面向压缩图像复原的网络增强训练方法
2022-07-22廖理心韦世奎
廖理心 赵 耀 韦世奎
(1.北京交通大学信息科学研究所,北京 100044;2.现代信息科学与网络技术北京市重点实验室,北京 100044)
1 引言
近年来,深卷积神经网络的快速发展,极大地促进了计算机视觉相关任务的发展。深度卷积神经网络成功的关键因素之一是高质量的数据。在机器学习领域,高质量的数据产生高质量的模型。例如,ImageNet 大规模图像数据集,该高质量图像数据集包含了100 多万张图像和相应的注释,极大地促进了深度学习的发展。高质量的数据不仅意味着高质量的标注,而且指代着数据本身的质量。在学术领域,常用的图像数据集多数是由从互联网上抓取的图像组成。这些数据集的图像通常以JPEG 格式存储,与原始图像相比,不可避免地丢失了一些信息。在没有额外数据的情况下,研究人员在相应数据集上的竞争是公平的。这种方式也确实促进了深度卷积神经网络的发展。然而,这其实使得研究者们忽略了压缩图像对于卷积神经网络的影响。
图像压缩不可避免地在一定程度上造成图像质量的下降,因此研究增强图像质量、降低压缩效应的工作伴随着图像压缩的诞生而出现。这类方法主要可以分为基于重建的方法和基于学习的方法。基于重建的方法综合利用压缩图像和特定的一些先验知识来重建原始图像。中科院计算所的张等人[1]提出利用已知的量化系数和非局部块的平均变换系数来预测每个压缩块的变换系数,进而通过重建增强图像。此外,为了降低图像压缩效应,许多工作选择融合图像空间域信息和频率域信息来重建图像。研究者[2-3]提出了各种各样的滤波器在频率域去处理压缩图像的特定区域,例如边缘、纹理和平滑区域等。研究者首先将压缩图像从空间域转换到频率域,在频率域中处理变换系数。一旦优化得到变换系数,研究者再将其再反变换到空间域重建图像。除了基于重建的方法,研究者们也提出了基于学习的方法来增强图像质量,降低压缩效应。在深度学习之前,基于稀疏编码的方法[4-6]和基于回归树的方法[7]是学界的研究热点。研究者[7]在前人工作基础上进一步利用一个回归树模型进行了全局优化,达到了当时图像增强的最好效果。ARCNN[8]是第一个将卷积神经网络应用到降低图像压缩效应的工作,极大地提升了JPEG 压缩图像的增强效果。研究者[9]在非线性扩散模型的基础上提出了一个可学习的扩散网络来解决各种图像复原问题。事实上,随着深度卷积神经网络的快速发展,研究者提出了很多图像复原的工作[10-15]。傅等人在去除图像压缩块效应方面利用深度学习做出了一系列优秀的工作[14-15]。在工作[14]中,作者提出了一种深度卷积稀疏编码(DCSC)网络结构,编码特征图而不是原始图像。在后续工作[15],作者进一步提出了一种基于模型驱动的可解释性网络结构。此外,很多超分辨率相关的研究工作[16-18]在降低图像压缩效应方面也显示了一定的潜力。
由于卷积神经网络是一种数据驱动的方法,数据对网络的性能具有重要的影响,那么自然有一个问题,有损压缩技术产生的压缩图像会对卷积神经网络的性能产生影响吗?为了回答这个问题,本文在CIFAR10 数据集上进行了一个验证实验。假设CIFAR-10 数据集为原始图像,并在此基础上通过PIL 工具包按照不同质量因子(95,75,55,35,15)压缩原始图像,获得不同质量的JPEG 压缩图像。本文利用同一类型的图像在CIFAR-10 数据集上训练和测试卷积神经网络,记录网络在对应测试集上的分类准确率。从结果中发现,使用质量较低的压缩图像训练卷积神经网络时,获得的网络性能也较低。显然,有损压缩技术会造成原始图像信息的丢失,进而导致卷积神经网络性能的下降。针对该问题,本文致力于对压缩图像进行复原增强,缩小压缩图像与原始图像的差异,进而实现对使用压缩图像训练的卷积神经网络的性能增强。
