基于Transformer模型的RUL预测方法研究*
2022-08-02李学伟王毅洋齐永兰孟昕元
李学伟,王毅洋,齐永兰,邢 倩,孟昕元
(1.河南工学院 智能工程学院, 河南 新乡 453003;2.新乡市工业测控电器系统工程技术研究中心,河南 新乡 453003)
0 引言
预测性维护是智能制造的关键创新点之一[1]。预测性维护通过传感器技术[2]、工业物联网技术、机器学习算法以及大数据技术,从设备的历史运行数据中挖掘运行规律或模式,通过这些规律或模式,能够准确有效地实现对设备剩余使用寿命(Remaining Useful Life,RUL)的预测,进而制定合理的维护计划,以降低维护成本,提高维护效率[3,4]。近十年来,深度学习在RUL预测领域取得了显著成效[5],Giduthuri[6]首次将深度卷积神经网络(Deep Convolutional Neural Network, DCNN)引入RUL预测方法中并取得了较好的效果;Chen[7]目前RUL预测主要存在以下问题:(1)基于支持向量回归(Support Vector Regression, SVR)的预测方法具有对RUL的不同健康状况使用相同权重向量的局限性[8];(2)DCNN模型在捕捉由故障或异常引起的快速退化趋势方面是无效的[9];(3)利用LSTM进行RUL预测虽然可以消除计算过程中梯度消失的问题,但其计算耗时长的缺点无法回避。因此,鉴于注意力机制在模型架构上的优点,本文意图设计一种基于Transformer模型的计算耗时少且相对传统预测算法准确率更高的RUL预测算法。
1 RUL预测系统方法设计
1.1 系统设计方案
一般的RUL预测系统大都采用以大数据为基础的深度学习设计方法,其框架如图1所示。

图1 RUL预测系统框架图
实施预测的具体步骤如下:
步骤1:明确预测目标及目标涉及的范围,针对预测目标搜集相关数据。
步骤2:对收集到的数据进行初步整合、分析,确定数据预处理方案。
步骤3:进行数据预处理,数据预处理主要包含数据清理、数据转换、规范数据、特征选择等内容。
步骤4:选择合适的训练模型,通常情况下,会选用几种不同的模型进行特征学习,然后比较它们的性能,从中选择最优的模型。在选择模型时还需要重点考虑以下几个关键点:(1)最后一层是否需要添加softmax或RELU激活层;(2)选择合适的损失函数;(3)选择合适的优化器。
步骤5:利用测试数据对所选用的模型进行测试,比较不同模型的RUL预测性能。
为了将Transformer模型优越的特性引入设备的RUL预测方法中,本文设计了一种改进的Transformer模型。该RUL预测模型是基于注意力机制的Transformer模型,是Vaswani[10]在2017年为语言翻译任务提出的,在翻译任务中有良好的表现。Transformer模型的体系结构仅依靠注意力机制来完成翻译任务,不再使用任何循环和卷积层,虽然结构简单,但其在精度和计算速度方面优于以前最先进的模型。
1.2 RUL目标函数
在对设备的RUL进行特征学习之前,还需要确定预测的目标函数。
与典型的回归问题不同,基于数据驱动的预测问题有一个固有挑战就是需要确定每个输入数据点的所需输出值,即预测的目标值。这是因为在实际应用中,如果没有一个精确的基于物理的模型,就不可能准确地确定每个时间阶段设备的系统健康状态。一个合理的解决方法是以预测对象在其功能失效前的实际剩余时间作为预测系统的输出。然而,这种方法间接表示了系统的健康状况是随使用时间增加呈线性下降,这将导致RUL预测出现一定的偏差。另一种方法是根据适当的降级模型导出预测系统所需的输出值。
本文所使用的数据集采用分段线性退化模型,该模型限制了RUL函数的最大值,如图2所示。最大值是根据观测值选择的,每个数据集的数值是不一样的。分段线性RUL目标函数更有可能避免算法高估RUL预测的性能。

