首词素位置概率信息未参与汉语阅读的词切分:基于副中央凹加工的证据 *
2022-07-18梁菲菲龙梦灵
梁菲菲 向 颖 龙梦灵
(1 教育部人文社会科学重点研究基地天津师范大学心理与行为研究院,天津 300387) (2 天津师范大学心理学部,天津 300387) (3 学生心理发展与学习天津市高校社会科学实验室,天津 300387)
1 引言
词是阅读的重要加工单位,这在汉语和拼音文字语言中具有跨语言的普遍性(Bai et al., 2008;Li & Pollatsek, 2020; Rayner et al., 1998)。大多数拼音文字语言书写系统中包含词间空格,它能在视觉上进行词切分,在拼音文字阅读中十分重要。如果人为地删除词间空格,读者的平均注视时间会显著变长,眼跳距离显著变短,阅读速度下降30%~50%(Rayner et al., 2009)。与英语、德语、西班牙语等拼音文字语言不同,汉语在文本呈现方式上没有明确的视觉词切分线索(如词间空格)。那么,汉语读者在阅读文本时利用何种线索将词从句子中切分出来?该问题是揭示汉语阅读词切分认知机理的关键(李兴珊 等, 2011; Liang et al., 2021)。本研究将在Liang等人的研究基础上,继续对汉语阅读中的一种语言词切分线索—词素位置概率信息的作用方式进行考察。
词素位置概率信息是指一个特定汉字用在词内某个位置(如词首或词尾)的概率信息。如果一个汉字常用在多字词的某个特定位置,该汉字在一定程度上也携带了词内位置线索。例如,基于SUBTLEX-CH语料库(Cai & Brysbaert, 2010),在“各”字构成的29个双字词中(如“各位”“各家”“各路”等),“各”字均用在词首。该字出现在词首的概率为100%,其词素位置线索就指向词首。具有特定词素位置线索的汉字在文本阅读中提供了一定的词切分信息,如“主持人请各位获奖选手上台领奖”,由于“各”只能用在词首,因此,“各”的出现意味着上个词的结束,下个词的开始。在汉语阅读中,读者是否会利用词素位置概率信息进行词切分和词识别?
Liang等人(2017)和Liang等人(2015)系统考察了新词学习情境中词素位置概率的作用,操纵首、尾词素的位置概率信息,并控制词素字频和笔画数,构造三类双字假词作为新词,形成三个实验条件:(1)一致条件,首词素常用在词首,尾词素常用在词尾,提供了一致的词切分信息;(2)不一致条件,首词素不常用在词首,尾词素不常用在词尾,提供了不一致的词切分信息;(3)平衡条件,首词素和尾词素用在词首和词尾的概率均在50%左右,不提供任何词切分信息。其研究将每个新词嵌在6个强信息限制性语境中,将其描述成某个特定语义类别的新成员。以大学生和小学三年级儿童为被试,记录其阅读句子时的眼动轨迹。结果发现,在反映词汇加工早期和晚期的眼动指标(如首次注视时间、凝视时间、总注视时间)中,被试在一致条件下对新词的注视时间显著短于不一致条件,表明当词素在词内的实际位置和常用位置不相符时,读者在阅读中遇到了加工困难,他们需要额外的加工时间解决由于位置信息不一致带来的认知冲突。上述研究结果表明词素位置概率作用于汉语阅读新词学习的词切分。
然而,上述研究为达到自变量操纵力度的最大化,同时操纵首、尾词素的位置概率。因此,目前的研究发现虽然证实了词素位置概率信息作用于汉语阅读的词切分,但是并未回答以下问题:究竟是首词素、尾词素还是二者的位置概率信息共同作用于汉语阅读的词切分?因此,Liang等人(2021)通过两个平行实验,选择双字词作为目标词,分别操纵首、尾词素的位置概率高低,同时保持另一词素在两个实验条件中相同,如“湖水/泉水”(“湖”常用在词首,“泉”不经常用在词首),将目标词嵌在相同语境,记录被试阅读句子时的眼动轨迹,发现读者对目标词的注视时间在首词素位置概率高、低两个实验条件中无显著差异;而当尾词素是常用在词尾的汉字时,读者对目标词的凝视时间和总注视时间显著短于尾词素不经常用在词尾时。该研究结果表明,首、尾词素的位置概率信息在汉语阅读词切分和词识别中的作用不同,读者仅对尾词素的位置概率信息敏感。
