提高数据模型预测效果的新方法及其在蜡油加氢脱硫中的应用
2022-07-19李明丰胡元冲梁家林褚小立
田 旺, 秦 康, 李明丰, 胡元冲, 梁家林, 褚小立
(中国石化 石油化工科学研究院,北京 100083)
蜡油加氢作为催化裂化、加氢裂化重要的前处理工艺,除脱除产品中的一部分硫、氮,降低下游装置的负担外,还能对催化裂化或加氢裂化的原料进行改质[1]。随着环保要求的日益严格,国家对汽、柴油中硫含量制定了更为苛刻的标准[2],这给汽、柴油的主要生产单元——催化裂化装置带来了极大的压力。蜡油加氢装置作为催化裂化原料的供应者,为了减轻催化裂化装置在脱硫方面的负担,控制精制蜡油的硫含量在合理的范围内显得尤为重要。
实际生产中,精制蜡油硫含量超标或者过低,通常是由于原料发生较大变化或者操作波动较大所导致的。对于此情况,操作人员通常会对操作参数进行相应的调整,当调整不充分时,会导致精制蜡油中硫含量过高,出现“极大点”;当调整过度时,会导致精制蜡油中硫含量过低,出现“极小点”,造成过多的能耗损失。这些边际点虽然不多,但给正常生产带来了极大的挑战。建立相应的精制蜡油硫含量预测模型,准确预测少数硫含量边际点,成为迫切需要解决的问题。
常用的蜡油加氢建模方法主要有机理建模法和数据驱动建模法2种。由于蜡油的加氢反应是一个高度非线性且相互耦合的过程,原料性质、操作条件、催化剂等因素均会影响反应过程和产物收率,使用传统的机理模型很难描述这一复杂体系,因此数据驱动建模法则是解决这一问题的有效工具。
目前,基于大数据的统计模型发展迅速,并已经在航空[3]、电力[4]、电子商务[5]以及医疗[6]等领域取得了巨大成功。随着PI实时数据库系统(Plant information system)在石油化工领域的逐步普及[7],各种原料数据、工艺条件数据、催化剂性能数据等都可从装置的数据库平台中采集,这些长期积累的数据,为数据挖掘技术在石油化工领域的应用提供了良好的基础条件[8]。将数据挖掘技术应用于石油化工反应过程,建立完善的统计学分析模型,多角度全方位地对反应过程及其影响机制进行分析,具有传统机理模型无法比拟的优势[9]。杨帆等[10]基于梯度提升决策树(Gradient boosting decision tree, GBDT)算法构建了催化裂化汽油收率的预测模型,模型预测结果与实际汽油收率的误差小于1%。