An Overview and Experimental Study of Learning-Based Optimization Algorithms for the Vehicle Routing Problem
2022-07-18BingjieLiGuohuaWuYongmingHeMingfengFanandWitoldPedrycz
Bingjie Li, Guohua Wu, Yongming He, Mingfeng Fan, and Witold Pedrycz,,
Abstract—The vehicle routing problem (VRP) is a typical discrete combinatorial optimization problem, and many models and algorithms have been proposed to solve the VRP and its variants. Although existing approaches have contributed significantly to the development of this field, these approaches either are limited in problem size or need manual intervention in choosing parameters. To solve these difficulties, many studies have considered learning-based optimization (LBO) algorithms to solve the VRP. This paper reviews recent advances in this field and divides relevant approaches into end-to-end approaches and step-by-step approaches. We performed a statistical analysis of the reviewed articles from various aspects and designed three experiments to evaluate the performance of four representative LBO algorithms. Finally, we conclude the applicable types of problems for different LBO algorithms and suggest directions in which researchers can improve LBO algorithms.
I. INTRODUCTION
THE VRP is one of the most widely researched problems in transportation and operations research areas [1]. The canonical VRP has a simple structure and can be seen as a basic discrete combinatorial optimization problem. Many optimization problems can be transformed into the form of the VRP. Hence, the VRP can be used to demonstrate the optimization performance of different algorithms, which can help to design efficient algorithms. Moreover, the VRP has significant practicality in the real world. VRP variants have appeared in many fields [2], [3], particularly in the logistic industry that is flourishing with the development of the globalization. Effective routing optimization can save a lot of cost (generally ranging from 5% to 20%) [4], which is of great significance for improving distribution efficiency [1], [5]–[8]and increasing economic benefits of enterprises [9]–[11]. The VRP is still continuously attracting attention from researchers[12], [13]. However, it is still a challenging optimization task due to the NP-hard characteristic [14] and its different complex variants.
Optimization algorithms for solving the VRP can be crudely divided into three categories: exact, heuristic, and LBO algorithms. Fig. 1 shows the overview of referred algorithms.Heuristic algorithms and exact algorithms are traditional algorithms for combinatorial optimization problems, and much of the literature has reviewed their applications in the VRP [15]. Mańdziuk [16] reviewed papers using heuristic algorithms to solve the VRP between 2015 and 2017.Adewumi and Adeleke [17] emphasized recent advances of traditional algorithms in 2018, while Dixitet al. [18] reviewed some of the recent advancements of meta-heuristic techniques in solving the VRP with time windows (VRPTW). Exact and heuristic algorithms have made significant progress in the VRP, but the recent research trend has been to design a flexible model that can solve the VRP with large scale and complex constraints more quickly. Exact algorithms need adequate time to get an optimal solution when solving a VRP with a large scale [19]. The optimality of heuristic algorithms cannot be guaranteed and their computational complexity is not satisfactory [20]. What’s more, these two kinds of algorithms usually need a specific design for solving the concrete problem. In recent years, the LBO algorithms have been applied to different combinatorial optimization problems[21], [22], and many remarkable research breakthroughs have been achieved. Hence, the LBO algorithms have attracted significant attention in the field of the VRP.
The LBO algorithms can learn a model from training sets to obtain optimization strategies [23], [24], which could automatically produce solutions of online tasks by end-toend or step-by-step approaches. In end-to-end approaches,the model is trained to approximate a mapping function between the input and the solution, and the model can directly output a feasible solution when given an unknown task in application. While step-by-step approaches learn optimization strategies that could iteratively improve a solution rather than outputting a final solution directly. Both approaches have strong learning ability and generalization. They can overcome the deficiencies of the tedious parameter tuning of exact and heuristic algorithms and rapidly solve online instances with the advantage of offline training. However, the LBO algorithms still have some technological bottlenecks to be settled, such as training data limitation, generality limitation,and so on.
Overall, although the application of the LBO algorithms to the VRP have become popular and significant achievements have been made [25], [26] in recent years, up to now there are no comprehensive assessment experiments and in-depth analyses on the characteristics of different LBO algorithms in solving the VRP. Therefore, we aim to present an elaborate overview and experimental study of related works to fill the gap in this field. The contributions of the paper are mainly on the following aspects:
1) The paper briefly introduces the applications of LBO algorithms to the VRP to aid beginners in understanding the development of this field.
2) The paper discusses the advantages and disadvantages of different LBO algorithms based on extensive experiments on different datasets.
3) The paper suggests promising research trends on using LBO algorithms to solve the VRP in the future.
The remainder of this paper is structured as follows. In Section II, we introduce the background of the VRP, including the mathematical model and classical optimization algorithms.In Section III, we review the related literatures and provide a summative analysis of the references. In Section IV, the experimental comparisons among different algorithms are presented. The final section summarizes the full text and suggests several research trends of using LBO algorithms to solve the VRP.
II. BACKGROUND OF THE VRP
As routing optimization problems become increasingly crucial in industrial engineering, logistics, etc, a series of research breakthroughs have been achieved in the VRP and many algorithms have been proposed. In this section, we briefly introduce the background of the VRP.
A. Variants of the VRP
The mathematical model of the VRP is first proposed by Dantzig and Ramser [27] in 1959. A few years later, Clarke and Wright [28] proposed an effective greedy algorithm to solve the VRP, which also launched a research boom involving the VRP. The VRP can be defined as follows: for a series of nodes with different demands, the aim is to plan routes with the lowest total cost under various side constraints[29], [30] for vehicles to serve these nodes sequentially according to the planning routes. With its wide applications in the real world, the VRP must consider more constraints,which results in the derivation of many variants. Fig. 2 presents the hierarchy of VRP variants.
The basic version of the VRP is the capacitated vehicle routing problem (CVRP) [16], [31]. In the CVRP, each customer is served only once and the sum of goods carried by a vehicle should not exceed its capacity [32]. This type of problem has the following characteristics: 1) vehicles leave from the depot and return to it; 2) vehicles are permitted to visit each customer on a set of routes exactly once; 3) each customer has a non-negative demand of delivery. Fig. 3 is the schematic diagram of the CVRP.
B. Mathematical Model of the VRP
The VRP can be described by an integer programming model [19], and we mainly present the mathematical model of the CVRP in this subsection. According to [33], the mathematical model of the CVRP can be expressed as follows, whereNrepresents the set of customers, the number 0 represents the depot,Krepresents the number of vehicles,Arepresents the set of arcs andVrepresents the set of nodes,withV=N∪{0}.We defineabinarydecisionvariableto be 1 if the pairofnodesiandjareadjacentintherouteof the vehiclek; otherwise,equals0. Each vehicle’s maximum capacity isC.represents the surplus capacity of thevehiclekafterit serves the customeri,andqjindicates the demandof customerj.
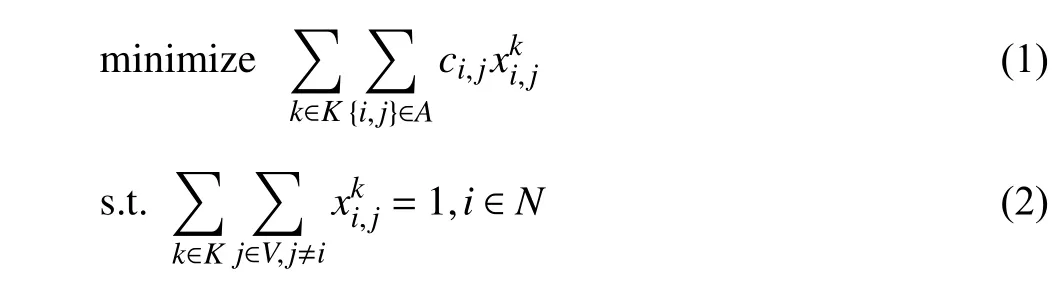
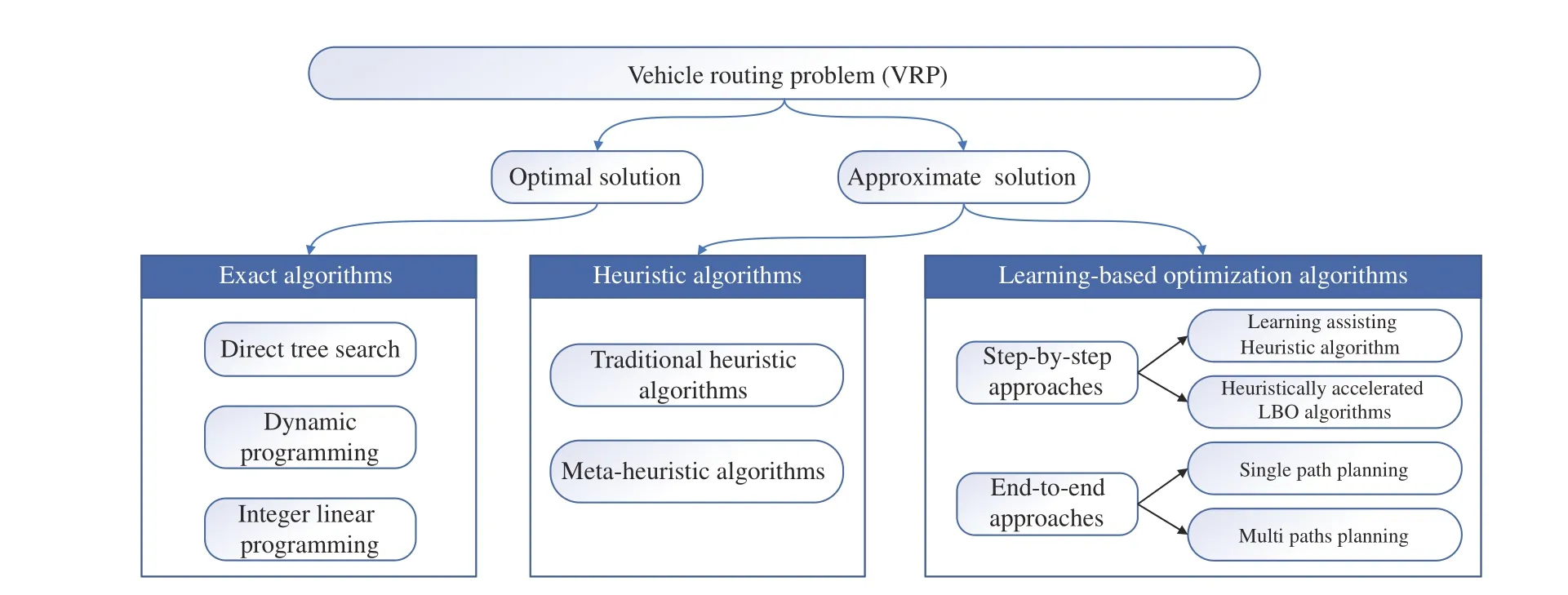
Fig. 1. Overall classification of the referred algorithms of the VRP.
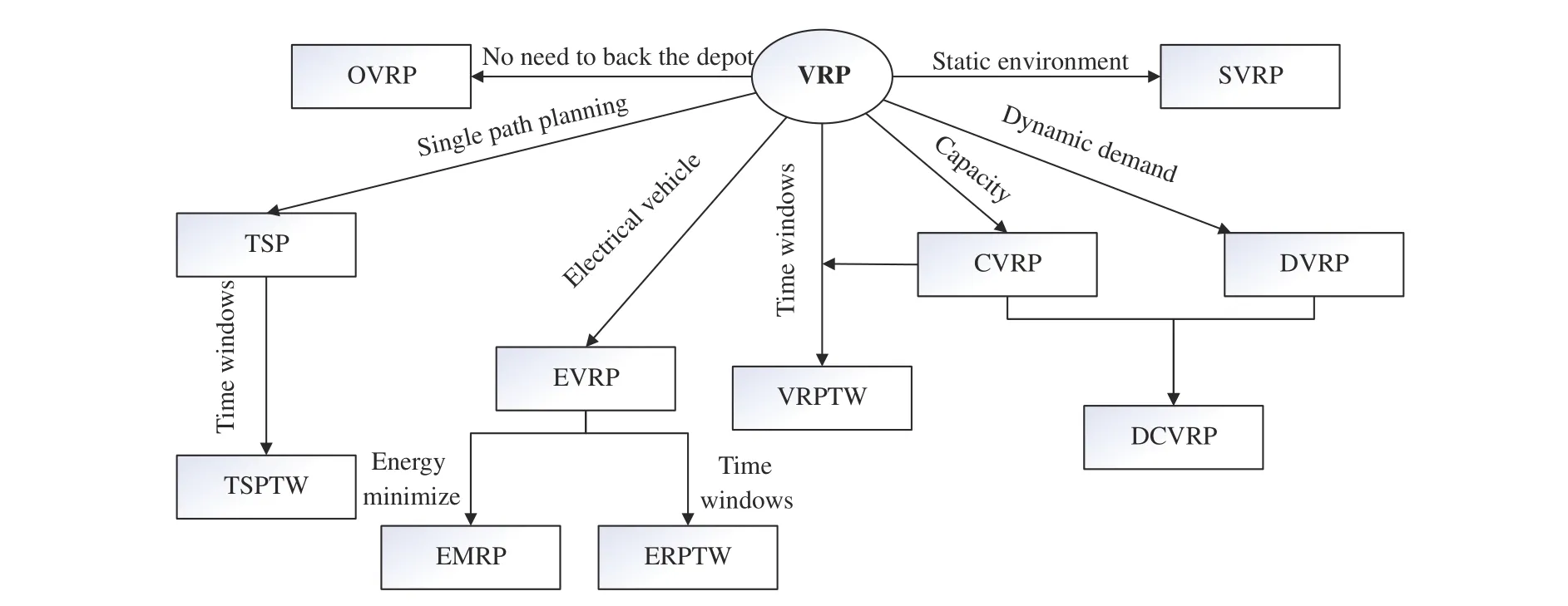
Fig. 2. Different variants of the VRP.
