SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer
2022-07-18JiayiMaLinfengTangFanFanJunHuangXiaoguangMeiandYongMa
Jiayi Ma,,, Linfeng Tang, Fan Fan, Jun Huang, Xiaoguang Mei, and Yong Ma
Abstract—This study proposes a novel general image fusion framework based on cross-domain long-range learning and Swin Transformer, termed as SwinFusion. On the one hand,an attention-guided cross-domain module is devised to achieve sufficient integration of complementary information and global interaction. More specifically, the proposed method involves an intra-domain fusion unit based on self-attention and an interdomain fusion unit based on cross-attention, which mine and integrate long dependencies within the same domain and across domains.Through long-range dependency modeling,the network is able to fully implement domain-specific information extraction and cross-domain complementary information integration as well as maintaining the appropriate apparent intensity from a global perspective. In particular, we introduce the shifted windows mechanism into the self-attention and cross-attention,which allows our model to receive images with arbitrary sizes.On the other hand, the multi-scene image fusion problems are generalized to a unified framework with structure maintenance,detail preservation, and proper intensity control. Moreover, an elaborate loss function, consisting of SSIM loss, texture loss, and intensity loss, drives the network to preserve abundant texture details and structural information, as well as presenting optimal apparent intensity. Extensive experiments on both multi-modal image fusion and digital photography image fusion demonstrate the superiority of our SwinFusion compared to the state-of-theart unified image fusion algorithms and task-specific alternatives.Implementation code and pre-trained weights can be accessed at https://github.com/Linfeng-Tang/SwinFusion.
I. INTRODUCTION
OWING to the limitations of hardware devices,information captured by a single-type sensor or with a single shooting setting cannot comprehensively characterize the imaging scenario [1]. On the one hand, different types of sensors usually capture specific information from multiple perspectives.For instance, the infrared sensor gathers thermal radiation information, which emphasizes prominent targets. The visible sensor generates digital images with abundant texture details by catching the reflected light information [2]. The near-infrared sensor could capture the complementary details that may be lost in the visible images [3]. Moreover, in the field of medical imaging, structural systems (e.g., magnetic resonance imaging (MRI) and computed tomography (CT)) generally offer structural and anatomical information [4]. By contrast,functional systems such as positron emission tomography(PET) could provide functional information on blood flow and metabolic changes [5]. On the other hand, the sensors with different shooting settings usually acquire limited information from the imaging scenario. More specifically, cameras with varied ISO and exposure times only capture information within the dynamic range and inevitably miss information outside the dynamic range. Similarly, the cameras with specific focal lengths only capture the objects within the depth-of-field(DOF) [6]. It is worth mentioning that images captured by different sensors or under multiple shooting settings generally contain complementary information, which encourages us to incorporate these complementary characteristics into a single image. Therefore, the image fusion technique was born. In terms of the difference in imaging devices, image fusion could be divided into multi-modal image fusion and digital photographic image fusion. A schematic illustration of these two types of image fusion scenarios is exhibited in Fig. 1. A single fused image with better scene representation and visual perception facilitates subsequent practical visual applications,such as object detection,tracking,semantic segmentation,scene understanding,etc. [7]–[9].
In the past decades, numerous image fusion techniques have been proposed, which can be broadly divided into two categories,i.e., task-specific image fusion schemes [11]–[14]and general image fusion algorithms[10],[15],[16].Both taskspecific image fusion and general image fusion can be further specified into four classes,including traditional framework[17]–[19],convolution neural network(CNN)-based framework[20],[21], auto-encoder (AE)-based framework [22], [23], and generative adversarial network (GAN)-based framework [24]–[26]. Although the frameworks mentioned above can generate considerable fused results, none of them can sufficiently mine and integrate global context both within and across domains.In particular, we assume that images shot by different sensors or under multiple optical settings belong to different domains in this paper. On the one hand, the traditional frameworks usually implement complementary information aggregation in the spatial domain [17] or transform domain [19], [27],but neither of them can exchange information between nonadjacent pixels. Therefore, the traditional framework fails to perceive the global environment. On the other hand, the basic components of CNN-, AE-, and GAN-based frameworks are convolutional layers that can only mine interactions within the receptive field. However, while exploiting local information for image fusion, these frameworks cannot leverage intra- or inter-domain long-range dependencies to further improve the fused results.
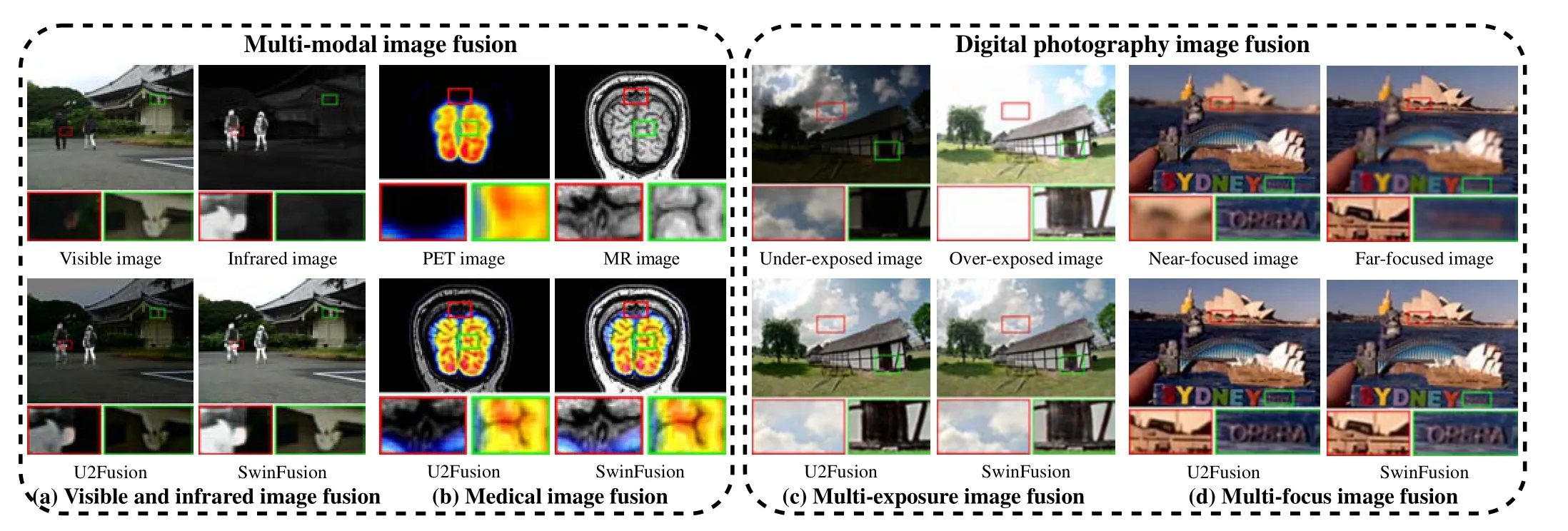
Fig. 1. Schematic illustration of multi-modal image fusion and digital photography image fusion. First row: source image pairs, second row: fused results of state-of-the-art general fusion algorithm, i.e., U2Fusion [10] and our SwinFusion.
As an alternative to CNN, Transformer [28] devises a selfattention mechanism to capture global interactions between contexts and shows promising performance in several vision problems [29]–[33]. In particular, the image fusion community also introduces Transformer to model the inter-domain longrange dependence and provides competitive fused results [34]–[37]. Nevertheless, there are still some drawbacks that need to be addressed. First, the existing Transformer-based methods merely explore intra-domain interactions, but fail to integrate cross-domain contexts,which is essential for image fusion tasks.Second, vision Transformers for image fusion usually request the input image that can be reshaped to a fixed size (e.g., 256× 256), which leads to distorted scenarios in the fused images.Third, the existing fusion Transformers are devised for specific fusion scenarios without considering the intrinsic connection between different fusion tasks.
To address the challenges mentioned above, we devise a general image fusion framework based on cross-domain long-range learning and Swin Transformer for multi-modal image fusion and digital photography image fusion. Our design is primarily developed from the following aspects.On the one hand, we model all image fusion scenarios as structure maintenance, texture preservation, and appropriate intensity control. In particular, we unify the form of loss function that consists of SSIM loss, texture loss, and intensity loss, for all fusion problems. All sub-loss terms follow the same modeling manners of different fusion tasks except for intensity loss, which is tailored to the specific fusion mission for more appropriate intensity perceptions. On the other hand, we design a joint CNN-Transformer image fusion framework to mine the local and global dependencies in source images adequately. The CNN-based shallow feature extraction unit mines the local information in source images.The Transformer-based deep feature extraction unit explores the global interactions among shallow features and generates deep features containing high-level semantic information.Then,the elaborate attention-guided cross-domain fusion module effectively integrates intra- and inter-domain interactions in the deep features. Specifically, the intra-domain fusion unit aggregates the global context in the same domain via the selfattention mechanism. The inter-domain fusion unit models the long-range dependencies between multiple source images and achieves global feature fusion via exchanging the query, key,and value from different domains. Finally, the Transformerbased deep feature reconstruction unit and the CNN-based fused image reconstruction unit leverage global and local information to reconstruct the fused image with superior visual perceptions.It is worth remarking that both self-attention and cross-attention are implemented by the shifted window mechanism (i.e., Swin Transformer[38]),which allows our framework to handle input images with arbitrary size. To sum up, the major contributions of this work can be summarized as follows:
• We propose a joint CNN-Transformer fusion framework for multi-modal image fusion and digital photography image fusion. The proposed framework can sufficiently exploit both local and global information to achieve better complementary characteristics integration.
