抑郁障碍高危人群特质测验中面部运动表情特征提取与识别
2022-08-01李志博卢思萌王加俊
李志博,卢思萌,王加俊,黄 申,张 昀
(1苏州大学电子信息学院电子信息工程系,江苏 苏州 215006; 2火箭军工程大学政治系,陕西 西安 710025; 3西安交通大学电信学部信息与通信工程学院,陕西 西安 710049)
世界卫生组织预测,抑郁症将成为全球范围内引起死亡和残疾的第二大疾病[1]。抑郁症严重影响了军人的身心健康和战斗力的生成。因此,通过心理测量,实现对抑郁障碍高危人群的早期筛查,对于抑郁症的预防具有很重要的意义。而这里的抑郁障碍高危人群是指具有抑郁易感人格特质[2],但尚未完全符合第五版《精神障碍和诊断手册》(DSM-5)[3]诊断标准的人群。
心理测量可以反映认知、情感、意识、技能、兴趣、动机等个人特征,既可用于筛查抑郁症、自闭症等心理疾病,也可用于性格测试、职业评估等。但传统的心理测量手段,如观察法、访谈法、问卷法、实验法、心理物理法等[4],容易受到主观因素的影响。一方面,测量结果取决于心理医师的专业素养;另一方面,由于无法记录被试在筛查中的客观情感状态,测量结果容易受被试情绪、掩饰等因素干扰[5]。近些年,随着生物神经科学的发展,人脸[6]、眼动[7]等客观生理信息特征在精神障碍筛查中的研究备受关注。
在诸多的生理信息特征中,面部表情的变化是最直观的,且与情绪障碍密切相关。抑郁症患者的面部表情存在明显与悲伤有关的特征:嘴角下拉、眉头紧皱、皱纹加深、眼睛经常哭的红肿等[1]。现有的文献中报道了不少面部表情的测量方法,例如VERMA等[8]通过对区域容积差函数的量化来测量高维人脸形变,并对面部表情进行分类,生成临床打分。WANG等[9]提出了一种全自动方法,通过对每帧视频的愉快、痛苦、愤怒、恐惧以及中性等情绪状态的概率似然值的量化,来对视频中的人脸表情进行分析。HAMM等[10]发展了一种先进的自动人脸运动编码系统,利用几何和纹理特征实现对面部标记的定位,从而分析视频中精神障碍患者面部运动的动态变化,帮助实现对患者的诊断。
虽然当前利用面部特征对包括抑郁症在内的精神障碍人群进行筛查的研究众多[6],但是利用面部特征对抑郁障碍高危人群进行识别的研究则鲜有涉及。与文献[6]中以六种基本情绪的短视频片段为刺激材料,对被试面部视频的采集与心理测量分开进行不同,本文以心理测量量表本身为刺激材料,在进行心理测量的同时采集被试面部视频数据,通过对被试在心理测量过程中面部数据的分析,实现对抑郁障碍高危人群的辅助心理测量。
1 方法与实验
1.1 方法