为何首词素的位置概率信息没有参与汉语阅读的词切分和词识别?根据Li和Pollatsek(2020)在汉语阅读眼动控制模型中对词切分和词识别关系的认识,二者是一个统一的过程。当一个词被切分出来,意味着这个词已经被成功识别;当一个词被识别出来时,也就意味着该词的词首和词尾被成功切分。此外,Li和Pollatsek在模型中假设,汉语阅读中的词汇识别符合序列加工原则。由于汉语文本无词间空格,当前词的右边界也是下一个词的左边界,也就是说,词N的左边界和词N-1的右边界完全重合。因此,在词N未被直接注视之前,其左边界已经在识别词N-1时被成功切分。那么,读者在直接注视词N时,就无需通过首词素的位置概率信息再次识别词N的左边界。该观点已得到一些实验结果的支持,例如,Liu和Li(2014)发现,如果在词的左侧插入词间空格,不会促进汉语阅读的词汇识别;但是在词的右侧插入词间空格,则会促进当前词的加工。
上述实验结果表明,在汉语阅读的实时加工过程中,判断一个词的左边界发生在直接注视之前,而判断词的右边界则发生在直接注视时。而读者在阅读过程中,除了在中央凹对正在注视的目标词进行直接加工外,还可以从副中央凹处加工到目标词右侧词汇的部分信息。前期研究已经发现读者在副中央凹处可以加工到词汇正字法、语音,以及部分语义信息(Rayner, 2009)。那么,读者在副中央凹加工中是否会利用首词素位置信息进行词切分和词识别?如果读者在注视词N-1时,可以在副中央凹处加工到词N的首词素位置概率信息,切分出词N的左边界,那么就不需要在直接注视词N时对其左边界再次进行切分。
为此,本研究采用边界范式,操纵目标词首词素的位置概率(高、低)和预视类型(相同预视、假字预视),考察读者是否在副中央凹对首词素的位置概率信息进行加工。研究假设:如果汉语读者在副中央凹处对首词素位置概率信息敏感,与首词素位置概率低相比,当首词素位置概率高时,被试将在目标词加工中获得更大的预视效益;如果读者在副中央凹处未对该信息进行加工,两个实验条件中的预视效益量差异不显著。
2 研究方法
2.1 被试
天津师范大学110名大学生,平均年龄为19.2岁。所有被试视力或矫正视力正常,无色盲色弱,不知晓实验目的。实验结束后,给予被试一份小礼物作为报酬。
2.2 实验设计
采用2(首词素位置概率:高、低)×2(预视类型:相同预视、假字预视)的被试内实验设计。因变量为反映词汇加工的系列眼动指标。
2.3 实验材料及实验范式
选择40对双字词作为目标词,操纵目标词首词素的位置概率。基于SUBTLEX-CH语料库(Cai &Brysbaert, 2010),计算首词素的位置概率:某个汉字用在双字词词首的数量/该汉字组成双字词的总数量×100%。高概率条件下首词素用在词首的平均概率为81%(全距: 70%~100%);低概率条件下首词素用在词首的平均概率为22%(全距: 7%~30%)。两个实验条件中目标词的尾词素相同,且用在词首和词尾的概率相当(全距: 36%~65%),不能提供明晰的词切分信息。匹配两个实验条件中目标词首词素的笔画数(高概率条件:M=8.1,SD=2.7; 低概率条件:M=8.5,SD=2.4)、字频(高概率条件:M=963次/百万,SD=2910次/百万; 低概率条件:M=436次/百万,SD=824次/百万)和目标词词频(高概率条件:M=59次/百万,SD=153次/百万; 低概率条件:M=33次/百万,SD=77次/百万)。统计检验结果表明,两个实验条件在笔画数、字频和词频上均无显著差异(ts<1.28,ps>0.05)。