• A self-attention-based intra-domain fusion unit and a crossattention-based inter-domain fusion unit are devised to model and integrate the long-range dependencies within the same domain and across domains, respectively.
• Both multi-modal image fusion and digital photography image fusion are generalized to structure maintenance,texture preservation, and appropriate intensity control.Especially, a unified loss function form is defined to constrain all image fusion problems.
• Extensive experiments demonstrate the superiority of our framework compared to state-of-the-art task-specific and general fusion algorithms on both multi-modal image fusion and digital photography image fusion.
The organizational structure of this paper is as follows.Section II summarizes some relevant research to the proposed framework,including task-specific image fusion,general image fusion, and vision Transformer. Section III provides a detailed discussion of our SwinFusion. In Section IV, we present some qualitative and quantitative results on multi-modal image fusion and digital photography image fusion, as well as performing the ablation study to verify the effectiveness of specific designs.Some concluding remarks are given in Section V.
II. RELATED WORK
The image fusion and vision Transformer are two of the most relevant techniques to our method, here we review some representative research to introduce their developments.
A. Task-specific Image Fusion Methods
As an essential image enhancement technique, image fusion has continued to attract increasing attention in recent years.The mainstream image fusion schemes, especially for task-specific image fusion, can be classified into the following four types of frameworks.
Traditional Image Fusion Framework:Traditional fusion frameworks usually realize image fusion in the spatial domain and transform domain. On the one hand, integrating pixel-level information in the spatial domain is one of the major genres of traditional image fusion. GTF [17] defines infrared and visible image fusion as overall intensity maintenance and texture structure preservation in the spatial domain, and yields the fused image by optimizing the objective function. Awadet al.developed an adaptive near-infrared and visible fusion scheme in the spatial domain for visible image detail enhancement [3].Moreover, Liuet al. designed a convolutional sparsity model based on morphological component analysis (CS-MCA) to achieve medical image fusion at the pixel level [39]. They also introduced the local feature descriptor (i.e., Dense SIFT)into the multi-focus image fusion task to perform activity level measurement and match the misregistered pixels between different source images [40]. On the other hand, researchers have also tried to map source images to the transform domain with relevant mathematical transformation and manually design fusion rules in the transform domain to achieve image fusion.Maet al. employed a structural path decomposition technique to transform source images into three conceptually independent components,i.e., signal strength, signal structure, and mean intensity [41]. Then, the multi-exposure image fusion is implemented by merging these three components separately.Furthermore, Liet al. proposed a transform domain-based multi-focus image fusion algorithm by combining the sparse feature matrix decomposition and morphological filtering technique [42].
CNN-based Image Fusion Framework:In recent years,convolution neural network (CNN) has gradually become the primary workhorse for image fusion, and has exhibited significant advantages. One form of CNN participating in image fusion employs the pre-trained networks to realize activity level measurement and generate a weight map for hand-crafted features [5], [43]. But the whole fusion process is still based on the traditional fusion framework, such as the Laplace pyramid [5] and guided filtering [43]. Another type of CNN-based image fusion framework is utilizing CNN to learn a direct mapping between source images and fused images(or focus map) in an end-to-end manner [2], [44]. Various researches integrated task-specific prior information into the CNN-based framework to design loss functions and network structures.Specifically,Maet al.proposed anα-matte boundary defocus model to precisely simulate the defocus spread effect and generate realistic data for the training of the multi-focus image fusion network [45]. In order to tackle the difficulty of the blur level estimation around the focused/defocused boundary, Liet al. introduced the deep regression pair learning to directly convert the whole image into the binary mask without any patch operation[46].Zhaoet al.presented a depthdistilled multi-focus image fusion method by taking depth cues into consideration [47]. They also focused on diversity of features to improve fusion performance [48], [49]. In addition,Hanet al. devised a deep perceptual enhancement network for multi-exposure image fusion, which contains two separate modules for gathering content details and correcting color distortion, respectively [50]. For visible and infrared image fusion, Longet al. designed an aggregated residual dense network that combines the structural advantages of ResNet and DenseNet on the basis of CNN [51]. Moreover, SeAFusion [7]incorporates semantic constraints into the modeling of image fusion for the first time and proposes a gradient residual dense block to boost the description ability for fine-grained details.
AE-based Image Fusion Framework:Contemporaneously,researchers have also explored the auto-encoder-based image fusion framework. Specifically, an auto-encoder pre-trained on large-scale datasets is employed as the feature extractor and image reconstructor, and then a specialized fusion strategy is designed for deep features to implement image fusion.DeepFuse [13] is the pioneer of such fusion frameworks.Afterwards, Liet al. introduced the dense connection [22] and nest connection [52], [53] to reinforce the feature extraction capability of the encoder. Moreover, Jianet al. injected the attention mechanism into the AE-based fusion framework to reinforce the salient features extracted by the encoder [54].In order to extract features with greater interpretability, Xuet al. tailored the disentanglement representation to the AEbased fusion framework [11]. Nevertheless, all aforementioned methods adopt hand-crafted fusion strategies,e.g., elementwise addition [13], element-wise weight summation [22],and element-wise maximum [20], to merge deep features,which obstruct the fusion models from achieving their optimal performance. For this purpose, Xuet al. devised a learnable fusion rule based on pixel-wise classification saliency and interpretable importance evaluation [23].
GAN-based Image Fusion Framework:Generative adversarial network (GAN) can effectively model data distributions even without supervised information, which coincides with the image fusion tasks. Maet al. instructively defined the image fusion problem as a game between the generator and discriminator. Then, they applied GAN to a range of fusion tasks, such as infrared and visible image fusion [55], multiexposure image fusion [25], multi-focus image fusion [56],and pan-sharpening [57]. However, a single discriminator fails to take into account the data distributions of multiple domains. Hence, Xuet al. proposed the dual-discriminator conditional generative adversarial network (DDcGAN), which leverages two discriminators to constrain the distribution of fused results. Subsequently, Hunget al. devised a multigenerator multi-discriminator conditional generative adversarial network (MGMDcGAN) for medical image fusion [26]. Moreover,Liet al.injected the multi-scale attention mechanism into the GAN-based fusion framework to encourage the generator and discriminator to pay more attention to the meaningful regions [58], [59].
B. General Image Fusion Methods
Task-specific fusion algorithms are able to exploit relevant priors to improve fusion performance, whereas they ignore the intrinsic associations between different image fusion tasks.Thus, a growing number of researchers are dedicated to developing the unified image fusion framework. MST-SR is the first general image fusion framework that implements complementary information aggregation by combining multiscale transform (MST) and sparse representation (SR) techniques [15]. Subsequently, Zhanget al. [20] designed the first convolution neural network for general image fusion with reference to DeepFuse [13]. In addition, PMGI [16] regards different image fusion problems as proportional maintenance of gradient and intensity,as well as designing a unified form of loss functions. On the basis of PMGI, Zhanget al. proposed a squeeze-and-decomposition network and an adaptive decision block to further improve the fusion performance[60].Moreover,Zhaoet al. developed a general framework for multi-realm image fusion via learning domain-specific and domain-general feature representations [61]. In particular, considering that different fusion scenarios can promote one another, Xuet al. developed a unified unsupervised image fusion model for multi-fusion tasks by combining the learnable information measurement and elastic weight consolidation [10], [62].
It is worth emphasizing that neither task-specific nor general fusion approaches can fully exploit the long-range interactions of images. In other words, these algorithms only merge complementary information from a local perspective but cannot implement global information aggregation.
C. Vision Transformer
Recently, the natural language processing model,i.e., Transformer [28] has received a lot of attention in the computer vision community. There are many Transformer-based models that have achieved impressive performance in various vision tasks, such as visual recognition [29], [63], [64], object detection [30], [65], [66], tracking [67]–[69], segmentation[31], [70], and image restoration [32], [33], [71]. Due to its powerful long-range modeling capability, Transformer has also been introduced to image fusion[34],[35],[37],[72].Building on the CNN-based fusion framework, VSet al. designed a multi-scale fusion strategy based on Spatio-Transformer (i.e.,IFT), which attends to both local and global contexts [35].In addition, on the basis of the AE-based fusion framework,Fuet al.replaced the CNN architecture with the Patch Pyramid Transformer to extract non-local information from the entire image [37]. However, the auto-encoder only consisting of Transformer fails to effectively extract local information. For this purpose, Zhaoet al. proposed a sequential DenseNet and dual-transformer architecture, termed DNDT, to extract local and global information, in which dual-transformer reinforces the global information in features before the fusion layer [72].In addition, Quet al. developed TransMEF [34], which injects parallel Transformer and CNN architecture into the AE-based fusion framework and leverages self-supervised multi-task learning to implement multi-exposure image fusion. Subsequently, Liet al. proposed a convolution-guided transformer framework for visible and infrared image fusion (i.e., CGTF),aiming to combine the local feature of CNN and the longrange dependency features of Transformer to generate more satisfactory fused results [73]. Furthermore, Raoet al. also introduced Transformer into the GAN-based fusion framework to achieve visible and infrared image fusion [36].
