基于知识图谱的中文地址匹配方法研究
2022-07-21陈雨晖姜滕圣奚雪峰吴宏杰付保川
陈雨晖,皮 洲,姜滕圣,李 响,王 震,奚雪峰,3,吴宏杰,3,付保川,3
1.苏州科技大学 电子与信息工程学院,江苏 苏州 215009
2.苏州市公安局,江苏 苏州 215009
3.苏州科技大学 苏州智慧城市研究院,江苏 苏州 215009
在高速发展的大数据环境下,要想建设能够很好提升资源效率、改善人民生活水平的智慧城市,准确、多样的地址信息空间是不可或缺的,这就需要高效、精确的非标中文地址匹配方法。传统的中文地名地址匹配技术主要建立在标准地址库的设置之上,但是随着地址建筑的日益增多,以及数据来源、数据结构标准的不同,传统中文地址匹配技术在处理非标中文地址需要迎接新的挑战。建立能够应对不规范、不准确的中文地址匹配方法,实现地址数据校验、地址可视化等功能,是我国发展智慧城市的必经之路。
知识图谱[1]原本是谷歌用来实现知识搜索功能的,在学术界和工业界被广泛使用,是各类结构化知识库的统称。知识图谱就是将人类知识结构化形成的知识系统,是人工智能研究和智能信息服务的基础核心技术,可以实现实体关系准确查找、智能推荐等功能[2]。因此将知识图谱运用在存储地址信息上也有很好的前景,不仅可以实现可视化查询地址关系,还可以起到地址清洗、地址补全的功能,更能在中文地址匹配方法中起到良好的效果。
传统的中文地址匹配方法主要分为三大类:(1)基于中文分词的地址匹配算法[3-4]。该类算法是基于建立未登录词的词典库对中文文本进行分词匹配,即直接匹配字符串。其中,逆向最大匹配BMM算法在进行中文文本分词时最为常用,这是因为中文文本的词义中心通常相对靠后,但是该方法需要建立完善的词典库,每当出现未登录词时,都需要及时对现有的词典库进行补充。(2)基于统计分词的地址匹配方法[5]。统计分词主要研究地址历史信息,若两个字符在地址信息中出现的词频较高,就能够推测这两个字符较可能构成一个词。该方法主要基于词频进行分词,不需要词典库支持,但对常用词的识别精度较差,在处理中文地址匹配时劣势较为明显。(3)基于语义理解的地址匹配算法[6]。中文地址由丰富的语义信息组成,通过对地址名称中不同的地址要素进行特征提取,可以在匹配时获取较高的精确率。基于上面这些方法,赵阳阳等人[7]提出了地址要素识别机制的地名地址分词算法,但是需要建立完备的词典库;张雪英等人[8]提出了一种基于规则的中文地址要素解析方法,但在处理包含POI(point of interest,兴趣点)特征的标准中文地址时,仅能基于统计分词分析上下文进行解析,识别率差;谢婷婷等人[9]提出了一种基于统计的中文地址位置语义解析方法,不需要建立词典库,但是忽略了地址语义信息,难以应对实际需求;许普乐等人[10]提出了基于贝叶斯推理的中文地名地址匹配方法,通过Spark大处理框架对中文地址解析,但对数据的质量和硬件的要求较高;邹恩岑等人[11]提出了一种面向中文非标建筑地址标准化的自动匹配方法,通过使用字符串匹配[12]的方法应对中文地址非标准的问题,但匹配效果不理想。
