改进CenterNet的无人机小目标捕获检测方法
2022-07-21刘鑫,黄进,杨涛,王晴
刘 鑫,黄 进,杨 涛,王 晴
西南交通大学 电气工程学院,成都 611756
目标检测[1]是计算机视觉的一个热门研究方向。目标检测的基础任务即识别与定位,需要识别出物体的类别属性同时确定其在画面中所处的具体位置。随着深度学习的崛起,在监控摄像头越来越普及的当下,目标检测更是活跃在人们的生活中,在行人检测、交通检测、工件瑕疵检测、医学图像分析等领域都能看到其应用。目标检测也是目前大火的视频分析方向的一个重要基础,包括视频理解、监控中的行人跟踪以及行为识别等。
基于深度学习的目标检测算法大致能分为两类:两阶段(two-stage)目标检测和单阶段(one-stage)目标检测。两阶段的目标检测需要提前在特征图上生成大量候选框,再进行高质量框筛选,最后再进行分类和位置回归,而单阶段目标检测则是直接一步到位完成分类和回归。Two-stage目标检测算法以R-CNN系列[2-4]为代表,单阶段经典算法以SSD[5]、YOLO[6-8]、RetinaNet[9]等为代表。根据有无预设锚框,又能分为Anchor-based与Anchor-free的目标检测算法。Anchor-free算法不需要提前预设锚框,对复杂场景下多尺度目标识别的普适性更强。在Anchor-free领域中,CornerNet[10]首次提出采用框对角预测替代锚框来进行定位与目标检测;FCOS[11]则直接预测目标框四边到目标中心的四边距离来进行目标检测;ExtremeNet[12]对目标框的四个顶点分别进行关键点预测,将预测结果进行几何枚举组合,再结合中心点预测以达到高质量的检测结果;CentripetalNet[13]在角点预测的基础上引入向心偏移和十字可变形卷积,将偏移与角点匹配对齐,从而预测出高质量的目标框;CenterNet[14]则将目标检测变成了一个标准的关键点估计问题,使用热力图来进行目标中心点的预测和分类,每个热力点同时结合高斯扩散预测目标的宽高信息;后续升级版的CenterNet2[15]中则是将宽高预测改为四边距离预测。
