基于区块链的农产品质量安全可信溯源系统研究
2022-08-05刘双印雷墨鹥兮徐龙琴李景彬孙传恒杨信廷
刘双印 雷墨鹥兮 徐龙琴 李景彬 孙传恒 杨信廷
(1.仲恺农业工程学院智慧农业创新研究院,广州 510225;2.广东省高校智慧农业工程技术研究中心,广州 510225;3.石河子大学机械电气工程学院,石河子 832003;4.国家农业信息化工程技术研究中心,北京 100097)
0 引言
近年来,农产品质量安全问题频发,各国政府高度关注,并出台系列法律法规以保障农产品质量安全[1-3]。各国政府、高校科研院所和企业采用条形码、射频识别、二维码、产品电子代码、物联网、云计算等技术等构建系列的农产品质量安全溯源系统[4-8],并在水产品、蔬菜、畜禽肉蛋类、粮油、水果等领域得到广泛应用,取得一些成效[9-10]。但因农产品全产业链具有产业链长、参与主体多、涉及面广、环节复杂、周期长、信息多源异构等特性,再加上传统的溯源系统多采用数据中心化存储,各自管理,尤其是农产品质量高附加值信息被选择性公开,使现有溯源系统存在共享性差、数据易篡改、信息不透明和不对称、数据可信任性差等问题,导致农产品质量安全事件仍多发[11]。因此,为解决上述问题,研究先进的溯源技术及其系统对保障农产品质量安全具有重要的研究价值。
区块链是一种分布式账本技术,具有去中心化、不可篡改、成本低、可追溯、安全可靠等特征[12-15]。一些国内外学者研究将区块链技术应用在农产品质量安全溯源领域,文献[16]提出了一种统一的食品本体论,该理论可提高全球食品可追溯性、质量控制和数据整合,它是一个由联盟驱动的项目,为建立一个全面的、容易获得的全球农场,它准确且一致地描述了常见的食物。文献[17]采用区块链技术构建了粮油食品供应链信息安全管理模型,并通过双模数据存储机制和基于智能合约的供应链信息管理,实现了信息存储与传输安全可信。文献[18]提出了“数据库+区块链”的链上链下追溯信息双存储模型,通过Hyperledger Fabric设计了区块链农产品追溯信息存储模型和查询方法,实现了农产品追溯信息高效存储和快速查询。文献[19]采用基于危害因子的食品风险评估和区块链溯源技术构建了食品质量安全管理系统,实现了大米质量安全管控。文献[20]设计了一个旨在为养鱼户提供安全的存储空间,以保存大量不能被篡改的农业数据平台,实现了使用智能契约来自动完成养鱼的不同过程,减少了错误操作。文献[21]提出了一种利用区块链和智能合约有效地执行商业交易,以实现整个农业的大豆跟踪和可追溯所有信息供应链,该方案以高完整性提高效率和安全性,实现了为用户提供高透明度和可追溯性的供应链生态系统。上述研究采用区块链技术实现质量安全溯源,一定程度上解决了传统溯源系统的问题,但存在数据存储压力大和查询效率低等问题,尤其是随着农产品产业链节点拓展和数据剧增,溯源系统负荷压力将增大。
本文首先对农产品溯源信息双链存储模式和智能合约进行设计,然后采用联盟区块链技术构建从田间到餐桌的农产品全产业链质量安全可信溯源系统,以期为农产品质量安全管控提供技术支撑。
1 农产品可信溯源系统与关键技术
1.1 农产品全产业链
农产品产前、产中和产后等全产业链涉及的活动主体主要有:育种企业、生产资料企业(生产化肥、农药等)、种养殖企业、加工企业、仓储企业、物流企业、分销商、零售商和消费者,其关键控制节点主要有种苗、种植、收获、加工、仓储、冷链物流、质检、销售、消费等环节。各节点的信息主要包括种苗信息(种子编号、种子名称、所属品种、来源)、环境信息(土壤、水质、气象等多参数)、投入品信息(投入品编号、名称、成分含量、投入量和库存量、来源、购买人、使用人)、检验检疫信息(重金属类别及含量、农药类别及残留含量、微生物类别及含量、检测检验方式、农产品品质量等级、检验人、检验单位)、控制信息(温度、光照强度、湿度、投入品配比等技术指标)、资质管理(企业资质、管理制度、执行标准)、人员信息(人员ID、姓名、工种类别、联系方式、所学专业等)、地块等其他信息(地块编号、时间、生产批次、土壤关键指标等)等[22]。由上可知,农产品产业链参与的主体众多,涉及节点多且各节点信息化水平参差不齐,缺乏统一的数据接口、标准规范和业务集成,形成诸多各自管理的“数据孤岛”,严重制约农产品全产业链质量安全有效监管和可信溯源[23-24]。