图2 分段线性RUL目标函数
2 基于注意力机制的Transformer模型
本文的创新点在于,Vaswani的模型在实现机器翻译任务时需要使用编解码结构,而本文提出的模型仅使用了一个没有循环结构的前馈网络,主要由前馈网络模块、尺度点积注意力模块和尺度点积自注意力模块三部分组成,模型的结构如图3所示。输入数据经过输入Embedding线性处理,在加入输入序列位置编码信息以后,分别传输给前馈网络模块、尺度点积注意力模块和尺度点积自注意力模块,最后经过输出层输出预测值。接下来对模型中的关键模块进行分别解释。

图3 基于注意力机制的Transformer模型架构
(1)输入Embedding和位置编码。
该模型的第一部分是输入Embedding模块,假设原始输入样本数据为XIN∈T×d,其中每一行数据表示在一个时间点上的特征向量,输入Embedding模块根据方程(1)给原始输入施加一个线性变换。
XIE=(XIN·W0+b0)+P,
(1)
其中W0∈d×h是贯穿所有时间区间的线性变换矩阵,b0∈h表示偏置,P∈T×h是位置编码矩阵。P和W初始值随机初始化,并在训练期间根据模型中其他参数的变化进行更新。由于该模型没有循环结构,因此序列的位置信息由位置编码模块提供。
(2)前馈网络模块。
由输入Embedding模块线性变换和位置编码矩阵合并的输出XIE∈T×h不能直接输入给注意力模块,需要先经过一个全连接前馈神经网络,然后进行归一化,依据公式(2)和(3)的计算得到前馈网络模块的输出XFF。
FFN(XIE)=ReLU(XIE·W1+b1)·W1+b2
(2)
XFF=Norm(XIE+FFN(XIE))
(3)
(3)注意力模块。
在Transformer模型中尺度点积注意力模块和尺度点积自注意力模块的核心就是注意力机制,注意力模型的输入有三个矩阵组成:有关keys的矩阵K∈T×h,有关values的矩阵V∈T×h,有关queries的矩阵Q∈T×h。注意力模块的输出是一个衔接矩阵C∈T×h,它是根据公式(4)计算得到的。
C=Attention(K,Q,V)
(4)
在尺度点积注意力模块中,注意力模块的三个输入keys矩阵和values矩阵均等于前馈网络模块的输出XFF,即K=V=XFF,与位置编码P相似,queries矩阵Q也是随机初始化并随着训练的过程进行参数更新。然后根据公式(5)进行归一化处理。
XSDA=Norm(Q+Attention(XFF,XFF,Q))
(5)
尺度点积自注意力模块跟尺度点积注意力模块非常相似,唯一的不同是其注意力模块的三个输入完全相同。该结构的目标是利用自注意力机制获取一个序列的深度上下文信息,如公式(6)所示。
XSDSA=Norm(XSDA
+Attention(XSDA,XSDA,XSDA))
(6)
(4)输出层。
我们都知道识字写字教学在小学语文教学中占有极其重要的基础地位,因此,我们需要扎实上好每一堂识字写字课。汉字教学不同于普通的汉字研究,而小学生的记忆、想象、思维及其他活动主要基于图像。在识字教学中,我们需要挖掘汉语言文字在几千年历史发展中积累的大量文化信息,从而增加识字教学的知识内容。整个过程应该集科学、知识和趣味为一体,也让学生进一步感受语言文字的独特魅力。
以上就是本文所提出的基于注意力机制Transformer模型的完整流程。
3 实验与结果分析
为了对本文所提出的RUL预测模型的性能进行深度分析,接下来通过一系列的实验测试,与曾经或目前在RUL预测方面表现较好的算法如SVR、DCNN和LSTM进行对比。
由于以往学者在做RUL研究时均采用CMAPSS或N-CMAPSS数据集进行模型测试,其中N-CMAPSS可以促进预测性维护应用的深度学习算法开发,这些算法更容易转移到实际应用中,此外,N-CMAPSS数据集是机器学习社区测试新的时间序列预测算法的重要资源。因此,为了方便在相同标准下对比深度学习模型的性能,本文采用N-CMAPSS数据集对Transformer模型进行测试。接下来对实验过程进行详细描述。
3.1 数据集
