基于DNA变异的中国汉族人群脱发表型推断及预测模型评估*
2022-07-25薛思瑶李彩霞贠克明赵雯婷
薛思瑶 李彩霞 贠克明 丛 斌 赵雯婷**
(1)山西医科大学法医学院,太原 030001;2)公安部物证鉴定中心,现场物证溯源技术国家工程实验室,法医遗传学公安部重点实验室,北京 100038;3)河北医科大学法医学院,石家庄 050017)
脱发问题是近年来社会各界关注的热点问题,尤其在中青年人群中的发病率一直居高不下,对患者的心理、生活社交造成明显影响。人类最常见的脱发形式是男性型脱发(male pattern baldness,MPB),其特点是头皮上依赖雄激素的进行性脱发表现。MPB 严重程度与年龄、脱发部位等密切相关,发病率随年龄以平均每10 年提高10%的增速增长[1],其在欧洲男性中的患病率很高,可达到80%[2],而一项针对3 519 名上海男性脱发情况的研究显示脱发患病率在19.9%左右[3]。有多项研究表明,与高加索人相比,中国人、日本人和非裔美国人的患病率较低[4]。
人群遗传学研究显示,MPB 是一种高度遗传的多基因疾病[5]。早期针对双胞胎的研究表明[6],MPB 的遗传力约为81%;Liu 等[7]基于单核苷酸多态性(single nucleotide polymorphisms,SNPs)常见变异的分子遗传学方法估计MPB 的遗传力可达50%。近年来,随着基因分型技术和DNA 测序技术的快速发展,尤其是全基因组关联分析(genome-wide association study,GWAS)的应用,MPB 的遗传学研究取得了突破性进展,欧洲人群GWAS 研究发现的MPB 显著关联SNP 位点已达1 000 个以上。比如,2017 年针对8 个独立的欧洲血统人群队列22 518 个样本的荟萃分析[8]确定了63 个MPB 显著关联位点(6 个位于X 染色体上,57个位于常染色体上),同时揭示了脱发不是孤立的特征,而是可与许多其他人类表型具有相关性的,例如前列腺癌和神经退行性疾病等。迄今人群规模最大的MPB 遗传分析来自2018 年Ⅴisscher等[9]对UK Biobank 205 327 个欧洲男性的研究,通过GWAS 关联出了624 个近独立的位点(598 个位于常染色体上,26个位于X染色体上)。同年一项针对7 万欧洲人群的GWAS 研究关联出了71 个独立遗传位点[10],可解释总遗传力的38%。可见,MPB 虽然是多基因复杂表型,但与身高等表型相比,可以用相对较少的SNP 来解释较大比例的遗传力。因此,通过SNP 位点建立准确性较高的MPB遗传预测模型是可行的。
