基于深度学习的双流程短视频分类方法
2022-07-14张瑷涵石蕴玉刘思齐
张瑷涵,刘 翔,石蕴玉,刘思齐
(上海工程技术大学电子电气工程学院,上海 201620)
0 概述
视频分类是指给定一个视频片段并对其中包含的内容进行分类,广泛应用于视频点播、网络演示、远程教育等互联网信息服务领域[1-2]。随着深度学习[3-4]技术的发展,通常将视频每一帧视为一幅单独的图像并利用二维卷积神经网络(Convolutional Neural Networks,CNN)进行图像分类。该方法将视频分类问题简化为图像分类问题,对比图像分类仅多了一个维度的时序特征。KARPATHY等[5]将时序语义融合分为识别动作靠场景和识别场景靠物体的单融合、相邻固定帧的两帧做卷积而全连接接受时序信息的后融合、在二维卷积中增加深度的前融合、在前融合中增加长度和步长的缓融合4 类。根据3D卷积神经网络(3D Convolutional Neural Network,3DCNN)保留时序特征的特点,TRAN等[6]在UCF101 数据集上的分类准确率最高为85.2%,每秒传输帧数(Frame Per Second,FPS)为313.9。研究人员对3D 卷积神经网络进行大量研究,CARREIRA等[7]提出增加网络宽度的I3D 网络,在单一数据集RGB 流中的分类准确率为84.5%,但需使用64 个GPU 并行训练,且计算量难以应用于现实场景。为解决现实生活场景下的视频分类问题,杨曙光等[8-11]分别对3D 卷积提取进行改进并将其运用于人体动作识别、体育运动分类等任务,获得了较高的分类准确 率。HARA等[12]将ResNet网络[13]从2D 扩展到3D,并将其与ResNeXt 网络[14]、DenseNet网络[15]在Kinetics 数据集上进行分类准确率对比,证明了预训练的简单3D 体系结构优于复杂2D 体系结构。陈意等[16]改进了NeXtVLAD,并且在VideoNet-100 数据集中的分类准确率最高为85.4%。
由于目前常用的UCF101[17]、Kinetics[7]、HMDB51等数据集主要是以人物动作进行分类,然而在现实生活场景中还有纯风景、纯文字、卡通动漫等识别类型,此类基于人物动作的分类数据集并不适用,因此本文构建来源于抖音、快手、今日头条等平台的短视频数据集,并提出一种双流程短视频分类方法。在主流程中,通过考虑短视频在时间维度的连续性、平衡性与鲁棒性,设计更适合短视频分类的A-VGG-3D 网络模型和采样策略。在辅助流程中,将帧差法判断镜头切换抽取出的若干帧通过人脸检测进行人物类和非人物类的二分类,以进一步提升短视频分类准确性。
1 双流程短视频分类原理
针对实际生活场景下的短视频分类问题,本文提出一种双流程分类方法。主流程采用A-VGG-3D 网络结构,通过对特征的精准提取并结合视频时序特征实现短视频分类。辅助流程通过镜头判别和人脸检测进行辅助分类。将辅助流程的分类结果与主流程分类结果进行分析,得出最终的分类结果。该分类方法不局限于人物动作,可将生活中的短视频进行更好的分类,适用于视频推荐、视频监管、视频查询等任务。
