知识图谱在电力设备缺陷文本查错中的应用问题与对策
2022-08-01李彦儒陈耀军王慧芳吴向宏
李彦儒,陈耀军,王慧芳,吴向宏
(1.浙江大学电气工程学院,杭州 310027;2.浙江华云信息科技有限公司,杭州 310012)
电力系统在长期的运行过程中,积累了大量的文本、音频和图像等非结构化数据。非结构化数据挖掘相对困难[1],准确性也较难得到保障。运用文本挖掘技术从电力文本中挖掘实用信息,已经成为当前的研究热点之一[2]。在对专业领域文本进行预处理时,常用的分词方法可以分为3类:基于字典的分词方法、基于统计规律的无字典分词方法以及二者的结合。研究专业领域文本的第一要素是充分理解相关专业术语,无字典分词技术对一些出现频率不高的专业术语难以准确识别,使用领域本体字典则可以帮助机器更准确地理解专业术语。此外,封闭领域的专业词汇数量相对少,新增速度慢,所以在建立相对完善的领域本体字典后,后续更新维护成本较低。
电力设备缺陷文本是由人工记录的描述电力设备缺陷现象的文本[3],会涉及较多出现频率不高的专业词汇,且同一指代可能有书面语、口语、简称等多种表述,因此为了保证分词的准确性,建立并优先使用电力本体字典是一个有效的方法[4]。通过电力本体字典,再结合多种文本挖掘技术,已可以实现缺陷精细化统计[4]、缺陷文本准确检索[5]、缺陷文本质量评价与提升[6-7]、缺陷自动分类与评级[8-9]、参与设备状态评价[3]等功能。上述挖掘技术,大都基于机器学习或深度学习的方法,如缺陷文本分类,文献[8]采用了CNN技术,并针对性地进行了模型的设计和改进,取得了较好的分类精度和效率;而文献[9]则采用了基于注意力机制的双向长短期记忆网络模型,也取得了较好效果。机器学习的方法是基于词的统计特征对文本进行表示,所选取的特征基本局限于关键词出现与否,或者词的出现频率[3],对关键词的内在逻辑缺乏考虑。深度学习方法的发展虽然在文本特征提取和泛化能力提高上有了一定的进步[10],但是依然没有突破语义框架二维表结构的局限,没能应用关键词间的内在逻辑。
近年来,知识图谱技术由于采用图结构对文本信息及其之间的关系进行表示,并可以通过知识推理等方式充分利用文本信息之间的逻辑关系,而受到了普遍关注,已经被用于智能搜索、智能问答、智能推荐及智能决策等领域[11]。在电力领域的多种业务中也陆续出现了一些知识图谱的构建与应用,如电力调度[12-13]、电力运检[5-6]等。然而,目前的研究以概念框架为主,或局限于图谱的理论构建,缺乏具体实施应用效果的分析与总结。针对电力设备缺陷文本,文献[5-6]进行了相应知识图谱的构建方法研究,并基于构建的知识图谱进行了电力设备缺陷文本检索与查错的应用实验,取得了良好的效果。然而在工程应用中发现,随着缺陷文本语料库的不断扩大,该方法出现了一些未曾被考虑到的问题,如少量高频词汇“开关”、“指示”等,存在一词多义的词汇歧义问题,并且还缺少知识图谱更新方法。
针对上述应用中发现的问题,本文研究了解决对策。重点针对词汇歧义问题提出了将歧义实体词与相邻词汇合并为新实体词加入电力本体字典的解决办法,并明确电力本体字典按词汇长度降序排列的规则;针对知识图谱更新问题,提出了通过文本查错来筛选新知识的增量更新方法和通过文本路径查找来筛选退化知识的方法。