1.1.1 面部运动单元及其检测 EKMAN等[11]提出人脸运动编码系统,该系统对特定人脸肌肉的运动(称为面部运动单元,action unit,AU)进行编码,反映了面部外观上不同的瞬时变化。表1给出了常用的AU及其意义。这些AU及其不同的组合可以反映一个人的情绪特征,进而反映个体的心理状态和特质。目前,已经存在非常多的基于AU特征的精神障碍类人群筛查研究,例如GAVRILESCU等[6]通过建立AU的强度特征矩阵,并利用前馈神经网络来预测抑郁、焦虑和压力水平,HAMM等[10]通过AU在一段时间内的发生频次来对精神障碍类人群进行研究等。受此启发,本研究从AU出发,对面部特征进行深入的研究,发展基于面部特征的抑郁障碍高危人群的检测算法。

表1 常用的AU及其意义
为了利用运动单元对抑郁障碍高危人群进行检测,本研究借助开源人脸识别工具OpenFace2对表情采集处理系统记录的视频进行面部标记和AU识别[12]。该工具首先对人脸地标进行检测,然后分别提取人脸外观特征和几何特征,并利用支持向量机(support vector machine, SVM)对AU进行分类,或者利用支持向量回归(support vector regression, SVR)对AU强度进行回归处理。最终会生成表1中的18种AU及其对应的强度值。本研究利用OpenFace2共检测出17种AU(除去AU28)的强度变化,AU的采样时间为0.101 s。
1.1.2 AU特征提取与抑郁障碍高危识别 针对每一个被试,借助于OpenFace2可以得到被试在心理测试过程中17个AU的原始时间序列。去除原始序列中与量表无关的部分AU 序列(量表准备时的AU 序列、回答每道条目之前的校准AU 序列等),就可以得到被试相应于量表所有条目的17个AU的时间序列。由于AU的时间序列中信息冗余,本文通过离散余弦变换(discrete cosine transform,DCT)[13]将AU的时间序列转换到频域,使得大部分信息集中在少数低频系数上,从而降低特征的维数,提高特征的表征能力。设f(i)(i=0, 1, …,N-1)为AU时间序列,则其离散余弦变换为:
(1)
k=0, 1, …,N-1
其中,k为频率,F(k)是频谱系数,N为AU序列的采样点数,c(k)为补偿系数,使DCT的变换矩阵为正交矩阵。本文以式(2)给出的能量谱为基础,构造抑郁障碍高危人群的分类模型:
zk=F2(k)
k=0, 1, …,N-1
(2)
其中,zk为频率点k处的能量谱。