将每组目标词嵌入相同的语境,目标词位于句中。平均句长为12.0个汉字。采用句子完形任务,请15个不参加正式实验的大学生对句子的预测性进行评定。让被试根据目标词左侧信息填充可能出现的词。经检验,高概率条件(M=0.11,SD=0.03)和低概率条件(M=0.13,SD=0.04)中句子对目标词的预测程度无显著差异,t(39)=0.72,p>0.05。邀请另外不参加正式实验的15名大学生对句子的通顺性做5点等级评定(“1”表示“非常不通顺”,“5”表示“非常通顺”),两个实验条件无显著差异,高概率条件:M=4.19,SD=0.21;低概率条件:M=4.24,SD=0.19,t(39)=0.96,p>0.05。
采用边界范式(如图1所示),设有两个预视条件(相同、假字),与目标词首词素位置概率这一自变量相组合,形成四个实验条件:(1)高概率-相同预视,眼睛在越过边界前和越过边界后,均为高概率条件中的目标词首字,如“湖”;(2)低概率-相同预视,眼睛在越过边界前和越过边界后,均为低概率条件中的目标词首字,如“泉”;(3)高概率-假字预视,眼睛在越过边界前为符合正字法规则的假字,越过边界后,则替换为高概率条件中的目标词首字;(4)低概率-假字预视,眼睛在越过边界前为符合正字法规则的假字,越过边界后,则替换为低概率条件中的目标词首字。假字在条件3和条件4中保持一致,其笔画数(M=8.4,SD=2.9)与两个目标词首字的笔画数均无显著差异,ts<0.56,ps>0.05。

图1 边界范式示意图
每个被试阅读40个实验句和40个填充句,填充语句正常呈现。为确保被试认真阅读,在20个句子后面伴有一个阅读理解判断题目,要求被试根据所阅读句子的语义作出“是/否”判断。
2.4 实验仪器
采用EyeLink 1000型眼动仪,仪器采样率为1000 Hz。实验材料在19英寸的DELL显示器上呈现,刷新率为120 Hz,分辨率为1024×768像素。被试与屏幕之间的距离为75 cm。实验材料以宋体18号字体呈现,每个汉字大小为25×25像素,呈0.74°视角。
2.5 实验程序
被试单独施测。进行水平三点校准。平均误差小于0.2°。眼睛校准成功后,句子逐一呈现,要求被试认真阅读所有句子。阅读完毕后,按鼠标“左键”结束当前句子阅读,并通过鼠标按键在屏幕上选择阅读理解题目的正确答案。正式实验前有4个练习语句,以确保被试熟悉实验程序。整个实验持续25分钟左右。
3 结果
被试的阅读理解正确率均在90%以上,平均正确率为94%,表明所有被试都认真阅读了实验语句。根据以下标准删除数据(王永胜 等, 2016;Rayner et al., 1998):(1)注视点持续时间小于80 ms或大于1200 ms;(2)句子注视点少于3个;(3)边界变化提前或延迟;(4)边界变化或注视目标词时眨眼;(5)3个标准差之外。删除数据占总数据的14.7%。
选取跳读率和第一遍阅读的眼动指标(首次注视时间、单一注视时间、凝视时间、再注视比率、首次注视位置)作为反映预视效益大小的因变量。采用R(R Core Team, 2019)环境下的线性混合模型(liner mixed model, LMM)进行数据分析(Barr et al., 2013)。将首词素位置概率、预视类型,以及二者的交互作用作为固定因素纳入模型,将被试、项目纳入模型的随机效应。采用随机效应最大逐渐递减的原则,直至模型拟合成功。