1 电力设备缺陷文本知识图谱构建与应用
1.1 电力设备缺陷文本知识图谱的构建过程
(h,r,t)三元组是构成知识图谱的基本单元,h为头实体(head),r为关系(relation),t为尾实体(tail),不同实体通过关系进行有向连接。从图的角度看,知识图谱是一种以实体为节点,以关系为有向边的网状有向图结构。电力设备缺陷文本知识图谱是根据缺陷文本中蕴含的实体以及实体间的关系建立起来的,其构建方法[5-6]大致如下:①实体/属性抽取。依据事先构建的电力本体字典[4],从电力设备缺陷文本语料库中抽取实体词汇,并定义了如下4类实体词性进行标注:描述电力设备的名词En、描述缺陷现象的动词Pv、描述缺陷程度的副词Pad、描述缺陷程度的量词Pq。②共指消解。设置了“同义词.txt”文档,用于存储同义词。判断上一步中的实体词是否属于同义词,若是,则将同义词转化为标准词。③关系抽取。识别实体间是否存在关系以及关系的类型。上述四类实体词汇可生成如表1所示的4种关系,不同实体通过这些关系形成具体的三元组,成为缺陷文本知识图谱的基础。④关系筛选处理。对上一步中自动抽取出来的关系进行人工确定或修正。⑤数据整合。从缺陷文本历史语料库中提取的与从文献[14]中提取的三元组相合并,形成电力设备缺陷文本知识图谱。
为了便于对数据层进行调用和修改,将缺陷文本知识图谱按照关系类型以三元组表的形式存储在4个excel文件中,文件名详如表1所示,其中头实体h、尾实体t均以词汇形式表示,关系r以数字形式表示。之后使用知识图谱时,只需要将4个文件中的数据导入即可。

表1 三元组与对应的存储文件Tab.1 Triples and corresponding storage files
1.2 基于电力设备缺陷文本知识图谱的查错过程
基于构建的知识图谱,可以进行缺陷文本的检索、查错、自动分类等应用,下面以新录入缺陷文本的查错为例介绍知识图谱的应用过程。
一条合格的缺陷文本必须包括缺陷位置和缺陷现象,也可以包括对缺陷程度的描述,因此在知识图谱图结构上,其对应的节点与边所构成的完整路径需要满足以下3个条件:①所有En节点构成单树支的包含关系;②处于树支最末端的En节点与Pv节点相连接;③若存在Pad节点和Pq节点,则它们需与Pv节点相连接。运用图搜索算法进行文本查错时,不存在质量问题的文本一般缺陷部位和现象描述准确,路径唯一存在;而存在质量问题的文本通常有以下几种表现:可能因为缺陷位置层级描述不详而查找到多条路径;也可能因为缺少缺陷现象、缺陷位置或者实体之间的关系而无法查找到完整路径。据此可以依据路径查找的结果判断文本是否存在质量问题。为了方便录入人员对存在质量问题的文本进行修改,可以将文本错误类型分为5种,并给出对应提示,如表2所示。

表2 文本的错误类型、错误原因及报错提示Tab.2 Types,causes and message of text errors
新输入缺陷文本的查错流程如图1所示。其中,同义词替换参照“同义词.txt”文档,将同义词统一规范化替换;在知识图谱中查找待查错文本的路径时采用的是图搜索算法;若判断文本存在质量问题,则给出相应的报错提示。
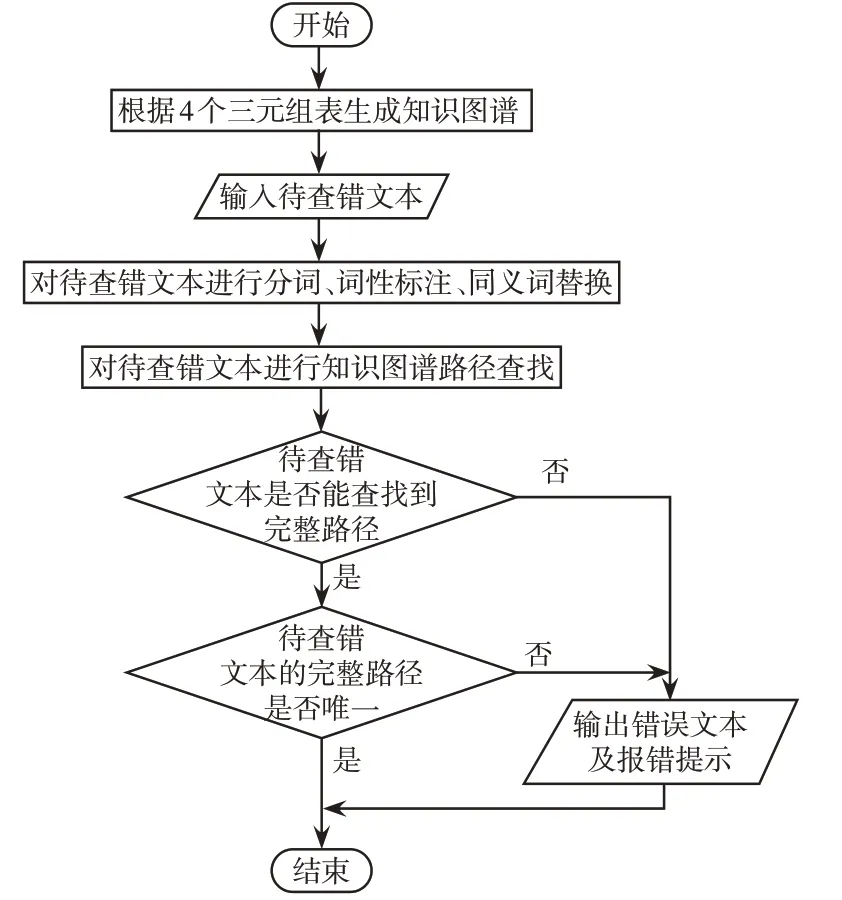
