基于ST-LSTM的植物生长发育预测模型
2022-08-05王春颖泮玮婷
王春颖 泮玮婷 李 祥 刘 平
(1.山东农业大学机械与电子工程学院,泰安 271018;2.山东省农业装备智能化工程实验室,泰安 271018;3.山东农业大学生命科学学院,泰安 271018;4.作物生物学国家重点实验室,泰安 271018)
0 引言
表型是对复杂植物生长、发育、抗性、结构、生理、生态以及个体数量参数等性状的定量评估[1-3]。自然植物的生长缓慢,提早预知植物生长发育并解析植物表型,将减少植物生长、成像和测量所需的时间,加快生物学家的实验周期,进而加速新品种的培育[4-5]。植物生长发育预测有望解决育种行业研发周期长、效率低、成本高、决策难等问题。
目前,国内外相关学者已开展了一些植物表型预测研究,如基于多相时植被指数估算作物产量[6-9],但这些研究仅能估算单一表型的最终结果。时序预测模型利用时序特征预测数据变化为表型预测和模拟提供可能[10-14],已有研究建立了时序预测模型预测环境因素对植物生长发育的影响[15-16]。YUE等[17]建立了基于长短时记忆网络(Long short-term memory,LSTM)和卷积长短时记忆网络(Convolutional LSTM,ConvLSTM)的预测模型,可预测未来一年的日照时数、累积降水量和平均温度,同时开发了数据驱动模型预测每个生长阶段。
但这些研究仅能预测单一表型的动态变化,不能很好地可视化植物生长发育。而植物生长发育的性状信息可通过分析植物图像获得,一些研究成果已成功探索了植物生长发育的空间和时间特征信息的提取与应用[18-20]。2019年,SAKURAI等[21]首次提出利用历史植物图像进行植物生长发育预测的研究,使用ConvLSTM和编码器-解码器模型来预测植物叶片的生长。YASRAB等[5]使用GAN模型来预测植物叶片和根系的生长变化,但该模型基于植物掩码预测生长发育,忽略了植物的纹理和颜色信息。

因此,本文利用植物生长发育的空间依赖性、时间依赖性,提出一种基于ST-LSTM的植物生长发育模型,通过植物历史生长图像序列,预测植物形态结构随时间而发生的几何变化,实现植物生长发育预测与可视化。
1 植物生长发育预测数据集
拟南芥是生物学模式植物,分子遗传背景清晰,生长周期短、生长条件可控,很容易从顶视图观察拟南芥的生长模式,时序采集图像可以保持一致性。因此,本文采用拟南芥植物图像[18]构建植物生长发育预测数据集。该拟南芥图像数据包括理想生长条件的4种基因型(Sf-2、Cvi、Landsberg和Columbia),共96个连续顶部图像生长发育序列,每个生长发育图像序列包含22幅图,图像采集时间间隔为24 h。