1.2 农产品可信溯源系统关键技术
1.2.1农产品可信溯源区块模型结构
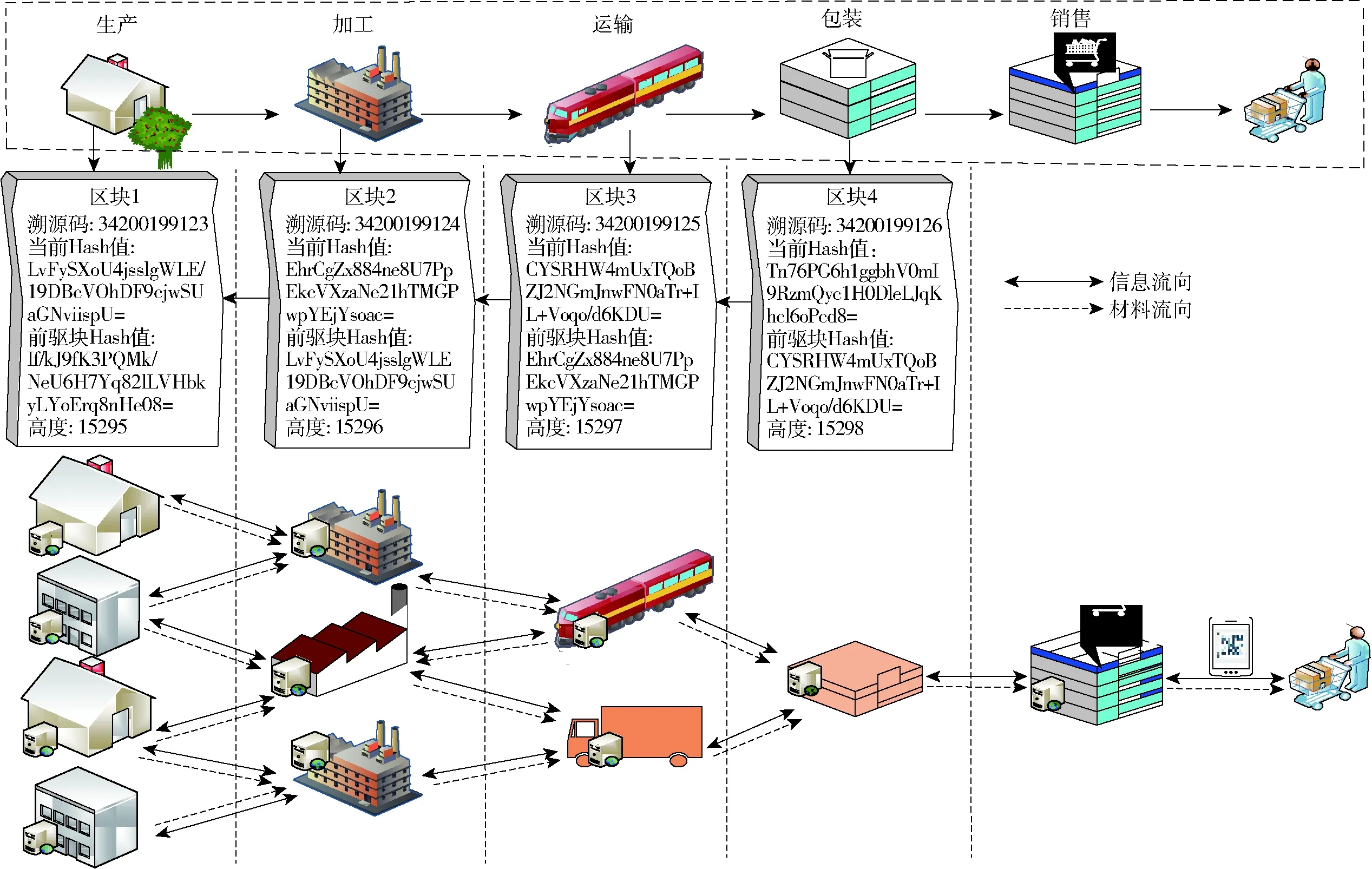
区块是区块链存储交易信息的链式数据结构,由区块头和区块体两部分组成,通过区块头中父区块头Hash值按时序排列将相邻区块首尾连接组成区块链[25-26],其区块结构如图1所示。采用哈希算法对区块体存储的农产品产业链各参与主体的交易关键数据加密成不可逆转的Hash值[27],并作为Merkle树叶子节点,将两两叶子逐层递归哈希计算,生成区块头的Merkle树根节点[28]。区块通过Merkle树特性、时间戳、版本号、区块复杂度、数字签名等措施[29-30],确保农产品溯源信息难以篡改[31],若某节点篡改溯源关键数据,通过区块Hash值比对,可快速追踪该节点,从而保障了农产品溯源系统数据不可伪造、安全可信[32-34]。

图1 区块链式结构图Fig.1 Structure diagram of blockchain
1.2.2“On-Chain+Off-Chain”双模式存储策略
农产品全产业链具有参与主体节点多、产业链长、涉及范围广、数据量大且多源异构等特征[35],在农产品溯源过程中,随着节点增加和数据量增大,若每次都把各节点所有数据全部上传到区块链网络中,不仅上传速度慢还易造成网络阻塞,导致区块链网络中各节点数据存储压力大,查询效率低,数据安全隐患大,还对数据存储系统的设备性能和投入成本都提出较高要求,影响了基于区块链的溯源系统的实施[36-37]。链上存储的主要压力如表1所示。
为此,本文提出了“On-Chain+Off-Chain”农产品质量安全溯源信息协同管理存储策略,其基本思想为:首先对农产品产业链各节点产出的数据进行标准化和规范化;其次采用智能合约对各节点规范化后的详细数据进行验证,把通过验证的大部分农产品产业链数据和区块链位置信息存储在本地或云服务器上的关系型和非关系型数据库中;然后将农产品溯源关键信息使用MD5对局部数据(图像、视频等)和持有人签名一起计算上链,并在链下建立索引,在链上仅进行Key-Value的精准读写。同时为了保证智能合约的隐私性,在必要的情况下智能合约也可以采用链下存储,使用计算节点进行合约的计算记录,共识节点记录合约的状态记录;最后,对于链下的溯源数据的存储要尽可能地详尽,链上经哈希算法计算过的数据要尽可能地精简,上链的数据一定是需要经过共识的,因此该“On-Chain+Off-Chain”协同管理存储策略能很灵活地应对网络拥塞、传输时延等的影响。对于链上数据的快速查询达到了效率、成本以及隐私安全的平衡。设计的农产品质量安全溯源信息协同管理存储模型如图2所示。

表1 链上存储数据开销与效率Tab.1 Analysis of cost and efficiency within storing data on chain

图2 农产品质量安全区块溯源信息协同管理存储模型Fig.2 Cooperative management and storage model of block traceability information for agricultural product quality and safety
链下存储的数据为当前区块高度、当前Hash值、溯源码,溯源码则包含了农产品从出产到销售整个流程的信息,也称为二维码溯源,如产品介绍、溯源信息、食品安全、企业信息以及信息防伪等各项数据的Hash值。当前Hash值是集当前的版本号(Version)、前区块Hash值(Previews Hash)、时间戳(Timestamp)、随机数(Nonce)以及默克尔树(Merkle Tree)所包含所有事务的Hash值(Merkle Hash)等各项信息经MD5哈希算法处理之后得到的结果。链下存储着由链上数据共同参与哈希计算产生的Hash值,链上分布式账本记录着所有的原始数据,块与块相连接,每一块的当前Hash值都有前一区块的Hash值参与计算完成,默克尔树的根Hash值无法篡改,得到的链下数据的上链情况如表2所示。