图1 缺陷文本查错流程Fig.1 Flow chart of defect text error checking
1.3 缺陷文本知识图谱构建与应用中的问题
在上述构建电力设备缺陷文本知识图谱和应用其进行文本查错的实践过程中,发现实际缺陷文本知识图谱还有一些尚未被考虑到的问题需要解决。
1.3.1 复杂多样的文本质量问题
(1)词汇错记。由于增字、漏字、错别字三类原因导致实体词汇出现错误。基于电力本体字典的分词与实体识别方法无法对错字实体词进行识别,反而有利于这类文本质量问题的发现。不同的错字实体词会导致不同的报错类型,如增字将“进油管”错记为“进油口管”,“进油管”是出现缺陷现象的位置,所以会导致该条记录中的Pv词汇“漏油”寻找不到与之匹配的En词汇,报错结果为“漏油无对应对象”。对于这类错误,需要录入人员根据报错提示对词汇进行修正。
(2)词汇缺省。缺陷文本录入是个主观性较强的工作,描述缺陷时,不同的人会形成不同详细程度的文本。因而经常会出现缺省某一个或某几个设备层级的缺陷部位描述,体现在知识图谱中,就是缺少一些En节点而无法形成完整路径。图搜索算法具有基于图的知识推理功能,可以挖掘图中隐含知识,推断出缺省部分所有可能的情况,每种可能都会结合已确定的部分生成一条路径。如果路径能够唯一确定,说明缺省部分可以被确定性的推断出来,就可以自动补充完整,因此可以视作正确文本。但若路径无法唯一确定,说明无法准确推断出省略的中间部分,只能将该文本视作错误文本,错误类型为“对象不唯一”。
(3)记录不全。存在严重的内容缺失而无法理解,如“通信异常”、“指示不清”,只有缺陷现象没有缺陷部位描述。这类问题难以参考其他文本或者设备缺陷用语规范实现精准补全,只能在录入时进行管控,要求录入人员按照错误类型提示予以补充,直到满足质量要求。
(4)词汇歧义。构建电力设备缺陷知识图谱时,认为它属于封闭域知识图谱,实体词义仅限于电力领域,且电力行业有明确的术语规范,基本不存在歧义问题,因此省略了实体消歧步骤。但是工程应用中发现,由于记录习惯和中文词汇的多义性等问题导致少量高频词汇出现歧义问题,主要表现为En词汇的一词多义和实体词汇的词性歧义,需要进行实体消歧以统一语义表达。这类问题难以通过文本录入时的质量查错得到解决,具体的原因分析及解决办法后续重点说明。
1.3.2 知识图谱更新的继承和发展问题
知识图谱需要在不断应用中,评估其质量,并结合知识的发展与丰富,对其进行更新与修正。然而实际应用中,存在两难情况:一方面,知识图谱的构建过程虽然可以自动实现,但还需要人工参与才能保证知识图谱的质量,如实体词及其词性、同义词、关系筛选等均需要人工确认或修改,因此知识图谱自动更新容易覆盖掉人工参与的成果,出现继承困难问题;另一方面,随着技术的发展电力设备在更新换代,电力设备缺陷文本知识图谱的发展不仅是增加新的缺陷知识,还需要删除失效的缺陷知识,相对新增来说,删除更为困难。因此,知识图谱更新过程中,这种继承和发展的平衡是一大难点。
2 词汇歧义问题分析与解决方法
2.1 En词汇的一词多义及解决办法