1.1 短视频采样策略
在采样过程中,为充分保留视频的时序性,并且考虑到2D 卷积网络在每次卷积运算后都会丢失输入的时间信息,而3D 卷积网络除了2D 卷积网络原有特征之外,还会保留输入的时间信息,因此选择3D 卷积用于视频的相关特征提取。给定一个短视频,将其按相等间隔分为k段,其中相等的间隔所获取到的帧数即为网络中3D 卷积采样深度,采样得到的片段序列T1,T2,…,Tk表示如下:

2D 和3D 卷积操作如图1 所示,其中,L、H、W分别表示为短视频的时间长度、通道数、高和宽,k、d、K表示卷积核的尺寸。
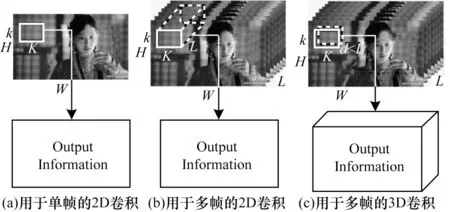
图1 2D 和3D 卷积操作Fig.1 2D and 3D convolution operations
1.2 VGG 网络
牛津大学的SIMONYAN等[18]提出的VGG16 卷积神经网络模型在ImageNet 数据集中的Top-5 测试精确率达到92.7%。VGG16 网络模型利用深度学习技术,使得每个神经元只能感觉到局部图像区域,而全局信息则通过整合不同敏感的神经元获得,减少了卷积神经网络训练所需的参数量和权值。
1.3 注意力机制
注意力机制是一种大脑信号处理机制,通过计算概率分布突出某个关键输入对输出的影响[19]。软注意力机制考虑所有输入,为每一个特征分配不同概率的注意力权重值,相对发散。硬注意力机制较为随机,在某一时刻只关注一个位置的信息,相对专注。通道注意力模块通过对特征图的各个通道之间的依赖性进行建模,提高了对于重要特征的表征能力。HU等[20]提出SENet block,其核心思想在于网络根据loss 学习特征权重,有选择性地通过权重分配加强有关特征或抑制无关特征。BAHDANAU等[21]将注意力机制引入循环神经网络(Recurrent Neural Network,RNN),实现机器翻译。
本文在VGG16 网络模型的基础上,引入压缩注意力模块(SENet block),SENet block 主要包含Squeeze 和Excitation 两部分,如 图2所示,其中X为输入,C为通道数,W为权重参数,Ftr为标准的卷积形式转换操作,Fsq为压缩操作,Fex为激励操作,Fscale为通道上的乘积操作。
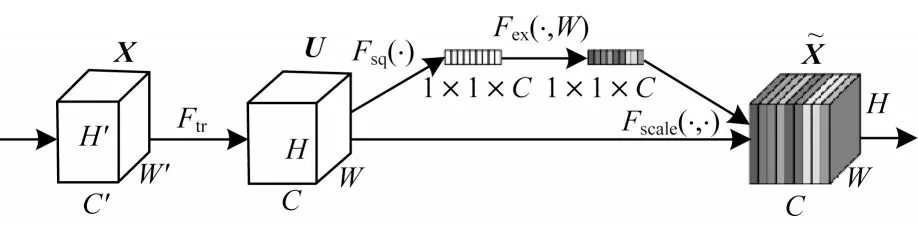
图2 SENet block 结构Fig.2 SENet block structure
压缩操作(Squeeze)是一个全局平均池化操作,将C个大小为H×W的特征图(H×W×C)的输入转换成的输出,输出结果为全局信息,如式(2)所示:
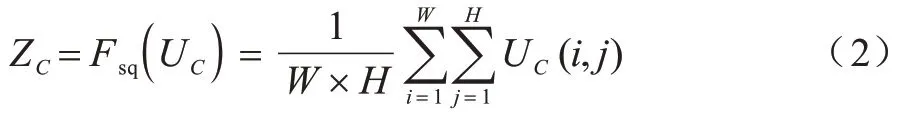
其中:UC代表2D 矩阵的数值。
激励操作(Excitation)是一个全连接层操作,位于压缩操作得到的结果Z后。权重参数W被用来学习显式地建模特征通道间的相关性,经过一个ReLU层,输出的维度不变,与W2相乘也是一个全连接层的过程,再经过sigmoid 函数得到S,如式(3)所示:
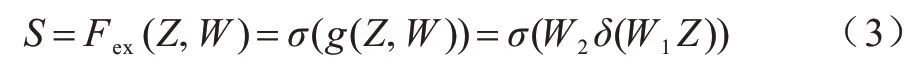
其中:S用来刻画U中C个特征图的权重,该权重是通过前面的全连接层和非线性层学习得到的。激励操作中两个全连接层的作用是融合各通道的特征图信息。
规模化操作(Scale)是在得到S后对U进行的操作,如式(4)所示:
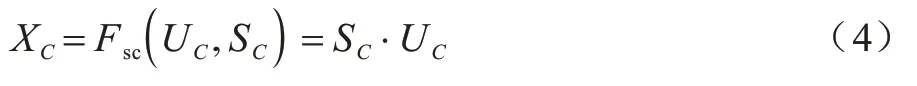
其中:SC代表2D 权重的数值。
2 双流程短视频分类流程
短视频分类流程如图3 所示,在主流程中选取网络输出的前5 类,从高到低设置为5 分至1 分,辅助流程输出结果各占1 分,采用投票法计算出最终分值后进行短视频类别排序,最终输出总排名第1的短视频类别作为最终分类结果,进一步提升短视频分类准确率。
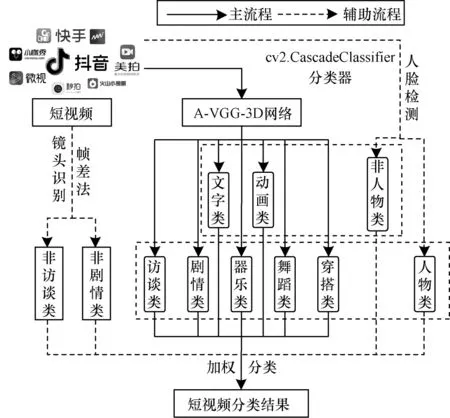
图3 短视频分类流程Fig.3 Procedure of short video classification
2.1 自建的短视频数据集
选取典型短视频,构建C1 和C2 两类数据集,其中,C1 是仅包含人物动作类的数据集,细分为访谈、剧情、乐器、舞蹈、穿搭5 类短视频,C2 数据集在C1数据集的基础上增加了文字类和动画类短视频,每类包括10~25 组短视频,每组包括3~7 个短视频。C1 和C2 数据集标签层级结构关系如图4 所示。

图4 C1 和C2 数据集标签层级结构关系Fig.4 C1 and C2 dataset label hierarchy relationship
通过观察创作者的短视频,自制数据集中的短视频时长为15 s 至1 min,主要集中在30 s 左右,分别选取对应的388 条和504 条短视频,以防止过拟合。本文提出的短视频分类方法以短视频实际展示内容为视频标签,在短视频分类上更具实用性和鲁棒性。C2 数据集中的部分短视频如图5 所示。

图5 C2 数据集部分短视频Fig.5 Part of short videos of the C2 dataset
2.2 短视频分类流程
短视频分类主流程如图6 所示,首先分割选取短视频片段,保证帧图像规格相同并确保相应数量的片段样本,然后把视频段输入A-VGG-3D 网络进行特征提取、训练和测试,最后网络预测出前5 类分类结果。
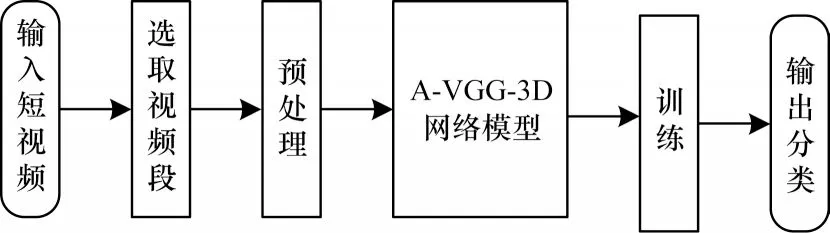
图6 短视频分类主流程Fig.6 Main procedure of short video classification
