基于MobileNetV2与LBP特征融合的婴幼儿表情识别算法
2022-07-16施一萍江悦莹朱亚梅
邓 源,施一萍,江悦莹,朱亚梅,刘 瑾
(上海工程技术大学 电子电气工程学院,上海 201620)
婴幼儿表情识别流程通常包含建立数据库、图像预处理、人脸检测、特征提取以及分类等步骤。目前常用的婴幼儿表情识别方法可分为:基于传统的机器学习和基于深度学习的方法。
机器学习[1-3]虽然能够取得较好的识别结果,但由于其采用手工设计特征,人为干扰因素较大,准备工作耗时较长。借助深度学习的方法[4-5]可以更方便、准确地提取出面部表情的隐藏特征。若将深度学习模型与传统手工设计特征相结合[6-7],并将其运用到表情识别中,可显著提升分类效果,对部分干扰也更具鲁棒性。
本文提出一种基于MobileNetV2与分块加权LBP统计直方图双路特征相融合的方法来对婴幼儿进行表情识别。该方法有效结合了面部表情的全局特征和局部纹理特征,并利用了支持向量机(Support Vector Machine,SVM)对小样本数据的分类优势,提升了对婴幼儿表情的识别效果。
1 相关工作
1.1 建立婴幼儿表情数据库
目前国内外针对婴幼儿表情的研究较少,且没有可供参考的数据集。婴幼儿的面部圆润饱满,骨骼轮廓不分明,导致面部表情特征不明显。婴儿的某些表情种类与成人之间差别较大,不能直接套用现有的成人表情数据集来训练模型。基于这些问题,需要自行构建一个标准的、实验环境下的婴幼儿表情数据库。本文所使用的数据库建立过程如图1所示。

图1 数据库建立流程Figure 1. Database establishment process
由于婴幼儿的心理活动丰富程度较低,因此不需要对其进行过于细致的划分。参考标准成人表情数据库,保留开心、难过、生气、中性4个常规类型的表情,并将恐惧和惊讶合并成一类,赋予惊恐标签。由于婴幼儿大多数时间处于睡眠状态,因此本文舍弃厌恶表情,增加睡眠表情。综上所述,本文所建立的数据库最终包含6种表情类型。
1.2 轻量级卷积神经网络
MobileNet被较多应用于移动端或嵌入式设备中。网络联合逐通道卷积(Depthwise Convolution,DW)和逐点卷积(Pointwise Convolution,PW)来提取特征图,降低了参数运算量。MobileNetV2引入倒置残差块和线性瓶颈结构[8-9]进行改进,有效缓解了特征退化问题,提升了网络性能。其网络微结构如图2所示。

图2 MobileNetV2网络微结构Figure 2. MobileNetV2 network microstructure
1.3 局部二值模式
局部二值模式(Local Binary Patterns,LBP)算法具有光照不变性,通常被用来描述图像的纹理特征。表情特征属于人脸五官特征和纹理特征的融合,所以在表情识别研究中,LBP算法一直有着重要的应用。
2 双通道特征融合模型
单一的LBP特征并不能全面表征出婴幼儿面部表情,所以需利用卷积神经网络(Convolutional Neural Networks,CNN)提取出面部表情的全局特征,通过融合两种特征优势进行识别。第1条通道是改进后的MobileNetV2,其可提取出全连接层的输出张量。第2条通道可将原始输入图进行分块,计算信息熵构造出权值,提取出加权环形LBP统计直方图特征。最后,对特征进行融合,并使用SVM进行分类。双通道模型结构如图3所示。

图3 双通道模型结构Figure 3. Dual-channel model architecture
2.1 分块加权LBP直方图特征提取
婴幼儿表情的纹理特征重点集中在眼、鼻、嘴这3个部分。为了有主次地呈现出面部表情特征,先将图像划分为12个子块,再计算出每一块的信息熵,合理地构造出权值并进行加权连接,突出信息丰富区域,使得表情特征更具有判别性。LBP特征可以通过统计直方图特征[10-13]来表示。利用子块特征串联得到的高维向量来表征婴幼儿面部表情信息。
本文利用环状LBP算子,根据输入尺寸去调整半径范围、采样点个数,进行多尺度的LBP特征提取。环形LBP值计算式为
(1)

