Meta Ordinal Regression Forest for Medical Image Classification With Ordinal Labels
2022-07-18YimingLeiHaipingZhuJunpingZhangandHongmingShan
Yiming Lei, Haiping Zhu, Junping Zhang,,, and Hongming Shan,,
Abstract—The performance of medical image classification has been enhanced by deep convolutional neural networks (CNNs),which are typically trained with cross-entropy (CE) loss.However, when the label presents an intrinsic ordinal property in nature, e.g., the development from benign to malignant tumor,CE loss cannot take into account such ordinal information to allow for better generalization. To improve model generalization with ordinal information, we propose a novel meta ordinal regression forest (MORF) method for medical image classification with ordinal labels, which learns the ordinal relationship through the combination of convolutional neural network and differential forest in a meta-learning framework. The merits of the proposed MORF come from the following two components: A tree-wise weighting net (TWW-Net) and a grouped feature selection (GFS)module. First, the TWW-Net assigns each tree in the forest with a specific weight that is mapped from the classification loss of the corresponding tree. Hence, all the trees possess varying weights,which is helpful for alleviating the tree-wise prediction variance.Second, the GFS module enables a dynamic forest rather than a fixed one that was previously used, allowing for random feature perturbation. During training, we alternatively optimize the parameters of the CNN backbone and TWW-Net in the metalearning framework through calculating the Hessian matrix.Experimental results on two medical image classification datasets with ordinal labels, i.e., LIDC-IDRI and Breast Ultrasound datasets, demonstrate the superior performances of our MORF method over existing state-of-the-art methods.
I. INTRODUCTION
MEDICAL image classification has been assisted by the deep learning technique [1]–[8] and has achieved tremendous progress in the past decade. Early detection and treatment of some diseases, such as cancers, are critical for reducing mortality. Fortunately, it is implicit in medical images that the image information across the different clinical stages exhibits an ordinal relationship, which can be used to improve model generalization. For example, computed tomographic (CT) images of lung nodule [9] are given with the malignancy scores from 1 to 5, where 1 means highly unlikely to be malignant, 3 is indeterminate, and 5 is highly likely to be malignant. The majority of existing lung nodule classification methods conduct binary classification while discarding indeterminate or unsure nodules [3], [8], [10]–[14].In other words, the unsure nodules that are between benign and malignant and cannot be classified by radiologists based on current scans become useless [15]. As shown in Fig. 1, a large number of nodules are indeterminate and then discarded in the binary classification problem. It is evident that the images with ordinal labels represent the development of the lesions, as do other diseases such as breast cancer.Considering that deep learning methods are data-hungry and that these medical images differ from natural images in fewer discriminative patterns, leveraging the ordinal relationship among limited medical data for training deep learning models is becoming an important topic.
Generally, most medical image classification methods work by feeding medical images into convolutional neural networks(CNNs) and updating the parameters of the CNNs based on cross-entropy (CE) loss. However, CE loss is inferior for fitting the ordinal distribution of labels. Therefore, ordinal regression-based methods have been explored for medical image classification with ordinal labels [15]–[17]. A simple solution is to construct a series of binary classification problems and evaluate the cumulative probabilities of all binary classifiers [16], [17]. However, those binary classifiers are trained separately, which ignores the ordinal relationship.Recently, the unsure data model (UDM) [15], neural-stick breaking (NSB) [18], unimodal method [19], and soft ordinal label (SORD) [20] have been proposed to improve ordinal regression performance based on rectified label space or the probability calculation of the output of the CNNs.
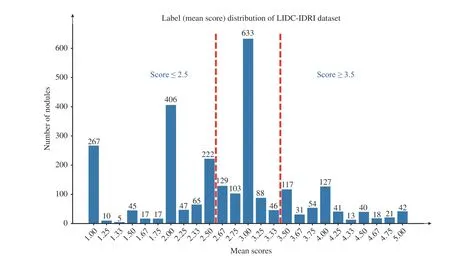
Fig. 1. The histogram of averaged malignant scores of nodules in LIDC-IDRI dataset. The red dashed lines split the nodules into three groups; i.e., benign(≤ 2.5), unsure (2 .5 ∼3.5), and malignant (≥ 3.5).
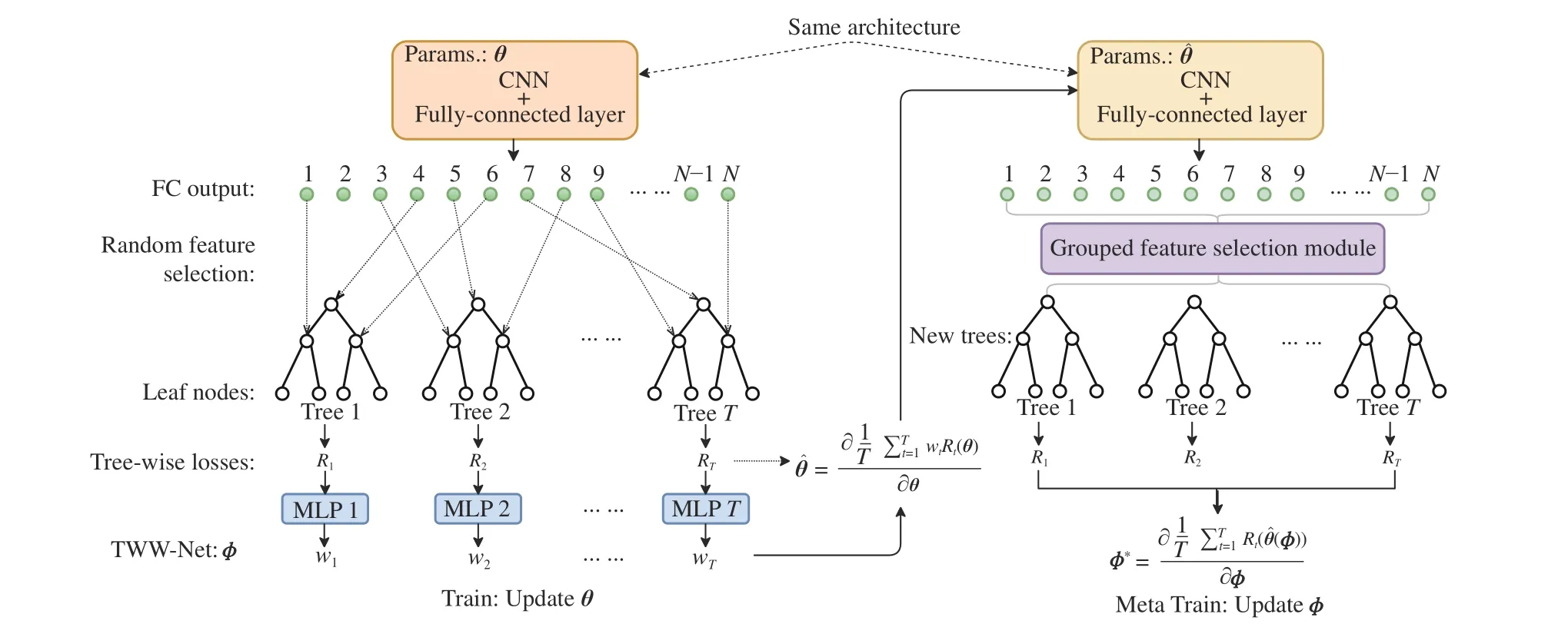
Fig. 2. The proposed MORF framework. Left: The deep ordinal regression forest with random construction of forest, which is followed by the TWW-Net.Right: The deep ordinal regression forest followed by the TWW-Net, where the forest is constructed from the GFS. During the meta train stage, the GFS features are used to guide the update of θ. The MORF framework involves three parts of parameters: θ (CNN), π (leaf nodes, i.e., the ordinal distributions), and ϕ(TWW-Net). Note that the parameter θˆ on the right side is the first-order derivative calculated via (8). And θˆ is used to obtain the TWW-Net parameterϕ(u+1)through (9).
Another method of ordinal regression without changing target distributions is based on the combination of random forest and CNNs, which has been evaluated to successfully estimate human age using facial images [4], [5], [21]. These models regard the largest probability among all the dimensions of the learned tree-wise distributions as the final prediction. To incorporate the global ordinal relationship with forest-based methods, Zhuet al. proposed the convolutional ordinal regression forest (CORF) to allow the forest to predict the ordinal distributions [22]. However, these forest-based methods suffer from the following two drawbacks: 1) The compositions of all trees depend on the random selection of split nodes from the feature vector of the fully-connected (FC)layer, and the structure of the constructed forest is fixed at the very beginning of training, leading to poor generalization due to the lack of the random perturbation of features, as suggested in [23]; and 2) There exists the tree-wise prediction variance (tree-variance) because the final prediction of the forest is the average of the results obtained by all trees, i.e., all trees share the same weights and contribute equally to the final prediction.
