基于深度学习的车灯零部件缺陷检测系统设计
2022-07-18曾文治王疆瑛蔡晋辉
曾文治,王疆瑛,蔡晋辉
(1.中国计量大学 材料与化学学院,浙江 杭州 310018;2.中国计量大学 计量测试工程学院,浙江 杭州 310018)
车灯零部件是汽车灯具中的重要组成部分,然而汽车车灯零部件的缺陷问题,如毛刺、裂痕和缺胶影响着产品外观以及后续的装配和导通。
随着社会需求和汽车工业的发展,对车灯零部件质量的要求越来越高[1],而目前大多数企业采用的都是人工检测方法,这种受人的主观因素的检验方法很难保证产品的质量,其速度也很难与自动化的机器相比较。然而,使用深度学习算法的检测不仅提高了产品的检测精度和速度,且减少了人工,极大满足企业高自动化和高精度检测需求。Lv[2]等人通过提出一种主动的缺陷检测学习框架来提升较少数据集的训练性能,Chen[3]等人通过深度学习算法对边缘胶合模板进行缺陷检测,取得了较高的准确性。Ullah[4]等人通过深度学习技术对高压电气设备进行了缺陷检测,能以96%的准确率将有缺陷和无缺陷设备分开。本文通过了解国内外深度学习技术的研究现状,以车灯零部件为对象,设计了一套缺陷检测系统对车灯零部件进行在线实时检测。
1 系统结构设计与检测需求
1.1 系统结构
本文缺陷检测系统结构简图如图1,车灯零部件通过放入工作平台的目标区内,相机拍照完成取图并检测,整个检测流程仅需1~2 s。

图1 缺陷检测系统结构简图
1.2 检测需求
待测产品的实际大小为100 mm×100 mm,通过下文选用的500万像素工业相机和精度公式(1):
(1)
式(1)中P为精度,F为单方向视场大小,K为相机单方向分辨率。
取视野范围120 mm×120 mm,可以算出单像素精度为0.063 mm。本产品的检测需求部位如图2,毛刺缺陷为1种,毛刺面积大多在2 mm×2 mm。红圈部位代表缺陷部位(毛刺)。

图2 待测产品检测需求部位
2 硬件设计与选型
本文根据该车灯零部件的缺陷部位和上面的结构图设计了一套满足该检测系统成像的硬件。相机选用海康威视的MV-CA050-10GM型号工业相机,镜头选用海康威视的MVL-MY-1-65-MP型号工业远心镜头,光源选用上海汇林图像科技有限公司的HL-BKH-60型号蓝色背光源,通过硬件方面的选型后,对产品进行打光拿到的效果图如图3。

图3 光源打光图
3 深度学习框架
深度学习[5]是机器学习中一种基于对数据进行表征学习的方法,分为监督学习与无监督学习,不同的学习框架下建立的学习模型很是不同。例如卷积神经网络就是一种深度的监督学习下的机器学习模型,而深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征,图4表示的深度学习框架的基本流程图。

图4 深度学习框架基本流程图
3.1 自制缺陷数据集
通过工业相机采集到车灯零部件中样品图片,拿到了缺陷(毛刺)图像100张,合格图像100张,由于样本数较少,通过图像仿射变换等方式提升正负样本数量各500张,如图5,并用LabelImg软件进行标注,划分训练集、验证集和测试集。

图5 缺陷图像
3.2 基于YOLOv3的车灯零部件缺陷检测
YOLOv3[6]的提出是在YOLOv2的改进点上做的进一步优化,主要将主干网络的Darknet19替换为Darknet53,然后使用多标签分类,对每个标签进行二元交叉熵计算损失,而不是使用均方误差来计算分类损失,同时也采用了多尺度预测对网络结构进行采样拼接,提升了小目标的检测精度。
3.2.1 网络结构
YOLOv3的网络结构主要包含四个部分。
输入层,YOLOv3一般会将输入进来的图像储存转换为固定的三通道608×608×3的大小。
主干网络Darknet53层,作为YOLOv3的主干特征提取网络,输入进来的图片会在该层进行特征提取,Darknet53的网络结构图如图6。

图6 Darknet53网络结构图Figure 6 Darknet53 network structure diagram
从图6中可以看出,以416×416×3的输入为例,Darknet53中使用了残差网络(Residual),整个主干部分都是由残差卷积构成的,每个残差卷积中使用一次1×1和一次3×3的卷积核进行卷积,通过连续使用残差卷积逐渐实现阶段的优化,并且通过增加深度来提高准确率。
颈部网络层,通过构建FPN特征金字塔对主干网络中的图像进行加强特征提取,将分别位于Darknet53的中下底层的三个有效特征层进行构建,并通过构建FPN特征金字塔能将不同形状的特征层进行融合,从而获取更好的图像特征。
预测网络层,将三个加强特征层将送入YoloHead中进行预测,针对每个特征层都存在3个先验框,比如输入M张416×416的图片后,通过运算将会输出三个形状分别为(M,13,13,255),(M,26,26,255),(M,52,52,255),其结果对应三个形状网格上先验框的具体位置。
3.2.2 损失函数
YOLOv3的损失函数大致分为以下几个部分。
由目标框的x,y,w,h四个参数带来的误差,即锚框的损失,同时锚框的损失又可分为x,y带来的二元交叉熵损失[7](BCE Loss)和w,h带来的均方误差损失[8](MSE Loss)。
由目标的置信度带来的误差,主要为BCE Loss。
由分类的类别带来的误差,主要为类别个数的BCE Loss。
BCE的具体公式计算如下:
(2)
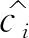
而对于YOLOv3,回归损失会通过乘以一个(2-w×h)的比例系数来提高整个模型的平均精度(AP,Average Precision),造成AP低的原因可能也是因为缺陷数据集的检测目标较小,损失值值不能出现稳定状态或是出线过拟合现象,以下为整理过后的损失函数公式:
(3)