(2)
式中,Pixeli为所选范围内第i个像素点;Pixelc为像素中心点。提取出婴幼儿表情特征如图4所示。

图4 婴幼儿表情圆形LBP特征图Figure 4. Round LBP feature map of infant expression
信息熵反映的是图像信息的丰富程度,熵值越大,信息量越多,特征越明显。本文通过计算每个子块的信息熵和整体图像的信息熵来构造加权系数。设第i个子块的信息熵表示为
(3)
式中,n是像素级数,随采样点个数而改变;Pik表示k级像素出现概率。子块信息熵越大,则给以的权重系数越高。据此设计定义的权重系数为
(4)
式中,Entropye表示整张特征图的信息熵。
加权连接各子块的LBP统计直方图特征,依照顺序串联成完整的直方图向量,如图5所示。
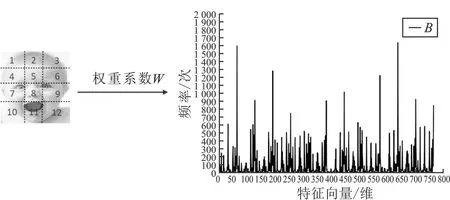
图5 串联纹理统计直方图Figure 5. Concatenated texture statistical histogram
每一张婴幼儿表情图提取出的直方图特征向量大小为12×64,共有768维。这些高维特征使得其他特征在进行分类时失去了原有的特性。本文采用主成分分析法(Principal Component Analysis,PCA)进行降维,保留100维主要特征分量。
2.2 MobileNetV2特征提取网络
LBP纹理特征更多突出的是五官区域的变化,而CNN可以通过卷积运算提取出面部表情多种复杂的局部特征,并在全连接层利用权值重构出全局特征图。考虑到自建数据集数目的大小,此处不适合采用层数过深的网络模型。本文在基于MobileNetV2的基础上,进行以下调整:
(1)去除原始网络中最后一个卷积层,用包含100个神经元的全连接层替代,用于提取出全局特征;
(2)增添一个随机丢弃层(Dropout),并将失活率设置为0.5,避免小样本数带来的过拟合现象。
最终网络结构如表1所示。

表1 调整后的网络结构Table 1. Network structure after adjustment
在表1中,n表示倒置残差块的重复频次。其中,每一个反向残差块都由图6所示结构组成,DW为深度可分离卷积,BN为批标准化。

图6 反向残差块结构组成Figure 6. Reverse residual block structure composition
2.3 支持向量机分类
将MobileNetV2在全连接层输出的100维全局特征向量与降维后的100维LBP特征融合,作为SVM的输入。
SVM被用于多分类时,需要先建立适宜的多类分类器。本文采用一对一法,任意两类之间构造一个子分类器,合并所有子分类器并利用投票法进行归类。
由于模型提取出的特征维数以及分类样本数量较少,因此选用高斯核函数进行映射。高斯核专门用于解决线性不可分的情形,其计算式为
k(x,y)= exp(-γ‖x-y‖2),γ>0
(5)
式中,x、y为输入向量;γ为高斯核唯一超参数;‖x-y‖为两类样本向量之间的模。
3 实验结果与分析
3.1 数据集选取与预处理
由于婴幼儿表情的种类、特征皆与常规数据集不同,所以本文采用自建的数据集对婴幼儿表情进行实验验证。部分样本如图7所示。

图7 自建数据集部分样本Figure 7.Partial samples of self-built data set

图8 成人表情数据集部分样本Figure 8.Partial samples of the adult expression data set
3.2 实验结果
在自建数据集中,选取其中77张样本作为测试集,得到误检数为11张,平均正确率为85.71%。混淆矩阵如图9所示。

图9 婴幼儿表情数据集混淆矩阵Figure 9. Infant expression data set confusion matrix
由图9可知,文中所提方法对生气、开心、中性表情的识别率在85%以上,对睡眠的识别达到了100%的正确率。但该方法对难过与惊恐表情的识别率相对较低,误检数都为3次。难过表情被错误识别为其他种类的次数最多,惊恐表情也多次被误认为是难过表情,说明在数据集中新模型无法有效地区分难过这类表情的特征,这也是造成识别率低的主要原因。部分错误样本如图10所示。