表2 上链数据Tab.2 On-chain data
1.2.3农产品产业链共识机制
共识算法是区块链去中心化的核心要素,影响区块链系统的执行效率[38-39]。公有链共识算法主要依靠计算机算力完成共识机制,存在计算资源浪费问题[40]。私有链共识机制主要应用于企业内部,常采用传统分布式一致性算法完成共识操作,不适于多主体参与的农产品质量安全溯源领域[41-42]。而联盟链网络由通过授权的联盟成员共同维护,常采用Kafka共识模式[43]或者实用拜占庭容错算法[44](Practical Byzantine fault tolerance,PBFT)。
Fabric区块链的共识过程包括3个阶段:背书、排序和校验,背书(Endorsement)阶段是背书节点对客户端发来的事务进行合法性校验,背书节点模拟并签署提案书,对结果作出批准或拒绝响应,根据设定的背书逻辑判断是否支持该交易,如果背书逻辑决定支持交易,会把交易签名后发回给客户端。背书节点和提交节点之间有重叠,背书节点作为一种特殊的提交节点,它们必须持有智能合约,每个背书节点通过在其模拟环境中调用智能合同,用来接收并执行交易建议,这样的模拟交易结果不会更新到分类账中,而是由背书节点将模拟结果捕获到一组特定的读写数据集(ReadWrite set,RW set)中。读取数据以捕获当前状态的最新读写集(RW set),保存模拟事务写入数据时将写入世界状态,背书节点在这些RW集上提供签名,然后将其返回给客户端应用程序。排序(Ordering)阶段是排序节点接受背书节点返回的所有交易并对这些交易进行排序的过程,排序服务是共识机制中重要的一环,所有交易通过Kafka机制排序服务进行排序才可以达成全网共识,客户端应用程序将对已签名的模拟事务结果进行打包,然后将该事务连同RW集一起提交给排序节点。当网络对提交的事务达成共识时,此事务将被打包成一个块,并将其交付给所有提交节点进行验证。验证(Validation)阶段是由排序节点与提交节点共同完成的,每个提交节点都会验证交易程序通过检查这些RW集是否与当前世界状态相匹配,交易的RW集是否符合多版本并发控制[45](Multiversion concurrency control,MVCC)的校验等。一旦交易验证,即可将其写入分类账中,并根据RW集设置更新世界状态写入数据。最后,这些提交节点生成异步消息以通知客户端所提交的事务是否已成功执行。整个事务的合约过程都由共识机制强制参与执行,每当事件发生时,客户端应用程序就可以订阅每个提交节点的事件通知。Fabric利用Kafka对交易信息进行排序处理,为实时数据提供统一的、高吞吐量、低延时的处理能力,并且在集群内部支持节点故障容错;PBFT解决拜占庭将军问题,但需要O(N2)时间复杂度(N表示同一消息共识次数)的网络通信才能完成n个网络节点共识,导致网络带宽压力大,影响算法共识效率。图3为基于联盟链共识机制设计的农产品溯源共识机制原理。
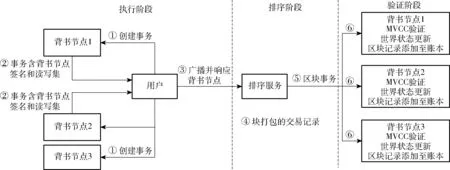
图3 农产品溯源共识机制Fig.3 Consensus mechanism of agricultural product traceability
1.2.4农产品产业链智能合约机制