记录人员出于记录习惯等原因,对于一些电力设备、部件等专有名词会使用简称或者代称,这样会导致En词汇的多词同义和一词多义。多词同义可以通过同义词的替换来实现统一,而一词多义属于歧义问题,在构建知识图谱过程中,需要在关系抽取前增加实体消歧。
实体消歧目前主要采用聚类法,常用模型有语义模型、社会网络模型等。但是这些模型的训练效果受文本质量和数量影响很大,多应用于大型开放域知识图谱,如百科网站。用于缺陷文本这种规模不大的封闭域效果难以得到保证,为此使用电力本体字典辅助分词来实现实体消歧。
电力本体字典参与分词时,是按照词汇排列顺序作为依据对文本进行分词,即匹配到排在前面的词,那该词就被分出。因此为避免长实体词汇被拆分,提出电力本体字典要按照词汇长度降序排列的规定,且先使用电力本体字典分词,再进行jieba分词。基于上述排序规则和分词规则,对于存在多种含义的En词汇,可以通过将该实体词汇与相邻实体词汇合成为一个新的长实体词汇来进行识别,即通过提高词汇长度来保证优先被识别,实现实体消歧。以缺陷文本“储能电源开关合不上”为例,最初的分词情况为“储能/电源/开关/合不上”,该分词结果中的“开关”会被同义词“断路器”替代,发生实体歧义。将“开关”与相邻的“电源”实体词汇合并成“电源开关”,标注En词性,并按照词汇长度将其放到电力本体字典相应位置。再进行分词时,“电源开关”由于词汇长度比“电源”和“开关”长,会被优先检索到,分词结果就会变为“储能/电源开关/合不上”,新的分词结果与原有的“开关”进行了区分又没有影响文本语义的整体识别,达到了消歧的目的。在新实体词实现消歧后,需要根据新词汇与其他实体词之间的关系更新三元组表,保证知识图谱中知识的完整性和准确性。
2.2 实体词汇的词性歧义及解决办法
由于中文文本的词性和语法结构等原因,有一些中文词汇在不同的缺陷文本中出现兼类现象,且缺乏形态转换等区分手段,如表3所示。以“显示”这个实体词为例,它原本是Pv词汇,如表3的第1句;但是也常作为“显示值”或者“显示结果”的简称,因此又被用作En词汇,如表3的第2句,这样就出现了词性歧义。构建和使用知识图谱过程中,在进行文本分词和词性标注时,没有对实体词的多种词性进行区分;且同义词转化是在词性标注之后,因此无法将En词性的“显示”进行同义词转化以作区分。并且,一些歧义词的词性还会影响其他词汇的词性,如表3的第3句,“显示”和“异常”这两个词有两种词性定义方式,即①“显示”是Pv词汇,“异常”作为“显示”的修饰词是Pad词汇;②“显示”是En词汇,“异常”作为“是异常的”的缩略写法,是Pv词汇。这种复杂情形再度增加了知识图谱对歧义词汇识别的困难性。缺陷文本中存在词性歧义的词大概有十几个,如“遥控”、“指示”等,它们出现频率较高。
词性歧义问题也可以通过电力本体字典辅助分词来实现消歧。对于存在多种词性的实体词汇,一般设定一种常用的词性,对存在该词汇其他词性的文本,寻找与该词汇相邻的词汇,将其合并为一个新词汇添加到电力本体字典进行识别。仍以“显示”为例,考虑到En词性易于与相邻词汇合并,所以在电力本体字典中将其定义为Pv词性,而当其在句子中呈现En词性时,则与相邻词汇合并为新的实体词,如表3中第2句合并为Pv词性的“显示不一致”,第3句合并为Pv词性的“显示异常”。合并后词汇长度增加,不会对原有词的识别产生不利影响。如原有词“异常”,是出现频率较高的Pv词汇,如表3中第4、5句,新增的“显示异常”实体词汇加入电力本体字典后,对其识别没有影响。因此,上述解决办法,不仅与原有词性进行了区分又没有影响文本语义的整体识别,达到了消歧目的。