Fig. 3. Schematic diagram of the CVRP.
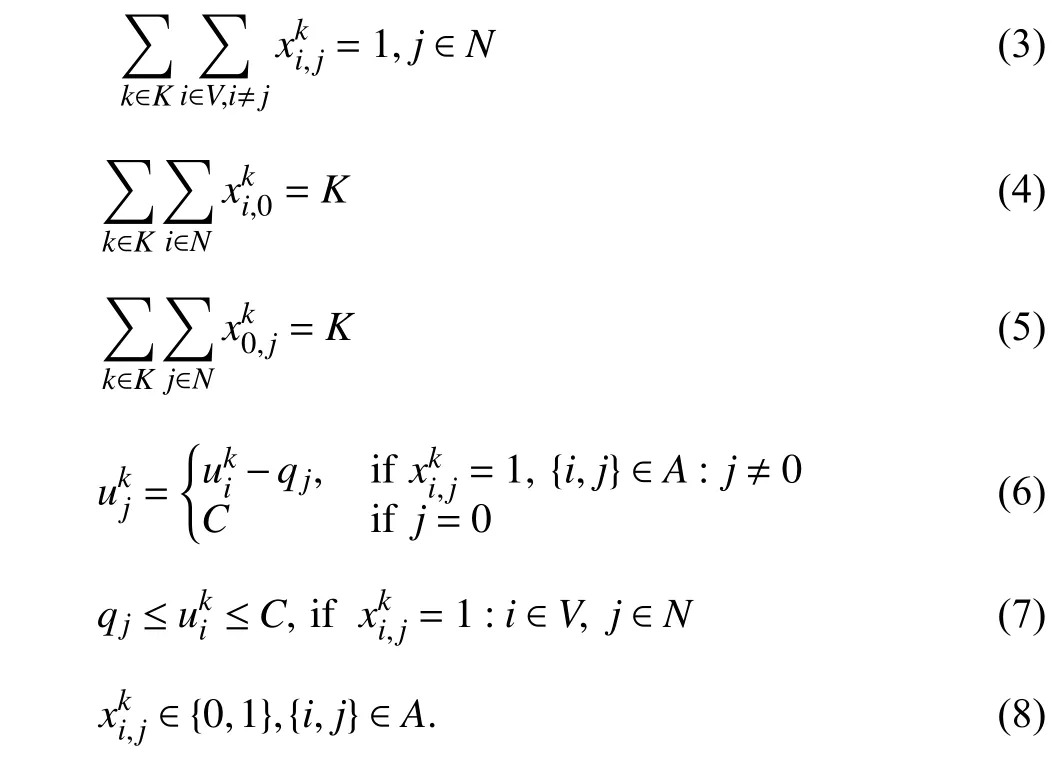
In this formulation, the objective is to minimize the total cost of transportation andci,jrepresents the cost of arc {i,j}.Equations (2) and (3) indicate that each customer can be served only once. Constraints (4) and (5) ensure that both the number of vehicles leaving the depot and returning to the depot should be equal to the total number of vehicles, which means that each vehicle should start from and end at the depot. Equation (6) shows the update process of the surplus capacity of the vehiclek, and constraint (7) ensures that the surplus capacity of the vehicle must not be less than the demand of its next customerjwhile does not exceed the maximum capacityC. Constraint (8) is used to ensure decision variableis a binary.
C. Traditional Optimization Algorithms for the VRP
Traditional optimization algorithms for solving the VRP include exact algorithms and heuristic algorithms. Fisher [34]divided the development of traditional algorithms applied to the VRP into three stages. The first stage is from 1959 to 1970, and simple heuristic algorithms were mainly used, such as the local heuristic and greedy algorithms; the second stage is from 1970 to 1980, and this stage primarily applied exact algorithms; the third stage is after 1980 and meta-heuristic algorithms began to be applied to VRPs. These traditional algorithms have been successfully used to solve different VRP variants [35].
1)Exact Algorithms:According to [36], exact algorithms for solving the VRP can be divided into three categories:direct tree search (such as the branch-and-bound algorithm[37]), dynamic programming [38], and integer linear programming (such as the column generation algorithm [39]).Many breakthroughs were achieved using exact algorithms in the 1970s. Christofides and Eilon [40] studied the CVRP and dynamic VRP (DVRP) by designing three approaches: a branch-and-bound approach, a saving approach, and a 3-optimal tour method. Christofideset al. [41] used tree search algorithms to solve the VRP. Although these exact algorithms are easy to understand, their computational expense is prohibitive in large-scale problems [42], [43].
2)Heuristic Algorithms:Heuristic algorithms can be divided into traditional heuristic algorithms and meta-heuristic algorithms. Referring to [44], traditional heuristic algorithms can be divided into constructive and two-stage heuristic algorithms. The former gradually generates feasible solutions to minimize costs (e.g., the savings algorithm [28]). The latter first clusters nodes and then constructs multiple feasible routes to satisfy constraints. The quality of the solution is improved by changing the positions of nodes between or within routes(e.g., [45]). Constructing the neighborhood of a solution is a significant part of heuristic algorithms. However, traditional heuristic algorithms perform an entire search without focus;therefore, they only explore neighborhoods in a limited manner. A meta-heuristic algorithm can focus on potential areas by combining intelligently complex search rules [46]and memory structures. As reported in [47], meta-heuristic algorithms generally produce better solutions than traditional heuristic algorithms (typically between 3% and 7%).
Although exact and heuristic algorithms have been developed for many years, they all have their own limitations.Both algorithms frequently require optimization expertise to model the problem and design effective search rules.Moreover, algorithms based on search frequently encounter the challenge of a trade-off between searching efficiency and solution accuracy when solving complex combinatorial optimization problems. This is apparent because finding an optimal solution comes at the expense of searching for a larger neighborhood and longer computational time. With the development of computer technology since 2010, the LBO algorithms have become a popular research topic and many breakthroughs have been obtained in using them to solve optimization problems. Along with the deepening of research on the VRP, it is necessary to design algorithms that can more rapidly and efficiently solve problems. Hence, the LBO algorithms are beginning to be applied to solve the VRP.
III. LEARNING-BASED OPTIMIZATION ALGORITHMS FOR THE VRP
From a technical point of view, the LBO algorithms usually include three kinds of learning modes [48], [49]. If the agent learns on data with labels, this training mode is called supervised learning (SL). In contrast, learning from unlabeled data is named unsupervised learning (UL). Note that UL is commonly used for the parameter optimization of continuous problems; therefore, it is rarely used in the literature reviewed in our paper. The final type of learning framework is reinforcement learning (RL), which requires the agent to learn from interacting with the environment. RL involves agents that sense the environment and learn to select optimal actions through trial and error [50], [51]. Compared with traditional optimization algorithms, the LBO algorithms have three advantages:
1) The LBO algorithms do not require substantial domain knowledge [52] for mathematical modeling and parameter tuning, which enables the LBO algorithms to model routing problems in a real-world more flexibly.
2) The LBO algorithms can automatically construct an empirical formula to approximate the mapping function between the inputs and solutions through pre-training on a dataset.
3) The LBO algorithms can automatically extract optimization knowledge from training data and give computers the ability to learn without being explicitly programmed [53].
The ability of autonomous and offline learning results in LBO models not requiring any hand-engineered reasoning and rapidly provides a promising solution for unknown data [52].The LBO algorithms have been applied to different fields[24], such as video games [54], Go [55], robotics control [56]and image identification [57]. Many studies have used the LBO algorithms for the VRP, and we divide related frameworks into two types: end-to-end and step-by-step approaches.
A. Step-by-Step Approaches
Step-by-step approaches learn optimization strategies that could iteratively improve a solution rather than outputting a final solution directly. These approaches can find a promising solution, but they have low time efficiency for training since their search space is more extensive. We subdivide this type of approaches into learning assisting heuristic and heuristically accelerated LBO algorithms according to different solving frameworks.
1)Learning Assisting Heuristic Algorithms:Heuristic algorithms use a series of operators to find the optimal solution [58]. During the search process, heuristic algorithms would generate considerable information about how to evolve and search in different stages [59], but this useful information is not comprehensively well utilized by heuristic algorithms.Hence, many studies have used the LBO algorithms as assistors to learn from this information and define the optimal setting of heuristic algorithms. Hence, we call algorithms of these studieslearning assisting heuristic algorithmsbecause they still search based on heuristic frameworks.
In their book in 1995, Gambardella and Dorigo [60] used Qlearning to construct the initial path for the ant system (AS).The LBO models in both papers of Limaet al. [61] and Alipouret al. [62] were also used as constructors of initial solutions for heuristic algorithms. Subsequently, many scholars used LBO models to assist heuristic algorithms from different aspects. Liu and Zeng [63] proposed an improved generic algorithm (GA) with RL called RMGA. They used RL model to determine whether to break the connection relation of the initial tour and used the GA to reselect the next city for the current city. Later, Phiboonbanakitet al. [64 ] used a transfer learning algorithm to aid the GA in dividing customers into regional clusters beforehand. Dinget al. [65]used the LBO models to predict the values of nodes for accelerating the convergence of solvers, and recently, Sunet al. [66] used the LBO model to quantify the likelihood of each edge belonging to an optimal route by the support vector machine (SVM). The LBO models can reduce the search space to simplify problems for heuristics, and all experiments demonstrated that these learning assisting heuristic approaches can significantly improve the performance of original heuristic algorithms and speed up the solving process.
In addition to using the LBO algorithms to assist heuristic algorithms in constructing the solution, the LBO algorithms can set parameters of heuristic algorithms. In 2017, Cooray and Rupasinghe [67] used the LBO model to set the mutation rate of the GA for the energy-minimized VRP (EMVRP).They experimented with GA with different mutation rates on instances and selected the optimal parameter settings that can produce minimal energy consumption. It has been proven that parameter tuning according to data characteristics has a significant effect on improving the applicability of the GA.Al-Duoliet al. [68] also used the LBO model to define the parameters values of a heuristic algorithm. Moreover, they used association rules trained using UL to provide an initial solution for the search.
The large neighborhood search (LNS) algorithm is a new heuristic algorithm that was first proposed by Shaw [69] in 1997. Compared with previous heuristics, this algorithm was based on the ruin-and-recreate principle [70] and would explore more complex neighborhoods. The LNS algorithms have outstanding performance in solving various transportation and scheduling problems [71]. Therefore, some scholars have considered using the LBO algorithms to improve the LNS algorithms. The learned LNS algorithm for the VRP was first used by Hottung and Tierney [72] for the CVRP and split delivery vehicle routing problem (SDVRP) in 2020 They adopted a LBO model as the repair operator for the LNS algorithm. Their model is limited by the number of destroyed fragments; hence, it ineffectively solves large-scale problems.Later, both Chenet al. [73] and Gaoet al. [74] used a LBO model as a destroy operator of the LNS algorithm to solve the VRP. Chenet al. [73] used the proximate policy optimization(PPO) algorithm to train a hierarchical recursive graph convolution network (GCN) as the destroy operator. Then,they simply inserted nodes removed by the destroy operator into the infeasible solution according to the principle of minimum cost. Experiments on Solomon benchmarks [75] and synthetic datasets demonstrated that the model of Chenet al.[73] performed better than the adaptive LNS (ALNS)algorithm in terms of solution quality and computational efficiency. Gaoet al. [74] considered the effect of graph topology on the solution, and they used an element-wise graph attention network with edge-embedding (EGATE) as an encoder in which both the node set and arc set contribute to the attention weights. They used a principle similar to that in[73] to repair the destroyed solution. Overall, using a LBO model as a destroy operator in the LNS algorithm is more beneficial for generating potential neighbor solutions than as a repair operator.
2)Heuristically Accelerated LBO Algorithms:Although using the LBO models as assistors can effectively improve the performance of heuristic algorithms, these heuristics still need to elicit knowledge from experts and encode it into the program, which is far from being easy in any applications.Hence, some studies proposed to replace knowledge-modeling in conventional algorithms and used heuristics as assistors of the LBO algorithms to search for solutions. We call these approachesheuristically accelerated LBO algorithms.
Reinaldoet al. [76] proposed a heuristically accelerated distributed deep Q-learning (HADQL) algorithm and compared their model with the ant colony optimization (ACO)algorithm and deep Q network (DQN) on TSP instances. The results indicated that the convergence of their model was fast,but their model required more computation time. Yanget al.[77] used the LBO algorithm to approximate the dynamic programming function, and their algorithm outperformed other well-known approximation algorithms on large-scale TSPs. Joe and Lau [78] used the LBO algorithm to compute the serving cost of each node, then they applied a simulated annealing (SA) algorithm to plan routes to minimize the total cost of the dynamic VRP with time windows and random requirements. Later, Delarueet al. [79] also used a LBO algorithm to compute the cost of nodes beforehand and their experiments demonstrated that their model achieved an average gap against the well-known solver OR-Tools of 1.7%on CVRPs. Yaoet al. [80 ] considered a real-life route planning problem. They regarded the safety of the planned route as one of the objectives and used RL to train the LBO model. They compared their model with EMLS and NSGA-II on a map of New York. Although their framework has good efficiency and optimality, it requires a large amount of time during training.
