基于深度时序卷积网络的功率放大器行为建模方法
2022-07-16周凡,赵轩,邵杰
周 凡,赵 轩,邵 杰
(南京航空航天大学 电子信息工程学院,江苏 南京 211106)
功率放大器作为辐射源发射机不可或缺的一个电路模块,直接影响着辐射源整体的性能。理想的功率放大器实现的是线性功率放大,但实际应用中,为了追求更高的效率,功率放大器内部晶体管常常工作在开关状态,因此实际的功率放大器系统中含有较多非线性成分[1]。功率放大器的行为建模是利用功率放大器的输入输出,实现一个非线性映射系统,用于模拟功率放大器的内部功能实现。此类研究有助于研究人员理解功率放大器内部非线性组成,并可帮助研究人员借助建模仿真来实现预失真技术[2],降低放大器的非线性失真。
早期的行为建模方法针对的是简单的电路系统或者窄带信号等应用场合,先后出现了无记忆多项式模型[3]、Saleh模型[4]和查找表(Look Up Table, LUT)[5]等无记忆建模方法。近年来,随着调制信号的多样化,辐射源由窄带信号不断向宽带信号过渡,功率放大器的非线性记忆效应带来的影响逐渐增加,早期的无记忆建模方法不再有效。Volterra级数作为Taylor级数的一种拓展[6],可用于建模带有记忆效应的非线性函数。文献[7]在数字预失真系统中使用了Volterra级数建模所使用的RF放大器,使得系统中的闭环估计器收敛到了稳定状态。但Volterra级数建模参数量会随着预置的非线性层数增加而快速上升,对于强非线性系统,存在参数爆炸等问题[8]。
目前,神经网络建模已成为该领域的主流研究方向[9-16]。文献[9]将径向基神经网络(Radial Basis Function Neural Network,RBF-NN)用于功率放大器的记忆建模。文献[10]和文献[11]分别提出的Elman网络模型和Jordan模型也可实现类似的建模结果。但此类方法都无法接收较长的序列,且该网络只具备一层隐含层,模型复杂度较弱,导致建模精度较低。为了解决可变输入和记忆问题,动态神经网络被引入到功率放大器行为建模领域中。文献[12]采用深度残差递归神经网络(Deep-Residual Recurrent Neural Network,DR-RNN)建模了非线性动力学系统,显著提高了建模精度。作为RNN的一种改进网络,文献[13]中采用长短时记忆神经元(Long-Short Term Memory,LSTM)神经网络对5/6G宽带功放实现了动态非线性建模,证明该类方法具有良好的泛化性[13]。文献[14]考虑到单独的LSTM网络在建模时存在效率问题,故将部分网络改为多层感知机结构。该方法虽然提升了建模精度和效率,但并未从根本上解决效率问题。得益于自回归结构,动态神经网络能充分保留记忆特性,提高整体的建模精度,但其迭代效率会大幅降低。