需要指出的是,由于每个被试完成每个条目所需的时间不同,在相同的采样频率下所得到的AU时序序列长度也不同。因此,为了使得频谱具有相同的频率分辨率,需要进行时域补零,保证样本的时域序列长度相等。考虑到造成每个被试的AU时间序列长度不同的原因是不同被试回答量表每道条目所用的时间不等,用时较短的被试在完成相应的条目后就离开了量表刺激这个测试环境,处于没有任何刺激的静息态,所以本文通过补零来使不同被试的AU时序序列长度相同。有多种补零策略可供选择,一种是对每一条目的AU序列进行补零,使每一个被试在每一条目上的序列长度相等;另一种策略是将所有的条目结合在一起进行补零,使所有被试在整个心理测试期间的AU序列长度相等。前者会使得AU序列的长度大大增加,而后者虽然使得AU序列的长度大大缩短,但是无法分析量表每个维度特征的分类性能。所以,本文采用一种折中的做法,按照维度进行补零操作,也就是说使得每个被试相应于每个维度的AU序列长度相等。图1给出了某一被试的AU01的时间序列及其频谱。在进行DCT变换后,AU01的能量多集中在低频。鉴于此,本文筛选出各个维度下40%的低频AU能量作为最终的特征。
为了均衡各个特征分量对分类器的贡献,首先对上述频域特征进行归一化处理:
(3)

x=Azn
(4)


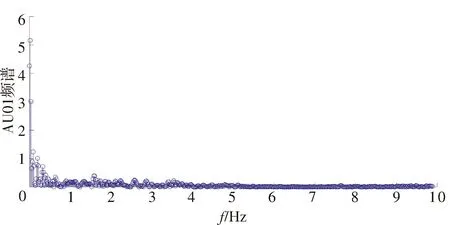
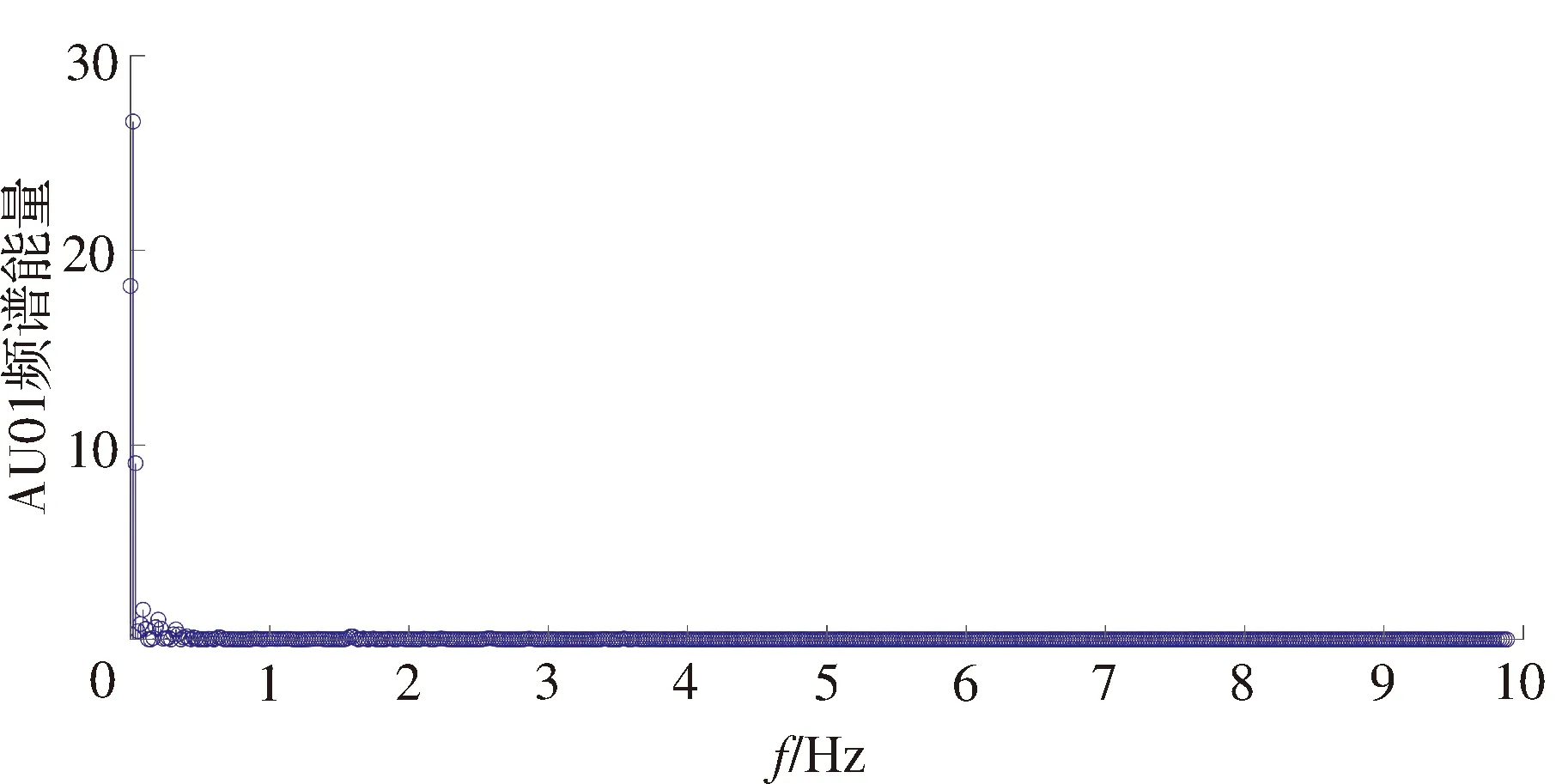
AU:面部运动单元。图1 AU01样例图
本研究利用SVM[15]对以特征向量x为描述子的两类人群(健康人群和抑郁障碍高危人群)进行分类:
(5)
其中,xl为测试集中第l个被试的特征向量,xj为训练集中第j个被试的特征向量,αj为拉格朗日乘子,可以通过训练得到,b是分类阈值,K(xl,xj)为SVM的核函数,这里选用线性核函数:
(6)
为了进一步提高分类模型的性能,本文结合SVM分类器,对上述特征向量x的各分量进行特征选择,算法如下:
算法1:基于支持向量机的特征选择与模型训练算法。
输入:所有样本的特征向量集Px={x1,x2, …,xns},所有样本的标签Plb={y1,y2, …,yns},ns为样本个数,L为特征向量长度。
输出: 最优分类模型αopt,最优准确率ACopt,最优特征索引集Iopt。
初始化: 特征索引集I=[1, 2, 3…,L],单个模型的准确率AC=0,最优模型准确率ACopt=0,Iopt=I。
划分:将Px划分为训练集Xtr=[x1,x2,…,xntr]T和测试集Xte=[x1,x2, …,xnte]T,Plb划分为训练集标签Ytr=[y1,y2, …,yntr]T和测试集标签Yte=[y1,y2, …,ynte]T,其中ntr是训练集的样本个数,nte为测试集的样本个数。
开始:
当I≠φ时,执行循环:
利用训练集训练SVM模型:α=SVM-train(Xtr,ytr);
利用测试集评估SVM模型,得出模型在测试集中的准确率AC;
根据特征打分准则ci=(wi)2对每个特征进行打分;
更新训练集与测试集中的特征:Xtr=Xtr(:,I),Xte=Xte(:,I)。
若AC>ACopt,则
AC→ACopt;
α→αopt;
I→Iopt。
输出:最优模型αopt,准确率ACopt,特征索引集Iopt。
结束。
1.2 实验
1.2.1 实验材料 本研究选用空军军医大学研制的 “抑郁障碍高危人群特质筛查量表”(Scale for High-Risk Population Trait of depressive disorder,SHPTDD)[16]进行抑郁障碍高危人群的检测。该量表共包含62道条目,分为悲观消极、缺乏自信、急躁忧虑、自责自罪、敏感退让、心态脆弱共6个维度。这一量表经过了长达三年的测试,验证了其良好的可信度(状态量表和特质量表的Krumbach指数分别为0.956和0.962)。
1.2.2 实验对象 利用SHPTDD在某部队开展普测,共计519人参加普测。采用随机对照的方法,将被试按SHPTDD得分和心理学专家访谈结果分为抑郁障碍高危组和健康对照组。
高危组:共16人,年龄19~32(平均22.71±4.24)岁,教育背景分别为高中、大专和本科。入组标准:①SHPTDD评分高于平均分数两个标准差(19.98±5.36);②抑郁自评量表(Self-Rating Depression Scale,SDS)评分未达到抑郁标准(SDS<50分);③经心理学专家访谈确定为抑郁障碍高危人群。
对照组:选取在同样测试条件下SHPTDD与SDS得分均正常且无精神障碍家族史18人,年龄19~32(平均23.36±3.62)岁,教育背景分别为中专、高中、大专和本科,SHPTDD得分13.14±3.21。
1.2.3 人脸数据采集 如前所述,本研究以SHPTDD为刺激材料,利用SciEye系列TM300设备[17](数据处理采用 SciOne开放API接口[18])采集被试完成量表答题时的面部表情数据。该系统利用计算机进行心理测试,将SHPTDD导入到计算机中,系统自动将量表中的条目逐项呈现给被试。系统利用键盘按键记录被试的回答选项,利用摄像头记录被试的人脸视频数据。
1.2.4 性能指标 本研究利用以下三个性能指标对算法的性能进行评估[6]:
①准确率(accuracy, AC):
(7)
②特异度(specificity, SP): 被模型正确预测的真阴性样本个数与模型应当预测为其阴性的所有样本个数之比。