图10 自建数据集错误样本Figure 10. Error samples of self-built data set
图10中,第1张图由于婴幼儿的面部自带了一定的偏转角度,因此不是一张完全的正脸图,导致产生识别错误;第2张图由于在预处理时经过了重组放大操作,导致分辨率较低,产生误识别;右侧图中,由于婴幼儿表情表达不充分,仅仅在眼睛周围纹理体现出差异性,从而导致识别错误。

表2 公开数据集下的表情识别率Table 2. Expression recognition rate under open data set
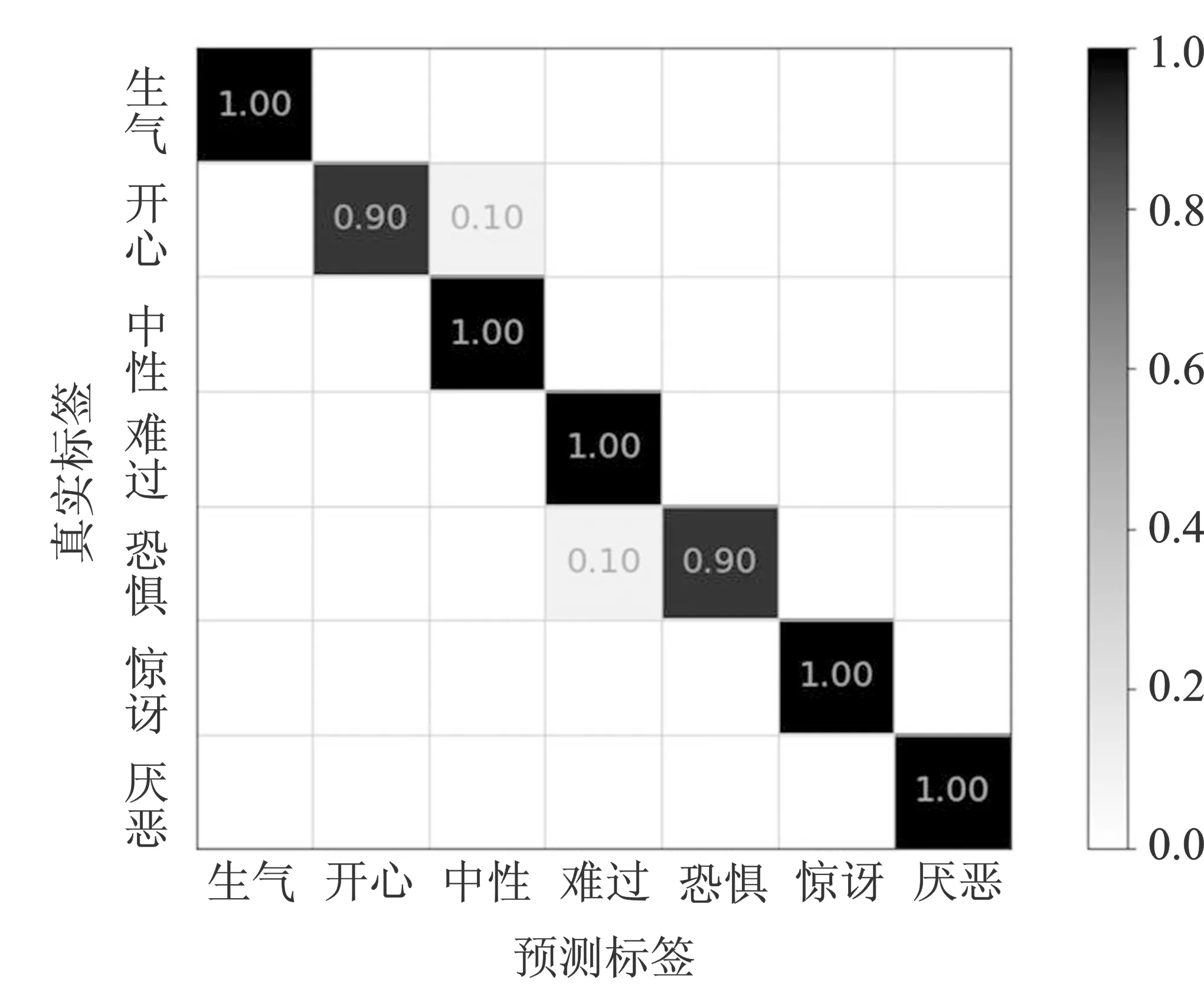
图11 JAFFE数据集下的混淆矩阵Figure 11. Confusion matrix under the JAFFE data set