为了解决现有建模方法的不足,本文提出一种基于深度时序卷积网络(Temporal Convolutional Network,TCN)的功率放大器行为建模方法。
1 卷积神经网络模型
卷积神经网络(Convolutional Neural Network,CNN)是一种深度前馈神经网络,其在特征处理上具有特征平移不变性和旋转拉伸不变性,被广泛应用于各类图像处理、信号处理问题。不同于人工设计的特征提取器,CNN通过数据迭代修正权重,具有针对性,可以避免人工设计的不足[17]。CNN基本结构包括:输入层、卷积层、池化层以及全连接层。

图1 CNN基本组成 Figure 1. Basic structure of CNN
输入层是输入数据进入的端口,该层的形状需要与输入数据相匹配。卷积层是CNN的核心结构,数据流在传递过程中,会与卷积层中的多个卷积核进行卷积以提取出高层特征。卷积核的维度与输入数据流的维度相匹配。池化层一般连接在卷积层之后,用于抽象出当前特征簇中的有效特征。全连接(Fully Connected,FC)层作为CNN最后一层,实现了特征簇到输出数据的非线性变换。
为了将CNN应用到功率放大器建模中,需要作出一个假设:功率放大器当前的输出只取决于有限时长的历史输入数据。基于当前的假设,当输入为有限时长的数据序列时,可以判定序列中已经包含了所有跟当前输出有关的信息量,则可以根据序列前有限时长的数据来预测当前的输出。实际建模中为了降低特征损失,提高生成数据精度,需要删除网络结构中的池化层,然而这种方案会成倍增加网络深度,不适用于长记忆效应的系统建模。此外,传统CNN建模方法属于单向多输入单输出模型,一旦确定了网络结构,输入数据的形状也随之确定,无法处理变长数据。
2 深度时序卷积网络原理与实现
深度时序卷积网络解决了传统CNN建模方法中的诸多缺点。针对无法保留长记忆的问题,其内部单元采用了因果膨胀卷积来大幅拓宽网络的感受野。在应对深度网络的弊端方面,采用残差结构来减少梯度弥散等问题。为了能处理变长数据,采用一种并行卷积计算结构,实现了类似RNN的灵活数据处理能力。
2.1 膨胀卷积
为了提取更长时间的历史信息,需要定义足够的有限时长,但是过长的输入会导致构建的卷积神经网络层数过深。采用膨胀卷积(Dilated Convolution)[18]结构可以在保证感受野不变的情况下大幅减少网络层数。膨胀系数为4的膨胀卷积示意图如图2所示。
