采用机器学习的变压器分层故障诊断
2022-08-01王子鉴秦瑜瑞李景丽
王子鉴,秦瑜瑞,李景丽
(1.郑州大学电气工程学院,郑州 450001;2.国网河南省电力公司郑州供电公司,郑州 450000)
电力变压器是电网中的核心设备,在发电、输电、配电每个环节中都有不可取代的作用,其运行状态直接影响着电网供电可靠性,对变压器运行状态做出正确评估,具有重要意义。变压器运行状态可分为正常工作状态、热故障、电故障和机械类故障四大类。其中,大类故障又可细分,如热故障可划分为低温过热故障、中温过热故障、高温过热故障。变压器发生故障时,可在绝缘油中检测到大量气体,气体的成分、含量、产气速度[1]与故障类型有密切关系。油中溶解气体分析DGA(dissolved gas analysis)是目前应用最为广泛的一种简单、有效的方法。DGA依据变压器油裂解产生的特征气体,构造用以确定故障类型的判据。近年来,基于DGA已发展形成了多种变压器故障诊断方法,如大卫三角法[2]、IEC三比值法[3]、改良三比值法[4]、Roger比值法[5]等,上述方法通过求取气体之间的比值,进行“编码-查表”的步骤后确定变压器的故障类型,但这些方法编码边界过于绝对,且都是建立于现场工程经验上,易出现诊断结果不一致的情况。近年来随着人工智能技术的发展,多种智能识别方法被运用在变压器故障诊断领域,如神经网络[6-7],支持向量机[8-9]等。这些方法以数据驱动为基础,不过多依赖于工程经验。文献[7]通过分析变压器油色谱数据特点,利用Spark计算框架,提出了一种基于多深度神经网络的故障识别算法。
但对于变压器故障诊断这一典型多分类问题,上述方法直接以小类故障为分类目标,未考虑大类故障之间、同一大类故障下的小类故障间的差异。同时,以H2、CH4、C2H2、C2H6、C2H4等全部特征气体及比值作为故障诊断的输入量,忽略特征量与故障类型之间的相关性。因此,应对变压器进行分层诊断,并选取与分类目标联系紧密的故障特征量。文献[10]基于机器学习中的特征工程,通过卡方检验分析特征量与分类目标之间的相关性,进行特征选择,在多分类问题中取得了良好效果。
文章针对变压器主要几种油中溶解气体(H2、CH4、C2H2、C2H6、C2H4),采用卡方检验对每种气体与分类目标的相关性进行探究,剔除与分类目标相关性较小的特征气体。在分层故障诊断方案的基础上,利用不同的机器学习分类器对精简后的特征气体诊断效果进行评估,确定效果最优的特征气体与分类器。最后,与未经特征选择的分类方法进行对比,验证了文中方案的有效性。
1 故障类型与特征气体分析
绝缘油是由不同碳氢化合物组成的混合物,在放电和过热故障作用下发生化学反应后,各类气体含量产生变化。不同故障类型对应的气体成分如表1所示。
