基于改进Deeplab v3+的服装图像分割网络
2022-07-14胡新荣龚闯张自力朱强彭涛何儒汉
胡新荣,龚闯,张自力,朱强,彭涛,何儒汉
(1.湖北省服装信息化工程技术研究中心,武汉 430200;2.纺织服装智能化湖北省工程研究中心,武汉 430200;3.武汉纺织大学 计算机与人工智能学院,武汉 430200)
0 概述
近年来,随着服装设计行业的发展和在线购物的兴起,服装图像的视觉解析变得越来越重要。其中对服装图像分割有利于将服装进行细分和归类。一方面,服装图像的分割细分了不同的服装部件,给设计师带来创作时尚新品的灵感。另一方面,消费者面对服装图像的精细分割,不仅可以获取更好的穿着偏好,而且可以进一步了解服装信息,提升购物体验感。
服装分割方法主要利用手工设计的特征和预估的人体姿态预测像素级标注。文献[1]提出一种应用于服装领域的分割框架,但该方法需要在图像的像素标注上耗费巨大的人力物力和时间成本;文献[2]提出一种弱监督的方法,虽然该方法省时省力,仅需使用基于服装图像颜色进行标注的标签和人体姿态估计,但该方法仍然有过于依赖人体姿态的弊端;文献[3]提出一种用于针对服装复杂纹理图像的服装解析改进方法,但该方法对服装复杂不规则的相似颜色纹理解析较差。
随着深度学习领域的快速发展,深度卷积神经网络(Deep Convolutional Neural Networks,DCNN)表现出强大的特征提取和表征能力。基于全卷积网络(Fully Convolutional Networks,FCN)[4]端到端经典语义分割模型的出现,虽然取得了很大的成功,但由于网络结构固定,FCN 也显露出了诸多弊端,例如:没有考虑全局上下文信息,将特征图上采样还原成原图大小的图像会造成像素定位不准确。文献[5]提出用于生物医学图像分割领域的U-Net 网络,不过在做多分类的任务时,U-Net 卷积网络不仅分割的边缘轮廓较差,而且容易造成显存溢出。文献[6]提出将FCN、SegNet 和边缘检测结合的集成学习方法,该方法在分割高分辨率的遥感图像时既减少了分割误差,又提高了分割精度。在处理外观较为相似的物体时,PSPNet[7]网络使用了空间金字塔池化,对不同区域的上下文进行聚合,提升了网络利用全局上下文信息的能力。此 外,SegNet[8]、RefineNet[9]等语义分割网络均采用编解码结构捕获细节的信息,提高了分割精度。文献[10]提出的语义分割网络利用服装语义分析预测图结合学习到的人体关节信息,能更好地定位服装分割区域,解决了过度分割过程中依赖手工设计特征和依赖人体姿态等问题。该方法分割性能较高,但对深层特征图的语义信息提取不够充分,且会导致空间信息的丢失,该方法在对现实生活中的复杂服装图像或者包含繁琐干扰性极强的背景图像进行分割时,分割的效果仍然不够理想。