智能合约是一种具有确定性、自校验、自治化、去中心化、自动执行、不可篡改等特点,能执行合同条款的可计算的计算机协议[46-48]。智能合约根据事先预置好和可自动执行的合约条款及业务逻辑机制,就可以为区块链网络中各节点活动主体提供数据交互、防篡改的交易记录、价值转移、关键数据上链存储等功能,也是在区块链网络上实施更加灵活、更细粒度的访问控制机制[49-51]。本系统以Hyperledger Fabric[52]为区块链开发平台,结合国家食品安全法规、行业标准,领域专家经验等,制定农产品质量安全溯源智能合约规则集和合约触发条件,通过编写的智能合约,实时验证拟上链的合约数据、监控区块链网络上的交易信息,实现对农产品全产业链各环节产品精准管控,为农产品生产企业优化生产工艺、保障产品质量和提高企业品牌提供技术支撑;同时也为广大消费者和农产品质量安全检测部门提供可信溯源信息。系统智能合约使用标准编程语言编写,但不能直接访问分类帐状态,而且它们在容器环境中运行以进行隔离。系统中智能合约主要体现在3方面:①对上链数据的验证及维护,智能合约以编程方式访问分类帐的两个不同的部分,一个不可更改地记录所有交易历史的区块链,以及一个持有当前这些状态值的世界状态。所以上链的数据经过验证之后不能更改,账本状态会记录所有的写入操作。智能合约打包并部署到区块链网络中,可以在同一包内定义多个智能合约,一旦合约部署完成,包内的所有智能合约都可提供给应用程序。因为智能合约是允许多步骤流程自动化的脚本,其操控的分散应用程序可完全按照代码条件触发,所以不会有任何审查、欺骗或宕机的风险。②对销售商品的赔付方面,在农产品从生产到销售的过程中需要经历各个阶段的合作加工处理过程,一旦其中某个环节出现问题,智能合约会根据事先约定的情况对出现的损失进行赔付,而不需要人为地计算损失与惩罚,这样既节省了成本也提高了效率。③对该“On-Chain+Off-Chain”协同管理存储策略的保护措施,外部应用程序会与智能合约在区块链网络上进行交互执行操作,由于区块链包含不可变记录,以反映这些操作产生的更改,所以“On-Chain+Off-Chain”协同管理存储策略可以支持最新的缓存信息,且对于数据的检索更加快速便捷,因此对于没有授权的应用程序开发人员则无法选择或修改验证阶段进行评估认可策略,在最终系统审计过程中,背书策略作为系统中事务验证的静态库执行操作,只能通过链码实行参数化,之后将分类帐更新结果作为响应返回到外部应用程序,因此可以保证用户和数据的安全。其农产品溯源智能合约如图4所示。

图4 农产品溯源智能合约Fig.4 Smart contract of agricultural product traceability
列出系统两个合约执行的算法逻辑(Query与Compare),即用户扫描溯源码得到溯源码内的信息,这些数据信息都来自以上链的信息。其中块与块相连接,每一块上存有大量事务,每个事务都有唯一标示ID,以及有上链的时间戳共同参与哈希计算,当链上返回的原始数据经过哈希计算后得到的字符串与本地数据库存储的字符串相匹配,合约自动执行对比逻辑进行数据调取,当tx.ID1==tx.ID2成立时,查询成功,否则合约调用失败,云端数据库返回源数据不成功,查询失败。两个合约如下:
合约1:Query
1.Contract Simplequery(off_infm)
2.var buffer bytes.Buffer
3.while(PreviousHash!=NULL){
4. hash := sha256.Sum256(buffer.Bytes(off_infm))
5. if(hash in PreviousHash.select) :
6. tx.ID1 = hash[:]∥从链下数据计算得到的Hash值中取ID
7.PreviousHash=PreviousHash.next}
8.returntx.ID1
合约2:Compare
1.Contract Simplecompare(tx.ID,on_infm)
2.while(PreviousHash!=NULL){
3. if(on_infm==hash):
4. tx.ID2 = on_infm[:]
5. if(tx.ID1==tx.ID2)
6. fmt.Println(off_infm)
7.return true}∥查询成功!