However, the above fusion Transformers merely mine longrange dependencies (or global interactions) from the same domain. In fact, the cross-domain long-range dependencies are more relevant to the image fusion problem. Besides, most of these Transformer-based fusion algorithms, such as IFT [35],DNDT [72], TransMEF [34], and CGTF [73], can only handle input images with fixed size(e.g.,256×256).Moreover,the existing vision Transformers for image fusion only solve specific image fusion problems, but fail to address both multi-modal image fusion and digital photography image fusion scenarios in a unified fusion framework.Thereby,we sufficiently explore the commonalities between different image fusion scenarios. Then,the multi-modal image fusion and digital photography image fusion are modeled uniformly as structure maintenance, texture preservation, and appropriate intensity control. Furthermore,an attention-guided cross-domain fusion module is designed to effectively mine and integrate the intra- and inter-domain global interaction in the fusion process.
III. METHODOLOGY
In this section,the multi-modal image fusion and digital photography image fusion are generalized to structure information maintenance, texture detail preservation, and suitable intensity control. We firstly provide the overall framework. Next, the design of the unified loss function is presented.
A. Overall Framework
LetI1∈RH×W×CinandI2∈RH×W×Cinrepresent two aligned source images from different domains, andIf ∈RH×W×Coutis the fused image with complete scene representation.H,W, andCinare the height, width and channel number of input images.Coutis the channel number of the fused images. The proposed SwinFusion aims to generate the fused imageIfvia merging local and global complementary information in the source imagesI1,I2.As illustrated in Fig.2,SwinFusion can be divided into three parts: feature extraction,attention-guided cross-domain fusion, and reconstruction.
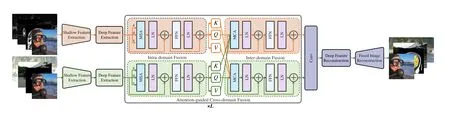
Fig. 2. The framework of the proposed SwinFusion for multi-modal image fusion and digital photography image fusion.
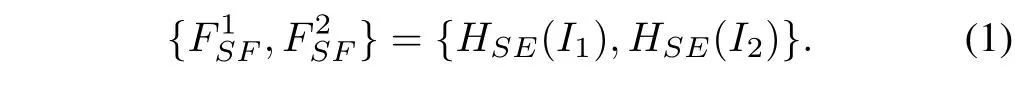
Feature Extraction:At the beginning, we extract the shallow featuresandby the multiple convolutional layersHSE(·) from the source imagesI1andI2, which can be expressed as:The convolutional layers are good at early visual processing,resulting in more stable optimization and better results [74]. It also offers a simple yet effective way to extract local semantic information and map this information into the high dimensional feature space. The shallow feature extraction module consists of two convolutional layers with the Leaky Relu activation function, whose kernel size is 3×3, and stride is 1.
After that, we extract deep featuresandfromandas:
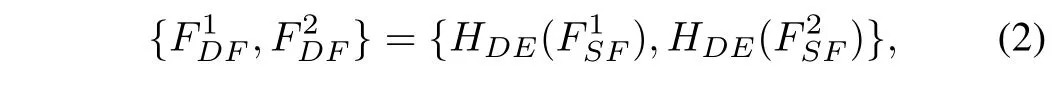
whereHDE(·) is the deep feature extraction unit that containsNSwin Transformer layers. The core architecture of the Swin Transformer layer is consistent with the inter-domain fusion unit, which is described in detail below. In this work,Nis set to 4.
Attention-guided Cross-domain Fusion:After extracting deep features with sufficient global semantic information, we design an attention-guided cross-domain fusion module (ACFM) to further mine as well as aggregate intra-and inter-domain global context.
First of all, we devise a self-attention-based intra-domain fusion unit to effectively integrate the global interactions in the same domain. Shifted window mechanism-based attention is the fundamental component in designing our intra-domain fusion unit. Given featuresFwith the size ofH×W×C,shi fted window mechanism first reshapes the input to×M2×Cfeatures via partitioning the input into non-overlappingM×Mlocal windows, whereis the total number of windows. Next, it performs standard self-attention separately for each window. For a local window featureX ∈RM2×C,three learnable weight matrices WQ ∈RC×C, WK ∈RC×C,and WV ∈RC×Cthat are shared across different windows are employed to project it into the query Q, key K and value V by:
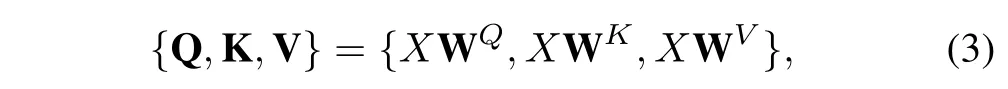
Then,the attention function basically computes the dot-product of the query with all keys, which is then normalized with the softmax operator to yield attention scores. The attention mechanism is defined as:
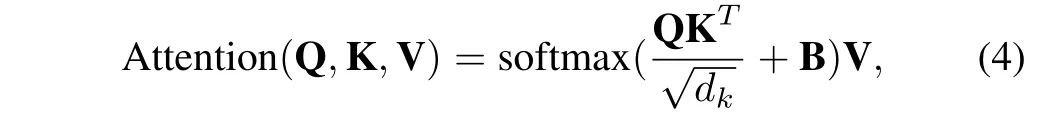
wheredkis the dimension of keys and B is the learnable relative positional encoding.Referring to the literature[28],we extend the self-attention into multi-head self-attention (MSA)to enable the attention mechanism to consider various attention distributions and make the model capture information from different perspectives. In practice, we perform the attention function forhtimes in parallel and concatenate the results for multi-head self-attention, in whichhis set as 6 in our work. Next, a feed forward network (FFN) that consists of two multi-layer perceptron (MLP) layers with GELU activation layer is deployed to refine the feature tokens yielded by MSA.The layer normalization (LN) is always performed after both MSA and FFN, and the residual connection is applied to both modules. Thus, the full process of intra-domain fusion unit for a local window featureXis formulated as:
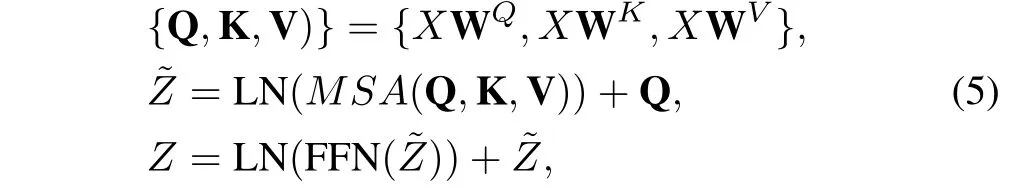
whereZis the output of the intra-domain fusion unit withXas the input. The feed forward network (FFN) is as follows:
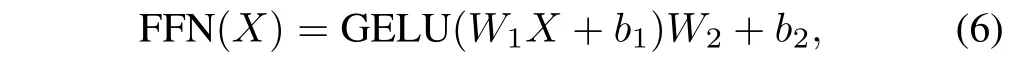
where GELU is the gaussian error linear unit. In particular, the Swin Transformer Layer follows the same processing procedure as the intra-domain fusion unit. We also present the framework of two successive Swin Transformer Layers in Fig. 3 to clearly illustrate their processing procedure.It is worth noting that there are no connections across local windows if the partition is fixed for different layers. Thus, following the literature [33], [38],we alternately utilize regular and shifted window partitioning to enable cross-window connections, where shifted window partitioning means shifting the feature by (⎿」,⎿」) pixels before partitioning. Fig. 4 shows an example of the shifted window mechanism for computing attention in the Swin Transformer Layer and intra-domain fusion unit.As can be seen,in layerl, a regular window partitioning scheme is employed,and the attention is computed within each window. In the next layer (i.e., layerl+ 1), the window partitioning is shifted,which results in new windows. Thus, the attention computation
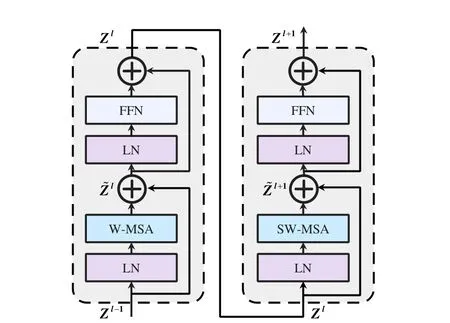
Fig. 3. Two successive Swin Transformer Layers. W-MSA and SW-MSA are multi-head self-attention modules with regular and shifted windowing configurations, respectively.
