基于深度学习的关键词生成研究综述
2022-07-21李艳玲
于 强,林 民,李艳玲
内蒙古师范大学 计算机科学技术学院,呼和浩特 010022
随着大数据时代的到来,衍生出大量缺少关键词的文本,如何以一组词语有效地表示语言文本所隐含的核心信息,已成为当下的热门研究方向。关键词提取作为自然语言处理(natural language processing,NLP)中的经典任务,其应用场景非常广泛。通过关键词提取技术获得的关键词可用于协助自然语言处理的下游任务,如信息检索、文本摘要、文本分类和观点挖掘等。
关键词被视为文本中重要主题信息的描述和总结,是概括文本的最小单位,也被认为是文本的最小摘要,可以有效地用于理解、组织和检索文本内容。例如在学术出版物中,文章开头的关键词部分提到了最能代表其内容的词语,读者可以通过关键词决定是否阅读全文。各类信息系统也可以利用关键词轻松完成文本分类和快速检索等工作。文本的数据是庞大的,导致在网络上搜索任何主题时,访问与主题相关的文本可能会遇到困难。如果有一些词语(关键词)来代表文本的内容、主题等主要特征,就可以更轻松地检索到相关文本。根据关键词提取技术的发展历程,可以将其细分为关键词抽取阶段与关键词生成阶段。其中,关键词抽取阶段指从原文中筛选能表达文本主题的词语作为关键词,该关键词必然在文本中出现;关键词生成阶段指从词表或原文中选择与文本主题最契合的词语作为文本的关键词,与该关键词是否在文本中出现无关[1]。
由于关键词的重要性以及它带来的便利性,1957年起,Luhn等人[2]开始陆续对关键词抽取任务展开研究。初始抽取算法得益于抽取速度和操作简易,主要遵循以下三个步骤:首先是进行分词,去停用词;其次利用文本特征如词频、词性、词的位置、词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)等对候选词进行筛选;最后通过相应指标对候选词进行排序,选择排名靠前的作为关键词。接着衍生出各种监督算法、半监督算法以及其他无监督抽取算法。
2017年,Meng等人[3]在相关研究中发现关键词是否在原文中的比例近乎一致,意味着不存在于原文中的关键词对于提取研究同样重要,也反映出关键词抽取方法所存在的缺陷:(1)只能抽取原文本中出现的词语作为关键词;(2)主要依靠文本的浅层特征来抽取关键词,因此很难挖掘和充分利用文本背后潜在的语义信息。现实中,关键词通常是作者理解了文本语义和主题所指定的关键信息,意味着作者可以依靠自身的阅历和与该主题相关的外部知识为文本补充更恰当的关键词[4]。
随着深度学习(deep neural networks,DNN)技术的发展,应用于自然语言生成(natural language generation,NLG)领域的序列到序列(sequence to sequence,Seq2Seq)模型在解决许多问题上取得了比现有方法更好的效果。它早期应用于机器翻译[5]任务,解决了原始序列与目标序列长度不相等问题,取得了不错的反响。越来越多的研究者也将其应用于关键词生成(keyphrase generation,KG)领域[6]来解决抽取方法存在的缺陷。Seq2Seq模型是一种编码器-解码器(encoder-decoder)神经网络,其中编码器通过捕捉原文本关键信息形成特征向量表示,解码器通过语言模型从预定义词汇表中生成关键词的概率分布,和依照复制机制[7]计算原文中关键词的概率分布选择当前时刻概率最大的词作为关键词。由于其弥补了关键词抽取方法的缺陷,基于序列到序列模型的关键词生成技术成为了当前领域的研究热点。
因而本文重点分析序列到序列关键词生成模型,依照不同的训练方式将其分为有监督学习、半监督学习、无监督学习以及深度强化学习,并对各类方法的原理和功能进行分析。
1 关键词生成
关键词生成方法采用了序列到序列模型,该模型本质上用到了两个循环神经网络(recurrent neural network,RNN),分别叫做编码器和解码器,前者用来获取输入文本词序列的关键信息,后者根据传递的信息逐项生成关键词序列。这种方法更符合用户的真实行为,图1给出了关键词生成数据集Inspec[8]的一个示例,蓝色斜体字代表原文中的关键词。

图1 关键词生成示例Fig.1 Example of inspec
1.1 模型的形式化定义
基于序列到序列模型的关键词生成方法包含三个部分:
(1)编码器:将原文按词序列X=<x1,x2,…,x||n>传入到编码器中,每个词经过编码器内部处理输出上下文特征向量作为隐状态h。
(2)上下文向量C:保存编码器输出状态向量,继而传给解码器进行解析处理。
(3)解码器:对编码器传来的上下文向量进行解析,产生输出序列Y=<y1,y2,…,y||m>,具体模型表示如图2所示。

图2 序列到序列模型Fig.2 Sequence-to-sequence model
1.2 关键词生成任务的数据集
(1)主流语料库
开放数据倡议和数据科学竞赛鼓励了越来越多数据集的创建和共享,自然语言处理数据集是解决特定任务的各种文本集合。在关键词生成领域,最流行的文本数据集合如表1所示。