王伟等[11]在梯度提升决策树GBDT算法的基础上,构建了P-GBDT模型,相比GBDT算法,该算法对于催化裂化装置汽油收率的预测效果更好。任小甜等[12]采用随机森林回归算法,建立了直馏减压馏分油(VGO)中噻吩硫化物组成分布的预测模型,该模型可实现减压蜡油(VGO)中苯并噻吩、二苯并噻吩、萘苯并噻吩以及总噻吩含量的准确预测。Ivana等[13]以神经网络算法为基础,选取6个操作参数作为输入变量,建立了加氢蜡油中硫含量的预测模型,结果表明,该模型可准确预测硫含量。胡元冲等[14]以神经网络框架keras为基础,为柴油产物中硫、氮、单环芳烃、多环芳烃质量分数分别建立预测模型,使用该模型对工艺参数进行优化,确定了最适宜的操作条件。田水苗等[15]基于BP神经网络建立数据驱动模型,预测石脑油、液化气、燃料气、精制蜡油流量以及精制蜡油中硫、氮质量分数,仿真结果表明BP神经网络模型具有较高的预测精度。
就蜡油加氢工业装置而言,所建的数据驱动模型预测精制蜡油中硫含量,要获得较好的泛化能力,除选取合适的算法外,还需要对错误的精制蜡油硫含量数据点进行甑别剔除以及关注这些数据中的边际点。因此,笔者提出两步法来构建模型,第一步,构建精制蜡油硫含量异常点判定新方法,将一部分隐藏的异常点筛选出来并剔除,得到所有硫含量正常点数据;第二步,在保留所有硫含量边际点的基础上,从正常范围点中随机挑选数据,增加精制蜡油中硫含量边际点所占比例,进而使其符合统计学模型的特点,提高模型对测试集中硫含量边际点预测的准确度。
1 预测模型的选用
利用数据驱动模型预测产品性质的方法被越来越多的研究人员使用,其中,神经网络是使用最多的算法。神经网络的优势在于强大的非线性拟合能力,较适合炼油工业中加氢装置的生产体系,且搭建模型方便,自学能力较强。但缺点同样明显,需调节的超参数多,要想获得理想的结果,寻优耗时较长;而且,模型易过拟合,所需数据量大,整个过程类似于“黑箱”,对于结果的解释性较差。基于上述分析,结合实际生产的需要,笔者决定采用另一种非线性拟合能力较强的算法——极限梯度提升XGBOOST (eXtreme Gradient Boosting)。
极限梯度提升XGBOOST是基于Boosting思想的集成学习算法,它是以决策树的方式(设置树枝和叶子),以信息增益(自变量特征本身所含的信息量对因变量结果的影响程度)和残差逐步减小(分为n个小模型,第n个模型以第n-1个模型的残差为基准,调整特征权重,得到最小残差)选择特征并构建模型。