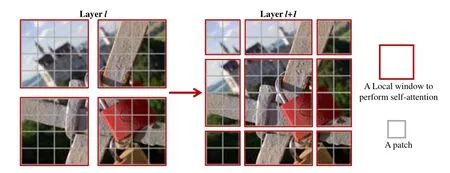
Fig. 4. An illustration of the shifted window mechanism for computing attention in the Swin Transformer Layer, intra-domain fusion unit, and interdomain fusion unit.
in the new windows crosses the boundaries of the windows in layerl, providing connections among them.
Following the intra-domain fusion unit, we also design a cross-attention-based inter-domain fusion unit to further integrate the global interactions between different domains.Both the intra-domain fusion unit and inter-domain fusion unit follow a similar baseline. The principal difference is that the inter-domain fusion unit employs multi-head crossattention (MCA) instead of MSA to implement global context exchange across domains. Therefore, given two local windows featuresX1andX2from different domains, the whole process of the inter-domain fusion unit is defined as:
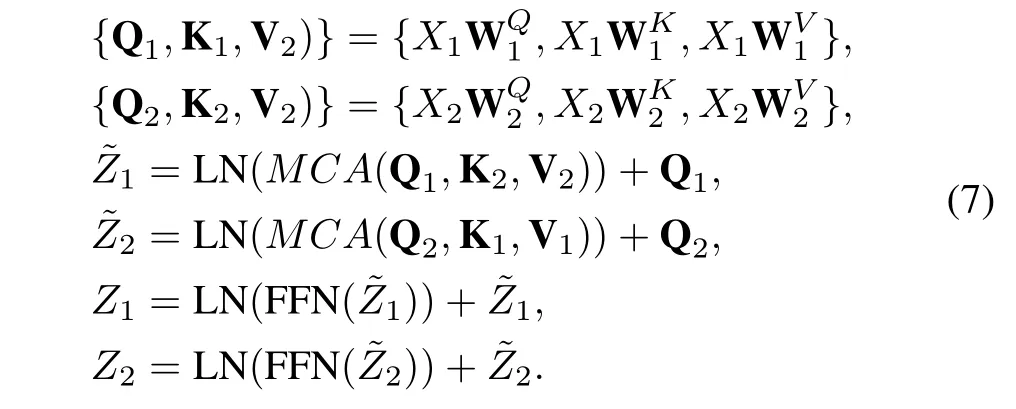
As presented in Eq. (7), for Q1from domain 1, it incorporates cross-domain information by performing attention weighting with K2and V2from domain 2, while preserving information in domain 1 through the residual connection and vice versa.Our model deploysLattention-guided cross-domain fusion modules, consisting of cascaded intra-domain fusion unit and inter-domain fusion unit, to alternately integrate the global inter-domain and cross-domain interactions. In order to balance computational efficiency and fusion performance, we setLto 2.
Following the attention-guided cross-domain fusion module,a convolutional layer with spatially invariant filters is deployed to aggregate local information in different domains and enhance the translational equivariance of our SwinFusion, which can be formulated as:
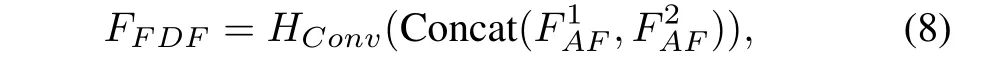
whereandrepresent the output features aggregated by ACFM withandas inputs,respectively.HConv(·)denotes the convolutional layer with spatially invariant filters and Concat(·)refers to concatenation in the channel dimension.FF DFindicates the fused deep features, which is the input of the feature reconstruction module.
Reconstruction:After fully merging complementary information in different domains, we devise the Transformer-based deep feature reconstruction unit and CNN-based image reconstruction unit to map the fused deep features back to the image space. First of all, the deep feature reconstruction unitHDR(·),containingPSwin Transformer layers, is deployed to refine the fused deep features and restore fused shallow features from a global perspective. This process can be expressed as:
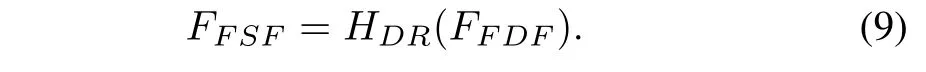
In order to fully exploit the global context in deep features to recover the fused shallow features,Pis set to 4. Then, the CNN-based image reconstruction unitHIR(·) is deployed to reduce the number of channels and generate the fused imageIf, which is denoted as:
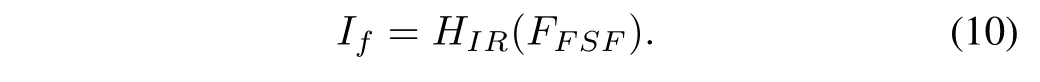
The fused image reconstruction unit contains three convolutional layers with kernel size of 3×3 and stride of 1, where the first two layers are followed by the Leaky Relu activation function.
B. Loss Function
In order to model the multi-modal image fusion and digital photography image fusion uniformly, we generalize different image fusion problems into structure maintenance, texture preservation, and suitable intensity control. Accordingly, we design SSIM loss, texture loss, and intensity loss to constrain the network.
SSIM Loss:Considering that the structural similarity (SSIM)index is the most widely used metric, which reflects image distortion from three aspects,i.e., light, contrast, and structure [75], we employ SSIM lossLssimto constrain the structural similarity betweenIfandI1,I2. Specifically, SSIM loss is defined as:
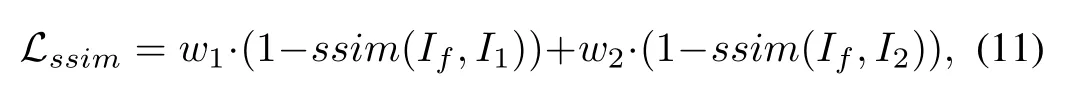
wheressim(·) represents the structural similarity operation,which measures the similarity of two images. We consider that both source images have the same contribution to the fused result in terms of structural information. Therefore, we setw1=w2=0.5 in this work.
Texture Loss:One of the objectives of image fusion is to integrate texture details in the source images into a single fused image. We observe that the texture details in source images could be effectively aggregated by the maximum selection strategy. Thus, texture lossLtext, presented in Eq. (12), is designed to guide the network to preserve as many texture details as possible.
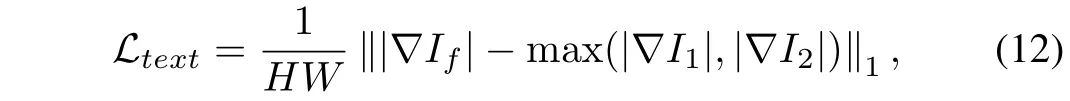
where∇indicates the Sobel gradient operator, which could measure texture information of an image.|·| stands for the absolute operation,‖·‖1denotes thel1-norm,and max(·)refers to the element-wise maximum selection.
Intensity Loss:An excellent image fusion algorithm is expected to generate a fused image with appropriate intensity according to global apparent intensity information of the source images. For this purpose, we devise the following intensity lossLintto guide our fusion model to capture proper intensity information:
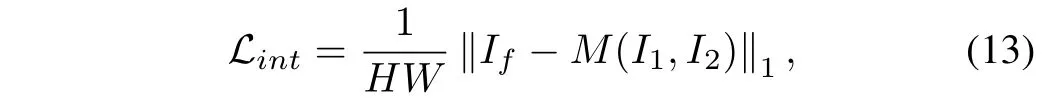
whereM(·) is an element-wise aggregation operation, which is associated with the specific fusion scenario. Inspired by IFCNN[20],the element-wise maximum selection,i.e.,max(·)is deployed for visible and infrared image fusion(VIF),medical image fusion (Med), and multi-focus image fusion (MFF). In addition, we leverage the element-wise mean aggregation,i.e.,mean(·) for visible and near-infrared image fusion (VIS-NIR)and multi-exposure image fusion (MEF).
Finally, the full objective function for our fusion model is a weighted sum of all sub-loss terms from Eq. (11) to Eq. (13):
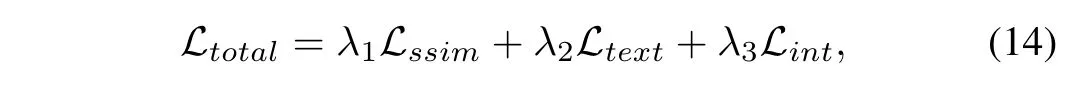
whereλ1,λ2, andλ3are the hyper-parameters that control the trade-off of each sub-loss term.
