面向智能运维的KPI异常检测模型研究
2022-07-22戴跃伟刘光杰
陈 倩,戴跃伟,刘光杰
(南京信息工程大学电子与信息工程学院, 南京 210044)
0 引言
随着互联网的快速发展,网络服务的单一节点技术日益复杂,系统规模逐渐扩张,使得网络服务系统的运维更加困难。面对监控数据量庞大、指标类别繁多的运维场景,智能运维(artificial intelligence for IT operations,AIOps)[1]将人工智能与传统运维相结合,形成了全新的技术领域。为保证网络服务系统的安全,需实时监控大量关键性能指标(key performance indicator,KPI)以了解各系统组件的运行状态。其中,关键性能指标的异常检测是智能运维技术的研究热点,通过各类异常检测方法对复杂KPI时序数据进行有效的数据挖掘分析,能够快速发现异常,从而达到规避故障,及时止损的目的。
目前,KPI异常检测方法主要分为基于统计预测的检测方法和基于机器学习的检测方法。基于统计预测的KPI异常检测方法假设KPI序列服从某种概率分布,为每条KPI选择合适的模型,根据分布的不同来判断是否有异常。文献[2]提出了一种基于自回归移动平均模型(autoregressive moving average mode,ARIMA)的异常检测方法,用于检测网络服务中可能发生的故障。通过ARIMA模型预测KPI指标的未来趋势,并对明显超出实际值的指标进行异常报警。包括上述方法在内的基于统计预测的方法需对KPI预先假设,且无法学习非线性关系,容易产生大量的误报。
随着课程改革的深入,我六年的小学语文已经“毕业”,2008年汶川大地震后的教育重建,让我更加关注“人”,从发展儿童的角度,将阅读的主要精力转向教育学、心理学特别是脑科学等领域,下面我仅举阅读教育学的例子。
基于机器学习的KPI异常检测方法又分为有监督机器学习方法和无监督机器学习方法。通过有监督的机器学习方法在一定程度上能够提升对KPI异常检测的建模阶次。文献[3]提出了一种自动异常检测框架EGADS,该框架使用多个传统异常检测模型对KPI进行特征提取并使用标签训练异常分类器判断异常,取得了较为理想的效果。文献[4]提出了一种基于随机森林算法的异常检测系统Opprentice,用工具对KPI进行标注并使用不同的检测器衡量指标的异常程度。包括上述方法在内的有监督学习方法,在模型适应性方面仍存在不足,需对具体场景针对性训练,不可避免的需要高成本的人工标注来构造训练数据集。基于无监督的机器学习方法可以在没有人工标注的数据上进行模型训练。文献[5]提出了一种基于时间序列聚类的方法,首先提取每类KPI序列的基线,采用SBD算法作为距离度量,并根据基线的相似性利用DBSCAN算法将KPI聚类,接着为每个簇训练异常检测模型。文献[6]使用PCA(principal components analysis)对序列进行特征提取,并基于One-Class SVM(support vector machine)算法进行聚类分析和无监督的训练,实现了KPI序列的异常检测。基于机器学习的聚类方法能够对较小的KPI训练数据集进行较为快速的收敛,但是所训练的模型保守型较强,对于数量庞大的KPI训练集无法保证聚类收敛,难以取得较好的检测结果。
