基于DRL的无人机辅助边缘计算服务质量优化
2022-07-22敬乐天贾向东曹肖攀万妮妮殷家祥
敬乐天 贾向东,2 曹肖攀 万妮妮 殷家祥
(1.西北师范大学计算机科学与工程学院,甘肃兰州 730070;2.南京邮电大学江苏省无线通信重点实验室,江苏南京 210003;3.中电万维信息技术有限责任公司中电万维研究院,甘肃兰州 730030)
1 引言
随着物联网技术的快速发展,移动设备在人们生活中的应用呈爆炸式增长,其需要处理的任务例如虚拟现实或物联网应用程序等需要大量的计算资源。而移动边缘计算(Mobile Edge Computing,MEC)用于在网络边缘卸载任务,它的应用可以有效减轻用户的负担,更好地为用户提供服务[1]。随着MEC的发展,人们提出了许多方法来提高计算性能,尽管开发了地面MEC 系统架构,但仍然存在未解决的问题,如服务器移动性较差和安全性问题等,因此出现了无人机(Unmanned Aerial Vehicle,UAV)辅助MEC来解决这些问题[2]。
从用户的角度来看,MEC 中最大的缺点是用户的服务质量(Quality of Service,QoS)难以保证[3]。在UAV 辅助MEC 系统中,文献[4]在满足物联网设备QoS 的前提下,提出了一种高效的迭代算法联合优化系统中的资源分配和UAV 的悬停时间,以最大限度地减少UAV 的能耗。文献[5]在UAV 电量和QoS 约束下,使用整数规划和连续凸优化方法优化了用户级联方案、UAV 轨迹和用户传输功率,以在UAV 辅助MEC 系统中最大化卸载任务总和。然而,传统的方法如迭代算法和凸优化等,往往需要大量的迭代计算,且不能找到关键问题的最优解,这导致了UAV 辅助MEC 系统中的优化方法往往“缺乏智能”。随着AI技术的不断发展,越来越多的智能方法被用来解决UAV 辅助MEC 系统中的优化问题。文献[6]中提出了一种基于Q 学习的智能资源分配算法,该算法能够使UAV 在保证用户QoS 的情况下智能地做出资源分配决策,同时最大限度的减少总资源消耗。在实际的MEC网络中,用户数量往往较多且网络环境相对复杂,这会使得状态、动作空间的个数随着用户数量的增加而增加,在维度较大的Q 表中寻找最优策略会变得困难,因此Q 学习算法往往变得不再适用。由于控制决策和资源优化的优势,深度强化学习(Deep Reinforcement Learning,DRL)被广泛认为是解决问题的理想工具,通过DRL 代理能够学习网络环境,这有利于代理更准确的做出控制决策,此外,DRL 由于通过集成强化学习提高了处理速度,因此DRL 更适用于大规模网络[7]。文献[8]中提出了一种基于DRL 的方案,在UAV 能量有限的情况下实现了最大化用户吞吐量,一定程度上提高了MEC 的QoS。文献[9]在考虑地面用户移动性的情况下为了保证用户的QoS,提出了一种基于DRL的算法,使得能量有限的UAV 能够根据用户位置的动态规划其飞行轨迹以提高系统的总吞吐量,然而文献[8-9]提出的UAV辅助MEC 系统中,UAV 的飞行高度固定不变导致其只能在固定高度飞行,不能够很好的发挥UAV 的优势。
