基于注意力引导数据增强的车型识别
2022-07-14孙伟常鹏帅戴亮张小瑞陈旋代广昭
孙伟,常鹏帅,戴亮,张小瑞,陈旋,代广昭
(1.南京信息工程大学自动化学院,南京 210044;2.南京信息工程大学江苏省大气环境与装备技术协同创新中心,南京 210044;3.南京信息工程大学数字取证教育部工程研究中心,南京 210044;4.南京信息工程大学计算机与软件学院,南京 210044)
0 概述
在智能交通系统中,车型识别[1]对于与智慧城市、无人驾驶、交通流计算等相关的实际应用具有重要意义。虽然车型识别研究已经取得了快速发展,但是仍然面临着诸多难题。因数据的采集与标注需要专业的知识和大量的时间,导致公开的车辆数据集较少[2]且数据集中的样本容量不足,基于数据驱动的车型识别效果降低。车辆不仅种类繁多,而且在同一品牌不同型号车辆之间的外观差异微小[3],导致车型识别率降低。因此,在车辆数据集不足的情况下,通过有效学习类别间区分性特征表达来分辨车型是解决以上难题的有效方法。
随着深度学习技术的发展,车型识别方法取得较大的进展[4-5]。ResNet 是深度学习中经典的卷积神经网络(Convolutional Neural Network,CNN),广泛应用于计算机视觉领域中的分类任务[6]。卷积神经网络由残差块和捷径连接构建层数较深的网络,以促进特征信息的利用与传递,但是仅通过现有的ResNet 难以获得准确的分类结果,需要采用注意力机制对现有网络进行特殊设计,以提高深层网络的性能[7]。基于注意力机制的神经网络学习方法[8]可以定位出对分类贡献较大的鉴别性位置信息,提高网络的表征能力。文献[9]基于OI-LSTM结构,将CNN与长短时记忆(Long Short-Term Memory,LSTM)网络相结合,在CNN 提取特征的同时,LSTM对提取的特征进行时序捕捉,但是LSTM网络在一个连续的过程中捕捉目标的注意信息时存在梯度消失的问题。文献[10]提出SE(Squeeze-and-Excitation)注意力模块,通过挤压每个二维特征图,以有效建立通道之间的相互依赖关系,从而提高模型性能,但是SE 模块会忽略位置信息,而位置信息对于在视觉任务中捕捉目标结构至关重要。文献[11]提出CBAM(Convolutional Block Attention Module)机制,通过减少输入张量的通道维数来利用位置信息,使用卷积计算空间注意力,但是卷积只能捕捉局部关系,无法对分类任务所必需的远程依赖关系进行建模。受SE模块的启发,文献[12]提出一种坐标注意力(Coordinate Attention)模块,该注意力不仅能够学习到图像通道域上的信息,还可以捕获方向感知和位置敏感信息,有助于模型更准确地定位和识别感兴趣的区域。
为解决车型识别中数据不足的问题,研究人员采用数据增强以降低过拟合现象的发生,从而提高模型的鲁棒性。训练数据量的增加是通过引入更多的数据差异,提高模型的泛化能力。在深度模型中数据增强方法[13-14]包括图像裁剪、图像擦除等。随机图像裁剪可以生成不同缩放比例的图像,使得输入深度模型的数据样本增多,在一定程度上改善模型的训练效果。但是这种数据增强方法可能会引入许多背景噪声,不仅不能提高提取特征的质量,反而会降低模型的训练效果。文献[15]提出自动增强方法,构建一个数据增强策略的搜索空间,利用搜索算法选取适合特定数据集的数据增强策略,但是与随机数据增强相比,其难以实现。文献[16]提出弱监督的数据增强网络(Weakly Supervised DataAugmentation Network,WS-DAN),通过注意力机制来增强数据,这种注意力机制使用的卷积核尺寸较小,在特征提取的深层网络引入注意力机制,使得浅层网络难以关注到原始特征的鉴别部分,导致数据增强质量降低。
本文提出一种基于注意力引导数据增强的车型识别方法。采用ResNet-50 骨干网络提取特征,在ResNet-50 每个残差块后都嵌入坐标注意力模块,生成一对方向感知和位置敏感的注意力图。利用双线性汇集(BAP)操作获得增强特征图,通过对增强特征图进行注意力裁剪和注意力擦除得到增强数据,将原始数据和增强数据输入到网络中进行训练,以提高识别准确率。
1 车型识别模型
受弱监督的数据增强网络(WS-DAN)[16]的启发,本文提出注意力引导数据增强的车型识别模型。车型识别模型结构如图1 所示。