图2 四倍膨胀卷积示意图Figure 2. Quadruple dilated convolution
原始数据经过长度为3的卷积核之后,生成了第2层特征数据,然而第3层的输出数据并非由紧密相连的第2层特征卷积得到,而是由固定间隔点的特征卷积而来,间隔的点数加一,即为膨胀系数。此种卷积方式可以在网络深度不变的前提下,大幅增加当前输出点的感受野。
若常规一维卷积中卷积核长度为K,则单次卷积的感受野大小也为K。采用膨胀系数为d、卷积核长度为K的膨胀卷积,则单次卷积的感受野大小Kd如式(1)所示。
Kd=d×(K-1)+1
(1)
式(1)表明,单次膨胀卷积相比于常规卷积,其感受野的大小增加了约d倍,且随网络层数成指数型增长。
2.2 因果卷积

图3 因果卷积示意图Figure 3. Causal convolution
2.3 残差结构
增加网络深度可以提高行为建模的非线性拟合能力,但网络层数过深,会带来网络梯度消失、训练缓慢和训练结果过拟合等问题,导致网络建模能力下降。为了减少网络层数带来的影响,需要向深度时序卷积网络中引入残差结构。
残差结构源于残差网络(Residual Neural Network,ResNet)[20]。文献[20]中搭建了层数达152层的超深度神经网络,其网络中的核心设计就是残差结构。残差结构在卷积网络中引入了直连通道,基本结构如图4所示。
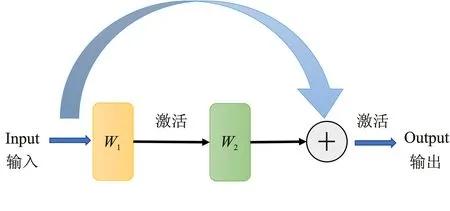
图4 残差结构示意图Figure 4. Residual structure
输入Input经过W1与W2两层变换之后,与自身拼接,拼接的结果再经过激活函数,即可得到输出。这种设计思路既保留了输入中的原始信息,也增加了非线性变换成分。在网络层数加深后,原始输出可以借助直连部分直达最终输出,保证了整个信息传递过程中信息的完整性。在反向传播时,此类直连通道可以直接传递梯度,提高梯度反馈效率,降低学习成本。
2.4 时序卷积块
本文提出的网络由多个时序卷积块(TCN Block)级联而成,单个时序卷积块内部包含数层因果膨胀卷积以及残差结构。图5为一个3层时序卷积块卷积流程示意图,每个卷积层的输出特征长度与输入长度相同,不足部分通过补零对齐。其中,虚线箭头与实线箭头所示的计算流程是同时进行的。CNN的特征可以打乱重组,但在时序卷积块中,每个时间点的特征簇对应了当前时间点的高维特征,需严格按照时序排列,遵循因果性。卷积计算以特征层方向进行。由于每层特征的长度与输入相同,所以对输入数据的长度没有固定要求。对比现有建模方法中所有CNN网络均采用多输入单输出的序列生成方式,本文方法在效率及灵活性具有一定的优势。
