基于海林格距离加权关键主元的流程工业故障检测研究
2022-07-14苏圣超
赵 成 苏圣超
(上海工程技术大学 电子电气工程学院,上海 201620)
引 言
随着现代工业的快速发展,工业生产的安全性与可靠性变得尤为重要。近年来,以故障检测为主导的过程监测技术与方法成为学术界和工业界的研究热点。目前的故障检测方法主要分为以下3类:基于数学模型的故障检测方法,基于定性知识的故障检测方法和基于数据驱动的故障检测方法。其中基于数据驱动的故障检测方法与基于数学模型的故障检测方法相比,不需要精准的系统模型,同时随着传感器技术的飞速发展,海量数据的获得也变得更加容易,因此基于数据驱动的故障检测方法扮演着愈加重要的角色[1]。主成分分析(principal component analysis,PCA)作为一种基于数据驱动的故障检测算法,由于其简便的算法流程及对高维数据的高效处理能力而受到广泛的关注与研究[2],相关的拓展算法包括概率PCA(probability PCA)[3]、核PCA(kernel PCA)[4]、动态PCA(dynamic PCA)[5]等。
尽管对于PCA算法的各种改进有很多,但针对其中主元的选取及后续的处理问题仍然需要更加深入的研究。传统的主元选取方法有累计方差贡献法(cumulative percent variance,CPV)[6],重构误差方差法(variance of the reconstruction error,VRE)[7]和平均特征值法(average eigenvalue,AE)[8]等。这些方法都是认为较大方差所对应的主元包含更多的信息,而较小的方差所对应的主元则常常被忽视。Jolliffe[9]提出具有较小方差的主元和具有较大方差的主元同等重要,Togkalidou等[10]指出具有较大方差的主元不一定具有最多的信息量。因此,仅凭方差的贡献度大小来确定主元的方法过于主观机械,有可能造成有用信息的丢失。同时,传统主元选取方法根据正常工况数据进行线下建模,没有考虑故障样本对建模的影响。上述问题都会导致故障检测性能的大幅下降。为此,陶阳等[11]将RelifeF算法与PCA算法相结合,从故障特征角度出发,避免了主元选取时的主观性。Jiang等[12]统计单个主元T2统计量的变化率,通过选取与监测敏感主元进行故障检测,但在选取主元阶段仍采用传统的CPV方法,导致有用信息丢失,从而影响检测效果。仓文涛等[13]通过构造累计T2统计量的变化率来体现主元的变异程度,但是传统T2统计量要求数据变量服从正态分布,而实际工业流程中采集到的数据显然很难满足此限制条件。同时从几何角度来看,T2统计量实质上是一个椭圆形控制边界,误差较大。