基于双分支网络联合训练的虚假新闻检测
2022-08-09郭铃霓吴兴财杨振国刘文印
郭铃霓,黄 舰,吴兴财,杨振国,刘文印,2
1.广东工业大学 计算机学院,广州 510006
2.鹏城实验室网络空间安全研究中心,广东 深圳 518000
互联网时代,推特、微博、微信等在线社交媒体平台的快速发展,给读者获取新闻资讯提供了便利,也为虚假新闻的滋生和传播提供了土壤。《2019年网络谣言治理报告》(http://society.people.com.cn/n1/2019/1226/c1008-31524533.html)指出,2019年期间,微信平台共发布17 881篇辟谣文章,辟谣文章阅读量1.14亿次。其中,医疗健康、食品安全、社会科学是虚假新闻的高发领域。
虚假新闻的泛滥,给社会和人们的日常生活带来不同程度的负面影响。例如,新冠肺炎疫情期间,各种虚假新闻层出不穷,包括但不限于:“盐水漱口防病毒”“喝板蓝根可以预防新型冠状病毒”“双黄连口服液能抑制新型冠状病毒”等。诸如此类的虚假新闻,导致相关商品遭哄抢脱销,不仅误导群众,还扰乱市场经济。Vosoughi等人指出,相比于真实新闻,虚假新闻传播更快、更频繁[1]。因此,对虚假新闻进行检测,具有重要意义。
最初的虚假新闻检测主要依赖于官方辟谣网站,由相关领域的多位专家对新闻的真实性进行研判。这种方式需要专家知识,不仅耗费大量的人力物力,而且时效性差。近年来,基于机器学习和深度学习的虚假新闻自动检测技术得到了发展。目前的虚假新闻检测方法大致可以分为基于内容的检测方法和基于社交上下文的检测方法。两种方法的区别在于是否使用社交上下文信息。例如,新闻在社交媒体上的传播路径、社交用户彼此之间的关系网络、社交用户的参与情况(点赞、转发、评论)等。社交上下文信息越丰富,越有利于虚假新闻检测。然而,基于社交上下文的虚假新闻检测方法不适用于虚假新闻早期检测,当新闻在新闻渠道上发布但尚未在社交媒体上传播时,社交上下文信息不充分。虚假新闻早期检测具有实际意义,当虚假新闻曝光的次数越多,并且反复出现在社交用户视野中时,用户越容易相信其真实性。一旦用户认为虚假新闻是真的,就很难改变他们的认知。基于新闻内容的检测,由于不需要考虑社交上下文信息,数据容易获取且能够实现虚假新闻的早期检测,受到越来越多的关注。已有研究通常把新闻文本内容作为整体,进行虚假新闻检测,较少考虑到新闻标题和正文之间的语义关联性。如果一则新闻并非真实发生,为了吸引读者,通常会采用猎奇、煽动性的标题,往往与正文内容无关。虽然带有“标题党”的新闻文章通常并不可靠,但并非所有这些新闻文章都是虚假新闻,这促使去探索虚假新闻和“标题党”之间的关系。
为解决上述问题,本文提出一种基于双分支网络联合训练的虚假新闻检测模型(jointly training twobranch network,JTTN),该模型由两个分支子网络构成,分别是最大池化网络分支(max pooling network branch,MPB)和广义均值池化网络分支(generalized mean pooling network branch,GPB)。MPB采用卷积神经网络进行文本特征提取,GPB在卷积神经网络的基础上,引入了可训练的池化层,两个分支网络联合训练,共同学习新闻内容潜在的语义特征。在每个分支子网络中,对新闻的标题和正文之间进行语义关联性度量。最终,对两个分支子网络联合训练后的结果进行决策融合,输出模型的预测结果。
1 相关工作
1.1 基于内容的虚假新闻检测
基于内容的虚假新闻检测方法指利用新闻的内容进行检测,包括文本信息(标题、正文、网页链接),视觉信息(图片、表情包),音频信息等。现有研究大多集中在新闻的文本内容上,从中提取统计特征或语义特征。Castillo等人[2]基于新闻文本内容的语言特征来检测虚假新闻,他们设计了一份语言特征列表,如问号、表情符号、情绪正负词和代词,来衡量推特上信息的可信度。Popat[3]发现,文章的语言风格对于理解文章的可信度起着至关重要的作用。然而,基于语言风格的特征不具备语义信息,很容易被操纵。Feng等人在文献[4]中使用上下文无关的语法规则识别虚假信息。Ma等人[5]首先探索了通过捕获时间语言特征来用深度神经网络表示新闻的可能性。Chen等人[6]将注意力机制引入到循环神经网络中,以集中捕获独特的时间语言特征。随着多媒体技术的发展,虚假新闻试图利用带有图像或视频的多媒体内容来吸引和误导读者,以便迅速传播。Qi等人[7]从图像角度出发,通过探索图像物理层面和语义层面的不同特征,提出了一个多域视觉神经网络模型来融合频域和像素域的视觉信息,从而进行虚假新闻检测。该模型对不同数据集的泛化能力仍需进一步验证。Xue等人[8]进一步挖掘虚假图片的信息,对图片的像素域特征和频域特征进行融合后,作为视觉特征。同时,引入了图片的物理属性,最后通过集成学习联合视觉特征和物理特征,实现虚假新闻图片检测。