目前注意力机制广泛应用于深度学习领域,特别是在图像处理方面发展迅速。文献[11]设计了DANet 网络,通过引入自注意力机制,并融合局部语义特征和全局依赖,提高了分割精度。文献[12]提出SENet 网络,简单地压缩每个二维特征图以有效地构建通道之间的相互依赖关系,CBAM[13]进一步推进了该方法,通过大尺寸内核的卷积引入空间信息编码。
为了应对较为复杂的服装分割任务,本文提出一种基于改进Deeplab v3+的服装图像分割网络。采用语义分割性能较好的Deeplab v3+网络[14],并引入注意力机制,利用Coordinate Attention 机制捕获得位置信息和通道关系,从而更有针对性地获学习目标区域的特点,获取更好的精细图像特征。在此基础上,为提取高层特征图的语义信息,引入语义特征增强模块,通过对不同大小的特征图应用non-local注意块来处理不同大小的服装图像,并将每个non-local 注意块的输出进行融合,增强更深层的语义特征。
1 服装分割网络
本文的服装分割网络使用深度学习语义分割领域性能较好的Deeplab v3+网络及其相关改进网络。下文依次介绍服装分割过程图、Deeplab v3+网络和改进Deeplab v3+的网络。
1.1 服装分割流程
本文的服装分割方法主要是基于改进的Deeplab v3+网络。首先获取服装数据集,处理服装数据集的标签,得到处理完成的服装数据集。然后将服装数据集作为输入送入到服装分割网络中进行训练,当网络损失收敛到一定程度,且在验证集的准确率趋于饱和时停止训练,得到最终服装分割网络。最后输入服装图像到训练好的服装分割网络进行预测,得到不同种类的服装预测分割图像。具体的服装分割流程如图1 所示。

图1 服装分割流程Fig.1 Clothing segmentation procedure
1.2 Deeplab v3+网络
Deeplab v3+是由谷歌公司开发的一种使用空间金字塔模块和编解码器结构的语义分割网络。Deeplab v3+的核心思想是利用端对端的训练方式,该网络的编码器结构由骨干网络resnet101 和ASPP[14]模块组成,resnet101作为骨干网络,提取图像生成的高级语义特征图,后面连接ASPP 模块,含有多个空洞卷积扩张率,用于将resnet101 生成的高级特征图进行多尺度采样,得到多尺度的特征图,将得到的特征图在通道维度上进行组合,最后送入到卷积核大小为1×1 的卷积核,以此降低通道维度。解码模块将编码模块得到的降维特征图进行4 倍上采样与resnet101 中间的原图1/4 大小的高层特征图融合,再进行双线性插值上采样。编码模块的特征图获取的是图像语义信息,resnet101 中间下采样获取图像的细节信息。Deeplab v3+的网络结构如图2 所示。将Deeplab v3+网络用于服装分割领域,可以发现该网络在对服装进行分割时,存在对服装的轮廓分割略显粗糙,遇到复杂背景分割错误等问题。
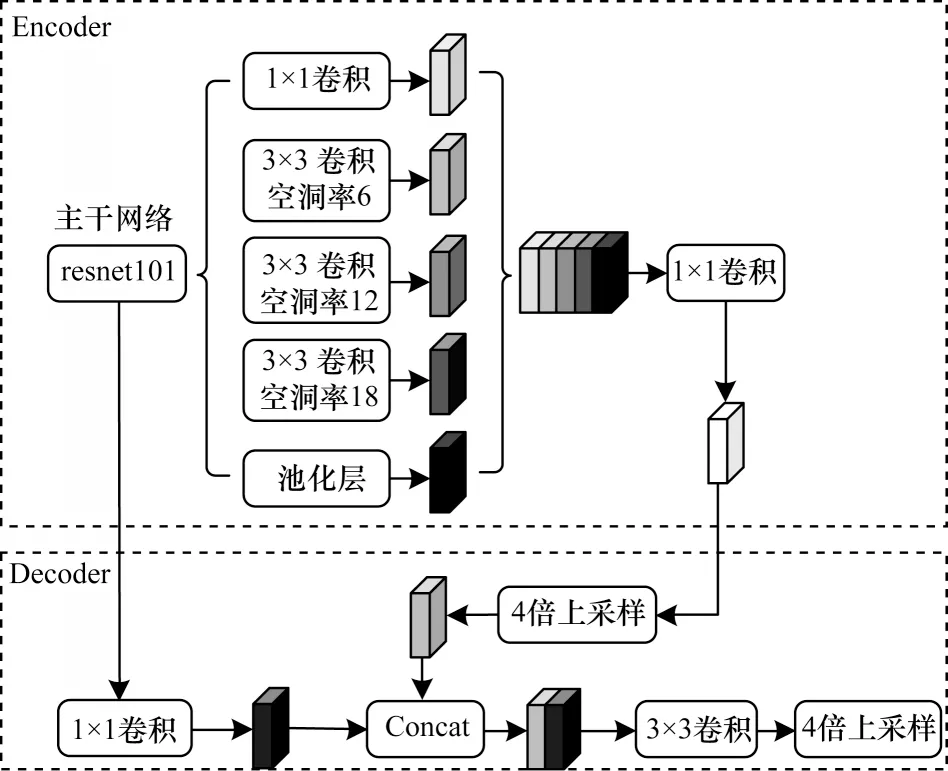
图2 Deeplab v3+网络结构Fig.2 Deeplab v3+network structure
