多模态特征融合的视频记忆度预测
2022-07-21常诗颖
常诗颖,胡 燕
武汉理工大学 计算机科学与技术学院,武汉 430070
随着网络技术的飞速发展,实时流媒体和用户生成的视频遍布互联网,研究发现人们对观看的这些短视频的记忆程度并不一样,一些视频可以记住很长时间,而另一些视频转瞬即忘[1]。研究表明记忆度是图像的固有属性[2],让人印象深刻的视频内容有着广阔的应用前景。商家投放高记忆度的视频广告可以帮助公司推销他们的产品,使用电影中令人难忘的精彩片段制作宣传片,可以达到更好的宣传效果。理解影响视频记忆度的因素并有效利用,对摄影师、广告商、视频网站、电影和多媒体制作人都有深远影响。
图像的记忆度预测问题广受关注,Isola等人[2-3]提出了一项图像记忆度的工作,这是图像乃至视频在记忆度方面的开创之作。首先构建了一个记忆游戏实验,用于测量图像记忆度的真实值(ground truth)。实验中受试者被要求观看照片并检测重复照片的演示,图像记忆度被定义为测试者对重复图片的正确检测率,作者建立了一个从低级视觉特征预测图像记忆度的计算模型,使其从视觉特征映射到记忆分数。
有关视频记忆度(video memorability,VM)的研究是近几年才开始的。受文献[3]的启发,Han等人[4]建立了一个类似的方法来测量VM,并提出了一种将视听和功能磁共振成像(fMRI)衍生特征相结合的方法,在记忆视频时传递部分大脑活动。但该方法跨度较长、实验方法昂贵且费时较多,不适合推广。2017年Shekhar等人[5]研究了影响视频记忆度的几种特征,如C3D时空特征[6]、从视频标题中提取的语义特征、显著性特征和颜色特征。但该研究进行人工实验时使用回答问题而不是经典的视觉识别任务来测量视频记忆度,视频收集的可记忆度标注可能不仅反映了视频记忆度的差异,而且反映了问题之间复杂性的差异。2018年Cohendet等人[7]介绍了一种新的方法来度量记忆在一个重要的保留期(即记忆后的几周到几年)后的表现。但注释者没有通过观看视频的学习任务,而是要求填写一份调查问卷,用来收集参与者之前对好莱坞电影的记忆。然而一些参与者有可能在任务之前看到过其中的一些内容(比如好莱坞比较出名的电影片段),导致一些标注偏向于著名的视频内容,问卷的答案完全基于主观判断,使得对记忆表现的测量并不完全客观。2019年Cohendet等人[8]为了解决视频记忆度预测数据集缺乏的问题,引入了一个由10 000个具有记忆分数标注的视频组成的大规模公开数据集(VideoMem),并提出了一个基于深层神经网络的视觉语义特征的预测模型,在短期记忆度预测达到了0.494(长期记忆度预测:0.256)的Spearman相关性。该研究实验体现了视频标题中提取的语义特征取得的预测效果,没有探索对记忆度有影响的特征融合方案,导致实验效果不高。
很多研究者从不同的角度来探讨这个领域,一些工作分析了记忆度和视觉概念之间的相关性,如显著性[5]、颜色[4-5]、审美[2,9]、情绪[7]特征等。也有一些工作关注了视频的音频[4,7]、C3D时空特征[5,7-8]、语义特征如视频标题[8-10]、摘要[5]等。从3D卷积神经网络(3D ConvNets)模型[6]中提取的C3D时空特征在记忆度预测任务中比一般的视觉特征更有效,它更关注于视频空间内容的理解。