图像噪声是植物生长发育预测的一个关键问题,需要对植物图像进行预处理,去除背景噪声的干扰。通过微调Mask R-CNN模型实现识别、提取植物掩模,进而通过形态学运算去除图像背景。去除背景后的拟南芥连续生长发育图如图1所示。
将拟南芥图像分辨率调整为128像素×128像素,并通过旋转图像90°、180°和270°来增强数据,按照不同的植株编号划分训练集和测试集。每个品种中编号1~12的植株生长发育图像为训练集,编号13~16的植株生长发育图像为测试集。训练集和测试集中每个序列包含10幅连续生长发育图像,其中前5幅作为输入,后5幅作为输出。最终形成植物生长发育预测数据集,包含3 340组训练数据和1 105组测试数据。

图1 背景去除后的拟南芥连续生长发育图像Fig.1 Successive images of Arabidopsis thaliana without background
2 基于ST-LSTM的植物生长发育预测模型
2.1 植物生长预测问题定义
植物生长发育随时间变化具有明显的时间相关性和空间相关性(图2),即在植物图像序列中的任意像素位置A的像素,不仅与历史时刻该位置A′的像素时间相关;又因为自然图像具有极高的结构性,位置A的像素也与同一时刻的图像内临近像素位置B的像素空间相关。植物生长发育预测的目的是利用观测到的图像序列来预测植物生长发育。
模式层计算输入特征向量与训练中各个模式的匹配关系,模式层神经元个数等于各个类别训练样本数之和,该层每个模式单元的输出为
因此,根据历史j个植物图像序列It-j+1:t,预测未来k个生长序列图像t+1:t+k,定义植物生长发育预测公式为
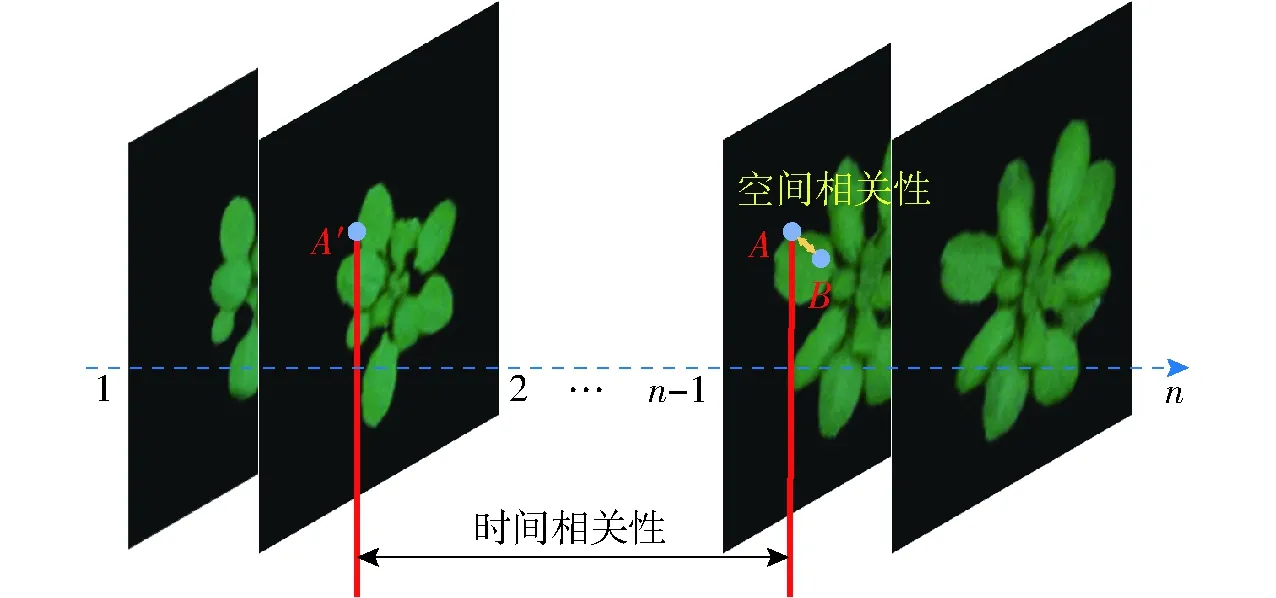
图2 植物生长发育数据时空相关性示意图Fig.2 Spatio-temporal correlation diagram of plant growth data
(1)
式中It——每个植株在t时刻的RGB图像,It∈R3×m×n,m×n为RGB图像尺寸
p——贝叶斯概率
2.2 植物生长发育预测模型结构
针对紧耦合的植物生长发育时空相关性,以植物生长发育时序图像为研究对象,提出基于ST-LSTM的植物生长发育预测模型,如图3所示。植物生长发育预测模型通过提取植物生长发育的空间和时间特征,近似估计植物生长发育。
