基于深度卷积网络的3D人脸重构算法
2022-07-10陈娜
陈 娜
(兰州工业学院计算机与人工智能学院,甘肃 兰州 730050)
1 引 言
基于单张人脸图片的3D人脸重构,无论是在计算机图形[1]还是光学成像[2]领域均是一个极具挑战性的研究方向。由于人脸丰富的差异特征,能够在性别、身份以及当前兴起的识别、支付等领域广泛运用[3]。但随着科技的不断发展,二维人脸图片的局限性越发明显,而3D人脸具有更为全面的信息、更强的鲁棒性,得到国内外学者更为广泛的关注[4]。
目前,关于基于单张人脸图片的3D人脸重构研究主要可以分为三类:基于统计模型的3D人脸重构、基于单一模板的3D人脸重构以及基于深度学习的3D人脸重构。其中,基于统计模型的3D人脸重构主要是依赖训练数据的统计分析,进而运用主成分分析等方法生成3D人脸模型[5-7]。该方法虽然可以有效地生成3D人脸模型,但对人脸五官及面部表情的描述有限。基于单一模板的3D人脸重构是使用输入图像作为指导,根据初始反射率和参考模型表面的几何形状找到阴影的初始估计位置,迭代计算位置区域的投影位置及深度信息,之后使用所获得的阴影特征信息构建3D人脸模型[8-9]。该方法并不能有效地将人脸模板变换到期望的形态,或多或少存在与真实人脸有信息差异的问题。基于深度学习的3D人脸重构则是收到近年深度学习对图像特征信息自主学习的启发,通过神经网络自主训练图像与参数、几何关系之间的映射关系,从而利用有限的2D人脸图像信息自主训练生成3D人脸模型的方法[10-12]。
国内近年也有许多学者致力于这方面研究,例如文献[13]首先对2D人脸图像标准化,使用光照信息和对称纹理重构人脸自遮挡区域的纹理;然后依据2D-3D点对应关系从标准化的2D人脸图像获取相应的3D人脸纹理,结合人脸形状重构和纹理信息,最终得到最终的3D人脸重构结果。文献[1]通过重新渲染合成的方法将参数化模型拟合到输入的多视角图片,然后在纹理域上求解一个光流问题来获取不同视角之间的对应关系;通过对应关系可以恢复出人脸的点云,并利用基于明暗恢复几何的方法来恢复人脸细节;从而提出了一种多阶段优化的方法来解决基于多视角图片在未知姿态、表情以及光照条件下的高精度三维人脸重构问题。文献[14]针对人的脸部特征复杂、细节纹理丰富,获取高精度人脸3D模型成本高、工作量大的问题,利用球形灯光装置建立6种不同的光照模式,并利用偏振光特性对镜面反射光和漫反射光进行分离;利用单向梯度光图像,并基于双向反射分布函数(BRDF)得到反射光方向与法线方向的关系,通过计算获取镜面反射和漫反射法线图,从而提出了一种基于梯度光图像的高精度3D人脸重构算法。