Song等[14]提出全变量表达(full variable expression,FVE)的主元选取方法,选取对各个变量解释性最大的主元作为关键主元,保留了所有变量信息,取得了良好的故障检测效果。但该方法仍然是依据T2统计量的形式构造相应的统计量进行检测;其次,上述所有方法都是同等看待被选主元。实际上,故障发生时只有某些主元含有与故障相关的重要信息,这些主元在后续处理中需要加以突出。海林格距离(Hellinger distance,HD)是信息论中的一个概念,在统计学和概率学中用来衡量两个概率密度分布间的差异。在故障检测领域,Jiang等[15]将HD用于变量块的划分,将拥有相似概率密度分布的变量归结到同一个分块进行故障检测;Harrou等[16]将HD作为统计量,用来监测非线性投影产生残差的概率密度分布;Chen等[17]将HD用于高速列车的故障检测,相关实验表明HD作为散度的一种,有着比Kullback-Leibler(K-L)散度更好的检测效果。
局部离群因子(local outlier factor,LOF)由Breunig等[18]提出,用于搜寻数据中的离群点。该方法利用样本点的局部离群因子值的大小来衡量其离群程度,对于样本数据的分布没有要求。故障样本相对于正常样本即可视为离群点,因此该算法已开始被研究者运用到故障检测领域。Lee等[19]将LOF算法与独立元分析法相结合,用于解决数据高斯与非高斯混合分布情况下的故障检测问题,突破了传统独立元分析法对于非高斯分布数据的限制。Deng等[20]利用双加权策略改进核主元分析法,并将其与LOF算法相结合,兼顾了工业过程的非线性特点以及数据的非高斯分布。冯立伟等[21]提出基于时空近邻标准化(time-space nearest neighborhood standardization,TSNS)-LOF的故障检测方法,提高了对于多模态过程的故障检测能力。由以上文献可以看出,将LOF算法融入到故障检测方法中并且构建相应的统计量,有利于提高故障检测能力。
本文在FVE方法基础上,利用海林格距离变化率对故障的敏感性提出一种基于全变量表达和海林格距离的故障检测算法(Hellinger distance weighted full variable expression-Mahalanobis distance LOF,HDWFVE-MDLOF)。首先利用FVE的主元选取方法有效地保留了全部变量信息,之后提出基于海林格距离变化率的指标,突出故障相关主元;同时,考虑到数据变量的无特定分布以及尺度问题,将加权后的关键主元作为改进LOF算法的输入,构造相应统计量进行故障检测。数值仿真实例和带钢热连轧实际生产数据验证了所提方法的有效性与优越性。
1 PCA算法及海林格距离
1.1 PCA算法
