基于优化改进的Xception模型的垃圾图片分类
2022-07-19刘后胜陶健林
刘后胜,张 洋,陶健林
(安庆职业技术学院 信息技术学院,安徽 安庆 246003)
1 引 言
21 世纪以来,人民的生活水平有了质的飞跃,对美好舒适生活的向往更加渴望。随着经济的快速增长,各式各样的垃圾也在快速增长。如何处理海量的垃圾,保持洁净的城市与乡村,取得一个舒适美好的生态环境,以满足人民生活的需要,已经成为城市和乡村发展必须面对的一大难题。
一般的垃圾处理过程是先由环卫公司统一回收,再运送到工厂,根据材料自身特性使用机器进行初步挑选,然后再由人工对可回收垃圾进行详细分类。尽管有机器帮忙,大大减少了劳动强度,但人工还是面临着工作效率低下等问题,其中玻璃等尖锐物品和垃圾中病毒细菌,时刻威胁着工作人员的健康安全。因此急需利用现有成熟的深度学习技术与计算机视觉技术,以实现智能化、自动化、无人化分拣。
近年来,有许多的学者对垃圾图片分类做了研究和实践,文灿华利用目标检测技术对垃圾图片进行处理识别[1];潘唯一提出了基于YOLOv3 的垃圾分类识别的方法[2];和泽提出基于预训练模型MobileNetV2 网络,运用迁移学习方法进行垃圾图片分类[3];梅书枰采用基于MobileNetv3 的深度学习分类模型以对垃圾图片进行分类[4];袁建野等提出使用最大平均组合池化,使用深度可分离卷积方法对垃圾图片进行分类[5];齐鑫宇在ResNet101模型的基础上,设计并构建了基于CNN 算法的新模型框架,对垃圾图片实时识别[6]。
为了解决自动化、智能化垃圾分类问题,本文设计了一种对垃圾图片进行分类处理的模型,采用了深度学习算法结合计算机视觉技术。改进了传统深度学习模型(Xception)的结构设计,在提升模型识别准确率的同时,也减轻了过拟合问题。我们在新模型中增加了全新的分类器,并采用了数据增强技术、正则化等算法,与原模型相比,识别准确率平均提升1.95%。在30 次的初步训练过程中,训练模型训练精度达到95%,新数据的预测精度已经达到90.67%。可见新模型已经实现了生活中大多数的垃圾图片分类,具备了实际应用价值,解决过拟合的方法和思路适用于其它同类型问题。
2 基于深度学习的计算机视觉图像处理技术
2.1 卷积神经网络
卷积神经网络是包含卷积运算以提取数据特征,其原理是利用卷积核不断对图像的特征进行卷积提取,再利用池化减少图片因卷积而产生的冗余数据。
2.1.1 卷积运算
卷积运算的基本原理是通过卷积核对输入图像数据进行卷积操作,是拿一个卷积核在原图上滑动窗口,每次卷积核元素乘以对应的元素再求和,最终得到输出特征图上一个像素值。
2.1.2 最大池化
最大池化运算的结果,不仅仅是要将经过卷积运算后的特征图的尺寸规模数量进行减半,更重要的是对局部特征进行筛选和过滤,以此实现对特征图进行采样,削减无用的数据,以提高模型的运行速度,减少算力的浪费。最大池化是对输入的特征图进行滑动窗口式提取,并在每次窗口提取最大值,其基础理论概念与卷积有异曲同工之妙。
2.1.3 激活函数
此次模型主要使用的激活函数有Relu 和Softmax 两大类,Relu 主要使用在卷积神经网络的中间层,Softmax 主要用在最后一层的分类器。Relu 是一种非线性的激活函数,当x>0时,取其本身,当x≤0时,取值为0。其特点是克服了梯度消失问题,且大大简化了计算过程,因此在训练速度方面有了很大的提升。Softmax 函数就是把一个N 维向量归一化为一个和为1的(0,1)之间的数值,其采用指数运算,使N维向量中的数值较大的量更加突出。
2.1.4 正则化
拟合与泛化是深度学习中一对矛盾,正则化就是试图解决此种矛盾。而在众多正则化当中,dropout正则化是最实用的也是最有效果的正则化之一,使用dropout正则化,该层神经网络在每次的训练过程中,会随机将一定比例的输出特征点归零,从而打乱当前维度的学习方向,从其他维度继续对图像特征进行学习。