并行计算提高了网络计算速度,但会带来庞大的中间参数量,本文网络的中间参数量随处理的时间序列的长度增长而增大。此外,网络深度也会影响中间参数的数量。本文通过计算上的技巧减少了所需中间参数量:在每层迭代完成之后,会生成新的高维特征序列。由于旧的特征序列不再使用,可以通过清空操作来删除,每次迭代只需保留一层的网络特征数据,避免了网络深度对于总体参数量的影响。
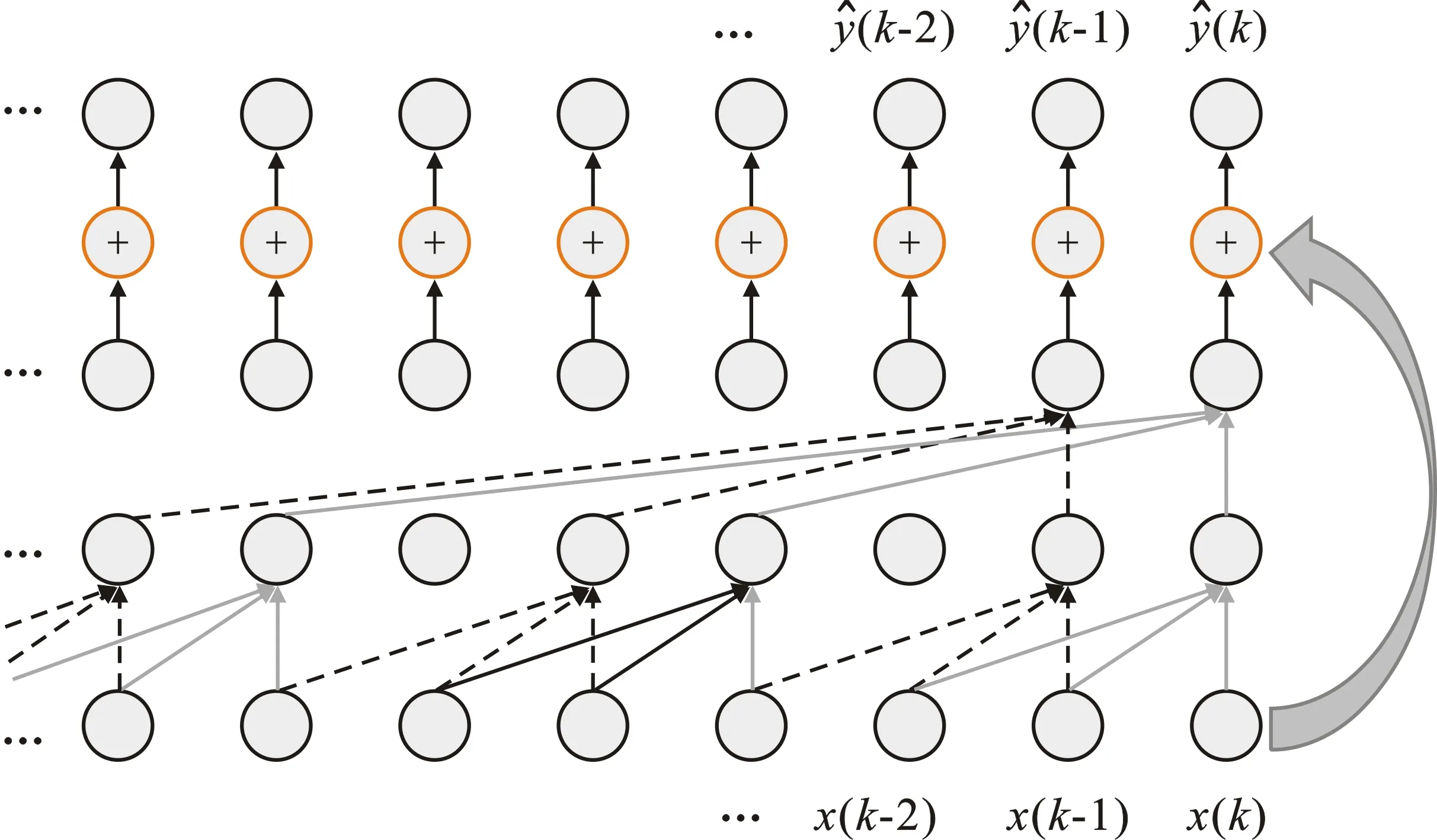
图5 3层时序卷积块卷积流程示意图Figure 5. Convolution process of three-layer TCN block
2.5 与RNN以及LSTM网络的对比
现有的主流方法为RNN以及LSTM网络,但该类网络是动态神经网络,每个时间步的迭代都需要上个时间步的数据作为输入,构成自回归。因此,该类网络在实现速率上较为低效。此外,RNN一直存在的问题是当时间步过长时,遥远时间点的历史信息会随着多次迭代弥散或呈爆炸增长,难以被训练,即使引入门控机制的LSTM网络,也无法完全避免。
深度时序卷积网络的每步输出是同时进行的,该特性使得深度时序卷积网络无论在网络训练还是最终的序列生成上,都要比动态神经网络更快。而在历史信息稳定度上,本文提出的网络内部主要结构是卷积层。卷积操作对于每个输入值都是等价的,且迭代次数固定,因此几乎不存在历史信息弥散或爆炸等问题。
3 实验结果分析
3.1 实验数据集
本文中的功率放大器电路采用的是半桥式D类功率放大器,其电路原理如图6所示。行为建模的实验数据由电路图对应的实际电路板前后级采样获得。

图6 半桥式D类功率放大器电路图Figure 6. Half bridge D-class power amplifier circuit diagram
3.2 深度时序卷积网络实例
本实验中所采用的深度时序卷积网络由8个时序卷积块构成,如图7所示。每个卷积块的输出特征维度分别为[4 8 16 32 64 128 64 1],单个卷积块的内部是一个“卷积→裁切→激活→卷积→裁切→激活 ”的3层结构,输出结果与原始输入构成残差后,经过线性激活得到最终的卷积块输出数据。Conv为因果膨胀卷积,用于拓展感受野和提取输入特征。Slice为数据裁切操作,用于把输入输出数据对齐。