2 农产品质量安全可信溯源系统设计与实现
2.1 可信溯源系统功能模块设计
以农产品全产业链分析和企业溯源需求为基础,对农产品溯源各环节数据进行梳理分析、归纳合并,并以“高内聚、低耦合”的现代软件工程思想进行系统功能划分。该系统由我的农场、基地管理、生产操作、作物追溯、系统设置、大数据分析共6大功能模块组成,每个功能模块又由多个子功能构成,实现农产品从农田到餐桌可信溯源。其系统功能模块如图5所示。
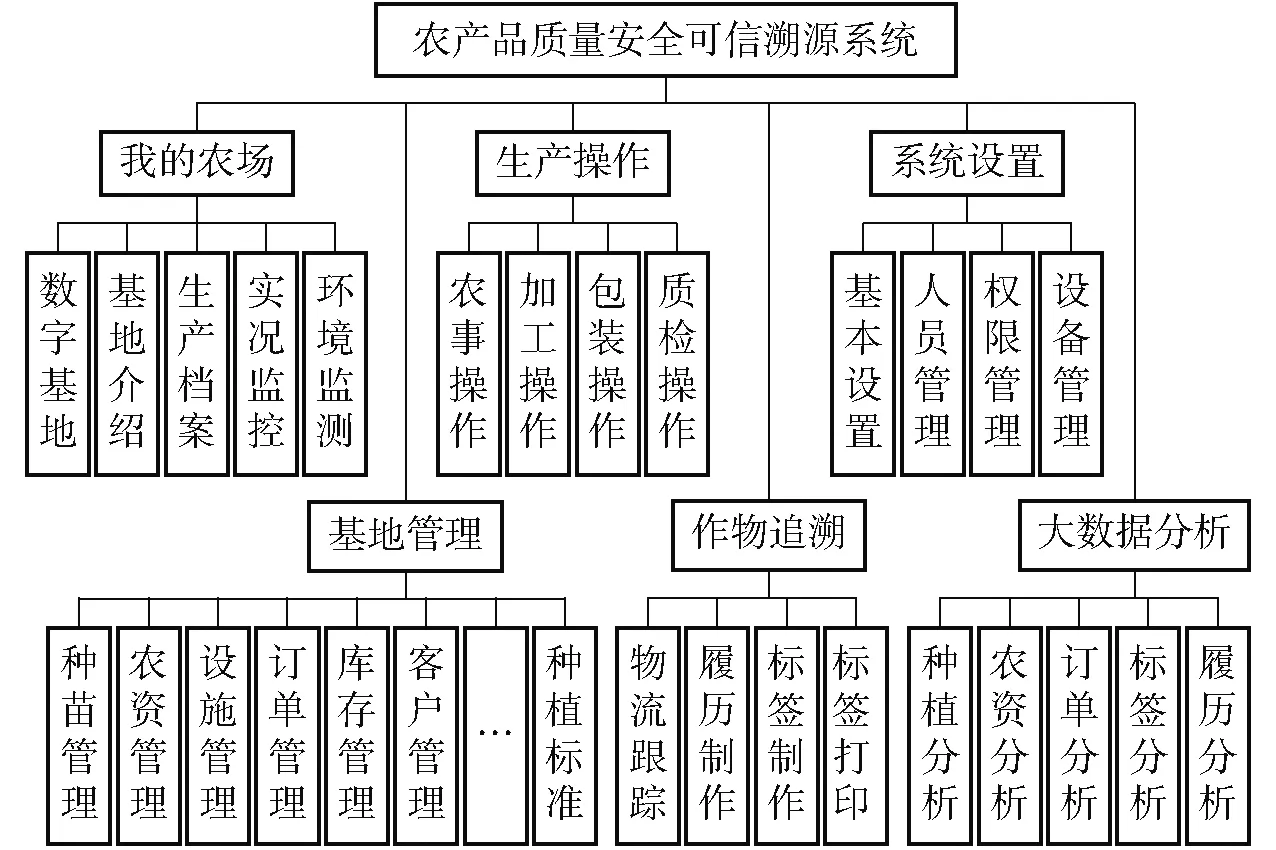
图5 系统功能模块Fig.5 Diagram of system function module
2.2 可信溯源系统架构设计
结合农产品全产业链产前、产中和产后企业的实际生产过程和农产品可信溯源的需求,设计的系统整体架构如图6所示。该系统架构主要由数据采集层、数据存储层、服务管理层、接口层、业务逻辑层、用户层等6层组成。
数据采集层主要采用物联网系统、多参数智能传感器、分析仪等设备在线或离线采集农产品产业链各节点的数据,并通过无线传感器网络、4G/5G、LoRa、WIFI等网络把数据传输到数据存储层。
数据存储层采用链上和链下双存储模式存放所有数据,首先对数据进行清洗、转化、融合等预处理,然后把通过智能合约和共识机制验证的溯源关键数据、分布式账本、时间戳、数字签名、区块头Hash值等信息上链存储到联盟区块链网络中,该链上数据可通过不同身份验证和访问权限查看不同数据;将通过智能合约的各节点大量的数据和区块链网络映射关系都存储到链下关系型和非关系型数据库中,这种链上和链下双存储模式可有效提高存储效率及保障数据安全可靠。
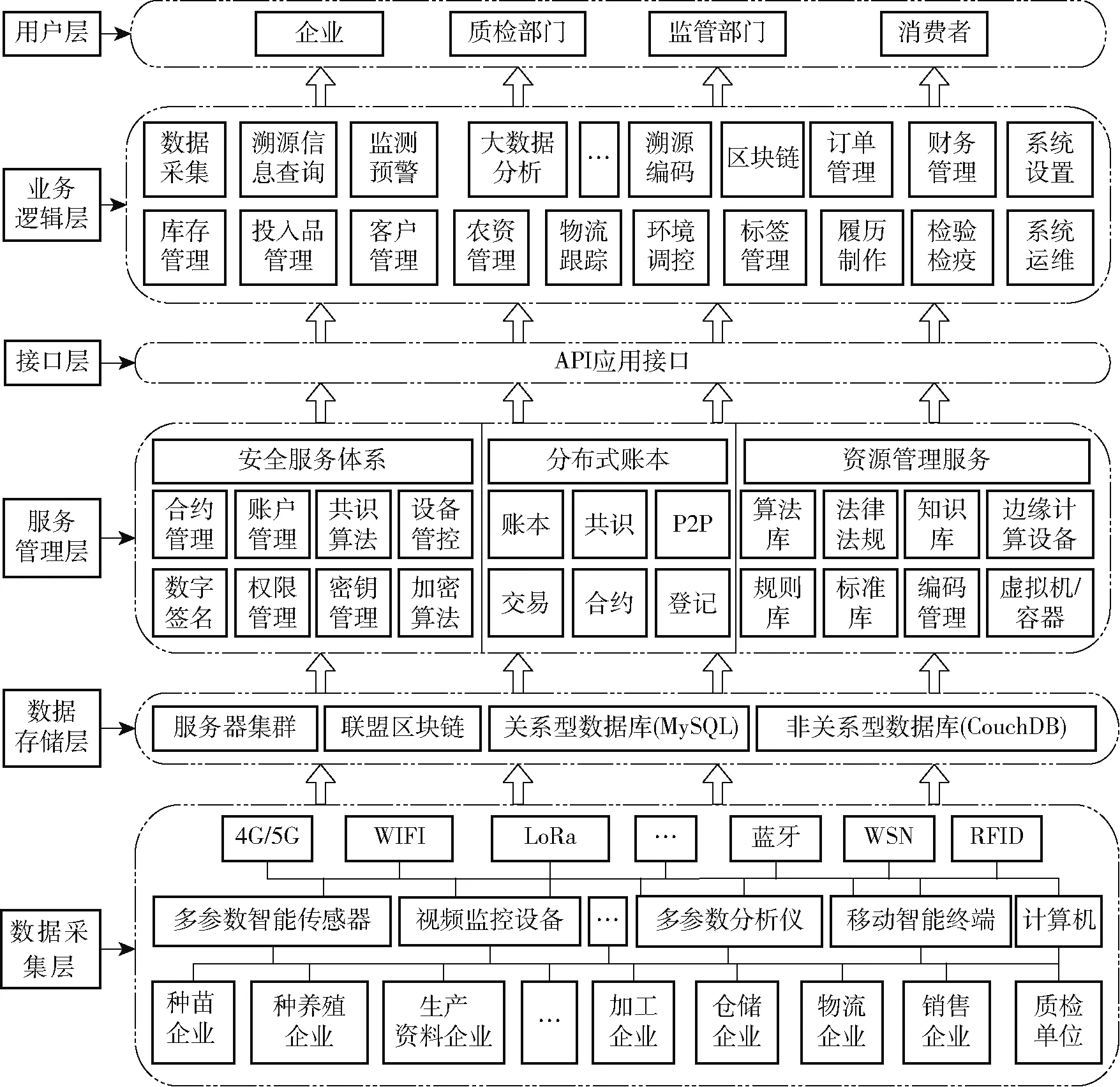
图6 农产品质量安全可信溯源系统架构Fig.6 Architecture diagram of reliable traceability system for agricultural product quality safety
服务管理层主要包括安全服务体系、分布式账本、资源管理服务3部分,其中安全服务体系负责管理整个系统的账号、密钥、认证、权限、签名、共识算法、合约等信息;分布式账本负责管理所有交易记录、数据共识、智能合约,登记和交换实体或虚拟的资产等;资源管理服务负责系统算法库、农产品质量安全法律法规库、农产品行业标准库、规则库、专家知识库、编码规则与管理、边缘计算设备、虚拟机和容器等通过API 应用接口,支持业务逻辑层的功能应用。
业务逻辑层主要负责整个溯源系统的数据采集、溯源信息查询、大数据统计分析、区块链管理、溯源编码等业务功能,为企业、质检部门、监管部门和消费者提供真实可靠的溯源信息和决策支持。
2.3 农产品可信溯源信息查询执行过程