植物生长发育预测模型由时序图像输入层、卷积层、ST-LSTM网络隐含层和输出层组成。首先将历史j个时刻的植物图像序列It-j+1:t输入到卷积层中,1×1卷积运算,不破坏图像的空间结构,跨通道交互和信息整合,提升网络的表达能力。然后,将空间结构特征输入ST-LSTM网络隐含层,提取层次化的时空特征。最后,输入到1×1卷积层,连接ST-LSTM网络隐含层的所有状态,预测生长发育图像序列t+1:t+k。
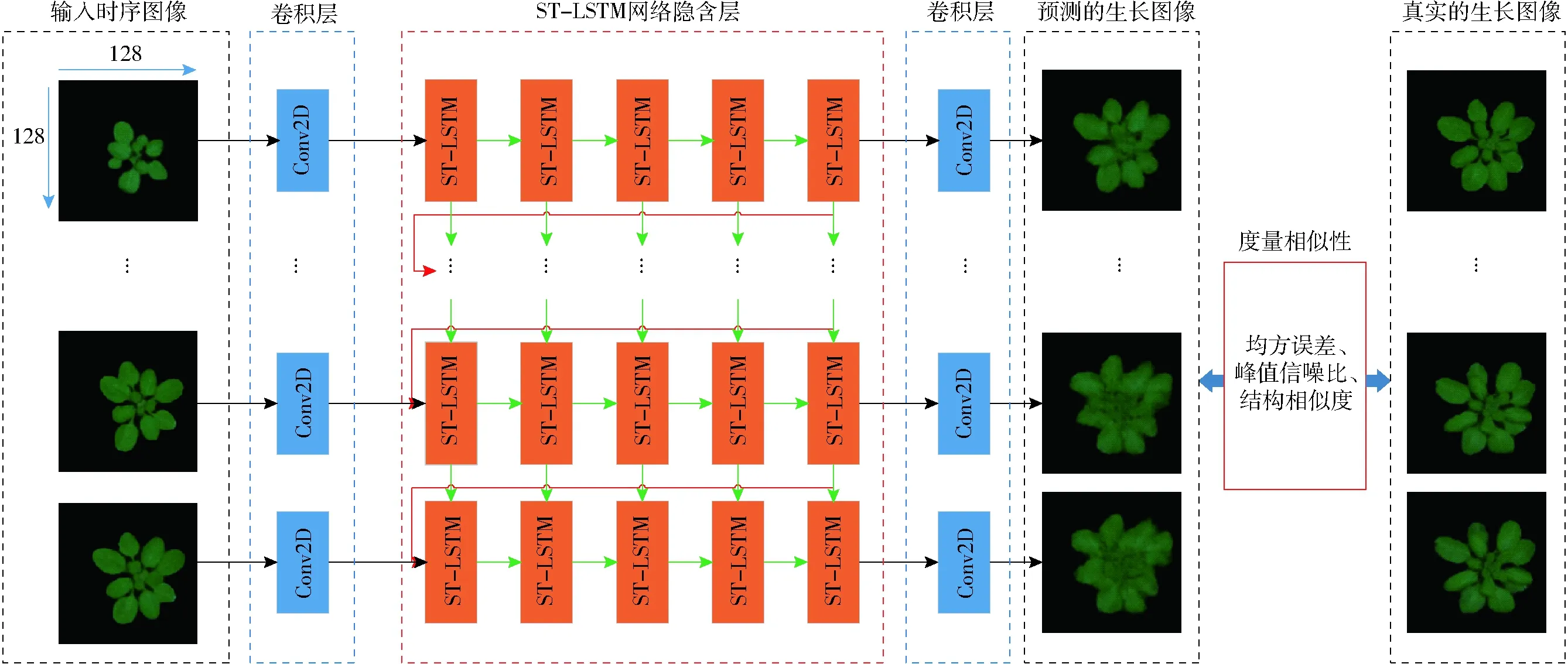
图3 植物生长发育预测模型结构图Fig.3 Structural diagram of prediction model for plant growth and development
2.3 ST-LSTM网络隐含层结构
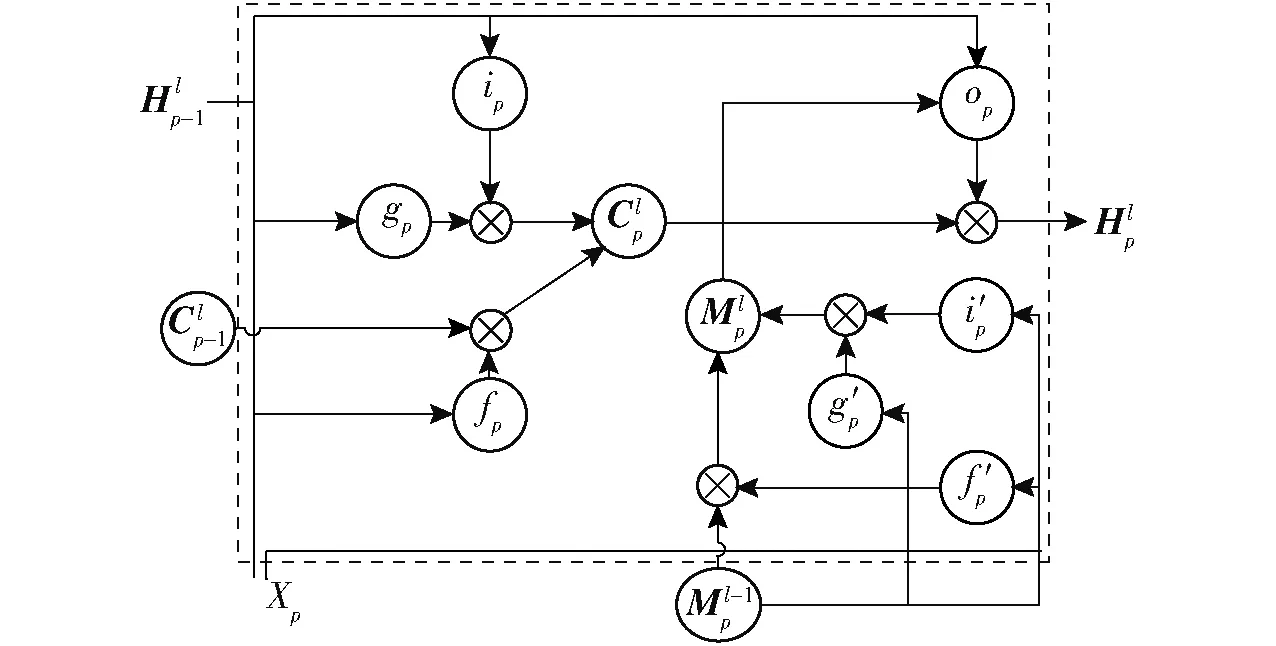
图4 ST-LSTM单元内部结构图Fig.4 Structure diagram of ST-LSTM cell
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
式中ip、gp、fp——输入门、输入调制门、遗忘门
i′p、g′p、f′p——另一组输入门、输入调制门、遗忘门
Xp——输入状态

ω、ω′——权重矩阵
b、b′——偏差矩阵
σ——Sigmoid激活函数
*——卷积运算符
⊙——哈达玛积
2.4 评估指标
为了评估植物生长发育预测模型,定量评价预测的植物生长发育图像,使用均方误差(Mean square error,MSE)、峰值信噪比(Peak signal to noise ratio,PSNR)和结构相似性(Structural similarity index measure,SSIM)作为评估指标[18,24-25]。MSE评估了实际与预测图像之间的像素差异度;PSNR是峰值信号能量与MSE之比,评估了实际与预测图像之间的像素差异度,PSNR越高,图像和实际图像越接近;SSIM则是一种基于感知的度量方法,衡量结构信息在整幅图像上的差异,其值域为[0,1],SSIM越接近1差异越小,当且仅当两幅图像完全相同时,其值为1。
同时选择拟南芥冠层叶面积、冠幅和叶片数作为植物生长发育预测的评价内容。将拟南芥图像转换为二值图像,冠层叶面积通过统计二值图像的连通域像素和计算,冠幅为连通域的最小外接矩形的长、宽的平均值。冠层叶面积、冠幅和叶片数预测的评价指标包括决定系数R2和均方根误差(RMSE)。
