基于国密SM9 的可搜索加密方案
2022-07-14张超彭长根丁红发许德权
张超,彭长根,3,丁红发,许德权
(1.贵州大学计算机科学与技术学院 公共大数据国家重点实验室,贵阳 550025;2.贵州大学 密码学与数据安全研究所,贵阳 550025;3.贵州大学 贵州省大数据产业应用发展研究院,贵阳 550025;4.贵州财经大学 信息学院,贵阳 550025)
0 概述
云存储技术的快速发展使得人们存储、管理大量数据更加便捷,但是数据面临泄露风险。为保护云服务器中的数据隐私,云存储技术通常对原始数据进行加密,把加密后的密文数据上传至云服务器,但是会给使用数据的用户带来不便。例如,当用户需要检索数据时,需要将全部密文数据下载到本地,在本地解密之后再执行检索操作。为更好地解决云数据的安全问题,可搜索加密(Searchable Encryption,SE)技术应运而生,并得到研究人员的广泛关注。SE 技术允许云服务器在密文场景下进行安全检索,并将满足检索条件的密文数据返回给用户,最后由用户在本地将检索结果解密,从而获得自己需要的明文数据。
本文结合SM9 算法构造基于身份的可搜索加密方案。根据非对称双线性对的特性,同时结合SM9加密算法的密钥形式,设计相应的索引生成算法、陷门生成算法和服务器检索匹配算法。基于可证明安全理论,验证该方案在随机谕言模型下满足密文不可区分性和陷门不可区分性。
1 相关工作
文献[1]首次提出对称可搜索加密(Symmetric Searchable Encryption,SSE)的概念,解决在密文环境下的搜索难题,实现了在对称密码体制下密文的搜索。文献[2]基于布隆过滤器(Bloom Filter,BF)[3]设计满足安全索引的SSE 方案,将检索的时间复杂度改进为与文档的数目呈线性关系。SSE 的计算效率较高,适用于大部分第三方存储。文献[4]提出公钥可搜索加密(Public-key Encryption with Keyword Search,PEKS)方案,并基于文献[5]利用双线性对设计一个具体构造,适用于复杂的加密环境。PEKS 不用在发送者与接收者之间建立安全信道,因其实用性较强,而得到快速发展,其中基于身份加密的可搜索加密减少了建立和维护公钥基础设施(Public Key Infrastructure,PKI)的开销,因此成为该领域的研究热点。
文献[6]提出带关键字搜索的基于身份加密(Identity-Based Encryption with Keyword Search,IBEKS)方案,并给出一般化的转换方法,将任意的选择明文攻击模式下不可区分安全且匿名的IBE 方案转换为选择明文攻击模式下不可区分安全的PEKS 方案。文献[7]提出一种基于身份的关键字搜索加密方案,不需要安全通道,但要求服务器是可信的。文献[8]提出带关键字搜索的阈值公钥加密(Threshold Public-key Encryption with Keyword Search,TPEKS)和带分布式私钥生成器的基于身份匿名加密。