视频的语义特征在单模态下预测效果突出[8-10]。可能是视频对应的描述性标题具有一定的概括性,能够从全局的角度总结视频的内容。文献[11]的实验给出了与视频记忆度成正相关和负相关的单词列表,目前还没有对该单词列表展开的研究。文献[11-13]使用预训练的深层卷积神经网络提取的视觉特征优于其他所有特征的预测效果,可以更好理解视频中令人难忘的内容。文献[14]探索了深度特征对图像记忆度的影响,实验证明该特征对图像记忆度的预测有明显作用。目前为止还没有相关研究针对视频的深度特征进行视频记忆度的预测。受其启发,本文将探索深度特征对视频记忆度的影响,修改影响视频记忆度的单词的语义特征权重,并与C3D时空特征进行多模态融合。主要贡献如下:
(1)利用文献[15]提出的深度估计模型提取视频的深度特征图,使用预训练的深层卷积神经网络提取深度特征,探索其对视频记忆度的影响。
(2)采用TF-IDF算法提取视频标题的语义特征,对文献[11]列出的对记忆度有影响的单词赋予不同的特征权重。
(3)将视频的深度特征、语义特征、C3D时空特征进行后期融合,提出了一个融合多模态的视频记忆度预测模型,在大型公开的数据集(VideoMem)上进行实验,证明了模型的有效性。
1 视频记忆度融合模型
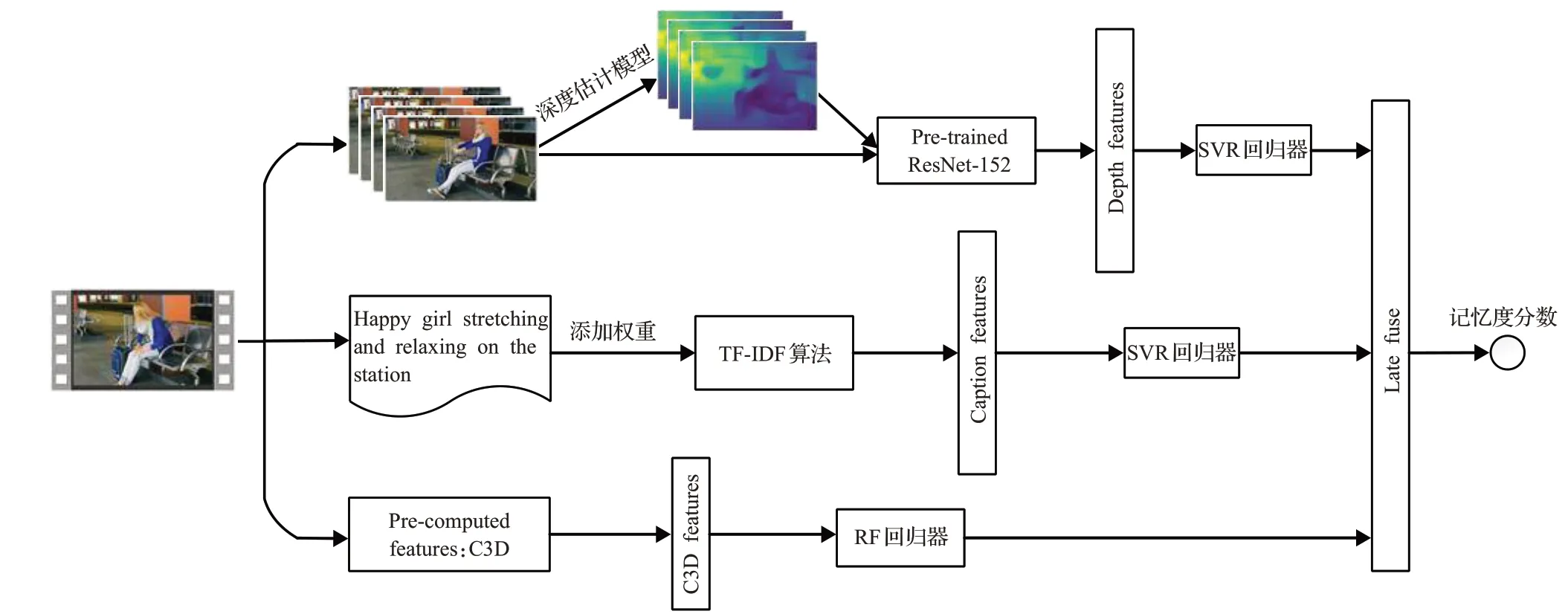
图1 模型总体结构Fig.1 Overall structure of model
视频记忆度融合模型的总体结构如图1所示,将模型整体分为三部分:预处理、特征提取、回归预测与多模态融合。首先将媒体文件进行分帧,提取深度特征、标题所含的语义特征以及视频内容的C3D时空特征,将视频提取到的图片与深度图一起输入预训练的ResNet152网络[16]中提取深度特征以提高预测效果。受文献[11]启发,在提取语义特征时添加相关单词的权重来增强模型预测能力。融合阶段使用晚融合方法通过网格搜索获取最佳特征权重。
1.1 视频记忆度的深度特征
图像深度估计在计算机视觉领域起着重要作用。如视觉显著性[17]、图像去噪[18]和图像质量评估[19]等。场景中各点相对于摄像机的距离可以用深度图(depth map)来表示,即深度图中的每一个像素值表示场景中某一点与摄像机之间的距离。深度图中像素值越低,表示像素离摄像机越近,像素值越高,表示像素离摄像机越远[20]。文献[14]探索了图像深度与图像记忆度之间的关系,发现图像中心包含较近物体的图像比在图像中心包含较远物体的图像更令人难忘。该实验表明,深度特征对图像记忆度的预测效果达到了0.63的图2视频图像与其深度图Spearman相关性,接近人类真实测量值(0.68),证明了该特征对图像记忆度预测有显著作用。用于预测图像记忆度的数据集[21]没有图像深度真实值,他们使用文献[15]中提出的深度估计模型来获得深度特征图。本文使用的VideoMem数据集中也不包含深度特征的真实值,因此也使用该深度估计模型[15]来获取该数据集的深度信息。图2显示了原始视频中切分的某一帧图像和提取的对应深度图。
VideoMem数据集中的每个视频都有其对应的短期和长期记忆度真实值标签,为了了解深度图和视频记忆度之间的关系,本文将数据集中每个视频的记忆度真实值按照短期记忆度由高到低进行排序,选取了几个具有代表性的视频图像,给出了一组具有高记忆度和低记忆度视频图像与其深度图的对比,如图3所示。其中(a)显示了高记忆度视频图像与对应的深度估计图,(b)显示了低记忆度视频图像与对应的深度估计图。可以看出,深度图中心位置靠近相机的物体更容易让人印象深刻,而中心位置远离相机的物体的视频让人易于忘记。