目前,短视频分辨率一般为720×1 280 像素。通过降采样处理,将短视频分割为224×224×3×15 的片段输入A-VGG-3D 网络特征提取部分,将Conv 3-3特征图输入短视频分类部分,将调整特征图做上采样处理为112×112×3×15 的片段输入A-VGG-3D 网络分类部分,其中采样深度为15,通道数为3,最终输出为该短视频类别。短视频深度选择方法主要分为给定固定值和选择所有帧2 类,本文选择所有视频帧,这样能减少特殊样本对数据的影响。在式(5)中,Nframe为在视频中被抽取的首帧序号、Nnframe为短视频文件的总帧数、Ndepth为需要抽取的总帧数,x(x=0,1,…,Ndepth)为从0 开始依次递增的整数。

A-VGG-3D 网络架构分为特征提取部分和短视频分类部分,其中特征提取部分为增加注意力机制的VGG 网络,短视频分类部分为改进的C3D 网络。A-VGG-3D 网络模型的创新之处在于:1)特征提取部分在VGG-16 网络浅层增加注意力机制,可模拟人脑对感兴趣区域合理分配权重;2)短视频分类部分减少了卷积层和池化层,在几乎不影响准确度的情况下降低了计算复杂度,加快了分类速度,并具有较高的分类鲁棒性;3)短视频分类部分新增3 个BN层,解决了因网络层数加深而产生的收敛速度慢甚至消失的问题;4)短视频分类部分增加了级联融合模块,将小尺度图像放大至所需尺度,实现了多级特征融合。
A-VGG-3D 网络架构如图7 所示,彩色效果见《计算机工程》官网HTML 版。在特征提取部分,卷积层为粉色(Convolution+ReLU)、池化层为蓝色(max pool)、全连接层为黄 色(Fully connected+ReLU)、深橙色为注意力机制模块(SENet block),最后输出层为绿色(softmax)。该网络在VGG 网络Conv 1-1 和Conv 1-2 之间加入SENet block,主要包含Squeeze 和Excitation 两部分,通过在浅层进行学习并分配注意力权重从而选择性地加强有关特征或抑制无关特征。然后将特征以Conv 3-3 特征图作为短视频分类部分输入。在短视频分类部分,绿色部分为本文加入的归一化层,通过两个跳跃连接的上采样模块(浅橙色)融合多尺度特征进行预测,从而加强对局部特征的学习,其中32@3×3×3为32个3×3×3的卷积核。
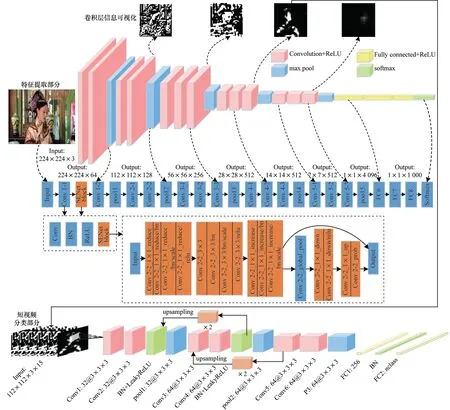
图7 A-VGG-3D 网络架构Fig.7 A-VGG-3D network architecture
短视频分类辅助流程主要包括镜头判别和人脸检测两部分辅助流程。由于短视频拍摄可分为航拍、弧型运动、衔接等镜头,因此不同类别短视频采用的镜头拍摄方法存在差异。剧情类和访谈类短视频的拍摄视角和场景切换频率存在很大不同,以相同方式选取短视频的46 帧,剧情类前景与背景均存在较多变化,如图8(a)中黑框区域,访谈类前景背景几乎不变,如图8(b)所示。

图8 短视频镜头拍摄差异图Fig.8 Lens shot difference images in the short videos