激活函数采用双曲正切函数(Tanh),这是因为该网络功能是实现数据回归,需要输出准确数值,所以不能用线性整流函数[21](Rectified Linear Unit, ReLU)以免截断梯度。输入输出均包含正负数据,因此也不能使用S型函数(Sigmoid Function)。残差直连通道处的Conv用于改变输入数据形状,以匹配输出,便于合并数据。

图7 深度时序卷积网络结构Figure 7. Deep temporal convolutional network structure
模型损失函数采用均方误差(Mean Square Error,MSE)损失,其计算方法如式(2)所示。MSE损失是回归问题中最常用的损失函数之一。梯度优化策略则采用Adam算法[22]。
(2)
所有实验测试均在表1所示的软硬件平台上实现。

表1 硬件和软件配置Table 1. Hardware and software configuration
实验测试采用四折交叉验证的方式进行,每次测试时将模型参数初始化,取75%数据作为训练集,余下25%数据用于测试并记录结果,最终结果取4次测试的平均结果。
3.3 实验结果分析及与现有方法的对比
本文复现了文献[7]、文献[12~13]中的行为建模方法,并将本文提出的行为建模方法与上述已有建模方法(使用3层记忆深度的3阶Volterra级数、包含128个隐含单元的双层RNN网络、包含128个隐含单元的双层LSTM网络)进行对比,实验时域结果如图8所示。
图中结果表明:(1)Volterra级数建模方法的行为建模精度最差,无法准确还原预期的输出波形,整体偏差较大,最大误差高达7 V;(2)RNN网络建模结果跟随性良好,但在一些特殊位置存在比较突兀的转折,出现较大误差;(3)LSTM网络建模结果与RNN类似,但整体误差更小。此外,RNN网络和LSTM网络建模的结果均无法拟合出细节处的高频分量;(4)本文提出深度时序卷积网络的结果精度最高,无论在整体信号跟踪还是细节处的高频分量上都取得了良好的效果。
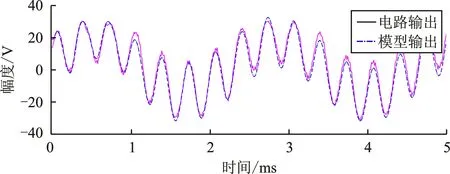
(a) (b)

(c) (d)图8 行为建模时域波形对比
图8对应的时域均方误差如表2所示。
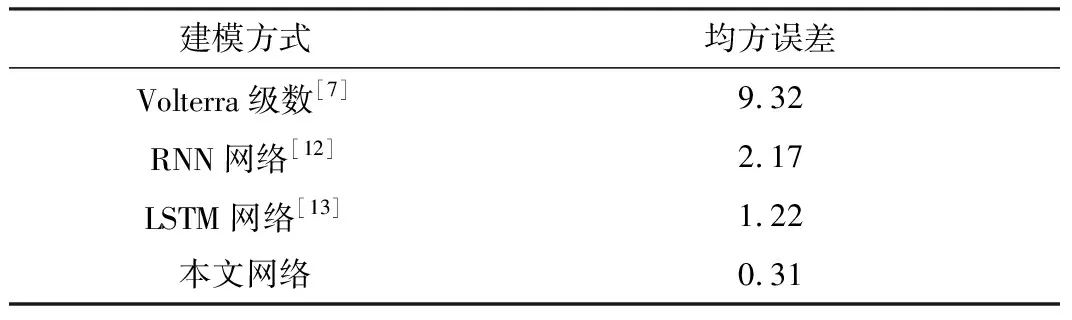
表2 时域均方误差对比Table 2. Comparison of time domain MSE