已有的MPB 遗传预测模型大多采用了逻辑回归算法。Hagenaars等[11]使用287个SNP位点建立多元逻辑回归模型,重度脱发的AUC(ROC 曲线下方的面积大小,area under curve)为0.78,但轻度脱发和中度脱发的AUC仅能达到0.68 和0.61。Liu 等[7]针对2 725 个德国和荷兰男性的研究尝试建立了25 个SNP 的逻辑回归模型,AUC=0.74。Marcińska等[12]使用305个50岁及以上的欧洲人群样本构建了20 个SNP 的模型,对脱发的遗传解释力为35%,AUC=0.86。
与欧洲人群MPB 的遗传预测研究相比,针对中国人群的研究报道相对较少。在本实验室的前期研究中,潘思宇等[13]针对中国的欧亚混合人群建立了两种MPB 预测模型,一种以年龄、BMⅠ和25个SNP为预测因子,AUC=0.82;另一种是以年龄、BMⅠ和68 个SNP 为预测因子,AUC=0.89。这两种预测模型虽然展现出良好性能,但在仅将年龄作为预测因子的情况下AUC值就可以达到0.77。可见该模型年龄依赖性过强,SNP的独立预测能力有待提高。
本研究选取了近十余年发表的关于MPB 研究的16 篇文献中486 个欧洲人群关联SNP 位点[7-8,10-12,14-24],在312名中国汉族人群样本中进行关联验证分析,并基于筛选后的具有显著关联性的SNP位点建立了MPB逻辑回归预测模型,同时对k近邻分类器(k-nearest neighbor classifier)、随机森林(random forest)、支持向量机(support vector machine,SⅤM)等常见的分类器模型[25]在MPB遗传预测中的性能进行了比对评估,力求找到MPB预测准确性最高的建模方法。
1 材料与方法
1.1 男性型脱发表型的获取及分类标准
Hamilton-Norwood(H-N)脱发分级标准[1]根据发际线后移程度以及头顶部毛发稀疏程度将MPB划分为不脱发(Ⅰ类)、6种MPB主类型(ⅠⅠ至ⅤⅠⅠ类)和5 种亚类型(ⅠⅠA 至ⅤA 以及ⅠⅠⅠvertex)。参照该标准,本研究将表型分为两组(图1):a.MPB 表型组,即头顶部可见明显脱发且发际线严重后移(Ⅳ、Ⅳa、Ⅴ、Ⅴa、Ⅵ和Ⅶ);b.对照表型组,即完全没有脱发或轻微发际线后移(Ⅰ和Ⅱ)。表型读取时,由3名评分者同时观看照片,并独立对每一位志愿者的MPB 等级进行评级,排除表型判断有困难的样本,以3个评分者对每个志愿者分级结果的众数作为最终的MPB等级。
