面向神经机器翻译的正向翻译与反向翻译相结合的改进方法
2022-07-15吴章淋魏代猛李宗耀於正哲商恒超陈潇雨郭嘉鑫王明涵雷立志陶士敏
吴章淋,魏代猛,李宗耀,於正哲,商恒超,陈潇雨,郭嘉鑫,王明涵,雷立志,陶士敏,杨 浩,秦 璎
(华为文本机器翻译实验室,北京 100038)
近年来,神经机器翻译(neural machine translation,NMT)[1]已经取得了巨大的进步,相较于传统的统计机器翻译[2],NMT展现出更加卓越的性能和更强的适应性.然而,NMT是一种数据依赖的方法,通常需要利用大量数据才能训练得到性能良好的NMT模型.在现实中,相比于庞大的单语数据量,高质量的双语数据比较有限,因此,如何有效地利用单语数据成为了NMT的重要研究课题.
目前,源语言和目标语言单语数据已被证明可用来改进NMT,但如何更有效地同时使用源语言和目标语言单语数据还需进一步地研究.为此,本文提出了一种基于集束搜索的正向翻译和基于最优N随机采样的反向翻译的组合方法.为验证该方法的有效性,在第十七届全国机器翻译大会(CCMT 2021)汉英和英汉新闻领域的翻译评测任务上,与其他常用的几种单语数据增强方法进行对比实验.此外,本文还探究了领域知识迁移[3]后该方法的有效性,并分析了单语数据规模对该方法的影响和该方法对困惑度的影响,以及该方法是否能提升不同类型源句的翻译质量.
1 相关工作
基于反向翻译的单语数据增强方法最早由Sennrich等[4]提出,具体地,在真实双语数据上训练目标语言到源语言的NMT模型,用该模型将目标语言单语句子翻译成源语言句子,构造伪双语数据,然后利用伪双语数据与真实双语数据联合训练源语言到目标语言的NMT模型,从而达到提升源语言到目标语言的NMT模型翻译质量的效果.随后,Burlot等[5]对反向翻译进行了系统的研究,再次证实了反向翻译是非常有效的.
在反向翻译的解码策略方面,Edunov等[6]指出基于集束搜索的方法受源句类型的影响,只能提升源句为翻译腔类型时的翻译质量,并表明了基于集束搜索加噪声和基于随机采样的翻译性能均优于基于集束搜索的方法.在使用基于集束搜索的解码策略时,Caswel等[7]表明了加噪声的方法提升反向翻译效果的原因是使NMT模型在训练过程中能够有效区分伪双语数据和真实双语数据,并提出了基于集束搜索加标签的方法,该方法使用额外的标签标记伪双语数据的源端,其效果好于基于集束搜索加噪声的方法.而在使用随机采样的解码策略时,往往会存在低质量采样句子的问题,因此,Graça等[8]提出了基于最优N随机采样的改进方法,通过限制采样空间的方式,提高伪双语数据的质量.
在反向翻译的训练策略方面,Hoang等[9]提出迭代式反向翻译的方法,利用反向翻译增强后的模型重新进行反向翻译,通过迭代的方式逐步提升NMT模型的翻译质量.Abdulmumin等[10]则提出了一种不需要加标签的反向翻译方法,将伪双语数据用作域外数据预先训练模型,然后使用真实双语数据作为域内数据来微调预训练的翻译模型,旨在通过预训练和微调,使模型能够有效地从这两个数据中学习.Jiao等[11]也提出了一种交替训练的反向翻译方法,其基本思想是在训练过程中迭代地交替伪双语数据和真实双语数据.
当目标语言单语数据已被证明通过反向翻译改进NMT的翻译质量非常有用时,Zhang等[12]提出了正向翻译的方法,采用自学习算法生成源语言单语数据对应的伪双语数据,用于与真实双语数据联合训练,提升NMT模型的翻译质量.值得注意的是,其实验结果表明,源语言单语数据并不总是改善NMT,正向翻译只有使用密切相关的源语言单语数据才可以获得更好的翻译质量,当使用更多不相关的源语言单语数据时,会导致翻译质量下降.Wu等[13]对如何同时使用源语言和目标语言单语数据促进NMT的翻译质量进行了研究,提出了基于集束搜索的正向翻译和反向翻译的组合方法,实验结果表明,源语言和目标语言单语数据混合使用是一种有效的方法,其效果优于单独使用源语言单语数据或目标语言单语数据,且NMT模型的翻译质量可以随着单语数据的增加而不断提升.