文献[9]提出模糊关键词检索,可以防范内部敌手和外部敌手的关键词猜测攻击。文献[10]提出指定服务器的带关键字搜索的基于身份加密方案,该方案不需要额外的安全信道。文献[11]对可搜索加密进行探讨和总结。文献[12]提出一种具有隐藏结构的可搜索公钥密文(Searchable Public-key Ciphertexts with Hidden Structure,SPCHS),提高了关键字搜索效率。文献[13]对加密数据的关键字搜索技术进行研究,并对他们的效率和安全性进行分析。文献[14]提出基于公钥并且带身份验证功能的PEAKS 方案。文献[15]结合格理论提出一种基于身份的可搜索加密方案,可以抵抗量子计算机的攻击。文献[16]设计基于身份的关键词可搜索加密的广播加密方案,以防范内部敌手的攻击。文献[17]提出基于身份的指定服务器用于加密邮件的可搜索认证加密方案。文献[18]提出支持代理重加密的基于身份可搜索加密方案,支持搜索权限的高效共享。文献[19]提出基于身份的动态可搜索加密方案,可以删除指定身份的文件。文献[20]提出在电子邮件系统中指定服务器的关键字搜索加密方案。文献[21]提出一种基于生物识别身份的多关键字搜索(Biometric Identity-Based Multi-Keyword Search,BIBMKS)机制。文献[22]提出身份认证权威辅助的基于身份可搜索加密,在保持效率和安全性的同时,减少存储空间的开销。
上述方案为达到一定的安全级别,多是基于安全参数较大的对称双线性对,且在方案中多次使用双线性对运算,导致方案的计算效率降低。因此,通过优化方案设计,提高可搜索加密方案的检索效率和安全性成为研究热点。
从国家信息安全方面考虑,发展我国自己的加密算法势在必行。2016 年,基于身份的SM9 密码算法为国家商用密码行业标准(GM/T 0044—2016),并于2018 年11 月被纳入国际标准。SM9 密码算法的密钥长度为256 bit,采用运算速度快、安全性能高的R-ate 双线性对[23],可以有效减少Miller 算法循环次数,提高计算效率。近年来,SM9 密码算法作为基于身份的密码算法,受到越来越多的关注。
SM9 密码算法使用安全参数较小的非对称双线性对,用户的公私钥分别在两个循环群中产生,而现有的可搜索加密方案大多通过安全参数较大的对称双线性对来实现,计算效率相对较低[24]。由于用户密钥的形式不同,因此现有的可搜索加密方案并不能很好地与SM9 密码算法相结合。
SM9 密码算法在邮件系统、数据安全传输协议、物联网安全平台等场景中都有重要的应用,但由于缺少适应性强的可搜索加密方案,用户难以对这些加密数据进行检索,导致这些系统中的加密数据可用性较低。此外,通过为每个用户提供一对额外的密钥,以实现可搜索加密,但繁琐的操作流程会给用户的使用带来不便。为解决该问题,结合以上对SM9 密码算法的分析,本文设计基于SM9 密码算法的可搜索加密(SM9-based Searchable Encryption,SM9SE)方案。方案中用户的公私钥对分别在不同的子群中生成,其形式与SM9 密码算法的密钥对一致,因此用户可以用同一对密钥完成数据的加解密和密文检索操作,并且使用系统参数相对较小的非对称双线性对运算,从而提高计算效率。