为了探索深度特征对视频记忆度的影响,本文使用了预先训练的ResNset152网络[16]来提取深度特征,ResNset152是卷积神经网络(convolutional neural networks,CNN)中的一种残差网络(residual network,ResNet),152代表了网络的深度。使用残差网络可以有效地解决网络加深后性能退化的问题。将视频原始图像与深度特征图一起输入ResNset152网络来提取深度特征和视觉特征,然后进行回归预测可以达到更高的实验效果。实验将在后续章节详细介绍。

图3 高记忆度和低记忆度的视频图像与深度图Fig.3 High and low memorability video images and depth maps
1.2 视频记忆度的语义特征
视频的语义信息在记忆度预测方面有重要的作用,VideoMem[22]数据集中提供了每个视频的标题,该标题信息是对视频的一个概括性描述。研究发现与自然景观有关的单词与视频记忆度呈负相关,与人和人物动作相关的单词与视频记忆度呈正相关[11]。根据VideoMem数据集中的记忆度分数真实值标签的排序,图4列出了3个数据集的记忆度实验中短期记忆度预测最令人难忘和最不令人难忘的视频和对应的记忆度真实值得分,可以看出记忆度得分最高的3个视频中都出现了人物和人物相关动作,而记忆度得分最低的3个视频中都是自然景观。受其启发在视频的标题中对记忆度预测有影响的词语进行了深入研究。

图4 高记忆度得分和低记忆度得分的视频对比Fig.4 Comparison between high memorability score and low memorability score videos
自然语言处理领域中TF-IDF算法(term frequencyinverse document frequency)表示词频-逆向文档频率,TF是词频(term frequency),IDF是逆文档频率(inverse document frequency)。该算法用以评估字词对于一个文件集或一个语料库中其中一份文档的重要程度,其定义如下:

表示词汇ti的TF-IDF权重值。其中tfi,j表示词汇ti在文档dj中的频率,定义如下:

ni,j表示词汇ti在文档dj中出现的次数,表示文档dj中所有词汇中出现的次数。
i dfi表示逆文档频率,定义如下:

|D|是语料库中的文件的总数,|{j:ti∈dj}+1|表示包含词汇ti的文件数目。
TF-IDF算法的主要思想是:如果某个词或短语在一篇文章中出现的频率较高,而在其他文章中很少出现,则认为该词或者短语具有很好的类别区分能力[23]。TF-IDF算法对比较少出现的单词给予重视,经常出现在标题中的词的权重减少。较少出现在标题中的单词被赋予更高的权重。这样可以确保记忆度分数取决于一个单词而不是整个句子。这样在测试集中出现了罕见的单词时,该模型可以认识到它们的重要性并能更好地预测得分。该算法适合当前视频语义信息的特征提取。本文对特定单词添加不同权重并使用支持向量回归算法(support vector regression,SVR)构建模型,取得了优于其他基于语义信息预测视频记忆度的结果,实验将在后续章节详细介绍。