Inspec是最早的数据集之一,其中探索了各种语言特征在关键词提取中的作用。它由2 000篇英文摘要组成(1 000个用于训练,500个用于验证,500个用于测试),其相应的标题和关键词来自Inspec数据库,摘要来自1998年至2002年计算机与控制、信息技术等学科出版的期刊论文。每个摘要都有两类由专业标注人员指定的关键词:一类仅限于Inspec同义词表中的词汇;另一类可以是任何合适的词汇。

表1 数据集信息Table 1 Dataset information
NUS[9]是最小的数据集之一,由211篇会议论文组成。每篇论文都有两组关键词:第一组由作者设置,第二组由学生志愿者们创建。另一个小数据集是SemEval(或SemEval-2010)[10],它由288篇论文组成,144篇用于训练,100篇用于测试,40篇用于验证。它们分别来源于ACMDigital中会议论文和研讨会记录。Krapivin[11]提供有2 304篇ACM于2003—2005出版的计算机科学领域发表的论文,每篇至少包含一位专家为文章指定了关键词。每篇文章的不同部分如标题,摘要被分开标记以简化各种关键词的提取。
从TREC-9收集的文章DUC(或DUC-2001)[12]数据集在新闻领域很受欢迎。它由308篇新闻文章和2 488个手动标注的关键词标签组成,每个文档的平均关键词数为8.08,每个关键词的平均字数为2.09,广泛应用于跨域测试。
上述公开数据集的规模都比较小,Meng等人制作了一个大型数据集KP20k[3]。它由567 830篇计算机科学领域的论文组成,527 830篇用于训练,20 000篇用于验证和20 000篇用于测试。KP20k被广泛用于训练和评估各种关键词生成方法。
上述数据集大多由学术文档(摘要或全文)和非专家标注的关键词组成。在学术文本以外的领域中,缺乏能够供神经生成模型训练的大量由专家标注的数据集。KPTimes[13]填补了这一空白,并提出一个由279 923篇新闻文章组成的数据集,其中包含编辑指定的关键词。在线新闻中包含最初由人工分配用于搜索引擎的词语,Gallina等人将这些元数据视为真实值来自动构建数据集,用于训练和测试关键词生成的深度神经网络模型。大型数据集也推动了其他自然语言生成任务的进程。
目前,关键词生成的英文数据集居多,中文数据集相对较少。为弥补中文社交媒体领域关键词生成数据集的空白,Weibo[14]数据集应用而生。它的数据来源于2014年1月至8月社交媒体微博中的所有帖子,它由46 296篇社交媒体帖子组成,将数据以80%、10%、10%分为三个子集,分别对应于训练集、验证集、测试集。由于其文本的非正式和口语化性质,Weibo被广泛应用于社交媒体这一类短文本的关键词生成中。
(2)大型语料库
对科学论文的关键词进行实验已成为一种趋势,这在很大程度上受到在线学术知识库中数据可用性的推动。2019年,Cano等人[15]制作了一个更大的数据集,由科学论文中关键词、标题和摘要组成。来源于开放学术图谱的全部数据,检索了关键词、标题和任何可用的抽象数据,使用语言过滤器删除了所有非英文文本记录,并用斯坦福CoreNLP分词器对文本进行小写和分词,标记标题和摘要文本,得到了数据集OAGKX,大约有22 674 436条数据,数据集样本在文件中存储为JSON形式。
2 相关工作
有监督的学习方法需要获取大量有标注的数据,是一种成本较高的学习方法,而不依赖于标注数据的无监督学习,模型的整体性能较差。半监督和深度强化的学习方法的出现,正好可以中和这一问题,使用较少的标注数据来进行训练。下面对基于深度学习的关键词生成方法分别从这四个方面展开详述。
2.1 基于有监督的关键词生成方法
2.1.1 基于复制机制的Seq2Seq关键词生成模型
随着Seq2Seq模型在机器翻译任务中取得不错的效果,大量研究者尝试用该模型来完成关键词生成任务。2017年,Meng等人[3]针对现有关键词提取方法无法生成不存在于原文中的关键词这一缺陷,首次提出了结合复制机制的Seq2Seq模型(CopyRNN),模型结构如图3所示。
CopyRNN模型中的编码器用于创建原文本的隐状态表示向量,原文的词序列Xseq=<x1,x2,…,x||m>作为模型的输入,词嵌入层[16]将每个词映射到向量空间,随后传输到由双向GRU(gate recurrent unit)组成的编码器来完成上下文语义交互信息并输出隐状态向量,具体过程为将长度可变的输入序列通过公式:ht=f(Vt,ht-1),随着时间t迭代转换为编码器的隐状态<h1,h2,…,h|m|>。其中,每一时刻的隐状态由当前时刻输入的词嵌入Vt和上一时刻的隐状态ht-1经过一种非线性函数f求得。
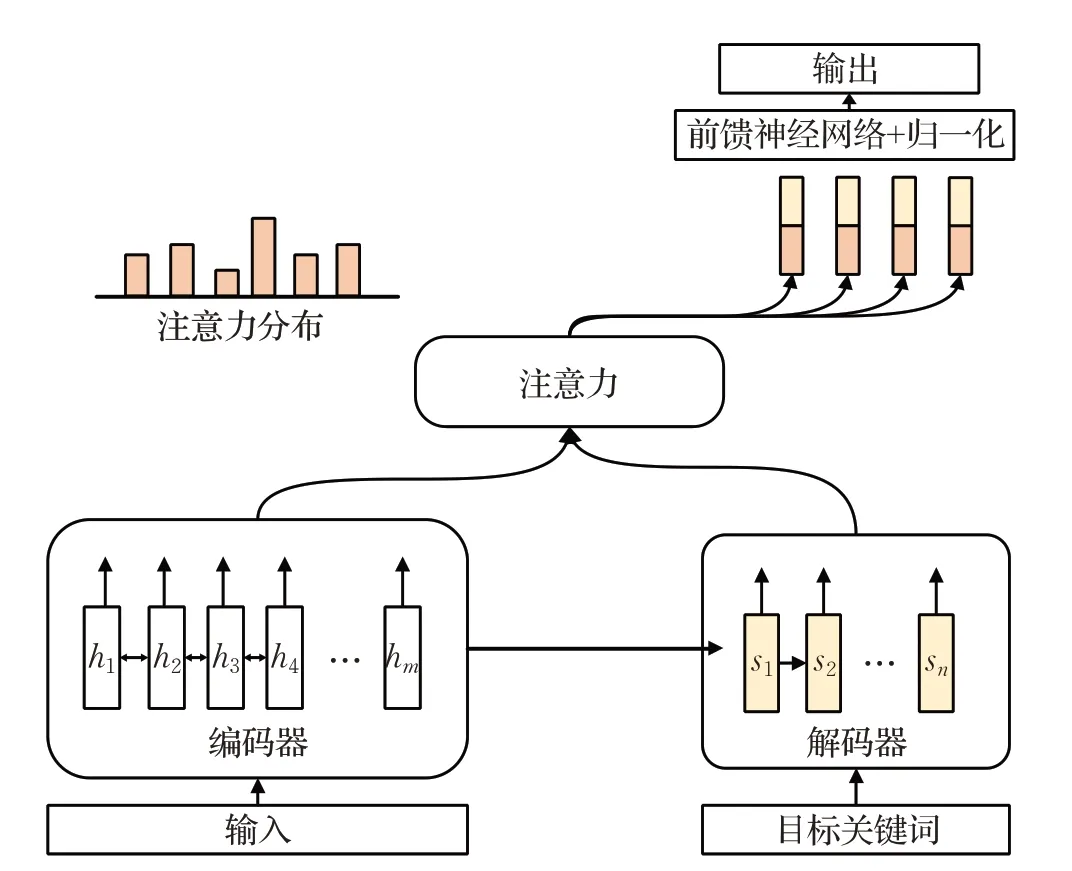
图3 基于复制机制的Seq2Seq关键词生成模型架构图Fig.3 Architecture diagram of Seq2Seq model basedon copy mechanism