2 基础知识
2.1 双线性对
假设n为正整数,(G1,+)和(G2,+)是两个n阶加法循环群,其零元分别记作O1和O2。又设(GT,g)为n阶乘法循环群,其单位元记为1T。假设在群G1,G2,GT上计算离散对数是困难的。

2.2 基于双线性对的困难性问题及假设
DBDH 假设:对于任何一个概率多项式时间敌手A,解决DBDH 问题的概率都是可忽略的,即Pr[0 ←A(Y)|β=0]-Pr[0 ←A(Y)|β=1]是可忽略的。
3 方案构造与安全模型
3.1 方案构造
本文方案使用的椭圆曲线及曲线参数与SM9 加密算法中所使用的参数一致。
本文SM9SE 方案由系统参数初始化算法、密钥生成算法、索引生成算法、陷门生成算法和检索匹配算法构成。
1)系统参数初始化算法SysSetup(λ),输入安全参数λ以生成一个基于循环群上的双线性对映射(G1∙G2)→GT,其中群G1、G2和GT的阶为大素数q。PKG 随机选择整数s∊[1,q-1]作为系统主密钥保密存储,然后计算系统公钥Ppub=sP1,P1为循环群G1的生成元,P2为循环群G2的生成元。此外,PKG 选择三个哈希函数。系统主密钥对为(s,Ppub),系统公共参数为
2)密钥生成算法UserKeyGen(ID,s),对于用户A的唯一身份标识IDA,以及系统主私钥s,PKG 在有限域FN上计算t1=H1(IDA)+s。若t1=0 则重新计算系统主密钥并更新已有用户的私钥,否则计算t2=s×
用户私钥dA=[t2]P2,用户公钥的计算方法为QA=[H1(IDA)]P1+Ppub=[t1]P1。
3)索引生成算法BuildIndex(IDR,w),对于接收者R 的唯一身份标识IDR以及关键字w。该算法随机选择r∊[1,q-1],计算并生成关键字对应的密文索引I=(I1,I2,I3),并将其发送给服务器。其中
4)陷门生成算法Trapdoor(w′,dR),文件接收者R运行该算法以生成检索陷门,输入要搜索的关键字w′和其私钥dR。该算法选择随机数t∊[1,q-1],然后计算陷门信息T=(T1,T2),并将其发送给服务器,其中T1=[t]Ppub,T2=[H2(w′)-t]∙dR,并且H2(w′)-t≠0,否则重新选取t。
5)检索匹配算法Test(I,T),由服务器执行,给定安全密文索引I=(I1,I2,I3)和陷门T=(T1,T2),服务器执行该算法来判断接收到的陷门信息与其存储的关键词密文索引信息是否能正确匹配。如果匹配,则返回密文文件,若则匹配成功。
3.2 安全模型
本节通过以下两个游戏来刻画本文方案在面对内部敌手的离线关键词猜测攻击(Keyword Guessing Attack,KGA)时的语义安全。由于内部敌手所获取的信息大于等于任意外部敌手所能获取的信息,因此不再考虑外部敌手。这两个游戏均由敌手A 和挑战者B 交互完成。游戏1 是密文不可区分性游戏,游戏2 是陷门不可区分性游戏。