To address the aforementioned problems, we propose a meta ordinal regression forest (MORF) for medical image classification with ordinal labels. Fig. 2 shows the overall framework of MORF including three parts: A CNN backbone parameterized byθto extract feature representation from the input medical image, a tree-wise weighting network (TWWNet) parameterized byϕto learn the tree-wise weights for reduced tree-wise prediction variance, and a grouped feature selection (GFS) module to construct the dynamic forest that is equipped with random feature perturbation. We adopt the meta-learning framework to optimize the parametersθandϕalternatively [24], [25]. The way we use meta-learning is similar to those in [24], [25], which calculates the second derivatives, i.e., Hessian matrix, via meta data or meta tasks.The main difference is that our meta data are selected features via the GFS module rather than the original images; the meta data in [24] are a subset of the validation set that contains equal numbers of images of all classes, which may be infeasible in medical cases because some classes have fewer samples. With meta-learning optimization, CNN parameters can be updated with the guide of the dynamic forest, which can achieve better generalizability.
The main contributions of this paper are summarized as follows.
1) We propose a meta ordinal regression forest (MORF) for medical image classification with ordinal labels, which enables the forest on top of the CNNs to maintain the random perturbation of features. The MORF comprises a CNN backbone, a TWW-Net, and a GFS module.
2) TWW-Net assigns each tree in the forest with a specific weight and alleviates the tree-wise variance that exists in the previous deep forest-related methods. Furthermore, we provide a theoretical analysis on the weighting scheme of TWW-Net and demonstrate how the meta data can guide the learning of the backbone network.
3) The GFS module only works in the meta training stage for generating the dynamic forest that incorporates the feature random perturbation. Combined with the TWW-Net, the final trained model can be further enhanced through the randomness of the dynamic forest.
4) The experimental results on two medical image classification datasets with ordinal labels demonstrate the superior performance of MORF over existing methods involving classification and ordinal regression. Furthermore, we also verify that our MORF can enhance the benign-malignant classification when leveraging the unsure data into the training set on the LIDC-IDRI dataset.
We note that this work extends our previous conference paper [26] with the following major improvements:
1) We further explore the relationship between our reconstructed dynamic forest and the random forest, which unveils that our MORF has stronger generalizability than the previous deep forest methods due to its retained random perturbation during training.
2) We improve GFS module by using random selection without replacement, where the resulting dimension of FC output should be equal to the number of split nodes in a forest.This improvement can avoid selecting unused elements during meta-training stage and achieve further performance gain.
3) We provide the detailed training algorithm and the theoretical analysis on the meta weighting scheme of TWWNet.
4) For the LIDC-IDRI dataset, we demonstrate that the binary classification on the benign and malignant classes can be improved by MORF. Most importantly, when we added the unsure data into the training set, the binary classification results on the test set are improved further.
5) We conduct extra experiments on a new breast ultrasound images (BUSI) dataset [27] to evaluate the performance of the methods.
II. RELATED WORK
In this section, we review the related work on the following three aspects: 1) CNN-based methods for medical image classification with emphasis on lung nodule classification and breast cancer diagnosis, 2) ordinal regression methods, and 3)meta-learning methods.
A. CNN-Based Medical Image Classification
Medical image classification, such as lung nodule and breast tumor classification, has benefited from advanced CNN architectures and learning strategies. In this paper, we focus on medical image classification with ordinal labels.
Lung Nodule Classification:Liuet al. combined statistical features and artificial neural networks to detect lung nodules in full-size CT images [28]. Shenet al. applied a single column network to classify lung nodule images with different sizes [12]. Douet al. [13] explored an ensemble of subnetworks, each of which has a specific convolutional kernel size. Caoet al. trained two 3-D networks on original data and augmented data, and combined them for lung nodule detection [29]. However, 3-D networks are difficult to train with limited medical data [30], [31]. Another kind of method combines low-level and high-level features that come from UNet-like network architectures [8], [32]–[36], which can avoid information loss through the concatenation of different features.
Breast Cancer Diagnosis:Breast cancer diagnosis has also been enhanced by deep learning [2], [18], [37]–[45]. In [41],[46], the authors conducted the CNN-based image fusion,feature fusion, and classifier fusion methods to classify breast tumors in ultrasound (US) images. Wuet al. explored the binary classification (benign and malignant) of breast cancer based on the proposed view-wise, image-wise, breast-wise,and joint learning approaches [43]. Akselrod-Ballinet al.combined CNN learned features with the electronic health records to improve the early detection of breast cancer using mammograms [44]. Dhungelet al. applied a pretrained CNN model in the classification of breast cancer and verified the effectiveness of deep features against traditionally handcrafted features [45]. Hagoset al. incorporated symmetry patches with the symmetric locations of positive tumor patches to help improve breast cancer classification performance [46].
All the methods we reviewed above did not take into account the progression of the diseases that implies the intrinsic ordinal relationship among the classes. In this paper,we use widely-used backbone networks such as VGG [47] and ResNet [1] to verify the effectiveness of our method in exploring ordinal relationship.
B. Ordinal Regression
Ordinal regression is a classical problem that predicts ordinal labels [16], [17], [48], such as facial age [22], aesthetic image classification [49], and medical image malignancy ranking [15], [18], [19]. Beckham and Pal enforced each element of the FC output to obey unimodal distributions such as Poisson and Binomial [19]. The unimodal method surpassed the normal cross-entropy baseline. Neural stickbreaking (NSB) was proposed in [18], whose output is a(N−1)- dimensional vector representingN−1 boundaries whereNis the number of classes. NSB guaranteed that the cumulative probabilities would monotonically decrease. The unsure data model (UDM) is a strategy-driven method and focuses more on the fact that normal samples and disease samples should be classified with high precision and high recall, respectively [15]. The UDM incorporates some additional parameters associated with techniques like ordinal regression, class imbalance, and their proposed strategies.Although the UDM outperforms the unimodal method and NSB, it requires more effort to tune the model to obtain the optimal additional parameters. Soft ordinal label (SORD)converted the ground truth labels of all classes in a soft manner by penalizing the distance between the true rank and the label value [20].
The methods discussed above contain a deep neural network(DNN) backbone followed by a modified classifier (FC layer)except for the SORD method. This pipeline cannot avoid the redundant use of the FC feature and may lead to overfitting.Recently appeared deep random forest-based methods targeted this problem. The deep neural decision forest (DNDF) defines a differentiable partition function for each split node [5].Hence, the forest can be updated jointly with the deep networks through backpropagation. The label distribution learning forest (LDLF) extended DNDF to output a predicted distribution [21]. However, the DNDF and LDLF have difficulty guaranteeing the global ordinal relationship of the predictions of leaf nodes. Convolutional ordinal regression forest(CORF) was proposed to incorporate the constraint of ordinal relation in the loss function, which enabled the output of the forest to be globally ordinal (monotonically decrease) [22].
In this paper, our MORF further improves the efficiency of the FC feature and incorporates random perturbation of features for the forest. Moreover, our MORF enables different trees to have specific weights through the guidance of the meta data.
C. Meta Learning
Meta-learning is tailored for learning the meta knowledge from the predefined meta task set or meta dataset. It is widely used in few-shot learning. Model-agnostic meta-learning(MAML) [50] learns the parameter initialization from the fewshot tasks, and the new tasks only take a few training steps while achieving better generalization than fine-tuning. Jamal and Qi proposed extending the MAML to avoid overfitting on existing training tasks by proposing a maximum-entropy prior that introduces some inequality measures in the loss function[51]. Liuet al. enhanced the generalizability of the main task from the predefined auxiliary task using meta-learning [25].Meta-weight-net is a novel weighting network to address class imbalance and noisy label problems [24]. In summary, these meta-learning methods involve optimizing two groups of parameters jointly. The meta training algorithm of our MORF is similar to that of [24], but differs in its construction of the meta data and weighting behavior over the decision trees. The construction of the meta data in [24] is to select a subset of the validation set with an equal number of samples for each class for meta training, whereas the meta data in MORF are feature level.
III. METHODS
In this section, we first formulate the problem of ordinal regression forest for medical images. Then, we introduce the meta ordinal regression forest (MORF) framework in order of the training objective, TWW-Net, and GFS module. Finally,we present the meta-learning optimization algorithm and the corresponding theoretical analysis.
