端到端的基于深度学习的网络入侵检测方法*
2022-07-12王金华
王金华
(四川大学,四川 成都 610207)
0 引言
基于网络的入侵检测的目标是识别那些企图通过网络跨越被保护系统安全边界的行为,任何损害系统安全性的网络入侵行为都应被识别,从而让系统快速做出响应。异常入侵检测对于网络安全有着重要的意义,通过对正常用户行为的建模它可以识别出异常的流量,从而检测新型的攻击。在检测过程中,研究者面对的是网络上捕获的网络流量数据,对于这些数据,其中一种处理方法是根据专家知识和统计学提取人工特征,形成特征集,然后基于人工特征数据执行入侵检测,识别某条记录是异常流量还是正常流量。
KDDCup-99数据集[1]是1999 KDD杯挑战赛提出的入侵检测数据集,该数据集对网络流量进行预处理,提取了基本特征、内容特征、基于主机的流量特征、基于时间的流量特征4大类人工特征,共计41个小特征,含有4种攻击类型,总计包含400万条记录,保存为txt文件。然而,使用KDDCup-99数据集来验证检测方法存在着诸多的不足,如存在攻击类型定义模糊、冗余的记录过多等问题。针对KDDCup-99数据集的缺点,Tavallaee等人[2]在该数据集的基础上,删除了冗余项,规划了训练集和测试集的比例,提出了NSL-KDD数据集,此数据集对于41维特征没有做出改变,主要优点是类别分配平衡,是用于入侵检测方法比较的基准数据集。
上述两种数据集并没有提供网络流量数据文件,而在2015年公开的UNSW-NB15[3]和2018年公开的CICIDS-2018[4]数据集则提供了网络流量数据pcap文件和已经预处理提取好特征的csv文件。Moustafa等人[5]对UNSW-NB15数据集做了评估分析,认为其包含新型的攻击方式,更具复杂性,可以取代KDDCup-99数据集成为新的基准数据集。上述3种数据集(KDDCup-99和NSL-KDD算一种)人工提取的特征有着高度的相似性,均包含数据流的持续时间、目的端口、协议、数据包发送速率、传输控制协议(Transmission Control Protocol,TCP)数据流中设置为PSH和URG的次数、数据包大小,以及一些其他的流统计特征,如流数据包数目、到达时间偏差、其他基于时间的(如最近100个连接中具有相同源地址的个数)统计特征。不同的是,不同的数据集中有一些独特设计的人工特征。值得注意的是,这些特征往往需要整体的流量情况做支撑,才能计算出统计学特征。
对于深度学习方法,如卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)等,其强大的地方在于可从复杂的原始数据如图像、文本等数据中自动提取特征,并用这些人类无法确切解释,但是十分有效的特征进行一些人工智能(Artificial Intelligence,AI)任务,如对象检测或者语音识别、机器翻译[6]等。将人工特征送入CNN或RNN中进行分类,只是将其作为一个强大的分类器,没有利用到深度学习方法强大的表示学习能力。尽管目前研究者所提出的方法在入侵检测分类上得到了良好的效果,但是面对各种新型的攻击类型,人工提取的特征是否还能胜任检测工作还存在疑问,以及对检测方法的实时性要求,也需要检测方法可以快速获取依赖的特征,而不是在整个流量都得到之后再进行计算,因此研究者开始探索直接监测网络流量的方法。