近年来,深度学习在KPI异常检测领域得到了广泛应用。作为深度生成模型之一的变分自编码器(variational auto-encoder,VAE)是当前深度生成模型极具竞争力的研究方向。An等[7]在2015年证明了变分自编码器在无监督异常检测中的可行性,之后变分自编码器在网络入侵检测等领域得到了成功应用。文献[8]提出了一种基于变分自编码器的无监督异常检测模型donut,编码器提取KPI序列中有代表性的特征,解码器根据特征重构序列,计算重构序列与原始序列的误差判断序列中的异常,该模型充分利用了深度生成模型对KPI序列深层次特征的表征能力。但是KPI作为一种时间序列数据,仅用变分自编码器进行异常检测无法较好体现时间相关的隐含特征。
针对现有方法对KPI检测不精确,难以提取数据中的有效特征,且未充分考虑KPI的时间相关性的问题,提出了一种基于变分自编码器和门控循环单元网络的KPI异常检测方法。利用变分自编码器能够提取KPI深层次特征的能力结合门控循环单元网络复杂度小、学习能力快和能够更好的处理时序数据的优势,实现了对运维中关键性能指标的精确检测。
1 基于VAE-GRU的异常检测架构
1.1 问题描述
1.1.1KPI基本概念
配电网自动化系统提升可感知性主要指充分利用配电网自动化技术运用功能设计过程中,保障自动化系统在运行过程中操作便利,并可提供精确的供电信息,系统能较快地被感知及维护,及时规避应用中的隐藏性漏洞,进而全面增强自动化系统的应用效率。
为确保服务质量和可靠性,需持续监控KPI以了解服务器或应用程序的运行状态。KPI是一种由(时间戳,值)键值对组成的时间序列,形式上可以表示为X={x1,x2,…,xn},xi是对应于时间戳T={1,2,…,n}中第i个时间戳的值。KPI包括页面访问流量、在线用户数、设备内存利用率和网页响应时间等,可以从简单网络管理协议(SNMP)、系统日志、网络跟踪、网络访问日志和其他数据源获得。与传统的时间序列相比,KPI包含的信息量更大,可以反映更多应用与服务的变化。
1.1.2KPI异常检测基本概念
随着公司规模的扩大,对技术人才、硬件设备、项目费用及周转资金的需求会越来越高,在这方面会有较大的投资。
对于八达岭老虎致害案件,我将从中华人民共和国侵权责任法角度来对于动物园在此案件中的责任判定问题进行论述。
Eqφ(z|x)[logpθ(x|z)]-
DKL[qφ(z|x)‖pθ(z)]=
1.2 异常检测架构
以VAE为基础设计了一个VAE-GRU的KPI异常检测模型,引入变分自编码器和门控循环单元网络,变分自编码器充分考虑到KPI序列的隐藏特征,门控循环单元网络利用提取到的特征进行时序数据的预测。该模型使深度生成模型较强的表征学习能力和门控循环单元网络的时序建模能力相结合,把KPI异常检测问题转化为一个无监督学习问题。本文模型的整体框架如图1所示。