A. Problem Formulation
Ordinal regression solves the problem that the data belonging to different classes have an ordered label, which implies that an intrinsic ordinal relationship exists among the data. It learns a mapping functionh:X →у , where X represents the input space and у is the ordinal label space. Here,у={y1,y2,...,yC} has the ordinal relationshipy1≤y2≤···≤yC, whereCis the number of classes. In this study,yc∈у denotes the stage of the progression of diseases; taking the lung nodule classification [9] as an example,Cequals 3 andy1,y2, andy3represent benign, unsure and malignant,respectively.
To solve this kind of ordinal classification problem, the givenlabely∈уcanbeconvertedtoanordinaldistribution label,i.e., a one-dimensional vectord=(d1,d2,...,dC−1)T∈D[22], wheredc=1ify>yc, otherwisedc=0. Practically,we will obtain an accuratedfor a given image, and thedshouldmaintaina monotonicallydecreasingpropertyacross all theelements. Therefore, we imposea constraintd1≥d2≥···≥dC−1ondduring training [22]. Under the framework of the ordinal regression forest (ORF) [4], [21], [22], the ordinal labeldcis given by the leaf nodes in the ORF, and the probability of the given samplexfalling into thel-th leaf node is defined as
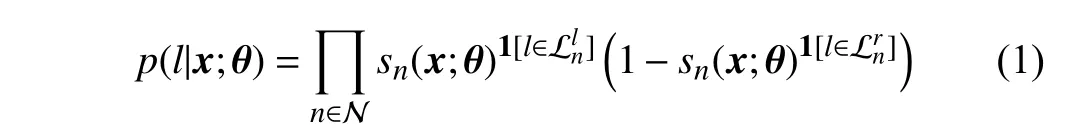
When we obtain the probabilityp(l|x;θ), the output of one tree can be defined as a mappingg:X →D,
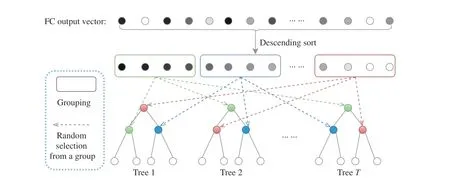
Fig. 3. The proposed grouped feature selection (GFS) assigning each tree with features of different groups. Note that the number of groups (colored boxes) in GFS equals the number of split nodes in one decision tree.
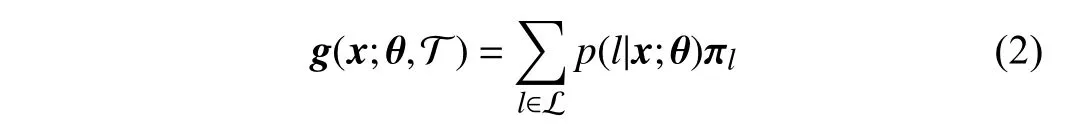
where T denotes one decision tree, and L a set of leaf nodes.πlholds the ordinal distribution of thel-th leaf node; i.e.,πl=(,,...,)T.Inthispaper, theparameterπcan be updated jointlywiththatofthebackbone networkthrough back-propagation, which has been illustrated in [4], [21], [22].Then, the final prediction of the forest is the average of outputs of all trees

whereTis the total number of trees. Here, all the trees contribute equally to the final prediction as well as that in previous deep forest methods such as the CORF [22], whereas in our MORF model, we assign each tree a specific learned weight.
B. Meta Ordinal Regression Forests
The total framework of the MORF contains a CNN with an FC layer as backbone network parameterized byθ, a TWWNet parameterized byϕ, and the leaf nodes parameterized byπ. Note that theπis updated according to [22].
1)Objective Function:As mentioned above, all trees in ORF and CORF are assigned the same weights, which can increase the inevitable tree-wise prediction variance. To cope with this drawback, we propose multiplying the tree-wise losses with specific weights. Therefore, the gradients ofθ,backpropagated from the losses of all the trees, can be affected by the weights ωt. Therefore, our training objective function is defined as
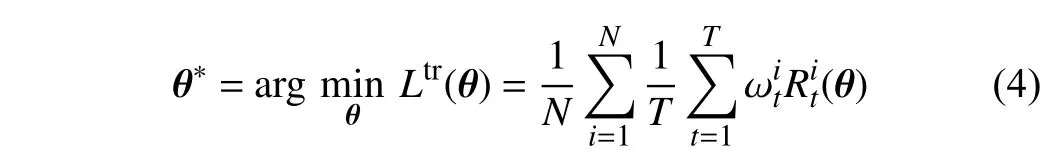
whereNis the number of training images,denotes the classification loss generated by (2), and ωtrepresents the specific weight for thet-th tree that is learned by the TWWNet, which will be subsequently introduced. Different from[24], (4) imposes the weights on the different trees w.r.t. one training samplei, rather than on the different samples.
2)Tree-Wise Weighting Network:Here, we introduce the TWW-Net that is used for learning the weights ωtin (4).Similarly to the meta-weight-net [24], TWW-Net is practically implemented as a group of multilayer perceptrons (MLPs),Vt,and each MLP acts as a weight learning function for a specific tree because of the universal approximation property of MLPs[52]. In Fig. 2 , we can see that thet-th tree generates a classification lossRt, thenRtwill be fed into the corresponding weighting netVt, and finallyVtoutputs the weightwtfor thet-th tree. This process can be formulated as
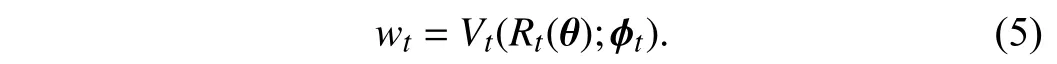
Therefore, TWW-Net is composed ofTweighting netVt,whereTis the number of trees. Here we useϕ={ϕ1,ϕ2,...,ϕT}to represent the set of parameters of TWW-Net, and they are updated together which will be described in Section III-C.Through (5), a TWW-Net can assign different weights to different trees.
Combined with (4), the training objective function can be modified as follows:
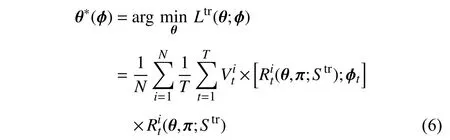
whereStrdenotes the training set.
3)Grouped Feature Selection(GFS):Although we have incorporated the tree-wise weights in the training objective function, the structure of the forest is still fixed. Therefore, we introduce the GFS module to construct the dynamic forest with random feature perturbation in this section. Then, we explore the relationship between the GFS and random forest.
As shown in Fig. 3, the GFS first ranks all the activation values of the final FC feature vector. Then it splits the ranked elements into N groups (denoted by different colors), where Nequals the number of split nodes in one decision tree. Both the elements inside and outside of one group are in descending order, and each tree randomly selects its own nodes across all the groups. Hence, one tree contains the features globally across the FC feature, and it retains the local random perturbation of the feature that is critical for the random forest. After repeating these procedures on all the trees, the dynamic forest is constructed. Note that the final trained model of MORF is also equipped with a forest that is fixed from the beginning of training, and the GFS module only works in the training stage and has no impact on the forest at the time of inference. Note that, the number of groups corresponds to the number of split nodes in one tree, i.e., the number of groups increases along with an increase of tree depth.
Relationship Between GFS and Random Forest:Random forest (RF) is a classical ensemble learning method, which benefits from base learners that have feature and data random perturbations. Specifically, feature perturbation means that each node in the decision trees is the most discriminative attribute in a subset of its whole attribute set [23]. Data perturbation is satisfied for all the deep forest-based methods that trained over shuffled mini-batches, however, feature perturbation occurs because of the fixed forest structure [4],[21], [22]. In Fig. 3(b), we can see that each split node is randomly selected from its own feature set. Although, in Fig. 3(a), all the nodes in the forest are also obtained through random selection within their subsets (indicated by different colors) of the FC feature, it differs from the RF in that the nodes in different trees share the same subsets, i.e., the GFSbased forest also maintains the node-wise feature random perturbation. Therefore, the MORF with GFS possesses the merit of randomness with respect to all the split nodes, and this advantage does not exist for previous methods [4], [5],[21], [22].
C. Optimization via Meta-Learning
When we obtain a dynamic forest, we expect it to guide the update of the CNN with a fixed forest. Moreover, from (6) we observe that the objective function involves two parts of parameters,θandϕ, andθis a function ofϕ, so we customize a meta-learning framework enabling the meta data to guide the learning of the target model. Here, the GFS selected features are regarded as the meta data, which is different from those in [24].