在目标检测,小目标由于其本身的特质,图像占比小、纹理特征不显著、浅层特征语义信息不足、高层特征信息缺失等原因,导致小目标的检测尤为困难[16]。场景复杂的无人机视角下,检测难度进一步提升。普遍的提升小目标检测精度的方法是进行多层特征融合,例如早期的图像金字塔,后期升级的特征金字塔FPN[17],以及在FPN基础上的各种改进特征融合模块PANet[18]、ASFF[19]、NAS-FPN[20]、BiFPN[21]、Recursive-FPN[22]等;另外一种方法是分而治之,如SSD、MS-CNN[23]、YOLO使用反卷积来强化浅层特征的语义信息,在不同分辨率特征层上对不同尺度的目标进行检测,但还是依托了特征融合的思路。
特征融合虽然一定程度上解决了小目标检测困难的问题,但是卷积网络带来的图像特征的高冗余问题,在这个过程中往往是被忽略的。GhostNet[24]指出卷积网络输出的特征图的不同通道中存在很多高度相似的冗余特征,某些通道层其实并不需要在整个数据流转过程中进行激活。与此同时,越复杂深层的特征融合会带来显著的内存压力,故而优化浅层的特征融合就显得尤为重要。因此本文针对图像特征高冗余的优化问题作为研究重点,在不影响算法速度的情况下,对算法进行优化,以期提升小目标的检测效果。
综上,考虑到算法的通用性与扩展性,本文采用基于Anchor-free的CenterNet作为基础网络,针对图像特征高冗余的优化问题进行模型改进,以提升小目标的检测性能,具体贡献如下:
(1)构建自适应底层模块(modified self-adaptive block,MSA),以削弱特征图融合时的高冗余问题,使得模型更注重于对关键点的表达。
(2)解码模块(depthwise module,DW)采用深度可分离卷积[29]与用Mish激活来提高解码效率和质量。
(3)在backbone输出处引入升维全局上下文注意力模块(global context block,GC-Block)[30],进一步削弱非关注点表达的同时,增强关键点的信息亮度。
1 CenterNet
CenterNet是一种单阶段的Anchor-free目标检测模型,其backbone有DLA(deep layer aggregation)[25]和Hourglass[26]两种框架,其中DLA模型小巧,可移植性高,作为本文的主要研究对象
DLA网络是一个高效的融合特征提取模块,如图1所示,包括内部特征融合和不同阶段层的跳跃特征融合,相较于广泛使用的残差网络ResNet而言,其充分利用了不同卷积层之间的特征,使模型拥有更高效的特征语义信息提取功能,模型更小精度更高。整个网络采用树状结构搭建,每一个特征融合节点相当于一棵树的树根或者树干支点,其余输入融合节点的各基础模块相当于四散的树枝,而一棵树又可以拥有多个树干支点,每个树干支点都能开支散叶。不同树之间的连接即跳跃特征融合,类似于生物学上的遗传链,将每棵树的信息传递到后续的树根和树叶中去。
