基于视频重建技术的视频会议图像传输方案*
2022-07-12庄祖江
沈 宜,庄祖江,石 珺,贾 宇
(深圳市网联安瑞网络科技有限公司,广东 深圳 518042)
0 引言
如今,视频会议的需求日益增加,对视频会议的传输安全技术[1]提出了挑战。在多人实时视频会议中,采用传统视频传输协议对网络带宽的需求较高。在实时视频传输场景中,为了减少传输数据的大小,都会首先对视频流进行编码,其次通过网络将视频流传输到接收端进行解码。目前常用的视频解码方案有H264协议[2],该协议可以压缩视频的大小,但是在压缩率和传输图像质量之间较难取得很好的平衡。
深度学习是最近几年学术和工业领域研究的热点,图像生成也是其中受人关注的一个研究方向。当前,已有不少对人像视频重建的研究,如NVIDIA公司在文献[3]中采用了将提取的人脸关键点输入生成网络来进行图像生成的方案,但该方案的生成效果受到关键点检测的影响,同时对于侧脸的效果较差;文献[4]基于3D模型的重建,通过3D信息来进行视频的生成,生成效果有所提高,但是由于受到3D模型生成的影响,因此生成速度较慢;文献[5]采用了自监督的2D关键点以及图像直接光流信息生成视频,生成效果可以较好地还原原始的动作,但是对细节如唇部、眼睛的还原效果较差。
本文设计了一种基于视频重建技术的单人像视频会议图像传输方案,将图像生成技术中的人脸视频重建技术引入到视频会议图像传输中。该方案先通过特征提取网络提取发送图像流中图像的低维特征向量,然后在接收端通过生成网络将低维特征向量重新还原为图片,最后将网络结构解耦分别部署在发送端和接收端。通过这样的方案,达到了在减少传输带宽的同时,减少图像质量的损失的目的。本文整体方案受到文献[5]的启发,将原始的二维特征点转换到三维空间上,并采用了更加先进的生成判别网络结构,从而取得了更好的图片生成效果,此外,还将输入编码和输出解码器网络相隔离,因此能够完成图像的远端传输工作。
1 图像编码传输方案
1.1 整体方案流程
视频图像传输方案整体思路如图1所示。

图1 视频图像传输整体方案
总体方案设计思路为,在发送端通过网络编码将图像流解码为低码率信息传输到接收端,然后再经过解码网络恢复成图像。具体的编码解码过程又分为参考帧传输方案和后续帧传输方案。本文将采用传输图像流的第一帧作为参考帧。
1.2 参考帧传输方案
参考帧传输方案主要是辅助网络生成,传输一些固定的特征信息,减少后续传输量,同时提高生成图片质量,参考帧传输方案具体如图2所示。

图2 参考帧传输方案
发送端各个网络的功能:特征向量提取网络通过人脸特征提取网络对图像进行压缩,提取原始的通用特征;头部信息提取网络通过头部信息,提取网络提取头部的姿态信息和表情特征;人脸特征提取网络提取参照人物身份特征。
参考帧特征信息由通用特征、参考帧头部信息特征和参照人物身份特征共同构成,用于后续帧传输方案中的图像重建网络。这些信息仅在选定参考帧时进行传输,减少了网络传输的数据量。参考帧传输时还没有开始图像重建,是一个系统状态初始操作。
1.3 后续帧传输方案
在进行了参考帧特征传输后,后续的帧采用另外的方案进行传输,同时开始进行图像的重建。

图3 关键帧传输方案
后续帧的图像在发送端需要经过头部信息网络提取姿态特征和表情特征,之后将处理的特征发送到接收端,接收端通过后续帧信息以及参考帧信息输入到生成网络中,就可以还原出发送端的原始图像帧。
2 神经网络结构
实现视频会议图像传输方案的神经网络包含人脸特征提取网络、头部信息提取网络、特征向量提取网络、密集运动场网络以及生成网络,其中生成网络的模型和密集运动场网络部署在接收端,其余模型在发送端。整体神经网络结构如图4所示。
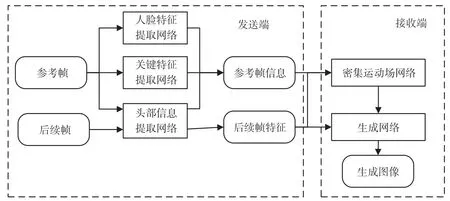
图4 整体神经网络结构
2.1 人脸特征提取网络
人脸特征提取网络的目的是提取参考帧人物的3D通用特征,用于最后生成器的合成,其网络结构如图5所示。
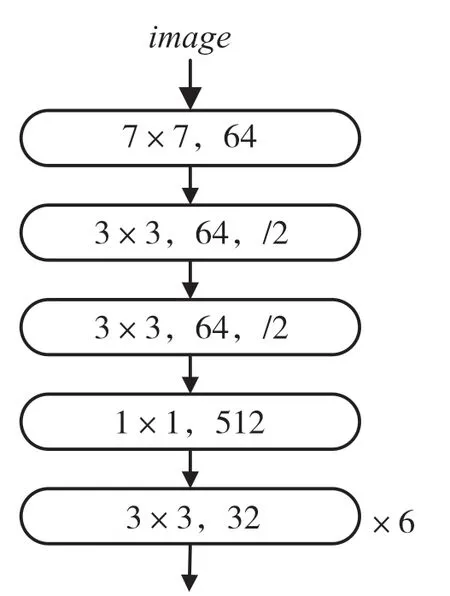
图5 人脸特征提取网络结构
输入图像的分辨率为256×256,输出的特征为fr(f表示特征信息,下标r表示参考帧)。人脸特征提取网络的设计目的是提取参考帧图片中人物的色彩特征,辅助最后生成网络进行生成。该网络只用于对参考帧图像进行特征的提取,在整个图像传输系统中只需要在初始化的时间工作1次。
人脸特征提取网络的训练采用无监督的方式,不采用具体的loss进行输出的约束,由整个网络模型的生成质量损失来进行学习训练。
2.2 头部信息提取网络
头部信息提取网络用于提取参考帧和后续帧中人物的头部姿态、位移、表情系数特征。参考的是HopeNet[6]的网络结构,在原始网络的输出端增加位移和表情系数的输出,其结构如图6所示,其中FC表示的是全连接层。参考帧和后续帧的图片都需要经过头部信息提取网络输入旋转系数r、位移特征t、表情特征δ,相关特征和关键点特征组合后可以得到对应图片的表达特征。