To obtain the optimal θ∗, we need to obtain the optimal ϕ∗.Therefore, we optimizeϕby minimizing the following objective function:
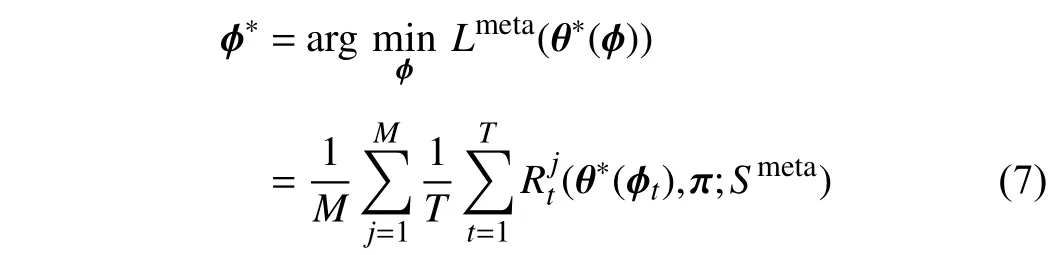
whereMis the number of meta data. This objective function indicates thatϕis updated based on the optimal backbone parameter θ∗.
First, we take the derivative of (6) with respect toθ
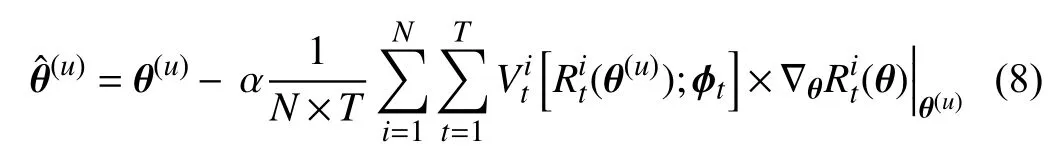
whereαis the learning rate forθ. For simplicity, we omit the parametersπand the datasetsStrandSmetain the above equations. The superscript (u) denotes theu-th iteration.Therefore, θˆ in (8) represents the weights obtained through the first order derivative ∇θ(θ). Then, we can use θˆ to update the parametersϕ
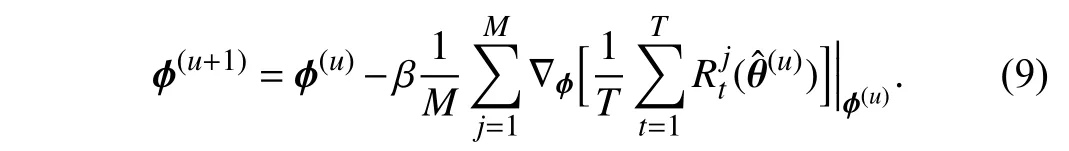
To go a step further, we derive (9) and obtain the following equation:
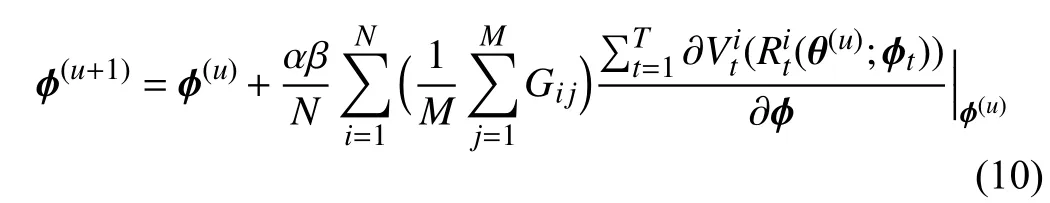
where
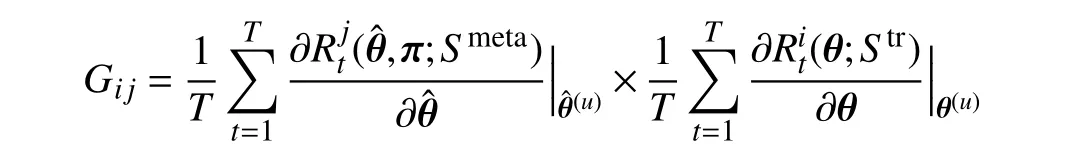
stands for the similarity between two gradients−the gradient of thei-th training data computed on training lossand the gradientofthemeanvalueofthemini-batchmetadata calculated on metaloss.Thisenforcesthegradientofthe feature of training data to approach that of meta data generated from GFS. Hence, the behavior of each tree is guided by the meta gradient and is consistent with other trees.Consequently, the predictions of different trees in our MORF are consistent, i.e., have lower variance, which guarantees a more stable prediction.
Algorithm 1 Training Algorithm of MORF

After we obtain the updated TWW-Net parameters ϕ(u+1),the update rule ofθcan be defined as
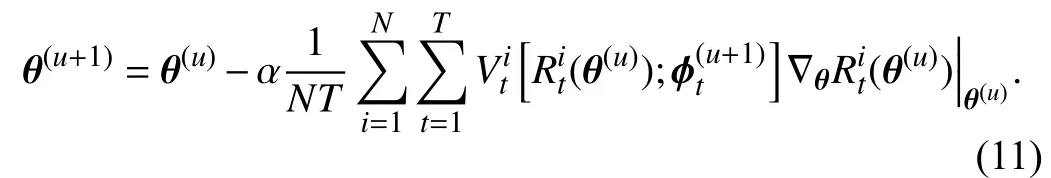
In (9), the tree-wise lossRt(,π;Smeta) is calculated via meta data, and the meta data are feature level. During the trainingprocedure, wefirstobtainthe first-order derivativein(8)bytaking theimagexasinput, andthe forestis constructed based on this forward process as shown on the left side of Fig. 2. Then, we fixin (8) and take the imagexas input, and the forest here is reconstructed through our GFS module as shown on the right side of Fig. 2. Once again, the globally and locally selected features via GFS are the meta data in our method. This retains the structural variability and the random feature perturbation of the forest. Simultaneously,our training scheme can guide the behavior of learning from training data to approach that of learning from the GFS generated meta data. The details of the training procedure are shown in Algorithm 1.
Note that the TWW-Net (ϕ) only works in the meta training stage, and it does not affect the prediction in inference. In other words, the trained model contains parametersθandπ,which are required during inference.
IV. EXPERIMENTAL SETUP AND RESULTS
In this section, we present the experimental setup and evaluate the proposed MORF method on the LIDC-IDRI [9]and BUSI [27] datasets. The experiments reported the average results through five randomly independent split folds, and for the accuracies, we reported the average values with standard deviations.
A. Data Preparation
1)LIDC-IDRI Dataset for Lung Nodule Classification:LIDC-IDRI is a publicly available dataset for pulmonary nodule classification or detection, which involves 1010 patients. Some representative cases are shown in Fig. 4. All the nodules were labeled by four radiologists, and each nodule was rated with a score from 1 to 5, indicating malignant progression of the nodule. In our experiments, we cropped the region of interest (ROI) with a square shape of a doubled equivalent diameter at the corresponding center of a nodule.The averaged score of a nodule was used as the ground-truth label during training. Note that the averaged scores also range from 1 to 5, and we regard a nodule with an average score between 2.5 and 3.5 as the unsure nodule, benign and malignant nodules are those with scores that are lower than 2.5 and higher than 3.5, respectively [15]. In each plane, all the CT volumes were preprocessed to have 1 mm spacing in each plane. Finally, we obtain the training and testing data by cropping the 32×32×32 volume ROIs located at the annotated centers.
2)BUSI Dataset for Breast Cancer Classification:The BUSI dataset can be used for ultrasound image-based breast cancer classification and segmentation, which contains 780 images of three classes: 133 normal, 487 benign, and 210 malignant images. Some representative cases are shown in Fig. 4. We first resized the original 2-D images into the same sizes 128×128, and then conducted the data augmentations,including flipping and adding random Gaussian noise, for the training set of BUSI. Finally, the training and test sets contain 1872 images and 156 images for each fold, respectively.
B. Implementation Details
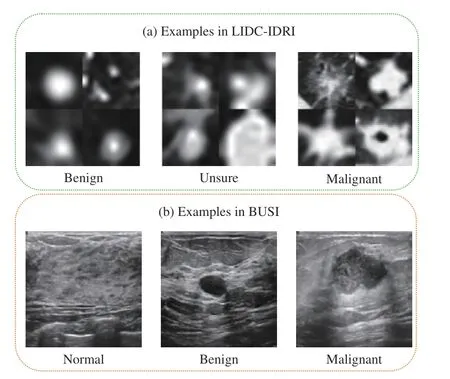
Fig. 4. Some examples in the BUSI [27] and LIDC-IDRI [9] datasets. For the LIDC-IDRI dataset, we provide four examples each class.