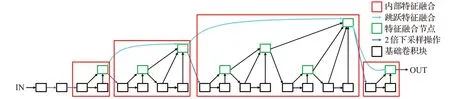
图1 DLA结构图Fig.1 Structure of DLA
CenterNet将目标视作关键点检测问题,使用高斯热力图进行物体的类别预测和中心回归,在中心回归的同时结合高斯扩散来预测物体的长宽。但由于物体中心并未全在矩形框的几何中心处,可能会导致模型收敛困难,故而采用物体中心与四边距的方式进行位置的回归。预测示意如图2所示。整个网络的目标总检测损失分为三个部分,一是类别损失,采用Focal-loss[9];二是框回归损失,采用Giou-loss[27];三是中心偏移损失,采用L1损失,总损失为三者的线性加权和。
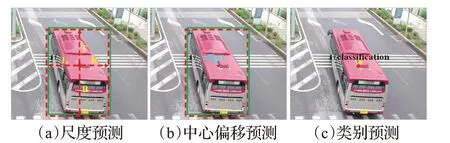
图2 CenterNet预测示意图Fig.2 Diagrammatic sketch of prediction for CenterNet
2 MSA-CenterNet
本文的网络总体结构如图3所示,主干部分采用DLA34结构作为框架,使用MSA自适应激活底层模块进行搭建。由于小目标检测的下采样倍数不能过大,本文选取4作为下采样最大倍率,主干输出特征层为DLA2。紧接着加入了一个升维GC-Block注意力块,对DLA2特征图进行二次冗余优化,得到特征图DLA2+。最后使用深度可分离卷积结合Mish激活进行特征解码模块的构建,分类头和回归头独立进行预测。本章接下来的部分将对各修改部分进行详细说明。
2.1 MSA自适应底层模块
在神经网络中,激活函数的存在是为了向网络模型中引入非线性因素,使模型可以任意逼近任何非线性函数,这对于多种非线性的推理场景来说更加适用。常用的激活函数有Sigmoid、Tanh、Maxout、ReLU、Leaky ReLU等。其中ReLU激活解决了Sigmoid存在的梯度消失的问题,加快了网络训练的速度。但在负半轴,网络输出全部置零,而往往负数部份也存在一些很重要的特征信息,负半轴失活导致了模型学习信息的缺失。与此同时,在神经网络的数据传播过程中,并不是每一层的每个通道的信息都值得传输到下一阶段,网络若能自适应地进行激活传输会大大提升特征的提取效率。ACON[28]激活使用3个可学习的参数(p1,p2,β)来控制模型以什么样的方式进行数据激活。具体而言(详见图4),不重要的通道可进行失活处理,而重要的通道则要进行增强激活,网络可以自适应地对接收到的数据分通道进行激活。