PCA是一种用于多变量统计过程监控的基本方法,其具体实施步骤如下。给定一个原始数据矩阵X∈Rn×m,其中n为样本数,m为变量数(传感器个数),其协方差矩阵为

接下来对协方差矩阵进行奇异值分解(SVD)

其中,
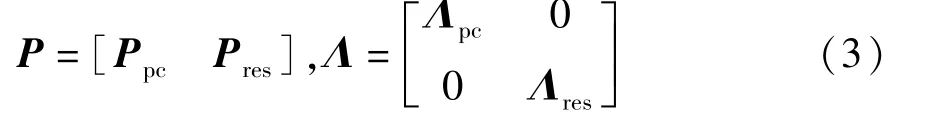
式中,Λpc=diag(λ1,λ2,…,λl),Λres=diag(λl+1,λl+2,…,λm),P为负载矩阵,Λ为特征值矩阵;l作为主元个数将负载矩阵划分成两部分,即主元空间的Ppc和残差空间的Pres。l由累计方差贡献率(CPV)确定
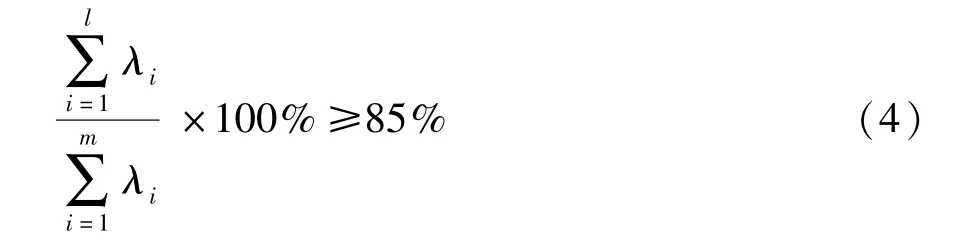
根据以上描述,样本X∈Rn×m可以被分解为

在PCA分解后的两个空间里分别建立T2统计量与平方预测误差(squared prediction error,SPE)统计量
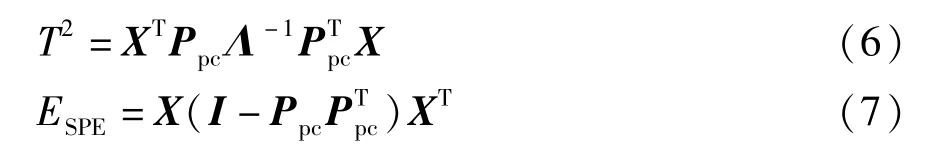
T2统计量反映的是主元空间的变化,而SPE统计量反映的是残差空间的变化。关于T2和SPE这两个统计量的具体描述以及相应控制限的设定可以参考文献[22],两个统计量中只要有任意一个超过其对应控制限,即可认定有故障发生。
1.2 海林格距离
HD作为一种度量两个概率密度分布差异的工具,已得到广泛应用[23-25]。假设有两个连续的概率密度函数f(x)和g(x),那么f(x)和g(x)之间的海林格距离可以由式(8)描述。
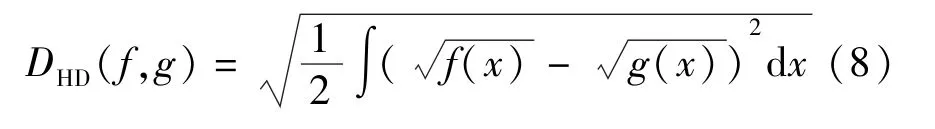
f(x)和g(x)的差异越大,HD的数值就越大。因此HD能够用来衡量正常指标与异常指标之间的差异。同时,海林格距离是一个对称有界的距离,即0≤DHD(f,g)=DHD(g,f)≤1,根据勒贝格测度[26]可以得到式(8)的平方变形形式
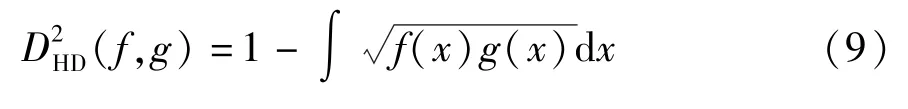
2 基于马氏距离的局部离群因子

同时,定义样本xi的局部可达密度为
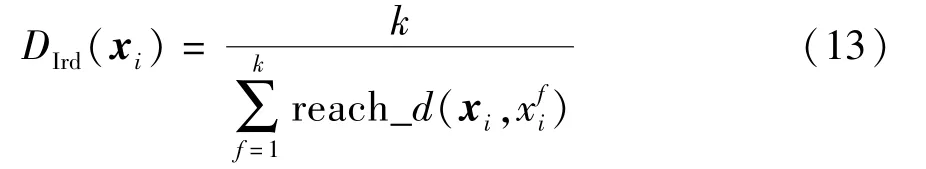
样本xi的局部离群因子表示为xi所有近邻的平均局部可达密度与样本点xi的局部可达密度的比值
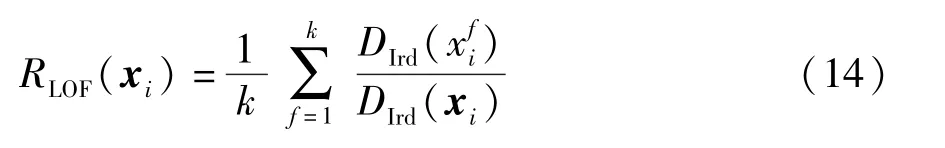
3 基于HDWFVE-MDLOF的故障检测方法
3.1 HDWFVE-MDLOF算法
X∈Rn×m经过PCA分解后得到得分矩阵T=[t1,t2,…,tm]∈Rn×m,传统PCA算法根据正常工况下的样本建立相应的模型,如式(15)所示,主元可由所有变量线性表示
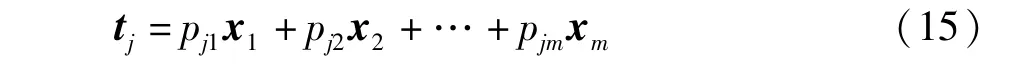