Chen and Tian [81] proposed a LBO model with a 2-opt algorithm as the search operator. The model selects a fragment of a solution to be improved according to the region-picking policy and uses the rule-picking policy to select a rewriting rule applicable to the region. Both policies are learnt by the LBO model, and the solution is iteratively rewritten continuously until it converges. Because this framework partially improves the solution, it is significantly affected by the initial solution. Luet al. [82] proposed an RL model incorporating several heuristic operators, called the L2I. If the cost reduction after improvement by heuristic operators does not reach the threshold, a random perturbation operator is applied and the operation begins again. Generally, [81] and[82] are similar because both include improvement and breaking during search process. Although they both obtained good experimental results, [82] generated more potential solutions than [81] because [82] designed a rich set of improvement and perturbation operators. Similar to [81],Costaet al. [83] and Wuet al. [84] used an LBO model as a policy network for the 2-opt operator. Reference [83] built an encoder-decoder framework based on the pointing mechanism[85]. Their greatest contribution was that they used different neural networks (NN) to embed node and edge information respectively, and proved that the consideration of edges has an important effect on solving the VRP. The difference in [84]from [81] is that they did not construct another LBO model to decide the rewritten region, and in [84] the nodes were embedded based on the self-attention mechanism before selecting node pairs to apply the 2-opt heuristic. Vlastelicaet al. [86] turned solvers into a component of the LBO model to search the optimal solution. They used the LBO model to embed a sequence of nodes into a matrix of pairwise distances to input the solver. Then they used the gap between the output of the solver and data label as a loss to optimize the LBO model. Later, Maet al. [87] modified the model of Wuet al.[84] by separating sequence embedding of the current solution from node embedding. Experimental results showed that their LBO model could capture the circularity and symmetry of VRP solutions more effectively. Although the above models could obtain better solutions for complex VRPs by making the use of an extensive heuristic search, they need a longer time to search.
In addition to incorporating heuristics as components of the LBO models, scholars have recently proposed to the use of the LBO algorithm to automatically select or generate heuristics,which can be considered as a type of hyper-heuristic algorithm. Hyper-heuristic algorithms have been used to solve the VRP in many studies [88]–[90]. This kind of algorithms does not search randomly and is guided by other high-level algorithms. Meignanet al. [91 ] first used a multi-agent modular model based on the agent metaheuristic framework(AMF) to build a selective hyper-heuristic framework for the CVRP and SDVRP. In their model, each agent builds an AMF model and selects low-level heuristics. RL and SL mechanisms are used by agents to learn from experience and other agents respectively. Later, Asta and Özcan [92] designed a hyper-heuristic algorithm based on apprenticeship learning to produce a new heuristic method for the VRPTW. The same LBO algorithm was used by Tyasnuritaet al. [93] to train the time delay neural network (TDNN) to solve the open vehicle routing problem (OVRP), which does not require vehicles to return to the depot. Moreover, some studies used the LBO algorithms to select heuristics. Both Kerschkeet al. [94] and Zhaoet al. [95] trained the LBO model as a selector to select the best algorithms for a given TSP instance. Gutierrez-Rodríguezet al. [96] constructed a multi-layer perceptron(MLP) to select the best meta-heuristic for solving the VRPTW, and Martinet al. [97] used LBO as a selector to select the best parameter settings for randomized Clarke Wright savings for CVRP. Using LBO models as selector of heuristics can leverage complementarity within a set of heuristics to achieve better performance.
B. End-to-End Approaches
End-to-end approaches learn a model to approximate a mapping function between the input (the features of the problem) and the output (the solution of the problem), and the model can directly output a feasible solution on unseen test tasks. The time efficiency for training end-to-end approaches is generally better compared to step-by-step approaches, but they currently encounter challenges in finding high quality solutions and scalability. According to the characteristic(whether the vehicle visits the depot multiple times) of problems which the approach is applied to, end-to-end approaches can be divided into single-path and multi-path planning approaches.
1)Single-Path Planning:In some VRP variants, the vehicle is not required to return to the depot, such as the TSP, and the LBO algorithms applied to this type of VRPs output a single path that connect all of nodes. Hence, we refer to these LBO algorithms assingle-path planning approaches.
Standard NNs rely on the assumption of independence among data points and fixed-length inputs and outputs, which is unacceptable for sequence-to-sequence problems [98].States of sequence-to-sequence problems are related in time or space, such as words from sentences and frames from a video.To overcome this shortcoming, recurrent neural networks(RNNs) were designed [99], and other RNN architectures,
long short-term memory(LSTM) [100] andbidirectional recurrent neural networks(BRNNs) [101] were also introduced for sequence learning in 1997. Later, many studies used these architectures in different sequence-to-sequence problems, such as natural language translation [102] and image captioning [103]. However, these models compress all the information of the encoder into a fixed-length context vector, which prevents the decoder from focusing on more important information when decoding. Hence, Vinyalset al.[85] introduced the attention mechanism [104] into the sequence model of [102] to enable the decoder to focus on important embeddings and called their modelPointer Net. The attention mechanism enables the LBO model to select the contexts that are most closely related to the current state as input. They trained an RNN with a non-parametric softmax layer using SL to predict the sequence of the cities. Although their end-to-end model can directly output the target point of the next step, it is not effective for a large-scale TSP. The experimental results also demonstrated thatPointer Netproduced better solutions when the number of nodes was less than 30, but performed poorly on TSP40 and TSP50.
Vinyalset al. [85] first proposed an end-to-end model for solving combinatorial optimization problems, but their research needs further improvement. Because SL is undesirable for NP-hard problems, Belloet al. [105]combined the RL algorithm withPointer Netto solve the TSP in 2016. They proved that their method was superior to that of Vinyalset al. [85 ] on TSP100. Levy and Wolf [106]transformedPointer Netto solve other sequence problems in addition to the TSP. They inputted two sequences to twoPointer Netsand used a convolution neural network (CNN) to output the alignment scores, which were subsequently converted into distribution vectors using a softmax layer.Later, Deudonet al. [107] used multiple attention layers and a feedforward layer as an encoder to simplifyPointer Net. Some studies have also extended the structure ofPointer Netto other single-path problems. Liet al. [108] usedPointer Netto solve the multi-objective TSPs (MOTSP). They first decomposed the multi-objective problem into a series of subproblems and then usedPointer Netto solve each subproblem. All sub-problems can be solved sequentially by transferring weights of the network, using the neighborhoodbased parameter-transfer strategy. Kaempfer and Wolf [109]added a leave-one-out pooling to extendPointer Netto solve the multiple TSP (MTSP), and Leet al. [110] trainedPointer Netusing RL to plan a route for cleaning robots. Maet al.[111] extendedPointer Netto solve the TSP. Reference [111]used a graph neural network (GNN) to encode distances of cities as context vectors of the attention mechanism, which is beneficial for solving a large-scale TSP. They also improved their model to a hierarchical framework to solve the TSP with time windows (TSPTW), in which they solved the vanilla TSP in the first level and solved the constraint of time windows in the high level.
AlthoughPointer Nethas been widely accepted to solve the TSP since its pioneering contribution, many scholars have proposed other end-to-end models to solve the TSP. As stated in [112], the mentioned neural architectures ofPointer Netcannot yet effectively reflect the graph structure of the TSP;therefore, Daiet al. [112] proposed incorporating a GNN to construct solutions incrementally for the TSP, which is named asStructure2vec(S2V) [113], where the embeddings of their model are updated continuously by adding new nodes into currently infeasible solutions. Later, Ottoniet al. [114] used a set of statistical techniques called the response surface model(RSM) to determine values of the learning rate and discount factor of the LBO algorithm. Although the experiments proved that using RSM can significantly improve the performance of the LBO model, their model needed to calculate optimal parameters per instance which limited the generalization of the model. To solve large-scale TSPs (up to 10000 nodes) within an acceptable runtime, Fuet al. [115]innovatively introduced a graphic transformation and heat map technique into an end-to-end model. They used graph sampling to abstract sub-graphs from the initial large graph,and the trained LBO model output the corresponding heat map(probability matrix over the edges). Finally, all the heat maps were merged into the final heat map, and the RL algorithm was used to output the optimal solution. The only limitation is that the model only experimented on simulation data but not on other benchmarks or real data. Zhanget al. [116] proposed an LBO approach for a kind of TSP that allows the vehicle to rejects orders, which was named the TSPTWR. They modified the model of Koolet al. [117] to output an initial solution for the TSP and then used a greedy algorithm to post-process the solution by rejecting the nodes that violate time windows.Compared with tabu search (TS), this method has a shorter solving time and better results. Because the decisions of endto-end approaches cannot be reversed, Xing and Tu [118]combined a GNN and Monte Carlo tree search (MCTS) to solve the TSP. In contrast to previous LBO models that directly made a decision by using a prior probability generated by training, they used MCTS to further improve the decision.Although their model outperforms previous LBO models in test sets of any size, the solving time is much longer.
Groshevet al. [119] and Joshiet al. [120] trained a GCN by SL to solve the TSP. What’s more, [119] further expanded their model by using a trained GCN to guide heuristic algorithms to output solutions and then used these solutions as labels to retrain the GCN for large-scale TSPs. Prateset al.[121] also used SL to train an LBO model. They considered the edge weights as features per instance, and that the deviation of their solutions from the optimal can be less than 2%. Previous LBO models are usually trained and tested on Euclidean space, which makes these models unavailable in instances where nodes are not uniformly distributed.Consequently, Sultanaet al. [122] tested their model in a non-Euclidean space. Although above LBO models trained by SL require fewer samples compared with those LBO models trained by RL, the optimal solutions that are selected as labels have a significant influence on the performance of the models.Joshiet al. [123] performed controlled experiments between the RL model [117] and SL model [120], and they also proved that the RL model has better generalization.
2)Multi-Path Planning Approaches:Most routing problems are limited by different constraints due to the complex environment. In these VRPs, the LBO algorithms need to output multiple path loops since vehicles need return to the depot more than once. We termed these LBO algorithms asmulti-path planning approaches.
To the best of our knowledge, Nazariet al. [124] first proposed an end-to-end approach to solve the CVRP. They believed that the order of inputs is meaningless; thus, they expandedPointer Netby utilizing element-wise projections to map static elements (coordinates of nodes) and dynamic elements (demands of nodes) into a high-dimensional input.The dynamic input is directly fed into the attention mechanism and not complexly computed using an RNN; thus,their model is easier to update embeddings while constructing the solution compared withPointer Net. The optimality of the model was proved by Ibrahimet al. [125] by comparing it with column generation and OR-Tools on different instances.Later, Koolet al. [117 ] introduced a multi-attention mechanism to pass weighted information among different nodes out of consideration for the influence of adjacent structures on solutions. This attention mechanism enables nodes to capture more information from their own neighborhoods;hence, their encoder can learn more useful knowledge to obtain better solutions.
Both Nazariet al. [124] and Koolet al. [117] laid the research foundation for the follow-up development of the VRP. Therefore, many scholars either extended their models to solve VRP variants or modified them to obtain better solutions. Penget al. [126 ] considered that node features should be constantly updated during the solving process.Therefore, they built a dynamic attention mechanism model(AM-D) by recoding embeddings at each step. Compared with Koolet al. [117 ], the performance of AM-D is notably improved for VRP20 (2.02%), VRP50 (2.01%) and VRP100(2.55%). Based on the model of Nazariet al. [124], Duanet al. [127] added a classification decoder based on MLP to classify edges. The decoder of Nazariet al. [124] was used to output a sequence of nodes, while Duanet al. [127] used this sequence as labels to train another classification decoder for the final solutions. This type of joint training approach outperforms other existing LBO models in solving large-scale CVRP by approximately 5%. Vera and Abad [128] used one more encoder than Koolet al. [117 ] to embed vehicle information for the capacitated multi-vehicle routing problem(CMVRP) with a fixed fleet size. The VRPTW has also been widely studied, and the work of Falkner and Schmidt-Thieme[129] can be considered the first extension of Koolet al. [117]to solve the VRPTW. They employed two additional encoders to embed current tours and vehicles for solving large-scale CVRP and produce a comprehensive context for the decoder.Their decoder would concurrently select the visiting node and the serving vehicle. Their model exhibits strong results on solving VRPTWs, even outperforming OR-Tools.
In the past two years, there has been an increase in the publication of papers that design end-to-end models for multipath problems. Similar to Penget al. [126], in 2020, Xinet al.[130] proposed the dynamic update of embeddings before decoding. However, they considered the computational complexity of the model; they changed the attention weight of the visited nodes in the top layer of the encoder instead of reembedding. In 2021, Xinet al. [131 ] proposed another approach to expand the model of [117] by using a multidecoder with different parameters to train multiple policies and select the best one to decode at each step. Experiments indicated that these innovations are useful in improving the original LBO model. Zhanget al. [132] used the model of Koolet al. [117] to solve multi-vehicle routing problems with soft time windows (MVRPSTW). They considered vehicles as multi-agents, where all agents share one encoder but use different decoders. Zhaoet al. [133 ] modified the model proposed by Nazariet al. [124] by using a routing simulator to generate data and update both the dynamic state and mask for the CVRP and the VRPTW. Furthermore, they applied a local search to improve solutions of the LBO model, and they demonstrated that combining the LBO algorithms and heuristic search can be a general method of solving combinatorial problems. In contrast to previous LBO models,which are based on the standard policy gradient method,Sultanaet al. [134 ] first proposed adding an entropy regularization term to encourage exploration in solving VRPs,thereby avoiding the limitation that the LBO model can easily converge too rapidly to a poor solution. They experimentally demonstrated that the policy with the highest entropy found a satisfactory solution more easily. Droriet al. [135]transformed the structure of the VRP into a line graph by defining each edge in the primal graph corresponding to a node in the line graph, and computed edge weights as node features. To effectively solve dynamic and stochastic VRP(DS-VRP), Bonoet al. [136] proposed a multi-agent model by adding two attention networks based on [117] to encode vehicle’s features and make a last decision. Their model presented favorable results for small-scale DS-CVRP and DSCVRPTW compared with OR-Tools. However, the model exhibited poor generalization when testing on deterministic CVRPs and CVRPTWs. Linet al. [137] incorporated the model of Nazariet al. [124] with a graph embedding layer to solve the electric vehicle routing problem with time windows(EVRPTW). They trained the model using the modified REINFORCE algorithm proposed by Koolet al. [117], but the maximum number of nodes in the test instance only went up to 100. Recently, Liet al. [138] modified the model proposed by Koolet al. [117] to solve the pickup and delivery problem(PDP), which has priority constraints and specific pairing relations. To learn complex relations and precedence among nodes of different roles, they added another six types of attention mechanisms based on the original attention mechanism. Later, focused on the fact that most end-to-end approaches are designed for homogeneous vehicle fleets, Liet al. [139] proposed adding a vehicle decoder to minimize the travel time among all heterogeneous vehicles based on the model of Koolet al. [117]. Their LBO model would select both a serving vehicle and a visiting node rather than solely selecting the next node to visit at each step.