大部分基于内容的虚假新闻检测工作通常把新闻标题和正文作为一个整体来进行语义和风格特征的分析,较少工作直接从“标题党”的角度出发,即分析标题和正文之间存在的差异和关联性。虽然已经有针对“标题党”检测任务的研究工作[9],但该工作的重点在于识别新闻是否存在“标题党”的现象。因此,基于“标题党”检测的思想,本文重点探索新闻标题和正文之间的语义关联性,利用最大均值差异(maximum mean discrepancy,MMD)[10]进行度量。结合深度神经网络和不同的池化操作进行联合训练,自动提取文本的潜在特征,以检测新闻的真实性。
1.2 基于社交上下文的虚假新闻检测
基于社交上下文的虚假新闻检测方法通过探索与新闻相关的社交上下文信息来检测虚假新闻,即新闻在社交媒体上的传播方式以及用户的参与情况等。社交用户和新闻之间的互动所建立的社会联系,为新闻提供了丰富的社交上下文信息。社交上下文信息代表了用户在社交媒体上对新闻的参与情况[11],例如关注者数量、评论、点赞、话题标签和分享转发的网络结构。Wu等人[12]利用社交媒体上的用户资料和新闻传播路径来分类虚假新闻。Liu等人[13]将新闻的传播路径作为多元时间序列来建模,结合RNNs和CNNs网络来检测虚假新闻。然而,在虚假新闻的早期检测阶段,即新闻在新闻渠道上发布但尚未在社交媒体上传播时,不能依靠新闻的传播信息,因为它们并不存在[14]。Ma等人[15]基于树状结构的递归神经模型来学习推文的表示。Jin等人[16]使用了手工提取的关注者数量、转发量等社交上下文特征。尹鹏博等人[17]通过对用户的历史微博进行分析,结合用户属性和微博文本,采用C-LSTM模型实现谣言检测。沈瑞琳等人[18]提出基于多任务学习的微博谣言检测方法,利用情感分析任务辅助谣言检测,在一定程度上解决了深度学习中带标签数据不足的问题,但模型对相关的辅助数据具有依赖性。
社交上下文信息通常是非结构化数据,需要通过大量的手工劳动来收集。同时,社交上下文特征需要经过一段时间的积累才能提取出来,不能及时检测新出现的虚假新闻。在新闻还没在社交媒体上传播开来之前,需要使用基于内容的检测方法,因为在这个阶段还不存在丰富的社交上下文信息。因此,本文基于新闻内容本身,通过挖掘潜在的信息来进行虚假新闻检测。
2 方法
本文提出的基于双分支网络联合训练的虚假新闻检测模型结构如图1所示,模型由两个分支子网络组成,分别是MPB和GPB。每个分支子网络包含了三个模块:(1)文本特性提取器;(2)标题正文间语义关联性度量;(3)虚假新闻分类器。首先,文本特性提取器分别提取新闻文章的标题特征和正文特征,并使用MMD来度量它们之间的语义关联性,然后将两个特征进行加权融合,作为虚假新闻分类器的输入。最后,对两个分支子网络联合训练的分类结果进行决策融合,输出模型的预测结果(真实或虚假)。MPB采用最大池化进行下采样,GPB采用广义均值池化进行下采样。
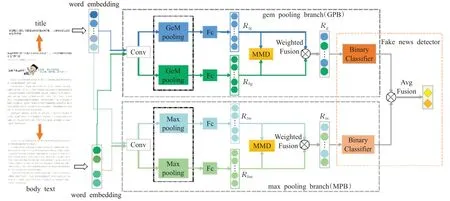
图1 JTTN模型Fig.1 JTTN model
2.1 文本特征提取
给定一篇由标题T(title)和正文B(body text)组成的新闻文章A={T,B},在不同的分支子网络中,采用不用的文本特征提取方法。在MPB中,本文使用卷积神经网络Text-CNN[19]来学习新闻的特征表示。Text-CNN利用不同窗口大小的多个卷积核来捕获文本的特征信息。对于标题T中的每个字,对应的d维词嵌入向量表示为x lt∈Rd,l=1,2,…,n t。本文使用下标t来标识标题T,使用下标b来标识正文B。新闻标题的词嵌入向量序列可表示为:

其中,T1:n t∈Rn t×d,⊕表示拼接操作,n t为新闻标题的长度。窗口大小为h的卷积核以标题中h个词的连续序列作为输入,对其进行卷积操作,输出特征映射。以从第i个字开始的连续序列为例,卷积操作可表示为式(2):

其中,x i:(i+h-1)t∈Rh×d,⊕表示拼接操作,w t为卷积核,b t为偏置项,σ(·)是ReLU激活函数。对卷积操作后得到的特征映射进行最大池化操作,实现降维。池化层对特征映射取最大值,从中提取出最重要的信息。每个特征映射经过最大池化后,可表示为:

最后,将池化后的结果输入全连接层,得到标题的特征表示为:

其中,R tm的下标tm表示标题特征通过MPB子网络获得,W tm表示权重矩阵,∈Rk,k表示不同窗口大小的卷积核数目。
类似地,对于长度为nb的新闻正文B,经过d维词嵌入后,可表示为:

采用跟上述新闻标题相同的特征提取方式,新闻正文特征可表示为:

Text-CNN的池化层采用最大池化操作,在减少模型参数量的同时能保证特征的位置和旋转不变性,但是忽略了文本特征的位置信息。Radenović等人在文献[20]中提出了一种可训练的广义均值池化层(GeM pooling layer),并证明其能够显著提高检索性能。广义均值池化介于最大池化和均值池化之间,二者是其特殊形式。
因此,在GPB子网络中,基于Text-CNN的网络结构,采用广义均值池化代替原来的最大池化方式,来捕获不同粒度的特征信息。对于公式(2)得到的每个特征映射cit,分别进行广义均值池化操作。计算公式可表示为:

当p i=1时,广义均值池化相当于均值池化,当pi→∞时,广义均值池化相当于最大池化。相比于最大池化,广义均值池化包含可学习的参数p i,对输入的样本先求p次幂,然后取均值,再进行p次开方。
将池化后的结果输入到全连接层,得到新闻标题的特征表示为:

其中,R tg的下标tg表示标题的特征表示通过GPB子网络获得,W tg为权重矩阵,b tg为偏置项。
类似地,对于新闻正文B,通过GPB子网络获得的特征表示为:

2.2 标题正文间语义关联性度量
一篇完整的新闻通常由标题(短文本)T和正文(长文本)B组成。受到“标题党”检测任务的启发,发现虚假新闻发布者为了吸引更多读者阅读和传播虚假信息,通常会使用夸大、猎奇、色情的标题来吸引眼球,新闻的正文内容往往与标题不匹配。但仅仅检测“标题党”还不够,因为一些真实新闻也会存在“标题党”现象。因此,在上述文本特征提取过程中,使用两个分支网络,充分挖掘新闻的语义信息。接下来,本文使用最大均值差异来度量新闻标题和正文之间的语义关联性。最大均值差异是迁移学习,尤其是域适应中使用最广泛的一种损失函数,主要用来度量在再生希尔伯特空间中两个分布的距离。
假设一篇新闻的标题和正文来自于两个文本语义分布,分别表示为X T和X B。如果标题跟正文描述同一件事情,在语义上相关,则认为它们所在的分布相同,该新闻倾向于是真实新闻。反之,该新闻倾向于是虚假新闻。本文使用MMD来度量标题和正文两个分布间的距离,距离定义为:

其中,σ(·)表示映射函数,用于把原变量映射到再生希尔伯特空间。如果一篇新闻是虚假新闻,则它的标题和正文之间的MMD距离要比真实新闻大,关联性更小。本文目的在于最大化虚假新闻的标题和正文之间的MMD距离。如果这个值足够小,就认为两个分布相同,否则就认为它们不相同。MMD距离损失函数可以表示为:

其中,θT={θtm,θt g}表示新闻标题特征提取过程中所需参数,θB={θbm,θbg}表示新闻正文特征提取过程中所需参数。
2.3 虚假新闻分类器
到目前为止,通过文本特征提取器,分别获得新闻标题和正文的特征表示。在MPB中,标题T的特征表示为R tm,正文B的特征表示为R bm。在GPB中,标题T的特征表示为R tg,正文B的特征表示为R bg。在每个分支网络中,分别对标题特征和正文特征进行加权融合,融合后的特征作为虚假新闻检测器的输入,然后连接含Softmax函数的全连接层来预测新闻的真假。虚假新闻分类器可表示为Ld(·;θd),θd表示分类器中的所有参数。对于第i篇新闻ai,虚假新闻检测器的最终输出记为pθ(ai),表示该新闻是虚假新闻的概率。
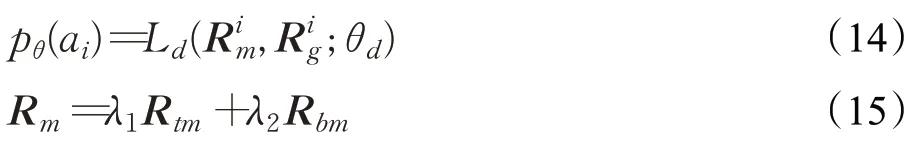

其中,R m、R g分别表示一篇文章在MPB和GPB中融合后的特征。λ1、λ2、λ3、λ4分别表示加权权重。虚假新闻检测器的目的在于识别某一篇文章是否是虚假新闻。用Y表示新闻文章集合A的真实标签集合,使用交叉熵损失函数作为虚假新闻检测器的分类损失:
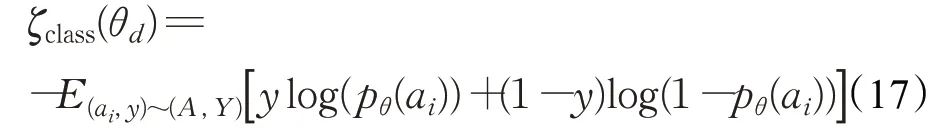
其中,a i表示某一篇文章,y表示该文章对应的真实标签。目的在于寻找最优的参数来最小化分类损失,这个过程可以表示为:

2.4 双分支联合训练
为了从不同范围和粒度捕获新闻文章的文本信息,采用了双分支网络联合训练的方法,分别为MPB和GPB。在每个分支网络里,基于Text-CNN和不同的池化方式,提取新闻的标题和正文特征,然后利用MMD度量标题和正文之间的语义距离并约束两个分布的特征。最后,两个分支网络联合训练,输出虚假新闻检测任务的预测结果。这样做的目的在于,(1)检测虚假新闻;(2)充分探索新闻的标题和正文之间的语义关联性。模型最终的损失函数可以表示为:

其中,ζclass(·)表示交叉熵分类损失。ζmmd m(·)表示在MPB中,标题和正文间的语义关联损失。θtm、θbm分别表示在MPB中标题和正文特征提取过程中所需要的参数。类似地,ζmmd g(·)表示在GPB中标题和正文之间的语义关联损失。θtg、θbg分别表示在GPB中标题和正文特征提取过程中所需要的参数。目的在于最小化最终的损失函数,该过程可以表示为:
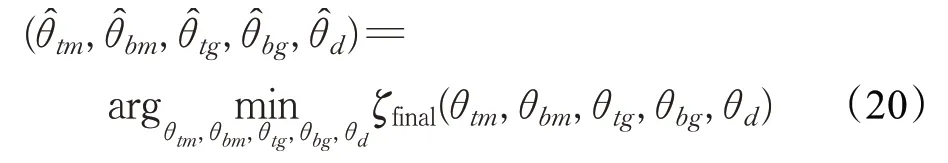
其中,θtm、θbm、θtg、θbg、θd表示MPB子网络、GPB子网络以及分类器中包含的参数,例如卷积核、权重矩阵、偏置项等。通过反向传播算法对上述参数进行更新,其优化过程见算法1。每轮训练都采用Adam优化器,通过自适应调整学习率来优化网络的收敛速度。在网络训练过程中,采用Early Stop策略,当模型的性能无明显变化时,停止训练。
算法1JTTN
输出:网络参数θtm,θbm,θtg,θbg,θd
1.随机初始化网络参数:θtm,θbm,θtg,θbg,θd
2.whilenot convergence do/*当网络未收敛时*/
3. for each epochdo/*对于每一轮迭代,执行以下步骤*/
4. for each mini-batch do/*对于每一个批处理,执行以下操作*/
10. end for
11. end for
12.end
13.返回网络参数:θtm,θbm,θtg,θbg,θd
3 实验与结果分析
3.1 数据集
为评估本文所提出的模型性能,研究采用Wang等人公开的新闻数据集[21]进行实验。该数据集(https://github.com/yaqingwang/WeFEND-AAAI20)收 集 了 从2018年3月到2018年10月,微信公众号发布的新闻文章。公开的新闻数据集包含了微信公众号名称(新闻发布者)、新闻标题、新闻链接、新闻封面链接、用户反馈报告以及新闻标签(fake or real)这六项信息。为了能够探索新闻标题和正文之间的语义关联性,从而进行虚假新闻检测,在该数据集的基础上,做进一步的信息收集和数据清洗。根据数据集公开的新闻链接和封面链接,通过网络爬虫技术爬取了每一篇新闻对应的文章正文,封面图片以及文章内部的图片。由于受到微信营运平台的监管和读者的反馈举报,很多新闻都已经失效,特别是虚假新闻。通常情况是新闻文章被删除或者公众号被封号,这导致不能爬取到所有完整的数据。因此,对于已经失效的新闻文章,只保留它们的标题信息。最终得到的数据统计信息如表1所示。本文使用新闻的标题和正文数据作为模型的输入。