为了增强卷积神经网络在压缩图像中训练的性能,本文提出了一个面向压缩图像复原的增强训练方法。该方法具体为一个包含复原模块和任务模块的联合增强框架。复原模块用于恢复有损压缩技术造成的信息丢失,复原压缩图像。任务模块用于指导复原模块对压缩图像进行有针对性地复原增强。本文采用EDSR[16]中的简单网络作为复原模块。任务模块与目标任务相关,可以根据目标任务的需求进行设计。在后续的实验中,本文采用ResNet 系列网络作为任务模块。在联合增强框架的损失函数设计中,本文引入了多个损失项来约束联合增强框架的训练。具体来说,复原模块引入了匹配损失项和感知损失项,任务模块引入了与任务相关的任务损失项。本文通过ResNet 系列的两个网络在低分辨率图像数据集和高分辨率图像数据集展开了一系列实验。实验结果表明,与使用压缩图像训练的网络相比,该方法能有效复原压缩图像,提升网络在图像分类任务上的性能。
2 方法介绍
为了缓解压缩图像对卷积神经网络性能的负面影响,复原压缩图像进而提升网络性能,本文提出了一种联合增强框架。该联合增强框架包含两个模块,复原模块和任务模块,如图1所示。在本节中,首先介绍复原模块的设计方法,该模块致力于弥补有损压缩技术造成的图像信息损失。其次,介绍任务模块的设计方法,该模块致力于在任务需求的前提下指导压缩图像的复原增强。最后,介绍联合增强框架的损失函数,阐述损失函数中每个损失项的功能和意义。

图1 本文提出的联合增强框架Fig.1 The joint enhancing framework
2.1 复原模块
深度卷积神经网络利用小批次随机梯度下降法在数据集上成百上千次的训练迭代来学习数据模式。由于卷积神经网络需要从图像数据中提取有用的信息来完成相应的任务,因此图像数据质量直接影响卷积神经网络的性能。如果使用图像有损压缩技术(例如JPEG)对图像进行压缩,压缩图像相较于原始图像会损失一些信息。另一方面,图像有损压缩技术的评估标准是针对人类用户建立的,并没有把卷积神经网络作为一个关注点。因此,有损压缩方法会对卷积神经网络的训练产生影响。在这一节中,本文引入了一个复原模块来复原压缩图像,修复由于有损压缩而损失的图像信息。
复原模块是一个像素到像素的匹配网络,建模原始图像和压缩图像(例如原始无损数据和压缩数据)之间的像素级关系,如图2 中(b)所示。该匹配网络主要包含一层卷积初始化层和八个残差块。受到超分辨率工作EDSR[16]的启发,将源自于ResNet 残差网络中残差块的批量归一化层去掉,因为批量归一化层对数据进行归一化后降低了网络整体的灵活性,会破坏网络对像素级精细匹配关系的学习。该残差块只包含两个卷积层和一个激活层,如图2中(a)所示。复原模块不仅仅在残差块中包含了残差学习,在匹配网络整体结构中也包含了一个额外的跳层连接。该跳层连接能够将浅层卷积层中丰富的边、角和纹理等低层视觉信息补充给只含抽象语义的高层残差块,实现网络对高层语义信息和低层视觉信息的融合学习。

图2 复原模块中残差块的具体设计和匹配网络的整体框架Fig.2 The detailed design of the residual block and the framework of the mapping network in the enhancing module
需要注意的是,复原模块是任务相关的,可以根据任务需求进行变换。在不同的任务中,可以应用不同的网络或其他基于学习的方法构建复原模块。事实上,本文采用的匹配网络也可以被其他图像增强网络所替代,针对任务需求对压缩图像实现更合适的增强。
2.2 任务模块
任务模块以复原模块输出的复原图像作为输入,然后执行相关任务的操作。与压缩图像相比,这些复原图像具有更高的数据质量。在高质量数据帮助下任务模块可以在任务上获得更好的性能。对于卷积神经网络在任务上的性能评估,不同的计算机视觉任务有不同的度量方法,如图像分类任务中的分类准确率、图像分割任务中的分割准确率和IOU等。训练卷积神经网络的目标是在训练集中使损失函数的值在不过拟合的情况下尽可能地低。在本文的联合增强框架中,任务模块是一个在压缩图像数据集中预先学习的模型。在联合框架训练过程中,任务模块的模型参数保持固定,在梯度更新过程中不更新,只负责向后传递梯度。这样任务模块能够利用任务的损失函数向复原模块施加指导作用,引导复原模块在任务需求的前提下进一步增强数据。如果复原图像在任务模块中获得较低损失,意味着复原模块输出了良好的复原图像;如果复原图像在任务模块中获得损失较大,则复原模块还有待进一步地学习加强。