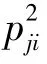


式中,n为样本个数,Ff,n-f;α为置信水平1-α下、自由度f和n-f的F分布临界值。关键主元的具体描述可以参考文献[14]。
一般情况下,当故障发生时,不同得分向量与故障之间的相关性是存在差异的。得分向量较正常工况变化幅度越大,说明其包含越多的信息量[12],与故障的发生也越紧密相关。因此,须根据得分向量与故障的相关性给予其不同的权重值。与故障相关性越大的得分向量,对后续故障检测的贡献度也越大,需赋予较大的权重。本文利用基于海林格距离的得分向量变化率对权重进行定义,并且给出了该指标对于故障敏感性的证明。从故障对得分向量产生的影响角度出发,文献[28]对加性故障和乘性故障有如下定义:加性故障指故障的发生只影响得分向量的均值,乘性故障指故障的发生只影响得分向量的方差。由文献[28]可知,传统T2统计量对于乘性故障的检测效果较差,这是由于T2统计量本身的定义是从加性故障的角度出发的。接下来,给出基于海林格距离变化率的统计量。
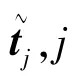
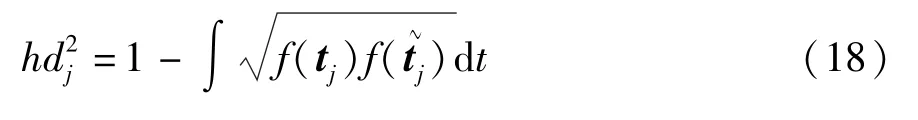
式中,f(tj)和f(~tj)为对应的概率密度函数,可以通过核密度估计获得,核函数采用最常用的高斯核函数形式
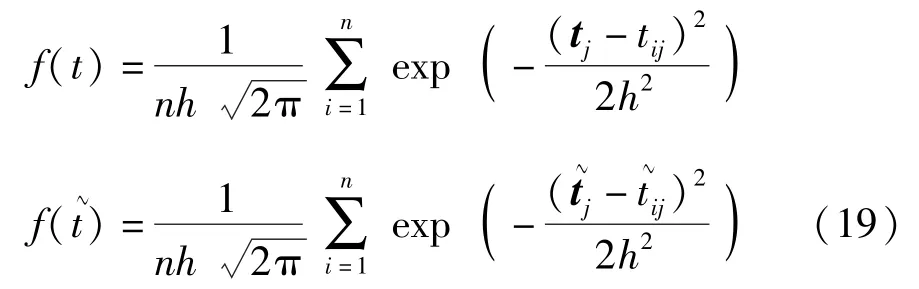
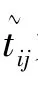
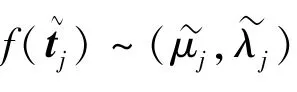
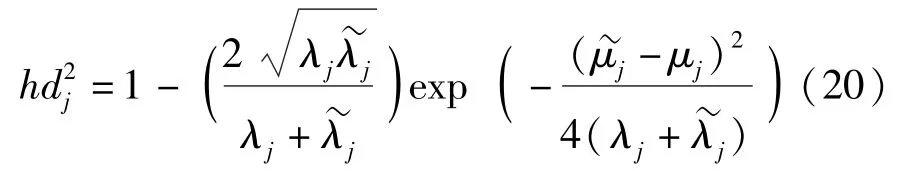
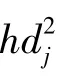

假设故障发生时导致得分向量均值的变化为Δμj,方差变化为Δλj,当传感器发生加性故障,即故障的发生只改变了得分向量的均值时,有
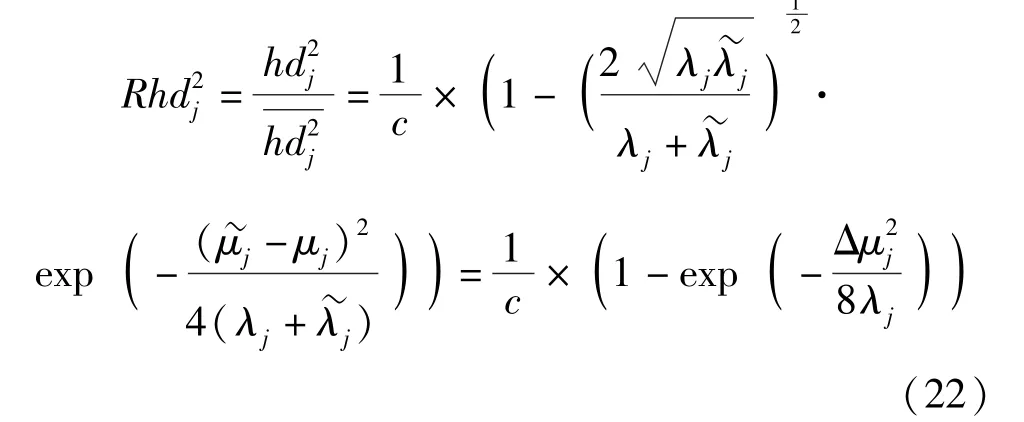
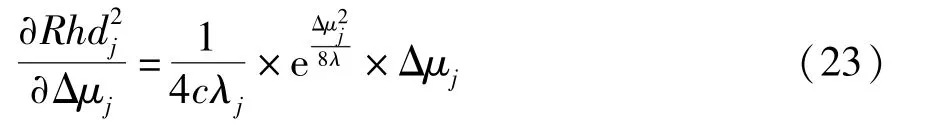
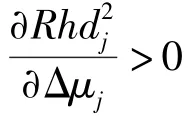
当传感器发生乘性故障,即故障的发生只改变得分向量的方差时,有
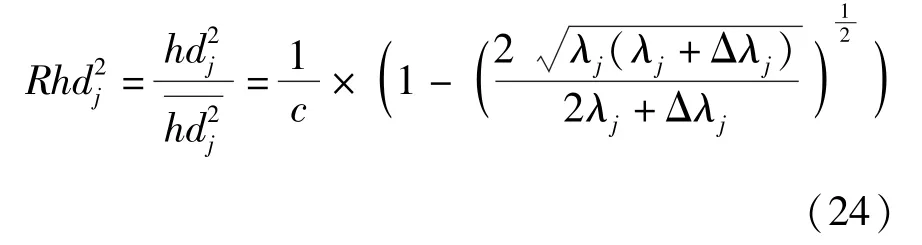
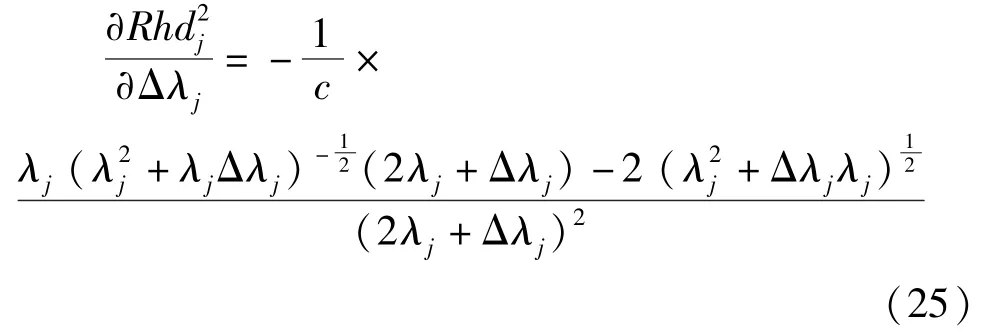
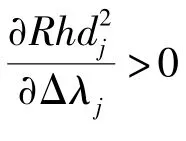