综上,现有的方法存在需要不断更新词典库、地址切分不明确、面向非标准中文地址时匹配准确率不高等问题。针对这些问题,本文提出了一种基于知识图谱的中文地址匹配方法研究。该方法通过提取分层特征对标准地址数据、POI地址数据分别建立知识图谱,以应对地址多样性的问题;利用待测地址的间接信息建立待测地址知识图谱,通过基于选择性注意力机制的知识图谱的关系抽取方法对待测地址进行地址分类;最后通过计算知识图谱实体相似度的方法实现对非标中文地址的地址匹配。
1 基于知识图谱的非标中文地址匹配方法
本文采用基于知识图谱的非标中文地址匹配方法,该方法的具体匹配流程如图1所示。
1.1 知识图谱结构
知识图谱通常以实体、关系及事实三元组[13]进行组织。对于事实三元组中的任意事实,使用(h,r,t)进行表示,其中h代表头实体,t代表尾实体,r代表头尾实体之间的关系。当应用在地址信息空间时,实体就是地址的详细名称、省名、市名、区名、道路名称等等;关系存在与各个实体之间,例如所在省、所在市、所在区、所在道路等等,可简单用“位于”表示。知识图谱中的实体关系包括了地址信息的各类属性,例如地址的行政区划代码、经纬度信息、行业分类等。
1.1.1 标准地址知识图谱
标准地址库作为地址匹配的数据基础,其质量的好坏将会直接影响地址匹配的准确率,在知识图谱中也是如此。为了保证数据的准确性,首先需要对获取到的标准地址库进行数据预处理后才能构建知识图谱。原地址库中包含了至少千万数量级的地址数据,需要从中挑选出合适的信息作为实体名称以及实体属性,实体属性包括每条地址的所在行政区划、经纬度等等。遍历整个标准地址库后,对挑选出的数据进行全角/半角处理,去除掉数据中的非法字符以及会影响实体关系的英文字母或数字,减少因干扰项而引起的匹配误差。数据清洗完毕后,选择通过提取地址要素对作为地址知识图谱的实体。根据实际需要进行简化后的地址要素如表1所示。
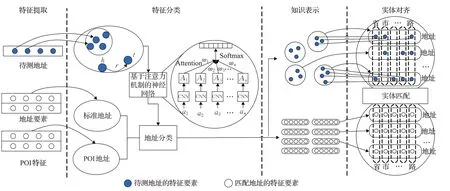
图1 基于知识图谱的非标中文地址匹配方法流程Fig.1 Process of non-standard Chinese address matching based on knowledge graph
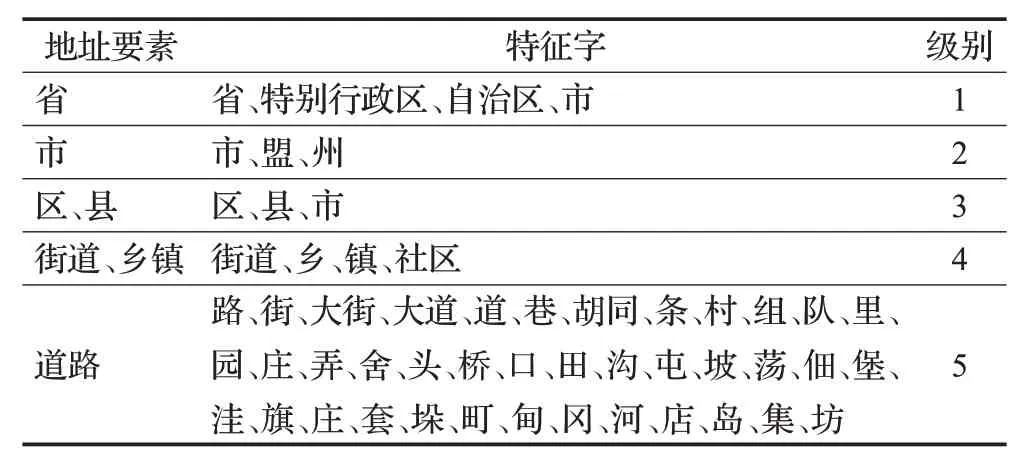
表1 地址要素特征Table 1 Feature of address element
根据该中文地址要素特征表,可以建立53种不同的实体和分别表示上下关系与同级关系的“位于”与“同级”2种实体关系。
通过分析提取标准地址库中的行政区划完整信息后,根据不同级别的地址要素信息,建立地址要素跨级间的关系图谱,作为标准地址知识图谱的基本框架,其地址要素结构框架如图2所示。
接着,通过对标准地址数据进行逆向最大匹配算法,从地址右侧开始进行字符串配对,提取出标准地址中级别最低的地址要素信息作为知识图谱三元组中的尾实体,即提取“路、街、大街、大道”等特征字直到遇到下一个不同级别的地址要素特征字为止。例如地址的名称为“木渎镇金山路33号”,将地址本身作为头实体,提取出“金山路”作为尾实体,“位于”作为实体关系,“33号”则作为实体属性,构造结果如图3所示。