在后续的实验中,根据不同的数据集,本文采取了不同的任务模块。在低分辨率图像数据集CIFAR-10和CIFAR-100中采用了小规模的ResNet8,在高分辨率图像数据集STL-10 中使用了两个不同规模的任务模块,ResNet8和ResNet20。
2.3 损失函数的设计
本文提出的联合增强框架包含了两个模块,复原模块和任务模块,如图1 所示。为了训练该网络框架,本文提出了三个损失项,匹配损失(lossmapping)、感知损失(lossperception)和任务损失(losstask)。接下来,本文将详细介绍每个损失项的设置和作用。
在联合增强框架中,压缩图像作为输入,首先经过复原模块进行图像复原增强。通过计算复原图像与原始图像的相似度,本文得到了第一个损失项,匹配损失。当匹配损失的损失值较低时,这说明复原图像和原始图像比较相似,相较于压缩图像恢复了一些损失信息。然后,复原图像和原始图像分别输入到任务模块,获取他们的任务输出。为了比较复原图像和原始图像在任务模块上输出,本文提出了比较两者输出相似度的感知损失。该损失项和匹配损失具有相同的目的,促使复原图像尽可能地接近于原始图像,尽可能恢复压缩图像损失的信息。复原图像在任务模块中将继续计算得到任务损失。它不是复原图像和原始图像之间相似性的直接度量。如果复原图像的任务损失较大,说明复原模块输出的图像质量较差,这可以作为一个指导信号反馈给复原模块,指导复原模块的训练学习。因此,任务损失的主要作用是指导复原模块基于任务目标函数对图像进行复原增强。因此,本文联合增强框架的损失函数设计如下:
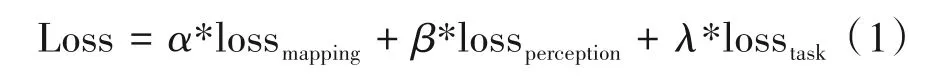
其中,α、β和λ是对应损失项的超参数。在后续实验中,本文采用了α=1、β=0.01和λ=0.01的超参数设置。在训练过程中,复原模块正常训练和更新。任务模块采用了在对应任务上利用压缩图像预训练的网络模型。该模块的参数保持固定,只执行梯度反向传播操作,不执行梯度更新操作。
3 实验分析
为了验证联合增强框架的有效性和通用性,本文在三个常用数据集上进行了实验。本文在CIFAR-10 和CIFAR-100 数据集上开展了一系列的消融实验,验证联合增强框架的有效性,分析联合增强框架的损失函数中不同损失项对整体框架的影响。接下来,为了评估该方法在应用环境的适应性,本文在STL-10数据集上利用多个不同任务模块进行了图像分类实验。下面将具体介绍相关实验细节和实验结果。
3.1 数据集与实验设置
(1)数据集
CIFAR-10 和CIFAR-100 常在消融实验中被用作实验数据集。数据集的具体细节已经在前文做了阐述,这里不再展开介绍。本文将CIFAR-10 和CIFAR-100 的图像数据当做原始图像,然后利用JPEG 压缩技术对其按照不同的质量因子(95,75,55,35,15)进行压缩,获取不同压缩程度的压缩图像。质量因子为95 时,压缩图像质量较高;压缩因子为15时,压缩图像质量较低。
STL-10 数据集和CIFAR-10 数据集的构建方法比较相似,但是STL-10 数据集的图像尺寸更大,数量更少,更接近真实世界普通用户接触的图像。STL-10 数据集总共有10 类图像,包含5000 张训练图像和8000 张测试图像,每张图像的尺寸是96 ×96。该数据集的图像是从ImageNet 大规模图像数据集上中选取,缩放到96 × 96 之后以二进制形式存储。本文采用了和CIFAR-10、CIFAR-100 数据集上同样的做法,将该数据集的图像数据视为原始图像,然后利用JPEG 压缩技术对其进行压缩获得压缩图像。
(2)实验设置