3 植物生长发育预测结果与分析
3.1 模型参数设定
植物生长发育预测模型以最小平方误差作为损失函数,选用Adam优化器进行训练。每次迭代随机选取10个生长序列,设置最大迭代次数为30 000,模型在所有时间节点上都对下一生长发育图像进行预测。选取不同学习率、ST-LSTM隐含层层数、隐含层中ST-LSTM单元数以及ST-LSTM单元的卷积核尺寸进行测试,以获得较优的预测性能。
不同学习率的训练损失值曲线如图5所示,最后1 000次迭代的训练损失值和学习率的关系如图6所示,训练损失值关于学习率呈U形曲线。当学习率为10-6,训练损失值较大,变化率较小,如图5中的蓝色曲线;当学习率过大,梯度下降使训练误差增加而非减小,如图5中的橙黄色曲线。学习率越低,权重更新速度越慢,损失函数变化速度越慢。因此在训练损失值相近的情况下,选择学习率为0.001,训练损失值小,且波动幅度小,不存在离散点。
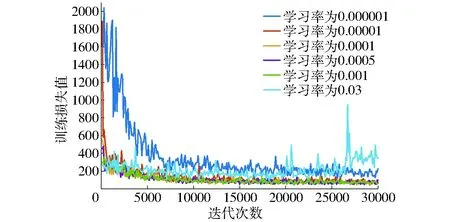
图5 不同学习率的训练损失值曲线Fig.5 Loss value curves of different learning rates

图6 最后1 000次训练损失值变化曲线Fig.6 Loss value curves of last 1 000 iterations
不同ST-LSTM隐含层层数、隐含层中ST-LSTM单元数以及ST-LSTM单元的卷积核尺寸,对模型容量和特征提取有很大的影响。设计ST-LSTM隐含层层数为3、4、5,隐含层单元数为32、64、128,ST-LSTM中的卷积核尺寸为3×3、5×5和7×7进行训练。同时监测训练误差和测试误差对训练结果的影响,通过网格搜索算法确定最优的隐含层数量和隐含层单元数组合为:隐含层层数为5,隐含层单元数为64,ST-LSTM中的卷积核尺寸为3×3。模型预测效果通过计算预测图像序列与生长发育实际图像序列之间的结构相似度(SSIM)来度量,如图7所示。
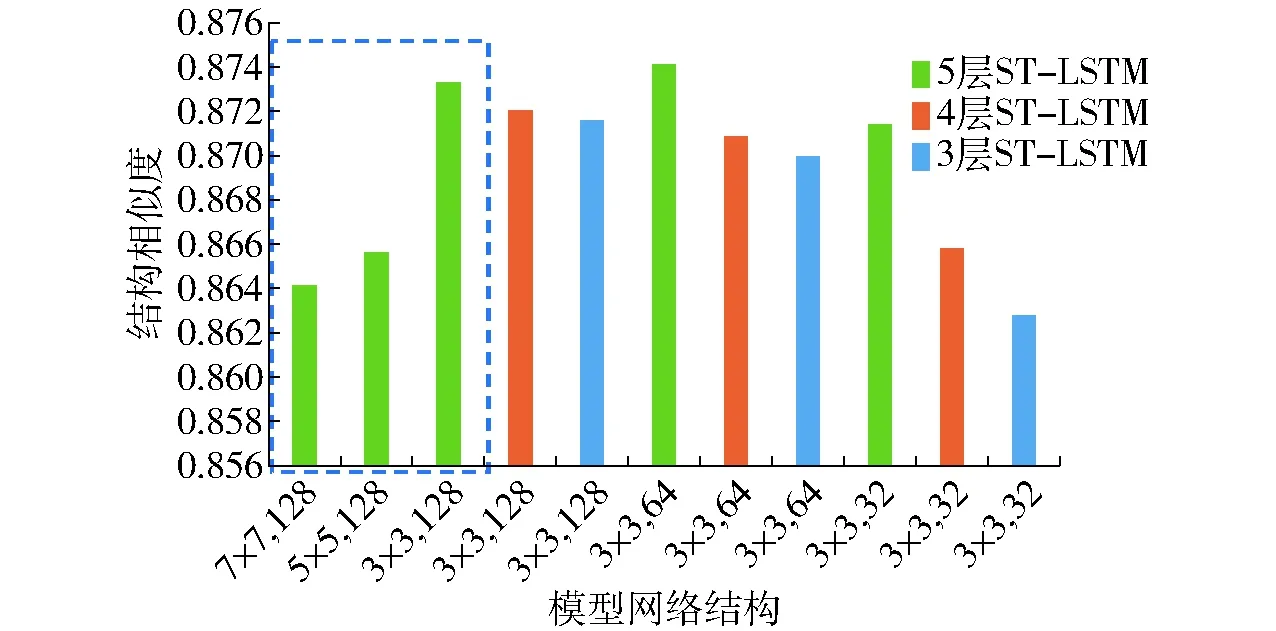
图7 不同模型网络结构的结构相似度对比Fig.7 Comparison of SSIMs for different model structures