3.2.1 密文不可区分性游戏
在密文不可区分性游戏中,假设半诚实服务器就是敌手A,它会诚实执行用户预设的操作,但是会尝试获取用户数据的信息。密文不可区分性旨在防止敌手分辨出某个给定的密文是从两个选定的关键词(由敌手自己选定)中的哪一个加密而来,即密文不可区分性可以保证服务器在没有获得用户授权的情况下无法私自对密文进行检索操作。
1)初始化。挑战者B 生成系统的公共参数Params 和主私钥s,以及各个用户的私钥,然后将系统的公共参数Params 发送给敌手A。
2)询问阶段1。敌手A 可以适应性地向如下的随机谕言机进行多项式时间次的询问,以获得用户的私钥、密文索引和陷门密文信息。其中,“适应性”是指敌手A 每次的询问都会根据当前已知的信息来决定应该询问的信息。挑战者B 运行随机谕言机,并按如下规则返回询问结果:(1)Hash 谕言机OH,对于给定的输入值,给敌手A 返回其哈希值;(2)密钥谕言机OE,对于指定的用户,给敌手A 返回该用户的密钥;(3)索引谕言机OC,给定关键词及接收方ID,给敌手A 返回其对应的密文索引;(4)陷门谕言机OT,给定一个关键词,计算并给敌手A 返回其对应的陷门。
3)挑战。敌手A 向挑战者B 声明一个发送者的身份标识ID*,并将其作为挑战,然后选择两个长度相等的挑战关键字(w0,w1)。挑战者B 随机选择β∊{0,1},根据选择结果,运行索引生成算法BuildIndex(IDR,wβ),生成密文索引Iβ,并将其发送给敌手A。
4)询问阶段2。敌手A 继续向各个随机谕言机进行询问,该阶段的询问与询问阶段1 相同。
5)猜测。敌手A 输出一个字节β′∊{0,1}作为对关键字wβ的猜测,假如β=β′,则敌手A 赢得游戏。前提是敌手没有询问过ID*对应的私钥,也没有询问过与身份ID*对应的关键字w0和w1的陷门密文信息及索引密文信息。
敌手A 在该游戏中的优势定义为:
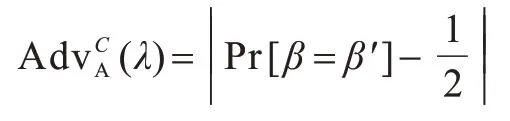
3.2.2 陷门不可区分性游戏
与游戏1 相似,游戏2 仍然假设半诚实服务器是敌手A。陷门不可区分性旨在防止敌手A 从一个给定的陷门信息中获取其对应关键词的信息。陷门不可区分性保证即使是服务器本身,也无法生成针对某接收者的有效密文。
1)初始化。与游戏1 的初始化相同。
2)询问阶段1。与游戏1 的询间阶段1 相同。
3)挑战。敌手A 向挑战者B 声明一个发送者的身份标识ID*作为挑战,并选择两个长度相等的挑战关键字(w0,w1),挑战者B 随机选择β∊(0,1),并根据选择结果,运行陷门生成算法Trapdoor(wβ,dR),生成陷门Tβ,并将其发送给敌手A。
4)询问阶段2。与游戏1 中的询问阶段2 相同。
5)猜测。敌手A 输出一个字节β′∊(0,1),作为对关键字wβ的猜测,假如β=β′,则敌手A 赢得游戏。限制条件与游戏1 相同。
敌手A 在该游戏中的优势定义为:
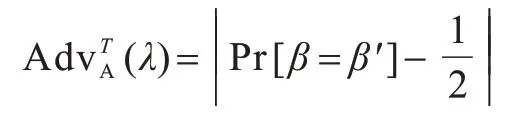