1 相关工作
随着深度学习的兴起,使用深度学习方法替代传统机器学习算法开展入侵检测的趋势逐渐形成,但也正如引言中的描述,这些方法很多是基于已有的人工特征的分类算法,很少直接针对网络流量数据进行设计,或者忽视了网络流量数据某一方面的特征。本节将简要介绍其他研究者在入侵检测领域所做的工作。
Hu等人[7]研究了传统支持向量机(Support Vector Machine,SVM)、鲁棒SVM、K最近邻(K-Nearest Neighbor,KNN)在KDD-99数据集上的性能表现,实验表明使用鲁棒SVM在准确率和误报率上表现更好。Dong等人[8]则对SVM、决策树C4.5、贝叶斯(Naive Bayes)和使用了玻尔兹曼 机(Restred Bolzman Machine,RBM)的SVMRBM进行了比较,实验表明结合了RBM技术的SVM在KDD-99数据集中具有最好的性能。Ravi等人[9]则综合评估了卷积神经网络CNN和循环神经网络RNN,包括长短期记忆网络(Long Short Term Memory,LSTM)、门控循环单元(gate recurrent unit,GRU),以及结合使用CNN和RNN的深度神经网络。他们将这些在KDD-99上表现良好的深度神经网络(Deep Neural Network,DNN)模型应用于其他数据集,例如NSL-KDD、UNSW-NB15、Kyoto、WSN-DS和CICIDS-2017,并对其进行了全面而完整的分析。实验结果表明,使用深度学习作为分类器学习人工特征所含信息做出决策的能力要比传统机器学习更好。此外,Xu等人[10]详细对比了采用LSTM和GRU[11]的循环神经网络在入侵检测数据集NSL-KDD和KDD 99上的性能表现,实验表明采用双向GRU能够达到更好的性能,当然这只是在特定领域里,比如Chung等人[12]的研究表明了在复调音乐建模和语言信号建模两种任务上,这两种网络性能相当。
虽然深度学习方法在人工特征集上的任务中表现出优越的性能,但是不能忽略其更强大的能力,即从原始低级数据习得高级抽象(自动特征)即表示学习的能力。Wang等人[13]将网络流量数据表示成1 000长的一维序列,采用堆叠的自动编码器(Stacked Auto Encoder,SAE)做网络协议识别,取得了良好的效果。Wang等人[14]第一次尝试将网络流量转化为图像,使用卷积神经网络进行恶意软件流量分类,在他们自建的数据集USTC-TFC2016上,取得了平均准确率99.41%的好成绩。他们还对如何表示网络流量取得最佳性能做了对比实验,实验结果表明,采取会话即双向流和所有数据包层的流量表示类型会取得最好的结果。此外,他们还使用一维卷积神经网络来鉴别加密流量和未加密流量[15]。也有研究者采用网络流量数据做入侵检测的流量识别,Peng等人[16]将网络流量作为图像,送入卷积神经网络中检测该流量是否是安卓恶意软件流量。此外,基于循环神经网络,Radford等人[17]将流量数据视为机器之间对话的语言,使用LSTM进行序列建模,并提出了一个简单的基于频率的模型,采用受试者工作特性曲线(Reciver Operating Characteristic,ROC)下面积(Area Under Curve,AUC)为评估指标,实验在IDS-2017上进行,取得了不错的效果。
