基于密码芯片的DDR加速器的设计与实现*
2022-07-12姜冬梅何欣霖
姜冬梅,何欣霖,李 军
(成都三零嘉微电子有限公司,四川 成都 610041)
0 引言
随着云计算、大数据、5G以及高清视频业务等领域网络信息技术的快速发展,通信设备对密码处理单元的加解密性能提出了更高的要求。为了满足网络汇聚层、核心服务器对海量密码业务处理能力的需求,需要研究具有高性能的密码芯片。
在基于对称算法的密码业务中,需要解决密钥和IV的管理(初始化、存储、访问、更新与注销)。密码服务涉及的密钥来源有以下两种:一是一包一密,随包下发,不需要维护;二是密钥需要由主机下发到加解密芯片并保存在加解密芯片内部,初始化完成后,由主机和加解密芯片共同完成密钥的维护。本文主要研究第二种。密码服务涉及的IV来源也有两种:一是一包一初始向量(Intial Vector,IV),随包下发,故无须考虑IV维护;二是对较大数据进行级联加解密处理,此时的IV生命周期为这个级联处理数据的整个处理周期,对于上层应用软件则是维护一个加密隧道的线程周期。本文主要研究第二种。IV的初始化、更新和销毁,需要加解密芯片协同主机下发的初始化包(initial package)、更新包(update package)和结束包(final package)共同实现,如图1所示。

图1 级联加解密过程
一个级联加解密过程可分为初始阶段、更新阶段和结束阶段3个阶段,更新阶段可以处理多个数据包。包序号和IV一对一绑定,密钥索引和密钥一对一绑定,下文将整个级联加密过程中的数据包统称为级联包。
初始阶段:首先主机创建一个加密隧道线程,完成密钥初始化,实现密钥和密钥索引的绑定,将包序号、IV、密钥索引及数据下发到密码芯片;其次密码芯片根据密钥索引查找密钥,并将密钥、IV和数据送入加解密模块进行运算;最后运算结果返回主机,并将运算结果的最后一个级联分组写入IV存储空间,完成IV的更新。
更新阶段:首先主机下发包序号、密钥索引和数据;其次密码芯片根据包序号和密钥索引从本地缓存获取IV和密钥,连同数据送入加解密模块进行运算;最后运算结果包返回主机,并将运算结果的最后一个级联分组写入IV存储空间,完成IV的更新。
结束阶段:首先主机下发包序号、密钥索引和数据;其次密码芯片根据包序号和密钥索引从本地缓存获取IV和密钥,连同数据送入加解密模块进行运算,运算结果包返回主机;最后主机释放包序号,加密隧道现场注销。
可见,在加解密过程中需要解决密钥和IV的存储和访问。在安全服务器应用领域,加解密业务通常需要支持百万级用户,密钥和IV的存储需求高达几百兆字节,片上静态随机存取存储器(Static Random Access Memory,SRAM)已不能满足应用的需求。DDR较SRAM具有容量大、成本低等特点[1],因此DDR取代片上SRAM成为密钥和IV的存储器。通常,一个密钥或一个IV只有几十个字节,当多用户多线程加解密业务同时进行时,需要维护很多密钥和IV,就会对DDR产生大量的离散数据读写访问。而芯动的DDR控制器和镁光的DDR颗粒、Cadence的DDR控制器和镁光的DDR颗粒的访问延迟均在几十个周期,这是由于对于DDR的离散数据访问的延迟较大,因此存在访问性能低的问题。
针对DDR访问的延迟较大的问题,本文提出预读机制,提前发起读操作,读回的数据缓存到高速缓冲存储器(cache)中,当加解密模块发起读写IV和密钥操作时,可直接从cache中读写数据,访问延迟小。当多包级联时,IV和密钥数据具有时间局部性[2],而当包序号连续时,IV数据具有空间局部性[2],因此在加解密模块与DDR之间引入一级cache,cache命中率较高,从而减少了DDR的访问次数。
1 DDR硬件加速器
在密码芯片中,高速加解密业务由高速接口、直接存储器访问(Direct Memory Access,DMA)、数据整形和加解密模块共同完成,如图2所示。高速接口是主机和密码芯片的通信接口;DMA模块将下行包从高速接口搬往加解密模块,将上行包从加解密模块搬往高速接口;数据整形模块将下行包数据进行整形并分发到加解密阵列中的各个加解密单元,当完成加解密后,将数据汇聚整理后组成上行包,送入DMA模块。加解密模块通常由多个加解密单元组成,完成加解密业务。

图2 DDR硬件加速器在密码芯片中的位置
如图2所示,DDR硬件加速器包含预读检测和cache加速模块。预读检测模块用于检测来自主机的高速接口的输入数据,当检测到初始包的密钥索引时,向DDR发起读密钥请求,cache加速模块在收到读请求后,从DDR中读取密钥,并将其存储在cache中。当数据流经过DMA和数据整形模块后,到达加解密模块,加解密模块根据包序号和密钥索引向DDR发起访问读写密钥和IV请求,此时密钥和IV已经存在cache中,可以较快地完成密钥和IV的读写操作。