1)Network Architecture:We applied ResNet-18, ResNet-34, and VGG-16 [1], [47] as backbone networks to compare our MORF with other methods. Because the scales of the two datasets are relatively small, we use the 2-D version of the backbone networks to avoid the huge number of parameters in 3-D networks. Therefore, the input of the model, the 32×32×32 volumes, can be treated as 32×32 patches with 32 channels each, and the corresponding number of channels of the first layer is set as 32. For our MORF, the output dimension of the final FC layer equals the number of split nodes in a forest due to the GFS using random selection without replacement, and for CORF, it is set as 256.
2)Hyperparameter Setting:The learning rates for the LIDC-IDR and the BUSI datasets are 0.001 and 0.00005,respectively, and are decayed by 0.1 every 120 epochs (150 epochs in total); the sizes of a mini-batch size are 16, and the weight decay values for the Adam optimizer are 0.0001 and 0.00005, respectively [53]. The loss functions used in the MORF, CORF, and each tree-wise loss during meta training are the standard CE loss [54]–[56].
The number of trees for the forest is 4 and the tree depth is 3. In practice, the TWW-Net contains several MLPs, where he number of MLPs equals the number of trees. For the LIDC-IDRI dataset, we evaluated whether or not the unsure nodules were used for training or testing. Therefore, in Tables I and II, we use the symbol Train(n1) -Test(n2) to represent that here aren1classes of data for training, andn2classes for esting. The values ofn1andn2are 3 (with unsure data) or 2(without unsure data). All of our experiments are implemented with the PyTorch [57] framework and trained with an NVIDIA GTX 2080 Ti GPU.
C. Training With Unsure Data for Lung Nodule Classification
In this section, we focus on the standard 3-class classification of lung nodules. Following [15], we also care more about the recall of malignant lesions and the precision of benign lesions, which fits more appropriately with the clinical diagnosis.
In Table I, we illustrate the results of the CE loss-based methods, the related ordinal regression methods, and our MORF as well as its conference version denoted as MORFc.When using different backbones, the MORF achieves the best accuracies and F1 scores of malignant and benign. For all the backbones, the MORF also maintains the higher recall of malignant and precision of benign. Under the meaning of the clinical diagnosis, the MORF is better able to reduce the missing diagnosis rate, i.e., there will be fewer unsure and malignant nodules diagnosed as benign, and fewer malignant nodules missing a diagnosis. Most importantly, MORF obtains the best precision for malignancy, demonstrating a lower misdiagnosis rate.
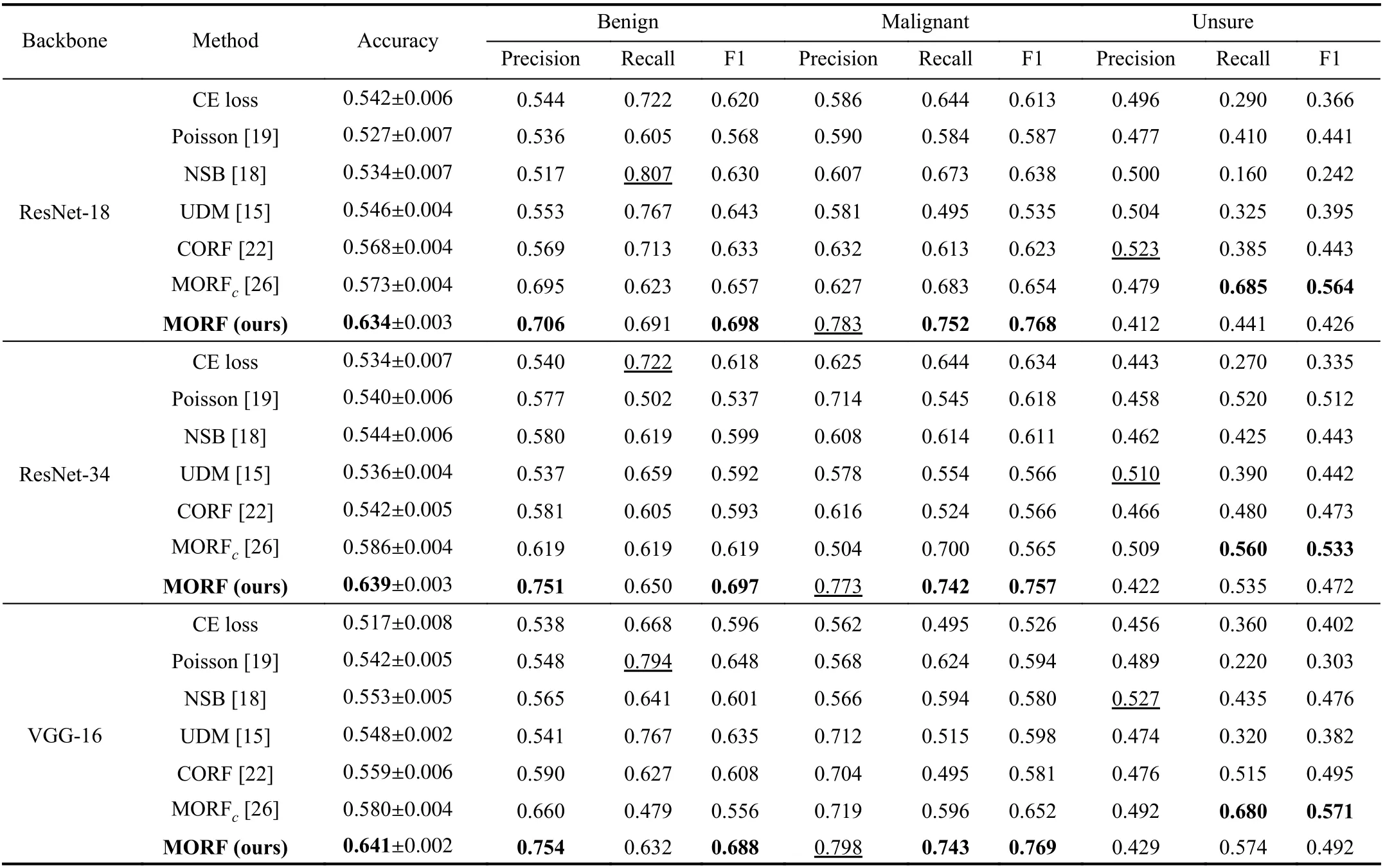
TABLE I CLASSIFICATION RESULTS ON TEST SET OF TRAIN(3)-TEST(3) ON LIDC-IDRI DATASET. THE VALUES WITH UNDERLINES INDICATE THE BEST RESULTS WHILE LESS IMPORTANT IN THE CLINICAL DIAGNOSIS [15]. MORFC IS THE CONFERENCE VERSION OF THE PROPOSED MORF [26]
Under the setting of Train(3)-Test(2) where training data include all unsure data, the feature space will be more complicated compared with the binary classification setting.However, the left part of Table II shows that the MORF significantly outperforms the other methods significantly on all measured metrics. We emphasize that the ordinal relationship of the data is critical to ordinal regression which can be regarded as a fine-grained classification, and the accurate feature representation determines the ability of the final classifier. Although both MORF and CORF [22] consider the global ordinal relationship, the fixed forest of the CORF degrades its performance in that the random feature perturbation is omitted. The MORF with reconstructed forest via the GFS module enables the update of the parameterθto be affected by the feature randomness, hence leading to a significant gain. Therefore, this experiment verifies the robustness of MORF against the influence of plugging unsure samples into the training data. Most importantly, the results of MORF on the left side of Table II are slightly better than those on the right side. This indicates that using the unsure class is helpful for improving the classification of the other two classes, i.e., the unsure nodules act as a boundary between the malignant and benign. Especially for ResNet-18/34, the recalls of malignant and the precisions of benign of Train(3)-Test(2) are higher than those of Train(2)-Test(2). VGG-16 achieves comparable results under these two settings, and we attribute this phenomenon to the different feature spaces learned by ResNet and VGG-16.