1.3 改进的Deeplab v3+网络结构
近几年出现的注意力机制广泛地应用于深度学习的诸多领域[15-16]。注意力机制的作用可简单地解释为:告诉模型“什么”和“在哪里”出现,已经被广泛研究[17-18],并被用来提高现在深层神经网络的性能[12,19-21]。注意力机制[22-23]已经被证明在各种计算机视觉任务中有帮助。因此,本文将Coordinate Attention[24]引入到Deeplab v3+网络中,有效地捕获位置信息和通道信息之间的关系,以此来提高服装分割的精确度。在Deeplab v3+原网络中训练服装分割数据集,通过resnet101 下采样提取到特征图,仅为输入网络图像1/16 大小的特征图,考虑到高层卷积提取的特征图较小,得到的特征比较抽象,本文将resnet101 提取到较小的高层特征图经过语义特征增强模块,有效地获取更加丰富的语义信息。
下文将分别介绍Coordinate Attention 机制、语义特征增强模块(SFEM)[25]和CA_SFEM_Deeplab v3+网络结构。
1.3.1 Coordinate Attention 机制
Coordinate Attention 是一种具有轻量级属性的注意力方法,它能有效地捕获位置信息和通道信息的关系。Coordinate Attention 是一个计算单元,旨在增强学习特征的表达能力,它可以取任意中间特征张量X=[x1,x2,…,xc]∊RC×H×W作为输入,并且输出与X大小相同的具有增强表示的变换张量Y=[y1,y2,…,yc]。Coordinate Attention 通过精确的位置信息对通道关系和长期依赖性进行编码,具体操作分为Coordinate信息嵌入和Coordinate Attention 生成两个步骤。Coordinate Attention 结构如图3所示。
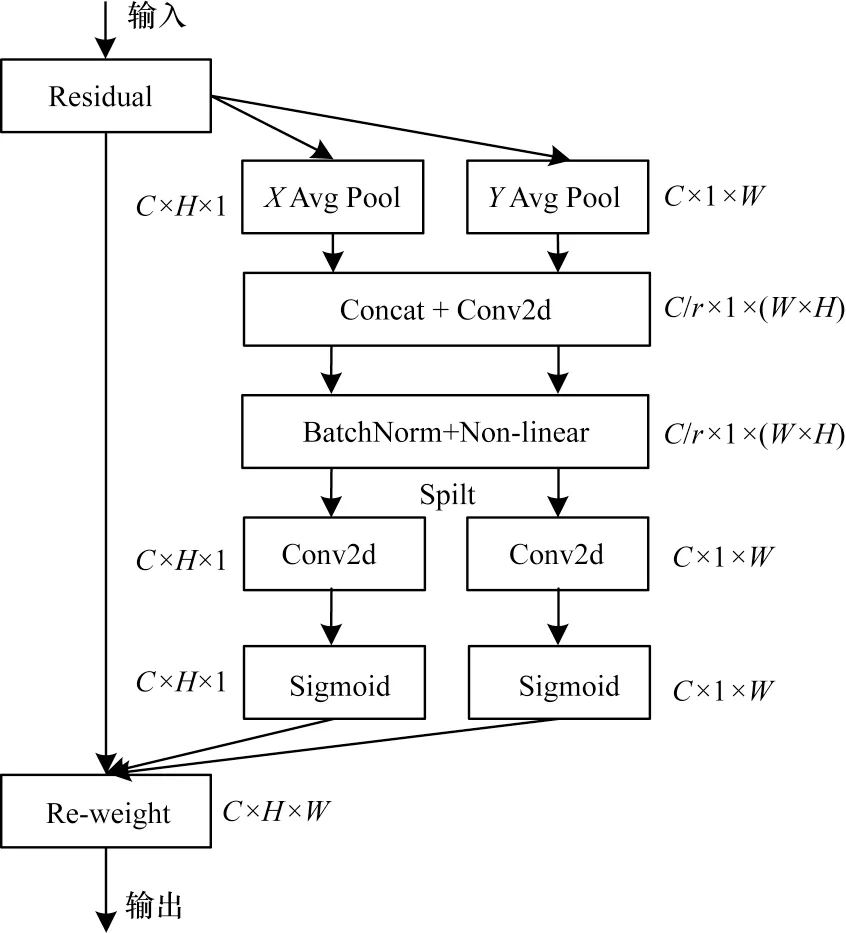
图3 Coordinate Attention 结构Fig.3 Coordinate Attention structure
1)Coordinate 信息嵌入全局池化方法通常用于通道注意力编码空间信息的全局编码,如SE(Sequeze and Excitation)block[12]挤压步骤,给定输入X,第c个通道的压缩步骤可以表示为如式(1)所示,由于它将全局信息压缩到通道描述符中,导致难以保存位置信息。为了促使注意力模块能够捕捉具有精确位置信息的远程空间交互,按照式(1)分解全局池化,转化为一对一维特征编码操作:

其中:zc表示第c通道的输出;xc(i,j)表示第c通道的高度坐标i和宽度坐标j位置特征图的数值;H和W分别为特征图的高度和宽度。
具体地,给定输入X,首先使用尺寸为(H,1)和(1,W)的池化核分别沿着水平坐标和垂直坐标对每个通道进行编码。因此,第c通道的高度为h的输出可以表示为:
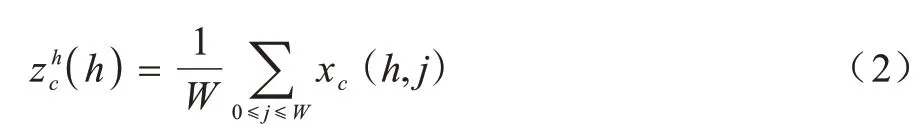