2 方 法
2.1 NMT模型
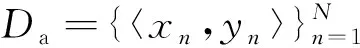
2.2 正向翻译
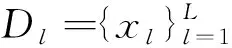
首先,基于真实双语数据Da训练一个源语言到目标语言的NMT模型:
然后,利用源语言到目标语言的NMT模型翻译源语言单语数据Dl(l=1,2,…,L):

在翻译源语言单语数据时,通常采用基于集束搜索解码的方式.尽管源语言单语数据与真实双语数据共享源语言词汇表,并且无法生成新的单词翻译,但源语言单语数据提供了词汇表中单词的更多排列.使用真实双语数据和源语言伪双语数据联合训练,可以泛化NMT模型的编码能力,从而提升NMT模型的翻译质量.
2.3 反向翻译
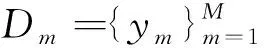
首先,基于真实双语数据Da训练一个目标语言到源语言的NMT模型:
然后,利用目标语言到源语言的NMT模型翻译目标语言单语数据Dm(m=1,2,…,M):
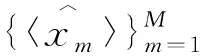
在翻译目标语言单语数据时,有两种解码方式,即基于集束搜索解码与基于随机采样解码的方式.基于集束搜索解码的方式[4]侧重于翻译出最可能的结果,会导致伪双语数据的多样性较差,直接使用这类伪双语数据和真实双语数据联合训练,给NMT模型带来的提升效果可能会不明显.另外,由于伪双语的数据分布与真实双语的数据分布差距较大,通过加标签[7]或加噪声[6]的方法向模型表明伪双语数据是合成的,可以给模型提供更强的训练信号,从而实现更好的提升效果.而基于随机采样解码的方式[6]可以生成更多样化的伪双语数据,还可以通过最优N随机采样的方式[8]限制采样空间避免伪双语数据的质量过低,这种方式对模型的增强效果会比较明显.
2.4 正向翻译和反向翻译组合与改进

Wu等[13]提出的正向翻译与反向翻译的组合方法已经被证明优于仅使用正向翻译或反向翻译的方法,其在构造伪双语数据时,均采用基于集束搜索的解码方式.本文改进了组合方法中反向翻译的解码方式,增加了目标语言伪双语数据的多样性,提出了基于集束搜索的正向翻译和基于最优N随机采样的反向翻译的组合方法.
2.5 领域知识迁移、正向翻译与反向翻译组合与改进
领域知识迁移[3]是指,用一个更接近目标评测领域的小数据集对NMT模型进行增量训练,加强NMT模型对目标领域知识的理解,从而提升NMT模型在目标领域的翻译质量.先使用领域知识迁移方法,再使用本文提出的基于集束搜索的正向翻译和基于最优N随机采样的反向翻译的组合方法,可以更好地提升NMT模型在目标领域的翻译质量.
3 实 验
实验基于Pytorch实现的fairseq[14]开源框架,使用Wang等[15]提出的层归一化前置的Deep Transformer模型作为基准系统.其中,编码器层数设为25,解码器层数设为6,词向量维度设为512,隐层状态维度设为2 048,多头自注意力机制使用8个头.实验的其他主要参数设置如下,每个模型使用8块GPU进行训练,batch大小为2 048,参数更新频率设置为32[16],学习率为5×10-4,标签平滑率为0.1[17],warmup步数为4 000,采用了dropout机制,dropout设为0.1;使用Adam调优器[18]调优,参数设置为β1=0.9,β2=0.98.训练数据先分词再用双字节切分(BPE)[19]切分,源语言及目标语言的词表共享设定为32×103,汉语分词采用jieba,英语分词采用Moses[20].在推理阶段,本次实验采用Marian[21]工具进行解码,集束大小设置为10,汉英翻译实验的长度惩罚设置为1.2,而英汉翻译实验的长度惩罚设置为0.8.此外,在基于最优N随机采样制造伪双语数据时,使用的是fairseq进行解码,解码参数beam设为1,sampling设为True,sampling_topk设为10.