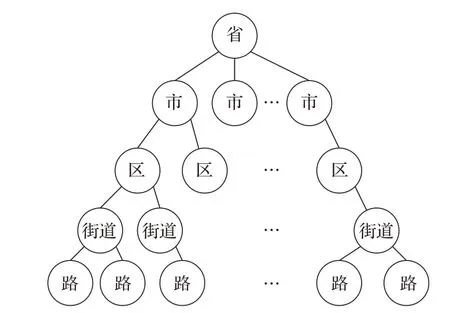
图2 知识图谱中的地址要素结构框架Fig.2 Structural framework of address element in knowledge graph

图3 知识图谱地址实体实例Fig.3 Address entity instance in knowledge graph
尽管名称为“木渎镇金山路33号”的地址中只包含了2个地址要素,但是依靠知识图谱的网络特性,可以根据“木渎镇”作为头实体连接的其他实体关系,在知识图谱中进行多步跳转,通过推理规则达到知识补全的效果。例如“木渎镇”又与“吴中区”相连,之间具有实体关系,通过层层递推,即可将原本的地址名称补全为“江苏省苏州市吴中区木渎镇金山路33号”。
最后,将所有的数据清洗过的标准地址进行实体特征提取并按上述规则录入,就能成功构建出标准地址知识图谱。
1.1.2 POI地址知识图谱
虽然标准地址知识图谱中包含了准确的地址实体关系,且可以通过实体属性明确得知地址的准确信息从而进行更精确的地址匹配,但仅仅使用标准地址知识图谱进行地址匹配并不能满足所有地址情况,在处理仅带有POI特征的中文地址数据时往往出现劣势,甚至会产生极大的误差判断。
POI[14-15]兴趣点表示地图上本身不包含任何地址要素但有实际地理意义的点,如某某银行、小区、学校等等都可以被称为一个POI。POI地址在标准地址库中也会有所记录,可作为“道路”的再下一级的地址要素,如表2所示。但大部分POI特征作为地址单独出现,因此选择在建立标准地址知识图谱进行地址匹配的基础上,创建了POI地址知识图谱进行数据融合,共同解决地址匹配问题,这在一定程度上提高了匹配的准确性与泛用性。
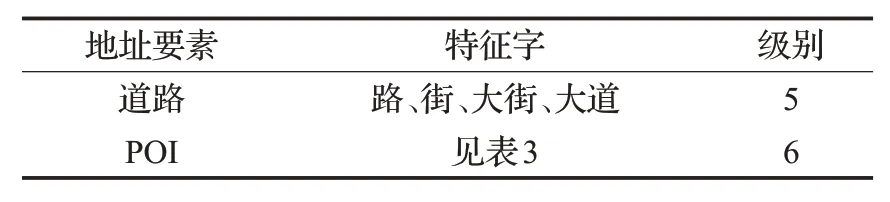
表2 POI作为地址要素Table 2 POI as address element
POI地址数据选择从百度地图API接口爬取获得,根据一级、二级行业对地址进行详细分类,其分类结果可以很好地作为实体属性特征,具体分类情况如表3所示。
尽管大多获取到的POI地址数据名称中并不包含地址要素,但是通过地址信息中记录的行政区划,可以通过代码转化补全一定的地址要素信息,扩充地址实体间的实体关系,构建知识图谱单元。这在一定程度上缩小了实体匹配范围,增大了匹配效率。
同时,建立POI地址知识图谱可以省去地址的共指消歧。例如,标准地址“江苏省苏州市虎丘区学府路99号”与POI地址“苏州科技大学”代表的是同一个地址,这样可以减少数据冗余带来的影响。
1.1.3 待测地址知识图谱
待测地址知识图谱的构建综合了上述两种方法,首先基于提取的特征要素对待测数据进行地址分类处理[16-17]。考虑到非标中文地址的特异性,根据是否能提取到实体关系特征将待测地址分为两种类型:包含特征要素的地址以及不包含特征的无效地址。同时,基于提取的特征要素不同选用不同的实体构造方法:当提取到“道路”地址要素时,选用与标准地址知识图谱相同的构造方法,反之则与POI地址知识图谱构建方法一致。