为了衡量更新信息的新鲜度,信息年龄(Age of Information,AoI)最近已成为衡量QoS 性能指标的新维度[10]。文献[11]在MEC 系统中研究了如何调度一组数据包的传输和计算来最小化平均AoI。文献[12]研究了MEC 系统中计算密集型数据的AoI,并考虑了两种计算方案:本地计算和MEC服务器远程计算,导出了本地和远程计算的平均AoI,并给出了远程计算优于本地计算的区域。文献[13]结合AoI 提出一种任务新鲜度的度量方法,且根据任务新鲜度进一步引入一种新的QoS 评价指标,提出了基于DRL 的算法来优化MEC 系统中的QoS。然而,文献[11-13]只是考虑了传统地面MEC 系统中信息的新鲜度,并没有考虑UAV 辅助MEC 系统中信息的新鲜度。
基于以上讨论,本文引入文献[13]中任务新鲜度的度量方法,用任务延迟来表示任务新鲜度,提出一种新的QoS 计算方法,研究使用基于DRL 的方法来提高UAV 辅助MEC 系统中用户的QoS。首先分析了UAV 辅助MEC 系统中的任务延迟并给出了QoS 优化问题表达式,其次,将最大化QoS 的问题建模为一个无转移概率的马尔可夫决策过程(Markov Decision Process,MDP),并定义了该过程中UAV 的状态空间、动作空间和奖励函数;最后UAV 利用强化学习在线学习和深度神经网络线下训练不断与环境进行交互来寻找最优飞行轨迹以及卸载方案为地面用户进行服务以提高QoS。仿真结果表明所提算法有效提高了UAV 为地面用户服务过程中的QoS且提高了任务新鲜度。
2 系统模型
如图1所示,本文考虑了由K个地面用户和单个UAV所组成的UAV辅助MEC系统。其中,K个地面用户随机分布在地面上的一个区域内,第k(k∈{1,2,…,K})个地面用户的位置为wk=(xk,yk)。地面用户的可以将计算任务进行本地执行,也可以将计算任务卸载到空中的UAV 令其上面的移动边缘服务器(Mobile Edge Server,MES)执行。UAV 整个飞行过程中所需时隙总数为N,在第n(n∈{1,2,…,N})个时隙中根据第k个地面用户的任务卸载指示onk来判断任务的执行方式,其中onk∈O≜{0,1},当onk=0 时,第k个地面用户将计算任务本地执行,当onk=1时,第k个地面用户将计算任务卸载到UAV 上执行。第n个时隙中第k个地面用户产生的任务数量Unk随机,每个任务的比特数固定为Nb,且在时隙n内卸载到UAV 上的任务遵循先来先服务(First Come First Service,FCFS)原则。在任务密集型的场景中,UAV 在一个时隙内需要处理来自地面用户卸载的任务,在此时隙内UAV在空中悬停来接收并完成任务,最后将计算结果返回给它所服务的地面用户,然后在下一个时隙飞往下一个位置继续为地面用户提供服务。
在水平方位上,假设UAV 在大小相同的I个空中单元上飞行,I个单元中心坐标的集合为相邻两个单元在X轴和Y轴方向上的距离分别为xd和yd。L0为UAV 在水平方位上的初始位置,Ln为UAV 在第n个时隙所处的单元的水平位置,因此UAV 在整个飞行过程中水平方位上的轨迹为{L0,L1,…,Ln,…,LN}。在垂直方位上,UAV 最小和最大飞行高度分别为Hmin和Hmax,假设UAV 可以在J个不同的高度飞行,J个不同高度的集合为G≜{G1,…,Gj,…,GJ},其中G1=Hmin且GJ=Hmax,连续两个不同高度在Z轴方向上的距离为UAV 的初始高度设为H0,第n个时隙的高度为Hn,因此UAV在整个飞行过程中垂直方位的高度为{H0,H1,…,Hn,…,HN}。假设UAV初始位置为F0=(L0,H0),在第n个时隙时所处空中位置为Fn=(Ln,Hn),则UAV 在整个飞行过程中的轨迹为{F0,F1,…,Fn,…,FN}。
在第n个时隙内UAV 到第k个地面用户到之间的距离为:
考虑到UAV 具有较高的飞行高度,假设UAV和地面用户之间可以建模为视距链路(Line of Sight,LoS),因此在第n个时隙内UAV 到第k个地面用户之间的信道增益为[14]:
其中β0为UAV 与用户之间距离为1 m 时的信道功率增益。
因此,第n个时隙内UAV 和第k个地面用户之间的数据传输速率为:
其中B为无线信道的带宽,pk为第k个地面用户的发射功率,σ2为加性高斯白噪声功率。
3 任务延迟及QoS分析
本节首先定义了任务延迟来表示任务新鲜度,其中,任务延迟越低,任务新鲜度越高。在任务延迟的基础上,进一步引入了一种新的QoS评价指标,并给出了优化问题表达式及相关约束条件。
3.1 任务延迟分析
在进行计算卸载时,时间延迟是指卸载数据到MEC 计算节点的传输时间、在MEC 计算节点处的执行处理时间、接收来自MEC计算节点处理的数据结果的传输时间三者之和[3]。由于计算结果的大小远小于原始任务,因此计算结果返回时间可以忽略不计[15]。
本文中在第n个时隙内,如果第k个地面用户需要将任务卸载到UAV 上进行处理即onk=1 时,UAV计算完成所有任务需要三部分延迟:
其中bnk为第n个时隙内第k个地面用户卸载任务的比特数,且bnk=UnkNb。
卸载到UAV 的任务遵循FCFS 处理原则,每次只能处理一个地面用户卸载的任务,因此卸载的任务所需的排队等待延迟为任务开始处理时间减去任务到达时间。
其中,C为计算每一比特任务所需的CPU 周期数,fu为UAV上MES的处理能力[17]。
本文将第n个时隙内第k个地面用户产生任务延迟定义为:
其中,当onk=0时,表示第k个地面用户本地执行计算任务,因此将任务延迟记为零。由上面的式子可以看出,任务延迟由三个因素决定,前两种主要取决于用户生成任务的数量,而第三种会受到任务卸载策略、服务器处理能力及信道条件等多方面的影响。如果地面用户卸载到UAV 的任务数量增加,任务的通信延迟和处理延迟会增加,由于服务器处理能力有限,且地面用户与UAV 距离改变导致的信道传输速率的改变会使得排队等待延迟也增加,因此,所有延迟的增加将导致完成任务需要耗费更多的时间,可以看出定义的任务延迟能够很好地涵盖对QoS产生主要影响的延迟因素。
综上所述,第n个时隙内所有地面用户产生任务的任务总延迟为:
3.2 QoS分析
当地面用户设备上运行如网络游戏、视频会议、虚拟现实等计算密集型和时间敏感型应用时,UAV 需要为一片区域内的多个地面用户提供服务,因此需要在较短的时间内处理大量地面用户设备卸载的任务以提升地面用户的QoS。
根据以上任务延迟的定义,进一步引入了一种新的QoS 评价指标。将第n个时隙内的QoS 定义为UAV所处理的任务的比特数与任务延迟之比[13]:
本文将此QoS 作为优化目标,力求在短时间内处理大量的任务,所以目标优化问题可以表述为:
其中,(9.1)、(9.2)、(9.3)为UAV 在水平范围和垂直范围飞行的空间约束,(9.4)为UAV 在每个时隙内最低服务要求约束,Dmin为UAV 在每个时隙内最少需要处理任务的比特数,(9.5)为任务卸载约束,保证任务只能被地面用户本地执行或者卸载到UAV上的MES执行。在下一节中,将提出一种基于DRL的QoS优化方案来解决问题(9)。
4 基于DRL的QoS优化方案
本节首先介绍强化学习中MDP的基本要素,然后提出了基于DDQN的QoS最大化算法。
4.1 MDP基本要素