图1 基于VAE-GRU的异常检测方法架构
重置门:rt=sigmoid(Wr·[ht-1,xt])

图2 KPI异常检测流程框图
2 基于VAE-GRU的异常检测过程
2.1 预处理
为了避免KPI指标数据中不同值之间的明显差异对实验结果造成影响,训练之前应该先对原始数据进行标准化处理,本文采用z-score标准化方法[9]处理数据,计算方法为:
(1)
L(θ,φ;x)
全局Moran's I用来检验观测对象在空间是否存在集聚现象,但不能看出区域间是如何集聚的,因此,采用局域空间相关指数来判断局部范围内分块集聚的具体情况。公式如下:
由于VAE模型不是一个序列模型,如果直接用VAE模型在原始数据点上进行训练来学习内部表示的话,每个数据样本将会被视为独立的,这种方法忽略了时间序列数据中固有的重要时间信息。因此我们提出采用滑动窗口[10]的形式训练数据,将时间相关性引入到模型中。在关键绩效指标上应用长度为l的滑动窗口,例如wt=[xt-l+1,…,xt]表示在t时刻结束的窗口,将整个时间序列分割成连续的短序列,此时KPI指标序列可表示为Wt=[wt-(m-1)×l,wt-(m-2)×l,…,wt],m表示用于GRU预测的不重叠窗口个数。
这场讨论受到了租界当局、军警和卫道士们的围攻,《民国日报·觉悟》的主编邵力子先生受到处罚,魏金枝寄去的文章忽然不登出来了,他写信去追问,邵力子回信中表示很尴尬,劝他不要再讨论这个问题,免得他受罚。这场恋爱的争论就此终结。魏金枝很不满意,就写了一篇新诗《大风歌》,“想将一股大风,把一切阻碍人世间的障碍一气吹得精光。”可惜这诗篇目前还没有找到。
例如,在晶状体移植手术中,通常采取PMMA作为移植材料,但这一人工晶状体若与眼角膜上皮细胞接触,将造成角膜的永久性损伤。而通过低温等离子技术中的沉积方法,能够将亲水性的单体如N-乙烯基吡咯烷酮等沉积到PMMA 的表面,从而降低角膜细胞的损伤。通过动物实验发现,利用低温等离子沉积技术处理后的PMMA进行晶状体移植,最低可以将复合表面的细胞损伤控制在10%以下。
2.2 基于变分自编码器的特征提取
变分自编码器是一种重要的生成模型,通过将深度学习和概率统计技术紧密的结合,能够提取出KPI指标数据更深层次的特征。变分自编码器主要由编码器、解码器以及隐藏层组成。其基本结构如图3所示。
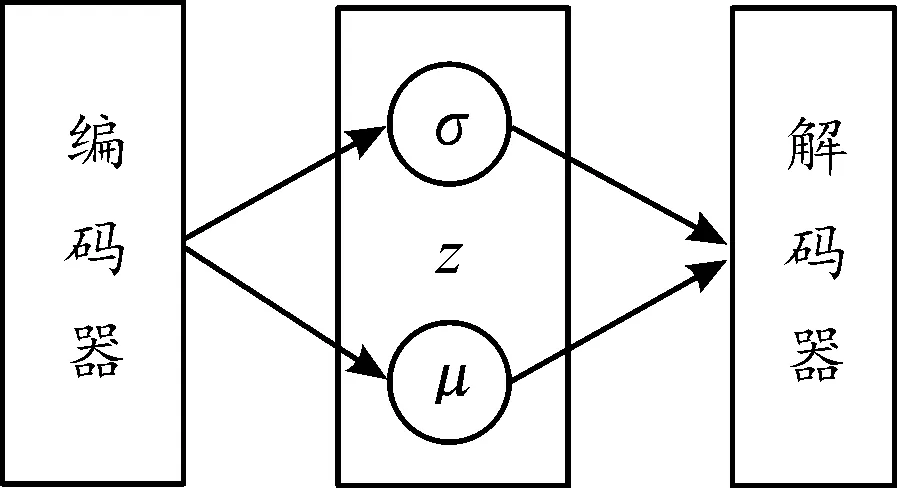
图3 变分自编码器基本结构

死体可燃物含水率(Y)与降水(X1)、气温(X2)、相对湿度(X3)、连旱天数(X4)、蒸发量(X6)之间的数学模型为:
(2)
根据Jensen不等式[12],式(2)可改写为:
早在中本聪提出比特币之前,BFT算法已经存在,1999年LISKOU B等提出了实用拜占庭容错算法。该算法达成共识需要“请求、预准备、准备、确认、回应”5个步骤。其中“预准备、准备、确认”3个步骤用于保障一致性。该算法虽然拥有1/3的容错性,但并不能防范女巫攻击,因此不能用于公有链类型货币中。实用拜占庭容错算法(PBFT)是传统一致性算法的改进,算法十分高效,在不需要货币体系的许可链或者私有链中较为常用。目前,IBM创建的超级账本就是使用了该算法作为共识机制。

KPI异常检测是指通过分析KPI曲线,发现其中突然出现的抖动、下降、尖峰等不遵循正常模式的数据,若出现异常通常表明互联网服务的软硬件中存在潜在故障,如服务器故障、访问用户急剧减少、访问延迟增大等。及时准确地发现KPI中的异常,可为后面的故障分析和修复节省时间,避免带来更大的损失,保证了互联网公司能够为用户提供高效可靠的网络服务。
水分管理:水分管理的关键时期包括新梢迅速抽长期和果实膨大期。贵州季节性干旱较严重,注意及时浇水。在梅雨季或降雨量大的时候,注意及时排水。
式中:μ为x的均值;σ为x的标准差;x是原始数据;x′为标准化后的值。
使用经VAE产生的前m-1个低维嵌入作为GRU的输入来训练模型,经GRU预测得到后m-1个嵌入:
(3)
其中L(θ,φ;x)为对数似然函数logpθ(x)的变分下界(evidence lower bound,ELBO),若要对数似然函数最大,就要最大化变分下界。因此变分自编码器的优化目标就是最大化变分下界函数L(θ,φ;x),定义为:
L(θ,φ;x)=Eqφ(z|x)logpθ(x|z)-
DKL[qφ(z|x)‖pθ(z)]
(4)
VAE经编码得到输入数据概率分布对应的均值μ和标准差σ,由于直接采样法对μ和σ均不可导,使得用梯度下降的方法更新权重难以实现,所以引入重参数技巧,VAE在编码网络上增加了高斯噪声进行约束,使生成的隐变量z服从高斯分布,z的表达式为:
z=μ+ε·σ
(5)
式中ε是符合标准正态分布的随机数。
由于异常检测要求实时性,需要进行异常检测的运维数据数量庞大种类较多,大多数时序数据都是单变量或者维度低,所以特征的构建就显得格外重要。传统的特征提取方法如PCA、局部线性嵌入算法(locally linear embedding,LLE)、多维标度分析(multidimensional scaling,MDS)等存在表征能力低、计算量大、对输入数据有局限性等问题。自编码器(auto-encoder,AE)是深度学习中的一种重要模型,主要用于对数据进行非线性降维特征提取。变分自编码器是AE的变体,通过变分推理学习输入数据的分布特征,具有较强的特征提取能力,适合运维数据异常检测需求。
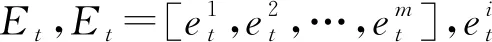
重症肌无力患者免疫治疗前后AIRE、Tfr/Tfh比值与病情的相关性 ………… 王圣元,等(8):933
2.3 基于门控循环单元的预测