1.2 样本及DNA提取
按照1.1的表型分组标准,本研究共收集了中国不同地域的汉族男性个体312 例,除7 例样本为南方汉族(四川6、江西1)外,其余均为北方汉族(山东4、山西296、河南5)群体,其中MPB表型组143 例,对照表型组169 例,且所有研究个体无内分泌功能障碍类疾病、未接受过毛发相关治疗。考虑到年龄因素对MPB的影响[12],MPB表型组年龄在28~69岁之间,平均年龄约53,而对照表型组选取了高龄不脱发的志愿者,年龄在55 岁以上,平均年龄59 岁左右。详细组内信息和外观概览见表1 和图1。使用Canon EOS 5D Mark ⅠⅠ(佳能,日本)高清照相机分别采集志愿者头部左侧、正面及右侧3张二维照片。本研究通过公安部物证鉴定中心伦理委员会审查,所有参与者均签署了书面知情同意书。
1.3 基因分型及质量控制
使用Ⅰllumina HiSeq X Ten测序平台(Ⅰllumina,美国)对样本进行3X 低深度全基因组测序,每个样本得到平均10G Raw data。对经过变异检测(variant calling)处理后的数据,使用本实验室中国人群低深度测序2 510 份样本进行基因填补。使用PLⅠNK v1.9[26]对SNP进行质量控制,包括分型成功率(call rate)>0.97,哈迪温伯格平衡(Hardy-Weinberg equilibrium,HWE)P>0.000 1和次等位基因频率(minor allele frequency,MAF)>0.01。个体样本质量控制包括性别检查,亲缘关系检测及杂合性判断。以千人基因组数据第三阶段(1000 Genomes Project Phase 3)数据作为参考基因组,使用ⅠMPUTE[27]对常染色体进行基因填补并过滤填补质量分数小于0.6 的SNP,并再次重复上面质量控制标准,最终共获得20 681 872个SNP位点。

Table 1 Sample information
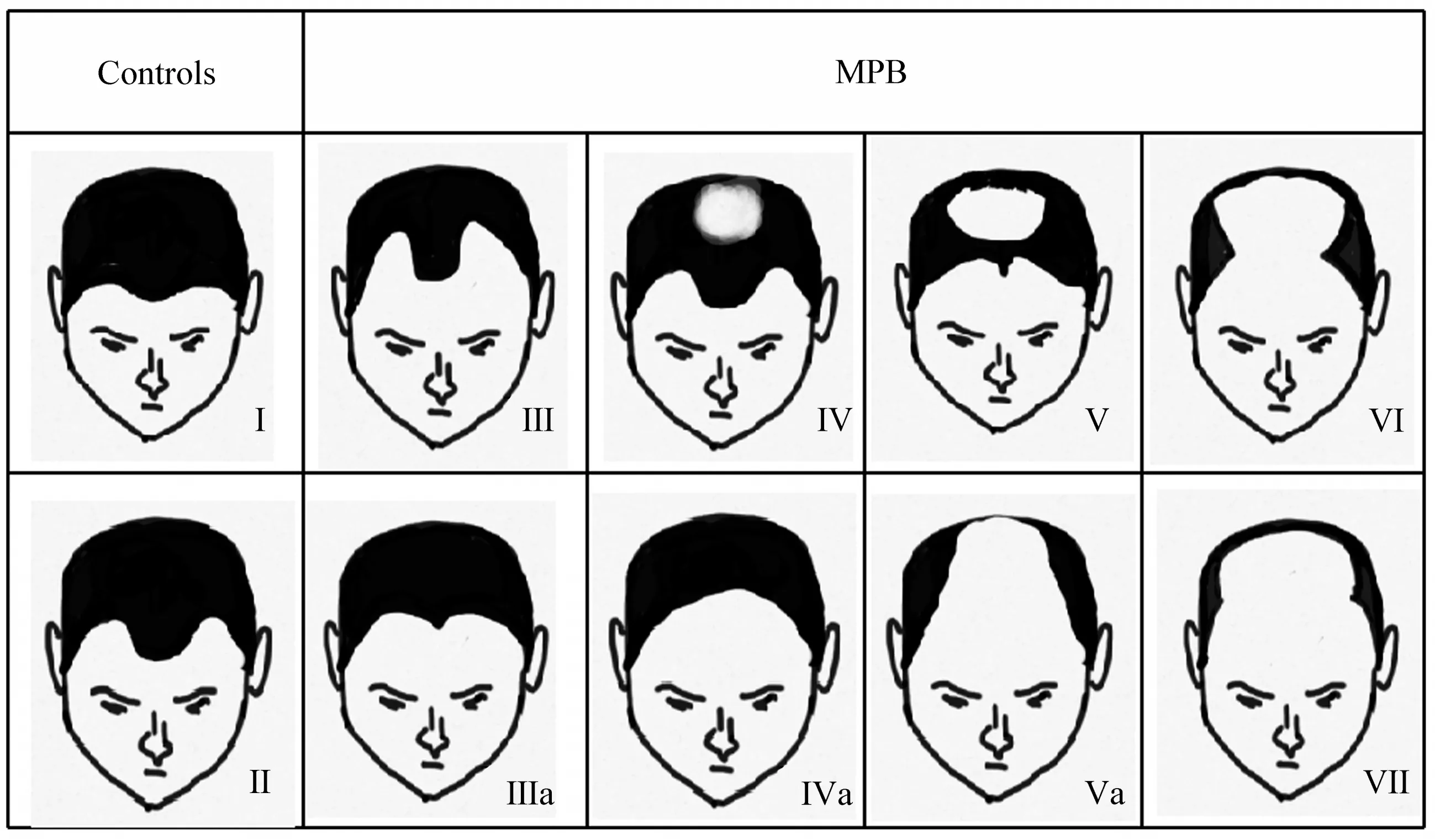
Fig.1 Diagram of MPB
1.4 统计分析
1.4.1 遗传关联分析