在消融实验中,联合增强框架的复原模块是前文介绍的像素到像素的匹配网络,任务模块是在对应压缩图像上预训练的ResNet8。在实验中,本文采用Adam 梯度优化算法,初始学习率为1e-4,学习率在250、375 个训练周期后分别降低一半,总共训练500 个周期。在STL-10 数据集上的实验中,复原模块和消融实验中的设置一样,但是在任务模块和某些训练细节方面不一样。任务模块采用了ResNet8 和ResNet20 两种不同规模的网络。训练时虽然同样采用初始学习率1e-4 的Adam 梯度优化算法,但是由于训练集规模较小总共训练200个周期。
3.2 消融实验
为了验证本文提出的联合增强框架的有效性,本文在CIFAR-10 和CIFAR-100 两个数据集上进行了一系列的消融实验。该部分实验主要分为三部分,第一部分验证联合增强框架对具有不同质量因子的压缩数据的有效性,第二部分测试联合增强框架中不同损失项的有效性,第三部分展示本文方法对压缩图像的增强效果的可视化展示。
(1)联合增强框架的有效性检测
本文提出的联合增强框架包含两个模块和三个损失项,用于复原图像以训练更好的卷积神经网络。对于复原模块,本文采用了一个简单的像素到像素匹配网络,其包含2 个卷积层和8 个残差块。对于任务模块,本文使用了ResNet8 作为图像分类网络。在CIFAR-10和CIFAR-100两个数据集上,首先用原始图像训练ResNet8,并将其作为网络性能的上界。然后,利用JPEG 压缩技术将原始图像在不同质量因子(95,75,55,35,15)条件下进行压缩,利用压缩图像训练ResNet8,并以此作为网络性能的基线。本文提出的联合增强框架对压缩图像进行复原增强,并利用复原图像训练ResNet8,获得本文方法的实验结果。在CIFAR-10 和CIFAR-100 两个数据集上,上界、基线和本文方法的实验结果如图3 和图4 所示。注意,图中的实验结果是实验重复5次之后的平均值。
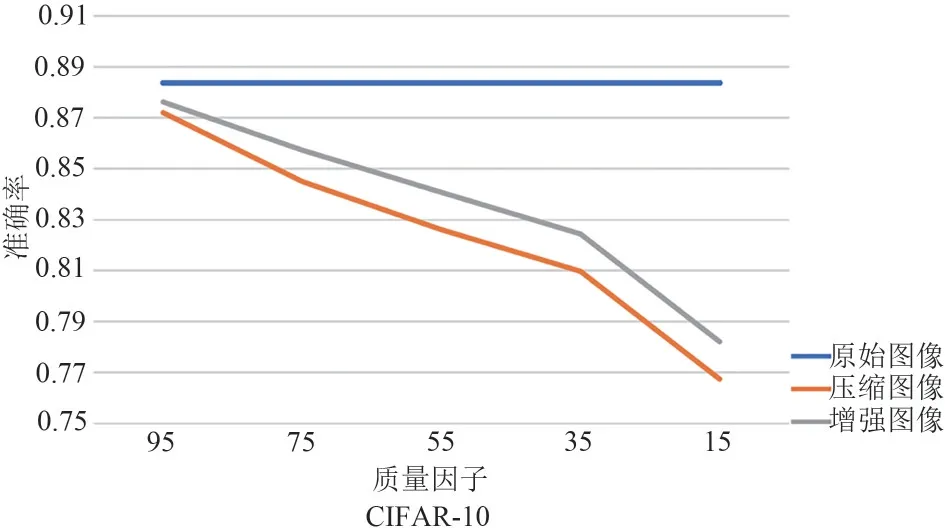
图3 利用不同类型数据在CIFAR-10上训练ResNet8的实验结果Fig.3 Experimental results of ResNet8 trained by different types of data on CIFAR-10

图4 利用不同类型数据在CIFAR-100上训练ResNet8的实验结果Fig.4 Experimental results of ResNet8 trained by different types of data on CIFAR-100
从图3 和图4 中可以清楚地看到蓝色线(上界)和橙色线(基线)之间有一个明显的间隙。这是由于有损压缩技术会造成原始图像信息的损失,在利用压缩图像训练卷积神经网络时,网络最终性能会受到影响。灰色线是本文方法的结果,它位于上界和基线之间的间隙之中。这些实验结果表明,该方法能有效复原和增强压缩图像,进而提高卷积神经网络的训练性能。值得注意的是,在不同压缩质量因子下,灰色线相对于基线的提升幅度是不一样的。在图3 中,对于CIFAR-10 数据集,本文方法在压缩质量因子比较小时的提升幅度较大,在压缩质量因子比较大时的提升幅度较小。例如当质量因子为95时,该方法相较于基线方法只提升了0.4%,当压缩质量因子为55时,该方法相较于基线方法提升了1.5%。在CIFAR-100数据集上,图4中的实验结果展示了相似的实验现象,在压缩质量因子较低时,本文方法提升幅度较大。事实上,本文方法在不同压缩质量因子下提升幅度不同是合理的。这是因为压缩质量因子较高时,压缩图像相对于原图的信息丢失较小,可提升范围本身较小。而在压缩质量因子较小时,压缩图像质量较低,对压缩图像的增强能够使网络获得更高的性能提升。
(2)损失函数的有效性检测
为了验证损失函数各部分损失项的有效性,本文进一步展开了关于损失项的消融实验。在公式(1)中,匹配损失和感知损失是超分辨率图像网络中常用的损失项,任务损失是一个能够促使联合增强框架针对网络特定任务进行图像增强的限制项。本文将这三个损失项进行两种不同类型的组合,匹配损失和感知损失组合在一起称之为组合A,匹配损失、感知损失和任务损失三者联合在一起称之为组合B。组合A实际上是工作EDSR[16]的单尺度版本的复现,在本文的实验中进行了重新训练。表1和表2分别记录了CIFAR-10 和CIFAR-100 数据集上不同损失项组合的实验结果。