文献[28]中指出最常用的最大值输出函数Maxout(x1,x2,…,xn)可平滑近似为式(1)。
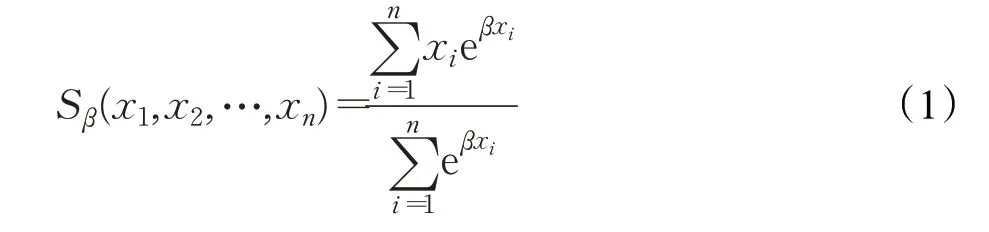
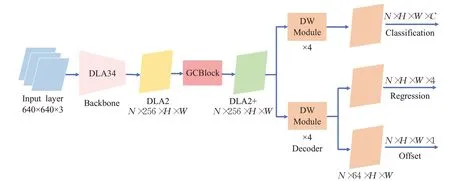
图3 MSA-CenterNet总体结构Fig.3 Overall structure of MSA-CenterNet
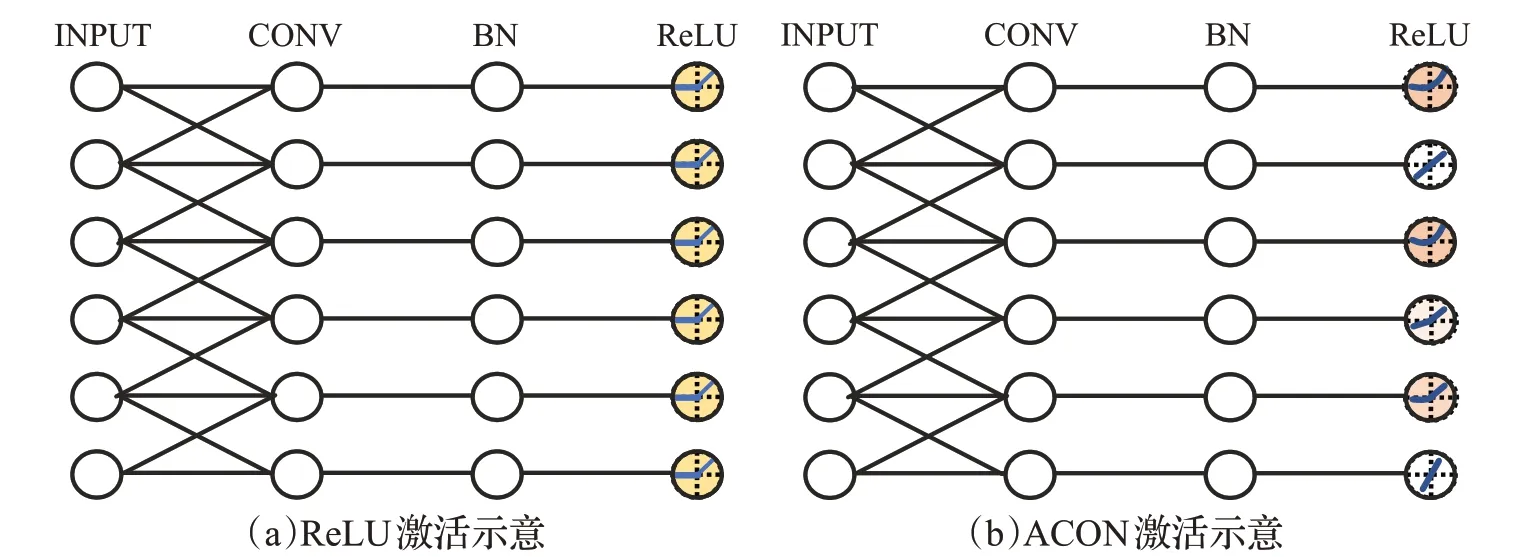
图4 ReLU激活与ACON激活示意图Fig.4 Diagrammatic sketches of ReLU activation and ACON activation
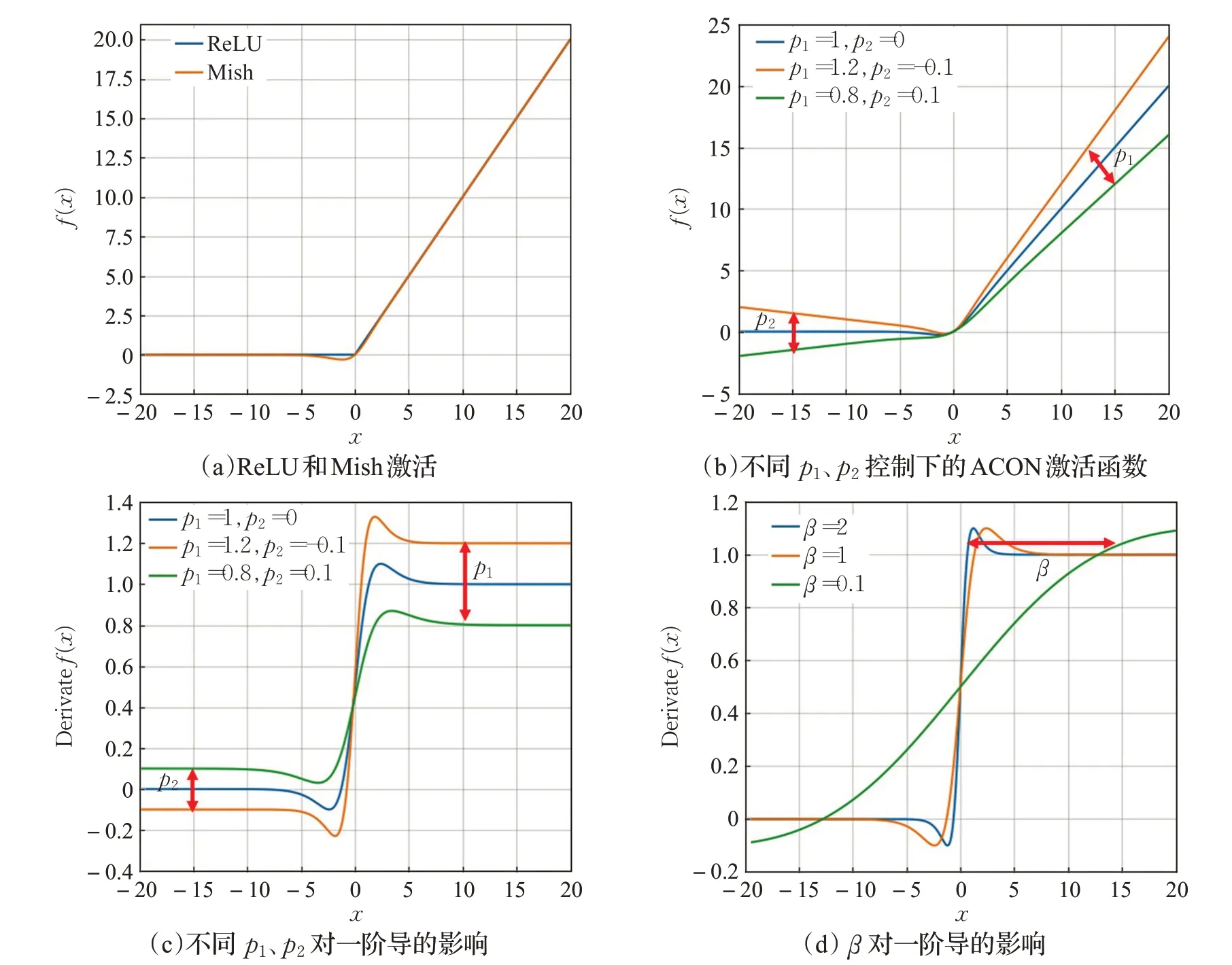
图5 一般激活与自适应ACON激活Fig.5 General activation and adaptive ACON activation
当β趋于∞时,Sβ趋近于最大值,而当β趋于0时,Sβ趋近于所有元素的算术平均值。激活函数大多可表示为max(ηa(x),ηb(x)),这里ηa(x),ηb(x)表示线性函数,当n=2时,式(1)简化为式(2):
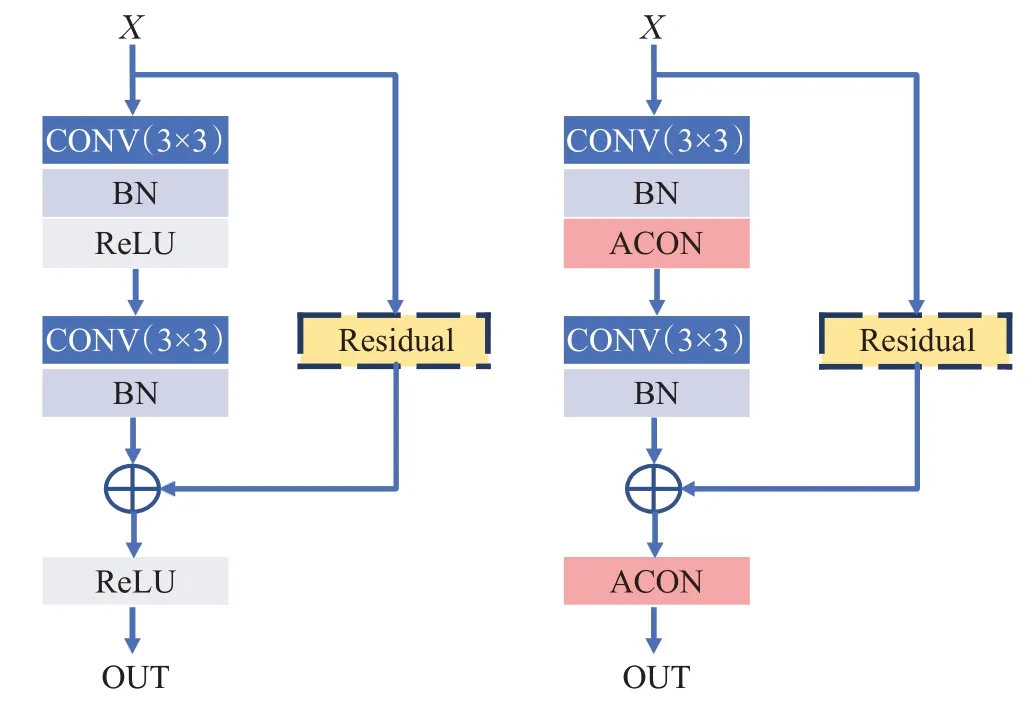
图6 BasicBlock与MSA结构图Fig.6 BasicBlock and MSA structure diagram
至此,即推导出本文MSA中采用的自适应激活的函数表达式,其中p1、p2是网络需要学习的激活权重,来控制激活的类型,例如Swish、PReLU等激活(见图5(b)、(c))。β使用卷积模块进行层归一化处理后经过Sigmoid函数后产生。每个通道的β控制激活一阶导的平滑度,由图5(d)可知,β越小越平滑,越大越陡峭。
DLA34中的基础模块使用ACON进行改造,搭建MSA模块作为网络的树状结构部份的基础模块,使网络可自适应地对不同通道进行选择性激活。修改后的网络会对非关注信息进行抑制,具体模块修改细节可见图6。
2.2 深度可分离特征解码模块
图7简单展示了深度可分离卷积[29]的运算过程。深度可分离卷积先进行独立的通道层卷积操作,卷积核按层独立地只进行一次卷积,与普通卷积操作相比大大缩减了计算时间,最后对卷积结果使用1×1卷积进行深度扩充,给予后续网络操作足够的特征信息。