1.3 视频记忆度的C3D时空特征
VideoMem数据集提供方[22]为了方便研究者进行视频记忆度预测方向的研究,提供了一些预先计算的特征,如梯度方向直方图(histogram of oriented gradients,HoG)、局部二值模式(local binary pattern,LBP)特征、美学视觉特征(aesthetic visual features,AVF)、颜色特征、C3D时空特征,研究者可以直接使用这些提取好的特征进行不同模型的预测或其他方法的探索。C3D时空特征是从3D卷积神经网络模型[6]中提取的,这是一种用于通用视频分析的三维卷积网络。C3D时空特征作为视频的一种动态特征,可以对视频中的时空信息进行编码,用于视频内容的分析。VideoMem数据集提供了卷积神经网络C3D模型最后一层的输出,可以将其用于视频记忆度的预测。文献[7-8,11-12]使用了C3D提取的特征和其他模态的特征单独构建预测模型。C3D特征对视频记忆度预测比数据集提供的其他预先计算的特征有更好的预测效果。受其启发本文构建不同的回归预测模型,尝试使用VideoMem数据集提供的预先计算的C3D时空特征进行视频记忆度的预测,探索视频令人难忘的时空因素。
1.4 融合方法
在融合方法上尝试了早融合和晚融合两种融合方法。其中早期融合是指对每种模态提取的特征在分类或回归操作前进行融合。在实验结果中晚融合模型的预测效果优于早融合,原因可能是由于不同的特征有不同的特征空间和含义,直接合并产生了“语义鸿沟”,导致了预测性能下降。如何消除多模态的“语义鸿沟”,考虑多模态间的关系,仍然是一个需要解决的技术问题。因此选择晚融合作为特征融合策略。
晚融合又称后期融合,第一步先提取不同模态的特征描述,然后将每个模态的特征用来训练各自独立的回归模型,来自不同模型的预测分数被组合起来产生最终的分数。晚期融合方案将学习到的单模态分数合并成多模态表示。晚融合模型结构如图5所示。晚融合着重考虑基于单个特征模型的预测效果。融合阶段有许多方法来合并分数。本文使用加权平均方法,假设深度特征的回归模型预测得分为η1,语义特征的回归模型预测得分为η2,C3D时空特征的回归模型预测得分为η3,那么晚融合模型的最终得分为:

其中,ω1、ω2、ω3分别是三种模型的权重,通过网格搜索算法获得三者的值。
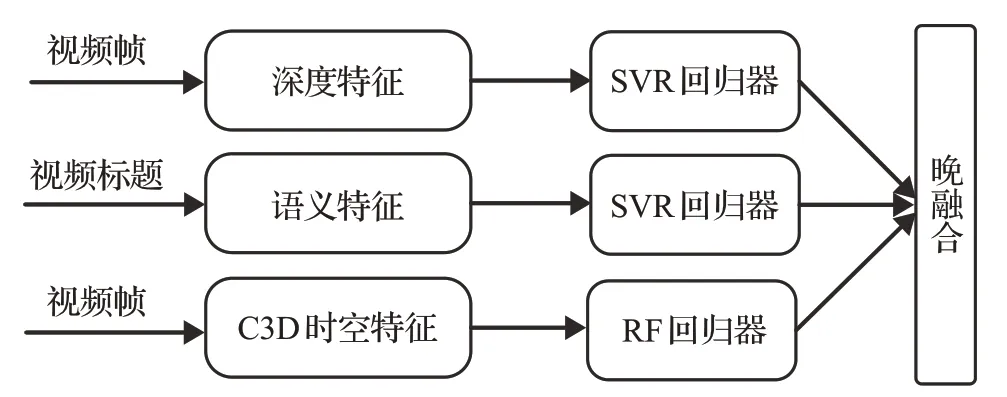
图5 晚融合模型示意图Fig.5 Schematic diagram of late fusion model
1.5 总体流程
融合视频深度特征、语义特征和C3D时空特征的计算模型总体流程如下:
步骤1视频预处理
将训练数据集中的每个视频进行分帧,一个视频被平均分为4帧图像。
步骤2提取深度图
将提取的4张图像输入深度估计模型[15],每个视频提取到4帧深度图。
步骤3提取深度特征
将上述步骤1和步骤2提取的4张原始图像和4张深度图一起输入预训练的ResNet152网络,提取深度特征。
步骤4深度特征预测模型
构建基于深度特征的回归模型,通过网格搜索方法选择最佳参数。
步骤5视频标题预处理