IV. EXPERIMENTS RESULTS AND DISCUSSIONS
In this section, we compare SwinFusion with several stateof-the-art algorithms on both the multi-modal image fusion and digital photography image fusion scenarios by quantitative and qualitative comparisons. We first provide the experimental configurations and then give some implementation details. Subsequently, we conduct quantitative and qualitative comparisons with state-of-the-art alternatives.Extended experiments on other vision tasks are also performed to demonstrate the potential of our method for other computer vision missions. Finally, we verify the effectiveness of specific designs through a series of ablation studies.
A. Experimental Configurations
Datasets:We verify our SwinFusion in multi-modal image fusion and digital photography image fusion. We select three representative scenarios,i.e., visible and infrared image fusion (VIF), visible and near-infrared image fusion (VISNIR) as well as medical image fusion (Med) for multi-modal image fusion. Two typical tasks,i.e., multi-exposure image fusion (MEF) and multi-focus image fusion (MFF) are chosen for digital photography image fusion. The training and test data for all fusion tasks are from publicly available datasets.The MSRS dataset [76], [77]1, containing 1,083 training image pairs and 361 testing image pairs, is selected for training and evaluating the visible and infrared image fusion task. We build the training and test datasets based on the publicly available VIS-NIR Scene dataset [78]2for VIS-NIR. The numbers of the training set and test set are 377 and 100,respectively. The training and test datasets for medical image fusion are built on the publicly available Harvard medical dataset3. Specifically, we select 249 and 20 image pairs for the training and testing of PET and MRI image fusion (Med (PETMRI)). The numbers of the training set and test set for CT and MRI image fusion (Med (CT-MRI)) are 163 and 20,respectively. Moreover, the MEF dataset [79]4is employed to train the model for MEF,and the MEF benchmark dataset[80]5,containing 100 pairs of images with various scenarios, is used as the test set. The MFI-WHU [56]6and Lytro [81]7datasets are utilized for training and testing of MFF,respectively,where the Lytro dataset is composed by 20 pairs of color multi-focus images of size 520×520 pixels.
The reasons why we set different test set sizes for different image fusion scenarios are as follows. First of all, some datasets (e.g., MEFB and Lytro) are only adapted to test the performance of different algorithms, so the number of the test sets is the number of the whole datasets,i.e., 100 for the MEFB dataset and 20 for the Lytro dataset. Moreover,the MSRS dataset specifies the number of the test set,i.e.,361. Because of the number limitation of the Harvard medical dataset, we randomly select 20 test images for all medical image fusion tasks, which is consistent with the Lytro dataset.Besides, 100 test images are randomly selected from the VISNIR Scene dataset for the visible and near-infrared image fusion mission, which is kept consistent with the MEFB dataset.
Comparison Algorithms:We select seven state-of-the-art methods, including four general image fusion frameworks and three task-specific approaches as the comparison algorithms for each fusion task. The four unified image fusion algorithms are IFCNN [20], PMGI [16], SDNet [60], and U2Fusion [10]. GTF [17], DenseFuse [22], and Fusion-GAN [55] are the three task-specific fusion methods for VIF.ANVF [3], DenseFuse [22], and GANMcC [82] are the taskspecific comparison algorithms for VIS-NIR. CSMCA [39],EMFusion [4] and DDcGAN [24] are three task-specific approaches selected for medical image fusion tasks. The taskspecific alternatives for MEF are SPD-MEF[41],MEFNet[83],and MEF-GAN [25]. SFMD [42], DRPL [46], and MFFGAN [56] are three comparison methods for MFF. It is worth mentioning that all algorithms, except GTF [17], ANVF [3],CSMCA [39], SPD-MEF [41], and SFMD [42] that are traditional schemes, are deep learning-based methods.

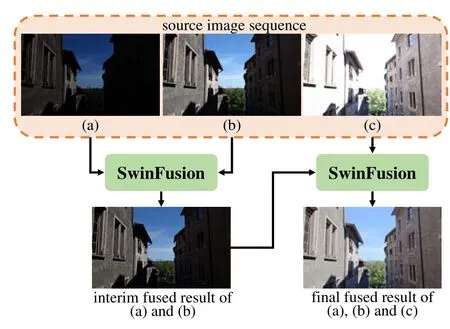
Fig. 5. SwinFusion to fuse multi-exposure image sequence.
Evaluation Metrics:Four metrics are selected to quantify the evaluation, including feature mutual information (FMI) [84],Qabf, structural similarity (SSIM) [75], and peak signal-tonoise ratio (PSNR). FMI andQabfrespectively measure the amount of feature information and edge information, which are transferred from source images to the fused image. PSNR reveals the distortion during the fusion process at the pixel level. In addition, SSIM reflects the image distortion from the perspectives of brightness, contrast, and structure. A fusion method with higher FMI,Qabf, SSIM, and PSNR implies better fusion performance.
B. Implementation Details
The batch size is set to 16, and it takes 10 000 training steps for each fusion task. In each step, the images from the training set are randomly cropped into 128×128 patches, which then are normalized to [0,1]. The parameters of our SwinFusion are updated by the Adam optimizer with learning rate initialized to 2×10−4then decayed exponentially.The hyper-parameters that control the trade-off of each sub-loss term are empirically set asλ1=10,λ2=20, andλ3=20. Besides, the window sizeMis set to 8, referring to SwinIR [33]. The proposed SwinFusion is implemented on the PyTorch platform [85]. Moreover, all experiments are conducted on the NVIDIA TITAN RTX GPU and 2.60GHz Intel(R) Xeon(R) Platinum 8171M CPU.
Dealing with RGB Inputs:RGB inputs are first converted into the YCbCr color space.Next,the Y(luminance)channel is employed as the input of the fusion model since the structural details and intensity information are primarily concentrated in this channel. As for multi-modal image fusion, the fused Y channel is mapped back to the RGB color space along with Cb and Cr (chrominance) channels of the visible image (or PET image) since only the visible image and PET image contain color information. As for digital photography image fusion,the Cb and Cr channels are merged traditionally according to:
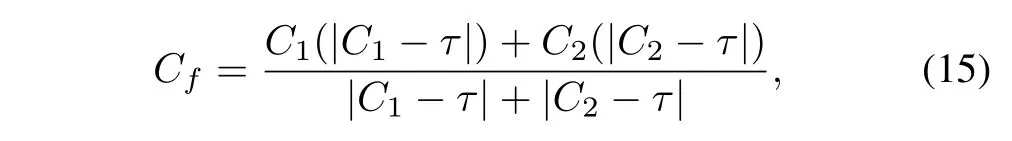
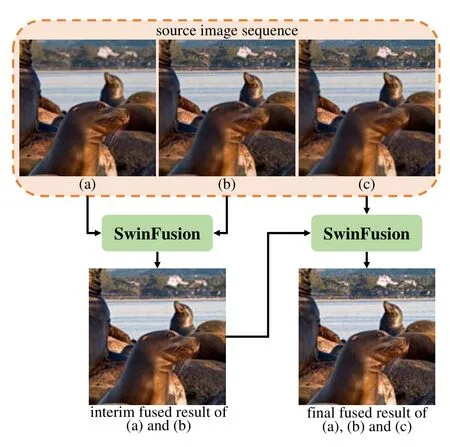
Fig. 6. SwinFusion to fuse multi-focus image sequence.
whereC1andC2are the Cb or Cr channels of source imageI1andI2,respectively.Cfis the fused result of the corresponding channel.τis set as 128 in this work.Then,the fused Y,Cb,and Cr channels are converted to the RGB color space through the inverse conversion. Thus, both multi-modal image fusion and digital photography image fusion are unified into the singlechannel image fusion problem.
Dealing with Sequence Inputs:In practice, a robust framework is expected to fuse sequence images,i.e., more than two images. In this case, we sequentially fuse these source images. The schematic diagrams are presented in Fig. 5 and Fig. 6. As shown in these diagrams, we initially merge two sequence images. Then, the interim result is fused with another source image to generate the final fused image. In this manner,our SwinFusion is theoretically capable of fusing an arbitrary number of sequence images.
C. Results on Multi-modal Image Fusion
Quantitative Comparison:Table I shows the quantitative comparisons between SwinFusion and state-of-the-art algorithms. As one can see, SwinFusion achieves leadership in almost all metrics for multi-modal image fusion tasks. More specifically, the highest FMI andQabfmean that our approach transfers the most feature and edge information from source images into the fused image. The best SSIM on VIF, VISNIR, and Med (PET-MRI) reveals the advantage of structural information maintenance. The proposed framework only lags behind IFCNN by a narrow margin in the SSIM index for Med(CT-MRI).Moreover,our method achieves the best PSNR on VIS-NIR, which implies that our approach has the least information distortion during the fusion process. Although the PSNR of our scheme on VIF lags behind other competitors,this is justifiable. More specifically, our model pays more attention to the salient target regions in the infrared image by adequately integrating the global interactions in source images, resulting in the loss of information in the non-salient areas. A similarphenomenon also occurs in medical image fusion because our fusion network focuses more on significant regions and ignores unimportant areas in source images.
