嵌入空洞卷积和批归一化模块的智能煤矸识别算法
2022-07-18郭永存
郭永存,张 勇,2,李 飞,杨 鹏,
(1.安徽理工大学 深部煤矿采动响应与灾害防控国家重点实验室,安徽 淮南 232001;2.安徽理工大学 电气与信息工程学院,安徽 淮南 232001; 3.安徽理工大学 机械工程学院,安徽 淮南 232001)
煤炭是我国的主要能源,在能源结构中占据较大的比重。原煤中往往含有大量的矸石[1],这不仅降低了煤的使用效率,而且矸石的堆放还会对环境造成一定的污染,因此,有必要对煤和矸石进行分离。传统的煤、矸石分离技术有筛网跳汰法、重介质法和浮选法等[2],但这些方法带来的粉尘污染、水污染和土地污染等问题,给环境和人类健康带来极大危害。
近年来,国内外学者对煤矸分选技术进行了大量的研究,潘越等[3]利用X射线透射法探测煤和矸石密度,根据透射信号图像的不同区分煤和矸石,但这种方法存在电离辐射,有可能对工作人员身体造成较大伤害,因此,在应用上受到了一定的限制;WANG等[4]结合激光三角测量法和动态称重法,通过煤和矸石的密度差来区分煤和矸石,但该方法误差较大;余乐等[5]提出一种基于部分灰度压缩扩阶共生矩阵的图像识别方法,对煤和矸石0~255级灰度图像进行特征提取,并依据特征参数进行分类,该方法稳定性有待提高;李曼等[6]采用滤波的方式提取煤和矸石表面灰度和纹理参数,通过最小二乘支持向量机识别判断煤和矸石,该方法识别准确率有待提高;雷世威等[7]通过对YOLOv3模型结构和损失函数的改进,提高了网络对小目标煤和矸石的检测识别能力;PU等[8]利用卷积神经网络和迁移学习技术训练、识别煤和矸石图像,并采用验证集数据去验证训练模型的效果,其训练准确率达到100%,但验证集数据准确率只有82.5%,且模型出现过拟合,模型性能有待提高;徐志强等[9]利用现有的卷积神经网络模型对采集的煤和矸石图像进行训练和识别判断,并采用模型剪枝技术对现有的卷积神经网络模型进行优化,进一步提高了煤矸识别的准确率。
笔者通过搭建实验装置采集、构建煤和矸石数据集,并利用算法对数据集进行增强。在VGGNet16网络的基础上,引入空洞卷积和批归一化模块对模型进行改进,增强模型特征提取能力,加快模型训练收敛速度,提高煤矸识别准确率;并与其他经典卷积神经网络进行浮点运算次数和F1分数的对比,进一步说明智能煤矸识别算法的优势。
1 研究方法
1.1 卷积神经网络
卷积神经网络是目前深度学习具有代表性的网络之一,在图像分析和处理领域应用广泛。其中卷积操作用于提取图像特征,生成特征图;池化操作用于降低特征图维度,减少模型参数量;激活函数使模型具备非线性映射的能力;全连接操作用于预测,输出结果。煤矸识别卷积神经网络如图1所示。
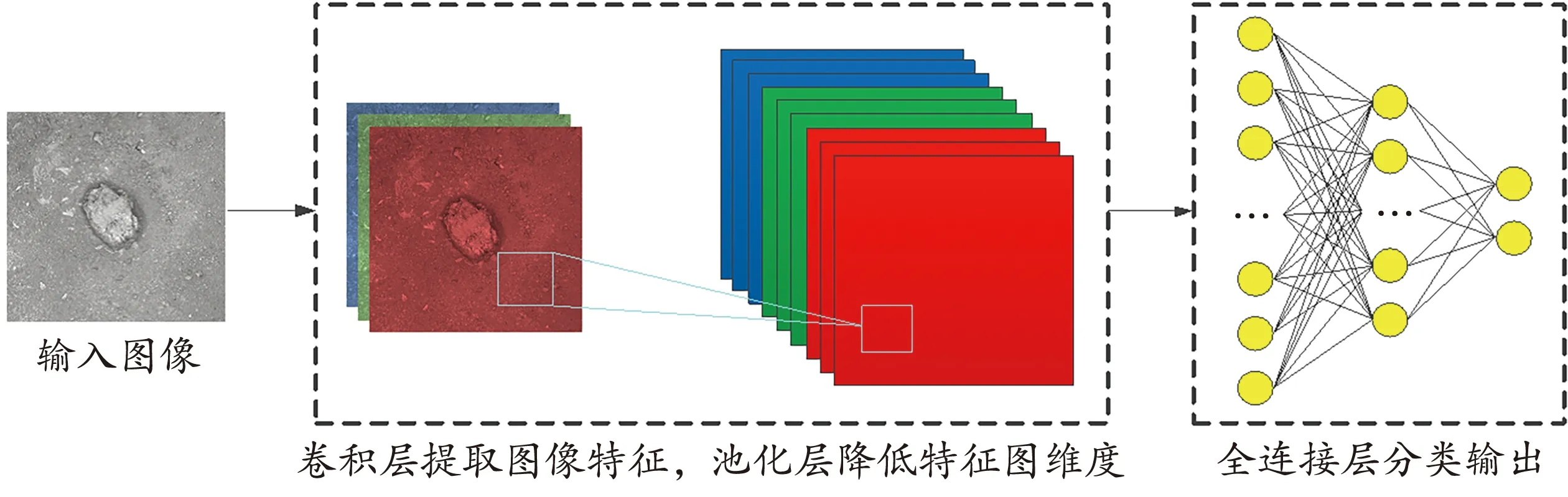
图1 煤矸识别卷积神经网络模型
卷积神经网络的特征提取能力主要体现在卷积运算,通过卷积操作,网络输出第m层特征图的感受野lm,其计算公式如下:
(1)
式中:lm-1为第m-1层特征图的感受野;fk为卷积核;si为第i层步长;*表示卷积操作。
卷积操作如图2所示。将感受野尺寸为5×5的特征图,通过与3×3的卷积核进行卷积运算,得到感受野为3×3的特征图。