在实现了上述溯源系统设计的基础上,需要将溯源信息清晰地呈现给企业、质检部门、监管部门以及消费者,因此该系统还需能够快速检索到链上所存储的溯源信息。
存储溯源信息时,客户端SDK将农产品生产、加工、运输、包装和销售等信息通过invoke函数发送到背书节点(Endorser Peer),背书节点将与链码(Chain Code)实例通信,并为其提供模拟的世界状态(World State)读写集,即链码会执行完溯源信息查询的逻辑任务,但并不会在执行参数时将模拟得到的读写集写入数据库,然后由排序节点对溯源信息进行排序打包入块,最终由提交节点进行验证并提交至账本更新状态数据集;查询溯源信息时,以ID标示码为 key 值查询账本记录,通过检索key值来依次遍历区块,索引的value值为溯源信息的Hash值,有时会多次检索key值,键-值引入键值的版本号加以标识,版本由块序列号和事务(存储条目)的序列号组成,因此该版本独特且单调递增,每次对同一个key值进行写入操作时其版本号(version)都会递增,遍历过程中以version的最大值为标准查询。同时,溯源信息与对应的区块号存储在本地数据库,即在查询时将链上、链下两次得到的Hash值进行对比以验证溯源数据是否被篡改。对应的合约执行解析区块信息如下
合约3:Parsing
1.contract parsing()
2.var (
3. block_height int
4. recorded_block_height int
5. block_seq int
6. )∥定义变量
7.Set max_block_height := retrieve block_height from the ledger
8.Set current_block_height := recorded_block_height
9.If current_block_height 10.For block_seq in (current_block_height,max_block_height): 11. Set recorded_block_height := block_seq∥解析区块序号得到key-value 12.parsing blocks 基于区块链的农产品质量安全可信溯源系统采用多层的浏览器/服务器结构,由客户端、服务器和数据库构成。其软件开发环境为区块链平台Hyperledger Fabric,操作系统Ubuntu 16.04,应用容器引擎Docker 18.09、开发语言Go、Java、JavaScript、HTML和CSS,开发框架Node.js和Bootstrap,数据库服务器CouchDB、LevelDB、MySQL,其中CouchDB和LevelDB为链上分布式存储的数据库,MySQL为链下存储数据库等。