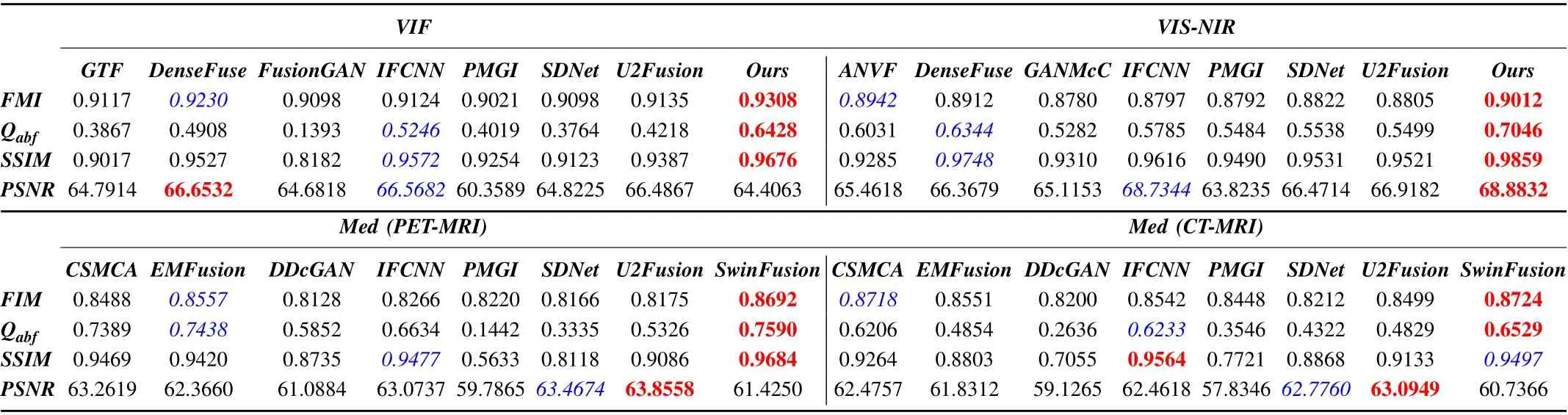
TABLE I QUANTITATIVE COMPARISON WITH STATE-OF-THE-ARTS IN THE MULTI-MODAL IMAGE FUSION SCENARIOS.RED INDICATES THE BEST RESULT AND BLUE INDICATES THE SECOND BEST RESULT

Fig. 7. Qualitative comparison of SwinFusion with five state-of-the-art methods on visible and infrared image fusion. From left to right: infrared image, visible image, and the results of GTF, DenseFuse, IFCNN SDNet, U2Fusion, and our SwinFusion.

Fig. 8. Qualitative comparison of SwinFusion with five state-of-the-art methods on visible and near-infrared image fusion. From left to right: near-infrared image, visible image, and the results of ANVF, DenseFuse, IFCNN, SDNet, U2Fusion, and our SwinFusion.
Visual Quality Comparison:We also provide some visual results in Fig. 7 - Fig. 10 to intuitively exhibit the advantages of our method in global context integration. As can be seen in Fig. 7, GTF, SDNet, and U2Fusion cannot effectively present scene information in the visible images,since the lack of global information interaction and inappropriate intensity control. In addition, DenseFuse and IFCNN can preserve some of the texture details of visible images, but still suffer from thermal radiation contamination and weaken salient targets of infrared images to varying degrees. It is worth emphasizing that our SwinFusion not only preserves the scene information of visible images but also maintains the salient objects, benefiting from effective global context perception and proper intensity control.In particular, our model is able to adaptively attend to salient regions in infrared images and the background in the visible images through the intra- and inter-modal long-range modeling and global context aggregation.
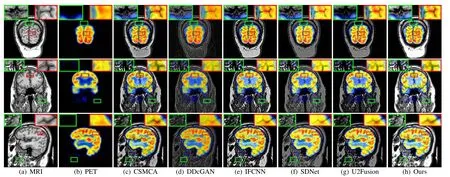
Fig. 9. Qualitative comparison of SwinFusion with five state-of-the-art methods on PET and MRI image fusion. From left to right: MRI image, PET image,and the results of CSMCA, DDcGAN, IFCNN, SDNet, U2Fusion, and our SwinFusion.
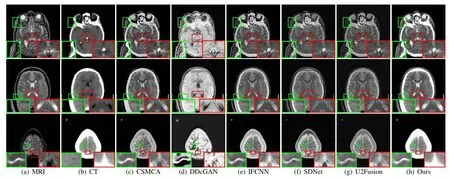
Fig. 10. Qualitative comparison of SwinFusion with five state-of-the-art methods on CT and MRI image fusion. From left to right: MRI image, CT image, and the results of CSMCA, DDcGAN, IFCNN, SDNet, U2Fusion, and our SwinFusion.
For visible and near-infrared image fusion, an excellent fusion algorithm is expected to transfer the texture details from the near-infrared image into the visible image to generate the fused image. As presented in Fig. 8, ANVF, DenseFuse, and U2Fusion fail to integrate the texture details in the near-infrared images into the fused results. Only the fused images generated by IFCNN,SDNet,and SwinFusion look like sharpened visible images. Particularly, our method is superior in quantitative evaluations thanks to adequate global information aggregation,effective structure maintenance, and texture preservation.
The visual quality comparison of PET and MRI image fusion(Med(PET-MRI))is exhibited in Fig.9.From the results,one can find that other fusion algorithms inevitably weaken essential information in source images. More specifically, in some areas where PET images do not contain functional information, other competitors usually corrupt soft-tissue information in MRI images due to the lack of global context integration and appropriate intensity control. This issue can be observed from the green boxes in Fig. 9. In addition, as shown in red boxes, DDcGAN and SDNet fail to efficiently aggregate complementary information in source images and smooth the texture details in MRI images. It is worth noting that our fusion model can preserve the abundant details in MRI images and characterize the functional information in PET images sufficiently, owing to effective structure maintenance,global interaction aggregation, and proper intensity control.
We also provide some qualitative fused results on three typical CT and MRI image pairs in Fig. 10. In the results of other alternatives, the dense structures in CT images are weakened to different extents. Moreover, the edges in MRI images are diminished by the CSMCA, IFCNN, and U2Fusion,as shown in the first and second rows. Besides, DDcGAN fails to maintain the intensity distribution and contrast of source images. On the contrary, our SwinFusion preserves more structural(texture)information under the premise of little loss of soft-tissue details and anatomical information.

TABLE II QUANTITATIVE COMPARISON WITH STATE-OF-THE-ARTS IN THE DIGITAL PHOTOGRAPHY IMAGE FUSION SCENARIOS.RED INDICATES THE BEST RESULT AND BLUE INDICATES THE SECOND BEST RESULT

Fig. 11. Qualitative results of multi-exposure image fusion. From left to right: under-exposed image, over-exposed image, and the results of SPD-MEF,MEF-GAN, IFCNN SDNet, U2Fusion, and our SwinFusion.
D. Results on Digital Photography Image Fusion
Quantitative Comparison:The quantitative comparisons between our method and other alternatives on digital photography image fusion scenarios are exhibited in Table II. From the results, we see that our framework ranks first inQabf, SSIM,and PSNR for both multi-exposure image fusion and multifocus image fusion. Moreover, the proposed method achieves the best FMI for MEF, and it only lags behind MADCNN by a narrow margin in the FMI metric for MFF. The above phenomena indicate that our model can effectively integrate the complementary information and sufficiently maintain texture and structure information in source images.
Visual Quality Comparison:The qualitative comparisons of multi-exposure image fusion are shown in Fig. 11. As one can observe, other algorithms fail to maintain appropriate exposure levels since these algorithms lack the ability of global exposure awareness. More specifically, SDNet and U2Fusion are unable to light up the scene information hidden in the darkness (e.g.,regions highlighted in the red boxes). Although the overall exposure level of MEF-GAN is slightly better, it causes local over-exposure and blur, owing to the introduction of downsampling in the modeling process. SPD-MEF and IFCNN introduce artifacts in some areas, such as the light in the second row. In addition, SPD-MEF loses all information in the under-exposed images, leading to severe over-exposure in the fused results. Only our SwinFsuion can effectively merge the complementary information in the source images and maintain the appropriate exposure level by global exposure perception.
We also present the results of subjective comparison for multi-focus image fusion in Fig. 12. From the results, we can note that all approaches could integrate information from the focused regions in different source images and generate an all-in-focus image.However,MFF-AGN,SDNet and U2Fusion cannot retain the best intensity distribution due to the lack of global context interaction. Our method enables adaptive focus region awareness and maintains the proper intensity distribution through global context aggregation.
In summary, extensive objective and subjective comparisons on both multi-modal image fusion and digital photography image fusion demonstrate the superiority of our SwinFusion in terms of structure maintenance, texture detail preservation, and appropriate intensity control. We summarize our strengths in the following aspects. On the one hand, we explicitly design the corresponding loss functions to achieve structure retention,texture preservation, and adaptive intensity control separately.On the other hand, the proposed attention-guided cross-domain fusion module enables intra- and inter-domain long-range dependency modeling and global context aggregation, which allows our method to model intensity distribution from a global perspective. Moreover, the transformer-based deep feature extraction module also assists our model to mine significant features and information from the global viewpoint.