图7显示了不同模型网络结构下,t+1时间节点植物生长发育预测图像的结构相似度(SSIM)。ST-LSTM中的卷积核越小,所需要的参数和计算量越小,降低了计算复杂度,卷积核增大,结构相似度明显降低,如图7中的蓝色虚线框。更深的网络比更宽的网络的表达能力强,能够逐层学习特征,增加感受野,生长发育预测结果结构相似度更高。
为了验证所提出的植物生长发育预测模型性能,选取ConvLSTM为对比模型。ConvLSTM网络选用ConvLSTM单元堆叠隐含层,参数设置均与所提出的模型相同。
3.2 植物生长发育预测结果与性能分析
植物生长发育预测结果如图8所示,根据历史的5个生长图像序列,预测t+1到t+5的生长发育图像。使用MSE、PSNR和SSIM作为评估指标,定量评价所提出的生长发育预测模型和ConvLSTM,每个预测时间节点的定量评估结果如图9所示。所有预测时间节点的SSIM均值为0.774 1,MSE均值为27.35,PSNR均值为39.74。首个预测时间节点的SSIM为0.874 1,MSE为17.10,PSNR为30.83,表明预测与生长发育实际图像序列具有较高的相似性。

图8 植物生长发育预测结果Fig.8 Prediction results of plant growth and development
植物生长发育预测模型的MSE、PSNR和SSIM值均优于ConvLSTM模型,意味着所提出的模型提取植物生长发育时空相关性的能力更强。但植物生长发育预测模型和ConvLSTM模型均无法有效拓展预测时效,预测时效越长模糊现象越严重,预测结果相似性越差,PSNR和SSIM值会逐渐下降,MSE值逐渐升高。造成这种现象的原因可能是预测误差积累和植物生长发育的复杂性。
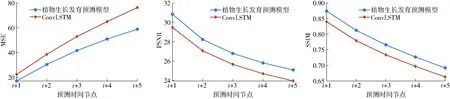
图9 定量评估结果Fig.9 Quantitative results
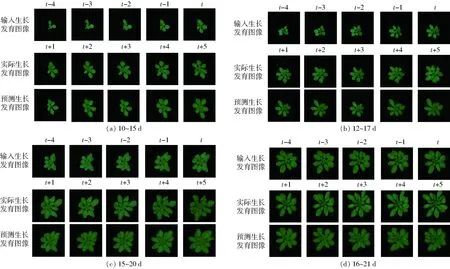
图10 不同生长阶段的生长发育预测结果Fig.10 Prediction results of growth and development at different growth stages

图11 不同生长阶段的冠层叶面积、冠幅和叶片数的预测结果Fig.11 Prediction results of canopy leaf area,crown width and leaf number at different growth stages