4 方案分析与证明
4.1 正确性分析
本文根据双线性对的性质来验证本文方案的正确性。
定义2假设在本文方案中所有密文索引和陷门都是按照正确的步骤生成,且在传输过程中未遭到恶意攻击,数据没有被篡改。方案正确性是指当用户向服务器发送包含关键词w′的检索陷门时,服务器运行检索匹配算法,以正确匹配到包含该关键词的密文索引,从而返回包含该关键词的密文文件。
假设用户ID′的公私钥对为用户ID′为关键词w′生成的陷门[H2(w′)-t′]∙d′)。当服务器运行检索匹配算法并逐个对比密文索引,由双线性对的性质可知:
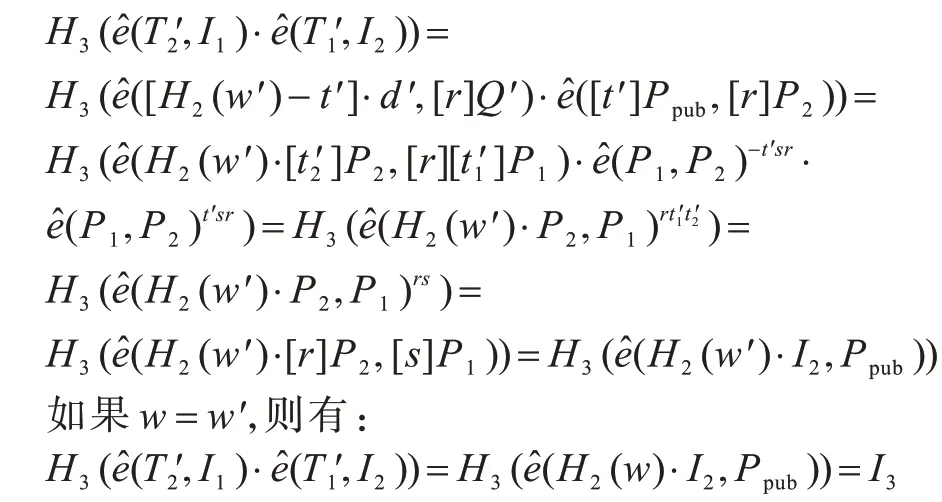
则服务器可以正确匹配到密文索引,正确性成立。
4.2 安全性证明
本文SM9SE 方案在随机谕言模型下满足适应性密文不可区分性以及适应性陷门不可区分性。具体证明过程如下:

证明若挑战者B 解决一个DBDH 实例元组Y=(G1,G2,GT,q,P1,[x]P1,[y]P1,P2,[y]P2,[z]P2,Z),则挑战者B 按如下过程与敌手A 进行密文不可区分性游戏。
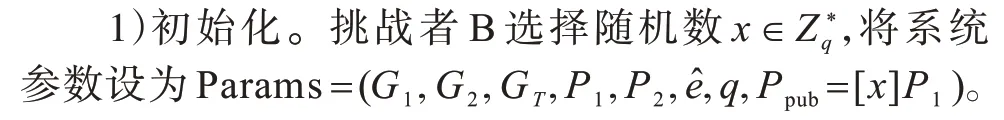
2)询问阶段1。敌手A 适应性地询问由挑战者B模拟的随机谕言机,假设敌手A 不会对同一个随机谕言机进行相同询问,并且在向H1询问ID 值之前不会对ID 做任何计算。随机谕言机主要有以下6 个:


4)询问阶段2。与询问阶段1 相同。
证明当敌手A2和挑战者B 进行密文不可区分性游戏时,在挑战阶段,敌手A2可将挑战者B 返回的挑战密文发送给敌手A1,若敌手A1猜测的结果为敌手A2挑选的关键词之一,则敌手A2向挑战者B 输出对应的结果作为猜测,否则随机输出猜测结果。可知敌手A2的优势为:


该证明与定理1 矛盾。因此,如果DBDH 假设成立,则不存在敌手能以不可忽略的优势对SM9SE方案发起离线关键词猜测攻击。
5 仿真实验与分析
5.1 效率分析
本文将SM9SE 方案与其他现有的基于身份可搜索加密方案进行对比分析。本文在同一标准下将EdIBEKS方案[10]、PEAKS方案[14]以及dIBAEKS 方案[17]进行效率分析。基于文献[25]中的定义,表1定义了若干不同符号及其换算方法。

表1 符号定义与换算Table 1 Symbol definition and conversion
EdIBEKS方案、PEAKS 方案以及dIBAEKS 方案所有的运算都建立在对称双线性对上,使用的曲线为嵌入度2,以1 024 bit 的大素数p为阶的超奇异椭圆曲线E(Fp):y2=x3+x。本文方案的运算建立在非对称双线性对上,使用的曲线为嵌入度12,阶为256 bit 的大素数p的BN 曲线E:y2=x3+5。以上选择参数能够确保所有方案都可以实现与2 048 bit 的RSA 密钥相当的安全级别。表2 表示不同方案的安全性假设、安全级别及其参数大小,以及本文方案与其他基于身份可搜索加密方案中用户执行一次索引生成算法、陷门生成算法和服务器执行一次检索匹配算法所需要执行的操作,其中忽略了方案中都存在的哈希函数运算。