MDP 是一种对代理与动态环境交互过程进行数学建模的方法。在本文场景中,UAV 不需要任何关于环境的先验信息,只能从环境状态中获取因果信息,所以模型中转移概率是未知的,因此本文把UAV 最大化QoS 的过程建模为一个无转移概率的MDP,且它是无模型的。基于模型的DRL 算法需要花费很长的时间来得到精确的模型,特别是在状态动作空间很大的情况下,而无模型的DRL 算法与基于模型的DRL 算法相比不需要精确的MDP 模型[18]。下面依次对MDP 的三要素,即状态空间、动作空间和奖励函数分别进行定义。
(a)状态空间:
UAV 在第n个时隙内的状态为它的位置,因此,UAV在第n个时隙的状态sn为:
其中S为UAV的状态空间。
(b)动作空间:
第n个时隙内,水平方向上UAV 可以向东、西、南、北四个方向飞行,也可以在水平方向上保持不动,假设ln∈L ≜{E,W,S,N,I}为UAV 在第n个时隙水平方向的飞行动作,其中E,W,S,N 分别表示向东、西、南、北方向飞行,I 表示在水平方向上保持不动,因此UAV 在第n个时隙水平方向上的位置可以表示为[19]:
在垂直方向上,UAV 可以上升、下降,也可以保持高度不变,假设hn∈H ≜{A,D,I}为UAV 在第n个时隙垂直方向的飞行动作,其中A,D 分别表示在垂直方向上和向下飞行,I 表示在垂直方向上保持高度不变,因此第n个时隙内UAV 在垂直方向上的动作为:
此外,UAV 的动作还包括地面用户的卸载指示onk,因此UAV在第n个时隙内的动作an为:
其中A为UAV的动作空间。
(c)奖励函数:
UAV 为地面用户执行卸载的任务时,需要获得一定的奖励,以提高地面用户的QoS 并引导UAV 更好地服务,因此将奖励函数设置为地面用户的QoS,在第n个时隙内的奖励函数Rn具体定义如下:
同时,每个时隙内如果UAV 超过规定的飞行空间,奖励Rn会减去一个定值Rp以对UAV 做出相应的惩罚。
4.2 基于DDQN的QoS最大化算法
和基于深度Q 网络(Deep Q Network,DQN)算法中的神经网络一样,本文所提基于双深度Q 网络(Double DQN,DDQN)的QoS 最大化算法中构建了两个结构完全相同但是参数不同的网络:当前值网络和目标值网络。其中当前值网络的参数实时进行更新,而目标值网络的参数每隔一段时间进行更新,这样可以增加训练过程的稳定性。同时加入回放记忆单元来解决数据关联性问题,把每个时间段UAV 与环境交互得到的记忆存储到回放记忆单元中,训练时随机拿出一部分样本来训练。算法中需要损失函数L(θ)来更新当前值网络的参数,将其定义为:
其中θ-表示目标值网络的参数,γ为折扣因子。可以看出在计算过程中采用的是这意味着会出现过高估计的问题,为了解决DQN 中可能存在的过高估计问题,在DDQN 中,采用了新的方式计算目标值网络输出,即利用当前值网络估计目标值网络中使得Q(sn+1,a;θ-)最大的动作值:
最后,根据计算的损失函数L(θ),使用梯度下降反向更新当前值网络参数θ。
在基于DDQN 算法中,Q值的更新满足贝尔曼方程:
其中α表示学习率,用来控制Q值更新的速度。
图2为所提算法的框架图,其主要由环境、回放记忆单元、当前值网络、目标值网络和损失函数五大模块构成。算法运行时首先初始化回放记忆单元,将状态s输入当前值网络,并使用ε-贪婪策略进行动作选择。本文所提算法中使用的ε-贪婪策略与一般的ε-贪婪策略不同,算法中为ε设置一个递减值,在算法刚开始时,将ε值设置较大,随着算法不断进行,代理学习的越来越好,逐渐减小ε的值,以减少随机选取动作的概率,这样使得学习的过程更加稳定。在选择了动作a之后,在状态s下执行所选的动作,进入到新状态s′,并接收奖励R;然后把记忆