本文从网络流量中提取会话样本后,首先将会话中数据包含有的字节作为一个一维长序列送入门控循环单元GRU中,类似于自然语言处理中一句话中的一个个单词,利用RNN提取数据包的时序相关特征;其次整个流中各个数据包被合并为一个固定尺寸的二维图像,被送入一个卷积神经网络提取空间特征;最后结合这两种特征做入侵检测。相比于先经过卷积然后经过RNN处理的线性方法,这种方法是双线并行的。先提取空间特征可能由于卷积层和池化层的存在送入RNN后会损失一部分信息,本文方法则避免了这种可能性,并且关注整个流的空间特征。本文算法直接从原始字节流量学习深层抽象特征,完成入侵检测任务,是一种端对端的入侵检测算法,一端是数据,一端是任务,无需人工特征提取,并且具有实时检测的优点。
2 算 法
本文提出的算法的重点在于处理网络流量数据生成可用于深度学习的流量样本,以及构建神经网络模型,从这些流量样本中提取出良好的特征用于检测流量是正常流量还是异常流量,整体流程如图1所示,最后得到一个可用于入侵检测的模型。图1还显示了本文算法的一个重要优点是无需人工设计特征,无需专家知识,由模型自动提取特征。
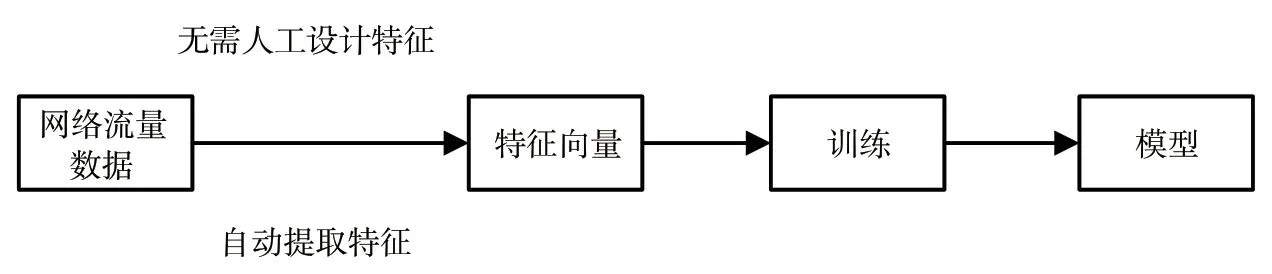
图1 算法流程
2.1 流量分割
在计算机网络中,定义5元组(源IP,目的IP,源端口,目的端口,协议)相同的一系列数据包同属于一个流,源IP和目的IP相反,源端口和目的端口相反,协议相同的另一个流是它的反向流,前向流和反向流就构成了一个双向流即会话,以下统称会话。在这样的定义下,网络数据基本上分为TCP会话和用户数据报协议(User Datagram Protocol,UDP)会话两大类,当然,根据应用层协议的不同在这两类上会衍生出很多小类,如网络流中最多的超文本传输协议(Hyper Text Transfer Protocol,HTTP)会话。对于TCP会话,第1个SYN报文标志着会话开始,而FIN包之后的ACK包表示会话的结束。对于UDP会话,定义在最初始的数据包之后600 s(已经能够包含绝大多数的数据包)内的会话是同一个会话,超时过后即使5元组相同也将其划分为一个新会话,同样对于TCP会话也有超时的设定。流量分割的流程如图2所示。

图2 流量分割流程
值得注意的是,在收到TCP-FIN数据包之后,根据TCP4次握手的规则,还需要再收到一个ACK包才算是结束了整个TCP会话,5元数组只会记录该会话第1个数据包的接收时间,用于判断与该5元组相同的数据包加入该会话时是否超时。
2.2 模型构建和特征提取