当计算椭圆曲线上的双线性对时,曲线的嵌入次数越多,计算越复杂,因此安全性也更高。相比其他方案采用嵌入度为2 的超奇异椭圆曲线,本文方案采用嵌入度为12 的BN 曲线,因此本文方案的安全性优于其他方案。由于BN 曲线的双线性对具有友好性[26],在BN 曲线上计算双线性对更加高效。从表2 可以看出,本文SM9SE 方案在保证计算效率的前提下,采用更小的安全参数实现与其他方案同等的安全级别,并且在索引生成算法上的效率优于其他三个方案,在陷门生成算法上的效率优于PEAKS 方案和dIBAEKS 方案,与EdIBEKS方案持平,都需要一次双线性对运算。由于本文方案采用参数更小的BN 曲线,因此计算效率会更高,检索匹配算法的效率优于EdIBEKS 方案和dIBAEKS 方案,与PEAKS 方案持平,都需要两次双线性对运算和一次椭圆曲线标量点乘法运算。由于本文方案采用参数更小的BN 曲线,因此计算效率会更高。因此,本文方案的总体性能优于其他方案。

表2 不同方案的计算效率与安全性对比Table 2 Computational efficiency and security comparison among different schemes
5.2 仿真结果分析
本文对EdIBEKS、PEAKS、dIBAEKS 和SM9SE方案进行仿真实验,在2.40 GHz 的4 核64 位Intel®CoreTMi5-10200H 处理 器、8 GB 内存(RAM)、Windows 10 操作系统的实验环境进行实验,以myeclipse 10 作为实验平台、Java 作为实验编程语言,对各方案的索引生成算法、陷门生成算法和匹配检索算法进行模拟运行。本文首先使用不同长度的关键词对各个方案进行模拟运行,以分析关键词长度对各方案效率的影响,然后分别抽取Enron 邮件数据集中的部分数据和Kaggle 邮件数据集中的部分数据作为测试输入,使用不同数量的关键词进行对比实验。关键词长度对各方案的算法运行时间的影响如图1 所示。

图1 关键词长度对各方案中算法运行时间的影响Fig.1 Influence of keyword length on the running time of algorithms in each schemes
从图1 可以看出,关键词长度对各算法运行效率的影响较小(关键词长度影响哈希函数运行时间,但哈希运算速度极快),略受各算法所选择的随机数影响,但总体运行时间较为平稳。
图2 表示各个方案中索引生成算法的运行时间,其中横坐标是关键词的个数,纵坐标为建立索引所需要的时间。从图2 可以看出,SM9SE 方案在索引生成算法上的运行效率优于其他三种方案。SM9SE 方案生成一个密文索引的平均时间在8 ms左右,而其他方案的密文索引时间则在35~68 ms 之间。因此,本文方案在索引生成算法上的效率相比其他三种方案提高了77%以上。
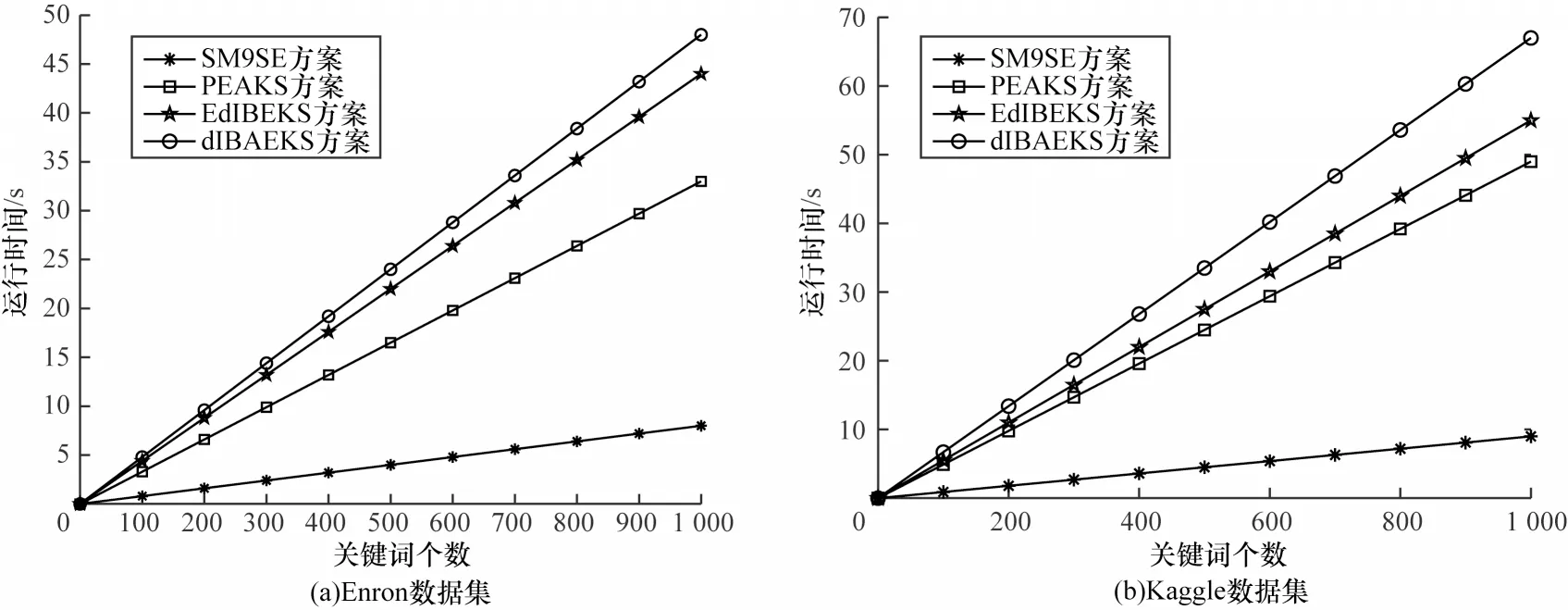