1.2 基于特征提取的地址分类方法
首先要对待测知识图谱中的每一个地址实体进行地址分类,决定进行实体对齐的对象。但地址名称有时分别包含了两种不同的特征要素,例如“中国石化壳牌交通加油站太仓路店”。
因此不能直接根据提取到的特征要素进行地址分类,选择使用基于选择性注意力机制[18]的知识图谱实体关系抽取方法,通过基于语句级别选择性注意力机制的神经网络模型[19],提取每个知识图谱单元的决定性特征,该方法使用神经网络来提取地址名称中的地址语义特征并以语义向量的形式来呈现。为了充分利用地址中的所有地址要素信息,以及避免远程监督带来的地址错误标注问题,该方法根据地址要素级别在地址语义向量上引入了注意力机制,从而动态地减少噪声实例所对应的权重,同时有效提升有效实体对应权重。最后,将利用注意力机制计算的权重与对应实例向量的加权求和作为特征向量来进行关系抽取,从而得出较为准确的分类结果。
1.3 基于实体关系权重的相似度匹配算法
当标准地址知识图谱以及POI地址知识图谱构建完备之后,便能够与待测地址知识图谱进行地址的实体匹配。在进行地址匹配时,现根据高层次的实体单元,如“市”“区”等缩小实体匹配范围,再选择待测地址知识图谱中底层的实体单元与匹配地址进行基于实体关系权重的余弦相似度计算[20],从而判断是否成功地址匹配。
假定待测地址Ai按照其实体关系进行切分形成序列Xi,匹配知识图谱中的地址Aj按相同方法形成序列Xj,使用文本空间向量表示法将Xi、Xj表示成两个n维的向量,即Xi=(Xi1,Xi2,…,Xin),Xj=(Xj1,Xj2,…,Xjn),n表示两个地址名称的序列总数,Xi与Xj的夹角余弦可以用公式(1)进行计算,当余弦值越趋近于1,两个地址文本就越相似。
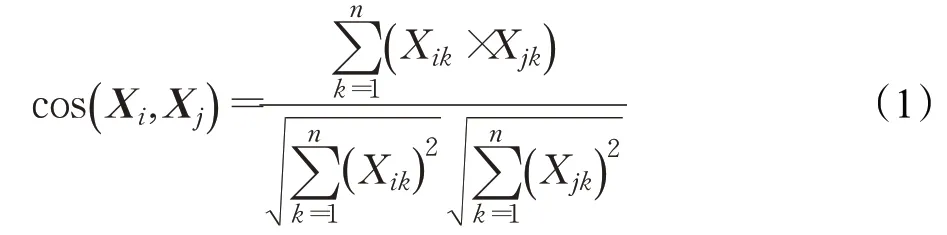
一个的实体通常包括多个实体关系。不同的实体关系在辨识和区分实体方面的能力呈现出不同的差异。在不具有相同实体的数据集中,实体关系越完整且相互间差异性越大的实体识别能力往往越好。在实体匹配过程中实体的关系所具备的识别能力越稳定,被分配的权重[21]也就更高。
由于在标准地址知识图谱中,其地址实体中基于地址要素产生了包括所在市、所在区、所在道路等等实体关系,这些实体关系因地址要素不同对地址信息的影响权重也不同,地址要素所在级别越小,赋予的实体关系权重就越高,权重的具体数值通过对待测地址数据进行实验分析得出。基于实体关系权重的实体相似度计算公式(2)如下:
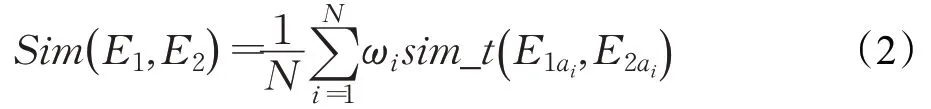
其中,N表示实体对共有实体关系数,E1、E2表示实体,E1ai、E2ai表示实体E1、E2的第i个实体关系,表示共有实体关系的相似度。
对于待测地址中不包含地址要素的POI地址,则通过对POI特征设立权重,其实体相似度方法与上述相同。为了获取各个特征要素所占的权重值,从中选取10%的地址数据作为训练集,5%的地址数据作为测试集进行实验。经过对300条非标中文地址数据的人工分析,综合得出符合需求的最优的权重分配,如表4所示即为地址要素权值分类示例。