(8)
③灵敏度(sensitivity, SE):被模型正确预测的真阳性样本个数与模型应当预测为真阳性的所有样本个数之比。
(9)
其中,TP、TN、FN、FP分别表示真阳性、真阴性、假阴性、假阳性的样例数,显然,TP+FP+TN+FN=被测样本总数。
2 结果
2.1 两类人群频域特征的差异性分析
为了探究频域AU特征的抑郁障碍高危表征能力,本文首先对两类人群(抑郁障碍高危人群和健康人群)在量表所有条目下的AU频域特征差异性进行了统计显著性分析。在分析的过程中,分别求取高危人群和健康人群的每个AU在对应频率下的频域特征的均值,得到均值向量,然后利用非参数t检验(不满足正态分布)对两类人群在每个频率成分对应的17种AU能量均值特征的差异显著性进行分析,以P<0.05为有显著统计学差异(图2)。结果显示,两类人群的AU能量特征的差异主要集中在低频部分。这为本研究提取低频能量来构建特征提供了理论依据。
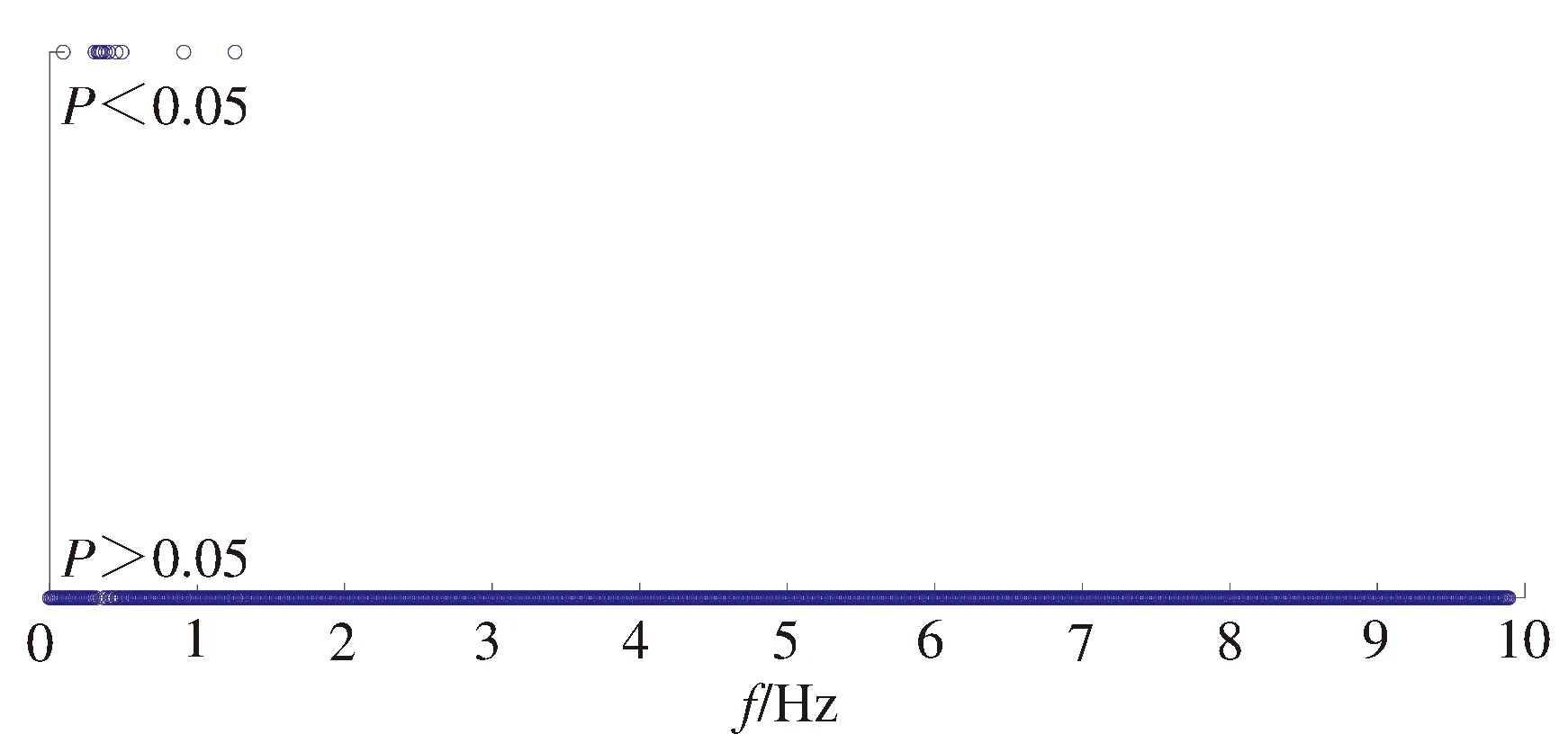
图2 频域特征差异显著性分析结果
2.2 两类人群分类识别的结果分析
本研究在提取各个AU的低频能量特征后,分别对特征集进行归一化以及PCA降维处理。在进行PCA时,将处理后的特征维数降至原来特征维数的10%以下,保证特征维数不大于训练集样本的个数。经过对比实验,各个维度下模型取得最优分类性能的特征维数见表2。结果显示,PCA降维后,特征维数相比初始维数大大减少,这为避免分类器训练中的“维数灾难”问题,提高分类器的泛化能力提供了可能。

表2 特征集在PCA降维前后的大小 (n=34)
利用算法1对PCA降维后的特征集进行特征选择和模型训练,采用五折交叉验证的方法,最终得出各个维度下抑郁障碍高危人群识别模型的平均AC、SP以及SE。表3分别给出了算法利用各维度上的面部特征以及全部条目上的面部特征数据建模并进行五折交叉验证后在五个交叉验证模型上的AC、SP、SE的均值和标偏差。
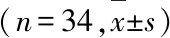
表3 不同量表条目维度下的模型分类识别结果
当利用不同维度的面部运动特征数据进行建模时,其模型的分类性能各不相同(表3)。在各维度中,“悲观消极”这个维度上模型的SE最高,但是SP较低,在“自罪自责”维度上,模型的AC在所有维度上最高,达到0.80,SP和SE均较高,如果利用量表所有条目下的面部特征进行建模,其在SE(0.90)、SP(0.87)、AC(0.88)上均高于其他单个维度的模型。说明量表各个维度的刺激,对抑郁障碍高危人群的检出均有贡献。比较各维度模型性能的标准偏差,可以发现它们的标准偏差普遍大于所有条目下的分类模型。