各实验条件下的平均数和标准差见表1,统计结果见表2。除了首次注视位置,在其他五个眼动指标分析中,得到相同的效应:(1)预视类型的主效应显著,与假字预视条件相比,被试在相同预视条件下对目标词的跳读率更高,注视时间更短,再注视比率更低,表明本研究对预视的操纵有效。(2)首词素位置概率的主效应不显著,当目标词的词频相当时,被试对目标词的第一遍阅读时间没有因首词素位置概率不同而发生变化。这与Liang等人(2021)第一个实验的研究发现一致,表明汉语读者在词切分和词识别过程中没有利用首词素的位置概率信息。(3)首词素位置概率和预视条件的交互作用不显著,表明目标词的预视效益量没有受首词素位置概率高低的影响。该结果表明,汉语读者没有在副中央凹处加工下一个词的首词素位置概率信息。
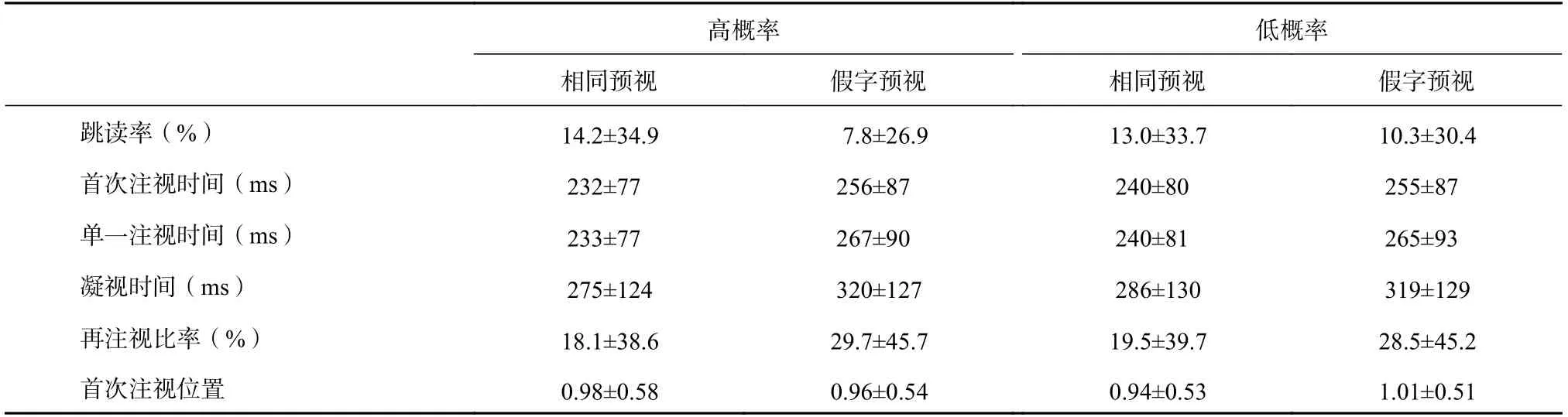
表1 被试在各实验条件下对目标词的注视情况(M±SD)
首次注视位置是指落入目标词的首个注视点的位置距离词首的距离,全距为0~2个汉字,其中,词首为0,中心为1,词尾为2。分析结果显示,预视条件、首词素位置概率以及二者的交互作用均不显著,表明首词素位置概率没有调节读者在目标词上的首次眼跳定位。
4 讨论
本研究采用边界范式,考察汉语读者是否在副中央凹处加工下一个词的首词素位置概率信息。结果发现,目标词的预视效益量并没有受到首词素位置概率高低的调节。结合Liang等人(2021)的研究结果,表明汉语阅读中首词素位置概率信息没有参与词切分和词识别过程。该研究发现加深了对汉语阅读词切分认知机理的认识。
汉语阅读中首词素的位置概率信息不作用于词切分和词识别,可能与汉语阅读的文本呈现方式有关。无词间空格意味着相邻两个词共用一个词边界。根据Li和Pollatsek(2020)所持的观点,词切分和词识别是一个统一的加工过程,当读者在中央凹加工处成功识别词N-1时,词N-1的右边界和词N的左边界均被成功切分出来。因此,当眼睛注视词N时,为了加工的经济性,读者不再分配认知资源加工首词素的位置概率信息。本研究结果进一步说明,读者没有在副中央凹处加工下一词首词素的位置概率信息。这在一定程度上支持了Yen等人(2012)的研究发现,即汉语读者对词素位置概率信息的加工发生在中央凹,而非副中央凹。可能是由于读者在阅读中对首词素家族成员的加工更多地涉及到语义层面的加工(Yao et al., 2021),首词素位置概率信息加工则是在所有家族成员(不论词内位置)激活的基础上,计算出该汉字用在词首的概率信息。语义加工大多发生在中央凹加工(张慢慢 等, 2020),因此,首词素位置概率信息的加工更有可能与中央凹加工有关。
需要指出的是,泰语是一种无词间空格的拼音文字语言。Kasisopa等人(2013, 2016)在泰语阅读中发现,词首和词尾字母的位置概率信息共同作用于词切分,具体表现为,当词首和词尾字母具有较高的位置概率时,泰语读者加工目标词的时间会显著缩短,同时,在目标词上的首次眼跳定位将更加靠近词中心。
综上所述,首词素的位置概率信息在泰语阅读中起到词切分的作用,而在汉语阅读中则没有起到作用,表明首词素位置概率信息在词汇识别中的作用具有跨语言的特异性。这可能和该信息在各语言中的性质不同有关。据统计,在泰语中,10个常用在词首的字母构成的词占所有词汇的50%,5个常用在词尾的字母所构成的词占所有词汇的50%(Kasisopa et al., 2013)。对于熟练的泰语读者,首、尾词素位置概率信息类似于词间空格,更像是一种视觉词切分信息。只要读者具备一定的阅读经验,他们在阅读中通过视觉加工就可以习得该词素的位置概率信息。因此,泰语读者很有可能在副中央凹处就可以通过视觉加工判断出词首位置,进而有效引导眼动。如果这种假设正确的话,研究者预期,当在泰语阅读材料中插入词间空格后,这种视觉词切分信息将和首、尾词素的位置概率信息共同作用于泰语阅读的词切分。因为两种词切分线索均类似于视觉信息,位于视觉加工这一层级。Kasisopa等人的研究结果支持了上述观点,该研究发现泰文阅读中的眼跳定位同时受词间空格、首、尾词素位置概率的影响,最佳首次注视位置的分布发生在词间空格条件下阅读词首和词尾位置概率较高的词汇时。