图2 卷积操作示意图
1.2 空洞卷积
空洞卷积[10-11]通过在卷积层引入空洞系数Dr,控制卷积核感受野的大小,使网络在不增加计算量、不损失特征图分辨率的同时扩大卷积核的感受野,获得更丰富的图像特征,加强网络对多尺度目标的检测效果。空洞卷积核尺寸fn计算公式如下:
fn=fk+(fk-1)*(Dr-1)
(2)
空洞卷积核尺寸在原卷积核的基础上增加了(fk-1)*(Dr-1),卷积核的感受野也相应增加,通过空洞卷积操作,网络第m层特征图的感受野l′m计算公式如下:
(3)
式中l′m-1为空洞卷积第m-1层特征图的感受野。
空洞卷积操作如图3所示。在空洞系数Dr=1时,卷积核的尺寸由原来的3×3增加到5×5,通过空洞卷积操作,感受野尺寸为5×5的特征图输出感受野大小为1×1。

图3 空洞卷积操作示意图
1.3 批归一化模块
在进行机器学习时,为了加速训练,常常会对数据进行预处理。传统的预处理方法有零均值和白化,但随着网络层数的加深,参数对分布的影响不定,导致网络层内和层间的输入分布均发生改变,迫使网络需要适应新的分布,传统预处理方法不再适用于深度神经网络。
批归一化模块[12-14]通过网络训练时的一个小批量数据,计算输出某个神经元的xi的均值和方差,并引入2个参数γ、β,对网络进行变换重构,学习恢复原始网络所需的特征分布,减少网络隐藏层数据分布改变对网络训练的影响,加快网络的训练收敛速度,提升网络稳定性。批归一化算法操作如图4所示。

图4 批归一化算法操作示意图
批归一化算法的操作步骤如下:

(4)
(5)
2)对当前批次输入数据进行批归一化操作:
(6)
3)通过可学习的参数γ和β对批归一化后的数据进行重构变换,输出最终的数据:
(7)
式中:xi为当前层的神经元,下标i=1,2,…,c;ε为一个接近于0的正值常量,用于表示变换重构中数值的稳定性。
2 网络优化
VGGNet[15]是牛津大学计算机视觉组研发的深度卷积神经网络,其通过将5×5的大型卷积核拆分成2个3×3的小型卷积核,并通过多次堆叠的方式,在不增加参数量的情况下,加深网络模型深度,提高模型特征提取能力。笔者提出的智能煤矸识别算法DC&BN(Dilated Convolution & Batch Normalization)是在经典VGGNet16网络的基础上嵌入空洞卷积和批归一化模块的方法,使模型具备在少量增加运行浮点次数的情况下,增大模型感受野,加强特征提取能力,加快模型训练收敛速度,提升分类准确率等。经典VGGNet16网络结构如图5所示。