为了验证AU时序补零策略的合理性,本文使用双三次插值算法将所有AU序列补足至相同长度进行建模,在所有条目上,当原始特征维数降至23时SVM模型取得最优性能:AC为0.85±0.16,SP为0.86±0.20,SE为0.88±0.14,其结果略差于补零策略,从实验上说明了本文补零策略的合理性。为了说明本文算法的优越性,还尝试了利用K-近邻、决策树、随机森林等算法,在所有量表条目下,对经过PCA降维的特征向量进行了建模,其分类性能如表4所示。
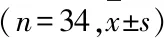
表4 量表所有条目下不同分类模型的性能比较
K-近邻算法的特征维数为25,近邻数为13;决策树算法的特征维数取23;随机森林的特征维数取27。
结果显示,随机森林表现要优于K-近邻和决策树,但劣于本文所提算法。为了进一步说明本文算法的优越性,表4中列出了前馈神经网络分类器对所有条目下的面部运动特征进行建模的分类性能[6]。由于本研究所用的视频采集系统的采样率约为10帧/s(文献[6]中为30帧/s),所以这里将与量表相关的10帧视频的AU堆叠成长度为170(17个AU)的特征向量作为神经网络的输入。由于本研究只有两类人群,所以输出为两个神经元,分别代表判定为两类人群的概率。为了方便比较,也将样本按被试分成五份,其中四份训练一份测试,进行交叉验证。在训练时,将训练集中与量表相关的视频切分成10帧/组,与其对应的标签(健康或抑郁障碍高危)构成训练样本集,对神经网络进行训练。在测试的时候,在被试的视频中截取5段10帧的视频,分别送到训练好的神经网络,进行判别。如果5段视频的判别结果相同则视为判别成功。为了获得被试最后的判决结果,对同一被试在所有5段视频上的判决结果进行投票,多数票对应的判决结果为该被试的判决结果。表4的结果同样说明,本文算法的分类性能要优于文献[6]的前馈神经网络模型。
3 讨论
从系统分析的角度看,每一个被试都是一个复杂的系统。心理测量的过程就是一个系统辨识的过程,其中量表就是这个系统的激励,而被试对量表中每一个条目的回答就是系统的响应。正如前文指出的那样,一方面,由于被试的诚实度等问题,这一响应缺乏相应的印证,导致心理医生对被试进行系统辨识的结果存在一定的不确定性;另一方面,由于受心理医生专业素养的影响,其进行系统辨识的能力也存在着差异,对被试进行心理辨识的结果也存在主观性。正是鉴于此,本文采集被试的面部运动特征,利用计算机自动进行辅助心理测量,使得其结果能和心理医生的心理测量的结果相互印证,从而提高心理测量的可靠性。