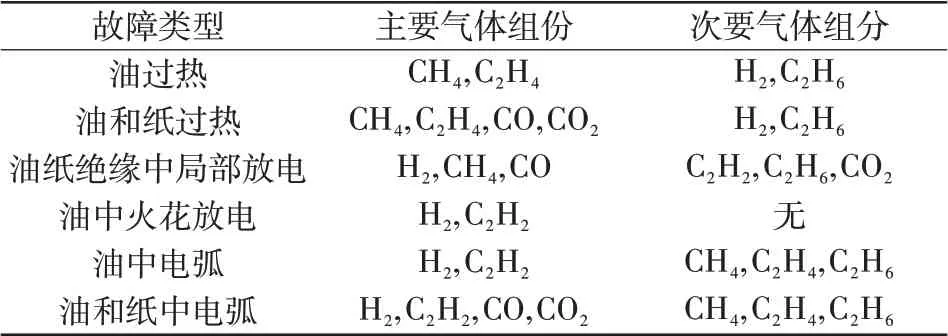
表1 故障类型与油中溶解气体Tab.1 Fault types and dissolved gases in oil
变压器故障按大类分为热故障和电故障,据表1可知,气体组分和故障类型之间具有很强的相关性,故障类型不同时,气体组分也会随之改变。例如:放电故障时,化合物中的C-H键断裂,生成H2,当放电具有较高能量,C-C键断裂,形成CH4、C2H6等气体;过热故障时,化合物中的C=C键断裂,生成C2H2等气体。
2 机器学习与分层故障诊断
2.1 分层故障诊断模型
文章依据DLT722—2000《变压器油中溶解气体分析和判断导则》和样本分布将运行状态划分为热故障、放电故障、正常三大类,其中,热故障分为中低温过热、高温过热,放电故障分为低能放电、高能放电。
由于大类故障之间、同一大类故障的小类故障之间气体特性均有所不同,为充分利用故障特性,采取分层诊断策略对其进行分类,先对大类故障进行诊断,进而细分故障类型[11]。分层故障模型如下图1所示。
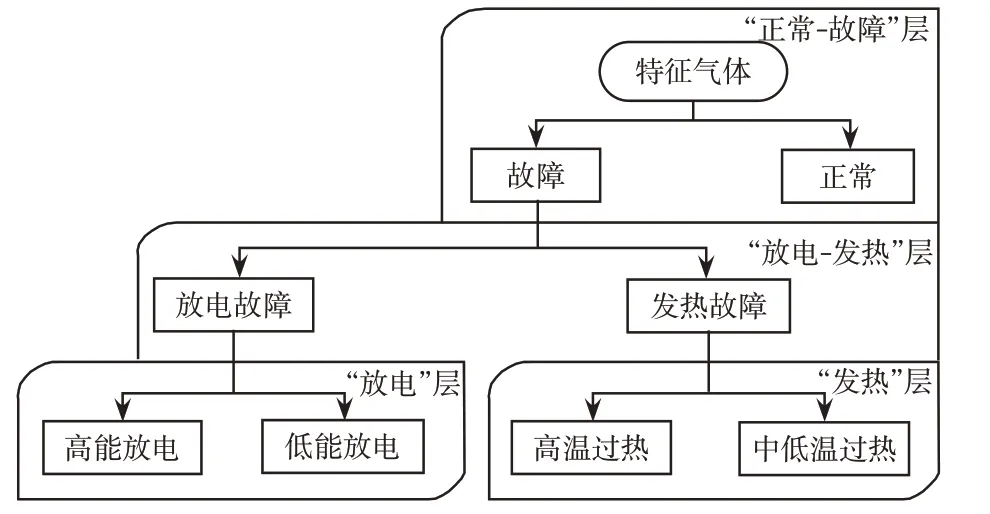
图1 分层故障诊断模型Fig.1 Multi-level fault diagnosis model
其中,第一层诊断用以划分正常与故障状态;第二层诊断区分过热故障与放电故障;第三层和第四层诊断为平行关系,分别对过热故障和放电故障进一步划分。模型中各层分别取名为“正常-故障(N-F)”层、“放电-发热(D-H)”层、“放电(D)”层、“发热(H)”层。
2.2 卡方检验计算特征气体相关性
卡方检验可用于检验两组量之间的相关程度,在机器学习领域的特征选择中得到广泛应用[12]。以“故障-正常”诊断层为例,如果某种特征气体与分类目标无关,则该气体在样本中的分布不会因为所属目标为“故障”或“正常”而不同,即该气体无论在目标为“故障”还是“正常”,其都应为均匀分布。以氢气为例,氢气含量的取值C可能属于n种不同区间{C1,C2,…,C n},目标值E有两种不同的取值{E1,E2},数据联合分布可如表2所示。

表2 氢气与目标的联合分布Tab.2 Joint distribution of H 2 and target
假设氢气含量和故障标签独立,取标签为E1的N.1个样本,标签为E2的N.2个样本组成样本集P,共N个样本。从样本集中随机抽取N1.个样本,若氢气含量和分类目标满足独立假设,则该N1.个样本中满足E=E1的期望个数m应该为

按照以上规则,则满足C=Ci,E=Ej的期望个数为

期望样本集与实际样本的差异定义为