解码器由前向GRU组成,通过公式st=f(yt-1,st-1,ct)将ct随着时间迭代输出解码器的隐状态st。其中ct为上下文向量,在求解该向量环节应用了注意力机制[17](attention mechanism),如图4所示。
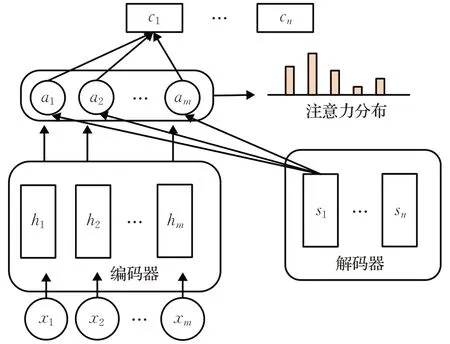
图4 注意力机制架构图Fig.4 Architecture diagram of attention mechanism
注意力机制的思想是解析原文本时重点关注文本与每个关键词的相关程度,降低无关文本对关键词的影响权重。例如(原文:我爱北京天安门;关键词:天安门)该文本中“北京”一词对“天安门”影响权重最大,“我”和“爱”一词的权重则相对小一些。动态变化的上下文向量意味着原文本序列Xseq中任意词xi对生成目标词yi的影响力不是等同的,它们之间的匹配程度越高代表原文中xi对当前预测词影响力越强。
如公式(1)所示ci是所有时刻t的输入隐状态的加权平均和。权值由每个输入隐状态与输出隐状态之间的相似性生成,之后经过归一化,得到最终的权重,如公式(2)所示:
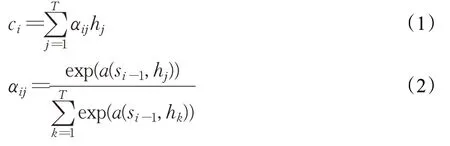
yt为t时刻预测的关键词。预测每个新词yt的概率由两部分组成,如公式(3)所示:
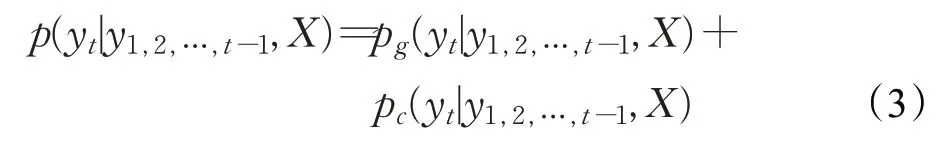
第一项是生成该项的概率,如公式(4)所示:
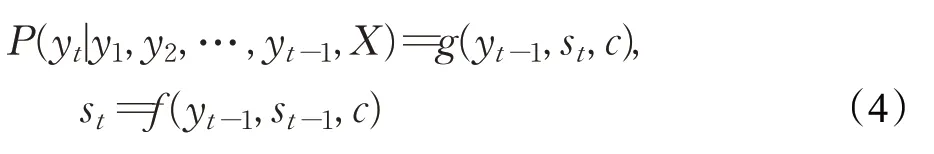
g是一种非线性的softmax分类函数,输出为词汇表中所有词的概率分布。
第二项是从原文本中复制该项的概率,被称为复制机制[7(]copy mechanism),其中输入文本中的一些词语被选择性地复制到生成的关键词中。在日常中也可以观察到类似的现象,如双方交流过程中实体名称(人名、地名)往往会重复出现。它和注意力机制比较相似,利用位置信息来衡量原文中每个词语的重要性,见公式(5):
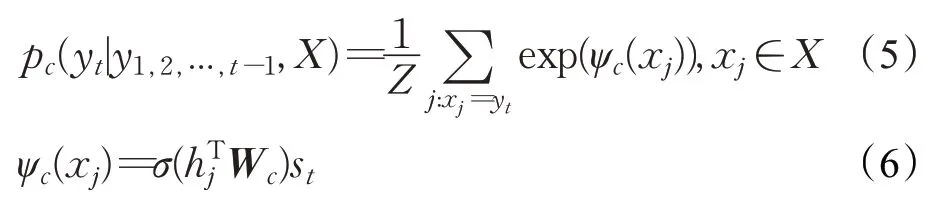
σ是一个非线性函数,用来计算每一个输入与当前预测词的得分。Wc是一个训练参数矩阵,Z是所有分数的和用来执行标准化,最终预测词的概率为生成部分与复制部分的和。该模型的损失函数如公式(7)所示:
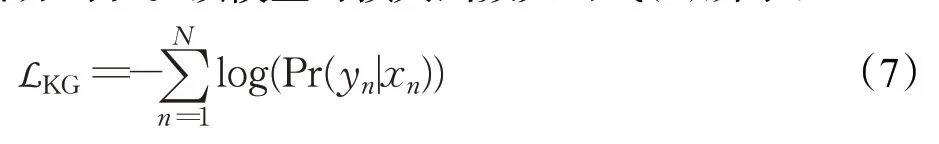
其中,N表示训练实例的数目,yn和xn分别为第n个样本对应的输入序列和输出序列。最终结果利用BeamSearch[18]生成概率最大的关键词。这是一项重要的开创性研究,该模型首次克服了以往抽取方法存在的缺陷,通过深度神经网络获取语言的深层次特征,能获取到20%不存在于原文中的关键词。综合比较,该模型的表现明显优于以往的各类抽取方法,对关键词生成的后续发展历程影响深远,后续许多研究者都是在此基础上进行深入的研究。但是,该方法还存在以下缺点:(1)解码器生成关键词时,并没有充分考虑所选词之间的依赖关系,所以生成的关键词存在语义重复和重要主题可能未覆盖的问题。(2)BeamSearch[17]是固定的,不能动态地根据文本调整生成关键词的数量。
2.1.2 其他扩展型
2017年,Zhang等人[19]尝试对CopyRNN的生成速度进行优化,提出了一种完全基于卷积神经网络(convolutional neural networks,CNN)结构的CopyCNN模型。与循环神经网络相比,并行工作的CNNs能更好地利用GPU(graphics processing unit)硬件,使计算完全并行化、高效化。门控线性单元(gated linear units,GLU)用作非线性函数来减轻梯度传播,同时还使用位置信息和输入词嵌入来保持序列顺序,在保持得分略高的情况下,生成时间减少了数倍。
2018年,Zhang等人[20]为了降低关键词之间的冗余度,提高关键词的多样性,在CopyRNN模型中引入覆盖机制(coverage mechanism)[21]如图5所示,从而形成CovRNN模型。覆盖向量可以看作是一个序列向量,它作为原文本词语压缩后的一个非标准化分布,利用文本中所有词的注意力分布来形成覆盖度,覆盖机制来记忆原文本中哪些部分已被前面的词语覆盖,使得后续生成的关键词更平衡地关注原文本中的其他信息,以此来覆盖更多的主题。该模型与CopyRNN相比,更具有科学性。
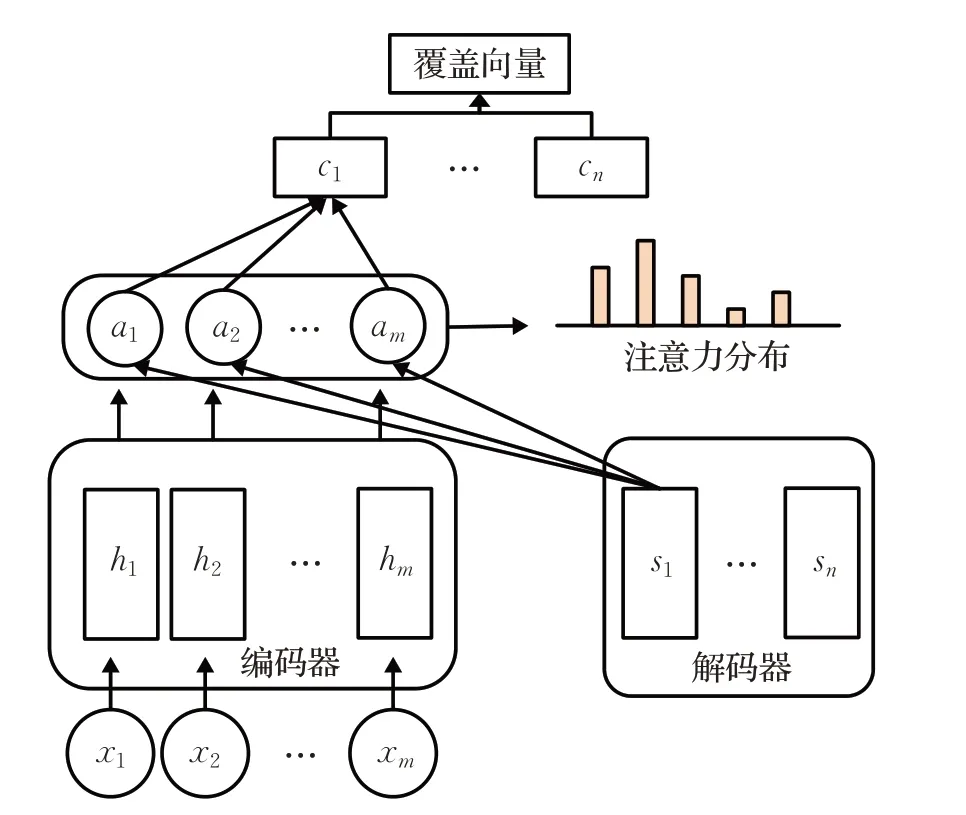
图5 覆盖机制架构图Fig.5 Architecture diagram of coverage mechanism
2018年,Chen等人[22]为了进一步优化关键词的重复率和多样性,提出了CorrRNN模型。在覆盖向量的前提下,引入了一种在新生成候选词过程中对比原文本和已生成关键词的审查机制(review mechanism),以避免最终结果的重复。该机制进一步减弱已生成关键词和将要生成的关键词之间的相关性,进一步提升了关键词的主题的覆盖度和多样性。