硬件环境:内存8 GB、硬盘容量500 GB、带宽10 Mb/s。Fabric联盟区块链使用Kubernetes集群服务,由1个命令行接口(CLI)节点、3个控制器节点、1个负载平衡器、1个网络文件系统(NFS)节点和多个工作节点组成,每个节点都在Ubuntu 16.04虚拟机上运行,Kubernetes集群的控制器节点负责调度,对等节点和排序节点由Kubernetes调度程序以循环的方式部署在工作节点上,以实现分布式存储、防篡改和农产品质量安全可信溯源的目的。 在基于Hyperledger Fabric开发平台中,账本(Ledger)作为系统文件记录着数据的更新,由状态数据库(StateDB)维护着真实世界状态(World State),其中StateDB就包括LevelDB和 CouchDB。其中区块链网络主要由许多对等点组成,其中还包含了向分类帐写入链上的多个智能合约。区块链是一个不断增长的记录列表,称为块。实际上,块包含先前块的Hash值、时间戳、事务数据和一些其他信息。除非打破散列Hash值,否则不可能篡改分类帐数据,因为分类帐上的所有事务都是按顺序并加密链接在一起的。区块链网络中的数据存储可以是本地数据库或云存储数据库,例如关于茶场的信息(茶场情况、用户简介、设备概况、来自传感器的环境数据以及执行器的控制参数等)。最终用户可以通过各种终端设备读取区块链网络或将数据写入区块链网络。 该系统从用户使用的角度分为管理端、客户端和移动端3个子系统,其中管理端是对系统进行管理和运维,管理端控制了客户端和移动端的数据连接,移动端是消费者查询农产品溯源信息子系统,提供了以应用程序接口控制用户界面的形式来显示数据,使用手机扫码的形式来反馈区块信息供用户访问。客户端是农产品产业链多个企业节点进行生产管理、农事作业、加工、运输、包装、销售等使用的子系统,包含产生结果的所有业务逻辑,其中产生的数据使用类似于JSON的形式编码,模块之间以JSON数据形式进行数据交互,它是一种简易、存取便捷、可读性强的编码形式,更重要的是它的树形结构天然具有可扩展性,对后期各个阶段需要添加更多的数据信息到链中可以扩展,对现有的数据结构仍具有兼容性。客户端使用面向服务的架构提供的接口,以实现与系统服务器的连接,消费者可以从系统获取溯源信息,例如生产数据或成品数据,各个阶段的参与者,如茶庄、加工厂、经销商等都能通过链上的信息对农产品数据进行确认核实。将开发的农产品质量安全可信溯源系统应用于广东清远英德红茶溯源中,其红茶追溯系统客户端、管理端和移动端界面如图7~9所示。 