图12 C数据集下的混淆矩阵Figure 12. Confusion matrix under the C data set

图13 C数据集错误样本Figure 13. C data set error samples
图13中,左1和左2图片被误判的原因在于受试者没有将表情充分表达,未能在两种表情之间呈现出明显的差异性;右1及右2图片中,由于惊讶与恐惧、厌恶与生气表情之间的差异较小,仅在部分五官周围的纹理区域存在一些变化,导致真实表情被混淆为相近的表情。
3.3 模型比对
为了深入验证本文模型的分类优势,本文依次删除部分主要功能结构,再进行比对,实验结果如表3所示。
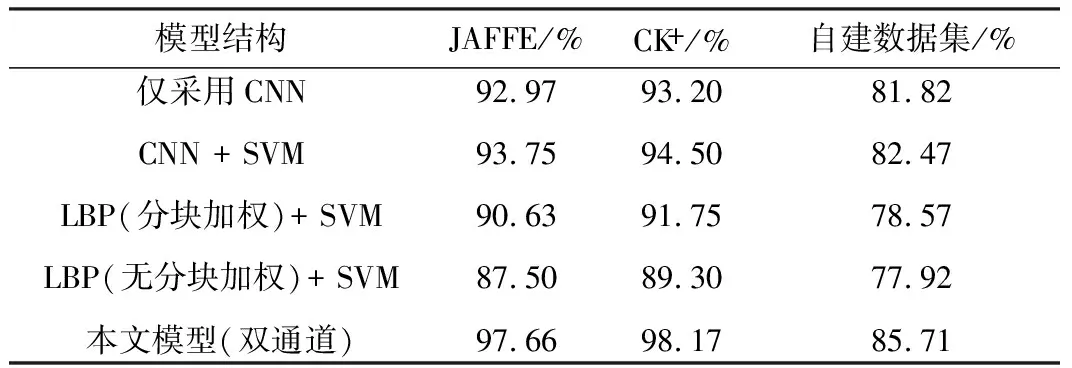
表3 不同模型结构下的准确率Table 3. Accuracy under different model structures
通过前两组实验可以看出,采用SVM模型代替Softmax分类层,能够增加模型的泛化能力,更适合小样本分类。后两组对比实验能够得出,分块加权后的LBP特征能够更充分地表达出面部表情的纹理特征,凸出差异性。融合CNN全局特征和分块加权LBP特征后得到的新特征拥有良好的表征能力,在3种数据集中均获得了最高的识别率。
将本文模型与其他现有方法在相同的两个公开成人表情数据集上的准确率以及网络参数运算量进行对比,结果如表4所示。

表4 不同方法识别率和参数运算量对比Table 4.Comparison of recognition rates and parameter calculations of different methods
实验表明,本文模型在所使用的成人表情数据集中,均获得了较高的表情识别率,且降低了参数运算量,减少了运行时间,表明本文模型更为轻量化。文献[5]中使用三通道并行VGG网络提取出人脸关键区域表情信息,参数量庞大,运算速率低,并且未能结合图像固有的特征属性,识别率还有待提高。文献[14]仅采用手工设计的特征进行分类,前期处理较为繁琐。文献[15~17]虽然有效结合深度学习网络与纹理特征,但网络模型结构复杂,计算量大,不适合对小样本数据的学习。
4 结束语
本文提出一种基于MobileNetV2与LBP特征融合的婴幼儿表情识别算法,结合CNN自适应提取特征和传统人工设计特征的优势,并利用SVM对小样本数据进行分类识别,不仅有效提高了对婴幼儿这个指定群体的表情识别率,而且其对成人表情也具有较好的分类效果。
在今后的研究中,还需要加强本文所提模型对带有偏转角度的人脸表情的识别性能,并且使其能够对视频序列中的人脸表情进行实时分类,以提高识别准确度,扩展应用范围。