Many scholars have proposed other novel end-to-end frameworks for VRPs with different objectives. Liet al. [140]and Jameset al. [141] proposed a model to plan online vehicle routes to minimize computation time. The differences between the two papers lie in the architecture and problem background.Liet al. [140] first used an LSTM network to predict future traffic conditions and then used a double-reward value iterative network to make decisions. However, Jameset al.[141] planned routes by improvingPointer Net[85 ]. In addition, Liet al. [140] trained their model on the data of 400 000 taxi trajectories in Beijing, whereas Jameset al. [141]applied to the green logistics system and trained their model on the traffic data of Cologne, Germany. Balajiet al. [142]combined a distributed prioritized experience reply [143] with DQN to maximize the total reward of the VRP. Although DQN is widely used in LBO models, it requires a significant amount of time to converge because the information update lag of the experience replay. With respect to this limitation,Mukhutdinovet al. [144 ] proposed using SL to generate preliminary Q values for nodes and they applied this approach to minimize the cost of the packet routing problem. Ramachandranpillaiet al. [145] designed an adaptive extended spiking neural P system with potentials (ATSNPS) to determine the shortest solutions for the VRPTW. They experimented on supermarket chain instances and demonstrated that their model can obtain better solutions. Shenget al. [146] used the principle of maximizing the total benefit and introduced global attention [147] to modifyPointer Net[85] to solve the VRP with task priority and limited resources (VRPTPLR).Caoet al. [148] first used the RL model to solve the stochastic shortest path (SSP) problem requiring an on-time arrival.They used the Q-value to represent the probability of arriving on time and set the discount factor of reward as 1 to maximize the probability of arriving on time. Chenet al. [149] built an LBO model for an autonomous vehicle fleet and postprocessed routes for minimizing the energy cost of the entire fleet. However, the environment of their model was too idealistic, and they did not consider the dynamics in the real world.
In addition to designing models for the VRP with a single objective, some studies were aimed at achieving multiple objectives simultaneously, which is difficult for traditional algorithms. To minimize driving time and route length,Kalakantiet al. [150] proposed a framework with two stages,which included clustering by heuristics and route planning by Q-learning. However, experiments on three VRP variants demonstrated that their model performed poorly in a stochastic setting. To minimize the tour length and cost of the ride-sharing field, Holleret al. [151] used a MLP to compute the pooling weights and selected action based on the pooling mechanism. They used the DQN and PPO algorithm to train the LBO model respectively, and experiments demonstrated that DQN is more efficient.
C. Analysis of Literatures
As we indicated previously, many papers using the LBO algorithms to solve different VRP variants have been published (Fig. 4). 14 and 25 relevant papers were published,respectively, in 2019 and 2020. As we can observe, there has been a rapid expansion in this field over the last two years.This is primarily because of the following reasons: 1) An increasing number of scholars have proven that the LBO algorithm is competitive in solving combinatorial optimization problems; 2) With the development of economic globalization, transportation efficiency has become a key factor affecting company profits; 3) Recent VRP studies have been characterized by large-scale online planning and complex constraints. These factors significantly promote the LBO algorithms in solving the VRP. Another aspect worth noting in Fig. 4 is that scholars tended to use step-by-step approaches in the initial research phase of the field. However, they preferred end-to-end approaches after 2017, which is primarily owed to the success achieved by Alpha GO. However, with recent indepth research using the LBO algorithms for the VRP, much of the literature has demonstrated that combining the LBO model with other algorithms is more effective for complex optimization problems. Hence, the research on step-by-step methods has been revived.
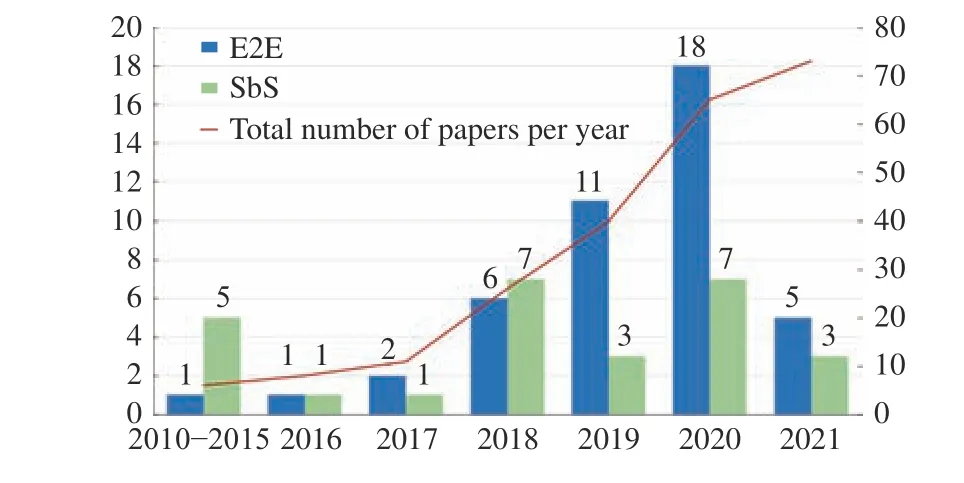
Fig. 4. Distribution of published papers per year for the VRP (the deadline for statistical data in 2021 is September).
As shown in the pie chart on the right of Fig. 5, most of studies focus on the TSP (approximately 41%). As a widely studied variants of the VRP, the TSP is a basic graph problem;therefore, scholars tend to test a new model on the TSP and then extend the model to other VRP variants. The second widely studied variant is the CVRP (approximately 27%),which has a simple mathematical model but strong flexibility.Both the CVRP and TSP primarily focus on minimizing the tour length; hence, length is the most studied objective among the distribution in the objectives of current literature(approximately 75.7%, Fig. 6 ). Note that the sum of percentages in Fig. 6 is greater than 1 because some studies are multi-objective.
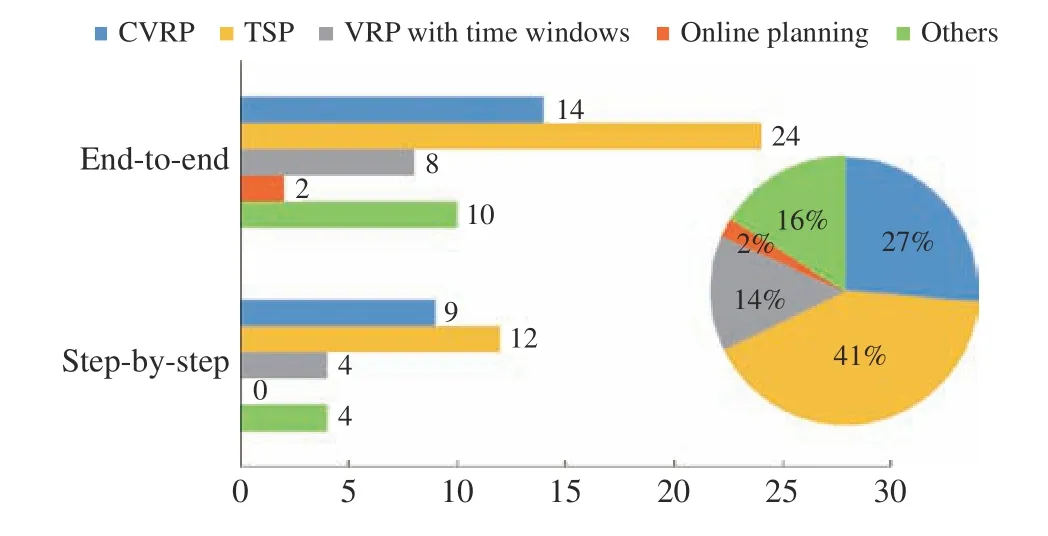
Fig. 5. Distribution of different variants.
We summarize the characteristics of different VRP problems by synthesizing and analyzing the referenced papers.The four evaluation indicators are described as follows.
i)High-complexity:High-complexity refers to VRPs with multiple constraints or objectives, and we quantifiably represent the practicability of an LBO model by the complexity of its application problem because the VRP in the real world often has multiple constraints or objectives. In this paper, we consider that problems with two or more objectives or constraints are high complexity. For example, the TSPTW with rejection solved by Zhanget al. [116] needs to minimize the tour length and the rejection rate; the VRP solved by Bonoet al. [136] requires time windows and stochastic demands to be satisfied simultaneously. We considered that the above problems are complex, and we compared the number of studies of two class approaches applied to complex problems.We observed that step-by-step approaches are more likely to be selected for problems with high-complexity.
Fig. 6. Distribution of objective functions.
ii)Stochastic:We define the VRPs whose customer’s demands, time windows or other uncertain elements follow some probability distribution models as stochastic problems.For example, Balajiet al. [142] considered a VRP variant of on-demand delivery, whose orders were generated with a constant probability; Joe and Lau [78] considered a real-time VRP in urban logistics in which customers and orders were randomly added or cancelled. Step-by-step approaches have limitations in solving stochastic VRPs since this type of LBO algorithms needs customers and travel costs to be known in advance and has a longer solving time. Compared with stepby-step approaches, end-to-end approaches have the advantages of flexibility and time efficiency under stochastic environments, which can quickly respond to changes by utilizing knowledge extracted from past training experience.
iii)Timeliness:Timeliness refers to those VRPs that require planning a tour with the least time, which is a significant characteristic of real-world VRPs. We consider problems that use LBO approaches to minimize tour time, such as in [141].Overall, end-to-end approaches are easily used for problems with timeliness because of their quick solution speed.
iv)Fuzzy:With the development of the VRP, many new VRP variants have been proposed. We use fuzzy methods to define these new problems because researchers do not have much expertise in these problems. The more likely it is that the LBO approaches is used to solve new problems indicates,the more likely it has a more generic modeling framework.More fuzzy problems are solved by end-to-end approaches among the included literature as the learning process of these approaches does not require abundant domain knowledge.
Generally, end-to-end approaches are suitable for VRPs with stochastic or time requirements; step-by-step approaches can solve more complex problems effectively.
In addition to analyzing the applied problems of the LBO algorithms, it is interesting to compare their models. The previous review clearly indicates that many studies used the encoder-decoder framework; therefore, we compared these encoder-decoder models (see Table I, where MHA refers to the multi-head attention layers and FF refers to the feedforward network). We observed that the encoder-decoder framework is more commonly used in end-to-end approaches,and most differences of frameworks are in the encoder. This is probably due to the fact that if scholars require different information, they must use different NNs to extract related features from the input. If authors seek to incorporate more features in addition to the node coordinates and demands, they often consider the GCN as a good option. Conversely, there are two main types of decoders: RNN with a pointing mechanism (PM) (Vinyalset al. [85]) and a decoder with several multi-head attention sublayers (MHA) (Koolet al.[117]). In terms of learning manners, Vinyalset al. [85] used SL to train the model, whereas all the others used RL. This is expected because the VRP is an NP-hard problem, and it is difficult to obtain labels for training data. We also present an overview of the LBO architectures in Fig. 7. We first classify NN models according to training algorithms. Then, we make a list where we solve problems of different structures together with the corresponding literature and their publication time.
To clearly compare the literature, we list the main content of the referenced papers, including model features, baselines,and benchmarks in experiments at the end of the paper. For convenience, we abbreviate end-to-end approaches as E2E and step-by-step approaches as SbS in this table. Benchmarks can frequently be divided into simulation data and data from the literature or the real world; we refer to the latter collectively as real data.