XGBOOST算法建立的模型不需要对数据进行预处理,就可计算出特征的重要程度,进而使模型更加关注重要的特征。该方法对于预测类问题解释性强,稳健性好,有较强的泛化能力,可保证较高的准确度,使得其在工业应用方面具有更大的潜力和优势。
2 数据的收集和清洗
以国内某石油化工企业蜡油加氢装置为研究对象,采集3年(2015—2018年)的运行数据,这些数据包含LIMS(Laboratory information management system)数据和DCS(Distributed control system)数据,LIMS数据主要包含原料油和精制蜡油2部分,原料油数据包括密度、硫含量、氮含量、馏程、残炭含量、金属含量等特征参数;精制蜡油数据包括硫、氮含量以及馏程特征参数。DCS数据包括:进料量、各原料比例、反应器各床层温度、进出口压力、循环氢流量等特征参数。由于实际的分析项目和分析频次会根据生产需要进行调整,所以,不同时间同一项目的分析指标可能不一致。为最大限度利用收集到的数据,笔者按照模型的架构对特征参数进行了筛选,保留20个特征参数作为模型的输入和输出。其中,输入参数为19个,输出参数为1个。模型的输入参数包括原料参数(密度、馏程、硫含量、氮含量等)、操作参数(原料进料量、原料比例、循环氢量、新氢量、反应压力、各床层温度等);输出参数为精制蜡油中硫含量。
数据质量关系着模型建立的好坏,因此,收集到的数据还要进行清洗,剔除一些重复、不对应、不完整、异常的数据。相应的数据清洗方法如下:
(1)对每组数据进行详细检查,如果有重复的数据组应进行删除。
(2)按照时间的先后顺序采集数据,保证每组数据输入和输出对应。
(3)每一组数据严格进行物料平衡计算,保证输入、输出数据的一致性。
(4)计算每个输入参数的平均值和标准差,使用聚类法、假设性检验等方法进行删除。
上述方法主要针对输入参数的数据,对于输出参数的数据,由于其本身是因变量,它的数值变化受自变量的影响较大,所以,需要使用专门的方式进行筛选。
3 精制蜡油硫含量异常点判定新方法