第c通道的宽度为w的输出可以写成:
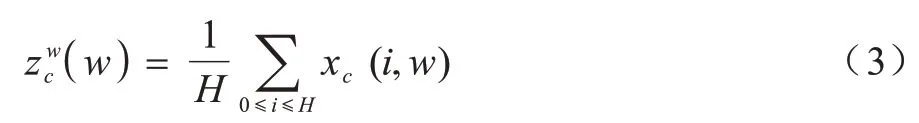
上述两种变换分别沿两个空间方向聚合特征,得到一对方向感知的特征图。这与在通道注意力方法中产生单一的特征向量的SE block 非常不同。这两种转换也允许注意力模块捕捉到沿着一个空间方向的长期依赖关系,并保存沿着另一个空间方向的精确位置信息,这有助于网络更准确地定位感兴趣的目标。
2)Coordinate Attention 生成如上所述,已经可以很好地获得全局感受野并编码精确的位置信息。为了利用由此产生的特征,给出了以下两个变换,称为Coordinate Attention 生成。通过信息嵌入中的变换后,由式(4)和式(5)产生的聚合特征图进行了拼接(concatenate)操作,使用1×1 卷积变换函数F1对其进行变换操作:

其中:[·,·]是沿空间维度的拼接操作;δ为非线性激活函数;f∈RC/r×(H+W)是对空间信息在水平方向和垂直方向进行编码的中间特征图,r是用来控制SE、SE block 大小的缩减率,然后沿着空间维度将f分解为2 个单独的张量fh∈RC/r×H和fw∈RC/r×W。利用另外2 个1×1 卷积变换Fh和Fw分别将fh和fw变换为具有相同通道数的张量输入到X,得到:

其中:σ是sigmoid 激活函数。为了降低模型的复杂性和计算开销,通常使用适当的缩减比r来缩小f的通道数,然后对输出gh和gw进行扩展,分别作为注意力权重。最后Coordinate Attention 块的输出Y=[y1,y2,…,yc]可以得到:
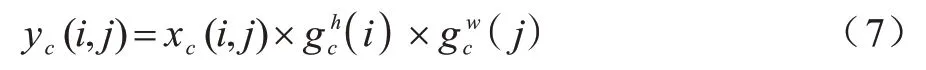
1.3.2 语义特征增强模块
CNN 网络深层包含语义特征,这些特征对检测和分割目标最重要。为了充分利用语义特性,受金字塔池[26-277]启发,本文引入了语义特性增强模块(SFEM),SFEM 结构如图4 所示。
如图4(a)所示,SFEM 由3 个平行分支的non-locol块组成,它将编码器特征图的输出作为输入,对特定大小的小块分别运用non-local 注意力,而不是自适应平均池化。第一个分支将图像分成4 个大小相同的小块(W/2×H/2),对每个块分别进行non-local 空间关注,然后将其折叠起来,如图4(b)所示。类似地,第二个分支产生16 个大小(W/4×H/4)的小块,并对每个块执行与第一个分支相同的操作。在本文的实验中,将编码器的输出特征图的大小设置为32×32。因此,第一个分支包含4 个大小为16×16 的小块,第二个分支包含16 个大小为8×8 的小块,最后一个分支对大小为32×32 的整个特征图执行non-local[28]操作。这3 个分支的输出串联之后,再送入到处理挤压和激励块(SE 块),用于处理最重要的通道,将SE块[12]的结果发送到所有解码器层。为了匹配每个解码器层的大小,对SFEM 的输出进行了上采样。