在流量分割后,获得了以张量形式存储的会话样本x,x是一个二维张量n×m,其中n表示该会话中数据包的个数,m是最大字节数,因此x是一个n行m列的矩阵。对于字节数超出m的数据包只能截取m个字节,少于m则空缺处填0。如图3所示,对于每个会话样本张量n×m,按顺序取出n个m长的一维序列送入GRU中,GRU将在这n个序列中共享权重、记忆相关信息,不需要理会这个n长序列的具体位置情况,最后在经过n个时间步后得到一个1×f的向量。将会话样本n×m组成一个固定大小为w×w的二维矩阵,类似于只有一个颜色通道的灰度图像,如果n×m大于w×w,则丢弃样本x的多余数据,小于w×w则在剩余位置填0,将其送入卷积神经网络CNN中,最后也会得到一个1×f的向量。最后将这两个特征向量在第一维拼接起来,得到一个1×2f的特征向量,至此,完成了特征提取。
图3上半部分所示的CNN卷积网络中,依顺序分别是3×3的卷积层、2×2的池化层、3×3的卷积层、2×2的池化层、2×2的卷积层,最后是一个全连接层,共计3个卷积层,2个池化层,1个全连接层,最后输出1×128的向量。下半部分为一个循环神经网络的展开图,采用的是LSTM的一个较为轻量的网络变种——门控循环单元GRU。一个流的所有数据包按顺序依次作为1个m长向量送入GRU,采用最后输出的output作为特征向量,是1个1×128的向量。最后,将这两个向量连接,就得到1个1×256的总特征向量,就是全连接网络所期望的输入值。
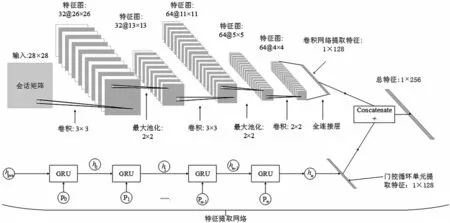
图3 会话样本特征提取流程
2.3 分 类
不同于人工设计特征,在执行任务前,提取的特征需要专家知识,而且后续使用传统机器学习也无法对该特征工程进行指导优化,这是因为没有明确的方法改进特征的优化提示,且如果模型效果不好,不能判断是特征不好还是模型不好;而本文算法模型所得到的特征向量和所执行的任务是一体的,提取的特征会在训练过程中通过优化算法不断改进,从输入网络流量数据到模型执行入侵检测任务的过程,整个模型是端到端的。
将前面特征提取网络输出的1×256向量作为输入,经过两层的全连接层,最后输出1×Categories(类别数)张量,使用Softmax函数概率化每个类别的置信度,取最高置信度所在下标的类别即为神经网络输出的类别。两个全连接层的网络结构为,1个(256,64)的全连接层和1个(64,2)的全连接层,最后使用softmax输出置信度。
3 实验证明
实验目的:对比本文提出的基于深度学习建立的端到端的入侵检测算法和基于人工规则特征的入侵检测算法的入侵检测性能,证明算法有效性。本文实验环境:Windows10-21H1,Python-3.8.10,Pytorch-1.9,scikit-learn-0.24.2,CPU i5-10400,GPU 1060。
3.1 处理数据
为了获得算法对当前网络流行攻击的检测效果,本文选择了CICIDS-2018数据集[5],该数据集是加拿大通信安全机构和网络安全研究所的合作项目成果,涵盖了如暴力攻击、Heartbleed漏洞攻击、DOS攻击、分布式拒绝服务(Distributed Denial of Service,DDoS)攻击、Web攻击(跨站脚本攻击)、结构化查询语言(Structure Query Language,SQL)注入、僵尸网络、渗透攻击共7种攻击场景。该数据集虽然不是真实场景的攻击流量数据集,但是该数据集通过机器学习技术统计分析正常用户的网络行为,从而模拟正常用户流量,使用上述攻击场景模拟异常流量,并使用配置文件的方式生成了一个较为全面、一定程度上真实可靠的异常检测流量数据集。