2.1.3 结合主题模型的关键词生成
2019年,Wang等人[14]将编码器-解码器模型应用于社交媒体来实现关键词生成。由于社交媒体语言的非正式和口语化的性质,神经主题模型(neural topic model,NTM)[23]用于探索输入文本的潜在主题信息,丰富文本特征和缓解社交媒体中的数据稀疏问题[24]。主题信息与编码器获得的上下文表示向量一起进入解码器共同指导关键词的生成。如图6所示主题感知神经关键词生成模型的整体架构包含两个模块。

图6 主题感知神经关键词生成模型架构图Fig.6 Architecture diagram of topic-aware neural keyphrase generation model
(1)用于探索隐含主题的神经主题模型
该模块由变分自编码器(variational auto-encoder,VAE)演变而来,结构由一个编码器和一个解码器组成,其过程类似于数据重建。给定一个长度为|C|的文本作为输入,表示社交媒体中的帖子{x1,x2,…,x|C|},将每个帖子x处理成词袋表示xbow,它是词汇表上的一个V维向量(V是词汇表大小)。输入xbow由编码器负责估计先验分布变量μ和σ,用于推导主题变量z(代表帖子的主题)。

解码器工作原理与LDA(latent Dirichlet allocation)风格的主题模型类似,假设给定的语料库C下有K个主题。每个主题k在词汇表上都表示为一个主题-词分布φK,每个帖子x∈C都有一个由θ表示的主题混合,即一个K维分布向量。特别是在神经主题模型中,θ是由Gaussian softmax构建的。因此,解码器采取以下步骤来模拟每个帖子x的生成方式:
①采样隐含主题变量z~N(μ,σ2)。
②主题混合θ=sof tmax(fθ(z))
③对于每个词w∈X,采样w~softmax(fΦ(θ))。
解码器采用fΦ(·)的权重矩阵作为主题-词分布(φ1,φ2,…,φK),之后主要采用主题混合θ(K维分布向量)作为主题表示来指导关键词的生成。
(2)用于关键词生成的序列到序列模型
该模块以词序列形式Xseq=<w1,w2,…,w|X|>(|x|是x中的词数)表示的原帖子x作为输入,目标是输出一个词序列y作为x的关键词。序列编码器从原文的词序列学习出上下文表示特征,每个词wi进入词嵌入层表示为vi,利用双向GRU完成编码,输出隐状态hi(前向和后向隐状态拼接),见公式(9):

序列解码器采用前向GRU通过公式sj=fGRU([uj;θ],sj-1)生成目标词的隐状态sj。其中uj是解码器第j个输入的词嵌入,sj-1是上一时刻的隐状态。解码器工作时也应用了上述方法的注意力机制和复制机制。具体来说,它通过公式λj=sigmoid(Wλ[uj;sj;cj;θ]+bλ)训练出一个向量λj∈[0,1]来决定是复制原文中的词还是从词汇表中生成,主题信息θ也参与指导关键词生成。最终,用下列公式(10)来预测第j个目标词的分布pj:
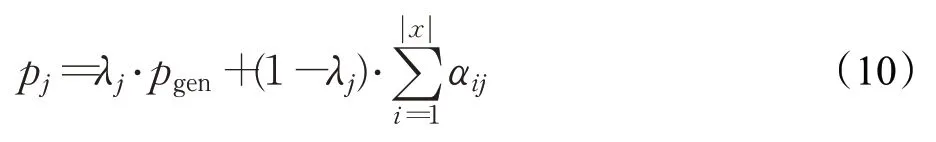
其中注意力分数αij指从原文中复制为关键词的概率分布。综合分析该模型的损失函数为两个模块对应的损失函数之和,公式为L=LNTM+γ·LKG,其中超参数γ用来平衡NTM和KG模型的影响。研究者对中英文社交媒体平台微博、Twitter和StackExchange等三个数据集上进行了实验。实验表明,该模型显著优于不利用隐含主题的抽取和生成模型,但是该模型没有考虑到生成关键词的数量问题,每个帖子关键词生成数量都是固定的。
上述有监督模型都使用Beam Search生成关键词,并选择组合条件概率最大的K个词作为关键词。取决于文本的长度、主题和关键词标注粒度等因素,每个文本的关键词数量可能存在差异,因此使用相同的K来评估数据样本不符合现实也不是最佳的方案。2020年,Yuan等人[4]引入一种训练设置,其中生成模型可以学习给定文本的目标关键词数量,通过加入可变数量的关键词序列,也将其视为序列生成的目标,为每个样本解码这些序列中的一个(如从BeamSearch中获取组合概率值最大的序列),最终该模型还可以为每个输入样本生成可变长度的关键词进行排序。为了提高输出序列的多样性,对解码器输出的隐状态向量进行正交正则化,以此表现各个序列之间的差异性。除了使用F1@5、F1@10,还提出两个新颖的评估指标:F1@M和F1@V。
该方法存在两个缺点:在该设置下训练的模型生成的关键词往往少于“基本事实”。现有的评估方法仅依赖词干的精确匹配来确定候选词是否与基本事实的词语匹配。例如,如果模型生成“支持向量机”,它将被视为不正确,因为它与标准标签给出的词语“SVM”不匹配。
2.2 基于半监督的关键词生成方法
2.2.1 结合无监督抽取的关键词生成