如图4(b)所示,以SFEM 结构中第一条分支为例,描述了图像应用non-local 注意力的详细版本,首先将图像分割成多个小块,然后对每个小块单独应用non-local 注意力,最后将其折叠回整个图像。
1.3.3 CA_SFEM_Deeplab v3+网络结构
在Deeplab v3+原网络中训练服装数据集,虽然可以分割出各类服装和背景,但效果一般。本文考虑在主干网络resnet101 中引入1.3.1 节介绍的Coordinate Attention 机制,沿一个空间方向捕获远程依赖关系,同时沿着另一个空间方向保留精确的位置信息。最后将生成的特征图分别编码为一对方向感知和位置敏感的attention map,可以将其互补地应用于输入特征图,以增强关注对象的表示。本文考虑将经过ASPP 之后的特征图,送入语义特征增强模块(SFEM)进一步提取,不仅能够增强高层特征的语义信息,而且可以保证不丢失空间信息。CA_SFEM_Deeplab v3+网络结构具体描述如下:将嵌入Coordinate Attention 机制的主干网络resnet101 提取的高层特征图输入到ASPP 结构,对主干网络提取的特征图以不同采样率的空洞卷积并行采样,以多个比例捕获图像的上下文得到多种特征图,将这些特征图融合送入1×1 卷积之后得到256 通道的特征图,此后将该256 通道的特征图输入到两条不同的分支分别处理。第一条分支:256 通道的特征图先进行4 倍上采样,之后输入到Nonlocal 中,得到第一条分支的特征图;第二条分支:将256 通道的特征图输入到特征增强模块(SFEM)进一步提取特征,将SFEM输出的特征图进行4 倍上采样,得到第二条分支的特征图。此后将第一条、第二条分支的特征图和resnet101 中间的原图1/4 大小高层特征图融合,将融合的特征图进行降采样和卷积,最后将输出的特征图进行4 倍上采样得到预测分割图片。CA_SFEM_Deeplab v3+的网络结构如图5 所示。
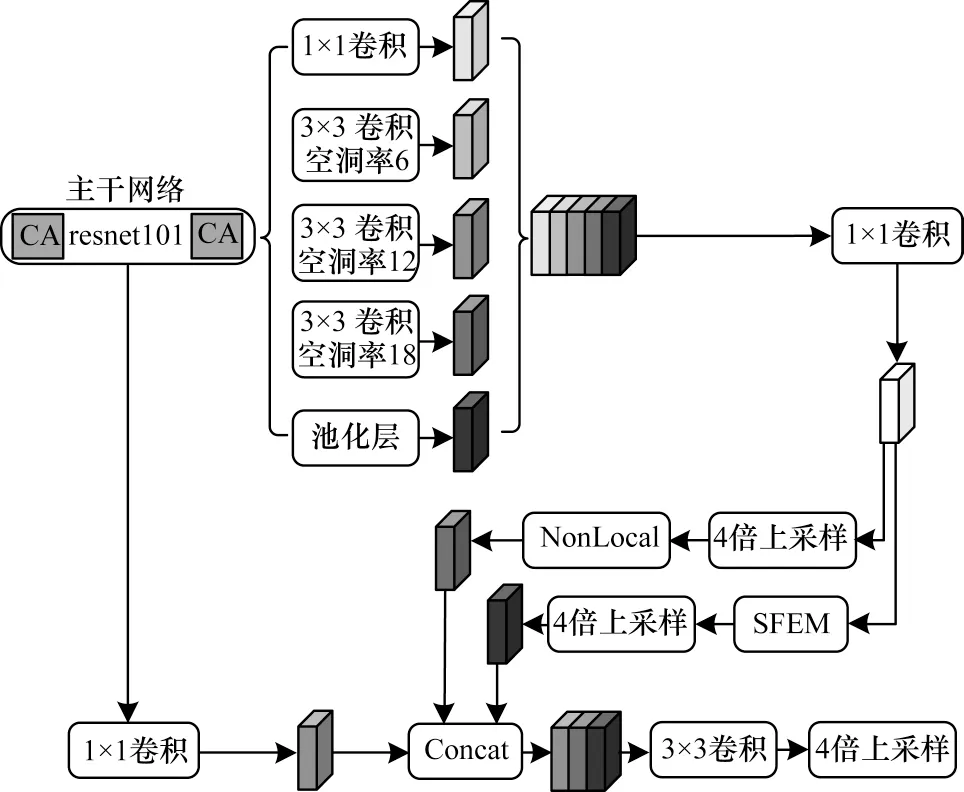
图5 CA_SFEM_Deeplab v3+网络结构Fig.5 CA_SFEM_Deeplab v3+network structure
2 实验与结果分析
2.1 数据集
本文实验的数据集来源于DeepFashion2[29],DeepFashion2 是一种大规模的基准数据集,具有全面的任务和时尚图像理解的标注。DeepFashion2 包含49.1 万张图像,具有13 种流行的服饰类别,在这个数据集上定义了全面的任务,包括服饰检测和识别、标记和姿态估计、分割、验证和检索。所有这些任务都有丰富的标注支持。DeepFashion2 拥有最丰富的任务定义和较大数量的标签,它的标注至少是DeepFashion[30]的3.5 倍、ModaNet[31]的6.7倍和FashionAI[32]的 8 倍。基于以上这些特点,DeepFashion2 非常适合作为本文实验服装分割的数据集。将标签json 文件转为单通道分割png 标签图,为了方便可视化,本文将单通道的标签图转为RGB彩色标签图(彩图效果见《计算机工程》官网HTML版),如图6 所示。