图2 索引生成算法的运行时间对比Fig.2 Comparison of running time of index generation algorithms
图3 表示在各个方案中陷门生成算法的运行时间对比,其中横坐标是关键词的个数,纵坐标为生成检索陷门所需要的时间。从图3 可以看出,SM9SE 方案在陷门生成算法上的运行效率也优于其他三种方案。其他三种方案生成一个陷门的运行时间平均为30~53 ms 之间,而SM9SE 方案生成一个陷门的平均时间在25 ms 左右,效率提高了16.67%以上。
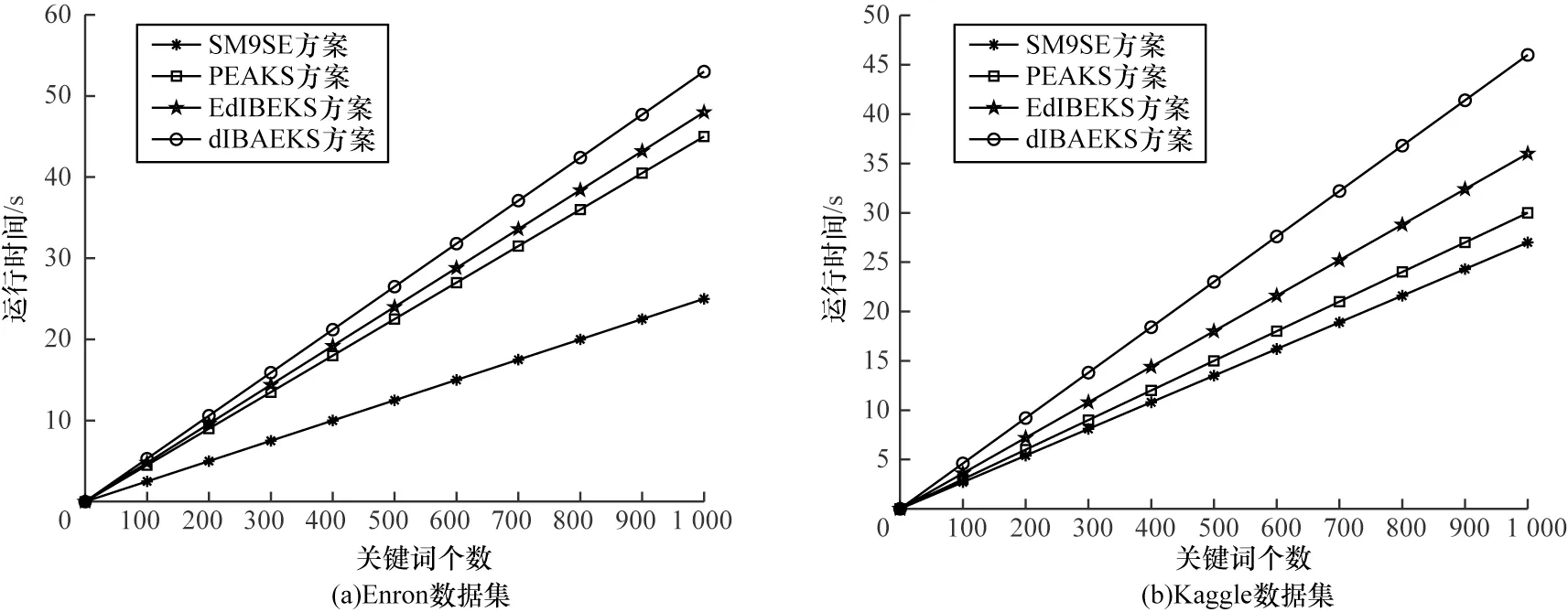
图3 陷门生成算法的运行时间对比Fig.3 Comparison of running time of trapdoor generation algorithms
图4 表示在各个方案中检索匹配算法所运行的时间,其中横坐标是密文索引的个数,纵坐标为所有密文索引的运行时间。从图4 可以看出:SM9SE 方案单次检索匹配算法的平均运行时间为18 ms 左右;dIBAEKS 方案的单次检索匹配算法的平均运行时间为53 ms 左右;PEAKS 方案和EdIBEKS 方案的单次检索匹配算法的平均运行时间在25~45 ms 之间。因此,SM9SE 方案的检索匹配算法运行效率相对其他三种方案提高了28%以上。
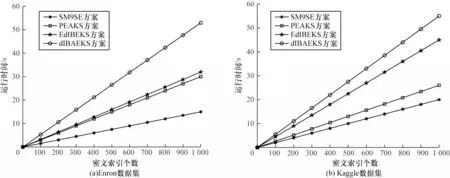
图4 检索匹配算法的运行时间对比Fig.4 Comparison of running time of retrieval matching algorithms
图5表示在不同方案中各个算法的平均运行时间。从图5 可以看出,本文方案执行一次索引生成算法、陷门生成算法和检索匹配算法的全过程所需要的平均时间总和为52 ms,其他三种方案则在105~168 ms之间。相比其他三种方案,本文方案的总体效率提高了50.4%以上。

图5 各个算法的平均运行时间对比Fig.5 Comparison of average running time of each algorithms
6 结束语
针对现有基于身份的可搜索加密方案计算效率低、与SM9 密码算法难以结合等问题,本文提出一种基于SM9 密码算法的可搜索加密方案。根据非对称双线性对的性质,结合SM9 加密算法的密钥形式,设计索引生成算法、陷门生成算法和服务器检索匹配算法,并验证方案的正确性和安全性。该方案在随机谕言模型下满足适应性密文不可区分性和适应性陷门不可区分性。仿真结果表明,相比EdIBEKS、PEAKS、dIBAEKS 方案,本文方案具有较高的计算效率,能够实现可搜索加密与国家商用密码算法SM9 的结合,并扩展了SM9 密码算法的应用。下一步将在本文方案中增加指定身份检索、身份验证等更灵活的功能,使其适用于较复杂的应用场景。此外,还将在安全索引中嵌入数据发送者的私钥,并在陷门中嵌入发送者的公钥,通过设计相应的匹配算法实现精确检索目标文件的功能。