图7 红茶追溯系统客户端界面Fig.7 Client interface of black tea traceability system 图8 红茶追溯系统管理端界面Fig.8 Management interface of black tea traceability system 图9 红茶追溯系统移动端界面Fig.9 Mobile terminal interface of black tea 农产品产业链可信溯源流程如图10所示,虚线框内代表红茶溯源安全供应链的材料流程,茶叶从茶园生产出来,经过工厂加工成茶叶或茶叶制品,然后运输到各个厂商进行处理,包装上会印上各自供应商的商标、茶叶的生产日期以及产地,最后摆放在货架上等待售出。这是一个复杂的溯源网络,在每个阶段都有多个合作伙伴,各阶段都有各自的供应商负责进行数据的上链和交互,每个合作伙伴都从多渠道采购原材料提供给上游的供应商,并且上下游的数据信息都是相通的,上链的数据存储进账本就不可以再更改。最终消费者扫描得到的溯源信息是上传到区块内的数据最终选择性的输出结果,其中包括茶叶的溯源码、当前区块的高度以及区块的哈希地址,消费者对买到的农产品通过扫描溯源码进行查询其来源,确保农产品质量溯源数据真实可靠。 (1)设计的农产品溯源区块结构,确保农产品溯源数据不可篡改或伪造;“On-Chain+Off-Chain”区块链溯源信息链上链下双链协同管理存储策略,有效减少区块链网络中各节点数据存储压力大、查询效率低等问题;采用 Kafka共识机制对多参与主体上链的事务进行有效排序,提供数据高吞吐量和低延时的处理能力;同时结合国家食品安全法规编写智能合约,使农产品产业链的数据得以标准和规范,以实时验证拟上链的合约数据、监控区块链网络上的交易信息,触发验证机制对合法信息进行存储,确保农产品数据的可靠性和溯源平台的公信力。 (2)基于Hyperledger Fabric区块链平台,对农产品质量安全可信溯源系统进行整体的设计,系统分为数据采集层、数据存储层、服务管理层、接口层、业务逻辑层、用户层6层,体现了由物理空间到网络空间、链下数据到链上数据、分散到统一、信息壁垒到透明可靠的全方位设计,解决了传统溯源系统中心化服务效率低、信息不透明、安全风险大等问题。 图10 农产品产业链可信溯源流程图Fig.10 Reliable traceability process of agricultural products industry chain (3)不仅实现了系统数据分散存储、安全规范上链、真实透明存储,消费者还能快捷地查询到所购买农产品的溯源信息,实现了从农田到餐桌全过程生产链、农资供给链、销售链、监督链等多链有机融合,建立了农产品溯源信息不可篡改、全程留痕、公开透明、集体维护的农产品质量安全可信溯源体系,实现了“农企-监管部门-消费者”之间良好的信任氛围,可为其他产品溯源提供借鉴和参考。2.4 系统实现



3 结论