3.1 实验数据
本文使用CCMT 2021和WMT 2021汉英和英汉新闻领域机器翻译任务提供的双语和单语数据搭建NMT系统,表1为使用的详细数据情况.在数据预处理时,针对评测方发布的数据:一方面,采取多种不同的数据过滤方法减少数据噪声以提高训练数据的质量;另一方面,训练领域分类器以选取更接近新闻领域的数据,其具体做法为使用新闻单语和非新闻单语,分别训练汉语和英语的fasttext[22]二分类模型,用于打分排序挑选新闻领域数据.

表1 数据详情
3.2 主要实验结果
本文在CCMT 2021汉英和英汉新闻领域的翻译评测任务上对不同的单语数据增强方法进行了对比实验,评测指标采用sacrebleu[23],评测集为CCMT 2019测试集,表2为详细的实验结果.由于评测集有4个参考译文,本文在计算BLEU值时,分别选用了1个和4个参考译文,记为1ref和4ref.在表2中,Baseline为双语基线,NoiseBT为基于集束搜索加噪声的反向翻译方法,TagBT为基于集束搜索加标签的反向翻译方法,ST为基于最优N随机采样的反向翻译方法,FTBT为基于集束搜索的正向翻译和反向翻译的组合方法,FTST为本文提出的基于集束搜索的正向翻译和基于最优N随机采样的反向翻译的组合方法,DTFTST为使用领域知识迁移后的基于集束搜索的正向翻译和基于最优N随机采样的反向翻译的组合方法.
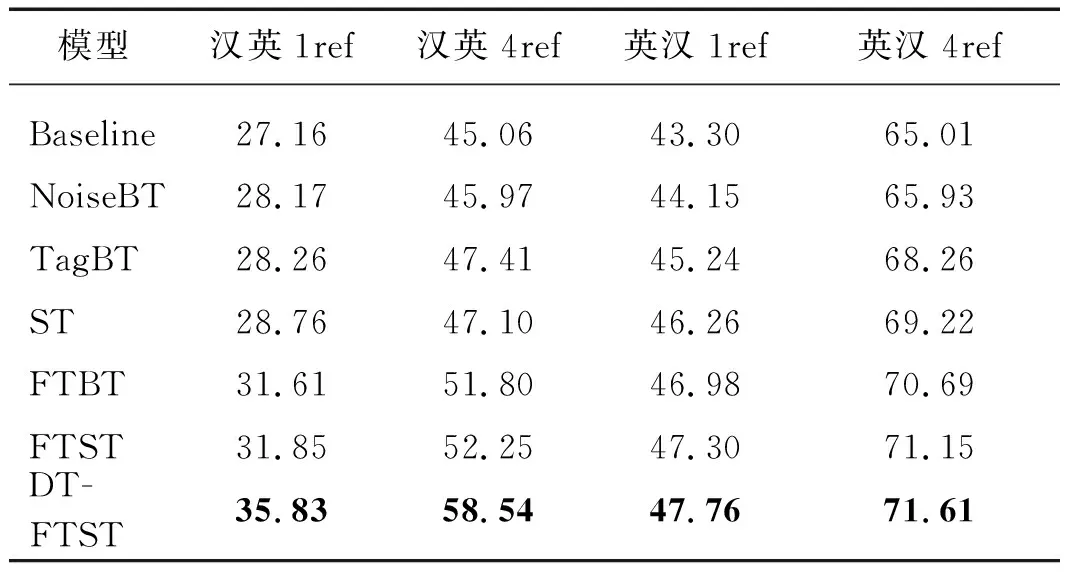
表2 不同单语数据增强方法的BLEU值
从CCMT 2021汉英新闻领域机器翻译和英汉新闻领域机器翻译任务上的实验结果来看,与其他常用的几种单语增强策略(NoiseBT、TagBT、ST和FTBT)相比,本文提出的FTST取得了最显著的增强效果.与双语基线相比,FTST模型在汉英和英汉CCMT 2019测试集1ref上的BLEU值均提升了4个百分点以上.此外,DTFTST在FTST的基础上取得了更进一步的翻译质量提升,特别是在汉英翻译上,提升比较明显.与FTST相比,DTFTST在汉英1ref上的BLEU值进一步提升了3.98个百分点.DTFTST方法在汉英和英汉翻译上提升幅度不一致,这一现象主要是因为使用领域小数据集在汉英和英汉模型上进行增量训练时带来的收益有差异导致的.