图5 VGGNet16网络结构
VGGNet16网络中主要存在CRM、L-CRM等2种基本结构,如图6所示。

图6 VGGNet16基本结构
CRM结构包括2个3×3卷积模块,卷积后均采用ReLU函数激活,并进行最大值池化操作;L-CRM结构则是在CRM结构的3×3卷积后增加一个1×1卷积,用于线性变换。智能煤矸识别算法DC&BN网络结构如图7所示。

图7 智能煤矸识别算法网络结构
智能煤矸识别算法基本结构包括DBRM和L-DBRM,如图8所示。

图8 智能煤矸识别算法基本结构
DBRM结构将CRM结构中的3×3卷积替换成卷积核尺寸为3×3,空洞系数Dr=1的空洞卷积,用于扩大卷积核的感受野,增强卷积的特征提取能力,实现对更大范围目标特征的采样。通过在空洞卷积和激活函数之间增加批归一化模块,加快模型训练收敛速度,提高模型稳定性和训练准确率。
3 实验过程
3.1 煤和矸石数据集
在实验室环境下搭建实验装置,采集煤和矸石图像,制作数据集。实验装置如图9所示。

图9 煤和矸石数据采集实验装置
利用搭建的实验装置,采集煤和矸石图片各500张,煤和矸石样张分别如图10(a)、图10(b)所示。数据集按照7∶1∶2的比例划分为训练集、验证集和测试集。

(a) 煤 (b) 矸石
3.2 实验设置
实验基于Windows10 64位操作系统,电脑配置为Inter Core i5-9300H, NVIDIA GTX1660Ti 6G显卡;在深度学习框架Tensorflow2.0中进行模型的训练、验证和预测。模型输入图像尺寸设置为224像素×224像素,训练周期为50轮,模型优化器为SGD函数,损失函数为交叉熵损失函数,并记录训练精度和损失函数曲线。
实验训练集样本仅有700张,在模型训练时容易陷入过拟合,需要对采集的样本进行数据增强。实验数据增强方式和参数值如表1所示。

表1 数据增强参数
智能煤矸识别算法DC&BN对采集数据集的训练曲线如图11所示。

(a) 训练准确率曲线

(b) 训练损失函数曲线
由图11(a)可知,煤和矸石图像训练准确率和验证准确率在第5个周期后,均达到90%以上,在27个训练周期以后训练准确率和验证准确率均达到98%以上,且波动幅度较小。
由图11(b)可知,训练损失函数在第5个周期后,损失函数值趋于0,虽有个别点出现较大误差,但总体趋于稳定。模型训练效果理想,模型各部分超参数和权重值训练较为合理,并且损失函数曲线间的间隙较小,属于完美拟合状态。
3.3 实验结果对比
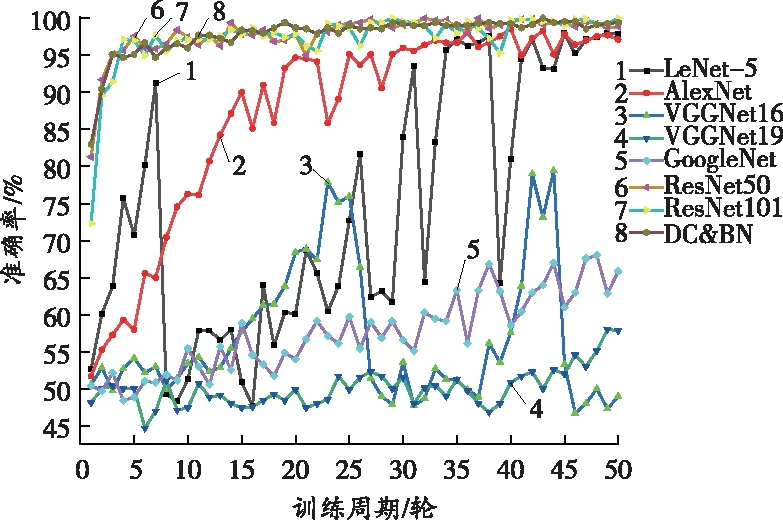
经典的卷积神经网络模型主要有VGGNet、LeNet-5[16]、AlexNet[17]、GoogleNet[18]和ResNet[19]等。利用Tensorflow 2.0分别搭建上述网络,对采集的煤和矸石图像数据集进行训练,模型训练曲线如图12所示。
(a)模型训练准确率曲线