E. Visualization of Global Information
As mentioned previously, our method is able to adequately exploit global information within and between domains.Abstractly, for multi-modal image fusion, our method can accurately perceive salient features (e.g., the thermal targets in the infrared images and soft-tissue information in MRI images) by combining global information and integrate them effectively into the fused images.For digital photography image fusion, global information assists our model in perceiving

Fig. 12. Qualitative results of multi-focus image fusion. From left to right: near/far-focus image, the fused results and difference maps of SFMD, DRPL,MFF-GAN, IFCNN, SDNet, U2Fusion, and our SwinFusion. The difference maps represent the difference between the near-focus image and fused results.
the intensity distribution in source images from a global viewpoint and presenting scene information with the appropriate intensity. In order to intuitively demonstrate the role of global information, we provide a schematic diagram in Fig. 13. The second column shows the fused results with the local patches as inputs. One can note that when global information is lacking (i.e., with local patches as inputs), our model fails to preserve the prominent targets in the infrared images effectively.Besides,without the ability to perceive the intensity distribution from a global perspective, our method is also unable to present scene information with a proper exposure level in the multiexposure image fusion task.Specifically,the fused images suffer from alternating underexposure and normal exposure. On the contrary, when the whole images are used as inputs, providing enough global information for our model, our method not only effectively preserves the salient targets in the infrared images but also presents scene information with normal exposure.
F. Image Fusion for Other Vision Tasks
We investigate the positive role of image fusion for other vision tasks. Specifically, we analyze the performance of othervision missions (e.g., semantic segmentation, object detection,and depth estimation) with the conditions of taking the source and fused images as inputs.

TABLE III SEGMENTATION PERFORMANCE(MIOU) OF VISIBLE,INFRARED AND FUSED IMAGES ON THE MSRS DATASET.RED DENOTES THE BEST RESULT

Fig. 13. Visualization of global information. The first two rows represent the visible and infrared image fusion scenario, and the following two rows show the multi-exposure image fusion scenario.
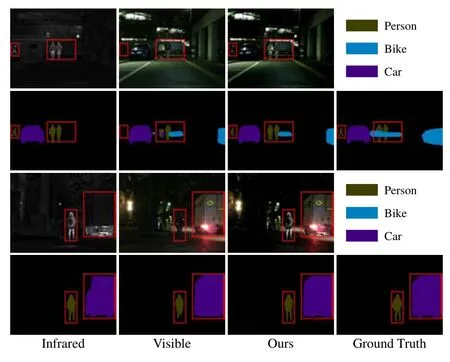
Fig. 14. Visual results of semantic segmentation. The first and third rows represent the source image and fused images. The second and fourth rows exhibit the corresponding segmentation results and ground truth.
Visible and Infrared Image Fusion for Semantic Segmentation:The relevant experimental configuration is followed by SeAFusion [7]. The quantitative results of semantic segmentation, measured by pixel intersection-over-union (IoU),are exhibited in Table III. From the results, one can see that our fusion method could effectively facilitate the segmentation model [86] to perceive the imaging scenario by adequately integrating intra- and inter-modal complementary information as well as global context.We also provide some visual examples in Fig.14 to intuitively reveal the positive effect of fused results for semantic segmentation.One can note that the infrared image can provide enough information about pedestrians and cars,but cannot give information about the bike for the segmentation model in the first scene. In contrast, the segmentation model can segment the car and bikes, but fails to split people from the visible image completely. Specifically, the segmentation model can segment the pedestrians, cars, and bikes from the fused image, which integrates the advantages of both infrared and visible images. Moreover, neither the visible nor infrared images provide enough information for the segmentation model to completely split both person and car in the second scenario.The segmentation network only perceives adequate scene information from the fused image to fully segment the car and pedestrian.

Fig.15. Visual results of object detection.From top to bottom are the detection results of infrared images, visible images, and fused images generated by SwinFusion, respectively.
Visible and Infrared Image Fusion for Object Detection:We also investigate the role of visible and infrared image fusion in object detection. A state-of-the-art detection network,i.e.,YOLOv5 [87] is employed to measure object detection performance on the source images and fused images. The test set is collected and labeled by GAN-FM [88]. We exhibit the mean average precision (mAP) of object detection in Table IV, where AP@0.5, AP@0.7 and AP@0.9 denote the AP values at IoU thresholds of 0.5, 0.7 and 0.9, respectively,and mAP@[0.5:0.95] stands for the average of all AP values at different IoU thresholds (from 0.5 to 0.95 in steps of 0.05).
As shown in Table IV, we can observe that visible and infrared images provide only object-specific information for the detector.Thus,the detection model achieves better car detection performance on visible images, but has superior pedestrian detection performance on infrared images.Such complementary characteristics offer the potential for the detector to achieve better performance on fused images. In fact, the detection network shows a more balanced performance on fused images.Moreover, the fused images can provide a more comprehensive description for cars by combining complementary information in source images.Thereby,the detector could achieve better car detection performance.Although the performance of pedestrian detection on fused images is inferior to that on infrared images,it is justifiable. The infrared image merely collects the thermal radiation information from the salient object but ignores the surrounding environment, resulting in a higher contrast for prominent targets such as person, which facilitates the detector to detect pedestrians. Some visualized examples are presented in Fig. 15.
Multi-focus Image Fusion for Depth Estimation:The impacts of multi-focus images and fused results on depth estimation are shown in Fig. 16. We employ AdaBins [89] to estimate the high quality dense depth map from a single RGB input image. From the visual results, we can find that AdaBins only successfully estimates the dense depth map of objects in the focused regions from the multi-focus images, while objects in non-focused areas are treated equally,i.e., the correct depth map cannot be estimated. Moreover, our method effectively integrates the scene information in the focused regions of the source images into a single all-in-focus image. Thus, AdaBins is able to successfully estimate the dense depth maps of all objects from the fused images.

TABLE IV OBJECT DETECTION PERFORMANCE(MAP) OF VISIBLE, INFRARED AND FUSED IMAGES ON THE MSRS DATASET. RED INDICATES THE BEST RESULT

Fig. 16. Visual results of depth estimation. The first and third columns are the source images and fused results. The second and fourth columns are the corresponding dense depth maps.
G. Ablation Study
The performance of our SwinFusion relies on the elaborate network architecture and loss functions. On the one hand, the joint CNN-Transformer architecture effectively mines the local information and global interaction from the source images.Especially, the Transformer-based deep feature extraction (DE)fully extracts the global context in the shallow features. Moreover,the attention-guided cross-domain fusion module(ACFM)adequately integrates complementary information as well as intra- and inter-domain long-range dependencies, which allows our network to perceive apparent intensity from a global perspective. On the other hand, the designed SSIM loss,texture loss, and intensity loss drive our model to achieve effective structure maintenance, texture detail preservation, and appropriate intensity control. In this section, we perform a series of ablation studies to verify the effectiveness of specific designs. The visual results of the ablation experiments on the multi-modal image fusion (e.g., VIF) and digital photography image fusion (e.g., MEF) are presented in Fig. 17.
Analysis of Deep Feature Extraction(DE):The Transformerbased deep feature extraction could exploit the global context in the shallow features to provide an appropriate intensity perception for the fusion model. As shown in Fig. 17 (c), the fused results fail to present a suitable apparent intensity after removing the deep feature extraction. Specifically, the fusion network is unable to perceive significant and complementary information in the source images for visible and infrared image fusion.
Analysis of Attention-guided Cross-domain Fusion Module(ACFM):The attention-guided cross-domain fusion module consists of the intra-domain fusion unit based on self-attention and the inter-domain fusion unit based on cross-attention,which can fully aggregate long-range dependencies and global interaction within the same domain and across domains.From Fig. 17 (d), we can find that the fusion model cannot effectively control the apparent intensity of the fused images after removing the ACFM. This phenomenon is particularly evident for the multi-exposure image fusion task,i.e.,the fused results fail to present an appropriate exposure level.
Analysis of Inter-domain Fusion Unit(Inter):The interdomain fusion unit, an essential component of the attentionguided cross-domain fusion module, is able to fully exploit and leverage the long-range dependencies across domains to achieve effective information integration. As illustrated in Fig. 17 (e), the visual performance of the network without the inter-domain fusion unit on the VIF task is similar to that of the network without the ACFM. This phenomenon indicates that significant targets and structures in the VIF task are perceived by integrating global information across domains. In addition, removing only the inter-domain fusion unit improves the exposure situation of the fused images compared to removing the whole ACFM. However, the fused images generated by the network without the inter-domain fusion unit still fail to present the scene information with a suitable exposure level.