本研究选用基于欧洲人群关联出的486个SNP位点,均通过了质量控制,详细位点信息见附件表S1。使用Plink v1.9 软件(哈佛大学,波士顿,马萨诸塞州,美国) 分别进行了一般线性回归(general linear model,GLM)和二元逻辑回归分析,测试486 个SNP 与MPB 的相关性。基因型的赋值为加性模型,假设个体携带的次等位基因的数量与表型特征有累积效应。估计了所有SNP 的优势比(odds ratio,OR)、相应的95%可信区间(confidence interval,CⅠ)和P值。将P<0.05 认为在关联分析中具有统计学意义。同时通过将所获得的OR与OR=1 时相比,从而估计脱发风险增加倍数。使用wANNOⅤAR[28]对与MPB 相关性最高的前20 个SNP 进行相关基因区域识别。多重假设检验校正后没有达到显著关联性的位点,故而在本研究中没有应用多重假设检验的校正。
1.4.2 预测建模
将在关联分析中具有统计学意义的SNP 位点作为建立预测模型的初始位点集合。首先对数据进行预处理,先将因变量的编码分为“1”(MPB 表型)和“0”(对照表型),再依据次要等位基因数目对SNP基因型进行编码:具有2个次要等位基因编码为“2”,只有1 个次要等位基因编码为“1”,不含次要等位基因编码为“0”。然后,采用两种方法对位点进行筛选,一种是基于R 软件STEP 函数对AⅠC信息标准进行逐步分析,另一种是通过R软件glmnet包建立Lasso回归模型,从而对SNP预测因子进行最终选择和排序。
逻辑回归适用于二值响应变量(即0和1),故选用二元逻辑回归对预测模型进行训练。模型假设因变量服从二项分布,模型的拟合形式为:
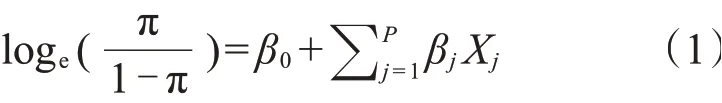

由于本研究样本量较小,采用十折交叉验证法来防止过度拟合。将MPB 的预测概率与观察到的MPB状态进行比较,将AUC作为预测准确性的总体衡量标准。AUC值的范围从0.5 到1.0,0.5 表示随机预测,1.0 表示完全准确的预测。如果预测概率>0.5,则定义受试者为MPB,否则为不脱发。使用混淆矩阵比较预测和观察的脱发状态,并得出灵敏度和特异值,两者的范围都在0 到1 之间。所有候选SNP 分析和预测分析都在R v4.0.2(http://www.r-project.org/)中进行。
1.4.3 多模型对比评估