在解码模块处,将原始的普通卷积模块修改为深度可分离卷积特征解码模块(具体模块构造见图8),模块中的激活方式采用Mish精进模型的数据解析过程,将前期由于自适应通道激活带来的部份高亮削弱调整回正,进一步抑制低关注区域特征的表达。
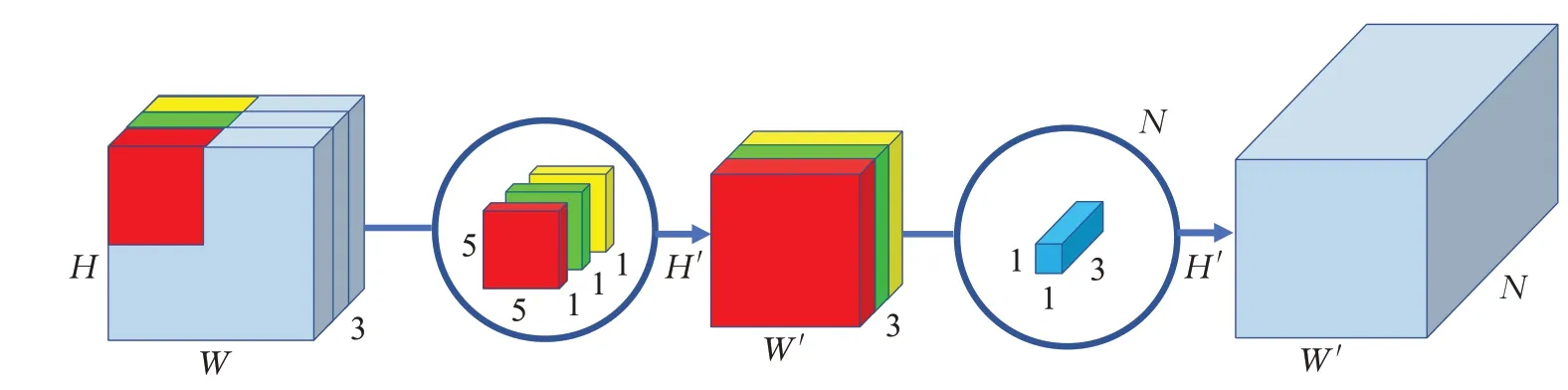
图7 深度可分离卷积示意图Fig.7 Schematic diagram of depth separable convolution
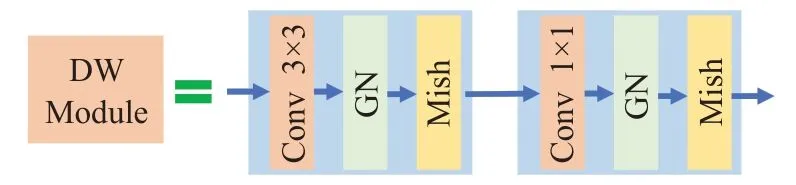
图8 Decoder基础模块DW-Module结构图Fig.8 Basic module DW-module structure diagram of decoder
2.3 注意力模块
在实验过程中,虽然MSA与DW模块的结合可以有效抑制非要素部份的表达,但在关键部份还是存在强度削减,虽然两者部份已有较为明显的区分,但是对网络识别而言还是稍微有所欠缺,为进一步提升两者之间的差异,让网络的“视线“更集中于要素点,本文引入升维GC-Block(global context-block)[30]注意力来进行对比增强操作。
GC-Block是清华大学研究人员结合了NL[31]与SE[32]两者优点而提出来的融合了全局上下文的通道注意力模块,具体结构见图9,运算过程见式(4):

其中,O是运算输出,是输入特征,对于图像数据来说Np表示单层通道上的像素点数量H·W,W是线性变换矩阵,网络中采用1×1卷积实现,R表示ReLU,LN是层归一化。
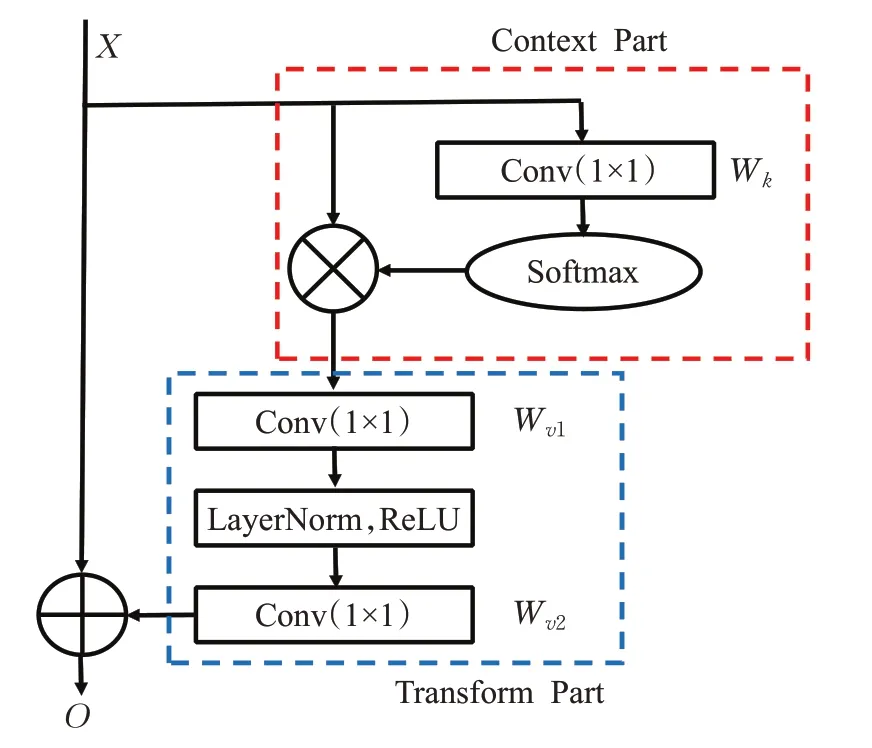
图9 GC-Block结构图Fig.9 Structure of GC-Block
升维GC-Block相较于原始模块在注意力提炼部分(transform part)将原来的降维操作,改为以32为倍率的升维操作,可有效增强关键信息亮度。
3 消融实验与结果分析
3.1 实验数据集及评价指标