4 分 析
4.1 单语数据规模的影响
单语数据规模往往影响着单语数据增强方法对NMT模型的提升效果.本文提出的FTST是在Wu等[13]的工作上进行的改进,因此,本文探究了在不同单语数据规模下,FTST方法是否能始终优于Wu等[13]提出的FTBT.此外,本文也探究了单语数据规模对FTBT和FTST方法的影响,因为Wu等[13]的工作表明,FTBT方法可以随着单语数据的增加而不断提升NMT模型的翻译质量.具体地,本文在16.5×106双语基础上,分别选取了40×106、80×106、160×106以及300×106单语数据(其中,源语言单语和目标语言单语各占一半比例),然后分别使用FTBT和FTST方法增强NMT模型.图1给出了不同数据规模下汉英和英汉翻译任务上使用CCMT 2019测试集源句与参考译文1进行评测的结果.实验结果表明,在不同单语数据规模下,FTST方法始终优于FTBT方法.此外,使用FTST方法时,随着单语数据规模增大,NMT模型的翻译质量并没有一直提高,甚至还会略微下降,这似乎与Wu等[13]的实验结果相反.本文分析,增加单语数据规模并没有提升翻译质量有可能是因为中文单语大部分是与测试集不相关的Common Crawl数据导致的.因为Zhang等[12]的工作表明,单语数据并不总是改善NMT,只有使用密切相关的单语数据才可以获得更好的翻译质量,当使用更多不相关的单语数据时,会导致翻译质量下降.

图1 不同单语数据规模的对比结果Fig.1 Comparison results of different scale monolingual data
4.2 对困惑度的影响
困惑度是语言模型效果好坏的常用评价指标,在测试集上得到的困惑度越低,说明语言模型的效果越好.本文探究了FTST在提升NMT模型翻译质量的同时对困惑度的影响.图2为参考译文的困惑度与不同NMT模型在CCMT2019测试集上译文的困惑度,其中,译文困惑度由所有句子困惑度的平均来表示,而句子困惑度由KenLM[24]工具计算.