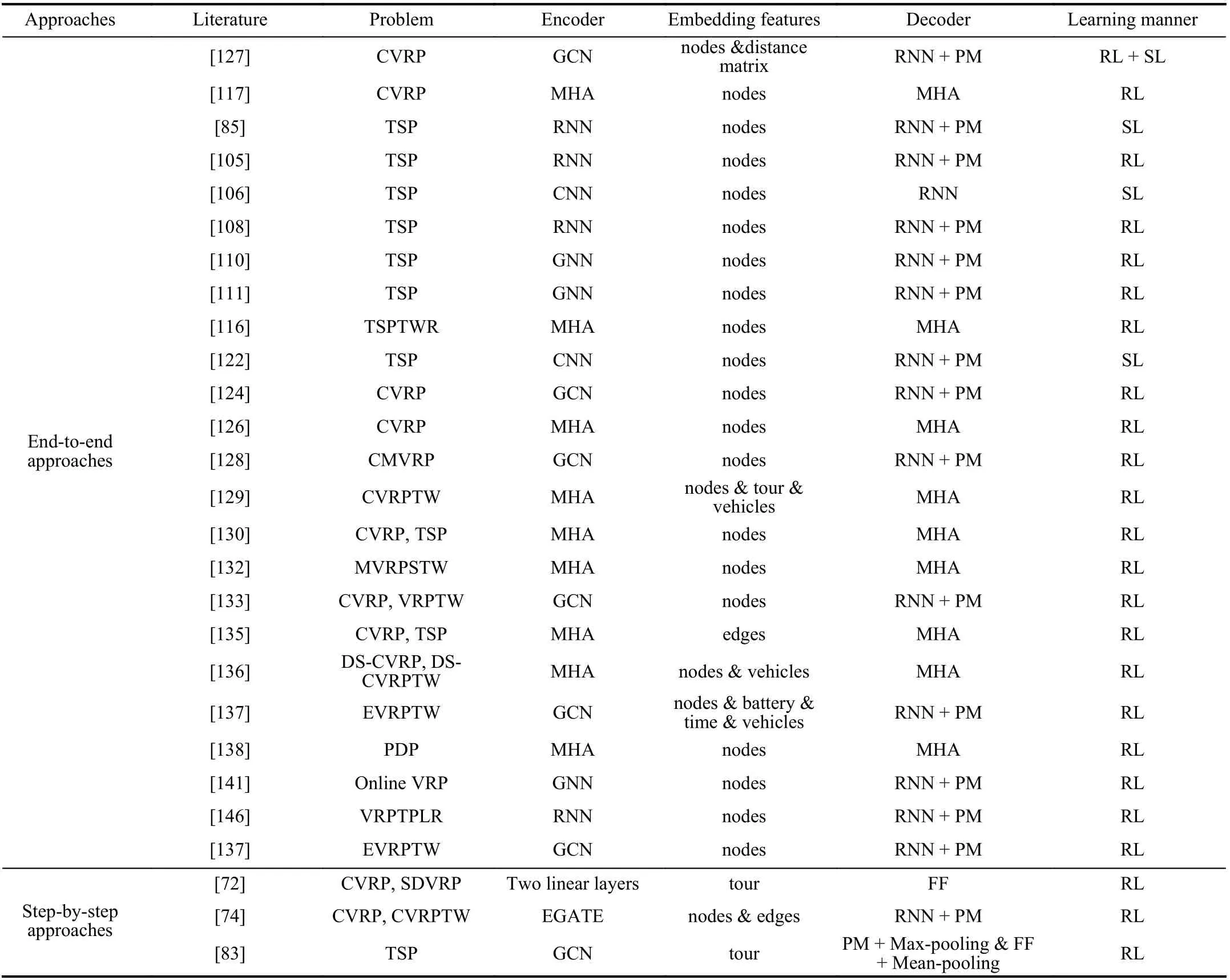
TABLE I COMPARISON OF ENCODER-DECODER FRAMEWORKS AMONG REFERRED MODELS
IV. EXPERIMENTAL STUDY
A. Experimental Setting
1)Experimental Algorithms:As described in Section III, the research of Luet al. [82] (L2I) and Chen and Tian [81](Rewriter) are the recent research trends of step-by-step approaches, and both papers are also among the most cited step-by-step approaches. Koolet al. [117 ] (AM) made a significant contribution to solving the VRP by using an endto-end framework. Many studies have modified the model of Koolet al. [117 ], and the model of Xinet al. [130](ASWTAM), proposed in 2020, is one of the representatives.ASWTAM designs a step-wise update embedding mechanism,which is beneficial for the original AM model as it helps it focus on useful inputs and determine the optimal solution. To analyze the characteristics and limitations of different LBO models, we test these four representative LBO algorithms on different sizes of instances, and we compare them with other algorithms in this section. We select three classical metaheuristics (ACO, TS and LNS), and two well-known solvers(Gurobi and OR-Tools) as baseline algorithms. The best parameters of different scales of the problems are determined through multiple experiments. To limit the total time expended when solving the problem, we modify the time limit parameter of Gurobi to 1800 seconds.
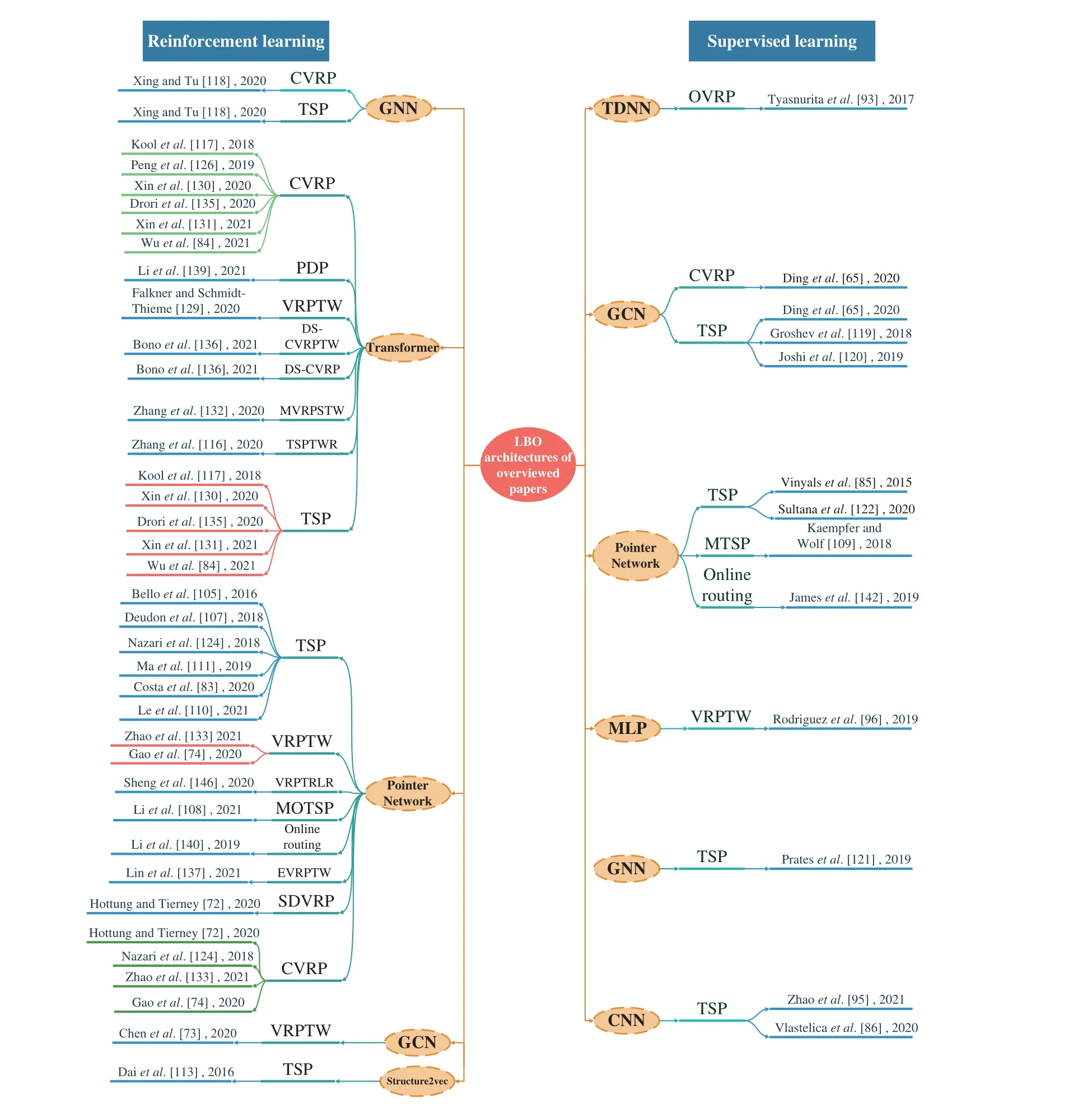
Fig. 7. Overview of LBO architecture of overviewed papers ([152]).
2)Problem Details:We evaluate four LBO models and baseline algorithms on the CVRP of different scales, and we do not distinguish the CVRP and VRP in this section.
3)Data Generation:
i)Training set:We consider three training instances, the Euclidean VRP with 20, 50, and 100 nodes, named VRP20,VRP50, and VRP100, respectively. For all tasks, the location of each customer and the depot are uniformly sampled in the unit square [0, 1]2, and the demand of each customer is also uniformly sampled from the discrete set {1, 2, …, 9}. The capacities of a vehicle are 30, 40, and 50 forN= 20, 50, and 100, respectively.
ii)Test set:We test different algorithms using three types of test data: a) Set 1, following the same rules as the training set,we newly generate 300 instances for the three-scale VRP. b)Set 2 also contains 300 VRP instances withn= 20, 50, and 100, but the locations of the nodes are sampled from the gamma distribution (α= 1,β= 0). c) Set 3 contains nine benchmarks from Subramanianet al. [153 ], whose nodes ranged from 100 to 200.
4)Hyperparameters Setting:The hyperparameters of the selected LBO models are the same as those in the literature to ensure the validity of the experimental results as much as possible. We set the random seed at 1234 to ensure the consistency of training data, and we set the batch size during testing to 1 to better compare the running time. Table II lists the other hyperparameters of the training model. We conduct all the experiments on Python software on a computer with a Core i7-9800x 3.8-GHz CPU, 16 GB memory, Windows 10 operation system, and a single 2080Ti GPU.
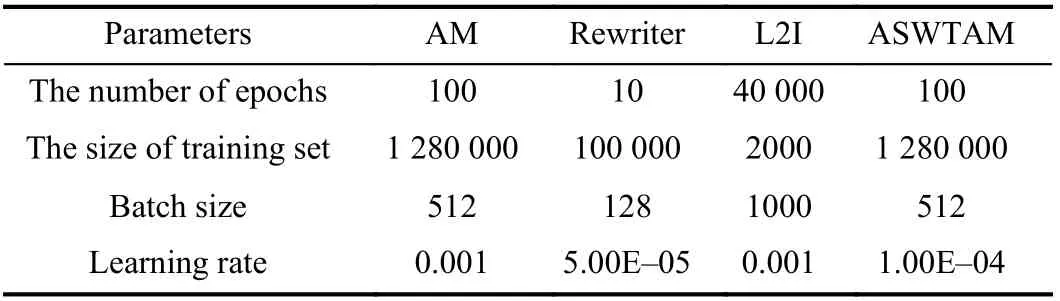
TABLE II THE HYPERPARAMETERS OF LBO MODELS
5)Evaluation Metrics:To better evaluate LBO models, we use multiple evaluation metrics that are widely used in the RL research community [25], [142]. In addition, since each type of VRP in sets 1 and 2 only contains 300 instances, we use the Wilcoxon signed-rank test and Friedman test on test results to infer the holistic performance of different LBO models.
i) Training time and occupy memory.
ii) Length of solutions, optimal gap, and solving time in perinstance.
iii) Rank obtained by Friedman test andp-value obtained from the Wilcoxon test.
6)Experimental Design:
To fully evaluate the effect of LBO models, we compare the experimental algorithms from three aspects: time efficiency,scalability, and optimality. The comparison experiments can be divided into three parts:
Part I:To validate the learning effectiveness of the LBO models, we train the LBO models on the training set and compare the training time, occupied memory, and learning curves among the LBO models.
Part II:To validate the time efficiency and optimality of the LBO models, we test algorithms on sets 1 and 2 and compare the solution length, solving time, and standard deviation. In addition, we use the Wilcoxon signed-rank test and Friedman test to analyze statistical results in depth.
Part III:To validate the scalability of LBO models to larger problems, we test LBO models trained on VRP20 on set 3.We use the solution length, solving time, and optimal gap as evaluation indicators.
B. Results and Analysis
1)Comparison and Discussion of Part I:We compared the training time (in hours) of the four LBO models on VRP20,VRP50, and VRP100. The left bar chart of Fig. 8 shows that end-to-end approaches frequently requires less training time than step-by-step approaches. AM requires the least training time, whereas Rewriter requires the most training time. This is primarily because these step-by-step approaches must be combined with heuristic search to determine optimal solutions; therefore, they require more time to constantly experience the circulation of generation, evaluation, and evolution during training. While end-to-end approaches use NNs to replace this complex circulation, they can cost less time to learn. Comparing Rewriter with L2I, although Rewriter uses only 2-opt to generate neighborhood solutions and L2I uses six heuristics, the training size of Rewriter is approximately 50 times than that of L2I. Therefore, Rewriter requires more time than L2I. Comparing two end-to-end approaches, ASWTAM costs longer training time since it needs to update embeddings at each step.
We also recorded the occupied memory of the LBO models during training (right bar chart of Fig. 8), and we observed that step-by-step approaches require less memory than end-toend approaches; e.g., L2I requires only approximately 1.2892 GB on VRP100 and ASWTAM requires 9.07 GB. This result reveals that end-to-end approaches can fully utilize advanced computing hardware to reduce training time but requires the computer to have a large amount of memory to store sizable data generated by parallel computing. In addition, we observed that LBO models require more memory as the size of the problem increases. This is apparent because a largescale VRP has high input dimensions, and solving it requires deeper NNs with more parameters. However, the problem size remains a challenge for the LBO algorithms to settle because of the curse of dimensionality and the limitations in computational resources. Comparing L2I with Rewriter,Rewriter requires more memory during training because it uses another policy network to select segments to be rewritten in addition to a rule-defining policy network. Similarly, we observed that ASWTAM requires more memory than AM.This is because ASWTAM requires step-wise update embeddings but the embeddings of AM are fixed.
We illustrated the comparison of learning curves in Fig. 9,and we defined the average solution length of samples of a batch as distance. The learning curve is an important index for evaluating the learning ability of an LBO model, and it can provide much information about the LBO model. The earlier the turning point of the curve tends to be stable, the fewer samples are required for model training. In addition, the distance in the training process predicts the optimization of the model on the training data, whereas a lower value indicates a better performance of the LBO model. Comparing the two approaches, we can conclude that step-by-step approaches can converge faster than end-to-end approaches.Among them, L2I has the best learning performance because its learning curve reaches the turning point earlier, which proves that using heuristics as search operators can effectively improve the learning effectiveness of LBO models. This also explains why step-by-step approaches require less training data than end-to-end approaches. In addition, we can speculate that there is a mutual promotion between LBO models and heuristic algorithms, but exceedingly few heuristics may reduce the learning ability of LBO models, similar to Rewriter. Additionally, note that the learning curve of ASWTAM is below the AM as the training progressed. This proves that the input features have an important influence on the learning ability of the model because ASWTAM modifies AM by dynamically updating the embeddings.