VisDrone数据集[33]是由天津大学提供的一个大型的无人机捕获数据集,该数据集不仅场景复杂且目标都普遍偏小,增大了检测难度。该数据集上发布有四个任务:(1)图像目标检测;(2)视频目标检测;(3)单目标跟踪;(4)多目标跟踪。本文就图像目标检测作为研究方向,采用VisDrone2019数据集作为算法训练和测试的基准,该数据集包含6 471张训练图片与1 610张测试图片,共计10个类别:pedestrian、people、bicycle、car、van、truck、tricycle、awning-tricycle、bus、motor,其中pedestrian指行走或站立状态的人,其余状态的人均属于people类。
模型评估采用COCO-style评价指标,包含AP、AP50、AP75、AR1、AR10、AR100。AP表示IoU在范围[0.5,0.95]内以0.05为步长进行变化的综合平均准确度(average precision),AP50、AP75分别是IoU等于0.5和0.75时的准确度。AR1、AR10、AR100分别表示最大检测目标数为1、10、100时的平均召回率(average recall)。
3.2 训练过程
模型使用Detectron2[34]框架来进行搭建与训练。Detectron2是由Facebook提出的一个模块化的深度学习框架,是对Pytorch框架的进一步封装。整个训练过程需要的操作均被模块化处理,顺应固定深度学习搭建模式,仅需对每个模块进行自需处理再注册到操作字典中,调用注册名即可将模块注入到固化的搭建系统中去,可灵活方便地替换模型零部件。
由图10可知,整个模型的训练包括三个流程,数据集的处理、模型的搭建、训练与评估。
数据集处理部分将数据转化为COCO格式数据,随后将数据集注册到数据集字典中,建立COCO格式的Dataloader进行模型输入数据的读取。
模型搭建部分建立DLA34-CenterNet,在此基础上修改模型结构建立MSA-CenterNet+++(+表示叠加,数量表示模块增改数量,后文不再赘述)。具体子步骤描述如下(详见图10 Sub-step 4.*,*表示顺序数字):
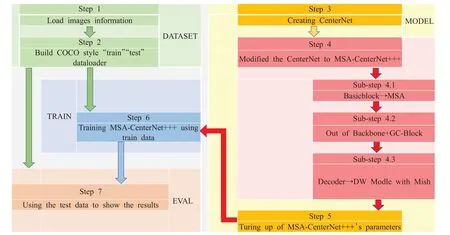
图10 模型训练流程图Fig.10 Flow chart of model training
(1)使用MSA替换原始BasicBlock。MSA可自适应地分通道进行激活操作,可有效抑制非关注信息的表达。
(2)在BackBone输出处添加升维GC-Block增强关键特征的语义信息,为避免歧义与简化用语,后文涉及的GC-Block均指升维模块。
(3)在Decoder部分使用深度可分离卷积结合Mish形成的DW模块进行搭建,在均衡模型复杂度的情况下精进特征的解码。