相比之下,汉语阅读中词素位置概率的特征在视觉上不明显。据统计,在5915个常用汉字中,少于20%的汉字仅用在词内的某一个位置(例如单字词、词首、词尾),提供明确的词切分标记(Yen et al., 2009)。最为重要的是,这些可以提供明确词边界的汉字的累积使用频率较低(1146.9次/百万)。相比之下,约50%的汉字在词内的位置非常灵活,既可以用作单字词,也可以用作多字词的词首、词中和词尾,例如“衣”“衣服”“洗衣机”“上衣”。这些汉字的累积使用频率非常高(960976.9次/百万)。由此可见,与泰语相比,汉语中词素的位置概率特征不具系统性,它更像是一种基于词素位置在语言学上的统计学特征,在加工中逐步编码和表征,随后影响词切分和词识别过程。Liang等人(2017)和Liang等人(2015)的研究成果支持了这一观点。其研究同时操纵词素位置概率和文本呈现方式(有无词间空格)两个因素,结果并没有发现两种词切分线索的交互效应。词间空格是一种视觉词切分线索,因此,研究者推断,汉语阅读中读者对词素位置概率的加工可能没有发生在视觉加工层级,而更有可能和早期的语言加工(如词汇通达等)有关。Yao等人(2022)发现,首词素家族大小效应发生在凝视时间和总注视时间等反映词汇加工相对晚期的眼动指标中,这也可以推断,汉语读者对词素位置概率信息的加工与词汇通达或后期语义整合有关。
尾词素位置概率如何作用于汉语阅读的词汇加工?在拼音文字阅读中的词汇识别中,特定字母构成的词汇在被激活的同时,包含这些字母的其它词汇(正字法临近词)在一定程度上也被激活,例如,在激活cat时,bat,cut,ate等正字法临近词也会不同程度地被激活。如果一个词具有较多的正字法临近词,那么,构成词的字母将接受到更多的、自上而下的、来自词汇水平的反馈(Andrews, 1989; Forster & Shen, 1996; Johnson &Pugh, 1994; Peereman & Content, 1995; Sears et al.,1995)。因此,这些词的识别速度将快于拥有较少正字法临近词的词汇(McClelland & Rumelhart,1981)。
无论是在词汇判读任务还是在自然阅读中,当词内特定位置的词素具有较多的正字法临近词时,其加工速度快于拥有较少正字法临近词的词汇(Tsai et al., 2006)。由此推之,当词尾汉字具有较多的正字法临近词时,包含同一尾词素的词汇受到更大程度的激活,目标词更容易胜出。由此可知,词素位置概率的加工发生在词汇识别和切分的“字组词”环节(Liang et al., 2017; Liang et al., 2015)。
本研究发现对当前的汉语阅读眼动控制模型有如下启示。第一,深化对汉语阅读词切分内在认知加工过程的认识。Li和Pollatsek(2020)在模型中提出了汉语阅读词切分和词识别的关系,但是并没有对词切分的内在认知加工过程进行详细解释。本研究结果表明,汉语读者对词首和词尾的切分不是发生在同一个时间点,而是有时间先后之分。其中,词首的判断发生在未被直接注视之前。当眼睛直接注视目标词时,会同时利用自上而下和自下而上的信息判断词尾的位置。一旦读者完成了整个词汇识别过程,那么,词尾的切分就已完成;或者说,一旦词尾的切分完成,读者就完成了当前词的切分。同时,下一个词的词首切分也就完成了。由此可知,在汉语阅读中,词尾切分在一定程度上要比词首切分更为重要。第二,研究者有必要在当前汉语阅读词切分与词识别模型中纳入尾词素位置概率这一信息,并继续考察尾词素位置概率和其它语言学因素(如词频、预测性)的交互作用,以此提高模型的解释力。
5 结论
首词素用在词首的概率高低不影响汉语读者在目标词上的预视效益量,表明汉语读者在副中央凹中没有加工首词素的位置概率信息。