表3 词性歧义词汇及实体消歧示例Tab.3 Examples of word of speech ambiguities and entity disambiguation
3 知识图谱更新
3.1 知识图谱更新常用方法
知识图谱更新包括新增知识和退化知识,即增减实体以及实体之间的关系。目前,针对电力领域知识图谱更新的研究相对较少。知识图谱的更新方式有两种,全面更新和增量更新。全面更新是在新数据加入后,依据现有数据重新自动构建知识图谱,常用于搜索引擎更新等开放域应用场景。增量更新大多是提取出新增数据中的新知识,加入到原有知识图谱中,这种更新方式资源消耗小,并能够利用之前的知识积累,多适用于封闭域知识图谱,是未来的发展方向。根据缺陷文本知识图谱的特点,并考虑新知识的有限性以及知识图谱中已有的人工经验需要继承,采用增量更新方式,实现最大程度的知识继承。
3.2 新知识的筛选与融合
新知识主要来自2种,一种是新实体的出现以及相关的三元组增加;另一种是原来无关系的一对实体产生了新的关系。筛选新知识需要先找到含有新知识的缺陷文本,依靠人工寻找的方式效率低下且难以保证找全。在运用缺陷文本知识图谱进行缺陷文本查错的过程中发现,报错的文本除了存在质量问题,也可能是存在某些未被识别的知识。因此可以通过对新的缺陷文本集进行查错和在报错文本中剔除质量确实存在问题的文本2个步骤,筛选出含有新知识的文本。从报错文本中筛选新知识需要人工经验参与,之后进行新知识与旧知识图谱的融合,这样既保证准确性又大幅度地缩小了新知识的查找范围,提高了知识筛选的效率。
比如“电容器开关内部并联电阻烧毁”,报错为“并联电阻无对应现象”。经查,“并联电阻”与“烧毁”这一对实体词汇之间的关系在已有的知识图谱中不存在,即出现了新知识,需要在stnstv.xls表中增加该三元组知识。表2中的文本错误类型对产生新知识的原因有指导作用,错误类型对应的新知识类型如表4所示。

表4 文本的错误类型与新知识类型Tab.4 Error types and new knowledge types of text
知识图谱更新流程如图2(a)所示。更新效果可以用正确文本的查错进行验证,直到没有出现新的错误。需说明的是,由于知识图谱通常是逐步更新的,即每次发现含有新知识的文本较少,因此可以由人工辅助来更新知识图谱,涉及的文件包括电力本体字典、同义词表和4个三元组表。上述更新方法可以最大限度地保护原知识图谱中经过人工确认过的知识,又能够更多的识别新知识,达到知识图谱继承与发展的平衡。同时,由于在此过程中可以识别到新增或者变化的实体词,电力本体字典也能得到更新维护。
3.3 退化知识的筛选与删除
寻找退化的知识一般有2种情景:①定期对知识图谱进行维护,删除长期不用的知识;②已知某类设备停用,删除相关知识。运用图搜索算法进行文本路径查找的过程中,可以对查找到的知识图谱中的节点和边进行标记,进而筛选出退化知识。上述2种情景中,对于前者,可以对一定年限内的缺陷文本进行路径查找与标记,无标记的节点和边就是退化的;对于后者,可以从缺陷文本语料库中找出所有与停用类型设备相关的缺陷文本,而后对剩余的缺陷文本进行路径查找和标记,无标记的节点和边也是退化的。