图1 车型识别模型结构Fig.1 Structure of vehicle type recognition model
车型识别模型将ResNet-50 作为骨干网络提取特征,在骨干网络ResNet-50 的每个残差块后都嵌入注意力CA 模块,使得车辆鉴别性部分特征在网络的每个阶段都能够得到明显关注,解决了WS-DAN 方法中数据增强质量较低的问题。表1 表示ResNet-50 骨干网络中每个区块(Block)的划分,包括卷积层中卷积核的大小和数量、池化层中池化核的大小和步长以及输出特征图的尺寸。
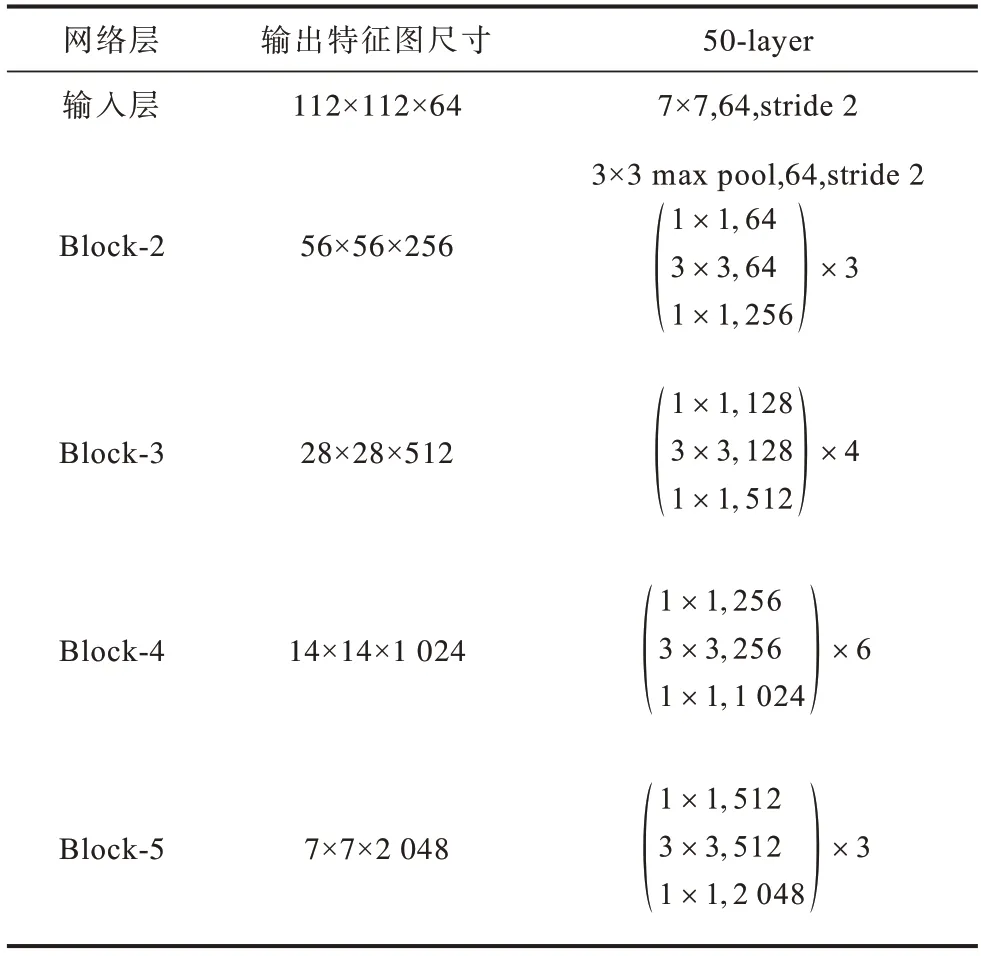
表1 ResNet-50 骨干网络的结构Table 1 Structure of ResNet-50 backbone network
CA 模块将通道分解为沿着两个空间方向分别聚合特征的一维特征编码,在捕捉一个方向特征的同时保留另一个空间方向的精确位置,生成一对方向感知和位置敏感注意力图。车型识别模型在得到注意力图后,通过双线性注意力汇集(BAP)生成增强特征图,在增强特征图的引导下进行注意力裁剪和注意力擦除,生成具有强鉴别性的增强数据,将其与原始的车辆图像一并送入到网络中进行训练。