在R 软件中分别对k 近邻分类器、随机森林、支持向量机3 种机器学习算法进行建模-验证,获得不同模型的预测准确性从而对比模型的预测性能。建模过程中使用的R 包主要包括class 包、kknn 包、randomForest 包、e1027 包等。每种机器学习算法共运行10 次,求其平均值。对于二分类任务,可将验证样本的真实情况作为金标准,对所有验证样本的模型分类结果和金标准结果分别计数,从而获得分类器性能混淆矩阵。分别计算模型的正确率、敏感度、特异度、阳性预测值、阴性预测值以及五折交叉验证的预测准确性。以上分类器性能衡量标准的取值范围均为0~1,值越大,表示分类性能越高。
2 结果与分析
2.1 遗传关联分析结果
通过对312 个样本的486 个SNP 进行关联分析,发现174 个SNP 与MPB 显著相关,相关性最显著的20 个见表2。在与MPB 相关的SNP 中,位于chr20 上的位点最多,有145 个,chr5 和chr6 上各有6个SNP,chr1上有4个SNP,chr9和chr10上各 有3 个SNP,chr2 上 有2 个SNP,chr3、chr7、chr8、chr15、chr19 上各有1 个SNP。与前20 个显著位点有关的基因分别为EBF1、TFAP2C、PAX1以 及RUNX3。位 于EBF1 的rs17643057 在chr5 上的分布具有最高的统计学意义(逻辑回归关联分析OR=0.479,95%CI=0.321~0.714,P=3.42×10-4)。值得注意的是,当应用一般线性回归关联分析时,前9个SNP的显著性更高。据估计,携带rs985546-C等位基因的男性患MPB 的风险是携带T 等位基因男性的3.4 倍。从OR来看,其余3 个与MPB 易感性 相 关 最 显 著 的SNP 是rs17643057-G (chr5)、rs1422798-G(chr5)和rs6113382-A(Chr20),使MPB的风险分别增加2.1、2.0和1.9倍。
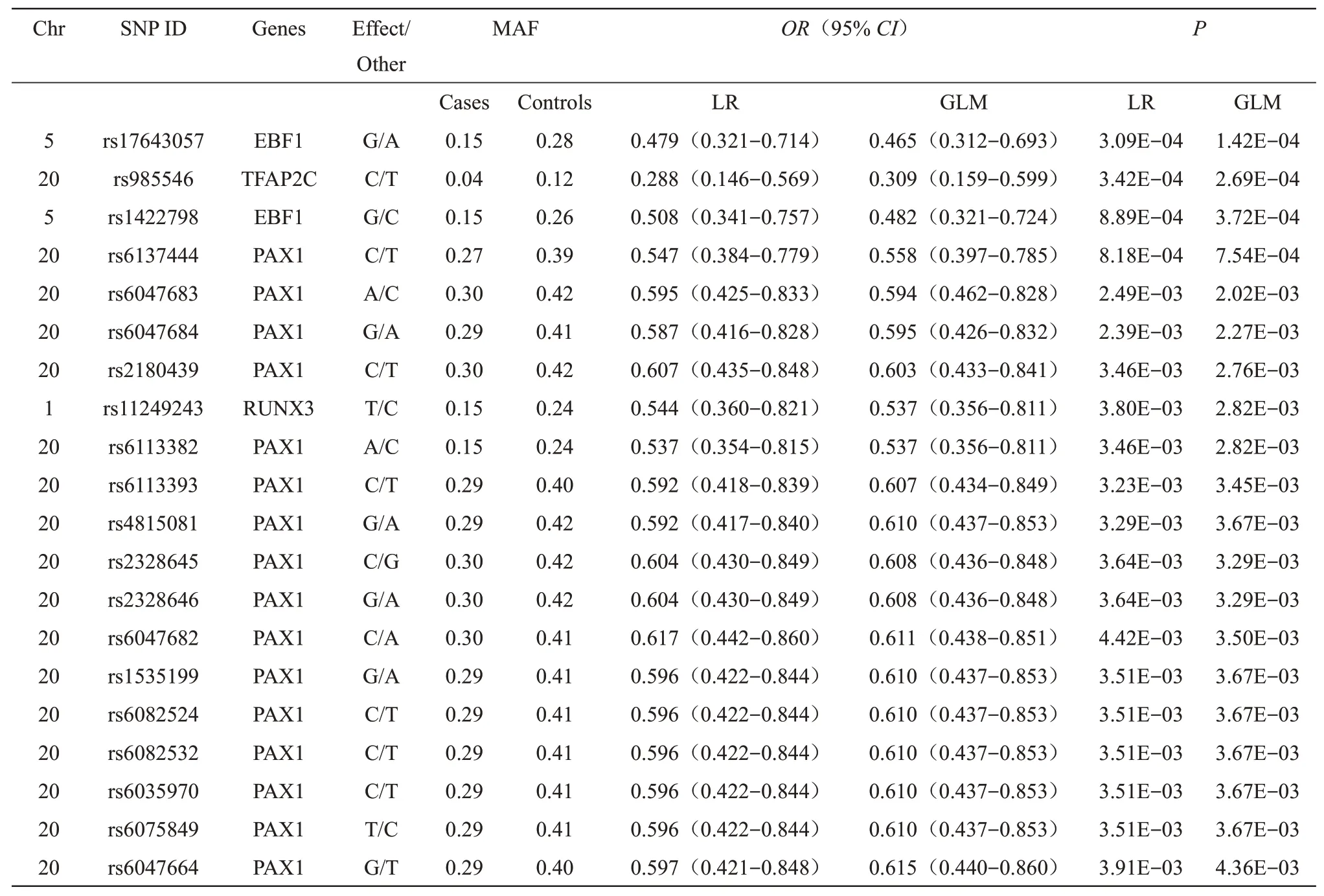
Table 2 Top 20 SNPs most significantly associated with MPB in Han Chinese (P<0.05)
2.2 位点筛选
逐步回归不仅可以从备选因子中筛选出最终预测变量,还可以防止模型过度拟合。本研究通过双向逐步回归的方法,根据提前设定的赤池信息准则(Akaike information criterion,AⅠC),将直接纳入模型的174 个MPB 相关SNP 精简至22 个SNP 用于下游预测模型的建立。此时的AIC达到最小值,跨度区间为322.38~305.81(图2)。每一预测因子的方差膨胀系数(variance inflation factor,ⅤⅠF)均小于10,不存在多重共线性问题。