筛选出退化的节点与边之后,就可以对它们进行删除,也就是在电力本体字典、同义词表和4个三元组表中删除退化的实体词、三元组等知识。之后,可以通过文本查错来校验更新后的知识图谱的完整性,即文本查错结果满足如下要求:①对含有退化知识的文本查错时均应报错;②对不含退化知识的正确文本查错时均不报错。退化知识的删除过程如图2(b)所示。
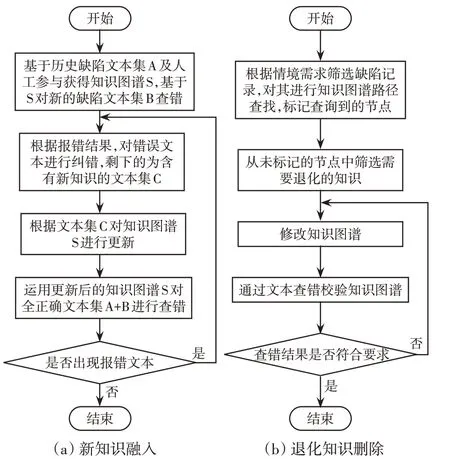
图2 知识图谱更新流程Fig.2 Flow chart of knowledge graph updating
4 算例分析
4.1 算例情况与实验结果
选择2 800条缺陷文本及文献[14]作为训练集,随机选取新录入的500条缺陷文本作为测试集,验证词汇歧义问题解决方法和知识图谱增量更新方法的效果。
实验过程中用到3个版本的知识图谱,它们的更新过程如图3所示。运用本文1.1节所述的知识图谱构建方法,使用初始的电力本体字典,获得缺陷文本知识图谱版本S1。采用第2节所述的实体消歧方法,实现了对版本S1的实体消歧,形成知识图谱版本S2。在使用S2对测试集进行文本查错后,采用第3节所述的知识图谱增量更新方法,根据报错文本筛选新知识,对S2进行知识图谱更新,形成知识图谱版本S3。在评价各版本知识图谱的缺陷文本查错效果时,采用错误文本的查准率P、查全率R和F1值3个指标[6]。
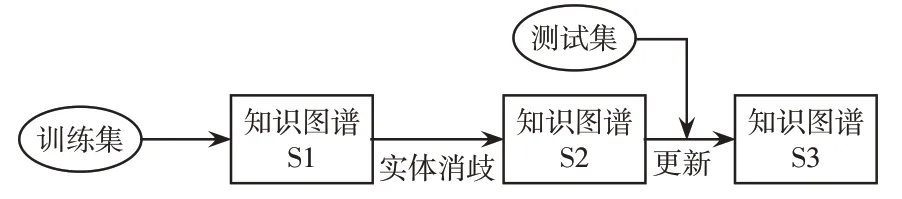
图3 实验过程中知识图谱的版本更新示例Fig.3 Example of knowledge graph version updating during experimental process
在测试集包含的500条缺陷文本中,人工检查认为存在质量问题的文本共有211条。基于S1、S2、S3版本知识图谱对测试集的文本查错结果统计如表5所示,3种性能指标如表6所示。

表5 3个知识图谱的文本查错数量统计Tab.5 Text error checking quantity statistics of three knowledge graphs
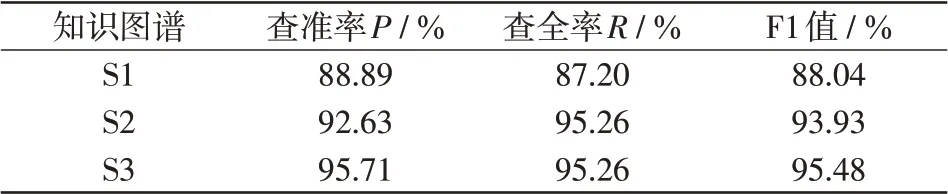
表6 3个知识图谱的文本查错性能指标Tab.6 Text error checking performance indexes of three knowledge graphs
4.2 实体消歧效果分析
知识图谱版本S1在查准率和查全率方面都相对较弱,其中由于歧义问题导致的误判大约占一半的比例。对S1增加实体消歧功能得到知识图谱版本S2,S2的性能尤其是查全率相较于S1有明显的提升,说明在增加了实体消歧功能后,知识图谱文本查错模型的性能得到了提升,特别是在寻找真正的错误文本方面取得了较大进步。
版本S1和S2的部分结构如图4所示,“电抗器温度计显示异常”在版本S1中,由于“显示”为Pv,“异常”也为Pv,所以两者间无法建立关系,因此报错“异常无对应对象”;在版本S2中“显示异常”为Pv,是En“温度计”的现象,所以为正确的缺陷描述。