式中:N.j为表2中第j列的数值之和;N ij为表2中第i行第j列的数值。
χ2越大,则氢气含量与分类目标的关联度越高,在分类过程中发挥的作用更重要。同理计算其余气体在该诊断层中的χ2,在不同诊断层中,也以此作为特征气体选择依据。
2.3 机器学习分类器
变压器故障诊断数据通常由两部分组成,分别是特征气体构成的特征向量集合X和目标类别Y,其中X={x1,x2,…,x n},n为样本数量。分类器的任务是通过训练数据,建立模型,利用该模型,对于给定的测试样本X,预测输出Y。
线性回归LR(linear regression)和支持向量机SVM(support vector machine),决策树DT(decision tree),随机森林RF(random forest)都属于判别模型,由输入的数据X得到预测分类目标f(X),在训练过程中,通过实际目标Y与预测目标f(X)之间的关系进行迭代,以此确定决策函数f(X)的构造。LR是一种线性回归模型,通过求解损失函数的最小值,来确定最优权重和偏置。SVM是机器学习中极具代表性的算法,通过将原始向量x映射至高维空间φ(x),使线性不可分数据变为线性可分,构造距不同类别距离最大的最优超平面进行分类[12]。分类模型为
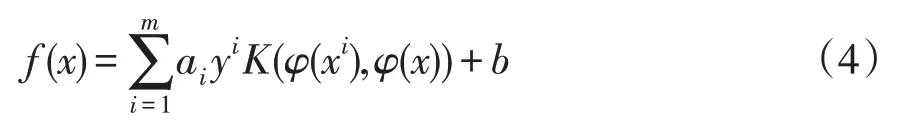
式中:a为拉格朗日乘子;,K为核函数。SVM是针对二分类问题提出的,而变压器故障诊断为典型多分类问题,利用“一对一”方法可将多分类问题分解为二分类问题。DT是一种树模型结构,构建决策树是从根节点不断递归生成子树的过程,在每个叶子节点,通过信息熵的大小来选取最优特征,之后经剪枝策略以防止过拟合。RF是一种集成算法,本质上为多个决策树的集合。
朴素贝叶斯NB(Naive Bayesian)则属于生成模型,生成模型的目标是求取联合分布概率P(X,Y),并利用条件概率公式,在训练完毕后,对于给定的输入X,该模型可给出属于Y的概率,以此判断所属类别。所采用的条件概率公式为

3 算例分析
3.1 数据预处理
文章以文献[13]中绝缘油分解产生的气体含量与故障类型作为数据来源,剔除冗余样本和异常样本,并将低温过热和中温过热合并为中低温过热,建立故障库。
样本中运行状态类型分布如表3所示。

表3 样本中各运行状态分布Tab.3 Distribution of each operating state in dataset
由于文献[13]中的特征气体在不同样本中大小差距较大,采用如下公式进行归一化处理:
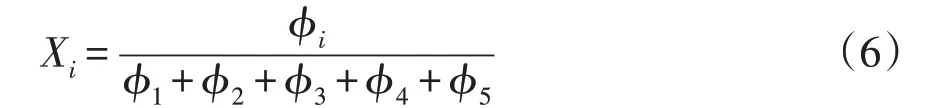