具体训练环境配置如表1所示。训练时,使用官方DLA34预训练权重初始化新建网络,修改部分采用Xavier初始化策略,图像输入大小长边限制在1 333内,短边限制在800以上,使用随机裁剪放缩增强,训练轮次设定为20 000,批处理大小设为16,权重衰减因子为0.000 1,初始学习率0.1,采用WarmupCosineLR学习率调整策略。

表1 训练环境配置Table 1 Configuration of training environment
3.3 结果定量评估
对测试集进行算法评估,对输入图像的处理均与训练时保持一致。表2列出了RRNet、CenterNet-Hourglass、原始CenterNet等算法与本文改进的MSA-CenterNet+++在VisDrone2019图像目标检测数据集上的各评估结果,表中*表示数据来源于比赛总结文献[35],其中粗体表示最优结果。由表中结果可知,本文提出的算法,较原始CenterNet在各AP上均有所提升,其中mAP提升了约2.2个百分点,召回率提升了2.4个百分点,参数量虽稍有增加2.4 MB,由FPS结果可知在实际运行时对速度的影响可忽略不计。而相较于其他算法,高精度指标AP75与召回率也均为最优结果。
原始算法与本文改进算法进行消融对比实验,结果见表3。由表中展示结果可知,MSA、DW模块、GC-Block对算法精度均有所提升。MSA相较于原始算法在AP上提升了1.0个百分点,在召回率上提升了1个百分点;在前者基础上引入DW解码模块AP提升了1.2个百分点,召回率提升了1.3个百分点;MSA+DW+GC-Block的AP提升了2.2个百分点,召回率提升了2.4个百分点。消融实验结果中均有所提升的精度与召回率,验证了本文改进算法各模块的有效性。
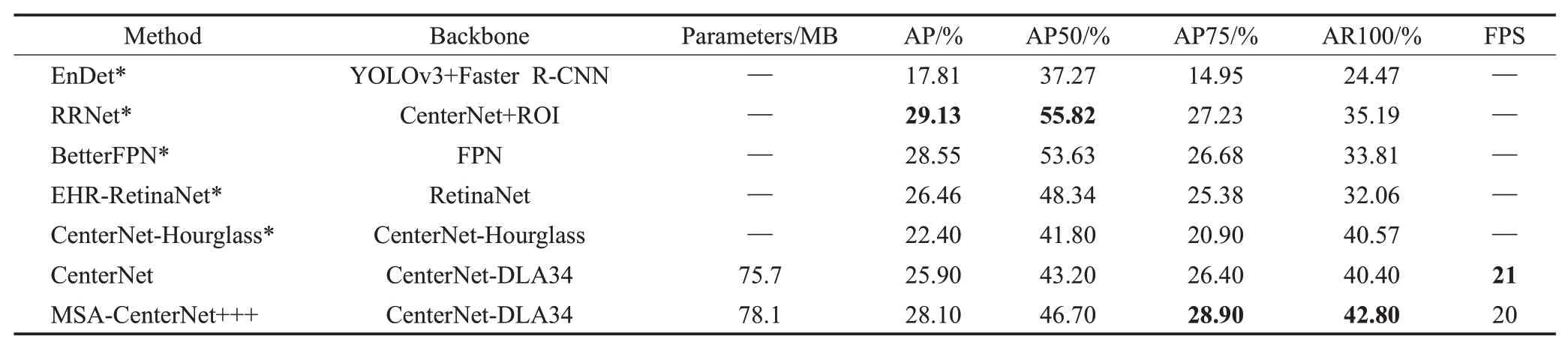
表2 现有算法与本文算法的模型大小与精度比较Table 2 Comparison of model size and accuracy between existing algorithms and algorithm in this paper

表3 模块消融实验Table 3 Module ablation experiment
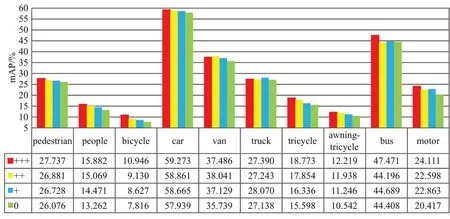