When comparing the unsure class with existing methods,Table I shows both MORF and MORFcachieve better results than other methods in terms of recall rather than precision.Similarly to the importance of recall of malignant [15], the higher recall of the unsure class provides us with significant insights that there will be fewer unsure nodules likely being classified as benign or malignant. Although the unsure class contains mixed benign and malignant samples, one should not miss any malignant samples in unsure class. That is, the unsure class should be similar to malignant class that the recall is relatively more important than the precision.Therefore, MORF and MORFcare helpful for further diagnosis of nodules, such as biopsy. Consequently, MORF is more suitable for real clinical circumstance while recomm-ending more accurate diagnosis of follow-ups. It is noticed that this superiority does not hold in the UDM method [15].On the other hand, for a certain backbone, both the MORF and MORFcoutperform the CE loss-based counterpart, which exhibits their effectiveness on exploiting ordinal relationship.
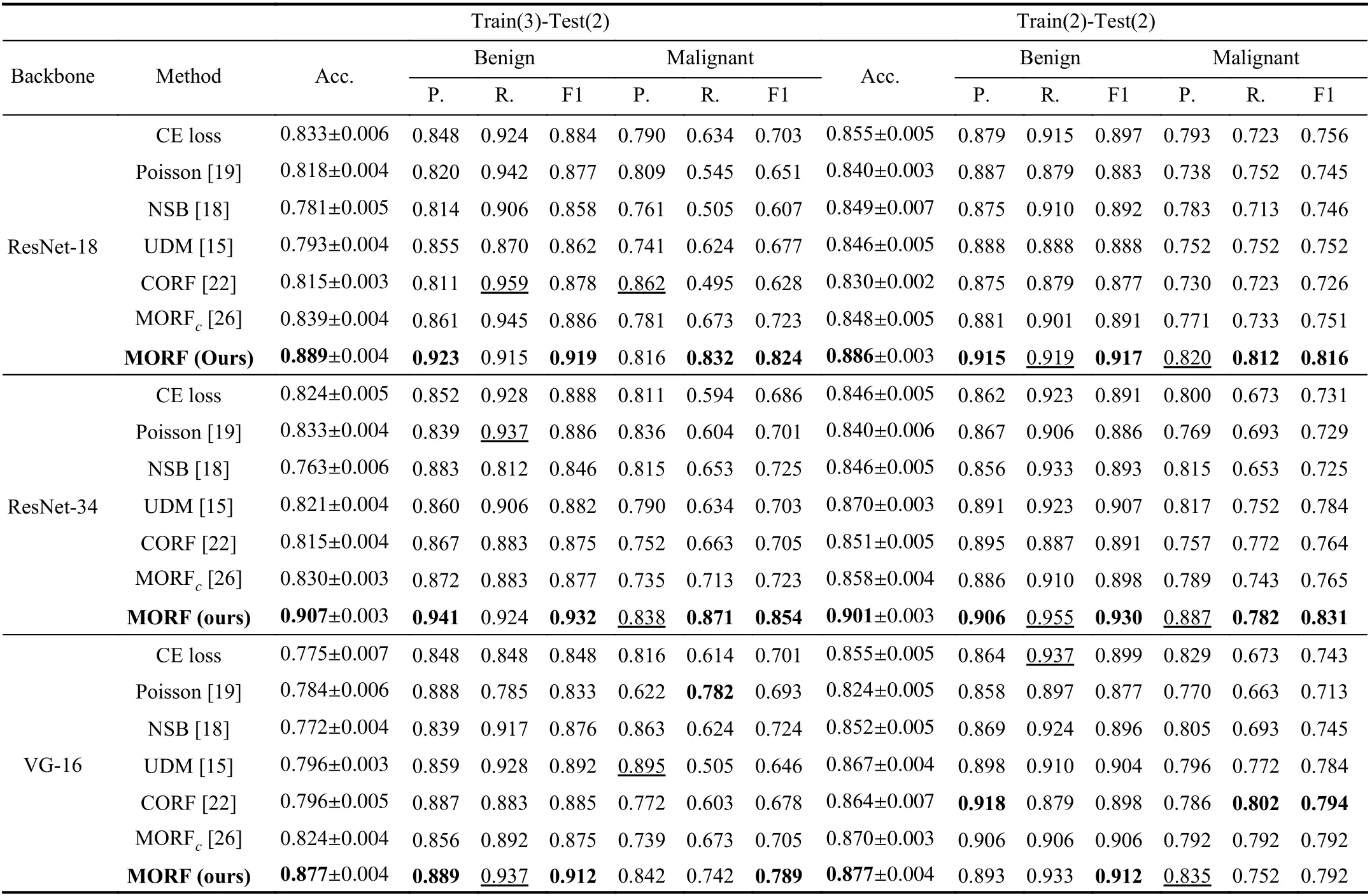
TABLE II CLASSIFICATION RESULTS ON TEST SETS OF TRAIN(3)-TEST(2) AND TRAIN(2)-TEST(2) ON LIDC-IDRI DATASET. THE VALUES WITH UNDERLINES INDICATE THE BEST RESULTS WHILE LESS IMPORTANT IN THE CLINICAL DIAGNOSIS [15]. IN THIS TABLE, P., R., AND F1 ARE ABBREVIATIONS OF PRECISION, RECALL, AND F1 SCORE, RESPECTIVELY. B. IS SHORT FOR BACKBONE. MORFC IS THE CONFERENCE VERSION OF THE PROPOSED MORF [26]
D. Training Without Unsure Data for Lung Nodule Classification
To verify the effectiveness of MORF on binary classification, we compare the results of all methods training without unsure data. The CE loss under Train(2)-Test(2) in Table II(right) is the conventional binary classifier whose output dimension is 2, and this is different from that of Train(3)-Test(2) whose output dimension is 3. It is clear that the MORF also achieves the best overall accuracy, precision of benign,and recall of malignant using different backbones.
Through the comparison in Table II, we can see that the unsure data largely affect the generalizability of the compared methods. There are no severe fluctuations in the performance of MORF under the two settings, indicating that MORF is able to distinguish the samples with ordinal labels regardless of whether the ordinal margin is large (without unsure) or small (with unsure).
Here, we would like to clarify why the performance in Table I is much lower than that seen in Table II. This is due to the imperfect performance of recognizing the unsure samples,so that it becomes unavoidable to encounter the classification errors of all classes.
E. Classification Results on BUSI Dataset
In Table III, we illustrate the results of all the methods on the BUSI dataset. For the benign and malignant classes, we also focused more on the precision of benign and recall of malignant. Differently from the LIDC-IDRI dataset, we can see from Fig. 4 that the first order in the BUSI dataset is the normal class, which does not contain nodules. Therefore, the benign class occupies different positions in the orders of the two datasets. Interestingly, our MORF also retains the best precisions of benign and malignant recalls as shown in Table III.This demonstrates the discriminative ability of MORF in recognizing nodules of different orders without the influence of the normal class that does not include nodules.
Clinically, false positives of the normal class indicate that benign or malignant nodules are falsely classified as normal,which will result in an increase of missing diagnosis; in contrast, false negatives of the normal class will cause an increase in misdiagnosis. Since the precision and recall correlate with false positives and the false negative, here we suggest that the precision and recall of the normal class have equal importance weights. The results of compared methodsin Table III show that they are prone to preferring precision or recall of the normal class. For example, the UDM obtains a precision of 1.000 when using ResNet-18 while the corresponding recall is 0.259; the NSB achieves similar results with a large margin between precision and recall. However, the MORF has relatively balanced precisions and recalls, and it also maintains the best F1 scores when applying all of the backbones.