图6 DeepFashion2 数据集样本Fig.6 DeepFashion2 dataset sample
由于DeepFashion2 数据集十分庞大,考虑到本文实验的硬件限制和训练时间成本,故选取DeepFashion2 中77 848 张图片用于训 练,10 492 张图片用于评估,10 568 张图片用于测试。
2.2 语义分割实验评价指标
本文采用的量化指标分别是类别平均像素准确率(Mean Pixel Accuracy,MPA)和平均交并比(mean Intersection over Union,mIoU)。
MPA 表示分别计算每个类别被正确分类的像素数的比例,计算公式见式(8)。作为性能的评价指标,mIoU 是语义分割实验中常用的度量指标,交并比是计算真实集合和预测集合的交集与并集之比。在每个类上计算交并比,求和平均值,得到平均交并比,计算公式见式(9)。其中:k+1 表示类别数(包括k个目标类和1 个背景类);pij表示本属于i类却预测为j类的像素点总数。具体地,pii表示真正例,即模型预测为正例,实际为正例,pij表示假正例,即模型预测为正例,实际为反例,pji表示假反例,即模型预测为反例,实际为正例。

2.3 结果分析
针对本文提出的方法进行实验研究,实验环境配置如下:操作系统为Ubuntu16.04;显卡为NVIDIA GeForce RTX2080T(i11 GB);处理器为Intel®CoreTMi9-9900X CPU;学习框架为Pytorch。
相关实验基于Ubuntu16.04 操作系统进行,CPU为Intel i9-9900x,GPU 为4 张NVIDIA GeForce RTX2080Ti 的深度学习服务器,实验涉及的代码是用pytorch 实现。
2.3.1 训练策略
为了使模型快速收敛,并且适用于本实验的数据集DeepFashion2,本文采用了如下的训练策略:对主干网络resnet101 载入ImageNet 数据集上预训练的权重,初始化主干网络resnet101 的权重,加快训练速度,首先前60 个epoch 采用poly 学习率调整策略进行训练,主干网络设置初始学习率为0.000 7,网络的其余部分参数设置初始学习率为0.007,这样模型可以快速趋近于收敛,最后采用较小的固定学习率进行训练至模型收敛状态。本文实验中将图像剪裁至512×512 大小进行训练。
2.3.2 网络训练结果
本文实验网络采用Deeplab v3+、嵌入Coordinate Attention 模块(CA_Deeplab v3+)和嵌入Coordinate Attention、SFEM 模块(CA_SFEM_Deeplab v3+)。训练的实验网络在验证集上得出的mIoU 结果曲线如图7 所示,3 个实验网络的mIoU 随迭代的次数增加逐渐趋于稳定。由图7 可以看出,CA_Deeplab v3+性能略微优于Deeplab v3+,而CA_SFEM_Deeplab v3+在每一个迭代轮次均远优于Deeplab v3+和CA_Deeplab v3+。这是由于模型不仅通过融入Coordinate Attention 模块增强保留空间信息的能力,而且通过嵌入SFEM 模块增强语义特征信息。