当传感器上加性故障与乘性故障并存,即故障的发生既改变了得分向量的均值,又改变了得分向量的方差时,有
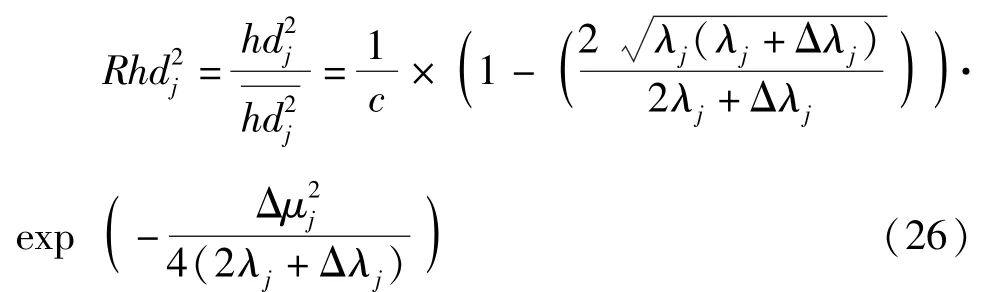
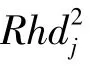
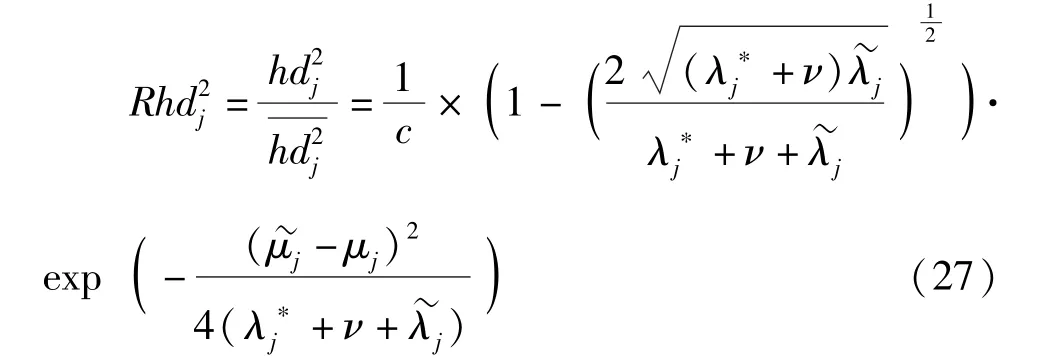
对式(27)关于ν求偏导可得其sgn函数为
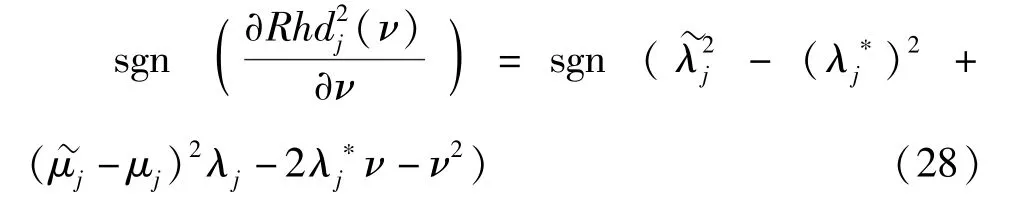
当ν=0时,式(28)的最大值为0,即
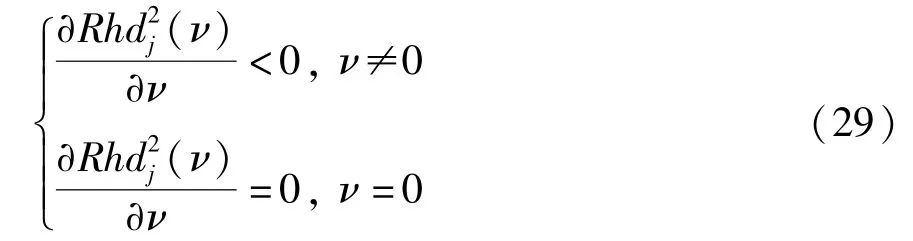

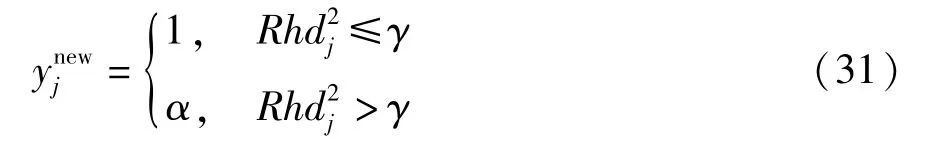
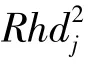

式中,L为预警宽度,一般取值为3,即3σ法则。
那么,新的得分矩阵可表示为
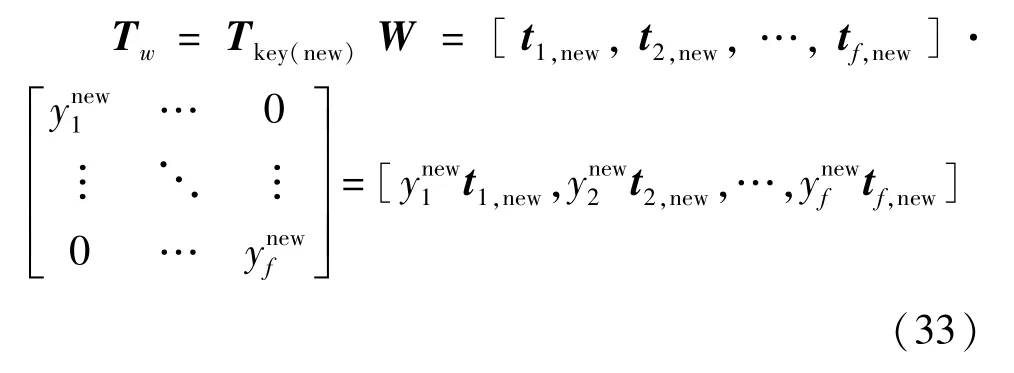
式中,Tkey(new)为故障工况下关键主元构成的得分矩阵,W为加权矩阵。
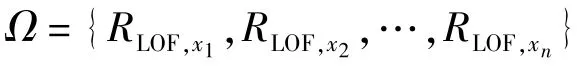
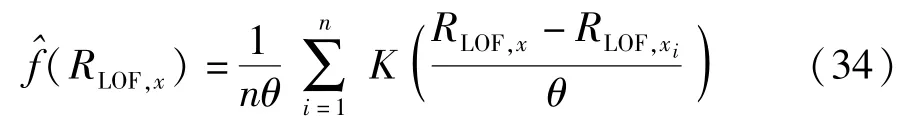
式中,K(·)为核函数,θ为核宽,LOF控制限RLOF,limit在置信水平为α的情况下可由式(35)获得
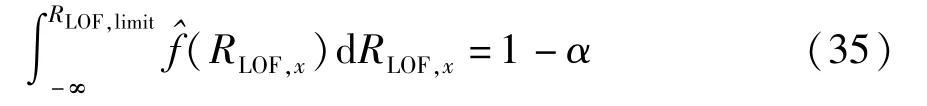
3.2 故障检测步骤
基于HDWFVE-MDLOF的故障检测流程如图1所示。
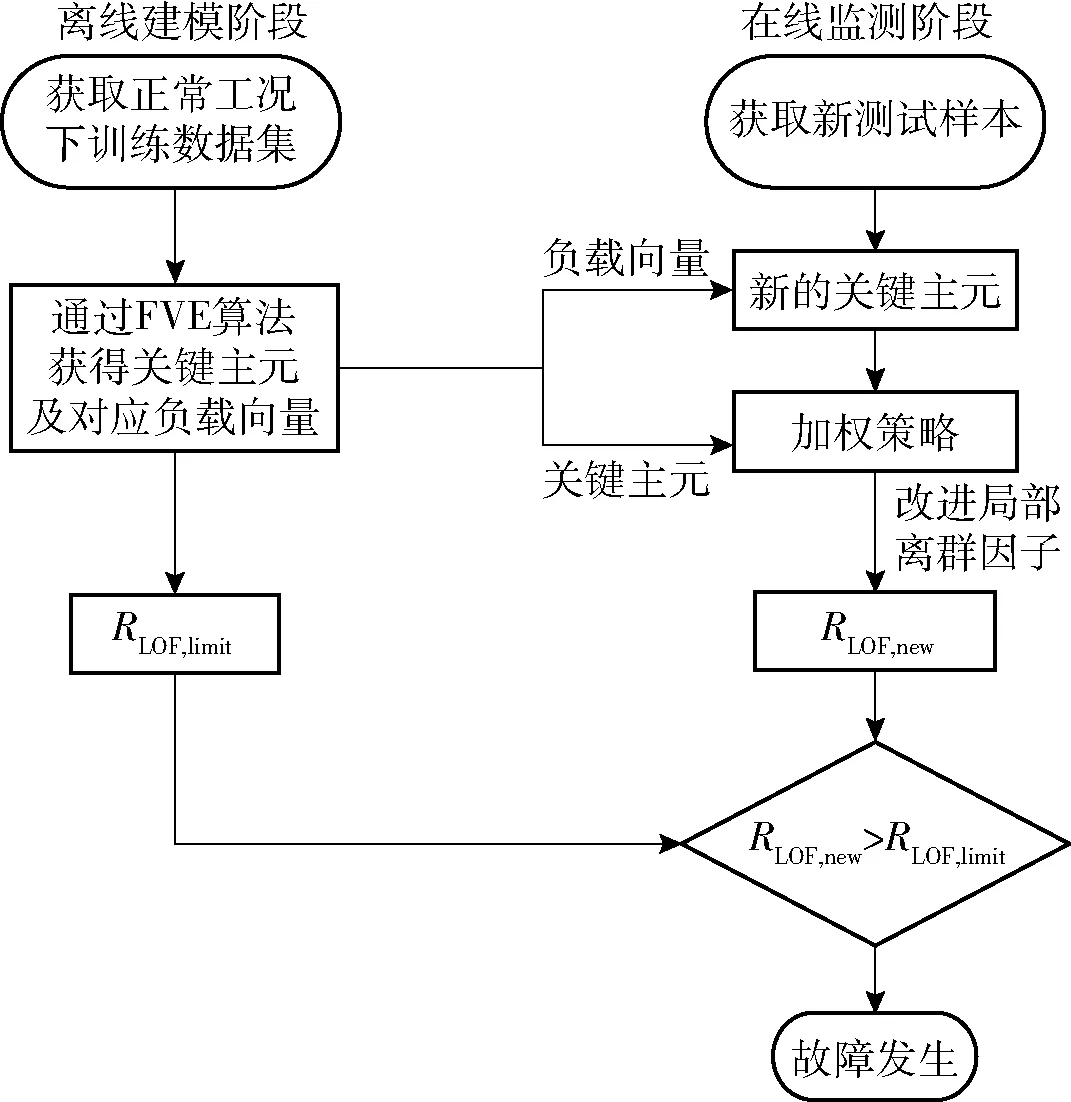
图1 基于HDWFVE-MDLOF的故障检测流程图Fig.1 Flowchart of HDWFVE-MLOF based fault detection
离线建模阶段步骤如下。
1)采集正常工况下的样本数据,标准化得到X∈Rn×m。
3)将Tkey=[t1,t2,…,tf]∈Rn×f作为改进LOF算法的输入,并利用核密度估计确定其控制限RLOF,limit。
在线检测阶段步骤如下。
1)采集异常工况下的样本数据,标准化得到Xnew∈Rn×m。
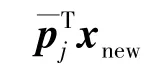
4)将Tw=[t1,new,t2,new,…,tf,new]∈Rn×f作为改进LOF算法的输入,求得统计量RLOF,new,若RLOF,new>RLOF,limit,则说明有故障发生。
4 仿真分析
4.1 数值仿真实例
文献[30]中的数值实例被广泛应用于故障检测的仿真实验中,本文采用此数值实例验证所提方法的有效性。该数值例子表示结构如式(36)所示。