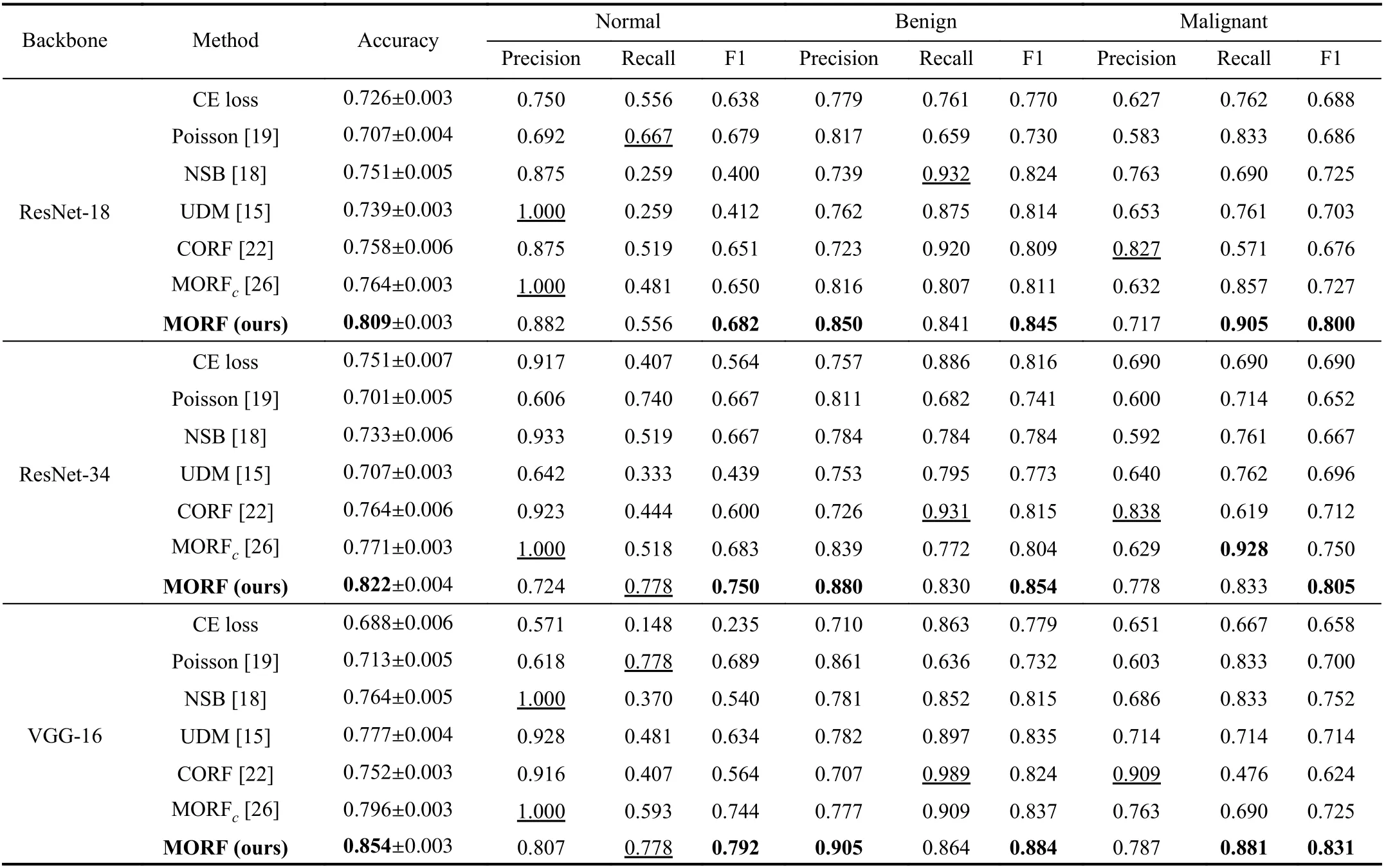
TABLE III CLASSIFICATION RESULTS ON TEST SET OF BUSI DATASET. THE VALUES WITH UNDERLINES INDICATE THE BEST RESULTS WHILE LESS IMPORTANT IN THE CLINICAL DIAGNOSIS [15]. MORFC IS THE CONFERENCE VERSION OF THE PROPOSED MORF [26]
F. Comparisons Between MORF and MORFc
From Tables I−III , we can see that MORF consistently outperforms MORFcin terms of overall accuracy, which is benefited from the improved GFS using random selection without replacement. For both of the two datasets, MORF is better at identifying benign and malignant classes compared with MORFc, and this guarantees the improvements of overall performance. Recalling the essential difference between MORF and MORFcthat GFS in MORF uses random selection without replacement, as a result, MORF makes more efficient use of FC output vector while MORFccould be affected by selection of unused elements in FC output vector. Therefore,the results suggest that GFS without replacement will be more conducive to distinctive feature learning that identifies benign and malignant.
G. Tree-Wise Variance Reduction
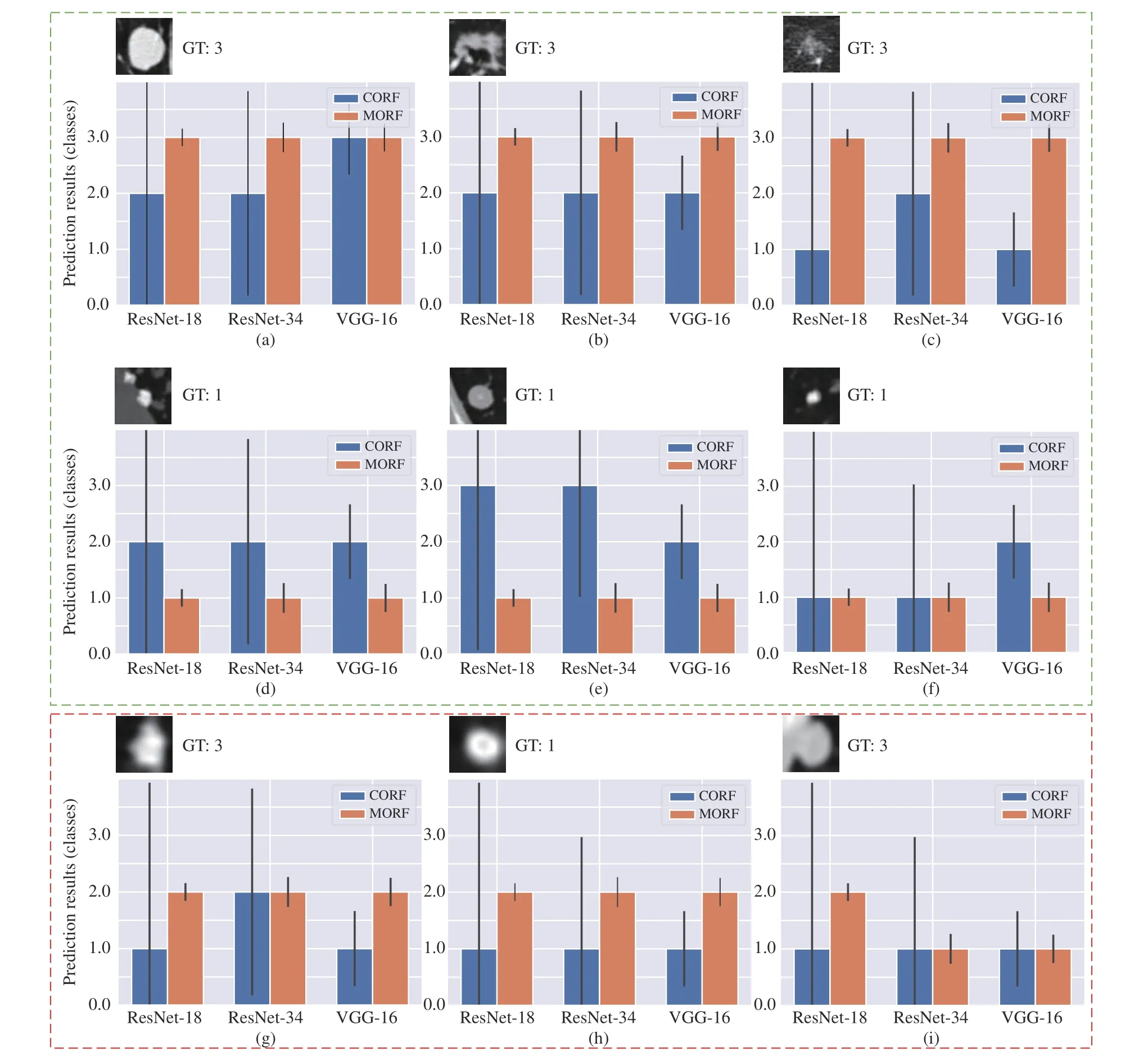
Fig. 5. Some prediction results of MORF and CORF under Train(3)-Test(2) setting. The y axis represents the prediction results: 1, 2 and 3 represent benign,unsure and malignant. The GT denotes ground truth. The black vertical line on each bar represents the variance over the predictions of all trees. Green box contains some representative nodules, and red box include some failure cases. The subfigures represent different classes of nodules: (a), (b), (c), (d), (g); and (i)are malignant; (d), (e), (f), and (h) are benign.
In Fig. 5, we also provide some failure cases obtained by MORF and CORF, i.e., Figs. 5(g)−5(i). Fig. 5(g) is malignant and its real malignant score is 3.75 which is referred to Fig. 1.However, both MORF and CORF make incorrect predictions,and this is due to blur edges or shapes of the nodule. Fig. 5(h)is a benign nodule in our study with malignant score 2.5 which is an upper bound of score range of benign class. We can see that MORF is prone to classifying it as unsure, while CORF obtains predictions of benign. Fig. 5(i) is a malignant nodule with malignant score 3.5, i.e., the lower bound of malignant, and the predictions are incorrect obtained by the two methods. We conclude that MORF and CORF can be confused by the malignant or benign nodules whose malignant scores are close to unsure class, and MORF prefers predictions of unsure for them. This phenomenon also reflects that MORF is more suitable for real clinical circumstance that requires more nodules surrounding the unsure class for further diagnosis.