(b)模型训练损失函数曲线
由图12可知,智能煤矸识别算法DC&BN收敛速度较快,经历5轮训练后,模型即收敛,准确率达到97%以上,最终趋于100%,性能与ResNet系列网络相当。AlexNet、LeNet-5分别经历约30轮、40轮的训练,损失函数才逐渐收敛;而VGGNet和GoogleNet在50个周期的训练过程中,准确率曲线均处于振荡状态,训练准确率较低,损失函数也不收敛。
此外,针对上述网络模型采用浮点运算次数FLOPs[20]和F1分数2个指标进行数据对比分析,如表2所示,模型预测结果示例如图13所示。
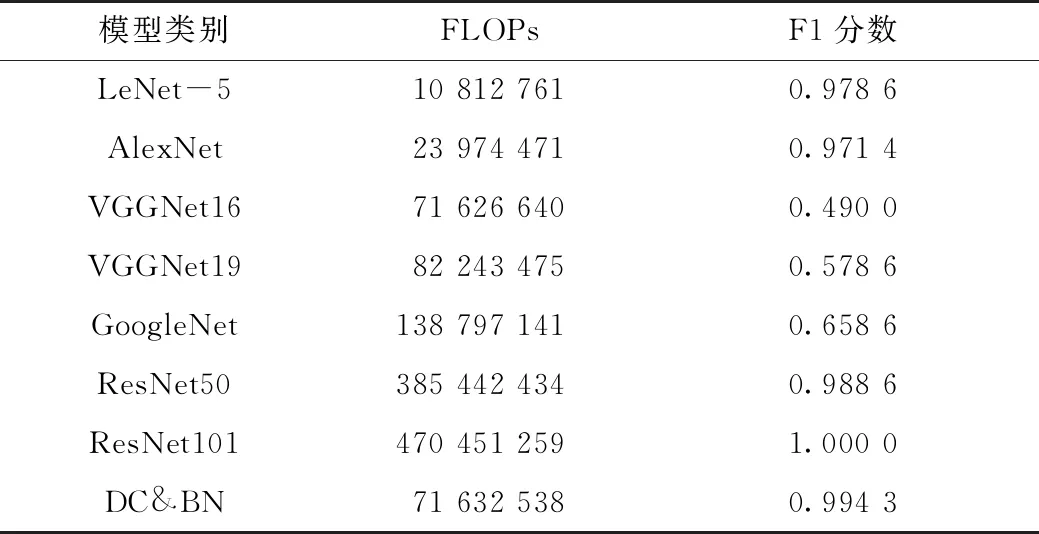
表2 模型评价指标对比

(a)预测正确示例

(b)预测错误示例
DC&BN的F1分数与LeNet-5、AlexNet、ResNet系列网络相当,均在0.97以上,模型预测准确率较高。对比浮点运算次数,DC&BN的浮点运算次数与原VGGNet16网络相近,为71 632 538次,虽高于LeNet-5和AlexNet,但远低于ResNet50和ResNet101;而原VGGNet16、VGGNet19和GoogleNet网络不仅浮点运算次数高,且F1分数较低,模型复杂度高,参数训练效果不理想。
综上所述,智能煤矸识别算法DC&BN在训练准确率、收敛速度和F1分数方面均取得了良好的效果,虽然浮点运算次数比LeNet-5和AlexNet高,但也在合理的范围内,且收敛速度较二者要快。
4 结论
1)基于空洞卷积和批归一化算法对经典卷积神经网络VGGNet16进行改进,并搭建实验装置,采集、构建煤和矸石数据集,通过对网络的训练和验证,结果表明智能煤矸识别算法DC&BN训练和验证准确率均可达97%以上,且从第5个训练周期后开始收敛,收敛速度较快。
2)利用浮点运算次数FLOPs和F1分数对智能煤矸识别算法DC&BN进行评价,其F1分数可达0.994 3,模型训练效果较好,能够对未知类型样本做出较高准确率的预测;模型浮点运算次数为71 632 538次,模型复杂度处于较低水平。
3)利用深度学习框架Tensorflow 2.0,分别对多个网络模型进行训练和验证,并与DC&BN进行对比分析,结果表明智能煤矸识别算法DC&BN训练收敛速度较快,准确率较高,虽浮点运算次数较大,但在合理的范围内。