均方误差大小代表了建模数据与预期结果偏离程度,可以定量判定建模结果的准确性。Volterra级数建模数据偏离程度最大,均方误差高达9.32。RNN网络建模结果精度有所提高,均方误差为2.17。相较于RNN网络,LSTM网络建模的精度又有了一定的提高,但提升幅度不大,均方误差为1.22。本文提出的建模方法,均方误差相比于前两种,下降了一个数量级,仅为0.31,表现出了优良的性能。
对于开关型功率放大器,频率的准确度直接影响下级电路输出波形失真度。图9为4类建模方法行为仿真波形的频谱对比图,该结果与时域结果类似。Volterra级数建模的波形在频谱上存在较大的误差。RNN和LSTM网络建模的波形在主峰处的频谱拟合度较高,谐波处误差偏大,超过了10 dB,与时域图上跟踪性较好、细节处拟合差的建模结果相吻合。本文提出的方法,建模数据的频谱除了在频谱边缘处(即高频区域)存在较大误差外,其他频率处误差较小,均未超过5 dB。

(a) (b)
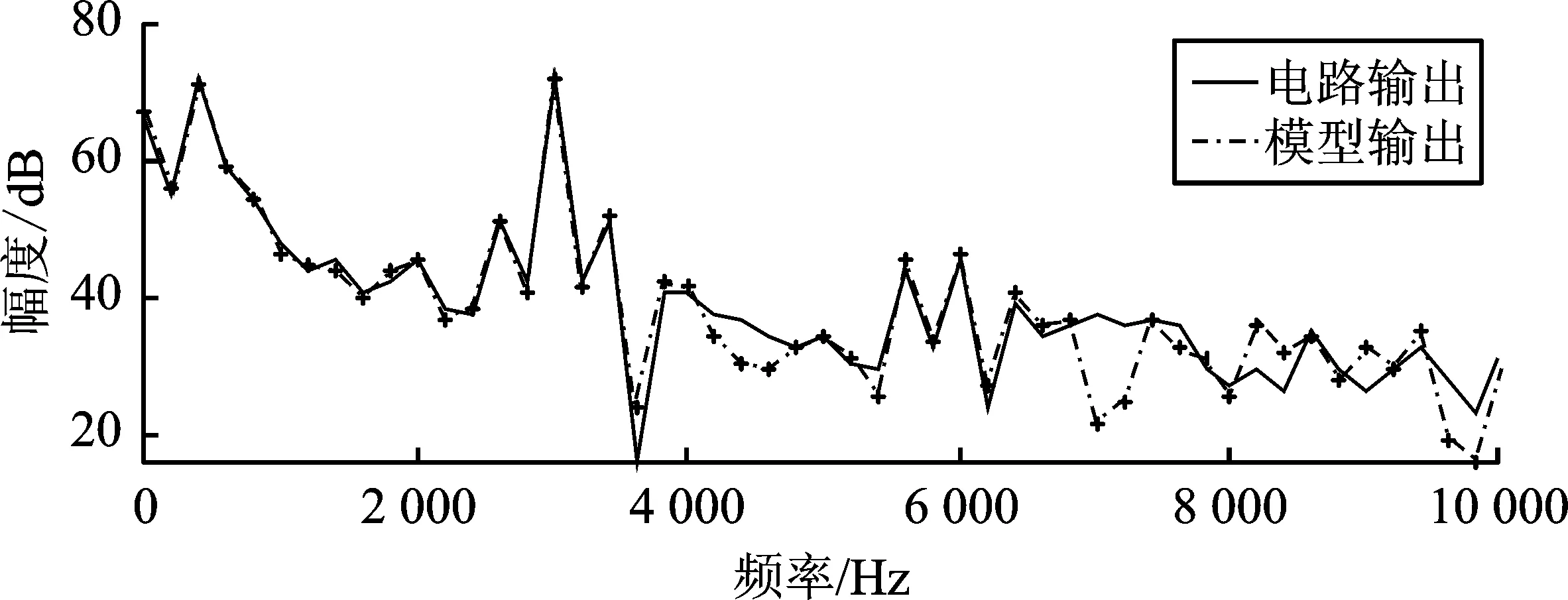
(c) (d)图9 行为建模频谱结果对比
模型的空间复杂度和时间复杂度也是衡量模型性能的标准之一。鉴于Volterra级数建模效果较差,所以此处不作对比,其余3种方法的参数量以及单次迭代时间如表3所示。从表3中可以看出,RNN以及LSTM网络虽然参数量差距较大,但是单次训练集训练迭代时间无明显差距,主要的时间损耗出现在动态神经网络时序迭代的过程中;对于本文提出的建模方法得益于并行卷积,虽然参数量与双层RNN网络相当,但单个训练集迭代时间低至0.061 04 s,效率高于动态神经网络建模方法。
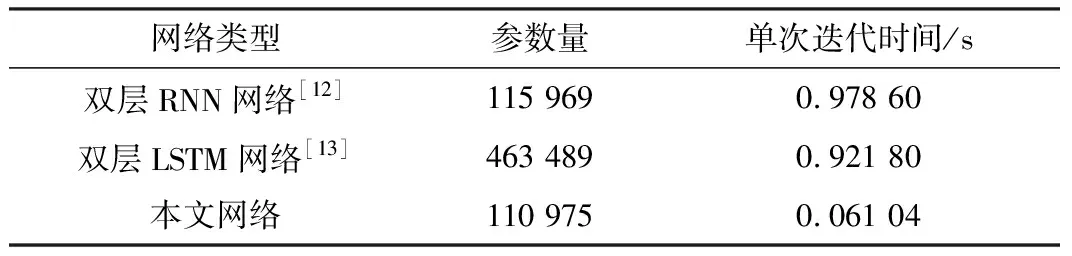
表3 建模方法的参数量和单次迭代时间对比Table 3. Comparison of parameters and single iteration time of modeling methods
4 结束语
基于神经网络的功率放大器行为建模方法相比于传统方法,有着较高的建模精度。现有的研究方案大多采用动态神经网络建模,通过引入历史信息机制来保存记忆信息,但此类动态神经网络受限于历史信息的自回归机制,训练和预测十分缓慢。本文提出的深度时序卷积网络行为建模方法实现了一种全新的行为建模方法。该方法通过因果膨胀卷积,实现了长记忆信息的提取,并利用卷积并行操作,加速了网络迭代速率。本文所提方法在速度和精度上,均优于现有的建模方法,可为快速搭建电路的行为模型以及高速预失真补偿提供参考。然而,深度时序卷积神经网络只能处理有限记忆效应,对于深度记忆系统,还需要进行方法上的改进。