虽然序列到序列模型在关键词生成任务上取得了显著的成功,但都建立在大量带标注数据的前提下,仅适用于资源丰富的领域。实际应用中如何更好地利用未标注数据也是值得重点考虑的问题。Ye等人[25]提出了利用标注数据和大规模未标注数据样本进行联合学习的半监督关键词生成方法,该方法有两种策略,第一种使用无监督方法TF-IDF和TextRank对未标注文本进行关键词抽取并对其进行去重,将结果与标注数据混合应用于模型训练。这些文本虽然是未标注的,但可以提供通用的语言结构和词汇信息,例如关键词的上下文信息。使用未标记文本也可以缓解因训练样本偏少而导致的过拟合问题,有利于提高模型的泛化能力。第二种是多任务学习,该框架通过参数共享策略将关键词生成作为基本任务与标题生成的辅助任务联合学习,两个任务共享一个编码器网络,解码器分别适配不同的任务,在训练阶段,对两个任务实施交替训练的策略。多任务学习将受益于端学习,提高编码器的通用性。在科学论文和新闻文章中,文档通常包含一个概括核心主题及文本内容的标题,和关键词的功能非常类似,因此选择标题生成作为辅助任务。最终研究结果表明该方法优于部分有监督的关键词生成方法。
2.2.2 基于结构信息的关键词生成
以往的方法将文本标题和内容平等对待,仅将它们连接作为原文输入,无法强调标题包含的高度总结性和有价值的信息,忽略了标题对整个文本的引领作用。2019年,Chen等人[26]研究了数据集上与标题相关的关键词的比例,发现接近33%的不在原文中的关键词与标题相关。对于在原文中出现的关键词,和标题相关度高达约60%。因此提出了标题引导网络(title-guided network,TG-Net)模型,如图7所示。
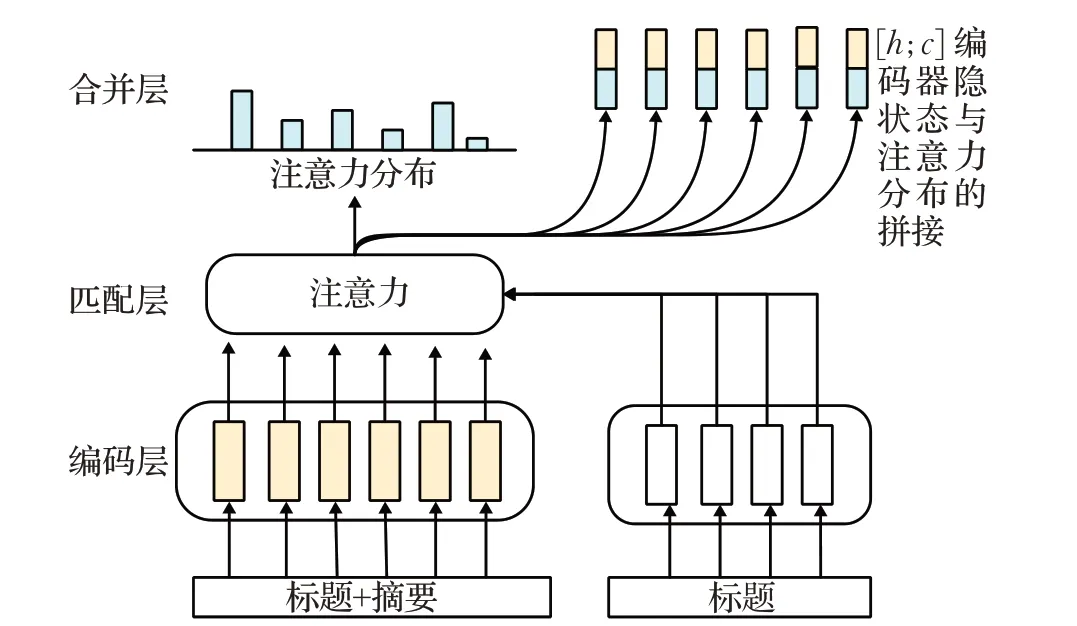
图7 TG-NET编码器架构图Fig.7 Architecture diagram of TG-NET encoder
该模型具有两个新特性:标题信息也用作类似查询的输入;指向标题的编码器用于捕获标题中重要信息。TG-Net主要由三个复杂编码器组成:(1)一个双向GRU分别编码原文本(标题+摘要)和标题在其上下文中的表示。(2)基于注意力的匹配层,根据上下文词的语义关系捕获每个词的相关标题信息。(3)另一个双向GRU将原始上下文和收集的标题信息合并到最终的标题引导表示中。解码器与之前方法类似,配置有注意力机制和复制机制,利用最终标题引导的上下文表示来预测关键词。与CopyRNN相比取得了重大进展,且对于不存在于原文中的关键词生成方面也有明显的改进(更好的R@10和R@50分数)。
2.2.3 多任务学习
2019年,Chen等人[27]提出了新的关键词生成方法,一个多任务学习[28]框架,共同学习一个抽取模型和一个生成模型,使基于编码器-解码器框架的序列到序列模型中具有抽取和检索的能力,利用关键词抽取模型和引入外部知识来提高关键词生成的性能。神经序列学习模型用于计算原文本中每个词成为关键词的概率。这些值用于修正解码器的复制概率分布,帮助后者检测原文中最重要的词。抽取模型训练时明确于从原文中识别关键词,且概率值表现为静态,用于辨别文本中包含关键信息的重要组成部分,有效帮助复制机制更准确地识别原文中的词语。同时还提出了一个检索器——从训练数据中检索与给定文本相似的文档,为解码器引入丰富的外部知识来指导文本关键词的生成。最后,合并模块将提取、检索和生成的候选词组合在一起,产生最终预测。该方法的优点是:(1)一个新的多任务学习框架,该框架利用抽取模型和外部知识来改进关键词生成;(2)一种新的基于神经网络的合并模块,将提取、生成和检索方法中的预测词结合起来,进一步提高性能;(3)在五个KG基准线上的实验表明优于先前的方法。但是他们提出的提取模型不是直接从原文档中提取关键词,而是旨在识别文档中每个词语的重要性,使用重要性分数来辅助关键词的生成。因此,提取模型的潜力尚未得到充分利用。
2020年,Liu等人[29]利用预训练模型(bidirectional encoder representation from transformer,BERT)[30]对输入文本按句子形式进行筛选,减轻将全部句子序列作为上下文的负担,重点关注包含关键词的句子,降低文本中无关内容对抽取性能的影响。在下游任务序列标记中对BERT进行精调,同时将训练好的BERT向量与生成模型共享,引入外部知识指导关键词生成。考虑到提取和生成方法的不同特点,将关键词预测分为两个子任务:原文中的关键词抽取(present keyphrase extraction,PKE)和不存在于原文中的关键词生成(absent keyphrase generation,AKG),如图8所示。目的是充分利用两种模型[31]的潜力,让它们发挥各自最佳的性能。
对于PKE,使用BERT预训练模型联合BiLSTM-CRF[32](bi-directional long short term memory-conditional random fields)架构将这项工作视为序列标记问题,整体框架由两部分组成:
(1)基于BERT的句子过滤器
将文档以句子形式切分,一些不包含关键词的句子被视为噪声数据,会显著降低抽取模型的性能。为了过滤掉不包含关键词的句子,使用BERT模型中的自注意力层判断每个句子的重要性。具体表现为将句子向量输入到Transformer[33]块中,每个区块包含两个子层:多头自注意力层(multi-headed self-attention)和一个全连接前馈网络(feedforward network,FFN)层,公式如下:
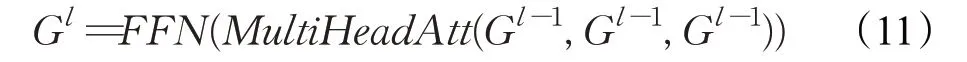
其中多头自注意力层的三个输入从左到右是Query矩阵、Key矩阵和Value矩阵。两者周围都采用了残差连接子层,接着进行归一化处理,最后通过sigmoid函数获得每个句子的分数:,根据得分为后续序列标记过程选择前K个句子。句子过滤器的损失函数为最小化负对数似然:,其中代表文档中的句子数。

图8 结合预训练模型的关键词生成架构图Fig.8 KG architecture diagram combined with pre-training model
(2)BiLSTM-CRF序列标记模块
将所选句子中词语的上下文向量输入到BiLSTM模型中进行精调以提高表达能力,条件随机场(CRF)对该输出进行评分和标记。对于输入x,标记序列t的评分定义为,其中,Ai,j是从标记i到标记j的转换分数,Pi,j是第i个词的标记j的分数。CRF的损失函数为最小化标准标签序列t的负对数概率:

最终利用Viterbi解码算法找到最佳序列路径,整体抽取模型的最终损失可以表示为LPKE=Lf+Lc。
对于AKE的整体架构是基于Transformer[33]的编码器和解码器组成。下面分两部分进行分析:
(1)融合注意力模块的Transformer编码器
给定一个文档x,文档中每个词嵌入经transformer编码为U0:
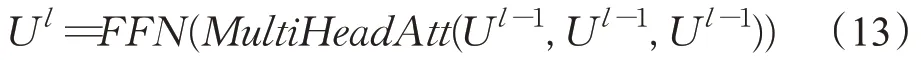
同时,为了防止BERT向量丢失掉抽取模型中关键词的信息,生成模型中不再使用Transformer训练BERT,而是共享关键词抽取中的BERT向量作为补充知识来指导生成过程,采用另一个L层多头注意力模块编码表示为,当时,使用“软门”权重将它们合并。;。其中V是文档的最终表示,是逐元素乘法。
(2)Transformer解码器
除了编码器模块中的自注意力层,每个解码器层还包含多头编码器-解码器注意层,对编码器的输出表示V执行,每个解码器块如下:
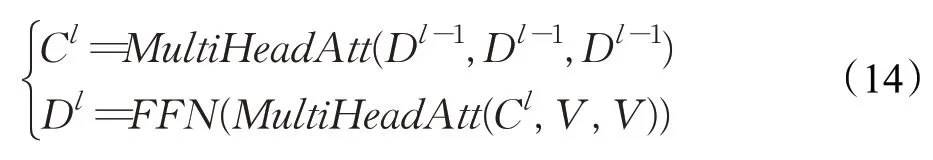
其中Dl为第l层解码块的输出。与以往方法一样,为了提高模型的生成能力,将复制机制与Transformer解码器结合起来,其中最后一个解码层的注意力分布表示从原文本复制词的概率。在步骤t的最终预测分布P表示为:

该方法的优点是结合预训练模型可以大大减少训练时间以及对大量标记数据的依赖,并利用BERT对文本中的关键句子进行甄别,避免了文本中所有句子作为输入上下文的负担,能有效地提升模型性能。将关键词预测分为两个子任务后,抽取模型充分考虑了候选词之间的依赖关系,提高了关键词的多样性,同时基于共享BERT提供的额外的关键词信息使生成模型性能进一步提升。
2.3 基于无监督的关键词生成方法
随着深度学习技术的发展,关键词生成任务已经取得了显著的成功,尤其在生成不存在于原文中的关键词方面。近些年的研究,在挖掘文本深层语义和已生成关键词的相关性上取得了不错的效果。但这些性能提升主要来源于大量带标注的数据。然而收集大量的关键词并不容易,需要专业人员对其标注,既费时也费力。2021年,Meng等人[34]提出了一种无监督的关键词生成方法AutoKeyGen,可以在不使用任何人工标注的情况下生成关键词。据观察在Inspec数据集中,99%的不存在于原文中的关键词可以在其他文档中找到。该方法的三个步骤为:(1)通过汇集语料库中的文档,遵循文献[35-36]完成关键词抽取,利用抽取出的词汇构建词库。相关研究表明,56.8%的不存在于原文中的关键词切分之后会分别出现在输入文本中,说明在大多数情况下,不存在于原文中的关键词能在该文本中找到出处。每给定一个输入文本,对词库中的每一个词切分后迭代查找,切分后所有的词都出现就作为不存在于原文的关键词。(2)利用TF-IDF和embedding similarity规则对关键词进行排序。(3)使用每个文本中两部分排名前五的关键词来训练Seq2Seq模型,以此获取更多的不存在于原文本的关键词。
该方法在无监督方法中实现了最好的性能,但是对语料进行抽取时忽略了关键词的语义相关性,会造成生成关键词的语义冗余问题。用于训练Seq2Seq生成模块的关键词,按排名进行选择时容易忽略掉低频词,造成关键词主题覆盖度不足的问题。
2.4 深度强化学习
2019年,Chan等人[37]在相关数据集上的实验表明,catseqD模型每个文档平均生成4.3个关键词,而每个文档平均有5.3个关键词。虽然现有的方法能够针对输入文本生成一定数量的关键词,并且可以根据每个文本调整关键词的生成数量,但依旧存在着生成数量较少的问题。