2.2 图片数据的采集与数据增强
2.2.1 数据的采集
本文数据均来自2020“智海”人工智能技术服务大赛初赛:计算机视觉的垃圾分类项目。该项目数据集包含了已经完成分类的2307 张生活垃圾图片。其中数据集被分成6 个类别,分别是玻璃(glass)、纸(paper)、硬纸板(cardboard)、塑料(plastic)、金属(metal)和一般垃圾(trash)。
2.2.2 数据增强
模型过拟合的主要原因是因为可供学习的样本数据太少,导致深度学习模型无法学习到能够泛化到新数据的特征,如果通过技术将样本进行不重复的微调,每次模型学到的都是新数据新特征,这样就可以大大减少过拟合发生的概率,数据增强是从有限的数据中,通过计算机视觉技术,对有限的样本数据进行随机变换来生成新的训练数据,其方法是随机对图片进行旋转、水平或者垂直的平移、缩放、错切交换、水平翻转、填充等方式增强样本。
3 基于深度学习算法的垃圾分类新模型与模型训练
3.1 新模型的框架结构
在原有模型Xception 的基础上,针对原有模型对垃圾图像数据提取的冗余特征,易出现模型过拟合情况,表现为对新数据泛化效果不佳,预测精度略低。因此我们使用密集连接层构建全新的分类器,让全新的分类器衔接在Xception 模型的卷积基上面。改进的新分类器结构,主要包含了3 个采用Relu 作为激活函数的密集连接层,1 个采用Softmax作为激活函数的分类层,3 个批标准化层,以及3 个正则化层构成。
3.2 模型性能分析
为了更好地验证新模型在原有模型基础上的性能提升效果,对两个模型进行了详细对比,包含在30 次训练情况下的训练精度(Accuracy)、训练损失(Loss)、预测精度(Predict_Accuracy),如表1 所示。在30 次训练的情况下,原有模型的训练精度在第7次训练的时候就以达到97%,后23 次训练模型精度仅仅提升2.91%左右,最终训练精度为99.13%,如图1所示;训练损失为0.310318,如图2所示;预测精度却仅有88.72%。相较而言新模型虽然起步较晚,但训练精度呈稳步上升达到了94.84%,训练损失稳步下降到1.213363,预测精度达到了90.67%。由此可知新模型不仅在一定程度上解决了原有模型的过拟合问题,而且可以从训练精度和训练损失看出,新模型还有更高的提升空间。
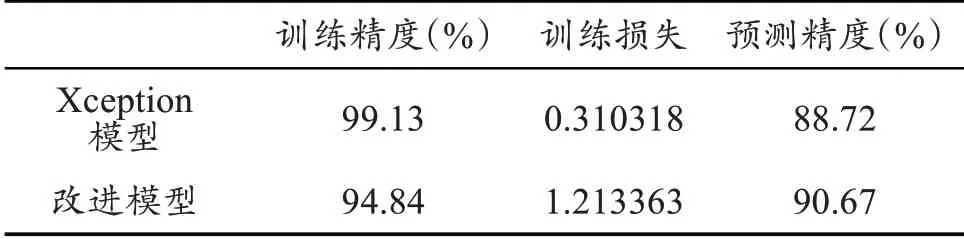
表1 模型性能对比
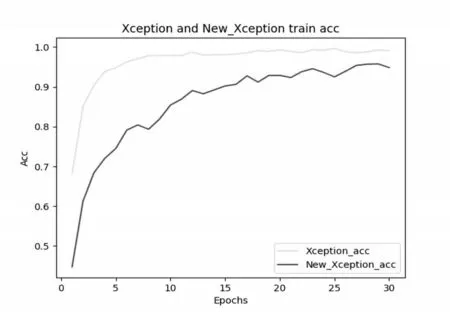
图1 模型训练精度对比图
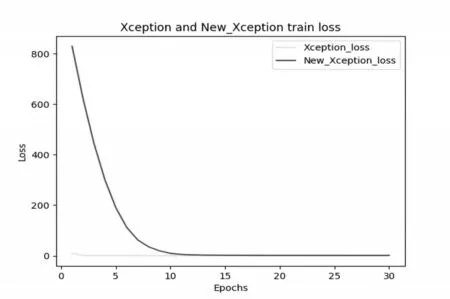
图2 模型训练损失对比图
实验环境配置如下:计算机为联想Y7000 笔记本电脑搭配16GB 内存,CPU 为Intel(R) Core(TM)i7-8750H CPU@2.20GHz 2.21GHz,显卡为NVIDIA GeForce GTX 1050 Ti 搭载GeForce Game Ready 457.49驱动。安装的操作系统为Windows 10家庭中文版操作系统,搭建了CUDA9.0+CUDNN7.6.5 深度学习环境。同时使用Python 编程语言和Tensorflow深度学习框架。
4 结 语
本文通过对传统深度学习模型Xception的优化改进,一定程度上解决了模型的过拟合问题,加强了模型对新数据的泛化效果,提高了新数据的预测准确率,最终新模型的预测准确率在90.67%。虽然垃圾分类图片仍然存在错误识别的情况,但由于深度学习模型的学习成本较低,识别准确率高,且在大算力的支持下,模型的预测准确率有望进一步提高。