1.1 坐标注意力模块
CA[12]模块用于计算机视觉任务,既考虑通道注意,也考虑经典SENet[10]模块忽略的位置信息,能够有效提升模型的性能。CA 模块沿着一个空间方向捕获远程依赖关系,同时沿着另一个空间方向获取精确的位置信息,从而编码出一对方向感知和位置敏感的注意力图,有效增强车辆鉴别性区域的表示,从而学习到类别间更加丰富的区分性信息。注意力CA 模块结构如图2 所示。
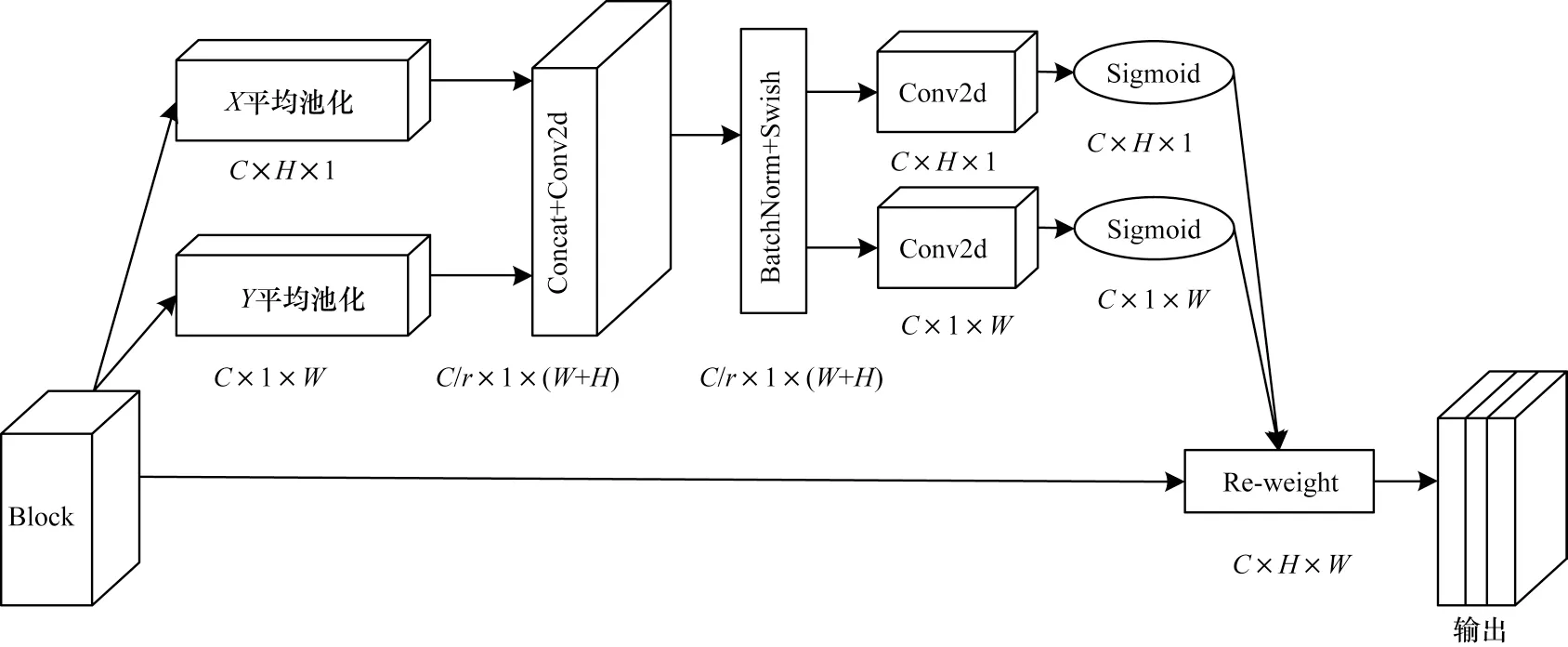
图2 坐标注意力模块结构Fig.2 Structure of coordirate attention module
假设对于给定的输入特征图X∊RC×H×W,使用池化核(H,1)或者(1,W)分别沿着水平坐标和垂直坐标编码每个通道,成为并行的2 个输出,在特征高度H和宽度W的第C个通道的输出如式(1)和式(2)所示:
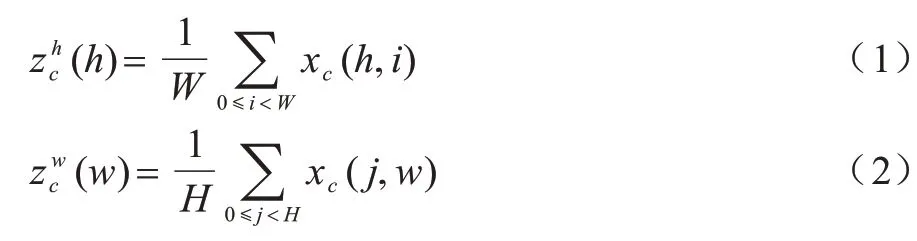
将上述2 个公式得到的特征图拼接,采用1×1 的卷积核进行卷积,如式(3)所示:

其中:[∙,∙]表示沿空间维度的拼接;δ表示Swish 激活函数;F1表示卷积运算。f∊RC/r×(H+W)是在水平方向和垂直方向编码空间信息生成的中间特征图,r是控制通道的缩减因子。CA 模块沿空间维度把f分成2 个独立的张量,再用1×1 的卷积核分别卷积分解后的独立张量,得到与输入X具有相同通道数量的张量,如式(4)和式(5)所示:

其中:Fh、Fw为2个卷积操作;fh∊RC/r×H;fw∊RC/r×W;σ为Sigmoid 函数;gh∊RC×H和gw∊RC×W分别为沿h和w方向的注意力权重参数。
CA 模块的输出如式(6)所示:
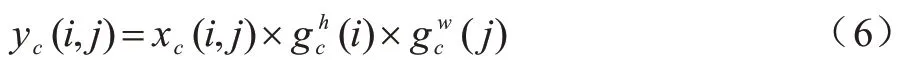
1.2 注意力引导的数据增强
在注意力引导的数据增强方法中需要进行双线性注意力汇集(BAP)操作。假设F∊RH×W×C作为输入的特征图,其中H、W、C分别表示输入特征图的高度、宽度、通道数量。1×1 的卷积核作用于输入特征图,生成注意力图A∊RH×W×N,其中N是注意力图的个数。注意力图A与特征图F执行双线性注意力汇集(BAP)操作,即特征图与注意力图对应位置逐元素相乘得到中间特征图,然后对这些中间特征图进行池化拼接运算得到最后的特征矩阵。双线性注意力汇集操作如式(7)所示:
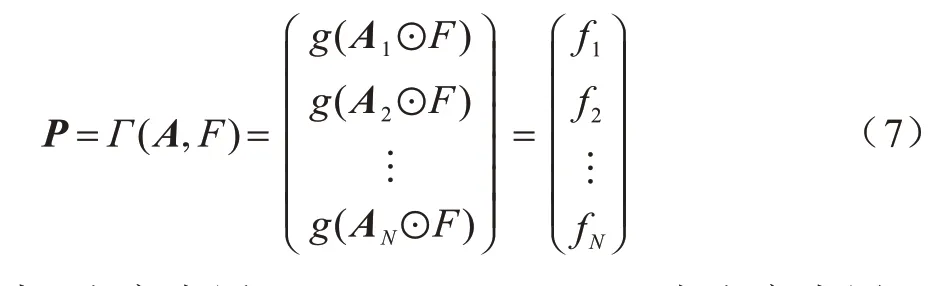
其中:注意力图A=[A1,A2,…,AN];⊙为注意力图A中的一个张量A1与F对应元素逐个相乘;g(∙)为全局平均池化操作;特征矩阵P∊RN×C由中间特征图[f1,f2,…,fN]拼接而成;Γ(A,F)为注意力图A和特征图F之间的双线性注意力汇集。
为了聚合注意力图上鉴别性区域的特征,受中心损失[17]解决人脸识别的启发,本文在弱监督注意力学习过程中引入注意力正则化损失函数。该损失函数不仅在最小化类内变化的同时保持了类间特征的可区分性,而且缩小了属于同一部分特征间的差异,如式(8)所示:

其中:cn为车辆某部分特征中心,可初始化为0;fn为某部分特征,如车辆的格栅;N为注意力图的数量。cn通过滑动平均公式更新,更新速率为α,如式(9)所示:

数据增强操作主要分为以下4 个步骤:
1)随机选出一张注意力图AN来引导数据增强的过程,通过对AN进行归一化处理,得到增强特征图如式(10)所示:

3)将式(11)获得的裁剪掩膜扩大到原始图像尺寸,并将其作为输入网络的增强数据,以放大车辆的鉴别性区域,有效地提取细节特征。
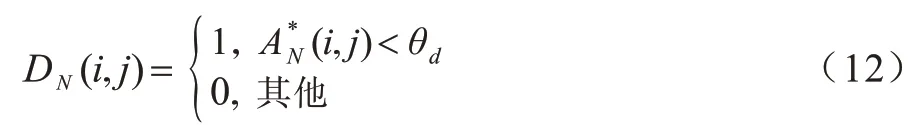
由式(12)得到擦除掩膜DN后,将其从原始图像中擦除,保留擦除之外的其余部分,从而得到另一个新图像。因此,注意力擦除有助于网络提取车辆其他鉴别性部分特征。
2 实验结果与分析
2.1 实验环境
本文实验所使用的计算机硬件为AMD Ryzen 7 3700X 8-Core Processor 3.59 GHz 处理器,内存16 GB,显卡为GeForce RTX 2070 SUPER 8 GB。软件环境为Windows 10 操作系统,Pycharm 开发环境,Pytorch 深度学习框架,Python3.6 编程语言。
2.2 数据集
本文采用公开的Stanford Cars[18]车辆数据集。Stanford Cars 数据集包含196 种车型的图像数据,共有16 185 张图像,其中训练图像和测试图像分别为8 144 张和8 041 张,标签具体到车辆型号和年份。数据集中部分车辆图像如图3 所示。

图3 Stanford Cars 数据集的部分车辆图像Fig.3 Partial vehicle images of Stanford Cars dataset
本文实验的评价指标为分类准确率(accuracy),如式(13)所示:

其中:i为车辆样本序号;m为车辆总数;yi为车型识别模型预测输出;yi为车型真实标签。
2.3 实验结果
本文将ResNet-50 作为骨干网络,选择Block-5_3的输出张量作为注意力图A的输入特征图,注意力图A的数量N设为32,注意力裁剪和注意力擦除的阈值θc和θd均设置为0.5。
本文使用随机梯度下降方法训练模型,利用ImageNet 数据集对预训练得到的权重进行参数微调,批大小设置为8,动量为0.9,训练轮数(epoch)为100,权重衰减值为0.000 01,初始学习率(Learning Rate,LR)为0.001,每2 个epoch 后LR 指数衰减0.9。
2.3.1 消融实验
本文在Stanford Cars 数据集上进行消融实验,验证本文方法的有效性。消融实验结果如表2 所示,基准模型采用原始的ResNet-50 网络结构。