为了模型能够生成足够且准确的关键词,提出了一种关键词生成的强化学习(reinforcement learning,RL)方法,如图9所示。RL已广泛应用于文本生成任务,如机器翻译、文本摘要、图像视频字幕。这类强化学习依赖于Enhanced算法或其变体,通过最小化梯度损失策略来训练生成模型以获得回报。而该RL方法使用了一种新的自适应奖励函数,通过一个“硬门”(if-else语句)将Recall和F1值结合起来。该模型的Encoder为双向GRU,Decoder为单向的GRU,为了缓解OOV(out of vocabulary)问题,研究者也采用了指针生成网络(pointergenerator network)[38],该网络使用generator保留了其生成能力,同时用pointer从原文中复制相应的词来保证关键词的准确性。该方法的亮点在于研究者采用强化学习解决了生成关键词过多或过少的问题,生成模型视为智能体,输入的样本视为环境,利用Recall值和F1值奖励智能体指示它选择相应行动,更新模型的参数,使模型生成更多更准确的关键词。
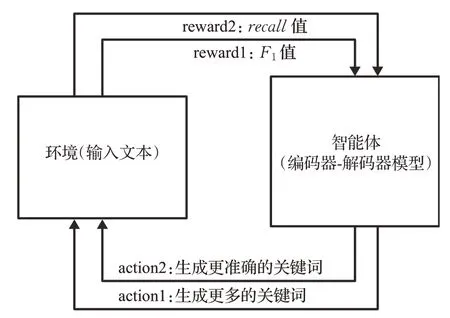
图9 强化学习架构图Fig.9 Architecture diagram of reinforcement learning
这是一项开创性的研究,首次将深度强化学习应用于关键词生成领域,同时显著地提高了生成模型的性能。
上述基于序列到序列模型关键词生成任务的强化学习框架利用评估指标进一步优化了训练良好的神经模型。然而,F1和Recall评估指标只能判断候选词的正确性,忽略了候选词和目标关键词之间部分匹配的问题,在一定程度上抑制了深度学习模型的性能。针对这个问题,2021年Luo等人[39]提出了一种新的细粒度评估指标fine-grained(FG)来识别部分匹配的候选词,可以更好地在细粒度维度上评估候选词质量,进而优化深度强化学习框架。该框架提出了两个阶段的强化学习:(1)当模型识别到一些部分匹配的词语,FG分数为模型提供积极的奖励。(2)将部分匹配的候选词按token顺序以及token级的预测质量进行筛选,最终提升为关键词。
新强化学习框架的关键词生成方法在所有的评估分数中都优于之前的强化学习,同时该方法还能有效地缓解同义词的问题并生成更高质量的关键词。
综合分析以上方法,分别从方法分类、网络结构、机制设计、数据集和评价指标五部分进行总结,具体见表2,IKNSK={Inspec,Krapivin,NUS,SemEval,KP20k},在相关数据集上模型生成原文关键词和非原文关键词的性能如表3、表4所示。
3 关键词生成评价方法
对关键词提取方法描述和比较之前,通常先介绍用于评估和衡量其结果的方法、措施和关键基准。关键词评估方法采用克兰菲尔德评估过程[40](Voorhees 2001),每种方法应用于一组测试文档,提取的关键词通常与一组由作者对该文档手动分配的关键词构成参考进行比较。
3.1 基于深度学习的评价方法
在关键词提取的现有技术中,使用不同的措施和协议来评估提取的关键词。最广泛的评价方法是精确率(Precision,P)、召回率(Recall,R)和F1(F1-measure)值,定义如下:
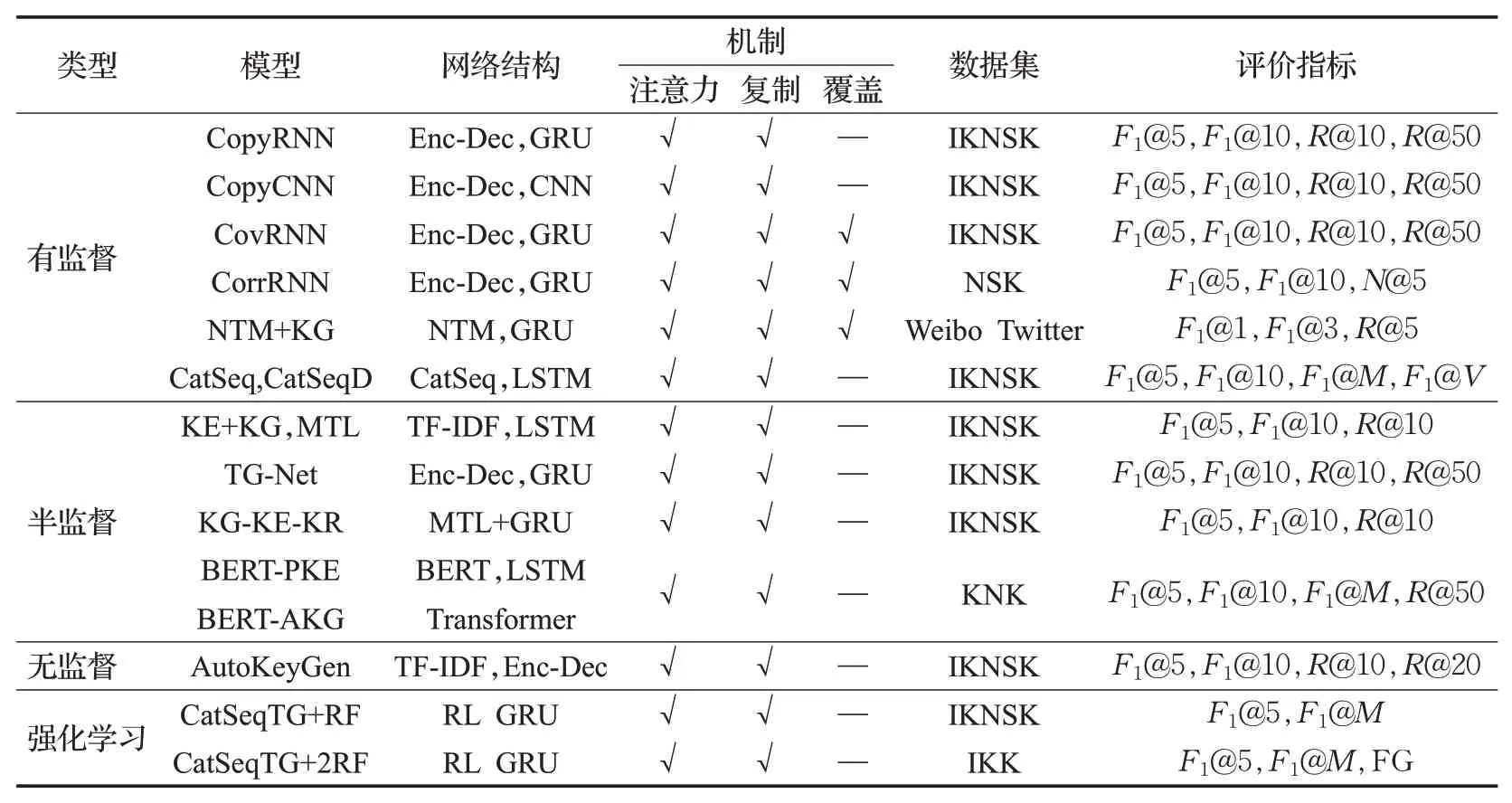
表2 关键词生成方法总结Table 2 Summary of keyphrase generation methods

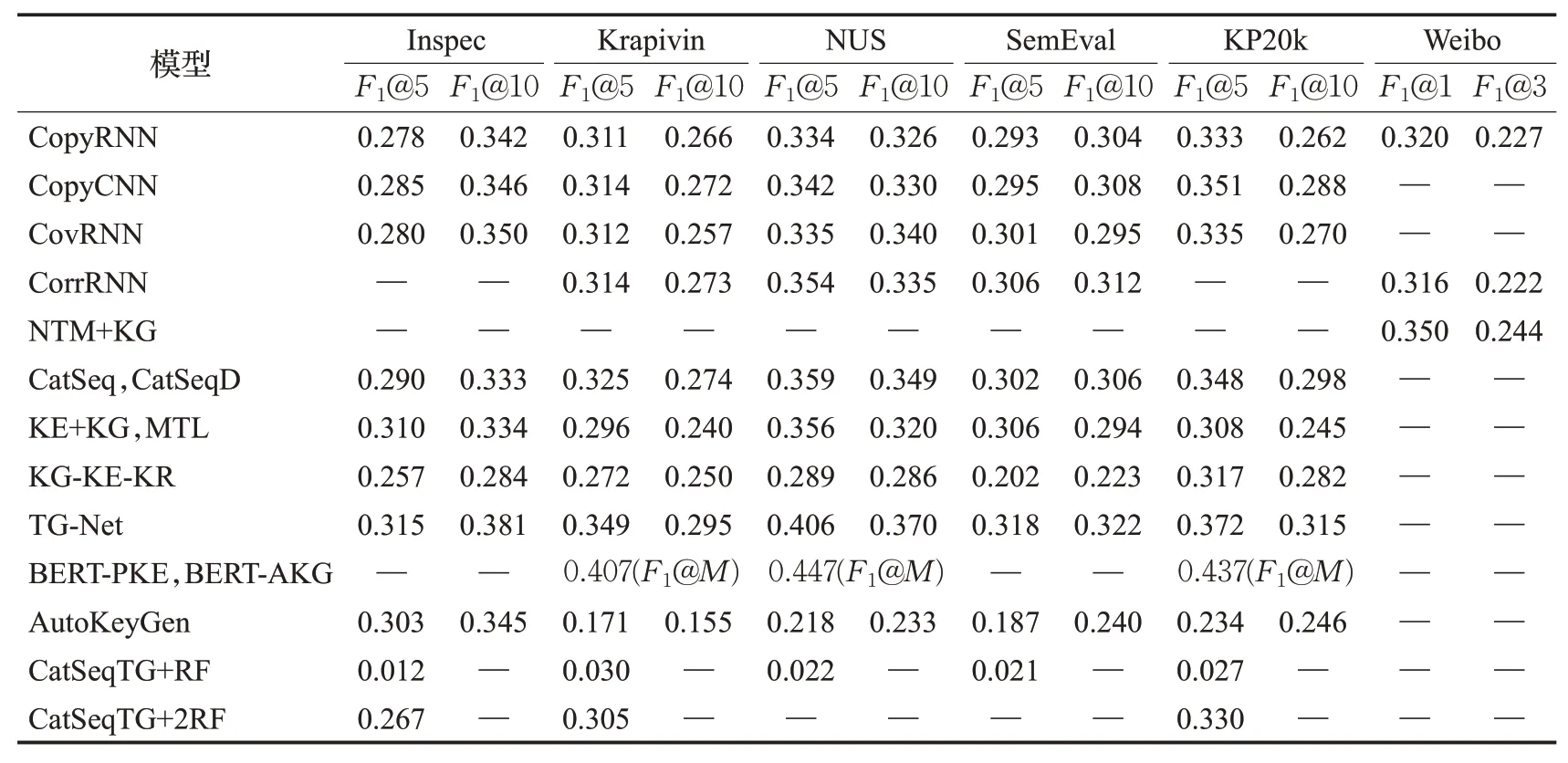
表3 在相关数据集上模型生成原文关键词的性能Table 3 Performance of generating present keyphrases of various models on datasets
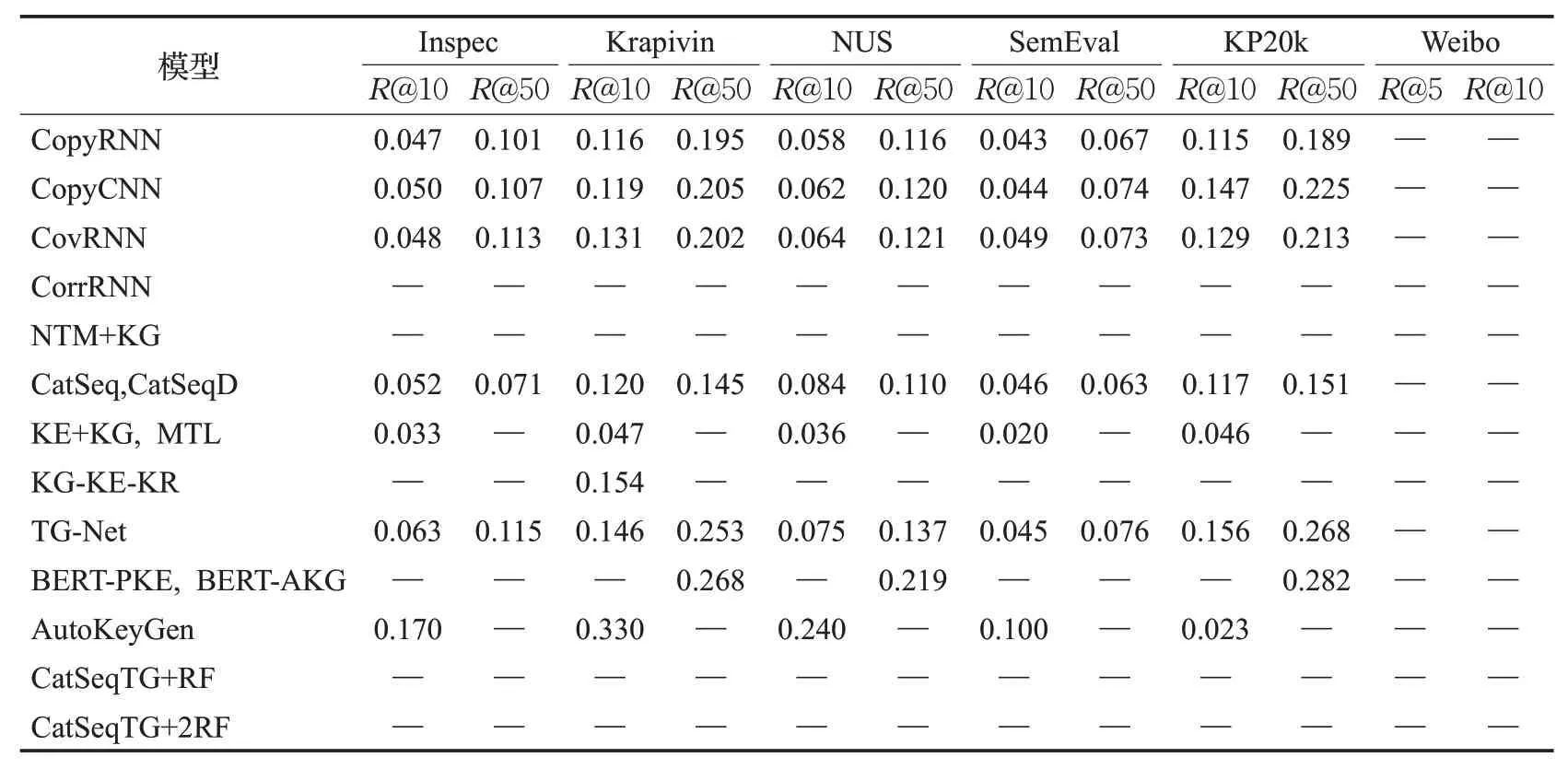
表4 在相关数据集上模型生成非原文关键词的性能Table 4 Performance of generating absent keyphrases of various models on datasets
信息检索中,通常根据关键词排名的质量来评估方法,例如Precision@K、Recall@K和F1@K等。此度量忽略排名低于K的关键词,并计算前K个关键词的精度值列表。2020年,Yuan等人[4]还提出两个新颖的评估指标:F1@M和F1@V,其中M是模型为每个数据样本生成的所有关键词的数量,其中V是在验证集中给出最高F1@V分数的预测数量。
因为抽取方法不能生成不存在于原文中的关键词,为了公平比较,将两类关键词的实验结果分开评估。
上述措施并没有考虑到关键词多样性[41]这一要素,因此在有排名关键词列表的情况下,还需要其他评估措施,如广泛使用的α-NDCG衡量关键词生成的多样性表示为N@K。α是相关性之间的权衡和α-NDCG的多样性,它根据Habibi和Popescu-Belis[42]被设置为相等,权重为0.5,α-NDCG越高,结果越多样化。
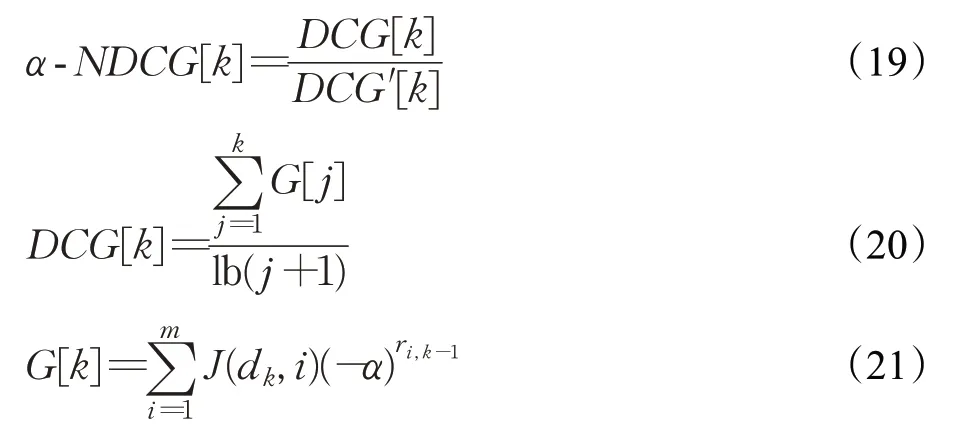
