERT模型在Macro-F1值指标上超过了其他所有的展平方法、局部方法和全局方法。MSML-BERT模型在RCV1-V2、NYT和WOS数据集上面取得的最好的Macro-F1值表现分别为59.7%、50.6%和62.9%。该模型在Macro-F1指标上取得了巨大的提升,结合Macro-F1指标对稀疏标签更加敏感的特性,可知MSML-BERT模型在预测下层的稀疏标签上具有更大的优势,这是因为本文的模型通过对层级依赖的建模,利用了从上层学到的知识来帮助下层标签的预测。
3.3 性能分析
首先,本文进一步做了消融实验来分别验证MSFEM和MLIPM的有效性。接着,本文做了模型的分层表现分析来进一步探究模型在不同层级上面的具体表现。最后,本文做了模型预测的标签一致性分析,来验证模型是否符合现实应用场景的需求。
3.3.1 消融实验
本文使用MSML-BERT在RCV1-V2数据集上面做了消融实验分析,实验结果如表4所示。在表4中,BERT表示采用普通MTC的方式,直接使用BERT模型统一对所有层级的标签进行一次性的展平分类;MS-BERT相比BERT多了MSFEM,表示采用多任务架构,分别处理每一层的标签分类任务,使用MSFEM抽取多尺度的特征,用于不同层的标签分类任务;MSMLBERT即是本文提出的最终模型,在MS-BERT的基础之上又多了MLIPM,该模块用于将上层中的有效信息传播到下层,以帮助下层的标签分类任务。
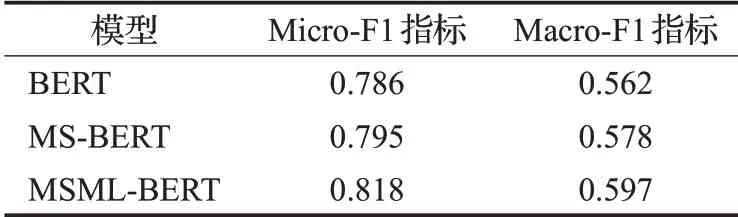
表4 MSML-BERT模型的消融分析Table 4 Ablation analysis of MSML-BERT
表4的前两行说明了MSFEM的有效性。通过MSFEM,模型可以捕捉不同层分类任务所需要的多尺度的特征,使得模型能够充分挖掘层级结构的信息。因此,该模块提高了每一个层级的分类性能,进而提升HMTC任务整体的表现。该模块使得模型的Micro-F1指标和Macro-F1指标分别提高了0.9和1.6个百分点。
类似地,表4的后两行说明了MLIPM的有效性。借助于MLIPM,模型将上层表征中的有效信息传播到下层表征中去,然后对不同层级的多尺度特征做充分的融合,使得模型能够很好地建模层次依赖关系。借助于该模块,模型提高了下层标签的预测表现,同时也提高了整体任务的性能。该模块使得模型的Micro-F1指标和Macro-F1指标分别提高了2.3和1.9个百分点。
3.3.2 分层表现分析
在HMTC任务中,除了预测整个标签层级结构中的所有标签,准确地预测每个层级的标签类别也同样重要。因此,本文在每个层级上都将MSML-BERT模型与其他模型的表现做了对比。实验在RCV1-V2数据集上进行,并且选用对模型表现更敏感的Macro-F1值作为对比指标。
关于不同层级的表现,本文将所提出的方法与表2、表3中的所有展平方法、局部方法和全局方法进行了对比,结果显示本文提出的MSML-BERT模型在每个层级上都获得了最好的表现并且显著地优于其他模型。由于其他方法的分层表现比较接近,在图上显示比较密集,为了获得更加清晰的视图,本文在对比的展平方法、局部方法和全局方法中分别选取两种在分层性能上表现最好的方法展示于图中,详细结果见图5。该图显示,MSML-BERT在标签结构的所有层级上的Macro-F1值表现都优于其他方法,这是因为MSML-BERT模型相比其他模型更加充分挖掘了层级结构信息,同时也因为MSML-BERT模型建模了层级依赖关系。

图5 模型在不同层级上的表现Fig.5 Model performance in different layers
此外,图5显示随着层次的深入,MSML-BERT模型与其他模型之间的差距也越来越大。这说明随着层级的增长,标签预测变得越来越困难,MSML-BERT利用从上层表征中学习到的知识来帮助下层长尾标签分类的策略变得越来越有价值。
3.3.3 标签一致性分析
标签不一致问题是HMTC任务中的一个严重的问题,因为它违反了实际应用场景的需求,但是标签不一致很难被诸如Micro-F1值的这种标准评价指标所反映出来[5]。标签不一致经常发生在那些采用统一的方式处理不同层的标签分类任务的方法中,这些方法往往采用统一的方式处理不同层级的标签分类任务,独立地预测所有标签,一定程度上忽略了标签层级结构信息,因此会导致标签不一致性的出现。
现有研究中通常使用标签不一致比率来衡量标签不一致性,标签不一致比率为具有不一致标签的预测数与总预测数的比例。值得一提的是,本文提出的MSML-BERT模型在具有出色的分类性能的同时,也保持了较低的标签不一致比率,使得标签不一致比率显著低于其他方法。本文在RCV1-V2数据集上做了MSML-BERT与其他模型的标签不一致性对比实验。实验结果表明MSML-BERT模型与其他所有的对比模型相比,具有最低的不一致比率,为了表格更加简洁,本文在对比的展平方法、局部方法和全局方法中分别选取两种不一致率最低的方法展示于表格中,实验结果详见表5。这是因为该模型分别把每一层的标签分类问题当做一个单独的任务去处理,同时本文在处理当前层任务的时候,也会结合使用其他层的信息,因此能够获得较低的标签不一致比率。

表5 标签不一致比率Table 5 Label inconsistency ratio
4 结束语
本文首次将多任务学习框架引入HMTC任务中,并提出了MSML-BERT模型,通过各层级任务之间知识的共享和传递,提高模型在HMTC任务上的整体性能。基于此,设计了多尺度特征抽取模块,用于捕捉不同粒度和尺度的特征,形成不同层任务所需的知识,以提高各层级任务的性能。同时设计了多层级信息传播模块,用于充分建模层级依赖信息,将上层任务的知识传递到下层任务中,以提升对底层长尾标签的预测性能。在RCV1-V2、NYT和WOS数据集上进行了大量的实验,结果显示该模型的整体性能显著超过其他模型。分层表现分析显示该模型在各层标签尤其是底层长尾标签上的表现显著优于其他模型。标签一致性分析表明本文方法具有更低的标签不一致比率,具有更好的现实应用价值。