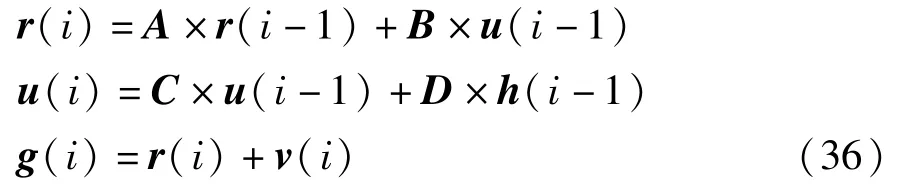

1)故障1 变量h1从第51个样本点开始直到200个样本点结束,增加一个幅值为3的单位阶跃故障。
2)故障2 变量h2从第51个样本点开始直到200个样本点结束,增加一个0.06(i-50)的斜坡故障。
在运用FVE方法进行主元选取时,特征空间包含了几乎所有原始变量的信息,残差空间中几乎不包含有用信息,因此只需构建反映特征空间的T2统计量进行监测。运用本文所提方法与CPV-T2、CPVSPE、FVE-T2、FVE-LOF以及HDWFVE-LOF进行仿真对比实验。其中CPV的贡献度设定为85%,控制限采用95%的置信度;LOF中的k值设定为15,核宽设为500m(m为变量个数)。在CPV主元选取方法中,前3个主元的累计方差贡献率超过了85%,因此按照方差从大到小的顺序选取PC1、PC2、PC3为主元,而在FVE的主元选取方法中,各变量对应的关键主元如表1所示,PC2、PC3、PC4、PC5被选为主元。表2为各个方法对于数值实例中故障1和故障2的漏报率与误报率。各个方法对故障1的检测结果如图2所示。图2(a)、(b)为传统PCA算法利用CPV主元选取方法所构建的基于T2和SPE统计量的故障检测结果,结合表2可知,其中T2统计量的漏报率为74%,检测效果不佳,SPE统计量的漏报率达到75%,表明该统计量基本无法检测到故障的发生。图2(c)为利用FVE主元选取方法进行故障检测的结果,结合表2可知,T2统计量的漏报率降低为48.7%。图2(d)为FVE主元选取法利用LOF作为统计量的故障检测结果,由表2知其漏报率为46%,漏报率的降低是因为该方法从数据密度大小出发来搜寻故障点。图2(e)给出了HDWFVE-LOF的故障检测结果,得益于对故障相关主元的合理加权,由表2可知其漏报率为28%,得到大幅降低。图2(f)为本文所提方法的故障检测结果,可以看出基于马氏距离的LOF算法起到了很好的效果,相比于其他方法,本文所提方法的漏报率最低,为20.8%。
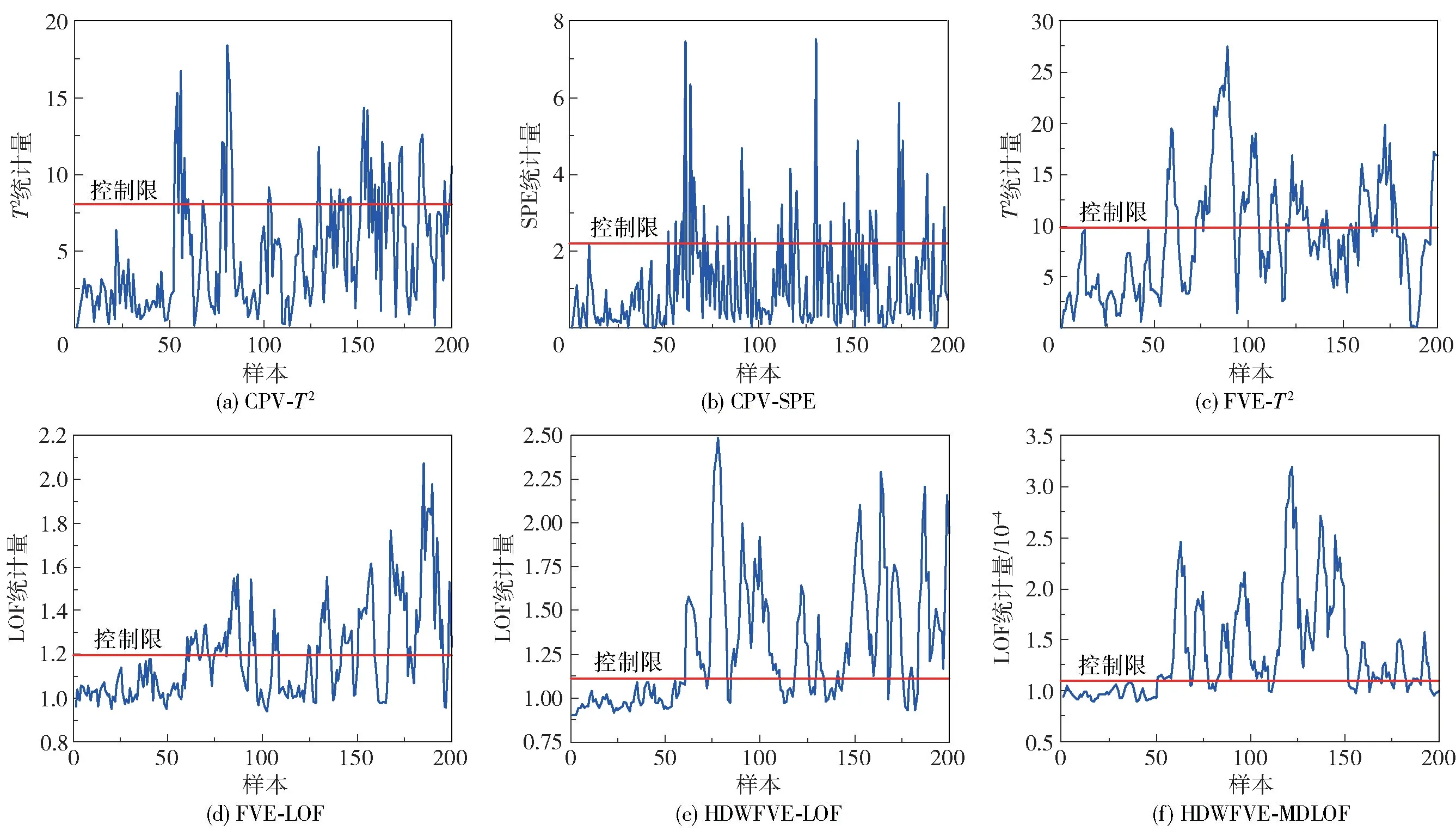
图2 数值实例中故障1的检测结果Fig.2 Detection results of fault 1 in a numerical example

表1 各变量所对应关键主元Table 1 Variables and corresponding key PCs
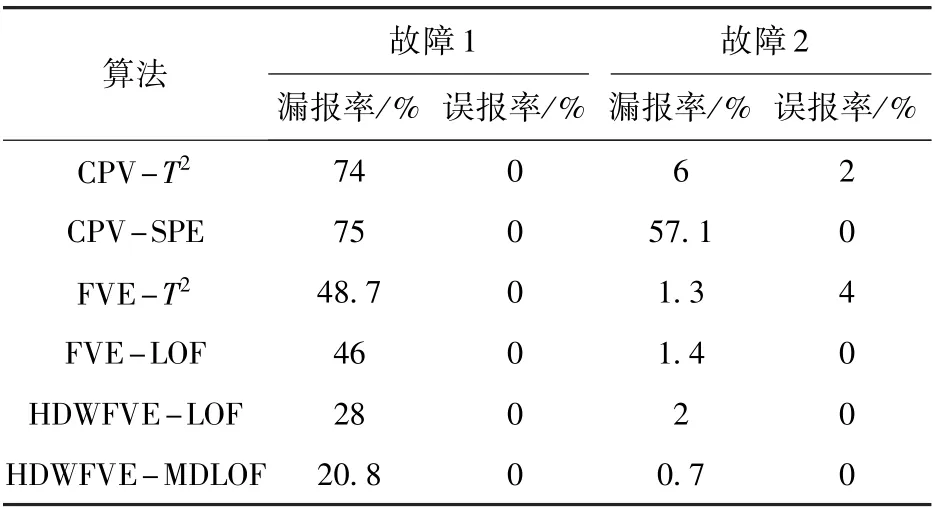
表2 数值实例故障检测结果Table 2 Fault detection results for numerical cases