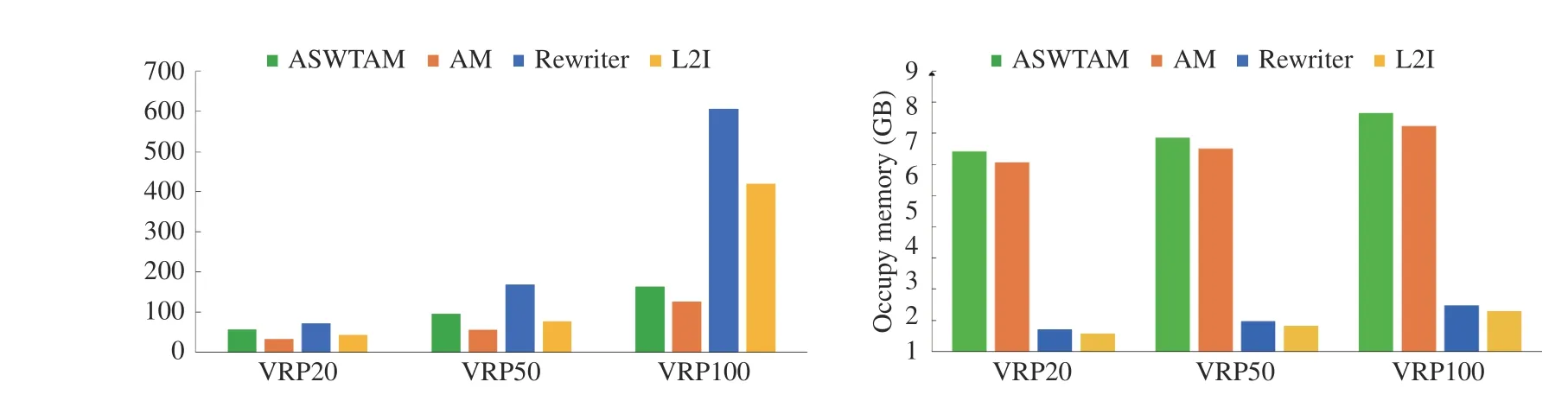
Fig. 8. Training time and occupy memory of LBO models on VRP20, VRP50, and VRP100.
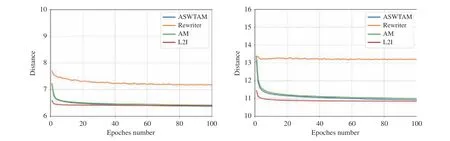
Fig. 9. Learning curves of LBO models on VRP20 and VRP50.
2)Comparison and Discussion of Part II:Tables III and IV show the optimization of the LBO algorithms on test sets 1 and 2, respectively. For the columns in Tables III and IV,column 1 shows the algorithms, and columns 2–4 respectively lists the average tour length (mean), standard deviation (std),and average solving time (time) used by each algorithm for instances withn= 20. Columns 5–7 and 8–10 respectively list the same information of experimental algorithms on the instances withn= 50 and 100. Note that we tested two types of search policies for AM for a comprehensive comparison.
First, the tables show that L2I has the minimum mean on testing instances except for VRP20, and its results are even better than those of OR-Tools. Furthermore, we observed that the standard deviations of L2I and Rewriter are always smaller than those of OR-Tools, LNS and ACO. These results indicate that incorporating the LBO algorithms within the heuristic search can result in a stable performance and strong generalization of the models. Several studies [107], [122],[133] have indicated this positive effect. Second, we observed that TS and LNS perform below ASWTAM and AM (greedy)in VRP50 and VRP100 on set 1, and ASWTAM is better than OR-Tools in VRP100. However, end-to-end approaches have disappointing performance on set 2, although their solutions are still better than that of ACO. Therefore, we can conclude that end-to-end approaches have a strong dependence on the distribution of data. In addition, comparing L2I to end-to-end approaches, although L2I outperforms ASWTAM and AM in terms of the quality of the solution, end-to-end approaches have an advantage in computational time, e.g., AM (greedy)requires only 0.93 s and ASWTAM requires 1.82 s on VRP100 from set 1, but L2I requires 25.25 s. Third, we observed that different search methods are applicable to different types of test data. Comparing Tables III and IV, we can conclude that the sampling search method outperforms the greedy search method on data obeying the gamma distribution, but the greedy search method can obtain better solutions for data obeying the same distribution as the training data. This is because the greedy search selects the best action at each step according to training experience, whereas the sampling search selects the best from many sampled solutions[111]. Hence, a greedy search is more dependent on the data distribution. Finally, comparing L2I with Rewriter, we observed that L2I has better optimization than Rewriter. Thus,more search operators are beneficial to searching for a larger solution space, and the optimal solution is more likely to be determined. However, note that an excessive number of heuristic operators result in the solving time of L2I being twice as that of Rewriter. We also compared two LBO models of end-to-end approaches and concluded that ASWTAM is better than AM in quality of solutions. ASWTAM adopts a dynamic embedding mechanism, and dynamic embedding aids the network in capturing the real-time characteristics of the environment.
To further illustrate the overall performance of the experimental algorithms across all test cases, we performed nonparametric tests on VRP20 from set 1 and 2, and the results are shown in Fig. 10 and Table V. Fig. 10 shows the results of the Freidman test and uses Freidman Rank as the abscissa. The smaller the rank value is, the better the algorithm performs in all instances. Table V shows the results of the Wilcoxon test and column 1 represents the tested algorithms. The Wilcoxon test first computes the difference between the two algorithms on a set of instances and then obtains the corresponding rank by sorting the absolute values of the differences. Column 2 of Table V summarizes the rank of the positive differences, and column 3 summarizes the rankof negative differences. The gap between the two sums represents the difference between the two algorithms, and thep-value in the final column is used to evaluate this difference quantitatively. Under the confidence degreeα= 0.05, apvalue greater than 0.05 means that there is no significant difference between the two algorithms.
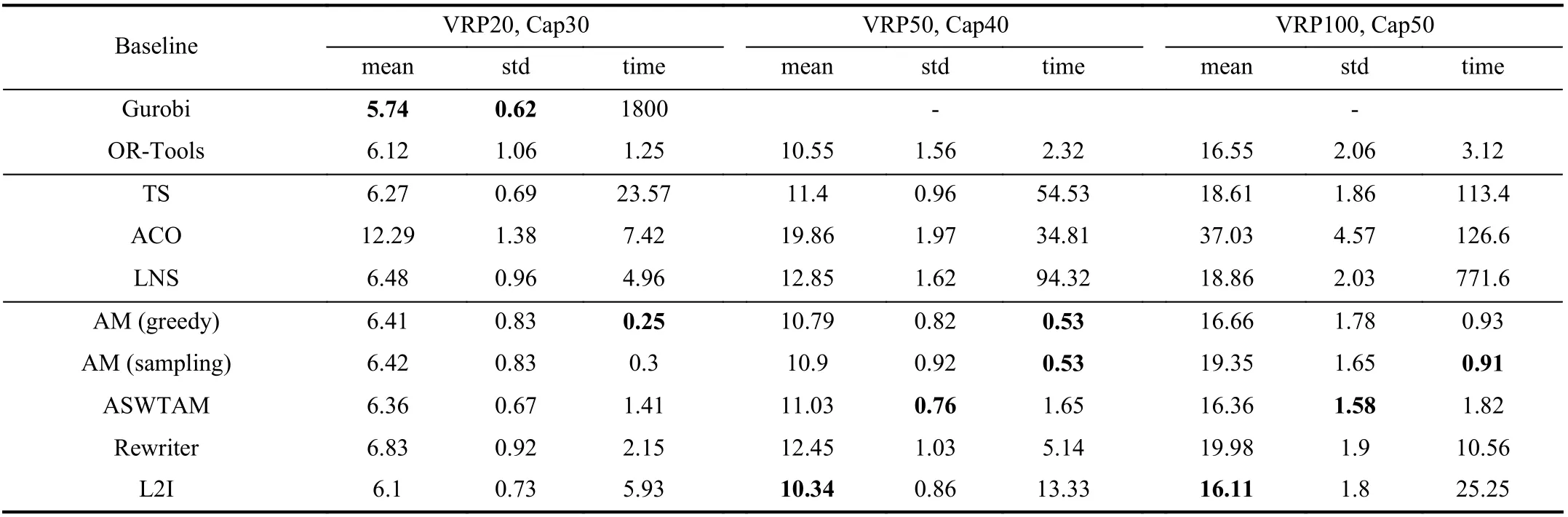
TABLE III COMPARISON OF AVERAGE VALUE AND SOLVING TIME (IN SECONDS) OF DIFFERENT ALGORITHMS ON DATASET 1
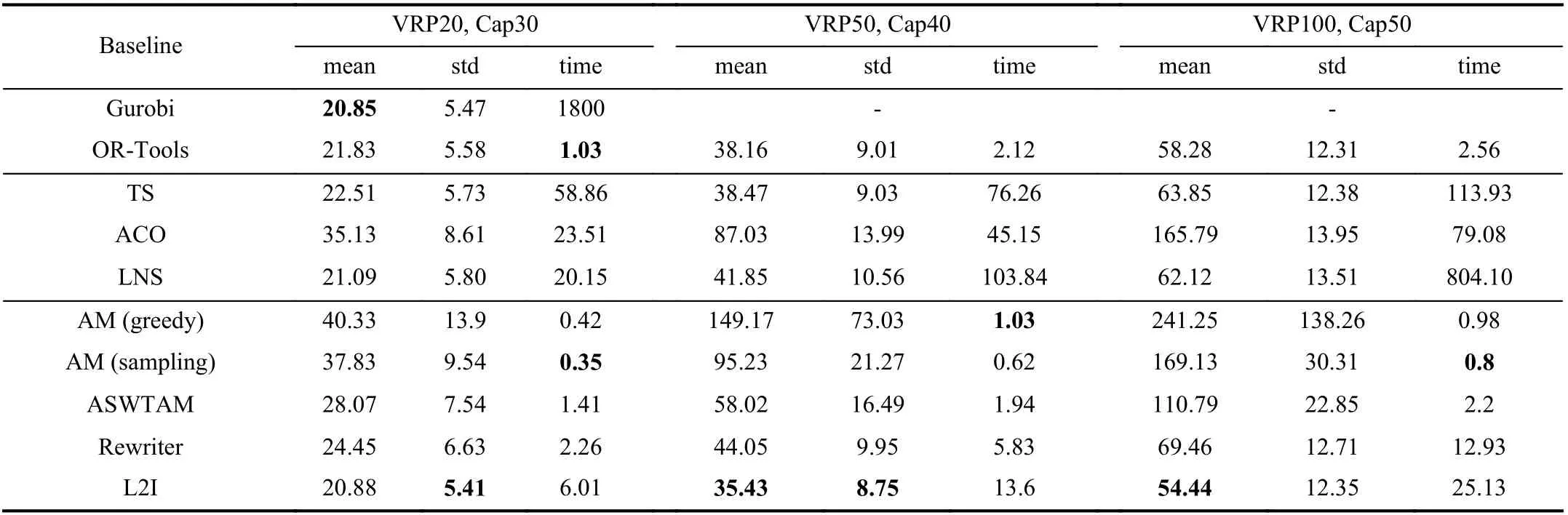
TABLE IV COMPARING AVERAGE VALUE AND SOLVING TIME (IN SECONDS) OF DIFFERENT ALGORITHMS ON DATA SET 2
From the Friedman test (in Fig. 10) on VRP20, we observed that L2I is second only to Gurobi in VRP20, and the results of the Wilcoxon test of the two algorithms in Table V indicates that L2I is not significantly different from Gurobi in VRP20 at a confidence coefficient of 0.05. Moreover, we observed that the performance of ASWTAM is not significantly different from AM on set 1, but AM is distinctly inferior to ASWTAM on dataset 2. This proves that AM is effectively improved by ASWTAM. It is worthy noting that thep-value of OR-Tools and L2I is 1 in set 2, although this value is 0.000002 in set 1.Similar results are observed in the comparison of the other three LBO models with OR-Tools, in which LBO models achievep-values >0.05 in set 1 but <0.05 in set 2. This indicates that LBO models have limitations when applied to the problem whose data distribution is different from the training set.
3)Comparison and Discussion of Part III:We trained LBO models on VRP20 and tested them on set 3 to verify the scalability of the LBO models, and we show the performance of the experimental algorithms in Table VI and Fig. 11. We selected only AM with a sampling search policy for testing.
Note that the solving time of all the algorithms increases as the scale of the problem increased, but the solving time of LBO is always significantly less than that of ACO and TS.The most time-consuming L2I is 33.08 s in instances with 195 nodes, whereas TS requires 319.98 s; the longest computational time of the end-to-end model is less than 7 s, which is significantly less than that of OR-Tools. Second, L2I has the best scalability on benchmarks, and the gap between L2I and the optimal does not exceed 0.1. However, L2I is still inferior to TS in X-n101-k25 and X-n186-k15. Moreover, as shown in Table VI and Fig. 11, models of end-to-end approaches are more unstable than the step-by-step approaches for large-scale problems. The maximum gap of AM is up to 5.99, but the minimum gap is only 0.83. However, compared with AM, the ASWTAM exhibits significant improvement, and it is better than Rewriter in X-n186-k15. In the other instances, the solutions of ASWTAM are always better than ACO and close to Rewriter. This indicates that end-to-end approaches are promising, and further research is required to achieve better improvement.