1.1 预读检测模块设计与实现
密码业务通常采用包传输模式,密钥索引字段位于包头信息中。预读检测模块根据包格式,找出初始包的密钥索引字段,根据密钥的索引规则,计算密钥在DDR中的存储地址,发起一笔长度为1、首地址为该DDR地址的读操作。cache加速模块在收到来自预读模块的读请求后,向DDR模块发起读请求,并读回一笔长度为缓存行(cache line)大小的数据包存放到cache中,以便后续的加解密模块可以从cache中读取密钥。
1.2 cache加速模块设计与实现
常见的cache组织方式包含全关联、直接映射和路组关联[3-5]。为了提高cache的命中率,本设计采用全关联方式。加速器的设计如图3所示,下面分别就各个子功能进行详细描述。
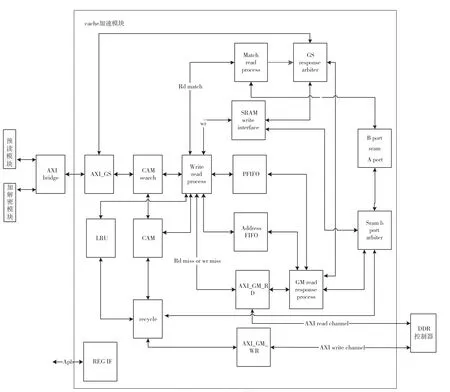
图3 cache加速模块
AXI_GS模块将AXI总线接口转化成内部自定义总线接口,并将读写命令、地址和数据送往内容可寻址存储器(Content Addressable Memory,CAM)search。该模块内设有深度为8的输入缓存和输出缓存,用于消除瞬时带宽不匹配对系统性能造成的影响。
CAM search模块用于检测地址是否命中,它将burst首地址送给CAM模块,从CAM模块获取命中信息,同时将读写命令、地址和数据送往Write and read process模块。
Address FIFO用于存放未完成的且需要从DDR颗粒读取数据的读写操作的burst首地址和burst ID。在Write and read process模块中,对于地址未命中读操作和地址未命中且需要从DDR读数据回填cache line 的写操作,burst首地址和burst ID写入Address FIFO;在Write and read process模块中,命中的写操作需要检查地址是否与Address FIFO中的地址相同,若相同,则当前操作与之前操作可能存在数据相关性[4],需要等到之前操作完成后,才开始当前操作。在Write and read process模块中,地址命中的读操作,需要检查当前读地址是否与Address FIFO中的地址相同,若相同,则当前操作与之前操作可能存在数据相关性,需要等到之前操作完成后才开始当前读操作,此外还需要检查当前读ID是否跟Address FIFO的读ID相同。根据AXI总线相同ID顺序执行的要求,则应该等到该ID的之前操作完成后,才开始当前读操作。
Write and read process模块根据地址是否命中,对读写burst进行分别处理。
为了减少对DDR的访问,读操作采用lookthrough机制[3,4,6]。对于地址命中的读burst,读命令和地址被送往Match read process模块处理;对于地址未命中的读burst,向AXI_GM_RD模块发起AXI读请求,将该笔读响应的参数写入PFIFO,同时将首地址写入Address FIFO。
为了尽快向加解密模块返回写响应信号,写操作采用write-back机制[3,4,6]。对于地址命中的写burst,写地址、写数据、写命令送往SRAM write interface模块处理;对于地址未命中的写Burst,写地址、写数据、写命令送往SRAM write interface模块,若burst长度小于cache line大小,为了保持cache数据和DDR数据一致,则需要从DDR读数据回填当前cache line,因此会向AXI_GM_RD模块发起AXI读请求,将该笔读响应的参数写入PFIFO,同时将首地址写入Address FIFO。每次操作,会更新CAM和LRU。
SRAM write interface用于处理写burst,它先将写数据写入SRAM,然后将response写回AXI_GS响应通道。
GM read response process模块根据PFIFO中的参数,处理从AXI_GM_RD模块读回的DDR数据。若是地址未命中写,则将从DDR读回的数据写入SRAM中;若是地址未命中读,则将从DDR读回的数据写入AXI_GS响应通道,同时将数据写入SRAM。
数据回收模块采用最近最少使用(Least Recently Used,LRU)替换算法[7-9]实现对cache line的更新。为了避免cache满时,没有可用的cache空间,导致流水线被阻塞,本设计在cache将满未满时,把最久没有访问过的cache line状态清零,更新LRU矩阵和CAM状态,若该cache line 中的数据比DDR中的数据新,则读出cache line的数据并写入DDR中。当接收到Flush命令时,将整个CAM的状态复位,当cache line的数据比DDR数据新时,则读出cache line的数据并写入DDR中 。