图3给出了不同方法对故障2的检测结果。结合表2的结果,总体上,除了传统PCA利用CPV的主元选取法将SPE作为统计量的漏报率较高外,其余方法均能够保持较低的故障漏报率。其中,本文所提方法最早检测到故障的发生,并且在检测到故障发生后依然保持着很好的稳定性,统计量曲线始终位于控制限上方,而其他方法在检测到故障发生后,统计量曲线有回落到控制限的现象(图3(a)、(b)、(c)、(d)),引起漏报。
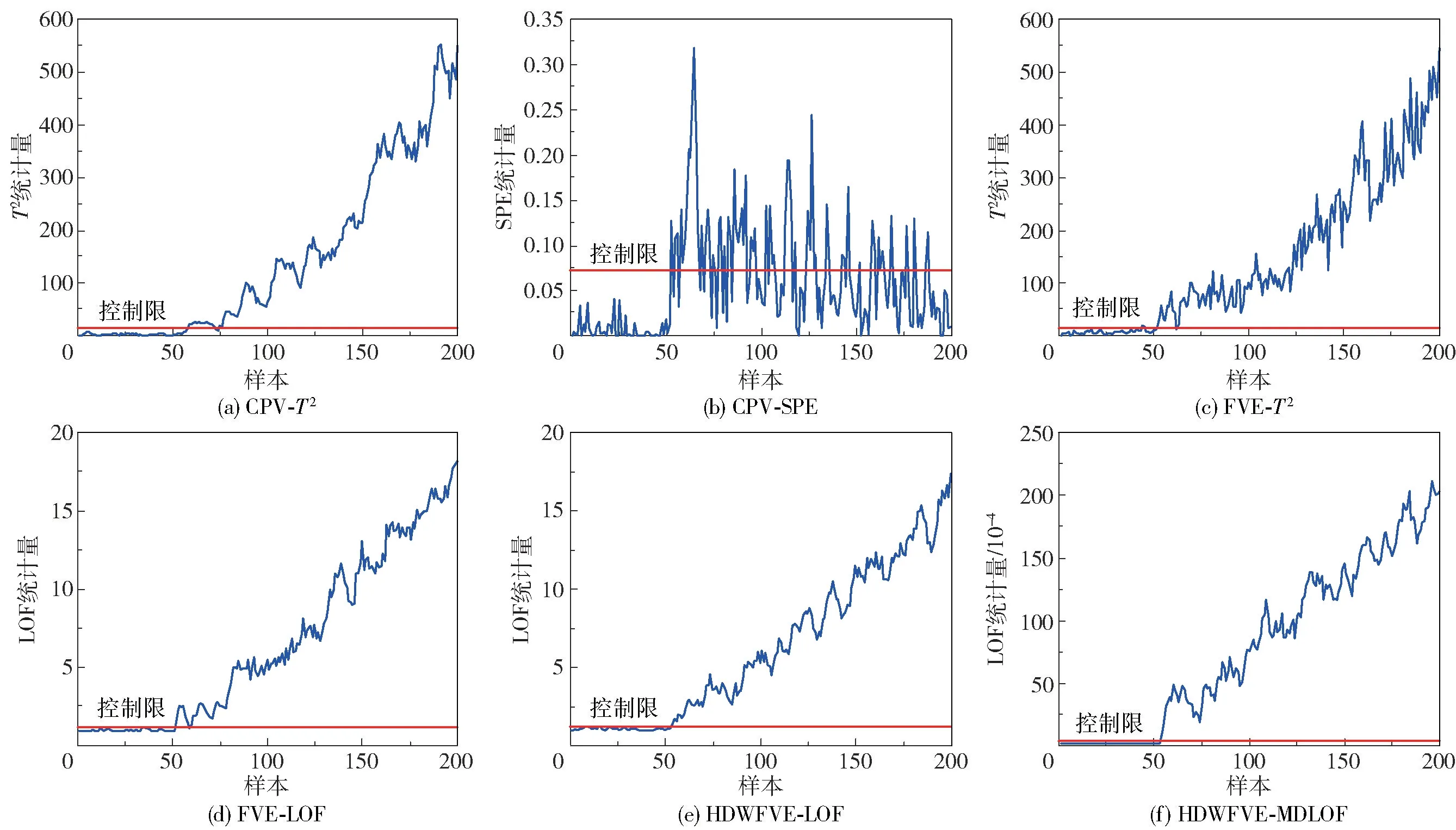
图3 数值实例中故障2的检测结果Fig.3 Detection results of fault 2 in a numerical example
为了进一步体现LOF作为统计量的优越性,图4(a)、(b)给出了故障2中运用本文方法加权后关键主元PC3和PC5的正态概率分布,其中横坐标为主成分样本点数据,纵坐标为先验概率。数据的分布越接近标准正态分布,相应图上散点的分布就越近似直线。由图4可知,图中条形点的头部和尾部较直线还是有着较大的偏移,意味着这两个加权后的主元并不服从正态分布,这也从另一个角度说明了利用LOF构建统计量的必要性。综上,数值仿真结果体现了本文所提方法的有效性与优越性。
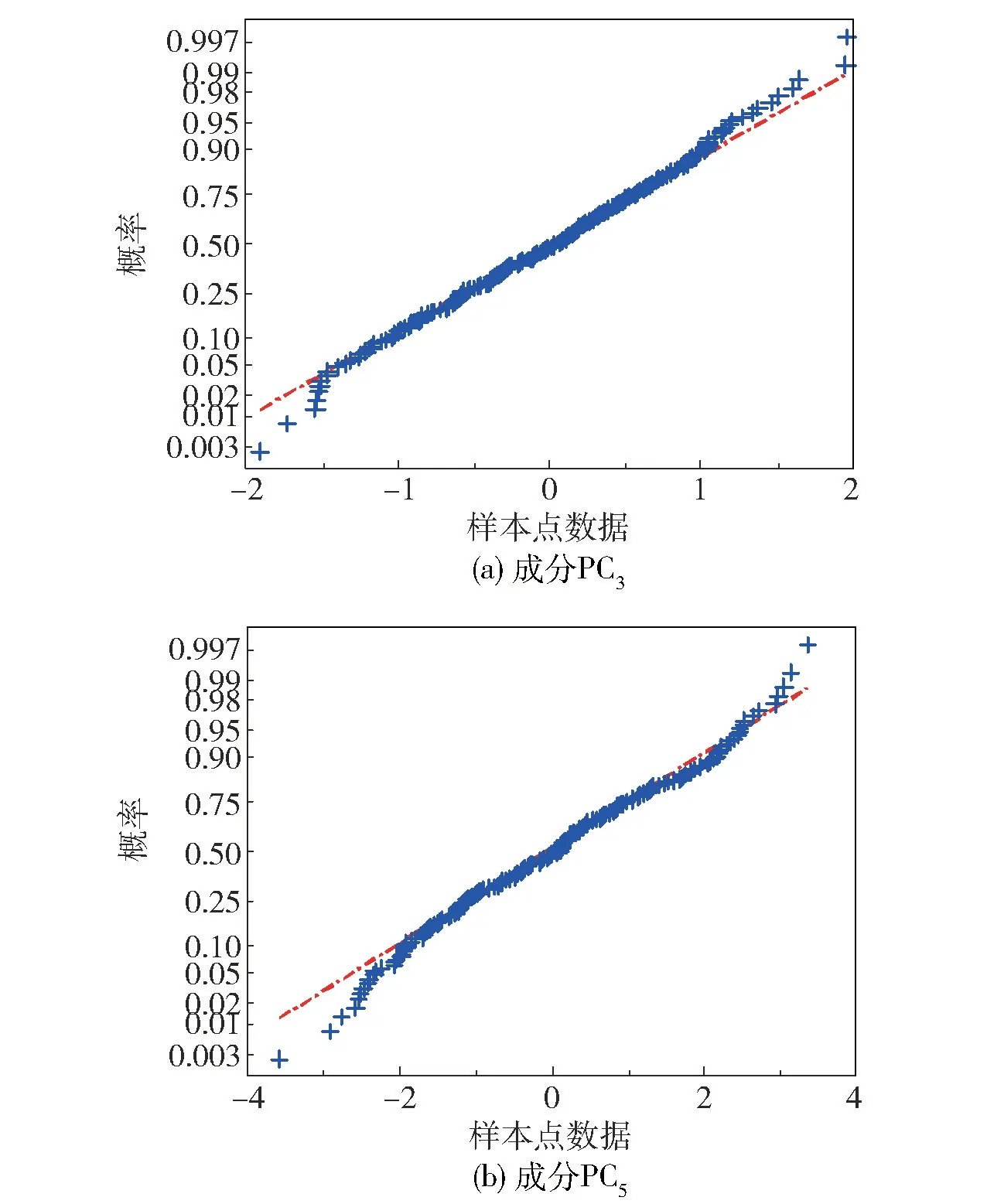
图4 成分正态概率分布Fig.4 Normal probability distribution of components
4.2 带钢热连轧过程验证
带钢热连轧过程(hot strip mill process,HSMP)是工业生产中的一个重要工序,其生产流程如图5所示。由于HSMP在运行过程中有高温度、高速度、多阶段的特征,导致其变量具有高耦合的特点。对此,本文将该过程用于故障检测的研究。在带钢热连轧现场(鞍钢集团1 700 mm带钢热连轧生产线)收集能够反映生产过程的数据,相关的20个过程变量的具体描述如表3所示。

表3 精轧过程变量Table 3 Process variables in the finishing mill
图5 带钢热连轧生产流程图Fig.5 HSMP flow chart
首先选取4 000个正常工况下带钢热连轧过程样本数据进行离线建模,再收集4 000个带有故障的样本数据进行在线检测,其中故障产生时间为样本点2 001到3 000,故障原因为第5机架的弯辊力测量传感器故障。LOF算法中近邻数k设置为150。利用KDE进行控制限计算时,核宽θ设置为500m(m为变量数)。利用FVE得到的关键主元与变量的对应关系如表4所示。各方法对于该故障的检测结果如图6所示,具体结果列于表5。