表4 地址要素权值Table 4 Example of assigning weights to address elements
2 方法使用案例
2.1 数据集
近年来,随着公安智能监控系统的不断建设,智能感知监控设备逐渐实现城市的大面积覆盖。智能监控设备的应用在管理和保护城市上已经起到了不可或缺的作用。早期的智能监控设备的数据录入工作是依靠地方派出所民警实地记录完成,但缺少统一规范的操作要求,不可避免地出现了其档案数据中大多地址名称不标准、不明确,所记录的地址经纬度信息与实际设备所在地址经纬度误差较大等问题。为了验证本文方法的有效性,选择使用该方法对126 640条设备档案记录种的非标中文地址进行地址匹配。126 640条数据对应生成126 640个地址实体。首先对待测地址进行地址清洗、歧义消除,再将地址进行分类,分类结果如表5所示。

表5 待测地址分类结果Table 5 Results of address classification to be tested
对于此地址分类结果,主要对无效地址进行精确度评估并建立相应的测试集:在126 640条一机一档数据中,抽样选取了100条无效地址,和200条可匹配地址(包含地址要素和包含POI特征的地址各100条),并进行了人工的分析校验,部分地址数据如表5所示。其中100条无效地址中分类正确的有97条,错误的仅有3条。200条可匹配地址中正确的有177,错误的则为23条。因此,可以证明该地址分类方法基本准确,也保证了之后地址匹配的准确性。
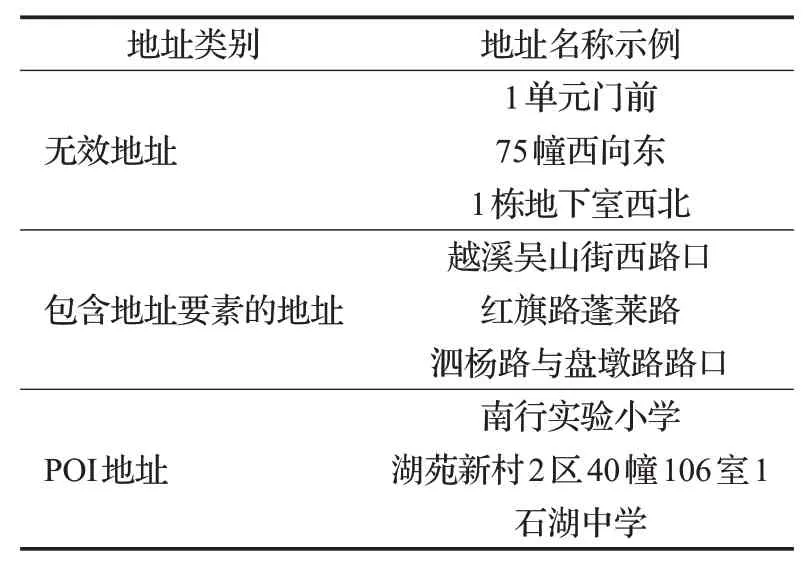
表6 部分地址示例Table 6 Partial address example
2.2 地址匹配结果
在进行地址匹配方法的有效性验证时,一般通过计算该方法的匹配率与准确率。
由于待测地址的数据中包含的地址要素数量与匹配地址中的相比差别过大,导致计算得出的相似度值普遍偏低。从待测地址中抽取了300条匹配结果,通过人工校验发现其中仅有173条数据可视为匹配成功,因此按照经验决定将相似度阈值定为0.6。匹配地址实体中还包含了经纬度属性。当两个地址完成匹配后,分别提取其经纬度属性,由于两个地址数据记录方式以及来源不同,经纬度的坐标系也不同。通过对经纬度进行坐标系转换后,计算两个经纬度的间隔距离,将间距的阈值定为1 000 m。最终决定将地址文本相似度大于0.6的视为匹配成功,成功匹配的地址中相似度大于0.7且两个地址实体经纬度间距小于1 000 m的视为匹配准确。
匹配率计算公式如下:

准确率计算公式如下:
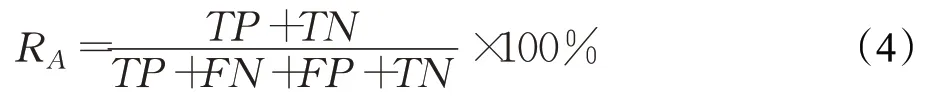
其中,RM表示匹配率,M表示匹配成功的地址个数,N表示待匹配地址的总数。RA表示准确率,TP表示匹配准确的地址个数,FP表示有正确的可匹配对象但匹配错误的地址个数,TN表示无匹配对象而匹配错误的地址个数,FN设为0。