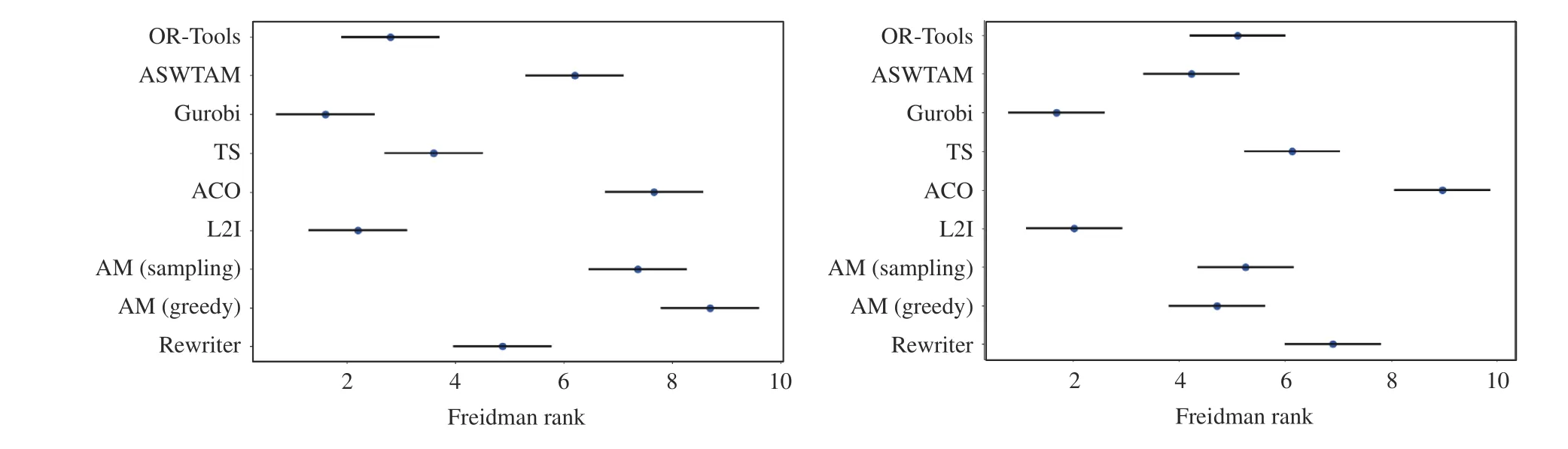
Fig. 10. Friedman test on VRP20 from different datasets (left from set 1, right from set 2).
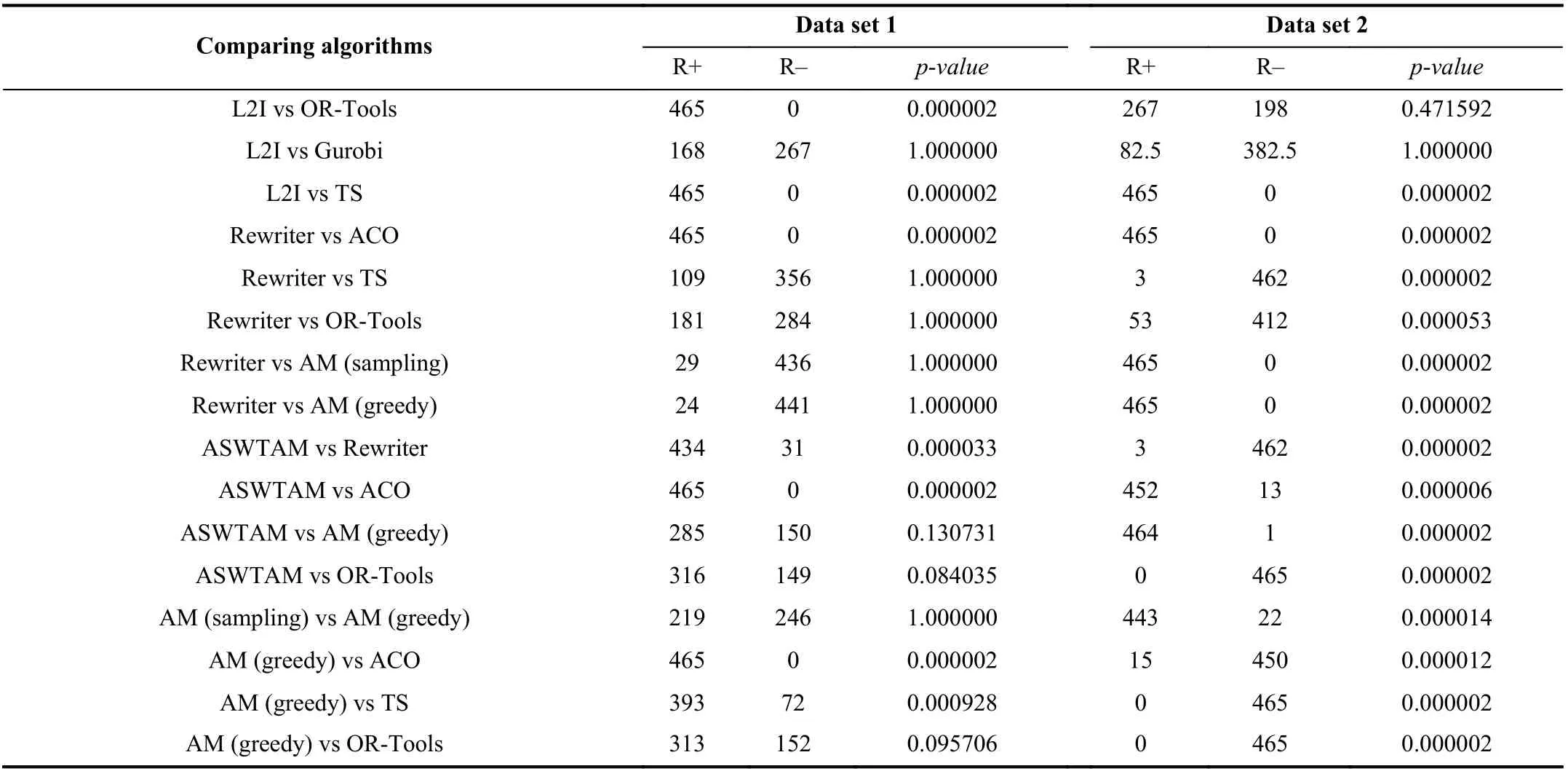
TABLE V WILCOXON TEST RESULTS AMONG DIFFERENT ALGORITHMS FOR α = 0.05 ON VRP20 FROM DIFFERENT DATE SET
4)Experiments Conclusion:To demonstrate the effectiveness of the LBO models, we tested AM, ASWTAM, Rewriter,and L2I on three datasets and compared the LBO approaches with ACO, TS, LNS, Gurobi, and OR-Tools. According to the results of the three experiments, the following conclusions can be drawn: i) Step-by-step approaches have faster convergence and better generalization than end-to-end approaches, but they require more computational time; ii) End-to-end approaches frequently have less computational time both during training and testing, but they require more computational resources;iii) Both approaches have limitations in the scale of problems and their performance is affected by data distribution; iv)Compared with conventional algorithms, LBO approaches require further improvements.
V. CONCLUSION AND RESEARCH TREND
The LBO algorithms have been successfully applied to a series of optimization problems, and studies on using these algorithms to solve the VRP can be divided into two types:end-to-end and step-by-step approaches. Exhaustive experiments demonstrate that step-by-step approaches have strong scalability but are not suitable for problems requiring solving time, whereas end-to-end approaches can rapidly solve problems but are more dependent on data distribution.
Using the LBO algorithms to solve the VRP is still under research. There are several challenges in the LBO algorithms that need to be settled in the future and we suggest several potential research directions of applying the LBO algorithms in the VRP from these limitations.
1) Solving sizable or more complex VRPs based on the decomposition framework.In 2014, Yao and Liu [154] had proposed that scaling up learning algorithms is an important problem. LBO models have difficulty in solving combinatorial optimization problems with high complexity or large scale,because these problems result in a curse of dimensionality and easy to overfit [155]. Liet al. [108] proposed to decompose a multi-objective VRP into a set of subproblems, and their results decomposing that their framework is better than NSGA-II in problems with five objectives; Fuet al. [115] alsodecomposed a sizable TSP into multiple small-scale subproblems and solved each of them using the SL model, and effectively solved the TSP with 10 000 nodes. Hence, decomposing complex or sizable problems to multiple simple subproblems and solving them seems to be a feasible approach.
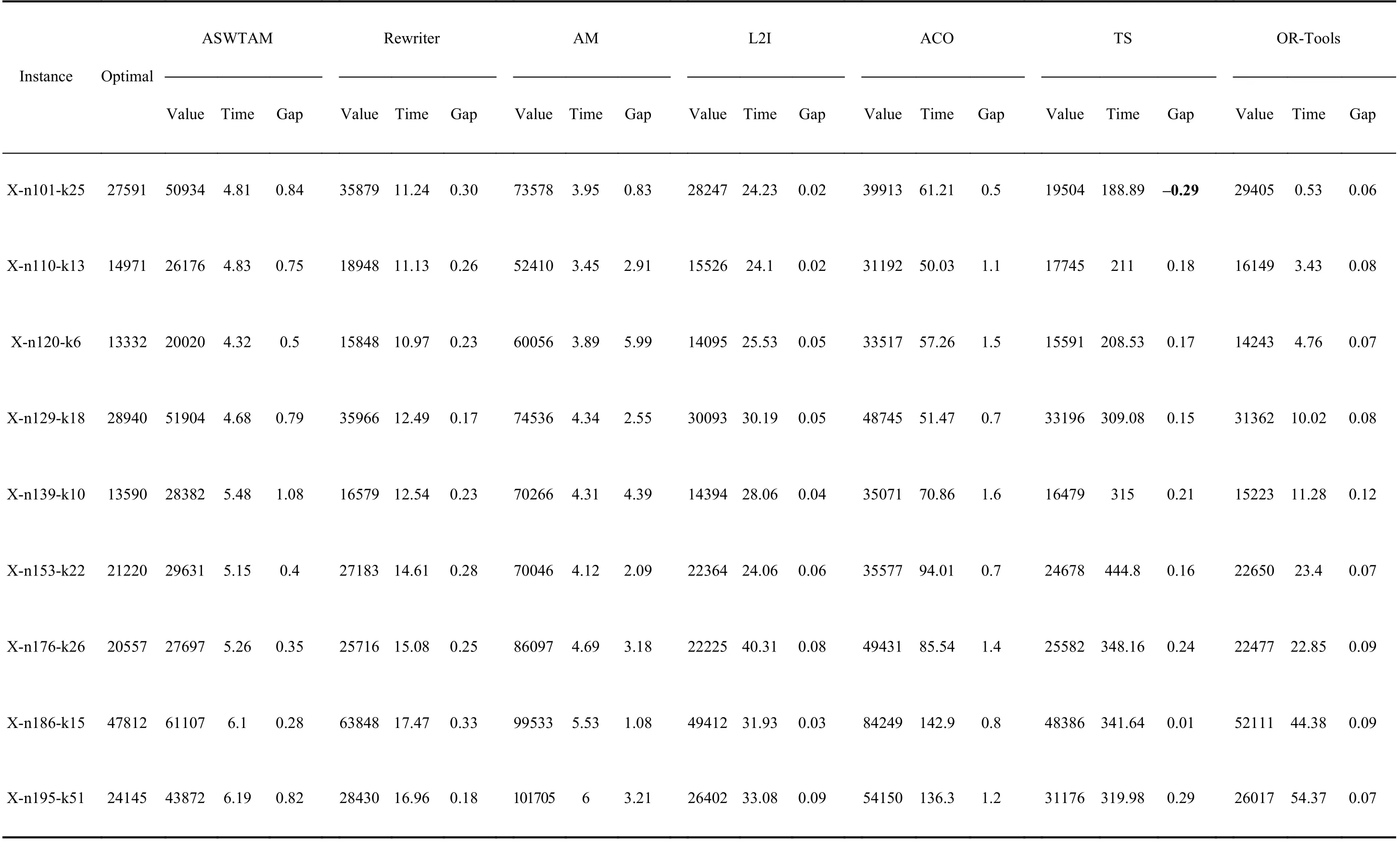
TABLE VI THE PERFORMANCE OF DIFFERENT ALGORITHMS ON DATA SET 3. THES OGLAVPIN IGS BTEIMTWE EISE CN OEMXPPUETREIMD EINN TSAELC OANLDGSORITHMS AND THE OPTIMAL SOLUTION GIVEN BY THE INSTANCE. THE
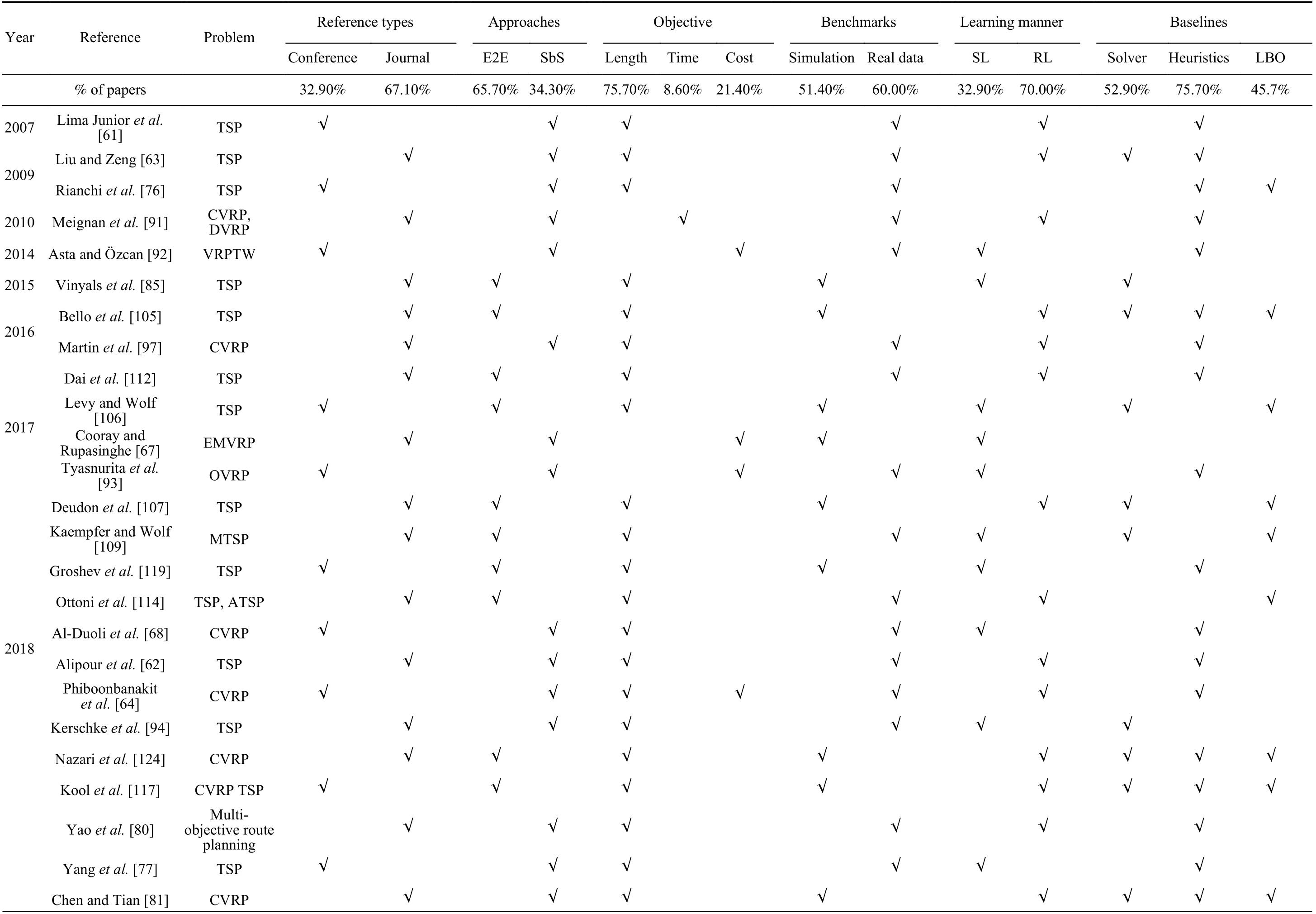
TABLE VII REVIEWED PAPERS ABOUT LEARNING-BASED OPTIMIZATION ALGORITHMS