门控循环单元(gated recurrent unit,GRU)[13]作为循环神经网络的(recurrent neural network,RNN)的一种,在设备故障诊断[14]、目标识别[15]等多个领域广泛应用。GRU结构如图4所示,GRU和LSTM都更好的保留了时间跨度较长的序列信息,避免了长期依赖问题。但是和LSTM相比,GRU结构更加简单,相比之下更容易训练数据,很大程度上能够提高模型训练速度。GRU引入更新门zt和重置门rt替代LSTM中的输入门、遗忘门和输出门。重置门用来控制忽略前一时刻的状态信息程度,值越小说明忽略的信息越多,更新门用来决定前一时刻状态信息有多少将保留到当前状态中,值越大说明前一时刻保留的信息越多。
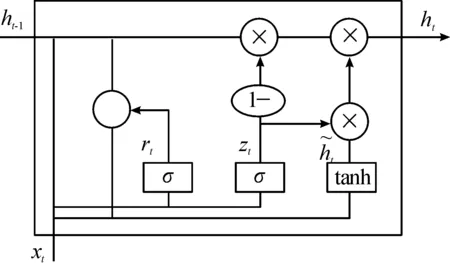
图4 门控循环单元基本结构
GRU的计算步骤如下:
步骤1重置门和更新门的输入与当前时刻和前一时刻的隐藏状态有关,用sigmoid函数计算输出,表示为:
更新门:zt=sigmoid(Wz·[ht-1,xt])
(6)
图2为KPI异常检测流程。先对KPI数据集进行标准化,再利用滑动窗口将标准化后的KPI数据分割成连续的短窗口序列,将短窗口序列输入变分自编码器模型,编码器对KPI数据进行特征提取,接着建立门控循环单元网络对提取到的特征进行预测,最后输入解码器得到重构窗口序列,将重构窗口序列与原始窗口序列对比,计算出的重构误差即为异常检测分数。如果重构误差大于给定阈值,则输入序列为异常序列,反之,输入序列为正常序列。
(7)
其中,W为权重参数。
步骤2将当前时刻重置门的输出和前一时刻隐藏状态相乘,重置门中元素的值接近1,则保留前一时刻状态信息,若接近0,则忽略前一时刻信息,使用tanh激活函数计算候选隐藏状态:
(8)

(9)
GRU作为一种常见的预测模型,可以长时间保存序列信息,且结构简单,参数较少,训练速度比LSTM更快,更不容易产生过拟合。考虑到KPI数据的特性,相比其他神经网络,GRU更适合用来预测KPI数据。
这些丰富的比赛不仅能锻炼学生的胆量,而且能提高学生的学习兴趣,在玩乐中提高朗读水平,在阅读中加大识字量,提高书写质量。
(10)
2.4 异常检测器设计
VAE模型对经过GRU预测得到的后m-1个窗口数据进行解码,得到重构序列,如式(11)所示。通过对比重构序列和原始序列计算重构误差,即异常检测分数来标记KPI指标数据的异常行为,异常检测分数f的定义如式(12)所示:
(11)
(12)
设定一个阈值d,当异常检测分数f大于阈值d时,将当前时间t判定为异常。为避免阈值选择问题,列举所有可能的阈值,获得相应的综合评价指标F1分数,并使用最佳F1分数作为度量,表明在给定最佳阈值情况下可能的最佳性能。在实际操作中,运维人员可以根据知识和经验来决定阈值。
3 实验分析
3.1 实验设置