表1 新闻数据集统计信息Table 1 Statistics of news dataset
3.2 对比实验
为了验证本文方法的有效性,选取了目前虚假新闻检测任务常用的方法作为基线方法进行对比。
(1)CNNT:CNNT只使用新闻标题作为输入,由于缺乏正文,所以在JTTN模型的基础上去掉标题和正文之间的语义关联性度量,然后使用双分支网络进行特征提取,再通过分类器进行二分类。
(2)CNNB:CNNB只使用新闻正文作为输入,其余设置与CNNT相同。
(3)LSTM:LSTM使用一层LSTM作为文本特征提取器,通过对RNN在每个时间步长的输出进行平均,得到潜在表示,然后将这些表示输入到全连接层进行预测。建立在LSTM特征提取器之上的全连接层输出新闻是虚假新闻的概率。
(4)HAN[22]:HAN基于新闻的内容,构建了一个层次注意力神经网络框架来进行虚假新闻检测。它对新闻内容进行编码,采用“词-句子-文章”的层次化结构来表示一篇文章,在句子级别关注词层次,在文档级别关注句层次。
(5)Att-RNN[16]:Att-RNN利用注意机制来融合文本、视觉和社会上下文特征。实验中,去除视觉和社会上下文信息,其余部分相同。
(6)EANN[23]:EANN由三个主要部分组成,多模态特征提取器、虚假新闻检测器和事件鉴别器。多模态特征提取器从帖子中提取文本和视觉信息,它与虚假新闻检测器一起学习可识别的特征表示来检测虚假新闻。事件鉴别器负责删除任何特定于事件的特征。由于输入只有文本信息,所以去除了视觉特征提取器和事件鉴别器。
(7)SAFE[24]:SAFE基于Text-CNN提取新闻文本特征,通过计算新闻文章文本和视觉信息之间的相似性,实现虚假新闻检测。该模型以完整的新闻文章作为输入,设置了与文献[24]相同的超参数。
3.3 评估方法与参数设置
本文使用准确率(Accuracy)、精确度(Precision)、召回率(Recall)、F1值(F1-score)作为评估指标。通常F1值越高,说明分类器性能越好。实验采用PyTorch深度学习框架来构建虚假新闻检测模型并进行模型训练。根据新闻的发布日期,按照7∶1∶2的比例划分数据集,70%作为训练集、10%作为验证集、20%作为测试集。其中,最新发布的新闻文章作为测试数据。在参数设置方面,新闻标题长度n t设为32,正文长度nb设为300,不足部分用0填充,超出部分删除。标题和正文的嵌入维度d均设为300,最后加权融合后的特征维度为128维。Text-CNN有三种卷积核,大小分别为2、3、4,每种卷积核的数量为200。在网络训练过程中,使用Adam优化器,设置批处理大小为256,迭代次数为200,学习率为1E-3。MMD中的映射函数φ(·)为高斯核函数。
3.4 实验结果及分析
表2显示了本文方法跟其他方法的实验对比结果。实验结果表明,针对虚假新闻检测任务,本文提出的方法在准确率、精确度和F1值上均优于其他方法,取得了最好的分类性能。针对实验结果,有以下几点分析:(1)从CNNT和CNNB的实验结果可以看出,将新闻标题和正文一起作为模型的输入来检测虚假新闻,其性能优于仅使用标题或者正文作为模型的输入。由此可验证新闻标题正文间语义关联性度量的有效性。(2)HAN采用了词层级和句层级的注意力机制,目的在于提取出文章中贡献最大的词和句子。这种解决方法,对文本分类能起到很好的效果,但不适用于虚假新闻检测,因为虚假新闻也是围绕一个主题展开描述。仅仅依靠文章最重要的信息,无法有效地检测虚假新闻,导致虚假新闻预测结果的F1分数偏低。(3)LSTM擅长处理时序信息,在文本任务中,它能够更好地联系上下文信息提取特征,但虚假新闻检测任务更注重语义风格等的局部特征,对时序特征不会过分依赖,因此使用Text-CNN进行特征提取的EANN模型能够更好地提取文本的局部特征,在虚假新闻检测任务上表现得更好。(4)SAFE通过引入额外的全连接层来扩展Text-CNN,以自动提取每篇新闻文章的文本特征。与之不同的是,本文方法引入了可训练的池化层,通过训练网络自动调节参数,进一步学习新闻潜在的文本特征,故其总体性能优于SAFE。(5)本文的模型使用双分支网络进行联合训练,能够充分地挖掘新闻文章潜在的语义风格特征,从而捕获虚假新闻与真实新闻的差异。另外,基于“标题党”检测的思想,通过度量新闻标题和正文之间的语义关联性,能更好地检测出虚假新闻。

表2 JTTN模型与其他方法的实验结果对比Table 2 Comparison of experimental results between JTTN model and other methods
3.5 不同关联性度量方法对比
为了分析不同关联性度量方法对实验结果的影响,共设计了4种变体:(1)去掉标题和正文之间的语义关联性度量(-MMD)。(2)使用CORAL[25]作为度量方法(CORAL)。(3)使用余弦相似度作为度量方法(COS)。(4)使用最大均值差异作为度量方法,即本文提出的方法(MMD)。实验结果如表3所示,结果表明,在4种变体中,使用最大均值差异作为度量方法的实验结果最好,使用余弦相似度作为度量方法的效果次之。实验结果也表明新闻标题和正文之间的语义关联性度量对虚假新闻检测任务的有效性。