表2 消融实验结果Table 2 Results of ablation experiment %
从表2 可以看出,ResNet-50 网络车型识别准确率达到91.02%。在ResNet-50 网络中嵌入CA 模块后,ResNet-50+CA 方法的准确率比ResNet-50 提升了1.87 个百分点,说明该注意力机制能够学习到车辆具有鉴别性的区域特征,提高模型的表达能力。如果在ResNet-50 网络中仅使用WS-DAN 方法,车型识别准确率也有所提高,准确率为94.53%。本文方法是在ResNet-50 网络中同时使用CA 和WS-DAN 的方法,车型识别准确率达到94.86%,说明本文方法在有效增强数据的同时,使得提取的特征更加具有可区分性,从而提升车型识别的性能。
2.3.2 CA 模块与SENet 模块的对比
本文在Stanford Cars数据集上对CA 模块与SENet模块进行对比,以验证CA 模块的有效性,从而改进车型识别的效果。不同注意力模块引导的数据增强模型损失曲线如图4 所示。
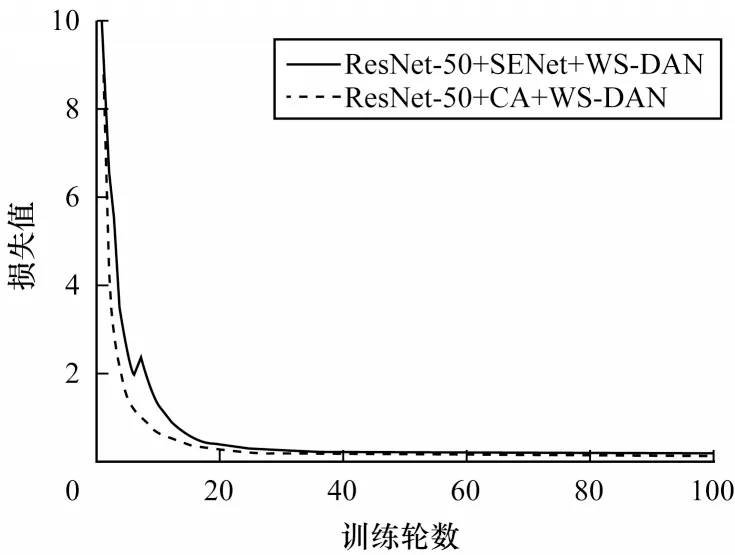
图4 不同注意力模块引导的数据增强模型损失曲线Fig.4 Loss curves of data augmentation models with different attention modules guided
从图4 可以看出,在模型的训练过程中,经过SENet 模块引导的数据增强模型损失曲线在训练轮数为10 时出现了较大的波动,之后缓慢下降,在训练轮数为50 时基本趋于收敛。CA 模块引导的数据增强模型损失曲线在整个训练过程中平滑下降,收敛速度比SENet 模块引导的数据增强模型曲线快。
不同注意模块引导的数据增强模型准确率曲线如图5 所示。从图5 可以看出,SENet 和CA 这2种注意力引导的数据增强模型准确率曲线的趋势相近,但是CA 模块引导的数据增强模型的准确率高于SENet 模块,说明这2 种注意力机制均可以增强模型对车辆鉴别性区域的表示能力。但是注意力SENet模块仅考虑了模型通道之间的相互依赖关系,忽略了位置信息的重要性,而CA 模块将通道注意力分解为2 个一维特征编码,分别沿2 个空间方向聚集特征,使得模型能够沿着一个空间方向捕获远程依赖关系,同时沿着另一个空间方向获得精确的位置信息。因此,本文所提的CA 模块引导的数据增强模型具有更优的识别效果。
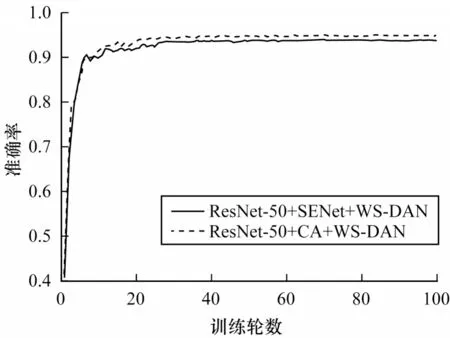
图5 不同注意力模块引导的数据增强模型准确率曲线Fig.5 Accuracy curves of data augmentation models with different attention modules guided
2.3.3 热力图可视化
不同模型的车型识别热力图[19]如图6 所示。从图6(b)可以看出,原始模型ResNet-50 对车辆的特征提取不明显,难以关注到车辆的鉴别性区域。从图6(c)可以看出,在原模型中嵌入注意力CA 模块后,网络对于特征的提取集中在车辆的尾部,说明该区域的鉴别性强,对于车型的正确分类具有重要作用。