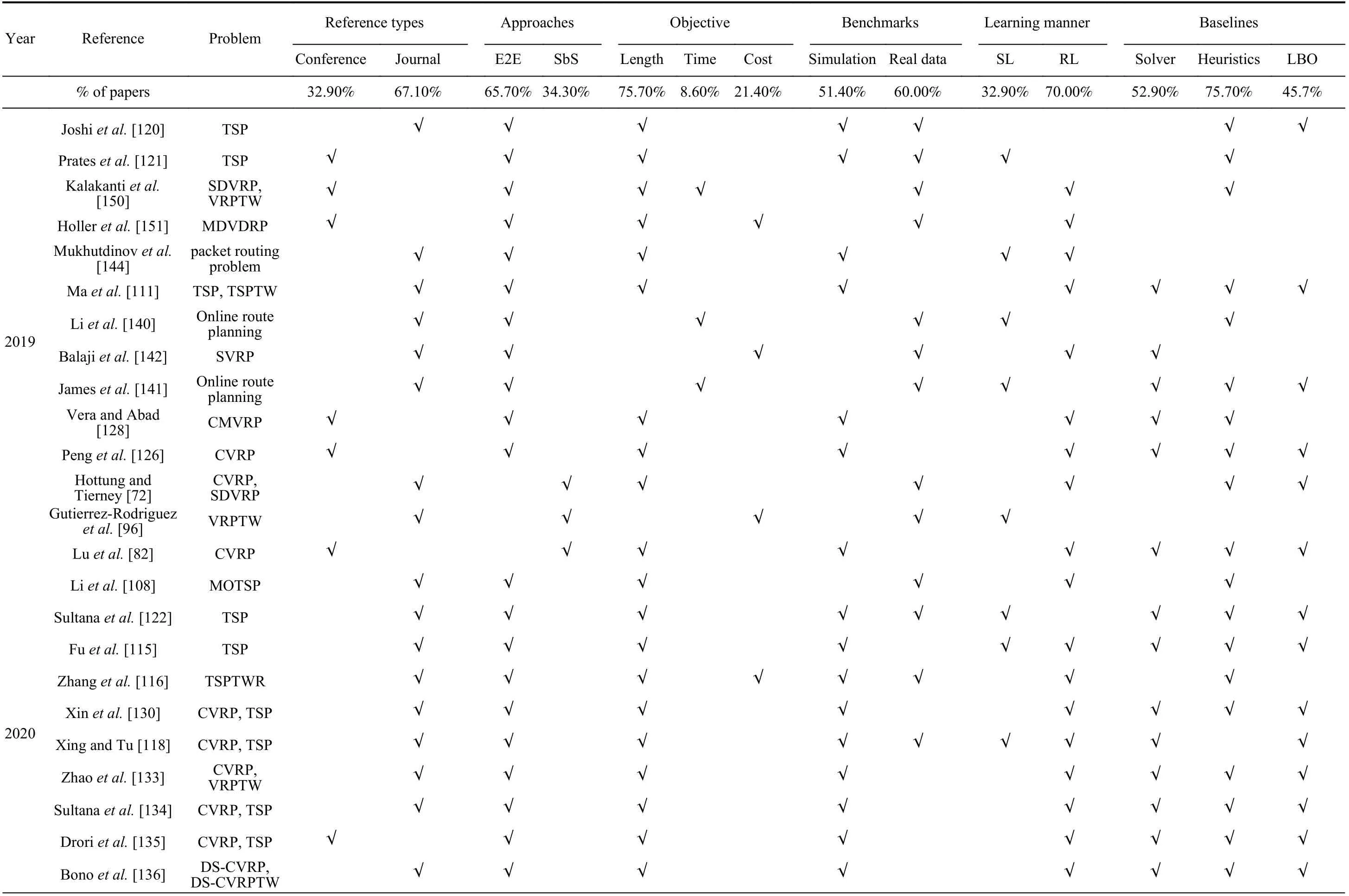
TABLE VII (continued)REVIEWED PAPERS ABOUT LEARNING-BASED OPTIMIZATION ALGORITHMS
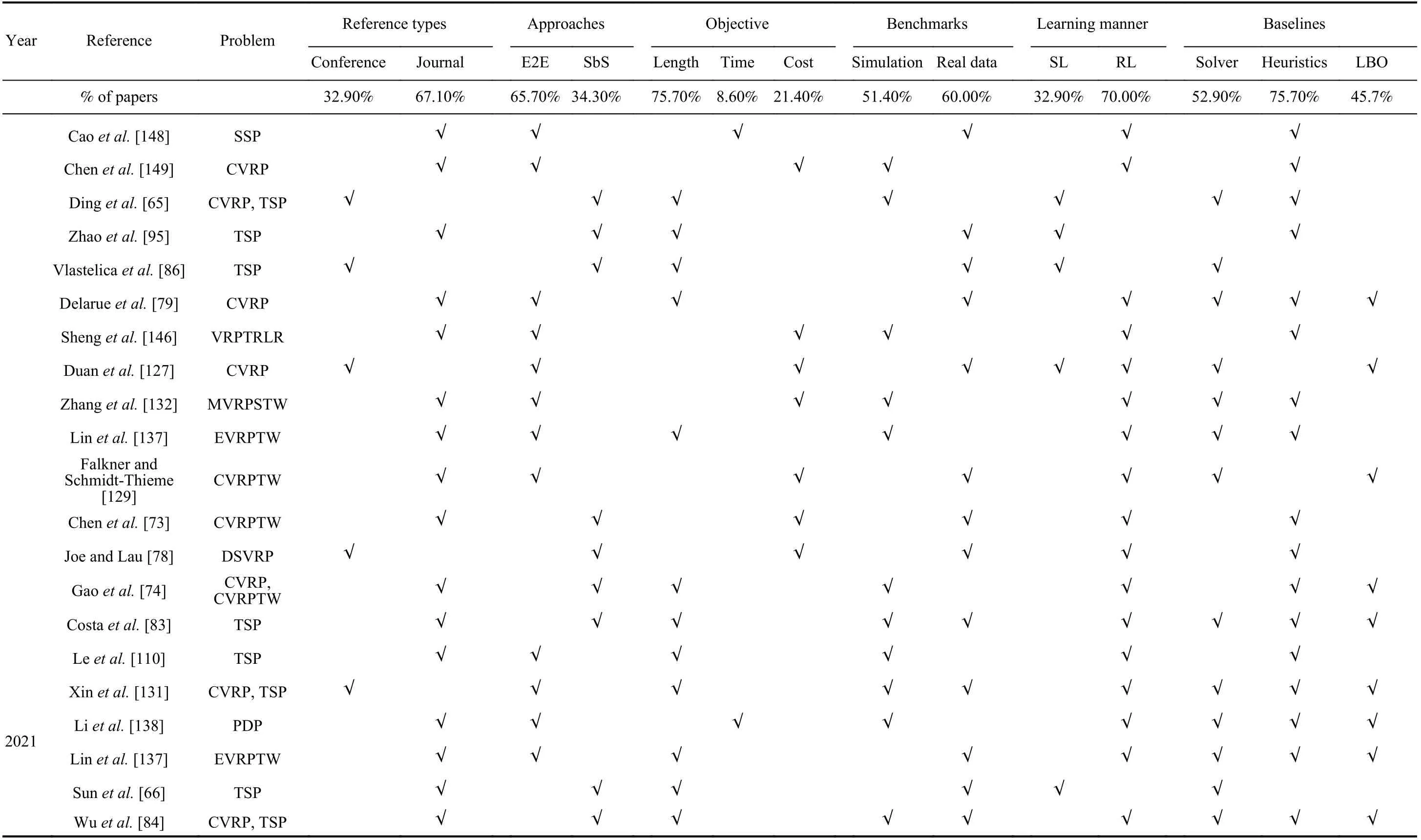
TABLE VII (continued) REVIEWED PAPERS ABOUT LEARNING-BASED OPTIMIZATION ALGORITHMS
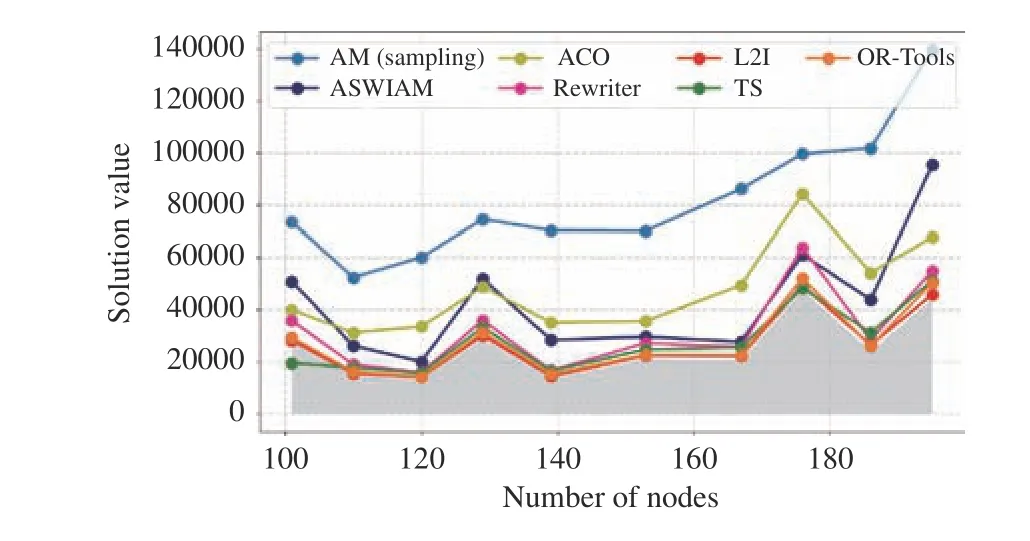
Fig. 11. Comparation of solution value of different algorithms on dataset 3.
2) Combining with conventional algorithms to improve the generality of LBO models.Nickelet al. [156] illustrated that the relation learned by an LBO model in knowledge graphs only makes sense when applied to entities of the right type. We also observed in our experiments that LBO models are affected by data distribution while combining heuristics,as search operators can improve the generality of the LBO algorithms. Hence, considering different forms of combination might be beneficial to guaranteeing a better generalization of LBO models. Using a solver to post-process solutions of LBO models [86] or using solutions generated by heuristic algorithms to pretrain LBO models [119] are all good research directions.
3) Embedding other algorithms to increase training efficiency of LBO models.Butleret al. [157] indicated that the data limitations of the LBO algorithms must be solved.The LBO algorithms frequently require sufficient data as a training set, but it is difficult to obtain sufficient raw data of combinatorial optimization problems in the real world. What’s more, the value function of learning models is randomly initialized, and models would select a random action with a certain probability to balance exploration and exploitation.LBO models might require a large amount of time and data to train but still converge to a suboptimal solution. Hence,embedding other algorithms to accelerate the convergence of the LBO model is necessary. For example, using other algorithms computes the initial value function [125], [144] or generates the prior knowledge for the next action [118].
4) Building a generic framework for the LBO algorithms to solve VRPs.Cappartet al. [158 ] proposed building a generic modeling framework for LBO algorithms as a new direction; Wagstaff [159] also indicated that the LBO algorithms have not yet matured such that researchers from other areas can simply apply them. Although many LBO algorithms have been proposed to solve different VRPs,encapsulating different LBO algorithms as a solver is still difficult for researchers. Many technical difficulties must be solved and the most critical step is to define a generic modeling framework to provide upper-application with uniform interface.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Towards Long Lifetime Battery: AI-Based Manufacturing and Management
- Disagreement and Antagonism in Signed Networks: A Survey
- Finite-Time Distributed Identification for Nonlinear Interconnected Systems
- SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer
- Real-Time Iterative Compensation Framework for Precision Mechatronic Motion Control Systems
- Meta Ordinal Regression Forest for Medical Image Classification With Ordinal Labels