实验采用基于Jaccard相似度[22]的地址匹配方法、基于动态规划的地址匹配方法[23]、基于Sorensen Dice的全文检索地址匹配方法[24]、基于bert4keras预训练[25]的地址匹配方法和本文方法分别对300条非标中文地址数据进行匹配率和准确率的计算。
基于Jaccard相似度的方法在信息检索或者搜索引擎中经常用到,在地址长度相同时有较好的效果;基于动态规划的地址匹配方法不需要进行地址分词,也不需要进行地址要素的特征提取,而是通过动态规划直接计算文本的Levenshtein距离作为相似度判断;基于Sorensen Dice的全文检索地址匹配方法则是当地址要素信息齐全时该方法的匹配结果较好;基于bert4keras预训练的地址匹配方法,采用包含语义的LCQMC数据集并在其基础上加入250条地址语料进行文本相似度的计算,计算耗时3天左右,匹配结果较好。
实验硬件环境:文中使用计算服务器为8核Intel Xeon E5-2640 V2,2.00 GHz处理器,128 GB内存。
由于测试地址数据集中包含了很多无效地址,极大影响了方法对高质量的非标中文地址的有效性检验。因此选择去除其中的无效地址,仅对有效地址进行匹配率和准确率的计算。通过人工的方法从有效地址即包含特征要素的地址中随机抽取300条匹配结果进行测试,实验结果对比如表7所示。
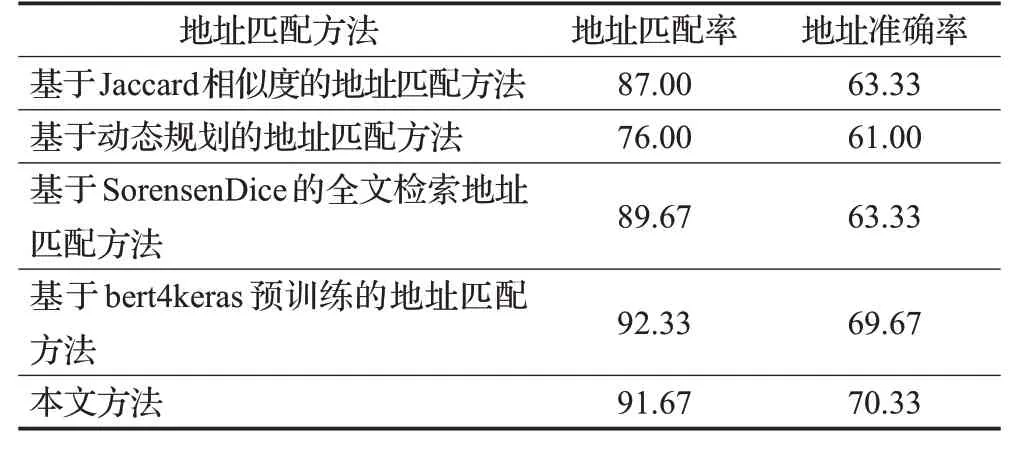
表7 对非标中文地址的匹配结果比较Table 7 Comparison of results of different matching methods for non-standard Chinese addresses %
从实验结果可以看出,本文方法对该非标中文地址数据集有较好的匹配率和准确率,相较于前三种方法分别提高了5.37%、20.62%、2.23%和11.05%、15.30%、11.05%,对于基于bert4keras预训练的地址匹配方法在地址准确率上也有0.95%的提高,匹配率可能由于训练数据集中包含了针对特殊地址的相似度判断处理,因此稍高于本文的方法。
3 结论与展望
本文提出了一种基于知识图谱的中文地址匹配方法研究,与现有的中文地址匹配方法不同,该方法运用到了知识图谱作为存储方式,将地址名称作为实体,地址所包含的特征要素作为实体间关系,构建匹配地址的知识图谱,并且可以随时可视化查询待测地址相关信息。同时对待测地址进行特征分析,构建待测地址的知识图谱,最后选用了基于实体关系权重的相似度算法进行地址匹配。实验结果表明,该算法在处理非标中文地址时优于的常见地址匹配算法,极大提高了地址的匹配率以及准确率。
知识图谱本质上是一种图结构数据,通过图建立知识和数据之间的关系,可以与图神经网络等深度学习技术进行融合。接下来的工作将致力于研究把知识图谱和图神经网络引入自然语言处理[26]之中,更好地对非标中文地址进行文本分类、关系抽取以及特征选择,同时结合实体对齐方法[27],优化地址匹配算法,提高非标中文地址匹配效率,也为地址匹配相关地实战应用做出基础支撑。