式中,φ为归一化后的气体,下标1、2、3、4、5代表H2、CH4、C2H2、C2H6和C2H45种特征气体;Xi为经过缩放后的气体i的含量,i=1,…,5。
3.2 特征气体与分类目标关联度分析
对于每个诊断层,求取特征气体与分类目标的χ2值,并按式(7)对其进行归一化后如表4所示。
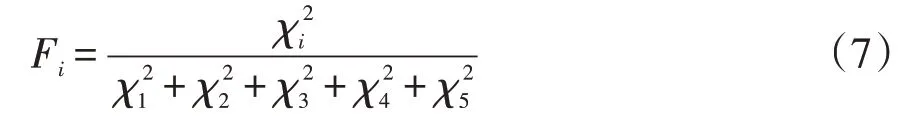
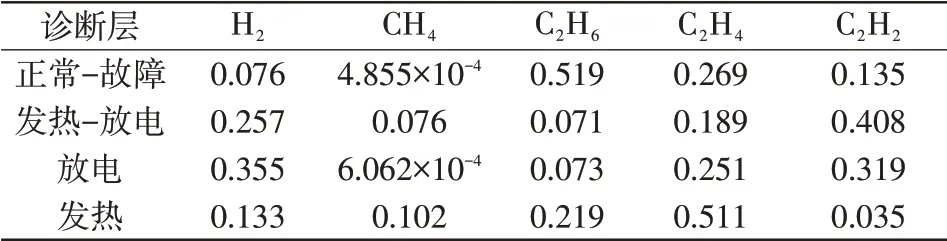
表4 归一化后的关联度Tab.4 Correlation after normalization
变压器在正常状态下,产生的能量不足以分解C2H6,该气体含量较高,发生故障时,变压器内部产生大量能量,使C2H6分解产生C2H4,C2H6和C2H4两种气体的含量变化与“故障”和“正常”两种运行状态之间具有很强的相关性,因此,这些气体在“正常-故障”诊断层相关程度较高;在“发热-放电”诊断层经卡方检验得到的相关程度较高的3种气体为H2、C2H2、C2H4。通过表1可知,过热故障时产生的主要气体有C2H4,而放电故障产生的主要气体为H2、C2H2,这3种气体对于区分过热故障和放电故障具有重要意义;过热故障时,随着温度的升高,由CH4和C2H6分解产生的H2、C2H4逐渐增多,由该特性可知,两种气体是温度升高的标志,可用于划分中低温故障与高温故障;电弧放电与电火花放电均存在大量的H2和C2H2,相比电弧放电,电火花放电能量较低,次要气体中存在C2H4和C2H6,而电火花放电则不存在两种气体。在上述其余各故障诊断层中,由卡方检验得到的相关气体相关度大小,与特征气体在不同故障类型中的理化性质保持一致,验证了卡方检验在分层故障诊断中的可行性。
3.3 分类器效果对比
文章为减少特征气体的维度,降低特征气体的冗余度,提高分类器故障诊断准确度,只选取部分特征气体输入分类器。根据表4中每个诊断层下每种特征气体的χ2大小,对其重要程度进行排序。将排序靠前的特征气体种类数定义为最优特征数Z,Z值由5至1依次选取,通过减小最优特征数来检验剔除次要气体对故障诊断性能的影响。以“正常-故障”诊断层为例,当Z=3时,只选取χ2大小为前3位的特征气体进行训练,即依据表4,选取C2H6、C2H4、C2H2的数据作为样本输入分类器进行故障诊断。
文章采用文献[13]中的数据,去除重复和异常样本,共选取其中517组数据,作为故障库,该故障库中各故障类型分布如表3。以Scikit-learn 0.2为平台,采取SVM、NB、RF、DT、LR 5种分类器,每种分类器训练时均采用“留一法”交叉验证[14],以综合准确度作为指标。其中,NB、RF、DT、LR采取默认参数,对于SVM,在每层诊断时采取网格搜索寻找最优参数C和γ[11]。对于每种分类器,计算流程如下:
(1)将每个样本中各类气体含量按式(6)进行归一化处理;
(2)对故障类型编号,作为分类目标;
(3)根据Z值选取特征气体;
(4)输入分类器,并采用“留一法”交叉验证,得出在当前Z值下的准确率;
(5)改变Z值,重复步骤(3)、(4)。
各诊断层中,Z取不同值时,各算法的准确率如表5至表8所示。
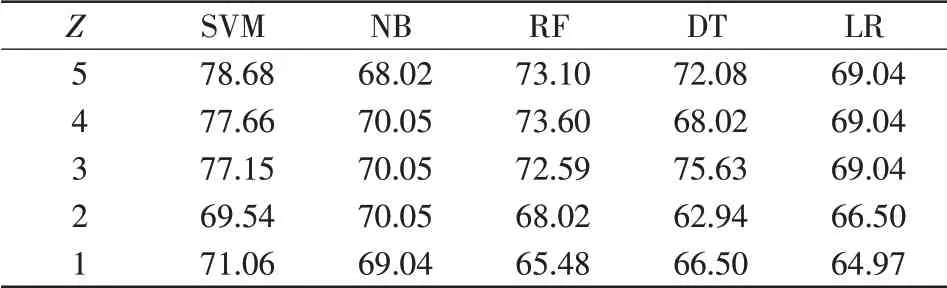
表8 “放电”层算法准确率Tab.8 Accuracy of algorithm at“D”level %
以下各表中,当Z=5时,即代表在分类过程中选取了全部5种特征气体。通过分析表5可知,在“正常-故障”诊断层中SVM、NB、LR 3种分类器,分别在Z=2、Z=4、Z=1时,出现了故障诊断准确率大于选取全部气体时的准确率的情况,RF和DT选取全部气体时的准确率仅比Z=4有微小提升。其余各诊断层与该层类似,除少数分类器在剔除相关性较弱的气体后准确率出现微小下降,其余分类器都体现出筛选特征气体的优越性。可见,剔除与分类目标相关性较小的气体,减少特征气体的维度,有助于避免各分类器的过拟合现象,故而提高分类器准确度。
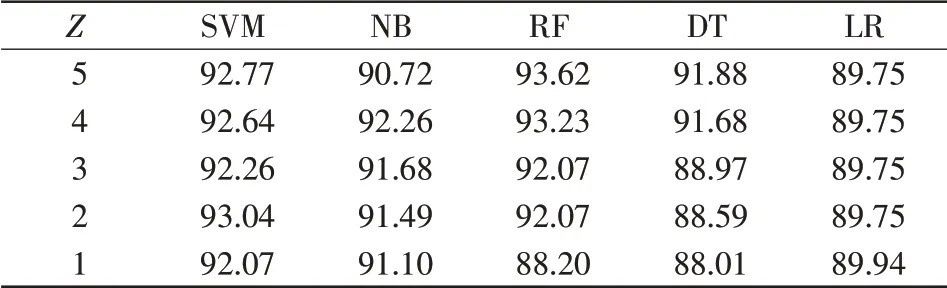
表5 “正常-故障”层算法准确率Tab.5 Accuracy of algorithm at“N-F”level %
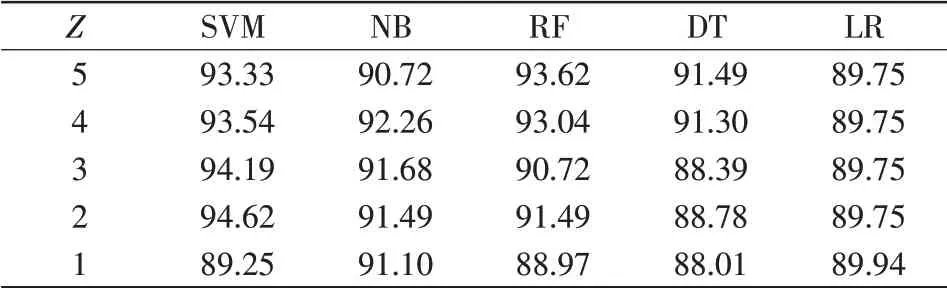
表6 “发热-放电”层算法准确率Tab.6 Accuracy of algorithm at“H-D”level %
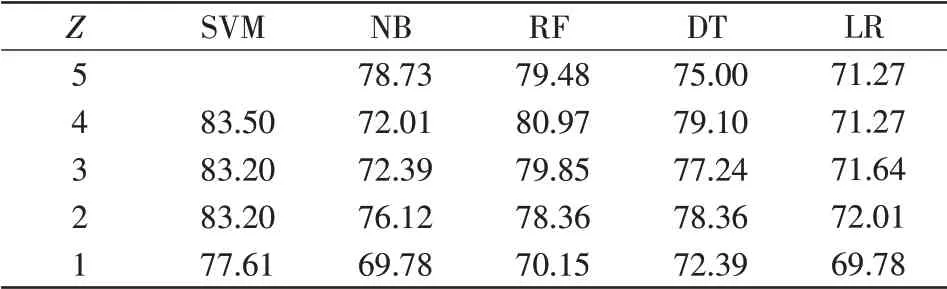
表7 “发热”层算法准确率Tab.7 Accuracy of algorithm at“H”level %
3.4 基于SVM和特征选择的分层模型
根据表5至表8中个各个分类器的性能,选择在不同诊断层具有不同核参数的SVM作为最佳分类器。分类器选择不同数量特征气体作为输入时,在每个诊断层的的准确率如图2所示。
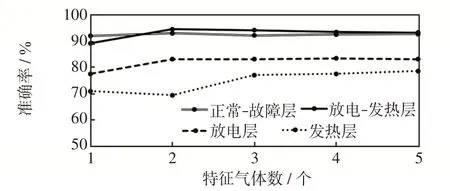
图2 SVM在各诊断层准确率Fig.2 Accuracy of SVM at each diagnosis level
从图2可以看出,SVM分类器在“正常-故障”层、“发热-放电”层、“发热”层经特征选择后准确率得到提高。在“放电”层,当Z=3时,剔除2种特征气体,准确率和采取全部5种特征气体时的准确率差别不大。