在镜头判别辅助流程中,采用帧差法来判断镜头切换,根据视频序列具有连续性的特点:如果拍摄镜头内没有较大变化,则连续帧的变化很微弱;如果存在镜头切换,则连续的帧与帧之间会有明显变化,即为本文选取的变换镜头帧。将相邻两帧图像对应像素点的灰度值进行相减并取绝对值,fn(x,y)为当前帧的直方图特征,fn-1(x,y)为上一帧的直方图特征,得到差分图像Dn,如式(6)所示:
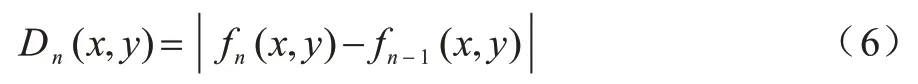
设定阈值T,按照式(7)逐个对像素点进行二值化处理得到二值化图像
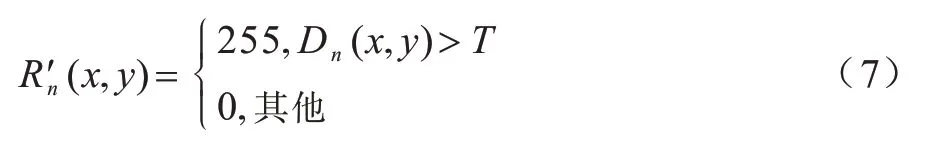
其中:灰度值为255 的点,即为前景点;灰度值为0 的点,即为背景点。
为进一步提升短视频分类准确性,将帧差法抽取出的若干帧通过人脸检测辅助流程进行人物类和非人物类的二分类。采用滑动窗口机制与级联分类器融合的方式进行多尺度人脸检测,若抽取的短视频帧中存在人脸,则将人脸框出作为人物类短视频依据。因为人物类短视频部分带有人物特征,所以将改进的行为识别网络作为分类网络进行分类。最终根据分类网络得到的分类结果进行分析优化,并与前几次分类结果进行比对,得到最优分类结果。
3 实验与结果分析
3.1 实验参数设置
实验操作系统为Windows 10 64 位旗舰版。实验环境GPU 为4 块NVIDIA GeForce GTX 1080Ti 显卡。A-VGG-3D以keras为框架,batch size设置为128,初始学习率为0.003,每经过1.5×105次迭代,学习率除以2,在第1.9×106次迭代(大约13 个epoch)时停止,共训练100 个epoch。镜头判别采用灰度帧差法,其中镜头边界阈值为0.5。人脸检测采用Python脚本在镜头帧中进行自动检测。
3.2 评价指标
采用Top-1 准确率和FPS 作为评价视频分类方法主流程的性能指标。Top-1 准确率和FPS 计算公式分别如式(8)和式(9)所示:

其中:A表示准确率;T表示分类正确的样本数;F为分类错误的样本数;NFrameNum表示每秒处理的图像帧数;Ttime表示时间间隔,取值为1 s。
选择查准率(ATR)和查全率(APR)作为评价视频分类方法辅助流程的性能指标。ATR和APR计算公式分别如式(10)和式(11)所示:

其中:AFP表示误检的数量;AFN表示漏检的数量。
3.3 结果分析
由于数据集数量有限,在较多的短视频样本中选取少量推荐率高、代表性强的短视频作为实验数据集。UCF101[17]为包含时间短于10 s的13320条实际动作短视频的公开数据集,共分为101 类,其中每类有25 个人,每人做4~7 组刷牙、击鼓、蛙泳等动作。由于UCF101 数据集与短视频分类研究数据集在时间上有相似性,因此选取UCF101 数据集和自建数据集以解决短视频分类问题。选择C1、C2 和UCF101 数据集进行5 类、7 类、101 类短视频分类,并按照4∶1 的比例划分为训练集和测试集。为确保结果的一致性,实验选取视频的随机性保持不变,使用RGB 帧输入。