CICIDS-2018数据集针对捕获的原始流量,使用CICFlowMeter-V3的工具,从统计分析的角度,按照人类专家规定的特征提取了80维特征,本文算法需要与该人工特征做对比。本文选取了Wednesday-21-02-2018_Traffic和Friday-02-03-2018_Trafficr两天的网络流量数据,其包含正常流量和Bot、DDoS-LOIC-UDP、DDoS-HOIC 3种攻击流量,其中LOIC(Low Orbit Ion Cannon)是低轨道离子炮,对该网络流量进行流量分割,其异常流量分布如表1。
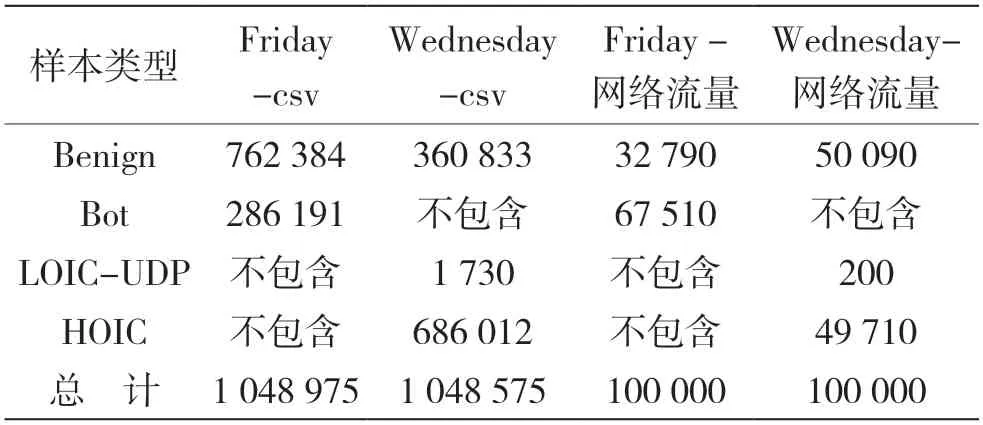
表1 CICIDS-2018人工提取特征和本文分割流量攻击类别分布
CICIDS-2018提供了基于主机的收集的众多流量pcap文件,对于这些文件,需要先筛选数据,选取攻击流量攻击目标主机的pcap文件分割得到攻击会话样本,并选取其他正常通信主机得到正常会话样本,提取数据后需要对样本进行标记,详情需要参考CICIDS-2018的具体实施攻击场景,按照攻击时间、端口、协议、IP等信息匹配样本,进行标签分配,该工作较为繁琐,需要格外仔细。
CICIDS-2018提供的已经提取好特征的数据集为csv文件,它的每一条记录就是一个会话(双向流),所有的特征是基于双向流的统计特征得出的,如流持续时间、正向包数、反向包数、正向字节数、反向字节数等,两天共计2 097 150条数据。本文基于2.1节所提出的流量分割算法切割网络流量,对于Friday-02-03-2018含有僵尸网络的流量进行分割,提取出双向流会话,共计100 000个会话,会话分布如表1第4列所示,对Wednesday-21-02-2018分割了共计100 000个会话,会话分布如表1列5所示。
提取的会话数据以张量的形式存储,一个会话最后的张量形式为n×256,n是数据包的个数,根据每个会话的情况动态变化,256个字节是每个数据包最大接受的字节数,在对网络流量数据进行处理的时候,发现数据包的平均字节数为213(Bot)、74(DDoS -LOIC-UDP)、179(DDoS -HOIC),最后选取了256字节的数据长度存储数据包,超出256就截取前256个字节,少于256,空余位置填0。
图4是各种异常会话的可视化图像,其中每一张图片都是一个会话的整体图像,尺寸为28×28。

图4 异常会话可视化
对于数据包数n,实际网络中n可能极大,而在本文分割出的DDoS-LOIC-UDP异常会话中,按照既定规则该会话的数据包数高达十几万个,同时这也是DDoS-LOIC-UDP的特点,该攻击使用多台计算机针对目标服务器开放的端口,短时间内发送了大量伪造源IP地址的UDP数据包,消耗服务器的资源,网络充满无用数据,使其瘫痪,从而不能正常提供服务。通常来说UDP会话在正向流和反向流中数据包数相等,而在该攻击中只会在发送方一侧出现大量数据。当DDoS攻击者已经发送了大量数据包的时候,攻击的目的已经基本完成时,服务器根据网络状况和自己负载状态等条件,很容易就可以判断自己受到了DDoS攻击,然而此时检测到攻击已经过于迟钝了,因此对于DDoS攻击最好的检测状态是能够提前发现攻击。本文采用的最大数据包数为32,对于大于32的会话会只截取一部分,对于有大量数据包的会话,可以根据局部特征识别该类攻击,在攻击初见迹象的时候就可以识别它,并作出警示。如图4所示,LOIC-UDP攻击可视化完整图像基本就是下半部分的重复。