综合表5至表8,以及表4中气体与分类目标的相关程度,在尽量剔除相关性较小的气体仍能取得较高分类准确率的情况下,选取正常-故障层、发热-放电和发热层的Z值为2,放电层的Z值为3,并通过GridSearch方法,对分类器中参数进行确定对各诊断层所需分类器及特征气体和准确度总结如表9所示。

表9 各诊断层分类器及特征气体Tab.9 Classifiers and feature gases at each diagnosis level
结合图1与表9,分层诊断最终模型如图3所示。
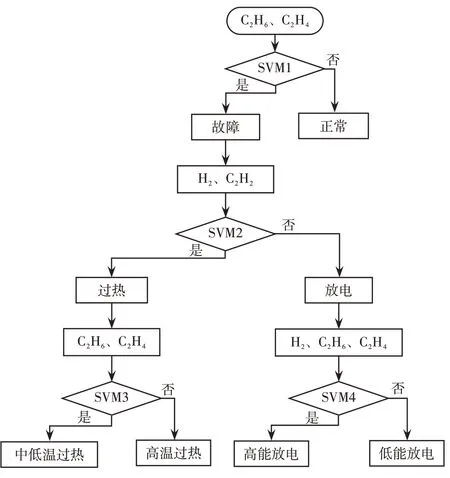
图3 基于SVM与特征选择的诊断模型Fig.3 Diagnosis model based on SVM and feature selection
模型利用C2H6和C2H4特征气体,通过正常-故障层诊断,将样本分为故障和正常状态,有故障的样本则进入发热-放电层的SVM分类器,利用H2、C2H2进行判断,结果为发热故障或放电故障。若为发热故障,则进入发热层,利用C2H6、C2H4判断,将故障进一步细分为中低温过热和高温过热;若为放电故障,则进入放电层,利用H2、C2H6、C2H4判断,将故障进一步细分为高能放电和低能放电。这样每个层次单独判断,都只需要实现简单的二分类,减少了重叠问题,有利于提高变压器故障诊断的正确判断概率。
采用上文所述数据集,将全部特征气体输入分类器并对中低温过热、高温过热、低能放电、高能放电、正常5种运行状态直接进行分类,同样在Sklearn0.2中使用SVM、NB、RF、DT、LR等5种分类器,并对SVM使用网格寻优,采用“留一法”进行交叉验证,所得到各分类器的综合准确率如表10所示。

表10 未选择特征气体分类准确率Tab.10 Accuracy of classification without selecting feature gases
结合表10和表9可看出,采用全部5种气体,利用单一分类器直接以每种运行状态为分类目标进行分类,所得到的分类效果低于经特征选择后的分层故障诊断模型。
4 结论
本文引入卡方检验对特征气体进行选择,并将其运用到分层故障诊断模型中。通过多种机器学习分类器对不同特征气体的组合进行分析,得到不同诊断层的最优分类器和特征气体组合,总结出如下结论:
(1)利用卡方检验能有效地剔除和分类目标相关性较低的气体,降低特征气体的冗余度,可作为变压器特征气体选择的依据;
(2)采用分层故障诊断模型,在不同诊断层应用不同分类器以及不同特征气体数量进行分析,得出在每个层应用自动调参后的SVM分类器时准确度最高。
所得到的分类效果优于采用单一分类器对多种运行状态直接进行分类。