结果表明,与其他常用的单语数据增强方法一样,基于集束搜索的正向翻译和基于最优N随机采样的反向翻译的组合方法在提升NMT模型翻译质量的同时也增加了困惑度.本文分析,困惑度增加是因为参考译文本身的困惑度比较高,单语数据增强后的NMT模型得到的译文虽然困惑度提高了,但与参考译文更加接近了.
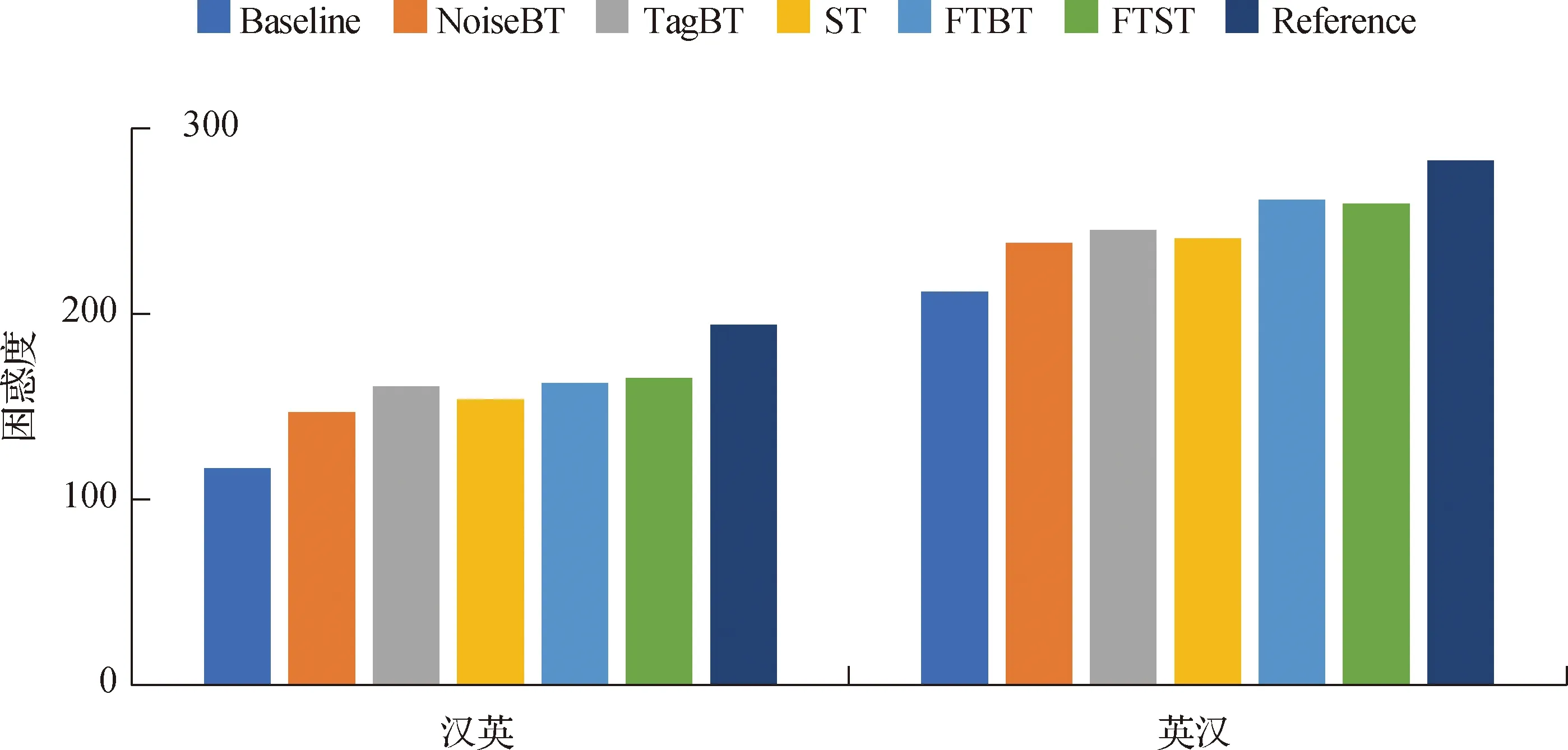
图2 不同NMT模型译文的困惑度Fig.2 The perplexity of translation of different NMT models
4.3 源句类型的影响
测试集的源句可以按创建来源分为两种不同的类型,即翻译腔类型与非翻译腔类型,前者来源于人工翻译,后者来源于自然文本.Edunov等[6]指出,基于集束搜索的反向翻译方法只能提升源句为翻译腔类型时的翻译质量,而当句子为非翻译腔类型时,该方法并不提供任何改进.因此,本文探究了FTST以及其他常用的单语数据增强方法是否也受源句类型的影响,表3为选用CCMT 2019测试集源句和参考译文1做评测的实验结果.其中,X和Y为非翻译腔类型文本,X*和Y*为翻译腔类型文本,以汉英模型为例,X→Y*是指测试集采用汉英测试集,X*→Y是指测试集采用英汉测试集.结果表明,与其他常用的单语数据增强方法一样,基于集束搜索的正向翻译和基于最优N随机采样的反向翻译的组合方法不受源句类型的影响,即不论源句是否为翻译腔类型,均能有效提升NMT模型的翻译质量.

表3 不同类型测试集的对比结果
5 总 结
本文提出了基于集束搜索的正向翻译和基于最优N随机采样的反向翻译的组合方法(FTST),并在CCMT 2021汉英和英汉新闻领域机器翻译任务上与其他单语数据增强方法进行了对比实验.结果表明,在大规模单语数据场景下,与其他常用的单语增强方法相比,FTST可以取得更优的效果,而且在使用该方法之前,先进行领域知识迁移还可以进一步取得翻译质量的提升.此外,还分析了单语数据规模对该方法的影响和该方法对困惑度的影响,以及该方法是否能提升不同类型源句的翻译质量.