本文所提出的基于DDQN 的QoS最大化算法流程如算法1所示。
算法1基于DDQN的QoS最大化算法
输入UAV初始位置
输出一个飞行周期内使得地面用户QoS最大的UAV飞行轨迹
5 仿真结果及分析
仿真考虑了在地面1000 m × 1000 m 范围内存在6个地面用户的模型,使用Python3.7和TensorFlow框架对UAV 的飞行轨迹及卸载方案进行了仿真,其中,算法的迭代次数为70 次,UAV 在每次迭代中总时隙数为400,其他参数设置如表1 所示。此外,将基于DQN 的QoS 最大化算法和传统的旅行商问题(Traveling Salesman Problem,TSP)算法作为对比实验进行分析。TSP 算法中,UAV 在飞行过程中采取随机服务的方案,即每个时隙中随机选取地面用户并为其提供计算服务,且在飞行过程中UAV 的高度固定为200 m。
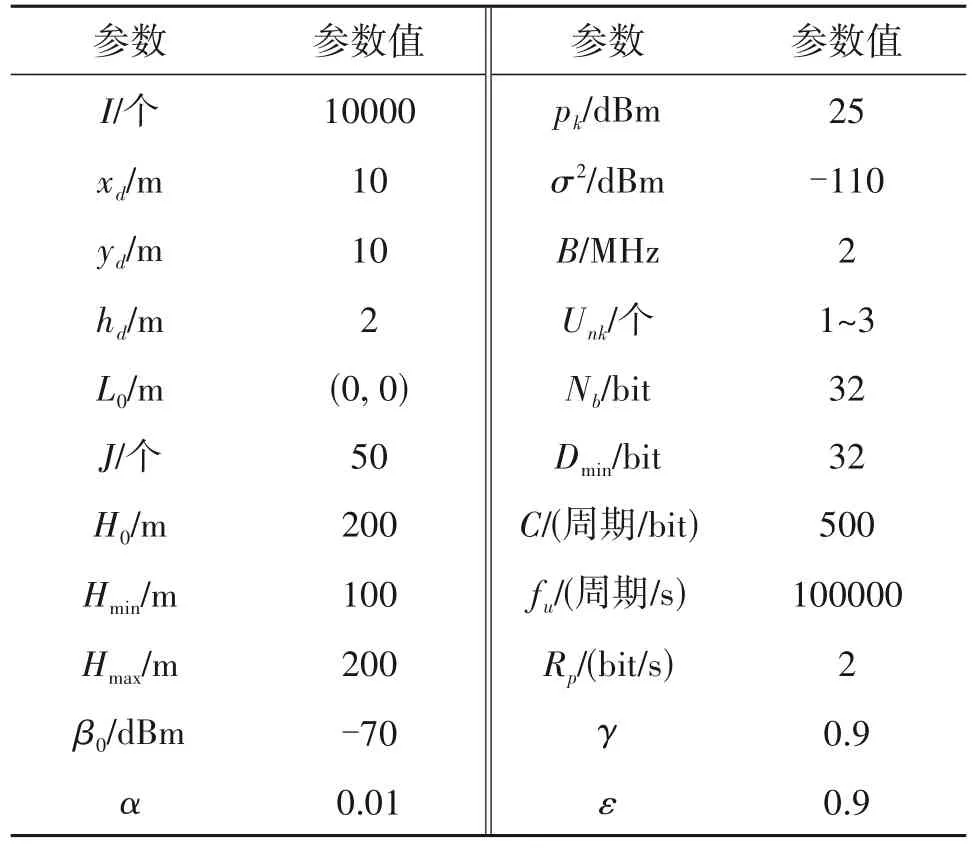
表1 仿真参数Tab.1 Simulation parameters
图3、图4分别为三种不同算法下UAV二维和三维飞行轨迹对比图。由图3可以看出,在水平方向上,采用TSP算法的UAV从起点出发,选取最短路径飞行并为地面用户提供计算服务,而采用本文所提算法时UAV则采取接近于TSP算法的飞行轨迹为地面用户提供服务,对比之下,基于DQN的算法下UAV很大程度上偏离最短飞行轨迹。由图4可以看出,本文所提算法下UAV在垂直方向上能够自适应的调整其飞行高度,这意味着UAV 能够更加接近地面用户来减少服务过程中的延迟,更有效地提高地面用户的QoS。
图5 为不同算法下UAV 在后30 次迭代中地面用户的平均QoS对比图,可以看出在开始的时隙中,由于距离地面用户较远,地面用户的QoS较小,随着UAV 继续飞行靠近地面用户并学习到更优的卸载方案,地面用户的QoS 逐步增加,相比于基于DQN的算法和传统的TSP 算法,本文所提算法能够有效提高地面用户的QoS。
图6 为不同算法下任务总延迟对比,基于DQN和基于DDQN 的算法在开始时需要不断的学习来适应环境,因此在开始的迭代中,两种算法下地面用户所需处理任务的总延迟较高,在不断地学习后,任务总延迟趋于平稳。而TSP 算法由于不需要进行学习网络环境,因此TSP 算法下的任务总延迟始终保持较为平稳的值。可以看出,在一定迭代次数的学习之后,本文所提算法下地面用户所需要处理任务的总延迟明显低于其他两种算法,所提算法能够很好的提高地面用户所需处理任务的新鲜度。
图7为基于DQN算法和基于DDQN算法的Q值对比,可以看出在刚开始的时隙中,由于需要学习新的环境,因此两种算法的Q值不断增加,之后趋于稳定,且相比于所提算法,基于DQN 算法拥有较高的Q值,这与4.2节中的分析吻合,并进一步证明了所提算法能够有效解决基于DQN 算法中出现的过高估计的问题,使得UAV 能够更好的学习寻找最优飞行轨迹以及卸载方案为地面用户提供服务。
6 结论
在UAV 辅助MEC系统中,基于DRL研究了UAV 搭载MES为地面用户进行服务时的QoS。本文最后给出了所提算法与其他两种算法的对比,仿真结果表明所提算法可以优化UAV 的飞行轨迹以及卸载方案,并有效提高UAV 为地面用户服务过程中的QoS且提高所需处理任务的新鲜度。下一步将在考虑地面用户移动性的基础上,研究多UAV 辅助MEC系统中的服务安全问题。