精制蜡油硫含量作为模型的输出参数,属于因变量,而传统的观察、聚类、统计检验等方法,主要针对自变量的情况,对于因变量的处理,极易导致误判。因为有些离群点是由于输入参数中的某些变量数值变化大导致的。为此,针对因变量,笔者提出了一种异常点判定的新方法,其具体流程示意图如图1所示。
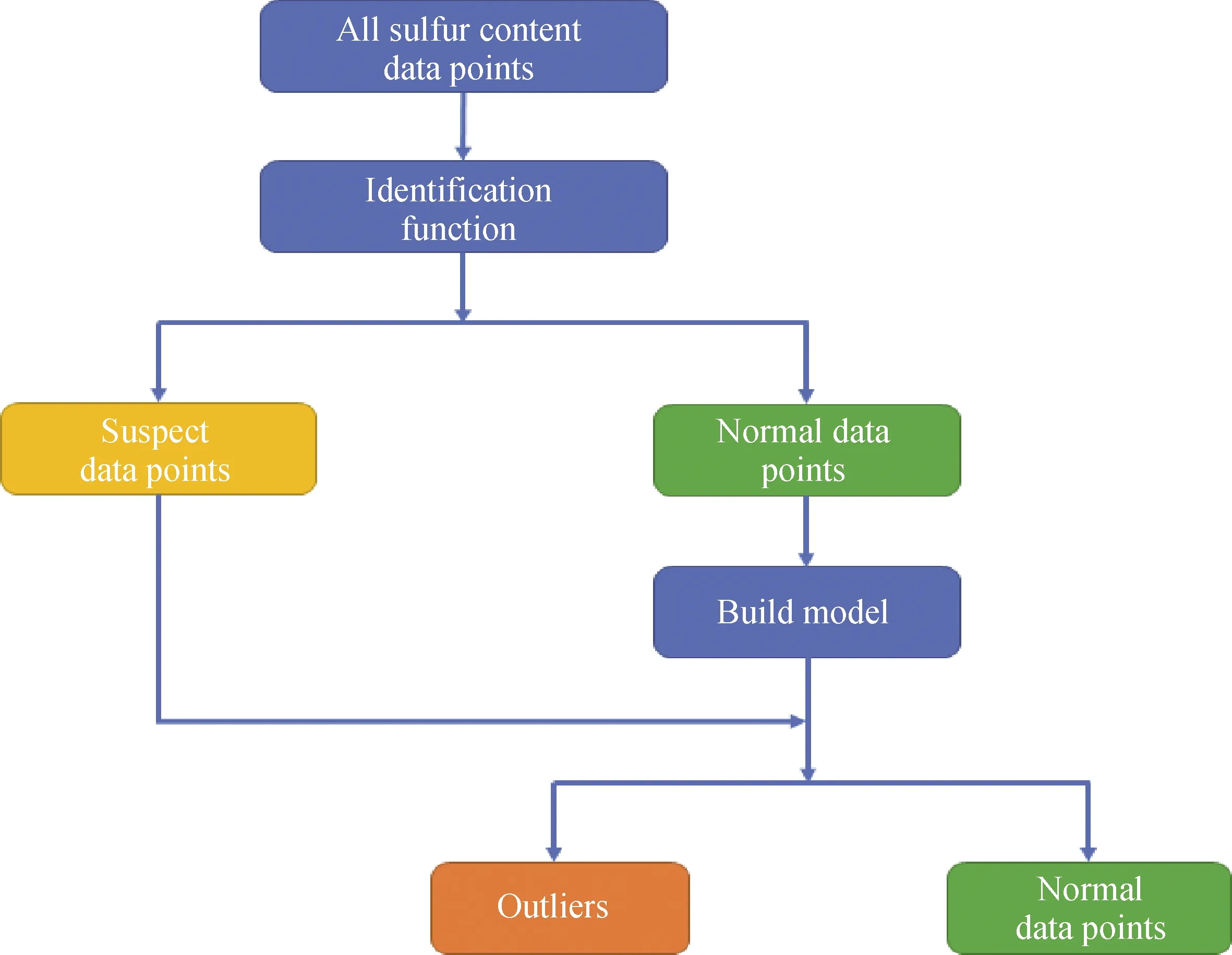
图1 精制蜡油硫含量异常点判定流程图Fig.1 Outliers determination flow chart for sulfur content of hydrogenated waxy oils
该方法判别硫含量异常点的过程主要分为2步。第一步,初步筛选出正常点和可能的异常点;第二步,用正常点建立模型,对可能的异常点进行预测,确定真正的异常点。整个过程的步骤如下:
(1)对LIMS上采集的153个精制蜡油硫含量数据点进行整理,所有硫含量数据点的分布如图2所示。
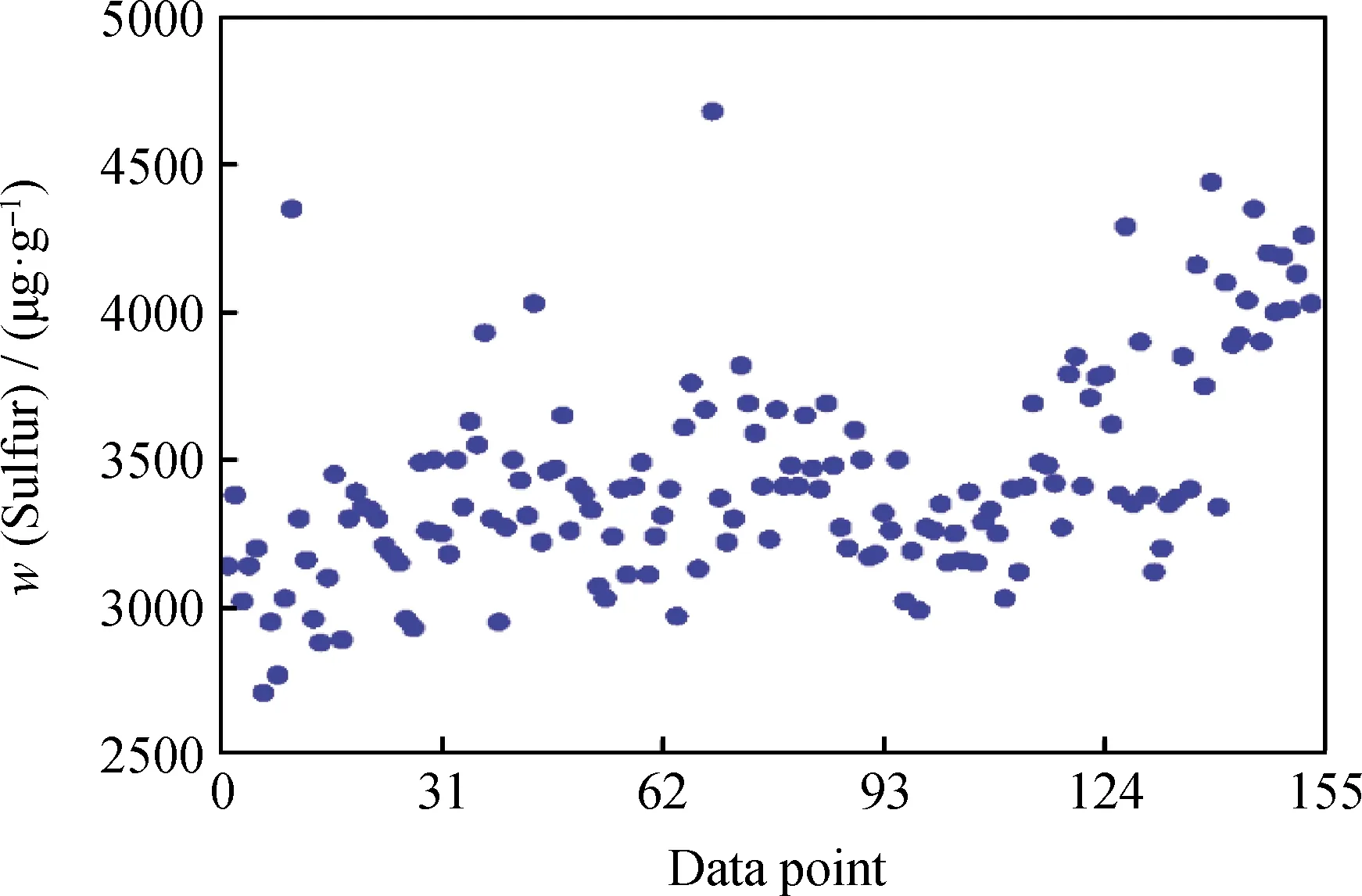
图2 所有精制蜡油硫含量数据点分布图Fig.2 Distribution of all sulfur data points of hydrogenated waxy oils
(2)构建硫含量异常点的判别函数(f(x)),其具体表达式如下:
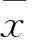

图3 初筛出来的正常点和可能的异常点Fig.3 Normal and possible outliers by initial screen procedure Blue points—Normal data points; Yellow points—Possible abnormal data points
(3)整理第一步筛选出的正常点集B所对应的原料性质和操作参数作为模型的输入;点集B所对应的精制蜡油硫含量数据点作为模型的输出,模型的输入和输出一一对应。
(4)利用Python进行模型的编写,使用已经安装好的XGBOOST算法包,调用模型的输入和输出,搭建模型。利用开源的机器学习库Sklearn将数据集随机划分为训练集、测试集。
(5)训练集用于训练模型,测试集用于检验模型的预测效果,为了保证所建模型的可靠性,采用五折交叉验证,直到评价指标平均绝对误差(MAE)达到最小。