其中,α是一个参数,m表示关键词的数量,k表示候选词的数量。J(dk,i)=0 or 1,表示第k个候选词是否与第i个关键词相关,并且ri、k-1表示候选词与第k个候选词之前的第i个关键词相关。这里的相关性被定义为当前关键词是否为其他关键词的子集(例如“多代理”与“多代理系统”)。
3.2 基于强化学习的评价方法
在关键词生成场景下,使用强化学习训练时,其输入的语料可以看作环境一方,生成模型作为智能体。智能体的预测结束时,将获得奖励,并更新自身策略(模型参数)。该奖励采用R值和F1值进行计算,(1)如果模型生成的关键词数量不足时,R值作为奖励,指示模型生成更多的关键词;(2)如果模型生成的关键词数量足够时,F1值作为奖励,指示模型平衡召回率和生成词的精度(准确性),这样就达到了优化R和F1评估指标的目的。
3.3 基于变体匹配的评价方法
考虑到真实关键词和提取的关键词之间无法检测到两个语义相似但形态不同的关键词,因此存在不能“完全匹配”这一局限性。为了解决这个问题,Zesch和Gurevych[43]于2009年提出了一种语义近似匹配策略,Chan等人[37]于2019年提出了变体匹配策略,Luo等人[39]于2021年提出了部分匹配策略,从各种来源提取每个关键词的语义变体、名称变体以及部分匹配变体,如果这些变体与真实值匹配,则将其视为正确预测。这些研究者认为,处理关键词之间这种变化的策略可以使关键词以更精确的方式评估提取方法。
4 总结与展望
本文对基于深度学习的关键词生成方法按如下类别进行了分析:有监督学习、半监督学习、无监督学习、深度强化学习。这些方法都运用了不同的机制和策略:如复制机制、注意力机制、覆盖机制、审查机制、结合主题模型、多任务学习、结合预训练模型等来提高关键词生成模型的性能[44]。相比以往的抽取方法能深层次地理解文本的内容,同时更加符合真实场景,也得到了该研究领域的认可。
大部分关键词生成方法的性能都是以大量带标注的数据为代价的,如何依赖少量标注数据保证生成关键词的准确性和多样性,以及关键词生成任务应用场景的创新是下一步重点考虑的问题。本文针对目前关键词生成任务发展方向[45]提出以下几个观点:
(1)与多粒度信息融合
目前的研究大多聚焦于以文本整体的输入作为主要信息,存在噪声多、复杂度高的问题,较少挖掘文本中有价值的句子和短语,忽略了它们对整个文本关键词生成的引导作用。因此,如何将融合深度学习模型的抽取算法[46-47]得到的重要句子和短语作为额外的信息与原文本整体输入进行多粒度融合编码,用于提高关键词生成模型对重要信息的归纳能力,也是未来需要解决的问题。
(2)与层次化神经主题模型相结合
关键词通常由输入文本中传达的重要主题的词语或短语组成,因此基于深度学习的主题模型与关键词生成研究紧密相关,其目标是从文本数据中学习到人类可以理解的潜在主题空间。以往的研究表明,语料库级别的隐含主题可以有效缓解其他任务中的数据稀疏[48]。对于基本主题模型来说,仅限于将主题归纳为平面结构,因此存在分类准确率低和主题一致性差等问题[49]。而层次化主题模型在一定程度上能获得更高质量、层次化的隐含主题信息,有效改善主题模型的效果[50]。因此,针对上下文信息有限的短文本数据集来说,如何通过层次化主题模型结合关键词生成模型,进一步缓解数据稀疏和提高生成词的多样性是未来需要关注的问题。
(3)运用知识蒸馏优化主题分布
当要求标注人员为文档指定关键词时,通常在阅读全文后,捕捉到文本的重要主题部分,然后根据更详细的理解记录关键词,所以文本主题的捕获对关键词生成的性能至关重要。但主题模型很容易忽略文本中的一些低频词或专业术语,它们在文章内出现的次数往往很少,仅依靠文本内部知识源明显不足。可以考虑知识蒸馏[51]的方法,依靠预训练BERT模型中已训练好的词向量知识作为监督信号去指导训练词袋模型,使其得到更高质量的主题分布,从而更有效地捕捉语言上下文的细微差别,在文本主题建模上表现出更好的主题一致性。优化后的主题模型与关键词生成模型相结合能发现文本中主题相关度高的低频词,进而指导优化关键词的主题覆盖度,提升关键词的多样性。
(4)与知识图谱相结合
对于一些特定领域如法律和医学的专业文章中,代表文本主题的词语被提及的次数很少,往往存在着关键词获取难度高的问题,很难捕获到真正意义上的关键词。因此,挖掘外部结构资源就显得尤为重要,如何借助知识图谱中的实体结构化信息以及实体间丰富的关系来丰富文本表示[52],用于提高生成词的准确性、扩展关键词生成应用领域是未来需要面临的问题。
(5)生成多类别关键词
以往都是对关键词生成性能进行考虑,也可以着眼于关键词生成的应用场景(生成结果分类)进行分析。首先对文本的关键词进行类别划分,在训练过程中,通过不同的关键词对文本主题类别进行约束,将其变为特征融入到不同主题的解码器,从而实现关键词分类。例如对于社交媒体帖子中的每一条评论都是由用户阐述自己的观点,根据每个评论的关键词涵盖的情感信息进行分类,形成正向情感如愉快、信任、感激等;中立情感如理性、不偏不向等和负向情感如痛苦、仇恨、嫉妒等。依据训练好的分类模型,可对众多评论数据进行倾向性分析,掌握用户舆论走向。