N-CMAPSS数据集描述的是一批飞机发动机在真实飞行条件下,由正常运行到出现故障的状态曲线数据,数据集利用商用模块化航空推进系统仿真动力学模型生成。该数据集由NASA公司的Ames联合苏黎世联邦理工学院和帕洛阿尔托研究中心合作提供,有关数据集的自述文件可以在参考文献[11]中找到。在预测中,准确估计飞机发动机的剩余使用寿命是一个关键问题。通常一些传感器如振动传感器,主要用于收集发动机运行信息,并将其作为估计RUL的特征。
N-CMAPSS数据集包含来自128个单元的八组数据和影响所有旋转子部件的流量和效率的七种不同故障模式。每组数据都存储在HDF5格式的文件中。数据集可在存储库中公开访问,数据存储库中还提供了Jupyter notebook形式的脚本,以演示如何加载、复制数据,并对数据的子集进行简单分析。每个数据文件提供两组数据:训练数据集和测试数据集。每个数据集都包含六种类型的变量:操作条件W、测量信号Xs、虚拟传感器Xv、发动机健康参数θ、RUL标签和辅助数据(即单元号U和飞行循环号C、飞行等级FC和健康状态Hs)。
每个发动机的退化模型由三部分组成:初始退化、正常退化和异常退化。通过调整这些发动机子部件的流量和效率(即发动机健康参数θ)来模拟退化效应。由于制造和装配公差,发动机子部件上有不同程度的初始磨损。虽然这种由初始磨损而导致的退化并不被认为是异常的,但会对部件的使用寿命产生影响,因此,通常会利用各种子部件的流量和效率的变化来模拟这种初始磨损。
3.2 评价指标
为了在测试数据集上公平地对比预测模型在准确率方面的性能,需要一些客观的评价标准。在本实验中,主要采用两种评价标准:评价函数和均方根误差(RMSE)。这两个评价指标值越低,表示对应模型的准确率越高。具体说明如下:
(7)
该评价函数对后期预测(执行维护决策的时间较晚)的程度比早期预测要多,虽然它没有太大的危害,但可能会浪费维护资源,而且,此功能有几个缺点。最显著的缺点就是单个异常值(具有较晚的预测)将主导整体性能得分(请参考图4右侧的指数增长),从而掩盖了算法的整体准确性。另一个缺点是缺乏对算法预测范围的考虑。预测范围在评估故障前的时间,算法能够在某个置信水平内准确估计RUL值。最后,这个评价函数更加偏向于通过低估RUL来人为地降低分数的模型或算法。
除了评价函数之外,估计RUL的RMSE也被用作预测模型准确率的评价指标。选择RMSE是因为它对早期和晚期预测给予相同的权重。将RMSE与评价函数结合使用将避免针对一种评价指标人为降低分数而导致另一种评价指标分数上升的情况。RMSE定义如式(8)所示。
(8)
两个评估指标之间的比较图如图4所示。可以观察到,在较低的绝对误差值下,评价函数产生的值低于RMSE。这两个评估指标的相对特征将在本文后面部分讨论实验结果时应用。
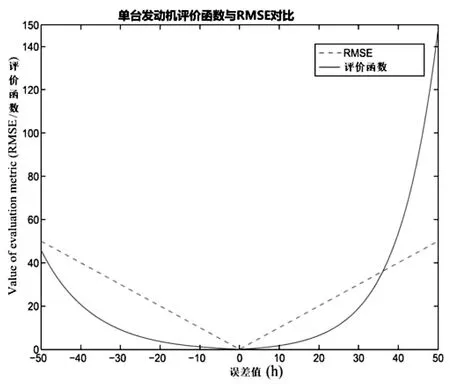
图4 不同误差值对比
3.3 实验条件
本文所有的深度学习模型运行在GPU工作站上,GPU工作站配置为酷睿TMi9-10900K CPU@3.7GHz,32G内存,1块NVIDIA GeForce RTX3080Ti GPU。在整个实验过程中,使用学习率为0.001的Adam Optimizer作为优化方法,在训练阶段对模型进行随机梯度下降。模型的架构使用python v3.7.1 + pytorch1.7.0构建。
3.4 结果分析
根据RUL预测系统的预测流程,在正式进行模型训练和模型测试之前,首先要对原始数据进行探索和预处理,使模型输入的数据更加规范,这样才能体现出模型真实的性能。图5显示了N-CMAPSS数据集中DS02组数据由场景描述变量w给出的模拟飞行数据的核密度估计:高度(alt)、飞行马赫数(Mach)、油门-解析器角度(TRA)和风扇入口处的总温度 (T2)。图6显示了一个典型的单个飞行周期的示例,该示例由场景-脚本变量的轨迹给出。每个飞行周期都包含不同长度的记录,涵盖对应于飞机运行的不同航线的爬升、巡航和下降飞行条件(alt >10,000英尺),其余单元遵循类似的飞行轨迹。