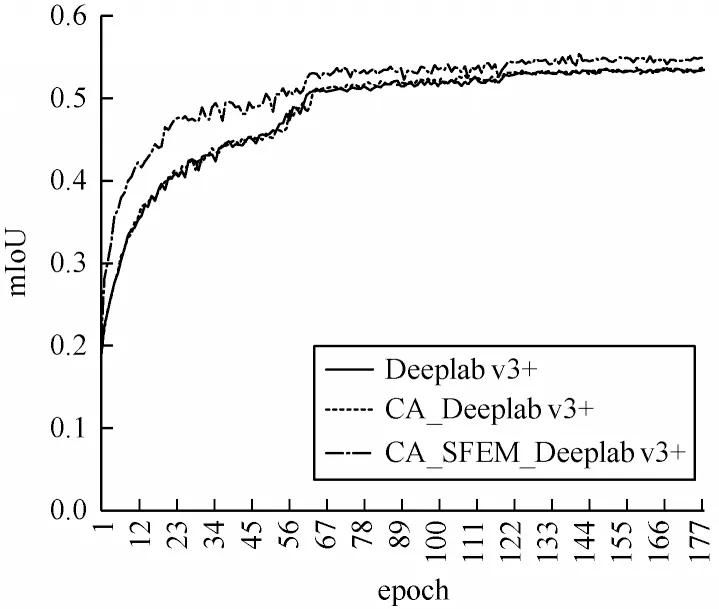
图7 不同网络在验证集上mIoU 结果曲线Fig.7 mIoU result curves of different networks on validationset
2.3.3 分割性能对比
在对比实验中,数据集采用DeepFashion2,包含13 种服装类别及1 个背景类。本文实验对比了Deeplab v3+、CA_Deeplab v3+和CA_SFEM_Deeplab v3+对服装分割的影响。由表1 可以看出,首先仅在主干网络resnet101 首尾添加了注意力机制Coordinate Attention模块的CA_Deeplab v3+,相比Deeplab v3+在MPA 指标上提升0.7%,结合图7 的增长趋势,将主干网络resnet101 中间的各个block 添加Coordinate Attention 会有更好的提升效果。考虑到本实验为主干网络resnet101载入预训练权重,同时兼顾到训练的效率,本文将不再破坏主干网络的结构,仅在resnet101 的首尾添加Coordinate Attention。其次在Coordinate Attention 模块基础上添加特征增强SFEM 模块的CA_SFEM_Deeplab v3+,MPA、mIoU 定量指标有了明显提升,与Deeplab v3+相比分别提升了2.3%、2.1%。这是因为本文提出的CA_SFEM_Deeplab v3+网络嵌入了Coordinate Attention和SFEM 模块,更准确地提取了特征信息,使得分割的精度较高。
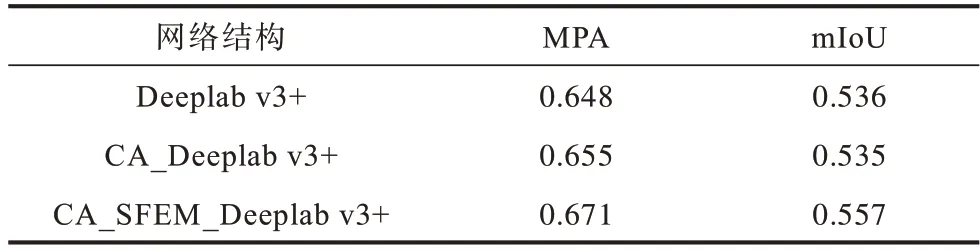
表1 添加不同模块的性能比较Table 1 Performance comparison by adding different models
为了更好地展现本文方法性能提升的直观效果,本文将网络分割出来的掩码对原图进行处理,将背景类别置为黑色,仅保留原始服装图像的服装分割图,因此直观显示出模型分割得到有用的服装信息。图8 所示分别为服装原图、标签图和3 个模型分割服装图像(彩色效果见《计算机工程》官网HTML版)。

图8 不同模型在DeepFashion2 数据集上的分割效果Fig.8 Segmentation effects of different models in DeepFashion2 datasets