表3 不同关联性度量方法的实验结果Table 3 Results of different correlation measurement methods
最大均值差异比余弦相似度表现更优的原因在于:余弦相似度假设在语义特征空间中,两个特征向量对应位置的元素特征是对齐的,但这种假设过于严格,在异构源向量中通常是无效的。而最大均值差异是将两个特征向量映射到再生希尔伯特空间中,通过核学习方法,来度量两个分布之间的距离,并不要求两个特征向量间的元素特征对齐,更适用于度量标题和正文间的语义关联性。
3.6 单分支网络与双分支网络实验结果对比
为了探究双分支网络联合训练模型是否比单分支网络训练更有效,本文设计了单分支网络与双分支网络的对比实验。以本文设计的JTTN模型为基础,分别去掉其中的一个分支,作为单分支网络。实验结果如图2所示,其中,MPB、GPB分支表示单分支网络,JTTN表示双分支网络。
从图2的结果可以看出,双分支网络的准确率和F1值均比单分支网络高。双分支网络的F1值分别比MPB和GPB高出了0.016和0.015。证明了双分支网络联合训练比单分支网络单独训练效果更好。

图2 单分支网络与双分支网络实验结果对比Fig.2 Comparison of single-branch network and two-branch network experimental results
3.7 参数分析
在损失函数计算公式(19)中,α和β被用来权衡交叉熵分类损失(α)和语义关联损失(β)之间的相对重要性。为了评估α和β对模型性能的影响,设计了相关实验,分别设置α和β的值从0递增到1,步长设置为0.2。在α和β不同的取值下,模型的检测结果(准确率和F1值)如图3所示。可以看出,相比于α,不同的β值对模型性能的影响较为显著。当β的取值较大时,模型的准确率和F1值较高,分类器效果较好。由此,可以验证模型中标题正文间语义关联性度量的可行性和有效性。图3(a)中,准确率的变化范围从0.982到0.988,α和β的不同取值对准确率的影响不明显。图3(b)中,F1值的变化范围从0.91到0.95,相差了0.04。从实验结果可知,当α=0.2;β=0.4或者α=0.4;β=1时,也就是说,当α∶β≈1∶2.3时,模型取得最好的效果。

图3 损失函数参数分析Fig.3 Parameter analysis of loss function
3.8 收敛性分析
图4展示了本文提出的模型在训练过程中,最终的损失函数值(loss)随迭代次数(epoch)变化的情况。网络经过约20次迭代训练后,逐渐收敛到相对平稳的趋势。由此可以验证本文提出的模型的有效性以及损失函数计算的可行性。

图4 损失函数Fig.4 Loss function
3.9 案例分析
对于模型分类错误的新闻,找出具有代表性的例子进行分析,探究分类错误的原因,如图5所示。图5(a)表示真实新闻被预测为虚假新闻的例子,从文章内容可以看出,它的标题使用了问号,且引用网友的话,让读者迫切地想知道文章主角的真实身份到底是什么。很明显,这符合“标题党”的现象。文章正文前半部分对标题提出的人物身份进行描述,但后半部分,却转向描述别的人物,偏离了标题。基于上述两点,本文模型把它识别成了虚假新闻。图5(b)表示虚假新闻被预测为真实新闻的例子,文章标题表明已找到“马航MH370”失联飞机,正文部分也举例证明标题的说法,很难区分真假,所以本文模型将其预测为真实新闻。

图5 识别错误的新闻例子Fig.5 Examples of wrong results
4 结束语
文本所提出的基于双分支网络联合训练的虚假新闻检测方法,通过采用双分支网络结构来挖掘新闻标题和正文潜在的语义特征,同时,度量标题和正文之间的语义关联性,实现虚假新闻的早期检测。本文模型取得了较好的性能,准确率、F1值分别高达0.988、0.941。实验结果表明,基于双分支网络进行联合训练的方法具有可行性和有效性。目前本文仅使用新闻的文本类型(单模态)作为模型的输入,未来的工作将集中在增加模型的输入数据类型,采用更多的社交媒体信息,如图片、视频等作为模型的输入,实现多模态虚假新闻检测。