Lasso 回归基于惩罚系数λ对备选因子进行筛选,随着惩罚系数λ的增大,模型回归系数β逐渐趋近于0,最终变为0(图3a,b)。图3a 左侧虚线对应使模型估计误差最小的λ,右侧虚线对应使模型估计误差在可接受范围内的λ,根据最高效原则确定纳入模型的最优变量组合,最终筛选出25 个SNP位点。
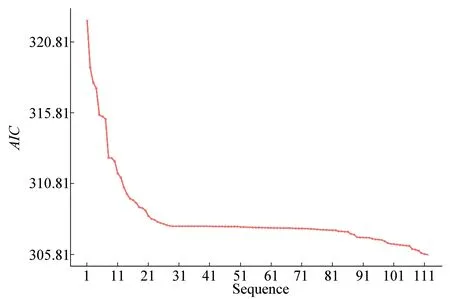
Fig.2 Characteristic variable screening based on stepwise regression
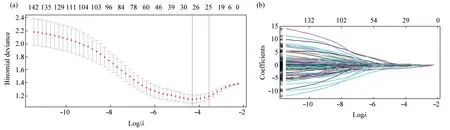
Fig.3 Characteristic variable screening based on Lasso regression
2.3 预测模型
根据上述筛选得到的两种位点集合,建立了两个预测模型。两模型所包含位点信息见表3,详细位点信息见附件表S2。
第一个模型包括通过逐步回归分析筛选出的22 个SNP,该模型解释了患MPB 总风险的48%(R2=0.48)。第二个模型包括通过Lasso回归筛选出的25 个SNP,该模型解释了患MPB 总风险的45%(R2=0.45)。MPB 预测模型具有总体预测精度,区分度指标分别为AUC=0.85 和AUC=0.84,ROC 曲线见图4。应用50%的概率阈值,22-SNP 预测模型正确预测的总数为76%(236/309),有3 个不确定结果。然而,65%的概率阈值的正确预测降低到75%(234/311),有1 个不确定结果。同样,应用50%的概率阈值,25-SNP 预测模型正确预测的总数为74%(228/309),有3 个不确定结果。而65%的概率阈值的正确预测保持不变,仍为74%(226/307),有5个不确定结果。两模型均通过十折交叉验证的方法进行验证,验证后的AUC分别为0.81和0.77。在加入年龄作为预测因子之一后,预测准确性分别提升到了80%(251/312)和81%(252/312),没有不确定结果。相比较而言,通过Lasso回归筛选出来的位点在十折交叉验证过程中AUC有一定程度的下滑,且有个别位点存在多重共线性问题。22-SNP预测模型和25-SNP预测模型在18个SNP 上相同,仅存在4~7 个位点差异,但22-SNP预测模型在各项指标上均优于25-SNP 预测模型。在加入年龄作为预测因子后,两模型的预测准确率等各指标均有提升, 整体表现AUC均为0.89(表4)。