图6 头部信息特征提取网络结构
头部信息提取网络的训练,对旋转系数r采用L1损失,标签信息rgt由Hope net得到,其损失函数为Lr=||r-rgt||1;δ也采用了L1损失用于限制其值的大小,其损失函数为Lδ=||δ||1;t采用自监督的方式进行训练。
2.3 关键点特征提取网络
关键点特征网络用于提取参考帧人物的身份特征,采用了MobileFaceNets[7]的预训练权重,增加了2层全连接层下采样到3×k维的特征,网络如图7所示。

图7 关键特征提取网络结构
关键点特征网络输入的变量为参考帧图片,输出为xk,k为选取的关键点数量,本文中k=15,则对于参考帧的特征向量结合头部信息提取网络的结果,计算公式为:
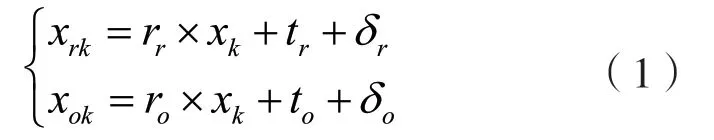
式中:下标r为参考帧的相关特征量;下标o为其他帧的相关特征量。
关键点特征网络为了让关键点均匀地分布在特征空间中,采用的损失函数为:

2.4 接收端模型
接收端模型包含密集运动场网络和生成对抗网络,其中运动场网络用于预测参考帧提取的特征和后续帧传输的特征之前的运动特征,用于提高图片的生成效果。3D运动场的输入是将参考帧和关键帧的光流特征与fr相结合输入到网络中,网络结构是将UNET[8]网络结构中的2D卷积替换为3D卷积。输出运动特征m(x)和遮罩mocc。
生成对抗网络的网络结构如图8所示,中间的隐特征与3D运动场网络输出的遮罩特征图相结合,解码器部分采用了spade块[9]替换res块[10],提高生成图像的质量。

图8 生成网络结构
对应生成网络的训练损失采用了Perceptual损失[11]、生成对抗网络(Generative Adversarial Network,GAN)[12]损失。
3 实验与结果
3.1 相关实验准备
本文模型训练数据集采用的是Voxceleb[13]数据集,数据集共包含1 251位不同人物说话的头部视频,训练集共有21 819段视频,测试集有677段视频,本次实验的评测结果的指标是在此数据集的测试集上得到的结果。本文模型训练采用了4块RTX3090,模型一共训练40轮。
3.2 重建精度实验
为了对比本文视频重建的效果,采用了一阶模型移植(First Order Model Migration,FOMM)模型[5]和Fs-vid2vid模型[3]为基线模型进行重建精度的对比,采用平均峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)[14]和结构相似性(Structural Similarity,SSIM)[15]作为图像清晰度指标,采用平均关键点距离(Averary Keypoints Distance,AKD)[5]作为重建动作准确度指标。结果如表1所示。

表1 模型重建精度实验结果
从表1中可以看出本文所提出的方案,在清晰度和准确性上都有更优的表现,这得益于选取了更加先进的网络结构以及更高维的三维特征。为了直观地展示结果,图9给出了一部分测试结果。
由图9可以进一步得到,本文的方案更加优秀,在存在面部遮挡的情况下,也能较好地还原人物的面部表情。

图9 视频生成实验结果
3.3 传输比特率实验
以分辨率为256×256、帧率为25的视频为例,在后续帧传输阶段只需要传输xrk,传输1帧图像需要传输数据量为15×3×2 bit,转换为视频码率为2.197 2 kbit/s。与采用H264标准进行压缩的视频码率分别为28 kbit/s和38 kbit/s的图像对比结果如图10所示。
由图10中可以看出,本文生成的结果不但在清晰度上优于采用H264压缩的图片,而且传输的码率低于传统编码结果,因此可以得出本文所提出的方案在降低视频传输码率的同时还保证了较好的清晰度。

图10 编码清晰度对比实验
4 结语
本文提出了一种基于视频重建的会议图像传输系统方案,可以用于脸部视频会议传输中减少传输的码率,降低网络带宽的压力。在和相关图像重建工作的对比中,本文所提出的方案取得了更好的重建图像清晰度和人物动作精度,评价指标PSNR达到了23.44;在和传统编码方式的对比中,本文方案取得了更高的图像清晰度以及更低的视频码率。在后续帧的传输中,本文码率为2.197 2 kbit/s,同时,传输的信息变为特征向量,且不附带其他信息,可以更好地保护传输数据的安全。
本文尝试将深度学习中的生成网络技术引入到视频会议的图像传输中,提出的方案具有一定的可行性,但是也存在着一些不足,如目前还只能限制使用在单人像场景下的视频会议中,场景单一,另外对于接收端和发送端的机器配置存在一定的要求。因此,还需要进一步改进网络和优化方案,从而能够采用更小的网络、适应更多的场景。