1.冬奥会的成功申办为冰雪产业带来了广阔的发展前景。北京冬奥会助推了冰雪运动在中国的推广与普及,同时也带动了冰雪旅游、冰雪文化、冰雪装备制造业等产业的发展。预计到2025年,我国冰雪产业总规模将达到万亿元,直接参加冰雪运动的人数可达5000万人,并带动3亿人参与冰雪运动。冰雪产业无疑有着广阔的发展前景。


图4 最终确定的异常点和正常点Fig.4 Final outliers and normal data points Blue points—Normal data points; Red points—Final abnormal data points
(9)将确定的3个硫含量异常点剔除,所得硫含量正常点个数为150,将这些点所对应的原料性质和操作参数数据整理好,以备后续建模使用。
4 精制蜡油硫含量预测数据驱动建模
4.1 XGBOOST模型的建立
将筛选出来的3个硫含量异常点及其所在的数组删除后,得到输入、输出对应的数据150组,来自LIMS系统中的原料性质数据见表1,来自DCS系统中操作变量数据见表2。
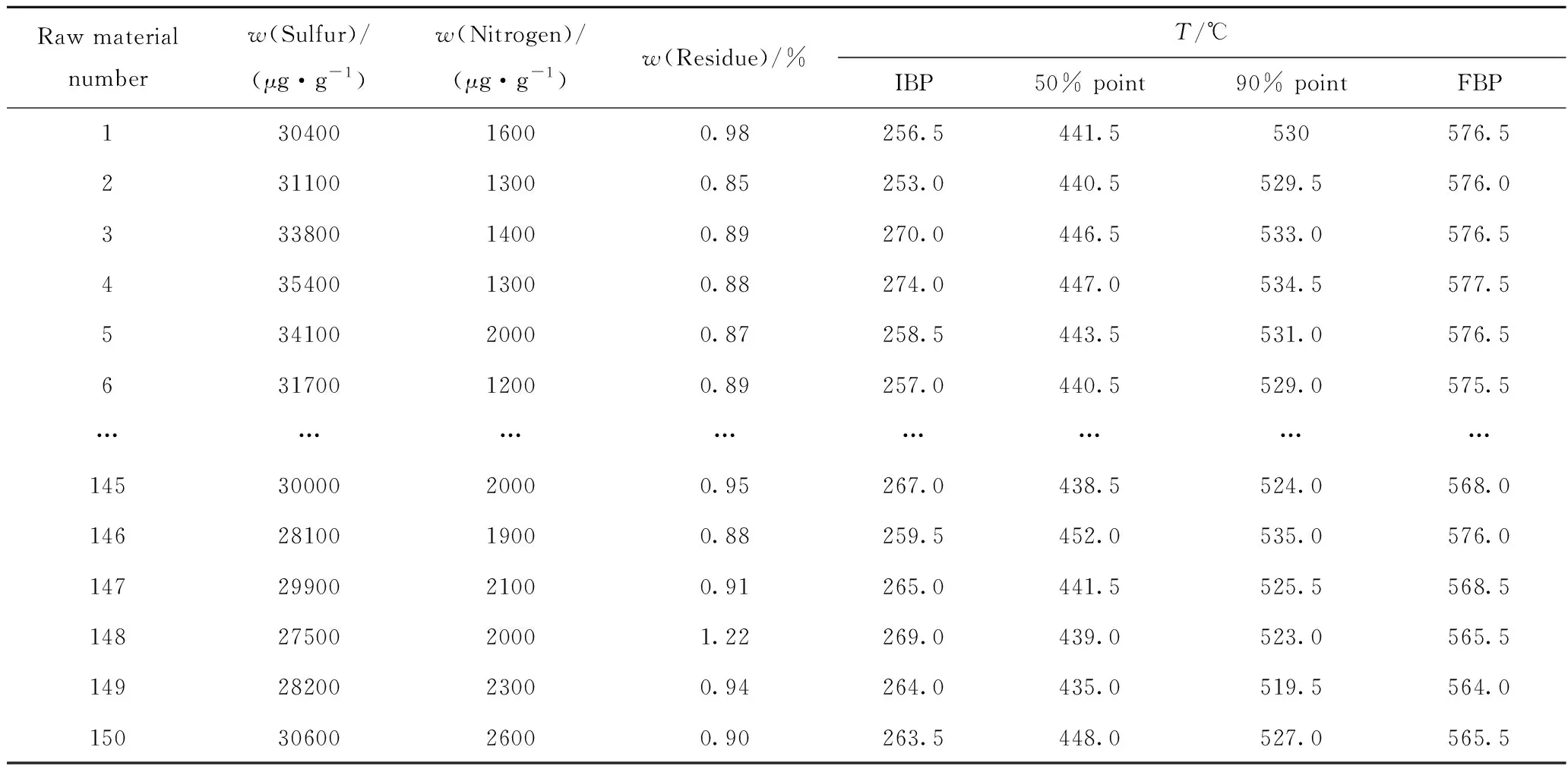
表1 来自LIMS系统的原料性质数据Table 1 Main properties of feedstocks from LIMS system

表2 来自DCS系统中的部分操作变量数据Table 2 Selected operational variables from DCS system
模型输入变量的选择基于工艺经验,模型的输出变量为精制蜡油产品中的硫含量。将挑选出来的输入变量与输出变量一一对应,便于模型调用。
将整理好的所有数据组,按照70∶15∶15划分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调节模型的超参数,测试集不参与模型的训练和调优。模型调优完毕后,对测试集数据进行一次性预测。
利用Python编写代码,调用开源的机器学习包XGBOOST,搭建模型架构。由于XGBOOST属于决策树算法,为了保证模型较好的学习能力,需要设置很多参数,这些参数由模型在验证集上的预测效果确定。模型主要设定3类参数:常规参数、增强器参数、学习任务参数。常规参数只需选择gbtree(基于树的模型),其他默认;学习任务参数中objective选择为回归,其他默认;增强器参数十分重要,可调参数较多,由于人工调参无法兼顾所有参数的最佳组合,且耗时费力,因此,笔者采用网格搜索确定增强器参数,这些参数包括学习速率、树的最大深度、叶子节点数、正则化等。模型以验证集中精制蜡油的平均绝对误差最小为停止训练指标,确定超参数后,即可对测试集一次预测,其预测效果如图5所示。