对训练数据集中的每个视频对应的标题进行预处理,去除特殊字符,所有英文字母都变成小写,去除停用词,留下有意义的单词,然后进行词干处理。
步骤6添加权重
给处理后的文本数据中对视频记忆度有影响的单词添加不同权重,计算词频和词频逆文档频率。
步骤7语义特征预测模型
构建基于语义特征的回归模型,通过网格搜索方法选择最佳参数。
步骤8提取C3D时空特征
提取预先计算的C3D时空特征,得到101维度的特征向量。
步骤9C3D时空特征预测模型
构建基于C3D时空特征的回归模型,通过网格搜索方法选择最佳参数。
步骤10多模态后期融合
将每个单模态特征进行后期融合,通过加权平均方法开展实验,使用网格搜索选择最优融合权重。
步骤11评价指标计算
将融合模型预测的视频记忆度得分与真实值做Spearman相关系数的计算,得出最终结果。
2 实验
2.1 实验环境
本文实验硬件环境与配置为:Ubuntu 18.04操作系统,借助GeForceGTX 2080 GPU进行加速处理,使用Keras深度学习框架。
2.2 数据集与预处理
最近视频记忆度预测得到研究者的广泛关注,数据集也在不断发展更新,在近几年的研究中也有相关作者构建的带标注的数据集,但由于数据集太小、构建的数据集选取有一定的主观性等原因,没有采用之前的数据集进行实验,而是采用MediaEval 2019 Media Memorability Prediction Task中提供的大型公开数据集VideoMem。这是目前最大的带视频记忆度真实值标签的数据集,该数据集由10 000个7 s的无声视频组成。这些视频是从专业人士制作视频时使用的原始视频中提取出来的,内容和场景丰富,包含不同的场景类型。数据集包含两种标签,即长期记忆标签和短期记忆标签,分别对应于两个子任务:短期记忆度任务和长期记忆度任务,短期记忆度任务反映了观看视频几分钟后记住的可能性;长期记忆度任务反映了观看后1到3天记住的可能性[24]。该数据集分为两部分:8 000个开发集和2 000个测试集。其中8 000个开发集给出了对应的记忆度真值的标签,而2 000个测试集并没有提供测量的真实的记忆度值,数据集提供方考虑今后可能有更多其他用途。因此本文将8 000个视频的开发数据集随机划分成7 000个训练集和1 000个测试集。
预处理过程首先将视频进行分帧,VideoMem数据集中的每个视频均为7 s,为了防止背景干扰去除头尾2帧数据,每个视频固定采样4张图片,然后利用这4张原始图片输入深度估计模型[15]来提取深度图,将采样后的图像大小统一调整为224×224,并将提取到的深度图与原始图片一起输入预训练的ResNet152网络。文本信息是从视频标题中提取的,经过删除停用词、合并同义词等预处理后,选取具备代表性的关键词(如名词、动词、数量词、副词和形容词)作为语义特征。根据TF-IDF算法计算词频逆文档频率。受文献[11]研究的启发,对出现该文献中列出的单词的每个视频添加计算出的权重,并与基于TF-IDF算法提取到的语义特征进行连接操作最终得到5 089维的特征向量。表1列出了为这些单词设置的权重值。C3D时空特征是描述视频时空内容的特征,在VideoMem数据集中提供了预先计算的特征,可以直接用来构建预测模型。他们提供了卷积神经网络C3D模型最后一层的输出,最终得到101维的特征向量。