图5 模拟飞行数据的核密度估计

图6 单个飞行周期的示例
为了说明运行条件对异常退化开始的影响,图7给出了DS02组数据三个单元的高压涡轮效率(HPT Eff mod)、低压涡轮效率(LPT_Eff_mod)和低压涡轮流量(LPT flow_mod)的退化轨迹。每个选定的单元对应一个不同的飞行级别。单元11为长途飞行单元,异常退化最早出现在第19次循环。单元14为短飞行长度单元,起始周期为第36次循环。最后,单元15为中等飞行长度单位,其起始周期为第24次循环。可以观察到单元14在后期出现异常退化,因此可以进行更多的飞行。

图7 影响低压涡轮效率和低压涡轮流量的退化痕迹
在经过数据探索和一系列预处理以后,开始进行模型训练和模型测试。表1用RMSE值说明了四种模型在四个子数据集上的比较结果。结果表明,无论运行条件如何,Transformer模型在所有子数据集上均比SVR、DCNN和LSTM获得了更低的RMSE值,表明本文所提出的深度学习模型能够从朴素神经网络中找到比浅层特征更多的信息特征。在四种方法中,SVR在所有数据上均获得了较高的RMSE值,说明单纯的机器学习模型甚至会损害性能,也进一步验证了探索现代深度学习技术的必要性。在单个工况数据集即第一和第三子数据集上,DCNN比SVR的RMSE值更低;在多个工况数据集即第二子数据集和第四子数据集上,LSTM比SVR和DCNN的RMSE值更低,而本文所提出的Transformer模型在多个数据集上取得了较LSTM更好的效果。

表1 N-CMAPSS数据集中不同模型的RMSE对比
同样,在相同的数据集中,表2描述了四种方法在评价函数方面的比较结果。可以看出,在多工况数据集即第二、第四数据集上,以及在单一工况数据集即第一子数据集上,Transformer比SVR、DCNN和LSTM的得分值更低(更好)。在四种方法中,无论运行条件如何,SVR在所有四个子数据集上都比其他方法获得了更高的评分值(最差的结果)。Transformer在一个单一的操作条件数据集即第三个子数据集上的得分略高于(较差)DCNN,尽管RMSE值较低。再加上每个评价指标的特征,这意味着稍微高的分数可能是由预测RUL的某些异常值造成的。基于这些观察,实验发现RUL估计方法的性能还取决于它们的运行条件。

表2 N-CMAPSS数据集中不同模型的评价函数对比
在分别利用RMSE和评价函数对预测模型进行评价中,本文使用的Transformer模型较LSTM模型的参数指标非常接近,但其模型训练耗时却相差较多,前者平均耗时3分30秒,后者平均耗时1.5小时,模型训练效率得到大幅度提高。
4 结语
目前工业核心设备的RUL预测主要存在对RUL的不同健康状况使用相同权重向量的局限性,在捕捉由故障或异常引起的快速退化趋势方面无效,以及利用循环卷积的预测模型计算耗时长的缺点。本文设计了基于Transformer模型的RUL预测算法,分别采用评价函数和RMSE作为衡量预测模型准确率的评价指标,在公开的N-CMAPSS数据集上检验它的RUL预测性能,实验结果表明,该预测模型的准确率显著优于文献中广泛用于RUL估计的现有最先进的深度学习模型如SVR、DCNN和LSTM模型。在未来的研究中,希望进一步探索新的深度学习技术,以解决预测性维护领域中的各种新问题。