对不同生长阶段的植物生长发育序列进行预测,检验模型适应性,包含预测10~15 d的生长发育、12~17 d的生长发育、15~20 d的生长发育和16~21 d的生长发育。植物生长发育预测模型预测结果如图10所示,预测结果相应的表型参数(冠层叶面积、冠幅和叶片数)如图11所示。显然,所提出的植物生长发育预测模型在生长发育中期(10~15 d、12~17 d)比后期(15~20 d和16~21 d)的生长发育预测效果好,原因在于生长发育后期植株形态结构逐渐复杂,预测难度增加。生长发育预测的冠层叶面积和冠幅具有较好的一致性和相似性,t+1、t+2和t+3时刻的预测误差明显小于t+4和t+5,说明所提出的植物生长发育预测模型有效地改善了预测时效问题。但生长发育预测的叶片数预测精度较差,这是预测图像的新生叶与成熟叶片边界不明显造成的;且叶片越密集(图10c),植物生长发育预测模型无法区分内部叶片边界,预测误差越大,因此,预测的叶片数在t+3和t+4时刻出现拐点(图11c)。
植物生长发育预测模型在包含4种基因型数据的测试集上的检验结果如图12所示。所提出模型预测的图像序列与生长发育实际图像序列具有较高的一致性和相似性,冠层叶面积、冠幅和叶片数的预测R2分别为0.961 9、0.908 7和0.915 8;RMSE分别为2 164像素、36.45像素和6.73,普适性较好。显然,t+5时刻相对于t+1时刻,冠层叶面积和冠幅的偏移量都大,同样反映了预测时效性这一问题。从图12中还可以看出,随着冠层叶面积和冠幅的增加,模型预测精度明显下降,再次说明预测精度受植物生长发育的复杂性影响。
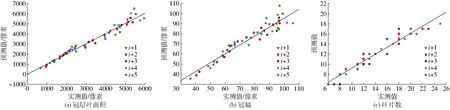
图12 测试集的预测结果Fig.12 Prediction results on test set
4 结束语
基于ST-LSTM提出的植物生长发育预测模型,利用历史植物生长发育图像序列,预测和可视化了植物的生长发育。生长发育预测图像序列与实际图像序列具有较高的一致性和相似性。首个预测时间节点的结构相似度为0.874 1,均方误差为17.10,峰值信噪比为30.83。植物生长发育预测模型对冠层叶面积、冠幅和叶片数预测R2分别为0.961 9、0.908 7和0.915 8。所提出的预测模型专注于预测预处理后的RGB图像而不是原始图像,既减少了预测的复杂性,又保留了图像中植物的颜色纹理信息。研究结果验证了预测植物生长发育的可行性,通过减少植物生长、成像和测量所需的时间,进一步加速生物学家培育新品种的试验周期,加快育种智能化的进程。