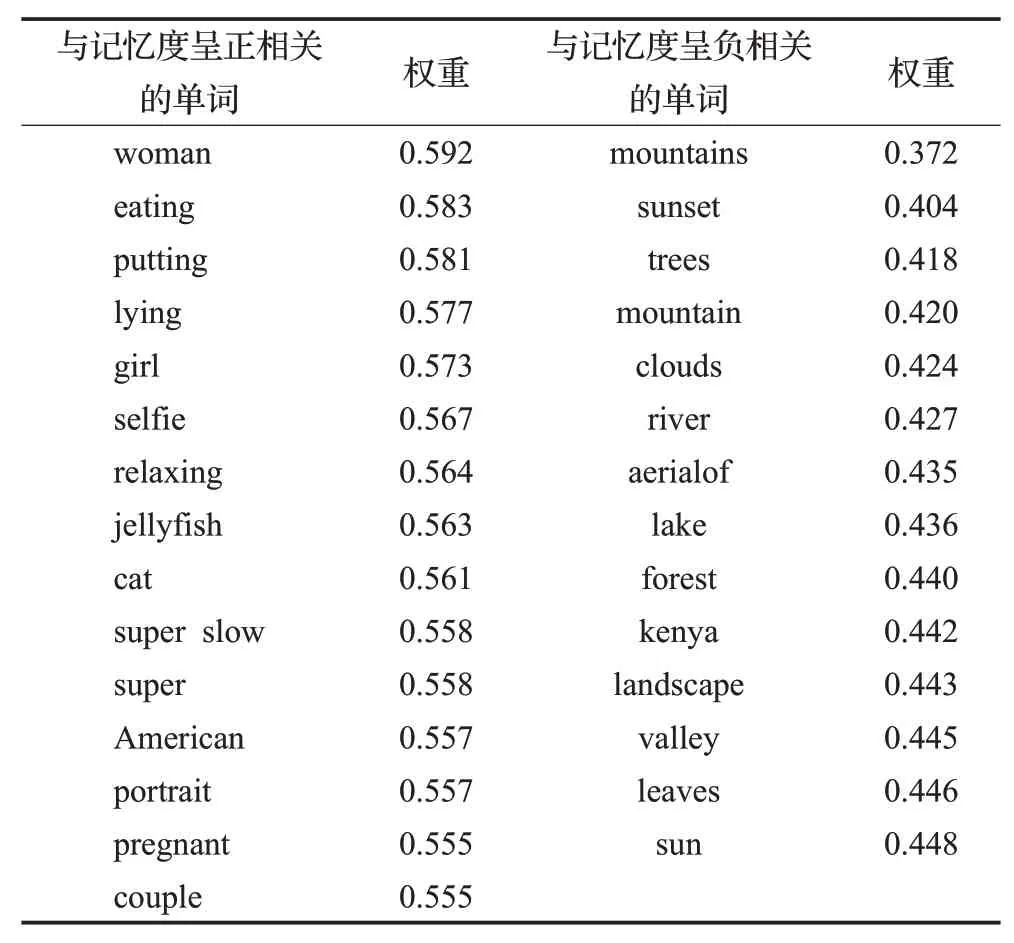
表1 影响视频记忆度的单词及其权重Table 1 Words and their weights that affect video memorability
2.3 评价指标
本文采用广泛使用的官方指标来评价模型的预测效果:Spearman相关系数(Spearman’s rank correlation coefficient)。Spearman相关系数是预测视频记忆度的常用指标[22],对于样本容量为n的样本,n个原始数据被转换成等级数据,Spearman相关系数ρ为:
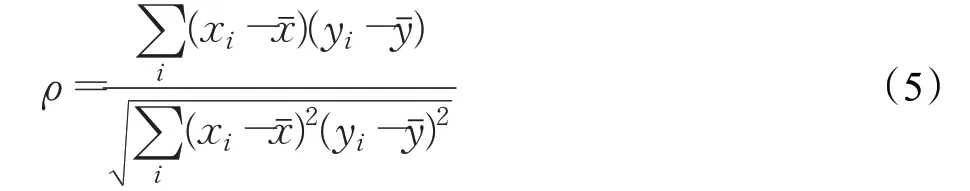
它利用单调方程评价两个统计变量的相关性。如果数据中没有重复值,并且当两个变量完全单调相关时,Spearman相关系数则为+1或-1。使用Spearman等级相关系数作为预测视频记忆度的评价指标,在不同的方法之间进行比较,通过考虑基本真实值和系统预测值之间的单调关系,可以对不同系统的输出进行规范化,并允许测试集中不同视频样本的等级对系统进行评估。
2.4 实验设置
视频预处理后使用预训练的ResNet152网络作为特征提取器来提取深度特征,ResNet152网络是在ImageNet上进行预训练的,选择平均池化操作,采用最后一个卷积层的输出,每张图片都是2 048维的特征表示,8张图片连接后组成16 384维的特征向量。将4张原始图片和4张深度图一起输入网络的目的是利用深层的卷积神经网络提取图片中蕴含的视觉信息,可以有效提高视频记忆度的预测效果。视频语义特征的提取中针对与视频记忆度呈正相关和负相关的单词的权重参考了文献[11]中提供的研究实验。
视频记忆度预测作为一项回归任务,多数研究利用回归算法预测视频记忆度分数。由于高维度的特征可能存在多重共线性问题,因此在融合阶段使用了SVR算法、随机森林(random forest,RF)算法等基线回归模型。通过实验结果验证,基于深度特征的预测模型使用了SVR算法,利用网格搜索算法,选择惩罚系数C为0.1,核函数为RBF,不敏感间隔epsilon为0.05;基于语义特征的修改权重的预测模型也使用了SVR算法,利用网格搜索算法,选择惩罚系数C为0.5,核函数为RBF,不敏感间隔epsilon为0.05;基于C3D时空特征的预测模型使用了RF算法,采用网格搜索选择森林中树的个数n_estimators为290。晚融合实验中使用加权平均的方法进行融合处理,使用网格搜索实验验证,深度特征、语义特征、C3D时空特征权重分别在取0.6,0.35,0.05的值时,取得最佳预测效果。
2.5 实验结果与分析
实验环节分为6个部分。表2展示了4张深度图(depth maps)、4张视频原始图片(original images)、深度图加原始图片(depth maps&original images)分别输入预训练的ResNet152网络中提取的特征进行视频记忆度预测的消融实验,可以看出深度特征预测效果在短期记忆度预测中达到了0.320的Spearman相关性(长期记忆度预测结果:0.140),说明了深度特征对于视频的记忆度预测有积极作用。而视频原始图片提取的视觉特征的预测效果要比深度特征更好,达到了0.522的Spearman相关性,说明记忆度预测任务更关注于视觉信息,深层的ResNet网络可以有效地学习到图像中令人难忘的视觉信息。将原始图片和深度图一起进行特征提取可以提高实验预测效果。