CAM[10]模块用于查询地址是否命中。当地址命中时,命中标志生效并返回当前地址所在的cache地址;若地址未命中且cache不满时,命中标志无效并返回可用的cache地址;若地址未命中且cache已满时,命中标志无效并返回没有可用cache地址的标志。
LRU用于查找最久未被使用的cache line。本设计使用LRU矩阵算法[11]。
AXI_GM_RD用于将内部的读请求总线转换成AXI读地址、读数据通道信号。
AXI_GM_WR用于将内部的写请求总线转换成AXI写地址、写数据以及写响应通道信号。
REG_IF模块为寄存器模块,用于CPU配置模块寄存器、读取模块状态和调试信息。
1.3 cache加速模块设计特点
为了提高性能,采用全流水线设计[10,12]。写操作处理过程包含4级流水:第1级,AXI_GS将AXI总线转化为内部总线;第2级,cam search模块检查地址是否命中;第3级,SRAM write interface将数据写到SRAM并向GS response arbiter输出写响应;第4级,AXI_GS将内部写响应转换成AXI写响应。
地址命中的读操作的处理过程包含4级流水:第1级,AXI_GS将AXI总线转化为内部总线;第2级,cam search模块检查地址是否命中;第3级,match read process从SRAM读回数据,并将其送往GS response arbiter;第4级,AXI_GS将内部读响应转换成AXI读响应。
地址未命中的读操作的处理过程又分为请求过程和响应过程。请求过程包含4级流水:第1级,AXI_GS将AXI总线转化为内部总线;第2级,cam search模块检查地址是否命中;第3级,write read process通过AXI_GM_RD模块向DDR控制器发起读请求;第4级,AXI_GM_RD将内部的读请求转换成AXI读地址通道信号,送给DDR控制器。响应过程包含3级流水:第1级,AXI_GM_RD将来自DDR控制器的读数据通道信号转换成内部读响应信号;第2级,GM read response process将来自AXI_GM_RD模块的读数据写入SRAM,同时送往GS response arbiter;第3级,AXI_GS将内部读响应转换成AXI读响应。
采用FIFO设计,PFIFO将DDR读请求和读数据分开,可以支持Outstanding操作。Address FIFO用于存放未完成的且需要从DDR颗粒读取数据的burst的首地址和ID,用于解决数据的相关性和AXI总线要求相同ID顺序执行的问题。
为了简化设计,所有仲裁均采用固定优先级算法[11,13]。
数据回收与数据读写相互独立,并行完成。当正在被回收的对象又被重新访问时,完成回收后,cam的状态不被清除。
2 DDR硬件加速器性能分析
如图2所示,预读检测利用DMA和数据整形模块的延迟(通常几十个周期),提早发起对DDR的读操作,读回的数据存放于cache中,这样抵消了DDR访问延迟对加解密模块的影响。该模块易于实现且硬件开销不大。
当包序号连续时,由于IV数据的存储地址是由包序号索引,相邻的级联包的IV数据存储地址连续,因此IV数据具有空间局部性。当多包级联时,由于更新包和结束包与初始包有相同的IV地址和密钥地址,因此密钥和IV数据具有时间局部性。由于数据的时间局部性和空间局部性,cache加速器会有较高的命中率,使得大量密钥和IV的访问在cache中完成,从而有效减少DDR的访问次数。
本文用芯动的DDR控制器、镁光的DDR3仿真模型以及SYNOPSYS的VCS仿真工具,搭建了仿真环境。本文分别对不同个数的级联包,以及包序号是否连续进行有、无加速器的对比试验。IV长度为16字节,4个级联包包个数分别为1,2,3,4,包序号连续时,加解密模块读写IV和密钥所需时间如表1所示,单位为时钟周期;IV长度为16字节,4个级联包包个数分别为1,2,3,4,包序号不连续时,加解密模块读写IV和密钥所需时间如表2所示,单位为时钟周期。

表1 包序号连续的访问时间

表2 包序号不连续的访问时间
通过对比试验,由表1、表2可知:加速器对密钥和IV的访问性能有较大提高,当包序号连续时,加速器性能有80%以上的提升,当包序号不连续时,有50%以上的性能提升。
3 结语
本文设计并用Verilog硬件描述语言实现了一种预读与cache结合的DDR硬件加速器。通过对比试验说明,加速器较大程度上提高了DDR的访问性能,且适用于安全服务器领域的对称算法密码芯片的密钥和IV存储管理,有效地解决了片上SRAM存储容量不够,片外DDR访问效率低的问题。