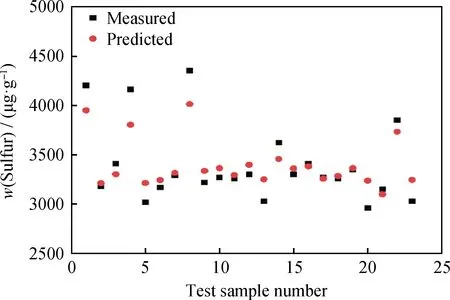
图5 测试集中精制蜡油硫含量预测效果Fig.5 Sulfur content prediction results of hydrogenated waxy oils
为了排除建模数据集划分不均匀对模型测试集预测效果的影响,笔者在编写代码的过程中,引入随机种子对训练集和验证集数据随机划分10次,调用模型,观察测试集精制蜡油硫含量预测结果,发现上述现象依然存在,对此现象进行分析,原因主要有2点:
(1)非线性预测本身的特点。由于蜡油加氢的脱硫反应是复杂的强耦合反应,在数据模型中属于非线性预测,过去规律和未来规律完全一致几乎不可能,所以必然存在一定的误差。这一点不同于线性预测(大多数情况可以完全符合)。
(2)统计模型的固有缺点。数据驱动模型终止训练的标准为均方根误差(RMSE)或平均绝对误差(MAE)达到最小,必然会忽略少数点的误差,来满足多数点的误差。
为解决这一问题,通过对精制蜡油硫含量边际点所对应的原料参数、操作参数进行检查。发现只有当原料出现较大变化、操作出现波动或者装置出现突发情况时,才会出现精制蜡油硫含量过大或过小的情况,此时,虽然操作人员对工艺条件进行了调整,由于调整不够或者过度,导致边际点的出现。对所有建模数据中精制蜡油硫含量数据点进行统计,发现边际点数据量与正常范围点数据量的比例基本为1/9左右,说明实际生产中,精制蜡油中硫含量边际点出现较少。所以,笔者在充分认识这些边际点出现原因的基础上,根据数据模型的特点,保留所有边际点,从精制蜡油硫含量正常范围点中随机挑选数据点与边际点放一起,通过改变模型精制蜡油硫含量边际点所占的比例,使模型的终止训练指标尽可能兼顾到所有的硫含量数据点。
4.2 刻意挑选数据建模