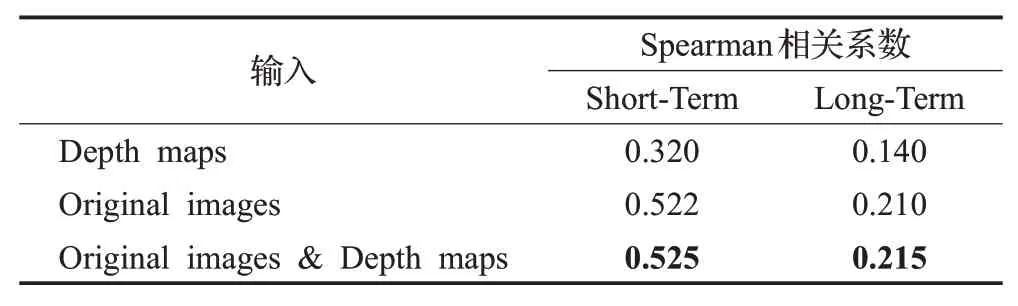
表2 不同图像输入ResNet152网络的消融实验Table 2 Ablation experiment of different images input into the ResNet152 network
表3列出了不同的研究中使用预训练的深层卷积神经网络提取的特征的预测结果。Gupta等人[11]从视频中提取了第1帧、第56帧、第112帧图片作为预训练的ResNet50网络的输入,每张图片从网络倒数第二层提取到2 048维的特征向量,Azcona等人[12]将视频固定每秒分割一张图片,得到8张图像作为预训练的ResNet152网络的输入,每张图片从最后一个卷积层提取到2 048维的特征向量,Leyva等人[13]提取视频中间一帧图片作为预训练的ResNet152网络的输入,从最后一个全连接层提取到1 000维的特征向量。本文的预测模型将数据集中的视频固定每41帧提取一张图片,每个视频得到4张图片,并与提取到的4张深度图一起(original images&depth maps)作为预训练的ResNet152网络的输入,从最后一个卷积层提取特征,最终得到16 384维的特征向量。可以看出本文的深度特征提取方法可以进一步提高预测效果,表明深度特征可以帮助捕获视频中令人难忘的内容。
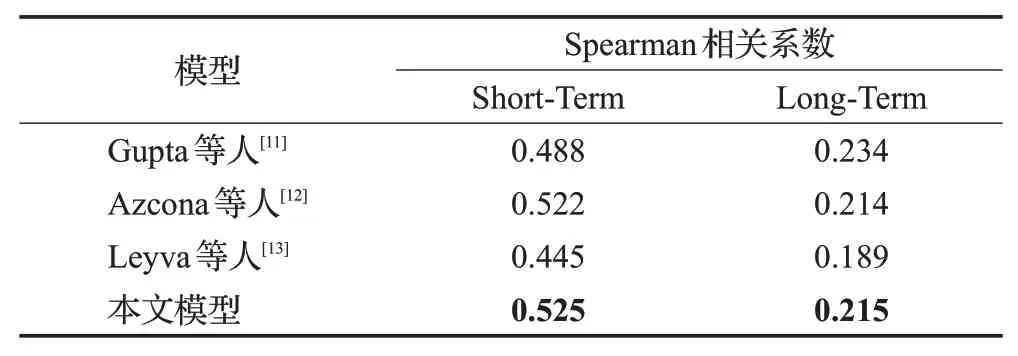
表3 ResNet网络提取的特征的对比实验Table 3 Comparative experiment of features extracted by ResNet network
表4是基于TF-IDF算法添加权重的语义特征模型与其他基于语义特征模型的对比,Sun等人[9]采用了词嵌入的方法提取语义特征和RNN的预测模型进行记忆度分数预测,Gupta等人[11]使用了CountVectorizer提取语义特征的模型,王帅等人[24]使用ConceptNet[25]模型进行语义特征处理,文献[26]使用了Word2Vec进行语义特征提取。本文基于TF-IDF算法添加权重后的特征提取方法在短期记忆度预测任务有更高的Spearman相关性。在长期记忆度预测中提升效果不明显。有可能的原因是视频中长期记忆度与自然景观和与人相关的内容的相关性不大。
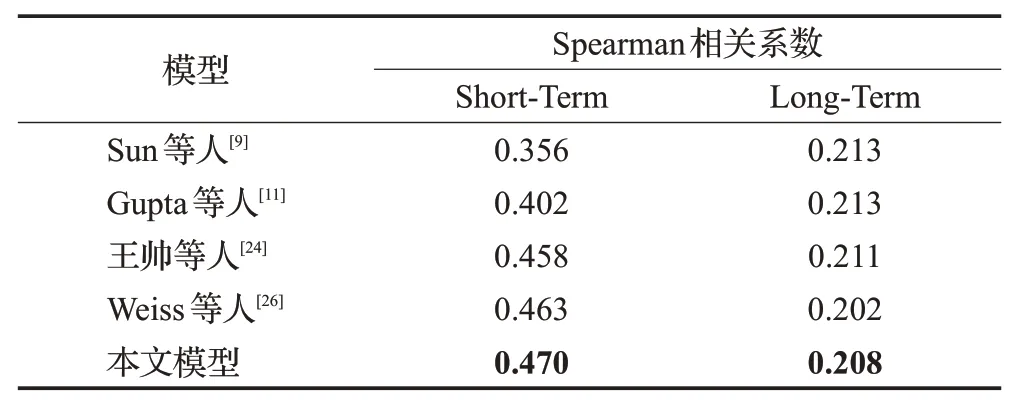
表4 基于语义特征的模型对比实验Table 4 Model comparative experiment based on semantic features
表5是在预测视频记忆度分数时三种特征选择两种不同的回归模型的对比实验。由表可知无论在长期记忆度预测任务还是短期记忆度预测任务中,深度特征和语义特征使用SVR回归模型的预测效果都比RF回归模型好,而C3D时空特征使用RF回归模型较SVR回归模型有更好的预测结果。因此在单模态视频记忆度预测中分别使用其最佳的回归模型进行实验。
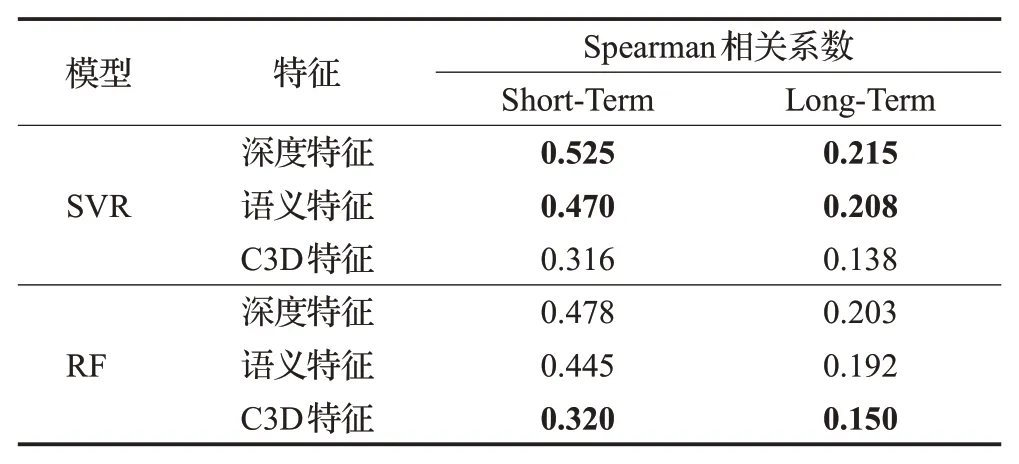