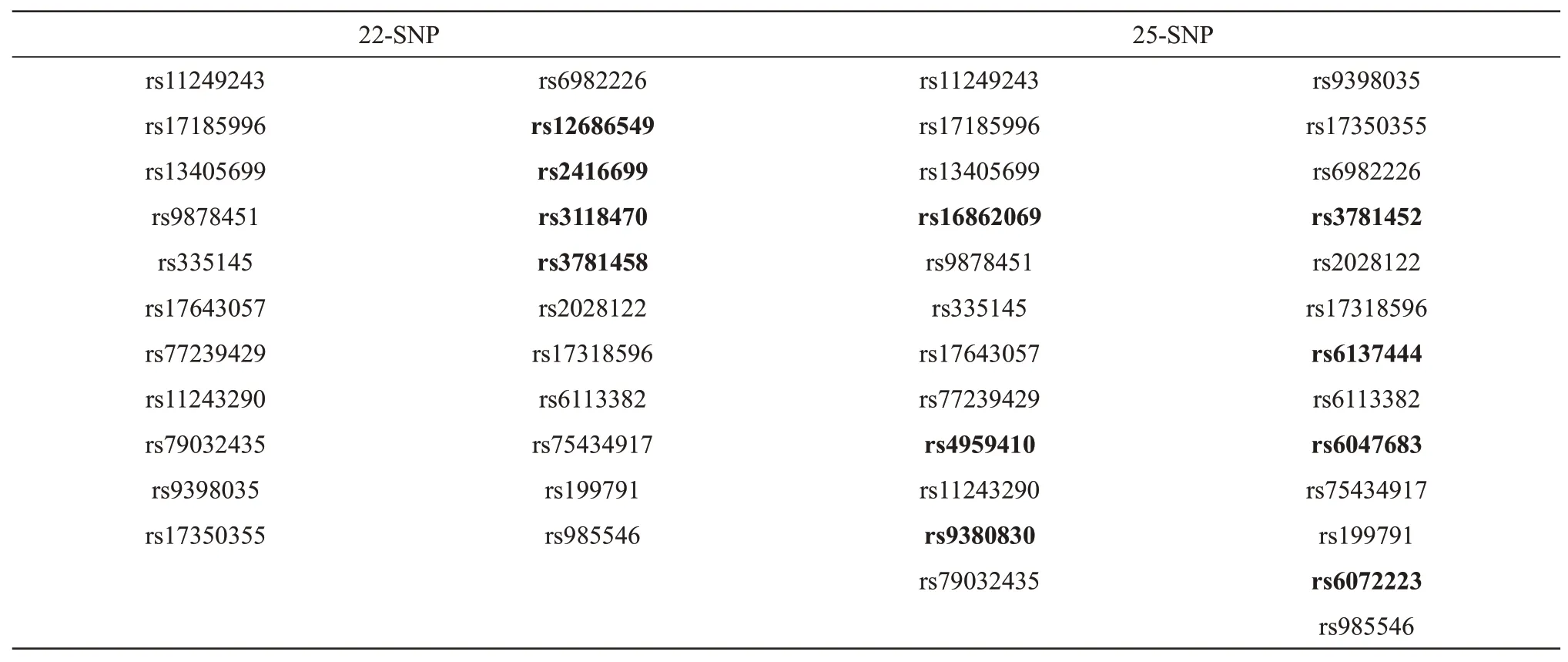
Table 3 Information of 22-and 25-SNP used in predictive model building
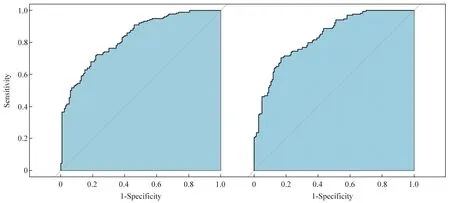
Fig.4 Receiver operating characteristic(ROC)curves for 22-SNP(left)and 25-SNP(right)MPB prediction models The ROC curves have sensitivity as the ordinate.

Table 4 Prediction performance for MPB with different SNP-sets and factors
2.4 分类器模型性能评估
通过混淆矩阵获得的分类器模型性能评价见表5。在3 种分类器模型中,最高的准确率是基于22-SNP 的支持向量机分类器模型,但也仅能到达68%,其预测效能和预测准确性远不如逻辑回归模型。
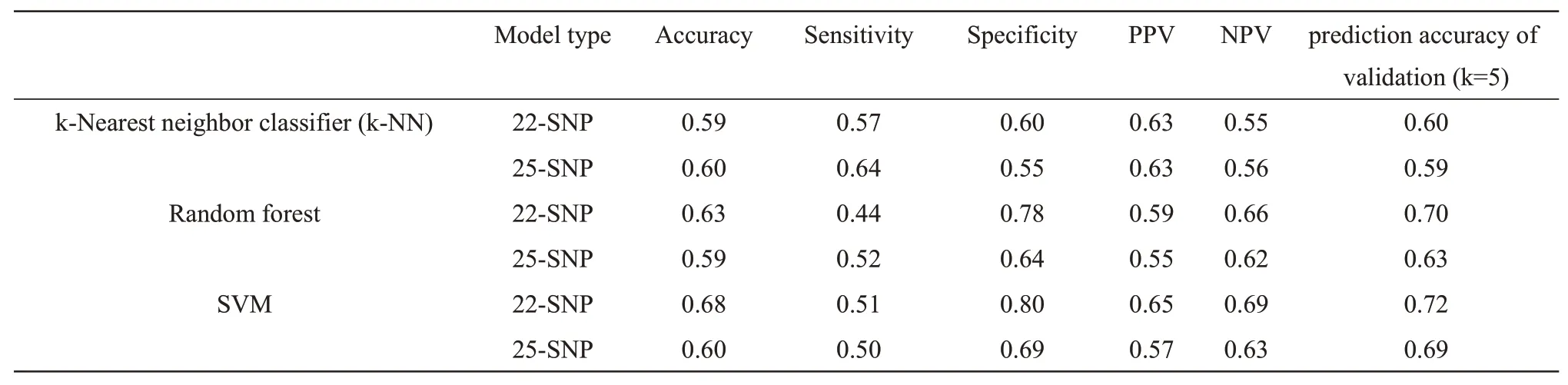
Table 5 Performance comparison of k-NN,random forest and SVM for MPB prediction
3 讨 论
本研究首次在中国汉族人群中进行较为系统的MPB 相关位点验证分析,并初步筛选出与中国人群MPB 表型相关的SNP 位点,同时构建出性能较高的非年龄依赖MPB预测模型。
从关联分析结果来看,chr20 上的多个SNP 与MPB具有强关联性,这说明chr20不仅是欧洲人群MPB的主要危险区域[29],也是中国汉族人群MPB的主要危险区域,这提示了在不同祖源人群中MPB 可能存在相似的遗传机制。本研究中关联性最显著的SNP位点(rs17643057)所在基因区域已被欧洲研究证实与毛发生长特征有关[8],受早期B细胞因子1(early B cell factor 1,EBF1)调控。EBF1 是早期B 细胞发育和脂肪形成所必需的转录因子,动物研究表明其在小鼠成熟、生长的毛囊中表达。