从图8 可以看出:在第一排服装分割图矩形框标注的区域,CA_SFEM_Deeplab v3+网络在长袖边和裤子结合处像素点误分类最少;在第二排服装分割图矩形框标注的区域,嵌入Coordinate Attention 的CA_Deeplab v3+网络在长袖像素点处相较于Deeplab v3+网络误分类更少,而CA_SFEM_Deeplab v3+网络在长袖像素点处不存在误分类的像素点;在第三排服装分割图矩形框标注的区域,CA_SFEM_Deeplab v3+网络在连衣裙袖口的边界处分割最平滑,分割效果最好;在第四排服装分割图矩形框标注的区域,在左边裤脚的轮廓处,CA_SFEM_Deeplab v3+网络将手部边界同裤腿边界分离的效果最好,分割的正确率最高,分割的结果最为贴近标签图。观察所有分割结果对比图,CA_SFEM_Deeplab v3+对服装分割更为精细,对服装边缘分割更为流畅,使得服装分割更为接近服装的真实轮廓。综上所述,本文CA_SFEM_Deeplab v3+网络对分割服装位置的精准性最优,对服装特征提取也更为充分,分割性能有了明显提高。
为了证明本文网络的分割有效性,选取了目前有代表性的主 流语义分割网 络PSP-Net[7]、Deeplab v3+[14]和FastFCN[33]和本文提出的CA_SFEM_Deeplab v3+网络进行对比实验。实验的数据集采用DeepFashion2。根据本文提出的两个量化指标,结合表2 可以得出,Deeplab v3+网络与PSP-Net 网络相比分割性能有了一定的提高,而本文提出的CA_SFEM_Deeplab v3+网络在MPA 和mIoU 定量指标上数值分别为0.671 和0.557,相较于PSP-Net 网络分别提升了8.3%和8.6%,相较于Deeplab v3+网络分别提升了2.3%和2.1%,相较于FastFCN 网络分别提升了0.9%和1%。实验数据结果表明,本文提出的CA_SFEM_Deeplab v3+网络相较于其他网络在服装数据集DeepFashion2 上更具有优势。

表2 不同分割网络性能比较Table 2 Performance comparison of different segmentation networks
3 结束语
本文提出一种用于服装分割任务的CA_SFEM_Deeplab v3+网络,该网络模型在主干网络的首尾分别嵌入了注意力机制模块,主干网络输出的特征图首先经过ASPP 结构处理,随后通过SFEM 模块对特征图进行语义特征增强处理,然后将特征图进行融合,经过上采样,最终得到服装分割的预测图。实验结果证明,相对于Deeplab v3+网络,CA_SFEM_Deeplab v3+网络具有更好的分割精度,能够实现对服装的准确分割。本文网络虽提升了分割精度,但嵌入注意力机制和SFEM 模块增加了参数量,降低了分割效率。此外,其在解码模块中仅使用了融合1/4 大小的低层特征图和编码模块输出的高层特征图,而单层次提取目标特征易导致小目标丢失或大目标特征提取冗余。后续将精简分割模型,进一步提高模型的准确率和分割效率。