图6(a)、(b)为PCA利用传统CPV方法对于该故障的检测结果,T2和SPE统计量的漏报率分别为74.2%和90.2%,数值都较高,尤其是SPE统计量,基本无法检测到故障的发生。图6(c)为FVE方法选取关键主元后构建T2统计量的故障检测结果,关键主元的选取使得故障漏报率大大降低,且故障误报率没有出现较大的增加。对比图6(d)、(e)、(f)可以得出,本文所提方法在检测出所有故障的同时,还获得了最低的故障误报率。
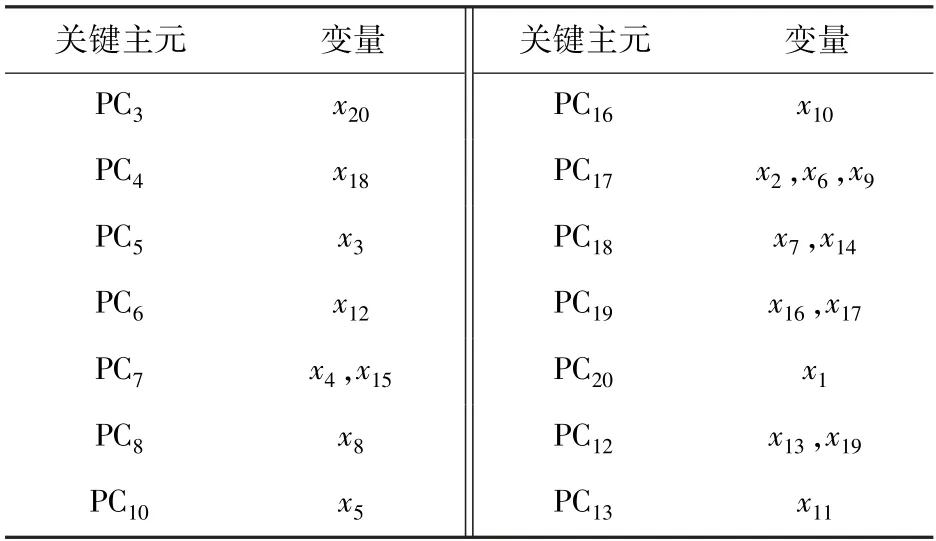
表4 各变量所对应关键主元Table 4 Variables and corresponding key PCs
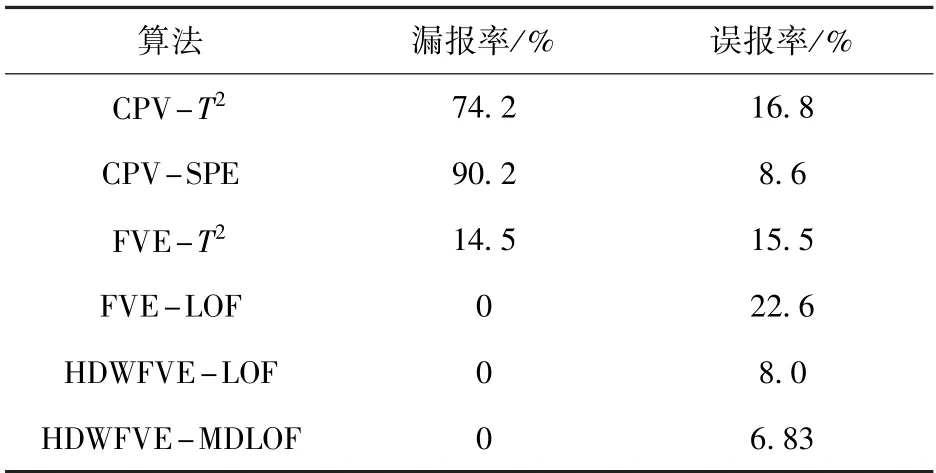
表5 不同方法的故障检测结果Table 5 Fault detection results of different methods
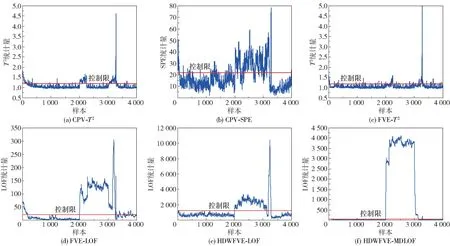
图6 故障工况下各个方法的检测结果Fig.6 Detection results for each method under fault operation
表6给出了ReliefF-PCA算法[11]、敏感主成分分析(SPCA)算法[12]、故障相关-贝叶斯推断主成分分析(FBPCA)算法[31]以及敏感主元多块主成分分析(MBSPCA)算法[32]对于第5机架的弯辊力测量传感器故障的检测漏报率和误报率。其中MBSPCA算法中ω取值0.2,即敏感主元阈值εlimit为0.003 9,所有方法的置信度均为95%。由表6的数据对比可发现,本文所提方法的漏报率与误报率均为最低。综上可说明本文所提HDWFVE-MDLOF算法的有效性与优越性。
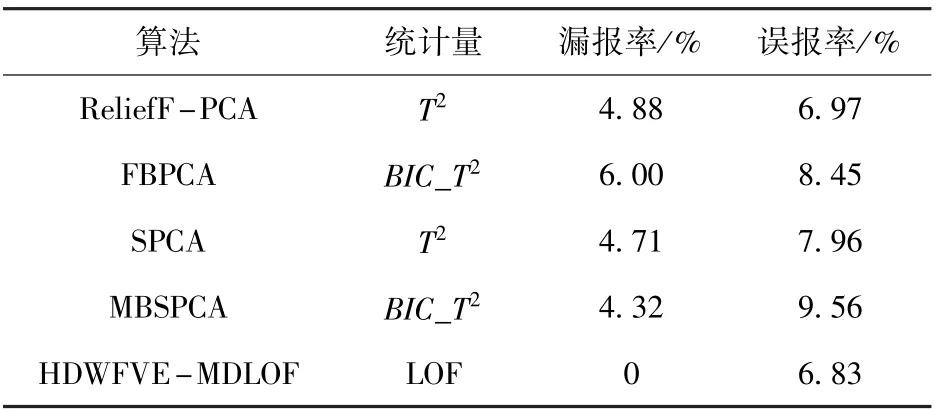
表6 几种现有主元选取方法性能比较Table 6 Performance comparison of some states of principal component selection monitoring methods
5 结论
本文提出一种基于HDWFVE-MDLOF的故障检测算法,在PCA框架下的主元选取阶段利用FVE方法获取关键主元,保留了全部变量信息,并利用海林格距离变化率对关键主元中的故障相关主元进行加权突出,有效地降低了故障漏报率;利用改进的LOF构造统计量,突破了传统统计量对于数据分布的限定。数值实例及带钢热连轧实际生产数据结果表明,与ReliefF-PCA、SPCA、FBPCA以及MBSPCA等算法相比,本文所提算法的漏报率及误报率均为最低,证明了所提方法的有效性与优越性。