为了改变建模数据集中精制蜡油硫含量边际点的比例,笔者提出了刻意挑选数据建模的思路。具体实施方法:首先,抽出初始建模数据集中所有精制蜡油硫含量边际点;其次,随机抽取精制蜡油硫含量正常点;最后,保证抽取的硫含量边际点数据量与正常范围点数据量之比(边际点/正常点)为2/8和3/7,以这些被抽出来的数据所对应的原料性质、操作参数作为模型的输入,抽取出来的精制蜡油硫含量作为模型的输出,建立模型。采用这种方式的目的是:人为使模型在训练过程中评估模型的训练效果时,能兼顾所有数据点预测值与实测值的偏差;不至于出现多数硫含量正常范围点预测值与实测值的偏差小,而少数硫含量边际点预测值与实测值的偏差大的情况。模型训练完毕,采用测试集数据检验模型的预测效果。当抽取的边际点/正常点为2/8时,模型的预测效果如图6(a)所示;当抽取的边际点/正常点为3/7时,模型的预测效果如图6(b)所示。
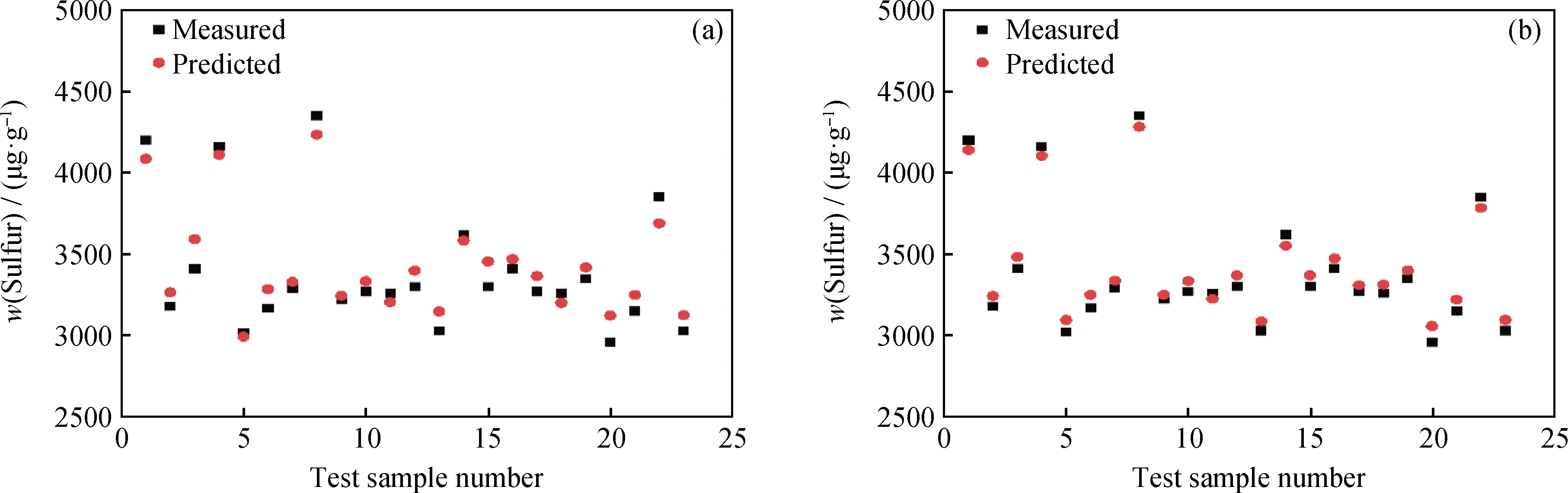
图6 不同边际点/正常点比例的建模预测效果Fig.6 Prediction results for models with different marginal point/normal point ratios(a) The ratio of marginal point to normal point of 2/8 model; (b) The ratio of marginal point to normal point of 3/7 model
将边际点/正常点为1/9的初始模型与边际点/正常点为2/8和3/7的模型对测试集精制蜡油硫含量的预测效果进行对比,统计结果见表3。
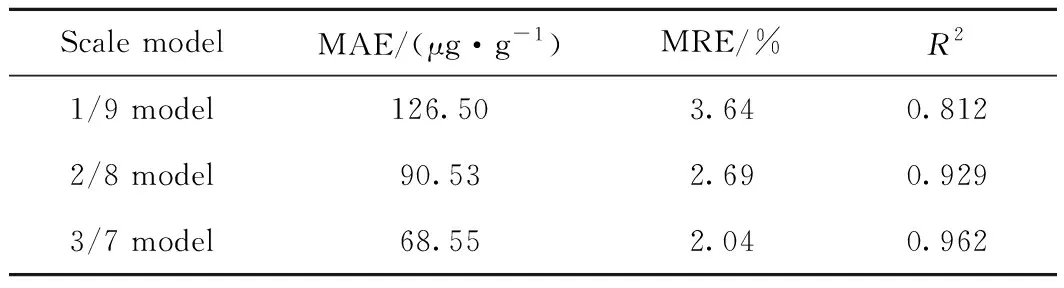
表3 不同边际点/正常点比例的模型对测试集 精制蜡油硫含量的预测结果Table 3 Sulfur content prediction results for models with different marginal point/normal point ratios
对比图5和图6可以明显看出,与边际点/正常点为1/9的初始模型相比,边际点/正常点为2/8和3/7的模型对硫质量分数大于4000 μg/g、小于3100 μg/g数据点预测值与实测值的偏差明显缩小。从表3可以看出,与边际点/正常点为1/9的初始模型相比,边际点/正常点为2/8和3/7的模型,MAE分别缩小了35.97和57.95 μg/g,MRE分别降低了0.95百分点和1.6百分点,R2分别增大了0.117和0.15,说明建模过程中增大精制蜡油硫含量边际点的占比,可显著提高模型对测试集精制蜡油硫含量的预测效果。