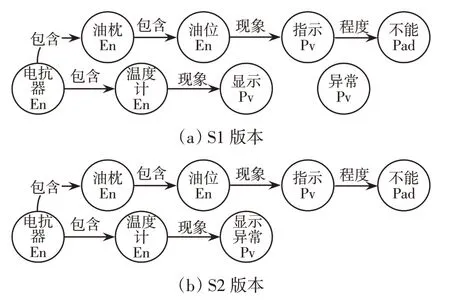
图4 知识图谱部分结构示例Fig.4 Examples of partial structure of knowledge graph
4.3 知识图谱更新效果分析
知识图谱版本S3在查准率方面相较于S2有所提升,这是因为S2是基于训练集生成的,在测试集中存在一些相较于S2版本具有新知识的正确文本,被其误判为错误文本。而S3版本是在S2基础上增加了这些新知识,所以没有出现误判。在S2的报错文本中,共寻找到7条含有新知识而被误判的正确文本。以其中的“母分开关连接铝排示温蜡片褪色”为例,这条文本在S2版本中报错“示温蜡片对象不唯一”,原因是“连接铝排”在分词和实体识别过程中没有被识别为实体词,知识图谱中没有“母分开关-连接铝排-示温蜡片”3个En词汇之间的包含关系。当将其作为新知识加入到知识图谱后,这条文本在知识图谱S3中的路径查找结果如图5所示。利用这7条文本中的新知识更新S2得到S3版本,电力本体字典条目也相应地由1 785条增加至1 789条,而S3版本的报错文本中这7条文本均没有出现,且相较于S2版本没有其他正确文本被判定为错误文本,说明新知识成功的融入了知识图谱,知识图谱更新得到实现。

图5 知识图谱S3示例Fig.5 Example of knowledge graph S3
分析发现,更新后知识图谱的查全率和查准率普遍较高,主要是因为知识图谱可以准确地识别关键信息、匹配同义词和进行知识推理,而不局限于字面上的相似度、关键词频率等信息,并能充分结合电力领域的专业知识,具有很强的针对性,这些特点是关注语义特征的机器学习和深度学习模型所不具备的。
然而,缺陷文本知识图谱的性能仍受到一定的限制,制约因素主要有以下两方面:①缺陷文本质量问题造成的影响。在1.3.1中已总结一些文本质量问题,其中词汇歧义和词汇缺省对知识图谱性能的影响最为严重。词汇歧义问题天然地干扰了关键信息的识别;而词汇缺省则影响了电力设备清晰明确的包含关系,对知识推理和路径查找产生了严重的干扰。随着文本录入智能管控的应用,文本信息将会更加规范,文本质量问题将不断减弱。②实体和关系提取的结果难以保证绝对准确,影响了知识图谱的质量。该问题受到文本质量和数量、分词模型、关系抽取模型、人工经验等多因素影响,为此,在构建和使用知识图谱的过程中,需要滚动进行,不断完善各个步骤,提升知识的准确性和完整性。
5 结语
本文以知识图谱技术在电力设备缺陷文本查错中的应用为例展开研究,总结了电力设备缺陷文本知识图谱构建与应用中的问题,并给出了相应的解决办法。重点针对词汇歧义这个难题,提出了将歧义实体词与相邻词汇合并为新实体词加入电力本体字典的解决办法,并明确电力本体字典按词汇长度降序排列的规则,进而有效提升了分词的准确性。此外,提出了一种通过文本查错来更新知识图谱的方法,并给出了新知识的筛选与融入流程,以及退化知识的识别与删除流程,解决了知识图谱继承和发展的平衡难题。
随着自然语言处理等人工智能技术的发展,知识图谱技术将获得更多的应用,未来电力领域需要探索更多适合知识图谱应用的需求,并建立知识图谱质量评价方法。