本研究和现有的一些利用面部运动特征进行心理检测的方法相比存在很大的区别:首先本文紧扣心理测量过程,以心理测量量表作为刺激材料,在传统心理测量的同时采集面部视频数据、提取面部运动特征并分类。而现有的一些方法,例如文献[6]中,被试的刺激材料为代表不同情绪的视频片段。由于情感问卷以及自分析问卷是在视频刺激完成以后进行的,所以该方法所采集的被试面部视频不能反映被试在完成问卷时的心理状态,因而也就无法窥探被试在回答问卷时的诚实度;其次,量表刺激是心理学家经过大量的理论和实验研究得出的结果,其科学性、系统性要高于简单的视频刺激;最后,心理测量是一个完整的过程,心理医生通过利用量表不同条目对被试的刺激,测量被试的心理特质和状态。因此,理论上讲应该直接对心理测量过程中所记录的完整面部视频进行分析建模。但是由于数据量巨大,会给数据分析带来很大的困难。为此,文献[6]利用前馈神经网络对被试面部视频片段进行建模并实现心理测量。但是这种思路破坏了心理测量的完整性,因为它只利用了被试部分面部视频片段进行判别,而这些视频片段不能完整地表征被试的特性,所以模型性能比较差,这与本文只利用部分维度的视频进行判别、模型性能较差的现象是一致的。为了利用完整的面部视频数据进行分析建模,本文通过离散余弦变换将AU的时间序列转换到频域,使得AU所包含的信息集中于少数低频的特征上,从而大大减少数据量(本文仅抽取了40%的低频特征)。通过PCA去除特征间的相关性并进一步降低特征的维数。利用特征选择算法挑选出极少数具有较强分辨能力的特征构建相应的分类模型,取得了较高的分类性能。本文之所以选择SVM分类器进行建模,一方面是考虑到SVM特别适合于对小样本进行建模,另一方面利用该方法可以很方便地实现封装型特征选择。本实验也验证了该分类器相对于K-近邻、决策树、随机森林等分类器的优势。
但是,本研究也存在一些缺点。本研究给出的结果是五折交叉验证的结果,由不同训练集得到的分类器在测试集上的分类性能存在较大的差异(标准偏差比较大),主要原因是本文用到的样本较少,多样性不够,所以该方法还需要在大样本集上进行训练测试。今后的工作可以从以下几个方面进行改进:首先,在处理AU时序序列的时候,由于不同被试答题的时间不一样,所以AU时序序列的长度不一样,为此本文直接进行了补零操作,这势必会使得分类性能受AU时序长度的影响,为了避免补零操作,考虑采用多层长短期记忆网络,将输入序列映射成固定长度的向量;其次,本文利用了简单的离散余弦变换以及PCA来提取特征,在样本数增加的前提下,未来将考虑采用卷积自编码器来提取更加鲁棒和紧凑的特征,提高分类器性能。