从图6还可以看出,对硫质量分数大于4000 μg/g、小于3100 μg/g的数据点,边际点/正常点为3/7的模型(见图6(b))预测值与实测值的偏差小于边际点/正常点为2/8的模型(见图6(a)),说明边际点/正常点为3/7的模型对于边际点的预测效果更好。从表3也可以看出,与边际点/正常点为2/8的模型相比,边际点/正常点为3/7的模型对测试集精制蜡油硫质量分数的预测,MAE缩小了21.98 μg/g,MRE降低了0.65百分点,R2增加0.033,说明精制蜡油硫含量边际点/正常点的比值越高,模型对测试集中精制蜡油硫含量的预测效果越好。
虽然刻意挑选数据,改变精制蜡油硫含量边际点/正常点比例的建模思路,一定程度上解决了由于统计模型的固有缺陷,导致少数边际点预测效果差的问题。但人为筛选数据,会导致建模数据量变少,且边际点/正常点的比值越高,用来建模的有效数据越少。当建模数据量不够时,模型会因为数据范围不够广,而影响其泛化能力。因此,在实际应用过程中,需要在边际点/正常点比例和建模数据量之间进行权衡。当建模数据量较多时,可以刻意选择更高的边际点/正常点比例用来建模;当建模数据量较少时,则需要适当选择较低的边际点/正常点比例,来保证模型的泛化能力。
5 结 论
(1)根据蜡油加氢装置实际生产情况,对收集到的精制蜡油硫含量数据进行处理,构建新的判别方法,分两步找出硫含量中隐藏的异常点,使选入模型的数据更为准确,避免了异常点对模型泛化能力的影响。
(2)对模型预测硫含量边际点时误差大的原因进行了深入分析,发现统计模型终止训练标准的固有缺陷,该缺陷决定模型在训练过程中会忽略少数边际点预测值与实测值之间的偏差,来保证多数点的准确性。
(3)通过刻意选择数据,改变原始数据中精制蜡油硫含量边际点数据量与正常范围点数据量的比例,使模型在训练过程中,尽可能兼顾到所有样本点预测值与实测值之间的偏差。使用测试集数据对训练好的模型进行测试,与硫含量边际点/正常点为1/9的模型相比,边际点/正常点为2/8和3/7的模型对精制蜡油硫质量分数预测的平均绝对误差分别缩小35.97 μg/g和57.95 μg/g,平均相对误差分别缩小0.95百分点和1.6百分点,基本解决了原料发生变化或操作波动时精制蜡油硫含量预测不准的问题。