图6 不同模型的车型识别热力图Fig.6 Heatmaps for vehicle type recognition of different models
2.3.4 注意力引导的数据增强与随机数据增强对比
注意力裁剪与随机裁剪方式的效果对比如图7 所示。从图7(a)可以看出,注意力裁剪能够有效裁剪出车型的整个区域。从图7(b)可以看出,随机裁剪把车尾部分裁掉了,如果鉴别性特征聚集在车尾部分,那么随机裁剪使得车尾信息丢失,识别效果相比注意力裁剪的数据增强效果差。

图7 注意力裁剪与随机裁剪对比Fig.7 Comparison between attention cropping and random cropping
注意力擦除和随机擦除方式的效果对比如图8 所示。从图8(a)可以看出,注意力擦除可以擦除车辆的某个部分,使得网络去寻找车辆其他鉴别性区域的特征,提高模型的鲁棒性。从图8(b)可以看出,随机擦除的部分是背景噪声,不在车辆区域上,而背景噪声对车型识别没有帮助,无法使网络学习车辆其他更多的鉴别性区域,使得数据增强效果较低。

图8 注意力擦除与随机擦除对比Fig.8 Comparison between attention erasure and random erasure
2.3.5 不同识别方法对比
不同方法的识别准确率对比如表3 所示。从表3可以看出,相比VGG-19 方法[20],Inception-v3 方法[21]的识别准确率提高了5.12 个百分点。RA-CNN 方法[22]通过逐渐聚焦图像的关键区域,融合不同尺度的注意力区域信息,其准确率为92.50%。MA-CNN 方法[23]则提出多注意力网络,通过特征通道生成更多的判别部分,并以相互强化的方式从判别部分学习更优的细粒度特征,相比RA-CNN 方法,准确率提高0.31 个百分点。WS-DAN 方法[16]使用的骨干网络是Inception-v3,基于弱监督学习有效提高数据增强的效率,车型识别准确率为94.5%。相比WS-DAN+Inception-v3 方法,本文方法的车型识别准确率提高了0.36 个百分点,在增强数据的同时提高模型的识别能力。

表3 不同方法的识别准确率对比Table 3 Recognition accuracy comparison among different methods %
3 结束语
针对传统方法车辆数据不足且识别率较低的问题,本文提出基于注意力引导数据增强的车型识别方法。使用ResNet-50 骨干网络提取特征,在网络的每个残差块后都嵌入坐标注意力模块,以准确定位车辆的鉴别性区域,增强车辆鉴别性区域的特征表示。利用双线性注意力汇集生成增强特征图,并对其进行注意力裁剪和注意力擦除以获得增强数据。在Stanford Cars 数据集上的实验结果表明,与RA-CNN 方法、MA-CNN 方法、WS-DAN+Inception-v3 等方法相比,本文方法能够有效提高车型识别准确率且具有较优的鲁棒性。下一步将采用知识蒸馏技术,把知识从繁琐的模型转移到更适合部署的小模型上,使车型识别模型适用于嵌入式边缘设备。