除EBF1外,在本研究前20个显著关联位点中,有75% 以上位点与PAX1 (paired Box 1,PAX1)这一基因区域有关。PAX1在皮肤、头发和头皮中表达,是典型的MPB易感位点[17,29]。这提示了将PAX1 作为中国汉族人群MPB 候选基因的必要性。值得一提的是,本研究关联出的显著位点(rs2180439)在另一项基于中国汉族人群的研究中[14]同样被证实与脱发显著相关,效应方向与本研究一致,超过了统计意义的关联阈值(P≤3.13×10-3)。对于那些关联性较低的SNP,本文暂时无法验证SNP 是否与MPB 存在真实关联,需要进一步扩大样本量来提升结果的准确性。
为了进一步优化MPB 相关SNP 位点集合以建立预测模型,本研究采用了两种不同的位点筛选方法,并获得22-SNP和25-SNP两组位点集合。这样做的目的一方面是为了比较两种位点筛选办法所获得的SNP 对模型的预测性能所造成的差异,另一方面是为了防止模型过度拟合。若模型过度拟合,其在外部验证中的表现就会变差。在仅使用SNP作为预测因子的情况下,基于22-SNP和25-SNP脱发的二分类预测模型均表现出了良好的性能。在加入年龄作为预测因子后,模型的预测性虽有小幅提升,但不能排除在高龄对照样本的影响下,年龄所产生的虚假相关性。在实验室前期研究成果中,不加入年龄作为预测因子的前提下,模型AUC低于0.7[13]。说明本研究所采用的表型组、对照组样本筛选方法,显著降低了年龄对关联结果的影响,筛选出的位点对表型的影响效力更强,所解释的遗传力度相较前期研究的不足30%也有显著提升。
已有的MPB预测模型大多基于逻辑回归算法,本研究进一步探索了不同分类器模型对MPB 表型的预测性能。从逻辑回归、k近邻分类器、随机森林、SⅤM 这4 种常用分类器模型在本研究人群的运行结果来看,逻辑回归模型具有明显优势。
4 结 论
本研究通过将欧洲人群MPB 关联位点在中国人群的验证分析,为了解中国汉族人群MPB 的遗传机制奠定了基础。同时,所构建的预测模型,能够在不依赖年龄作为预测因子的条件下,达到较为优良的预测性能。在后续的研究工作中,通过扩大样本量、采用全基因组关联分析、引入表观遗传分析等方法,有望得到更优的MPB 相关遗传位点集合,建立更为精准的MPB 预测模型,应用到临床医学诊断和法庭科学领域中。
附件PⅠBB_20210329_S1.pdf 见本文网络版(http://www.pibb.ac.cn或http://www.cnki.net)。