在实际训练中,数据包并没有出现由于冗余而造成计算资源浪费的现象,因为对于实际为空的数据包,其实并不参与实际计算,该种形式是为了样本统一格式,方便处理。
3.2 训 练
3.1 节中得到的会话总计100 000个,将其打乱,按照7∶3的比例,分出70 000个会话作为训练集,30 000个数据作为测试集。损失函数是交叉熵损失函数CrossEntropyLoss,用于衡量模型分布和经验分布之间的距离,距离越小,模型就越接近经验分布。优化算法是基于梯度下降的后向梯度传播算法Adam,训练集被循环使用10个epoch(时期),可以看到训练集在大概第8个epoch的时候就开始收敛。
学习率参数设置:在使用Adam优化算法时,本文算法设置初始的学习率为0.001,在训练中,开始时学习率可以设置得适当大些,以让模型更快地接近最优点,之后应该将学习率减少,以避免跳过最优点,因此本文使用余弦曲率衰减计划,它会按照余弦曲线,即初始缓慢减少学习率,之后快速减小学习率,余弦曲线的周期可以指定,本文指定其为10,与训练集的循环次数一致,最低学习率选择默认为0。
3.3 结果与分析
对于模型性能的指标,本文采用混淆矩阵的方式进行计算,表2为二分类混淆矩阵,可以基于将某一类视为正类,其他类视为负类的方式将混淆矩阵扩展到多分类。

表2 混淆矩阵
准确率acc:模型预测正确的数目占所有样本的比例,如式(1)所示。在各个类别平衡时,该指标能够表明模型性能,但是在极端类别情况,如正类10个、负类90个,模型只需要输出全负类,就可以达到90%的准确率,然而其对正类的预测能力为0。

精确率p:模型预测为类别C的样本中其实际类别为C的样本所占比例,如式(2)。
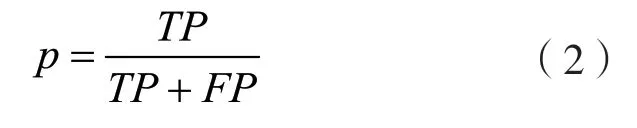
召回率r:实际类别为C的样本中模型预测为C的样本所占比例,如式(3)。在上面阐述的类别不平衡分类中,就可以计算出正类的召回率为0/10=0,由此可以判断模型的预测能力完全无效。

F1值F1-score:精度p和召回率r的调和平均值,如公式(4),它综合考虑了准确率和精确率的值,F1值越高,模型性能越好。
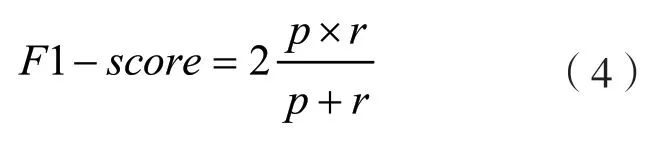
本文针对3.1节中所提取的网络会话做实验,具体是对Friday提取的100 000个会话的含有僵尸网络Bot的数据集进行实验,其结果如图5所示,其准确率为99.996 7%,精确率为100%,召回率为99.995 0%,F1值为99.997 5%。