在辅助流程中,镜头判别在C1、C2 数据集中进行镜头切换数量判定,在表示访谈类、剧情类、卡通类镜头切换数量与视频帧总数量的关系中:访谈类镜头切换数量基本保持在5 次左右,在视频总帧数中占比不足5%;剧情类镜头切换数量基本大于10 次,集中于20~70 次,在视频总帧数中占10%~20%;卡通类镜头切换数量并不稳定,在切换数量上与剧情类更为相似,通过人脸检测辅助流程可较好地将两者进行分类。在辅助流程中,人脸检测准确率高达99%,表明辅助流程在短视频分类中具有较大作用。由于访谈类和剧情类在镜头切换数量上存在较大区别,因此以镜头数量判别非访谈类和非剧情类效果较好,也可降低网络对短视频分类的误判。为保证较高的查准率与查全率,设置镜头切换数量阈值为10,查准率与查全率结果如表1 所示。
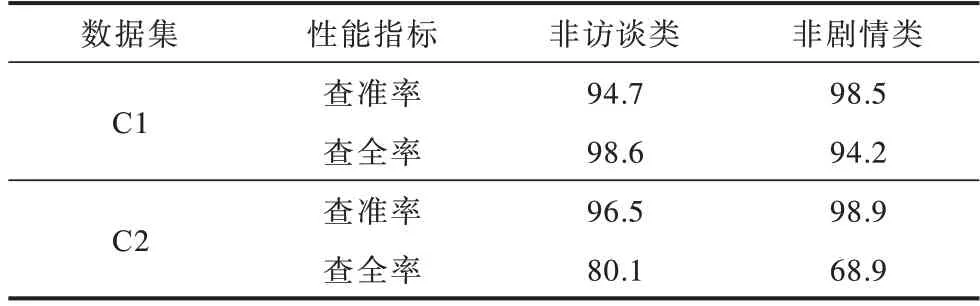
表1 镜头判别查准率与查全率Table 1 Precision and recall of lens discrimination %
通过双流程权重设置,主流程A-VGG-3D 网络判定中存在粗分类问题,在分类层得出的前5 名分类结果得分从高到低为5 分至1 分,辅助流程结果各占1 分,采用投票法计算出最终分值作为分类结果,进一步提升短视频分类准确率。由于镜头判别仅针对辅助访谈类和剧情类提升准确率,最终分类准确率主要依据A-VGG-3D 网络结果,因此本文权重设置较为合适。不同视频分类方法的消融实验结果如表2 所示。由表2 可以看出,与主流程A-VGG-3D 网络分类相比,增加人脸检测可提升人物类和非人物类的分类准确率,在C2 数据集上提升了3.2 个百分点,增加镜头判别在C1 数据集上提升了4.5 个百分点,可见本文方法中的辅助流程可提升现实生活场景短视频的分类准确率。
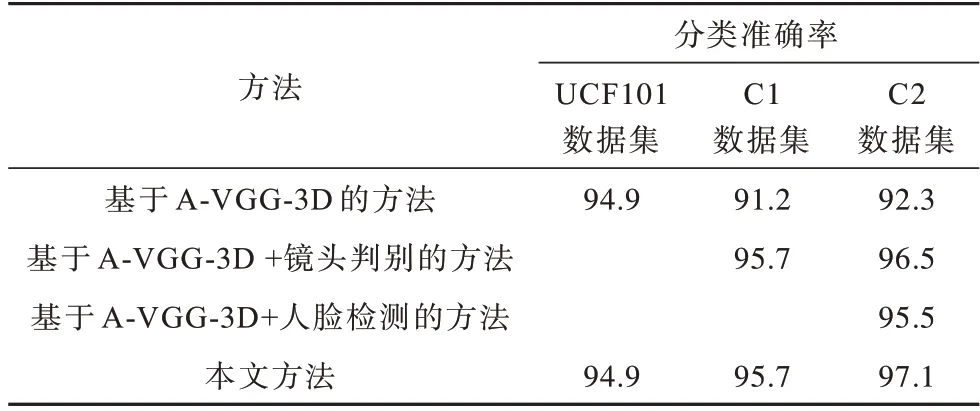
表2 消融实验结果Table 2 Ablation experiment results %
不同视频分类方法的对比实验结果如表3 所示。由表3 可以看出,与基于C3D 的分类方法相比,本文方法的准确率在UCF101 数据集上提升了9.7 个百分点,在C1 和C2 数据集上表现也较为突出。综上,本文方法针对不同数据集能快速高效地进行短视频分类,并且对于人物类和非人物类短视频均具有较强的鲁棒性。
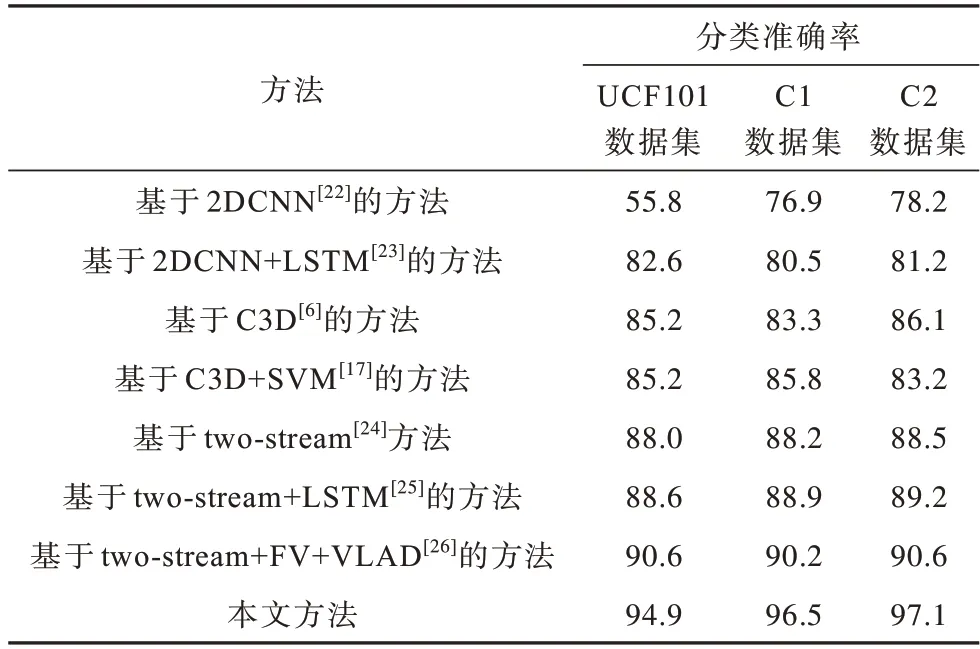
表3 对比实验结果Table 3 Comparative experiment results %
4 结束语
本文提出一种针对生活场景的双流程短视频分类方法,构建A-VGG-3D 网络模型,采用带有注意力机制的VGG 网络提取特征,利用优化的3DCNN 网络进行短视频分类,并结合镜头判别和人脸检测进一步提高短视频分类准确率。实验结果表明,该方法相比基于2D 网络的视频分类方法可以更好地保留时间信息,并且在UCF101 数据集和自建的生活场景短视频数据集上的分类效果均优于传统短视频分类方法。后续将优化A-VGG-3D 分类模型,通过匹配镜头判别和人脸检测辅助流程进一步提升分类效果。