表1 CIFAR-10数据集上不同损失项组合训练网络的实验结果Tab.1 Evaluation of the combinations of losses on CIFAR-10

表2 CIFAR-100数据集上不同损失项组合训练网络的实验结果Tab.2 Evaluation of the combinations of losses on CIFAR-100
从上述两表的结果可以看出,基于组合A 的损失项能在压缩图像进行一定程度的复原增强,使得卷积神经网络在使用复原图像训练之后获得一定程度的性能提升。例如在质量因子为75 时,在CIFAR-10 数据集上组合A 相较于使用压缩图像的方法提升了0.8%,在CIFAR-100数据及上组合A相较于基线方法提升了0.61%。通过添加任务损失形成组合B 的方法后,组合B 的实验结果在CIFAR-10 和CIFAR-100 两个数据集上的性能均优于组合A。例如在压缩质量因子为75时,在CIFAR-10数据集上方法B 相对于方法A 提升了0.44%,在CIFAR-100 数据集上方法B 相较于方法A 也获得了0.44%的提升。这些实验结果表明,任务损失对联合增强框架的重要意义,可以引导复原模块基于任务目标函数更具目的性地复原和增强压缩图像,进一步提升卷积神经网络的性能。
3.3 复原图像的可视化展示
为了更直观地展示该联合增强框架对压缩图像的复原效果,本文从CIFAR10 数据集随机选取了一些样本进行可视化。图5 展示了4 个样本数据的原图、压缩质量因子为75的压缩图像和对应的复原图像。图5中展示的压缩图像出现了明显的压缩块效应,相对于原图变的模糊,尤其是右下角的压缩图像,其中船的特征对于人眼来说已经非常模糊。图5中复原图像相对于原图在某些边缘上变的较为平滑,但是相对于压缩图像在图像质量上有了明显的增强。因此,这些可视化结果和上文定量结果获得了一致的结论,进一步验证了该联合增强框架实现了对压缩图像的复原增强。

图5 CIFAR-10中原始图像、压缩图像和复原图像的可视化Fig.5 Visualization of the raw image,the compressed image and the enhanced image on CIFAR-10
3.4 STL-10数据集上的对比实验
本节实验虽然和上节实验同属图像分类任务,但是STL-10数据集上的图像分辨率更大,更贴近现实应用场景的真实数据。因此,为了验证本文方法对真实数据的适应性以及联合增强框架中任务模块的适应性,本文在STL-10数据集上进行了一系列的实验。
本文将STL-10 数据集看做原始图像,利用JPEG 压缩技术在压缩质量因子75 下压缩原始图像获得压缩图像。本文选择压缩因子为75 的原因是当今互联网平台一般将用户上传的图像按照质量因子75进行压缩存储,例如新浪微博和腾讯微信两大平台对用户上传图像采取75 左右的质量因子进行压缩。此外,在联合框架的训练中,由于该框架中复原模块是一个没有下采样的像素到像素的匹配网络以及实验设备资源的限制,复原模块无法适应大尺寸图像的输入,所以该实验中复原模块的输入图像尺寸为48 × 48。而对于任务模块,输入图像尺寸为96 × 96。虽然同一框架中两个模块的输入图像尺寸大小不同,但是由于框架中两者的低耦合性,各个损失项依然可以联合起来训练该框架。下面本文将利用不同规模的网络,ResNet8 和ResNet20,作为联合增强框架的任务模块在STL-10数据集上进行实验。