对Wednesday提取了正常会话(Benign)和DDoS-LOIC-UDP、DDOS-HOIC两种攻击会话,总计100 000个会话。对这些会话进行实验,其结果如图5所示。实验对总体样本识别的准确率为99.99%,对正常流量的识别,以及对LOIC-UDP和对DDoS-HOIC的识别在各项指标上成绩也为99.99%,错误识别的样本数极少。在对LOIC-UDP的检测攻击中,即使由于最大数据包数的限制,导致算法无法取得该攻击高达十几万个的数据包,并整体作为数据输入神经网络中,但是对该攻击的局部特征识别非常成功。
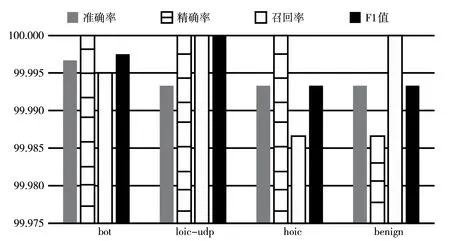
图5 异常流量实验结果
同时,本文也对CIC-IDS-2018提供的基于专家知识和统计学的人工特征数据集(只包含Friday-02-03-2018.csv和Wednesday-21-02-2018.csv这两个文件)在决策树、随机森林、AdaBoost集成学习、贝叶斯、SVM、KNN最近邻这6种传统机器学习中的表现进行了评估,其结果如表3所示。
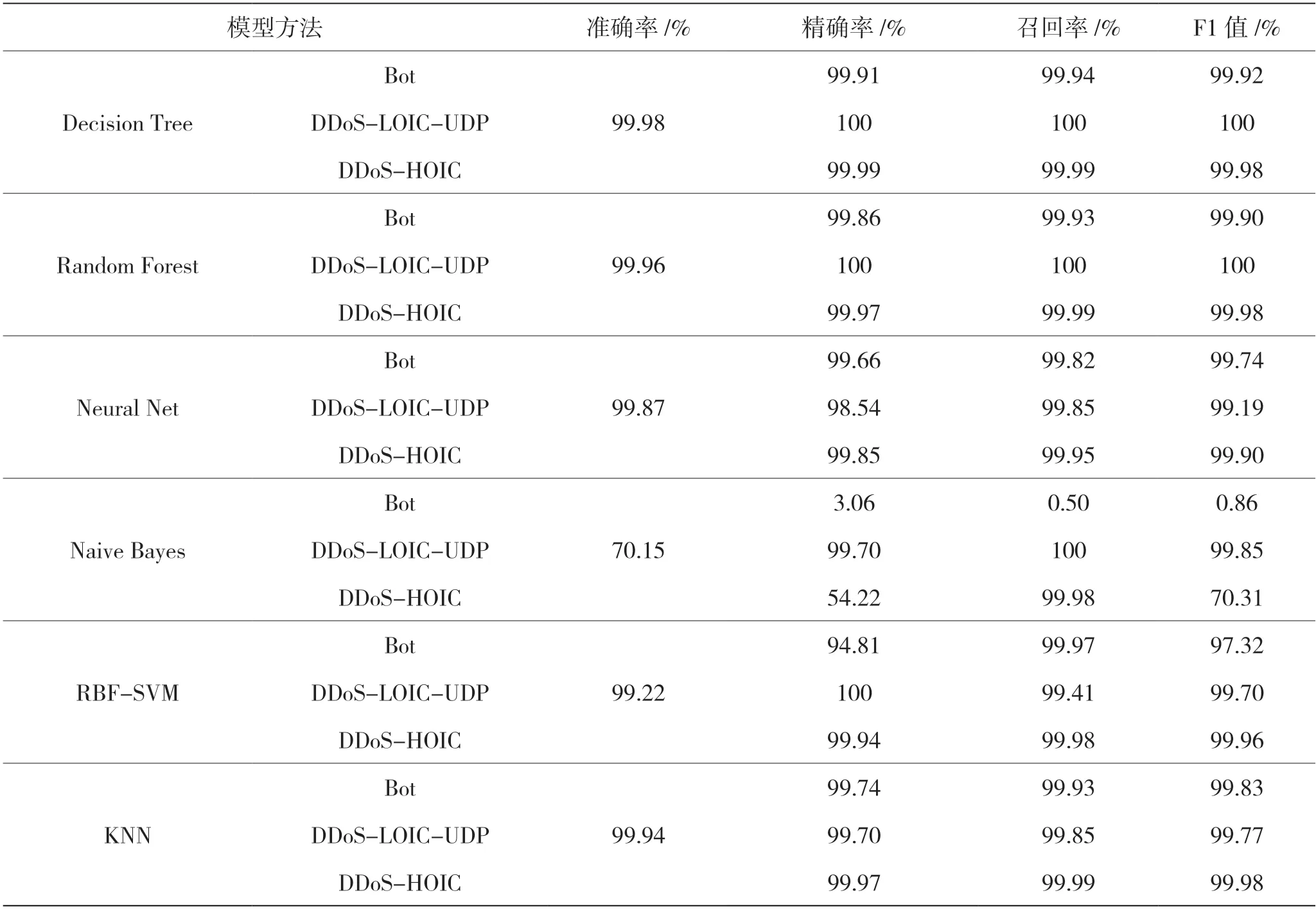
表3 CIC-IDS-2018人工特征数据集在传统机器学习上的表现
从表3结果分析,本文算法对Bot僵尸网络的准确率为99.99%,F1值为99.99%,对DDOS的两种攻击LOIC-UDP和HOIC的各项指标均高达99.99%。而人工特征数据集中对Bot的检测效果最好的是决策树算法,其准确率为99.98%,F1值为99.92%。对LOIC-UDP和HOIC的检测准确率最高的是决策树算法,分别为100%和99.99%。可以看到本文算法提取的特征检测攻击效果与人工特征持平,在Bot检测中略有优势。需要指出的是,这些指标较高的原因有可能是攻击类别较少,或者是该类攻击特征判定条件较为简单。
此外,本文在研究初期,采用提取单向流的流量分割方式,对Friday-02-03-2018-Trafficr提取的包含Bot僵尸网络的单向流样本数据进行实验。该方法对Bot的准确率为99.98%,F1值为99.98%,性能表现不如会话,最后调整策略,采取了提取会话的样本分割方式。
4 结语
传统的机器学习入侵检测算法多依赖于人工设计特征,本文提出基于深度学习的异常入侵检测算法,采用端到端的架构,自动学习会话中潜在的高级抽象特征,无需人工设计特征,并且由于样本可由流量数据实时构造,具有实时检测的优点。实验证明本文算法是有效的,并且效果好于人工设计的特征。此外,本文还详细研究了网络流量切割的方法,遵循一般会话的定义来提取双向流,并给出了详细的会话分割流程。
本文方法还存在一些可改进之处,比如本文将算法提取的网络流量表示为单纯的数字向量,然而从可视化图像中可以看到,每一种攻击都有较为明显的图形特征,如果攻击者将自己的攻击流量的数据包大小重新设计,添加一些无用数据,打乱其原本的图形特征,那么基于将网络流量视为图像的检测算法是否还可以达到检测的目的还需要验证。此外,未将CICIDS-2018数据集的所有攻击类型囊括,需要做更多工作。未来可以研究结合人工规则和深度学习的入侵检测算法,这样可以弥补两者的缺点,取得更高的准确率,降低误报率。此外,近几年,图神经网络开始兴起,采用图的结构来表示数据可以承载更加复杂的数据形式,如将主机和会话表示为结点,而边是流与主机之间的联系[18],这也是异常入侵检测研究的另一个方向。