3.2.3 模型训练与测试实验
网络训练环境基于Win10,CPU为Intel(R) Core(TM) i7-7800X CPU @ 3.50 GHz,16 G内存,GPU为NVIDIA GeForce RTX 2080Ti,CUDA和cudnn版本分别为V10.1和V8.04,使用YOLOv3模型训练时,设置学习率为0.001,迭代次数epoch为150,每次处理的样本数目为4。训练过程中在代码中设置实时绘制损失曲线,其损失函数曲线图如图7。

图7 YOLOv3的loss曲线图
从图7中可以看出,训练损失和验证损失在经过40次迭代后基本处于稳定,在经过140次迭代后损失降到0.5左右,当损失值趋于稳定时表明模型已经训练完成,将训练出来的模型权重在测试集中进行测试,得到的类平均精度(mean average precision,mAP)图如图8。

图8 YOLOv3 mAP图
图中7可以看出Maoci类的mAP达0.67,但还不足以满足实际生产检测需求。
3.3 基于改进的YOLOv3的车灯零部件缺陷检测
通过上节实验分析得出YOLOv3模型的mAP值较低,不能胜任企业检测需求。通过分析原因得出:在样本数没有增加的情况下,可能是目标太小导致检测不够精确,为此对YOLOv3模型的网路结构进行一定的改进和优化。
3.3.1 改进的YOLOv3的网络结构
从YOLOv3的对比实验可知,Darknet53主干网络对目标较大的物体检测效果较好,但是对本文中前照灯固定环中小的毛刺目标检测精度仍不理想。通过YOLOv3的网络结构了解到,Darknet53中含有23个残差单元[9],当网络进一步加深时,会出现梯度消失、训练困难等问题,并加大了网络设计难度和计算开销,从而影响后续的检测精度,为此,本文通过如图9的改进CresX结构将残差单元连接,让输入的特征分两部分进行卷积,以提高特征的重用性,并且在被输入到残差单元之前通道被减半,这就极大减少了计算量,提升了检测速度,而为了更好的识别到小目标,将原始的特征层大小52×52、26×26、13×13分别提升到104×104、52×52,26×26。

图9 改进的YOLOv3网络结构图
3.3.2 改进的YOLOv3的损失曲线
通过改进的YOLOv3模型对自制的缺陷数据集进行训练,得出其损失函数图如图10所示,图中可以看出,当训练迭代在60次左右,Loss曲线才区域稳定,并在110次迭代后Loss值稳定在0.1左右,代表训练完成。
3.3.3 其他模型实验对比
在同等设备下使用Faster-RCNN[10]和YOLOv4[11]模型对自制缺陷数据集进行训练,通过对比分析,其结果如图11,其模型大小和检测速度如表1。

图10 改进的YOLOv3 loss曲线图

图11 四种模型的AP值
从上面的图表可以分析得出,Faster-RCN的精确度高于YOLOv3,但是其检测速度在同等设备下太慢,而YOLOv3虽然精确度比Faster-RCNN低一点,但是完全体现了YOLO算法的优势,YOLOv4更是在速度和精度上得到了一定的提升,其mAP达到了0.74左右,通过本文改进的YOLOv3模型的mAP可达0.86,很好地满足了该产品的检测需求。

表1 四种网络模型大小和计算速度
4 实际应用效果
为了让员工更容易使用本文设计缺陷检测系统,设计一套人机交互系统,使员工更方便地通过界面直观地观察整个生产作业情况和质量情况,其界面如图12。将本文设计的检测系统投入实际试机,平均每小时生产情况表如表2。

表2 产品平均每小时检测情况

图12 缺陷检测功能界面图Figure 12 Defect detection function interface diagram
从表2中可以看出,使用本文中的检测系统对比人工目检,检测速度提升至少3~4倍,在实际生产检测中,本文检测系统准确率可达86.2%,提升效率的同时满足企业生产检测需求,后续可以对检测模型进行优化或者增加样本数提升准确率。
5 结 论
本文通过分析实际产品的检测需求、合理的硬件选型和深度学习框架的实验对比,针对车灯零部件设计了一套缺陷检测系统用于实际生产。本文通过标注缺陷数据集,使用YOLOv3模型对其进行训练,实验得出准确率为67.2%,而较低的准确率无法达到企业检测需求,进而提出一种改进的YOLOv3模型来对小目标缺陷进行检测,同时与Faster-RCNN,YOLOv4模型对比,实验表明,改进的YOLOv3模型的准确率达到86.2%,相较于人工目检,检测速度提升3~4倍,检测准确率也在一定程度上满足企业需求,验证了深度学习在缺陷检测方面的可行性,发挥了其实际应用价值。
然而,本文对毛刺这类小目标缺陷识别率仍有待提高,一方面通过提高缺陷样品数,另一方面通过优化网络模型和参数,通过调整以上两方面为未来针对小目标识别获取更高准确率提供基础。