图11 模块消融实验中针对各类别准确度Fig.11 Accuracy for various classes in module ablation experiment
消融实验更具体的针对测试集每个类别的准确度对比如图11所示,其中“+“的含义与前文一致,0表示原始算法。
对测试集中一张图片(图12)的主干输出特征进行分析,将相同的4个通道进行可视化,如图13,排序顺序从左至右为1到4。其中(a)是原始CenterNet的输出结果,可以看到通道四周存在很多非关注信息特征,而在(b)MSA引入之后杂质较多的特征层明显被削弱了表达,较为纯净的特征层中也有无关信息被抑制,但是仍然还是有较多杂质分布于各通道中。在此基础上加入DW解码模块(c),可以看到特征层中的无用信息大多都被剔除了,与此同时通道1中的有用信息也得到了激活,通道3中的关键高亮部分也被调整回正。最后再加入GC-Block(d),可以明显观察到各通道中关键点的表达均被有效增强。关键信息的突出在后续解码预测具有很重要的指导作用。上述对输出通道的可视化结果进行的展示与分析,进一步证明了改进网络的可行性与有效性。

图12 测试集样本展示图Fig.12 Display diagram of test set sample
3.4 检测效果展示
图14是原始算法与改进算法的检测结果展示图,从上往下分别是原始CenterNet、MSA-CenterNet、MSACenterNet+(此处+表示在MSA基础上叠加,与图14的含义依次对应匹配,后文同理)、MSA-CenterNet++的检测结果。从结果图中可以看出,原始算法存在很多漏检,替换MSA作为基础块之后效果有增强,再加入DW解码模块,最后加入GC-Block可以明显看到MSA-CenterNet++的检测效果是最优的,对细节的把控也是最强的。
4 结束语
本文以目标检测中Anchor-Free的经典算法DLACenterNet为基础,针对特征融合带来的层间高冗余问题进行优化,以小目标检测为对象,提出自适应通道激活模块MSA作为DLA搭建的基础模块,可有效抑制无关信息的表达,在主干输出处加入升维GC-Block注意力模块,增强关键点的语义信息,最后采用深度可分离卷积与Mish结合搭建了新的高质量解码模块DW,兼顾模型复杂度的同时增加解码检测精度。在公开数据集上的实验结果表明,改进算法提升了复杂场景下的小目标检测精度。

图14 效果展示图(+表示叠加,多个+表示在前者基础上二次叠加)Fig.14 Effect display diagram