表3展示了利用不同类型数据和不同规模网络在STL-10数据集上的实验,注意表格中的实验结果都是实验重复5 次的平均值。表3 中第一、二行分别展示了利用STL-10数据集的原始图像和JPEG 压缩图像进行实验的结果,第三行展示了利用本文方法输出的复原图像进行实验的结果。表中第二、三列分别展示了不同任务模块下的实验结果。从任务模块为ResNet8 的实验结果来看,原始图像经过质量因子为75的压缩之后,训练神经网络的性能下降了1.8%。经过本文方法对压缩图像复原增强之后,训练神经网络的性能达到了0.7115,较压缩图像提升了1.3%,这进一步证明了本文方法对压缩图像的复原增强,实现了神经网络的性能提升。另一方面,利用复原图像训练的神经网络性能相较于原始图像低0.5%,这说明本文方法只是部分找回了压缩技术造成的信息损失,未来通过替换更强的复原模块和任务模块还有进一步的提升空间。在任务模块为ResNet20 的实验结果中,得到了相似的结论。这进一步展现了本文方法中两个模块的低耦合性,可以被替换成不同网络框架,对不同应用场景具有广泛的适用性。

表3 具有不同任务模块的联合增强框架在STL-10数据集上的实验结果Tab.3 Experimental results with different task modules on STL-10
为了进一步展示不同任务模块对压缩图像复原增强的差异表现,本文从STL-10数据集上随机选取了4张图像进行可视化。这些复原图像来自于本文方法中任务模块为ResNet8 和ResNet20 的实验,如图6 所示。针对大尺寸的图像,从可视化结果上来看,人眼几乎分辨不出原始图像和压缩图像的差异。这也验证了本文第一节提及的问题,现在的图像压缩技术的评价标准之一是人类的视觉感受,不考虑压缩图像对于机器学习模型的影响。但是从表3中可以清晰地显示出利用不同类型图像训练的卷积神经网络的性能不一致,确切地说是利用压缩图像训练的卷积神经网络性能更低。为了更加准确地描述原始图像、压缩图像和复原图像间的关系,本文采用了图像处理领域常用的评价指标,峰值信噪比(PSNR),来评价图像间的相似关系。具体结果如表4 所示,可以明显发现复原图像与原始图像的峰值信噪比要明显高于压缩图像与原始图像的峰值信噪比,进一步证明了本文方法对压缩图像的复原增强。同时,基于ResNet20 的增强图像与原始图像的峰值信噪比高于基于ResNet8 的两者的峰值信噪比,这说明任务模块的更换会对该联合增强框架造成影响,更优秀的任务模块对复原模块有更强的指导作用,促使联合增强框架实现更好的图像复原增强。

表4 压缩图像和不同任务模块下复原图像与原始图像间的峰值信噪比结果Tab.4 Evaluations on PSNR between the compressed image and the enhanced image by our method with different task modules

图6 STL-10中原始图像、压缩图像和基于不同任务模块的复原图像的可视化Fig.6 Visualization of the raw image,the compressed image and the enhanced image with different task modules on STL-10
4 结论
本文提出了一种面向压缩图像复原的增强训练方法,致力于通过复原压缩图像增强卷积神经网络的性能。针对利用压缩图像训练的卷积神经网络性能下降问题,本文提出了一个包含复原模块和任务模块的联合增强框架。复原模块是一个像素到像素的匹配网络,构建压缩图像到原始图像映射关系;任务模块是一个利用压缩图像训练的预训练模型,利用该模块在任务上的损失函数进一步约束和指导复原模块进行图像复原增强。该联合增强框架的损失函数主要包含3 个损失项,用于约束框架中两个模块的学习。总的来说,复原模块用于恢复有损压缩技术造成的信息损失,任务模块基于任务损失函数指导复原模块对压缩图像进行有针对性地增强。大量的实验结果表明,本文方法能有效复原和增强压缩图像,提高卷积神经网络的训练性能。此外,该联合增强框架中复原模块和任务模块的低耦合性和可替换性,使得本文方法能方便地根据任务需求进行变换迁移,保证了方法的适用性。