实验中使用2个来自异常检测基准数据(NAB)的带有异常标记的公开数据集,数据均为有序且带时间戳的单值指标。实验数据集分别是亚马逊网络服务的CPU使用率和亚马逊东海岸数据中心服务器的CPU使用率,在这些数据集上已经成功进行了一些异常检测的研究[16]。在Windows 10操作系统上采用Python 3.6.11软件,整个框架使用Tensorflow实现。由于滑动窗口过短不利于对KPI序列的特征提取,过长可能会造成数据冗余,故分别取值24、48、144,发现当l=48时,准确率最高。用于GRU预测的窗口数m设置为12。VAE和GRU的Batch Size 都设置为32,学习率分别设置为0.000 4和0.000 2,分别选取Relu和Tanh作为激活函数。由于Adam优化器在训练过程中收敛速度快、调参容易,所以使用Adam优化器更新模型参数。为了实现无监督的训练模型,将KPI序列划分为训练集和测试集,使用不含异常的连续序列作为训练集,其余含有异常的序列作为测试集,训练集和测试集的划分情况如图 5所示。亚马逊网络服务的CPU使用率共18 050个样本点,训练集为正常序列,经划分,训练集共有15 500个样本,剩余含有异常的2 550个样本作为测试集。亚马逊东海岸数据中心服务器的CPU使用率共4 032个样本,划分后训练集共有2 000个样本,剩余含有异常的2 032个样本作为测试集。

图5 训练集和测试集的划分情况
3.2 实验评估指标
异常检测器检测异常的能力通常由准确率(Accuracy)、精度(Precision)、召回率(Recall)和F1值这4个直观的指标来评估,F1值为精度和召回率的调和平均数,其计算式分别见式(13)—(16)。其中TP(True Positive)表示异常检测模型正确检测出的异常数量,FP(False Positive)表示正常数据被检测模型判定为异常的数量,FN(False Negative)表示异常数据被检测模型判定为正常的数量,TN(True Negative)表示异常检测模型正确检测出的正常数据数量。
(13)
(14)
(15)
(16)
3.3 实验对比结果与分析
3.3.1性能比较结果
使用训练集对变分自编码和门控循环单元训练之后,分别用2个数据的测试集对VAE-GRU异常检测模型进行评估。为验证异常检测模型的实用性和有效性,将新模型同单独使用VAE模型[8]和GRU模型[18]进行对比。不同方法对亚马逊网络服务的CPU使用率的性能指标如表1所示,亚马逊东海岸数据中心服务器中CPU使用率的性能指标如表2所示。
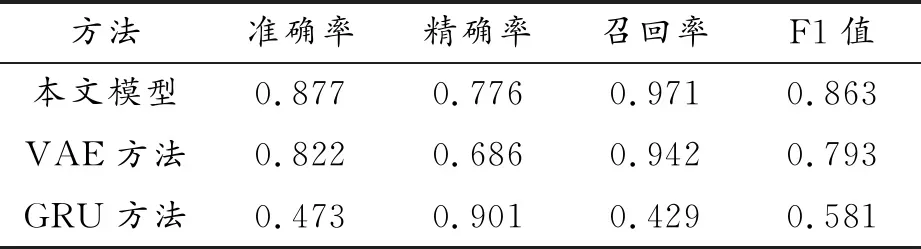
表1 不同方法对亚马逊网络服务的CPU使用率的性能指标
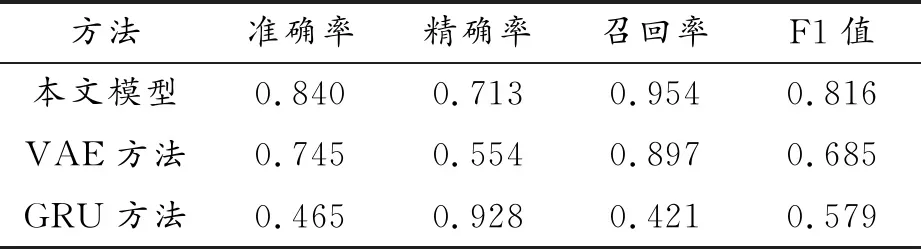
表2 不同方法对亚马逊东海岸数据中心服务器中的CPU使用率的性能指标
表1和表2表明,相比提出的异常检测方法,单独使用VAE模型和GRU模型检测异常时,2个模型在准确率、精度、召回率、F1值都有所欠缺。VAE模型在2个数据集上都有着很好的召回率,但是精确度不高,在亚马逊网络服务的CPU使用率上的精度为0.686,在亚马逊东海岸数据中心服务器中的CPU使用率上精度为0.554,表明VAE模型在对2个数据集检测的过程中将很多正常数据误判为异常数据。