表5 不同的回归模型的对比实验Table 5 Comparative experiment of different regression models
表6是本文提出的不同的特征在单模态、双模态和多模态下预测视频记忆度分数的消融实验。单模态下预测效果最好的是深度特征,深层的ResNet网络提取的深度特征包含了更多的细节信息,可以学习到图像中令人难忘的视觉内容。其次是语义特征,语义特征作为全局性描述视频内容的特征也发挥了很好的预测作用,相比之下C3D时空特征的预测效果不是很好,可能是由于数据集中的很多视频都属于某一个特定场景,视频中的动态因素较少,导致捕获的3D时空信息不足以达到更好的预测结果。同时可以看到无论哪两种特征进行双模态特征融合,视频记忆度预测效果都没有3种特征融合后的预测指标好,证明了本文提出方法的有效性。
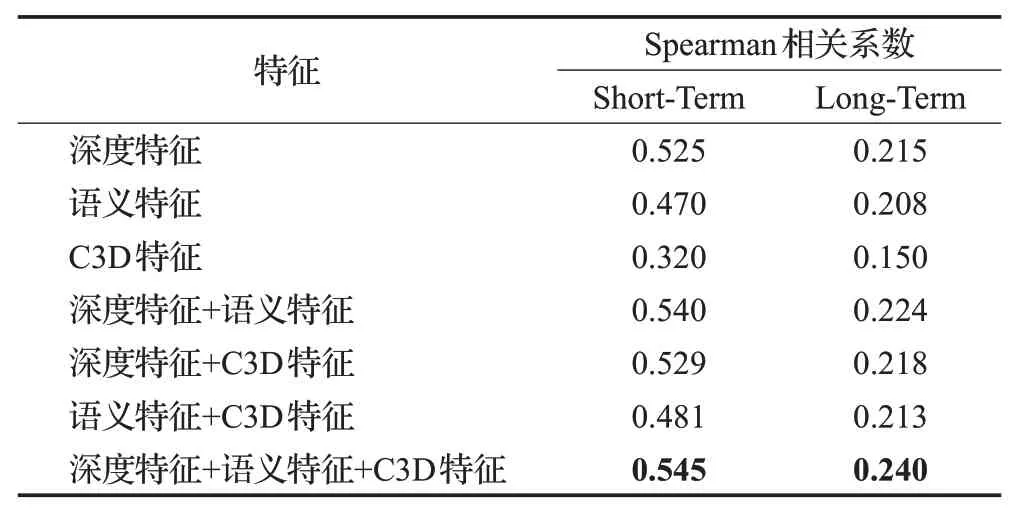
表6 不同特征预测视频记忆度分数的消融实验Table 6 Ablation experiment of predicting video memorability scores with different features
表7是本文提出的多模态视频记忆度预测模型与以往论文的研究模型的对比实验,所有模型的短期记忆度预测指标都高于长期记忆度,说明了短期记忆比长期记忆更具可预测性。在短期记忆度预测结果中,本文提出的融合多模态的视频记忆度预测模型与之前的方法有明显的提高,但是长期记忆度预测似乎没有很好的性能提高。可能的原因是长期记忆度预测更依赖于个人的记忆能力。晚融合中三种模态的权重比例可知,深度特征在融合中所占权重最大,说明了深度特征在该记忆度预测任务中更有效。
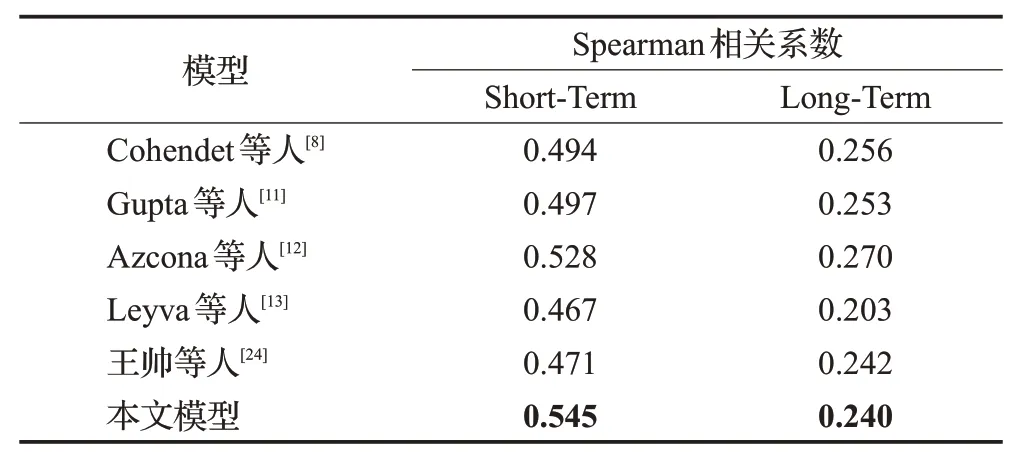
表7 不同的视频记忆度预测方法的对比实验Table 7 Comparative experiment of different video memorability prediction methods
图6给出了几个长期记忆度分数较低的视频中,使用本文提出的融合模型预测出的长期记忆度分数和其真实值的对比,可以看出在长期记忆度预测真值较低的视频中既有与自然景观相关的视频,也有与人相关的视频,这似乎与短期记忆度表现出的规律不完全符合,长期记忆度预测似乎更偏向于记住一些更新奇、人物情绪更激烈、动作更多的视频,同时也体现了每个人的记忆差异。

图6 长期记忆度预测值与真实值对比Fig.6 Long-term memorability prediction value compared with its ground truth
3 结束语
本文提出了一个多模态特征融合的视频记忆度预测模型,使用预训练的ResNet152网络提取深度特征,使用TF-IDF算法进行语义特征提取,并对视频记忆度有影响的单词赋予不同的权重,然后与视频的C3D时空特征进行多模态融合,晚融合加权平均的方法在实验中取得了最佳预测效果,证明了模型的有效性。模型的预测效果在视频记忆度预测任务中有了一定的提高。
未来的工作将重点关注视频中传达的运动信息和人物情绪特征,深入探索影响长期记忆度预测的因素,使用深层神经网络的方法探索对视频记忆度的影响,发掘更多影响视频记忆度的特征,尝试不同的特征融合方案,设计更加稳定的模型来预测视频的记忆度。