Analysis of Structure Maintenance(Lssim):We introduce SSIM loss (Lssim) to constrain the fusion network to maintain the structural information in the source images. In addition,SSIM loss could restrain the brightness of the fusion results to some extent.As presented in Fig.17(f),the network without the constraint of SSIM loss cannot maintain the optimal structure and intensity information. In particular, the salient targets in the infrared images are slightly weakened for the VIF scenario.
Analysis of Texture Preservation(Ltext):For better characterizing the imaging scenes, the abundant textures of source images are expected to be preserved in the fused results as much as possible. Thus, we design texture loss to retain more texture details. From Fig. 17 (g), one can note that the fusion model trained without texture loss fails to generate fused images with rich textures. This issue can be observed in cracks on the ground, fences on the roadside, clouds in the sky, and textures on the wall.

Fig. 17. Visual results of the ablation experiment on the visible and infrared image fusion and multi-exposure image fusion scenarios.
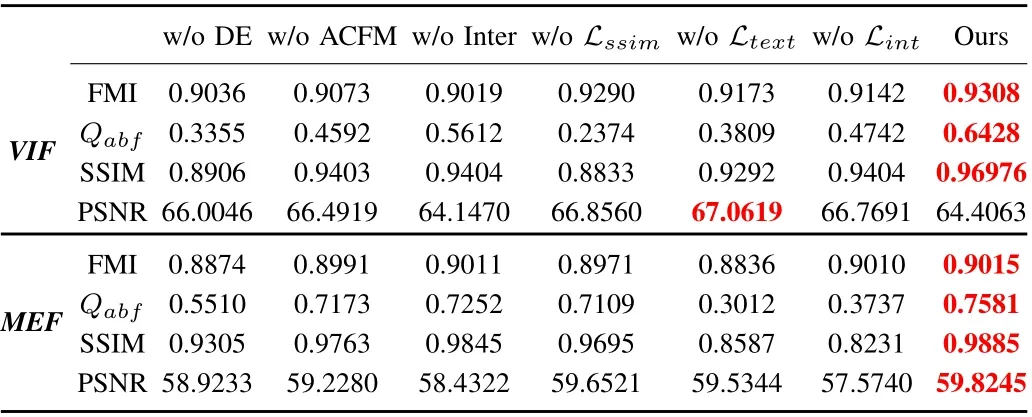
TABLE V QUANTITATIVE EVALUATION RESULTS OF ABLATION STUDIES ON THE VIF AND MEF TASKS. RED DENOTES THE BEST RESULT
Analysis of Appropriate Intensity Control(Lint):We also devise intensity loss to constrain the fusion network to present fused results with proper intensity. The fused images without the constraint of intensity loss are exhibited in Fig. 17 (h).From the results, we can find that the fusion network is unable to generate the fused results with suitable apparent intensity after removing intensity loss. Specifically, the fusion model weakens the significant objects for the VIF task and fails to perceive the normal exposure level for the MEF scenario.
It is worth emphasizing that our SwinFusion can implement effective structure maintenance,texture preservation,and proper intensity control with the constraint of SSIM loss, texture loss,and intensity loss.In particular,our fusion model could achieve global intensity perception by sufficiently integrating intra- and inter-domain long-range dependencies and global interactions.
The quantitative results of ablation studies are presented in Table V. As we can see from the results, removing any of the components will degrade the fusion performance to a greater or lesser extent. The PSNR is improved for the visible and infrared image fusion, which is caused by the fusion model failing to perceive significant information in the source images.Especially, although the degradation of visual results is not severe after removing SSIM loss,there is a distinct degradation of the quantitative evaluation.
H. Computational Complexity Analysis
As shown in Table VI,a complexity evaluation is introduced to evaluate the operational efficiency of different methods from three perspectives,i.e.,training parameters(size),floating-point operations per second (FLOPs), and runtime. The first image of the test set in each fusion scenario is utilized to calculatethe FLOPS of methods. From the results, we can observe that the deep learning-based methods have a significant advantage in runtime compared to traditional methods, benefiting from GPU acceleration. Among the general image fusion methods,PMGI, IFCNN, and SDNet have lower training parameters,FLOPs, and average running time. Moreover, MEFNet and MFF-GAN have the lowest training parameters and FLOPs in the MEF and MFF tasks, respectively. It is worth pointing out that our method has comparable operational efficiency with the dominant image fusion algorithms, although it requires computing pixel-to-pixel correlations (i.e., attention) within a window and includes several transformer-based components.
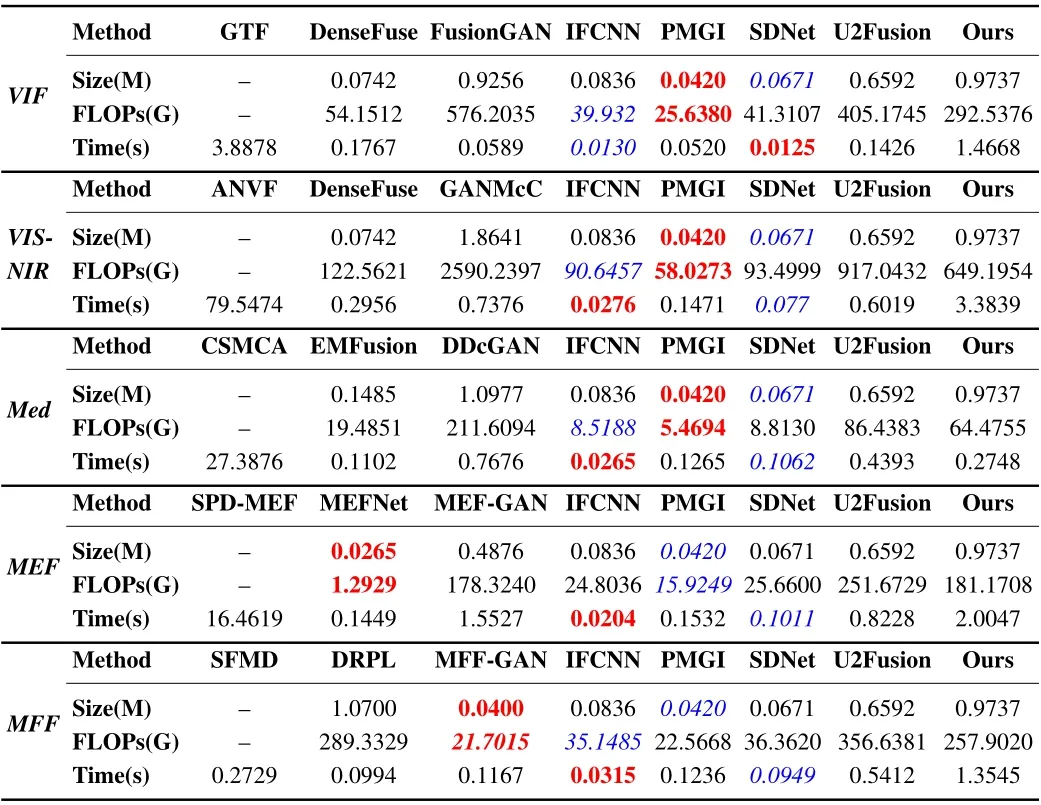
TABLE VI COMPUTATIONAL EFFICIENCY COMPARISON WITH STATE-OF-THE-ART IMAGE FUSION METHODS. RED AND BLUE DENOTE THE BEST AND THE SECOND BEST RESULTS, RESPECTIVELY
V. CONCLUSION
In this paper, we have proposed a general image fusion method based on cross-domain long-range learning and Swin Transformer, called SwinFusion, which could handle multimodal image fusion and digital photography image fusion in a unified framework. The proposed SwinFusion unifies multimodal image fusion and digital photography image fusion as structure maintenance, texture detail preservation, and appropriate intensity control. Then, we have devised a unified loss function consisting of SSIM loss,texture loss,and intensity loss to constrain the network to fulfill the corresponding functions.Moreover, a self-attention-based intra-domain fusion unit and a cross-attention-based inter-domain fusion unit have been developed to adequately integrate the long-range dependencies and global interactions within the same domain and across domains. Based on the elaborate network architecture and loss functions, the proposed method is able to maintain the structural information and preserve abundant texture details in source images under both the multi-modal image fusion and digital photography image fusion scenarios. In addition,our model presents the appropriate apparent intensity for the fused image from a global perspective. Extensive experiments have been conducted to verify the superiority of SwinFusion compared to state-of-the-art alternatives. Besides, the expanded experiments on semantic segmentation, object detection, and depth estimation demonstrate the potential of image fusion for other computer vision tasks.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- An Overview and Experimental Study of Learning-Based Optimization Algorithms for the Vehicle Routing Problem
- Towards Long Lifetime Battery: AI-Based Manufacturing and Management
- Disagreement and Antagonism in Signed Networks: A Survey
- Finite-Time Distributed Identification for Nonlinear Interconnected Systems
- Real-Time Iterative Compensation Framework for Precision Mechatronic Motion Control Systems
- Meta Ordinal Regression Forest for Medical Image Classification With Ordinal Labels