GRU模型在2个数据集上都有很高的精度,然而召回率较低,在亚马逊网络服务的CPU使用率上的召回率为0.429,在亚马逊东海岸数据中心服务器中的CPU使用率上的召回率为0.421,表明GRU模型在检测过程中遗漏了很多异常。而新提出的VAE-GRU模型在2个数据集上都有最高的召回率,分别达到了0.971和0.954,也获得了较好的精度。F1值最高的也是新模型,说明其整体效果比单独使用VAE模型和GRU模型好。
3.3.2异常检测结果的可视化对比
本文中提出的异常检测模型、VAE模型和GRU模型对亚马逊网络服务的CPU使用率的异常检测可视化结果如图6所示。异常检测模型、VAE模型和GRU模型对亚马逊东海岸数据中心服务器中的CPU使用率的异常检测结果如图7所示。蓝线代表原始KPI序列,红色虚线代表真实异常,绿色短线代表检测到的异常,浅蓝色窗口代表检测到的异常窗口。
我国兽医管理体制存在一些亟待解决的问题,随着兽医管理体制改革的推进,使我国在重大动物疫病的防控能力得到明显加强。农业部将加强与有关部门的沟通协调,加大对地方的督促检查力度,争取尽早把兽医管理体制改革工作落实到位。并提出“建设现代农业基地,大力发展现代畜牧业”,加快现代畜牧业发展,促进社会主义新农村建设的口号。此文笔者结合自己工作实践,来浅谈一下我国兽医管理体制改革方面的问题!
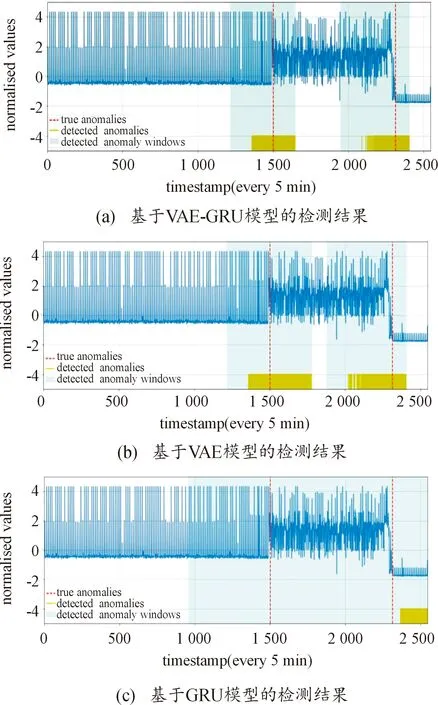
图6 3种模型的异常检测结果
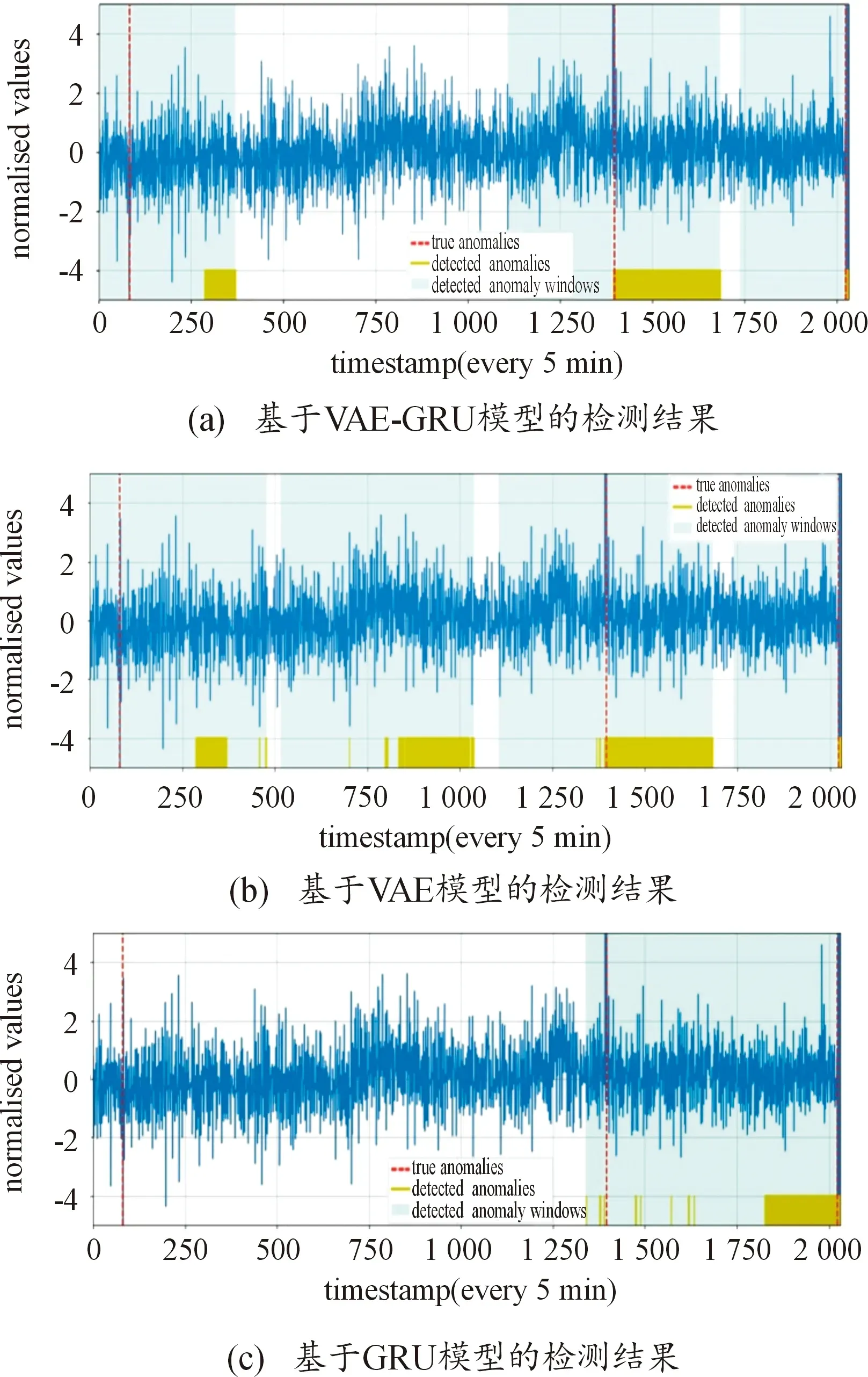
图7 3种模型的异常检测效果
如图6(b)和图7(b)所示,基于VAE模型对KPI序列进行异常检测时,能够检测到所有异常点,因此VAE模型的召回率很高;模型检测出KPI序列中大量的假阳性,这是因为VAE不是一个序列模型,无法处理与时间相关的异常,所以单独使用VAE模型进行异常检测往往会忽略时间序列中固有的重要时间信息,限制了模型的检测效果,导致精确度不高。如图6(c)和图7(c)所示,使用GRU模型进行异常检测时,模型检测出少量的假阳性,因此GRU模型的精确度较高,但模型遗漏了KPI序列中真实的异常,这是因为单独使用GRU模型进行异常检测时,由于缺乏KPI序列更深层次的有效特征导致检测效果不佳。如图6(a)和图7(a)所示,新提出的VAE-GRU异常检测模型相比VAE模型和GRU模型在2个数据集上都有较好的表现,VAE模型能够自动学习原始数据中较好的特征,GRU作为时间序列预测模型可使预测误差尽可能小,2种方法结合使得本文模型的整体性能优于单独使用VAE模型和GRU模型。
4 结论
提出了一种基于变分自编码器结合门控循环单元的KPI异常检测方法。与以往的KPI异常检测算法相比,不仅考虑时间序列中的时间相关性,而且有效挖掘了数据更深层次的特征。研究数据来自同一类关键性能指标,主要集中于单个关键性能指标的异常检测,但实际运维场景中,用于多种关键性能指标的异常检测器更有用,因此下一步将在本研究基础之上对多种关键性能指标展开研究。