H. Ablation Study
Here, we evaluated the effectiveness of the GFS module and TWW-Net based on CORF. The experiments were conducted on the LIDC-IDRI dataset under the Train(2)-Test(2) setting using the ResNet-18 backbone. Then, we evaluated the effects of the number and depth of trees in MORF. Finally, we conducted a significance analysis between MORF and other methods through predictions on the LIDC-IDRI testing set(Train(3)-Test(3)).
1)GFS Module:To verify the random feature perturbation enforced by the GFS, we added the GFS to CORF termed CORF+GFS. The forest of the CORF is fixed during training and inference. In contrast, the CORF+GFS enables the forest structure to be dynamic during training only, and the training process does not include the meta train stage. That is to say,
the CORF is equipped with random feature perturbations.From Table IV we can see that the CORF+GFS achieves better performances than the vanilla CORF. This indicates that the training of the CORF benefits from the GFS in that the GFS generated forest endows the target model (θ) with the generalizability increased by the random feature perturbation.However, the drawback of all trees sharing the same weights is not yet resolved. In addition, we observe that the precision of benign and the recall of malignant of CORF+GFS are worse than those of CORF, which can be explained as follows: GFS is specially designed to improve the metatraining of the proposed MORF while CORF does not have meta training, as a result, the GFS shall compromise the performance of CORF as expected.
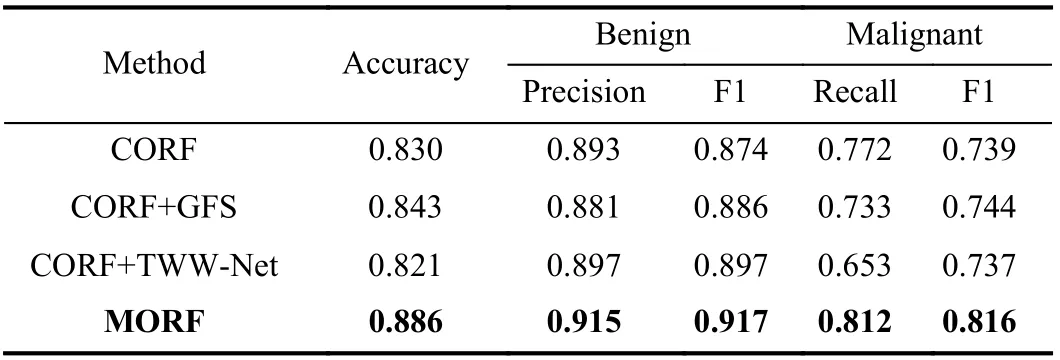
TABLE IV EFFECTIVENESS EVALUATION OF GFS AND TWW-NET ON THE LIDC-IDRI DATASET, UNDER THE TRAIN(2)-TEST(2) SETTING USING RESNET-18
2)TWW-Net:The CORF+TWW-Net in Table IV is tailored for evaluating the TWW-Net without the GFS, i.e., the structure of the forest is also fixed, and the training process includes the meta train stage. Table IV shows that CORF+TWW-Net performs worse than the CORF. This is due to that the training data and the meta data are the same and consequently, the two terms of the multiplication inGi jas shown in (10) are the same. Therefore, theGi jis almost at the orientation of the largest gradient, and this phenomenon happens equally to all training samples. So we argue that in(10), CORF+TWW-Net could accelerate the update ofϕ, and hence, may trigger the overfitting of TWW-Net. In other words, the update ofθis not guided by the meta data.Consequently, the meta weighting scheme of TWW-Net should be driven by the model generalizability gain from GFS.For MORF (i.e., CORF + GFS + TWW-Net), the update of parametersθcan be guided by GFS generated features,therefore,Gi jinvolves gradients of GFS features, thenGijwill slow down the update ofϕaccording to (10). Hence, the combination of GFS and meta training with TWW-Net achieves trade-off between updating the parametersθandϕ.
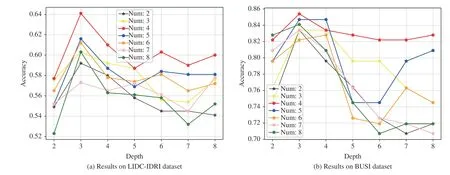
Fig. 6. Classification accuracies with varying values of the depth of trees and number of trees on (a) LIDC-IDRI and (b) BUSI datasets.
3)Number and Depth of Trees:Here, we further discuss the effects of the number and depth of trees. We fix one of them and evaluate the settings with various values of the other. The backbone network is VGG-16. Fig. 6 shows the performances influenced by these two factors on the LIDC-IDRI under the setting of Train(3)-Test(3) and BUSI datasets.
In Fig. 6, we can see that the setting with the number of trees being 4 and the depth of trees being 3 achieves the best performances for both of the datasets. Lower or higher values of number and depth will decrease the performances. If the number of trees is fixed, there will be more nodes in a forest which requires FC output vector to have higher dimension,i.e., more elements. Then the parameters of the framework begin to increase, and this will affect the performance. If the depth of trees is fixed, we observe that when the number is small, i.e., 2 or 3, MORF achieves lower performances on two datasets. This indicates that fewer ensembled trees can affect the capability of the MORF, then hinder the performance improvement. In contrast, too many trees ( >4) also results in a decrease of performance which is attributed to more MLPs for weights learning, i.e., there are more parameters to learn.
I. Significance Analysis
In order to show the significant differences between MORF and compared methods, we compare MORF and other methods through conducting the Wilcoxon signed-rank test[58] with respect to predicted probabilities on test set. In Table V, we can see that all thep-values obtained by MORF and baseline methods are less than the significance level 0.05.So we reject the null hypothesis that MORF possesses the same prediction distribution as baseline methods. Finally, we conclude that MORF is significantly better than the baseline methods.
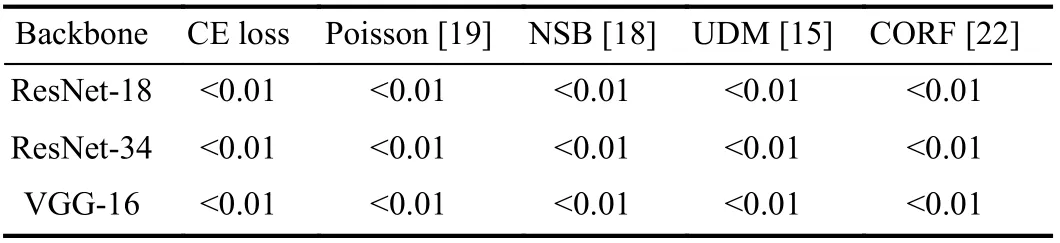
TABLE V P-VALUES BETWEEN MORF AND OTHER METHODS USING DIFFERENT BACKBONES
V. CONCLUSIONS
In this paper, we propose a meta ordinal regression forest,termed MORF, for improving the performances of the ordinal regression in medical imaging, such as lung nodule classification and breast cancer classification. The MORF contains a grouped feature selection module that is used to generate a dynamic forest with feature random perturbation.Another critical component of the MORF is the TWW-Net which assigns each tree with a learned weight, and this enforces the predictions of different trees to have smaller variance while maintaining stable performances. The parameters of the model are learned through the meta-learning scheme which can solve the problem of integrating two parts of parameters into one training loop, and it brings the gradients of target data and meta data to be closer. Through the experiments, we have verified that the MORF can help reduce the false positives and the false negatives of the relevant classes, which is significant to the clinical diagnosis.Moreover, we have also verified that the accurate recognition of the intermediate order can improve the classification of the other classes on both sides.
In the future, we will consider to explore attention mechanism for achieving better generalizability of deep random forest such as in [59]. Also, we will simplify the MORF framework such as using the design of light weight network or efficient loss functions [60], [61].
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- An Overview and Experimental Study of Learning-Based Optimization Algorithms for the Vehicle Routing Problem
- Towards Long Lifetime Battery: AI-Based Manufacturing and Management
- Disagreement and Antagonism in Signed Networks: A Survey
- Finite-Time Distributed Identification for Nonlinear Interconnected Systems
- SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer
- Real-Time Iterative Compensation Framework for Precision Mechatronic Motion Control Systems