然而,这类3D人脸重构算法由于优化复杂度高,且存在局部最优解和初始化不良等问题,通常模型复杂度较高、运算量较大。鉴于卷积神经网络在图像重构方面的强大潜力,本文通过使用深度卷积神经网络直接学习2D人脸图像从像素到3D坐标的映射,从而提出了一种基于深度卷积神经网络的单张图片向3D人脸自动重构算法。
2 单张图片向3D人脸自动重构
2.1 基于3DMM的图像信息提取
本文首先基于3D转换模型(3D Morphable Model,3DMM)来提取2D人脸图像的密集信息[15]:
(1)
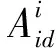
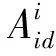

图1 基于3 DMM的图像信息提取
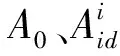
(2)
为了使3D人脸模型能够以单张2D人脸图像为基础进行重构,本文将其中人脸图像的基准点信息由一个稀疏集合表示,并用矩阵U表示这些二维信息的x和y坐标:
(3)
从而,3D形状矩阵A与二维信息U之间的关系可以用弱透视投影(Weak Perspective Projection)来描述,即:
U=sRΑ(∶,d)+t
(4)
式中,s是标度参数;R是由三个旋转角度信息α,β和γ所控制的3×3旋转矩阵的前两行;d是一个N-dim索引向量,表示与二维信息对应的有语义意义的3D顶点的索引;t是一个由tx和ty组成的转换参数。
通过收集所有参数相关投影,将形成投影向量m=(s,α,β,γ,tx,ty)T。由此,可以将任何2D人脸图像看作是3D人脸模型的平面投影。
2.2 DCNN架构
鉴于目前深度学习在计算机视觉以及图像处理中的长足发展,如图2所示,本文构建深度卷积神经网络(DCNN),从输入2D人脸图像中学习非线性映射函数f(Θ)从而对应的投影参数m和形状参数p,然后再利用估计的参数来构造密集的3D人脸模型。
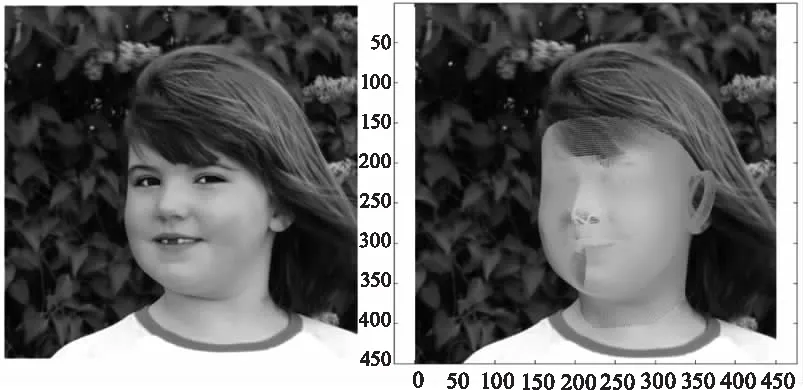
图2 基于DCNN架构的3D人脸重构
如图3所示,为本文所构建的基于深度卷积神经网络的单张图片向3D人脸重构架构。图中,两个分支共享前三个卷积模块。在第三个模块之后,使用两个相互独立的卷积网络模块来提取特定任务的特征信息,再接入两个完全连接层神经层来将特征转移到最终输出。其中,每个卷积网络模块的结构显示在左下角区域中。每个卷积网络模块由两个卷积层和一个最大池化层组成,后面是一个批处理归一化层和一个激励层。
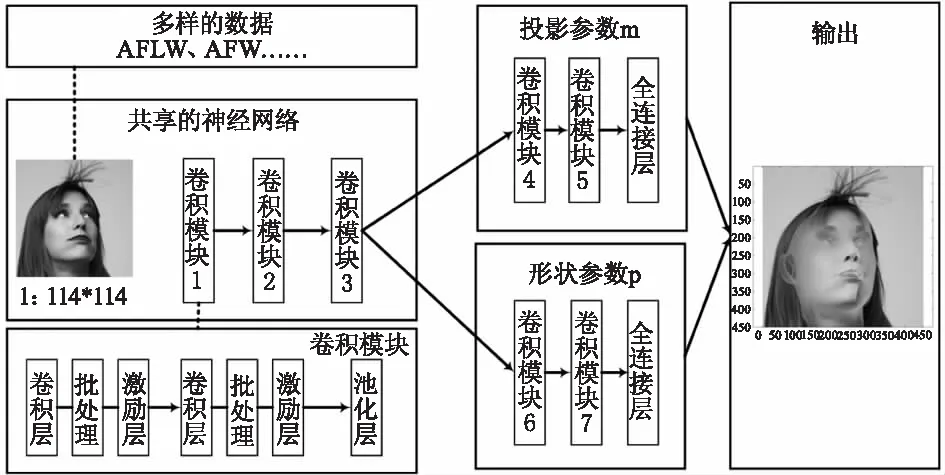
图3 基于深度卷积神经网络的单张图片向3D人脸重构架构
为了改进卷积神经网络的训练效果,本文使用了一个包含多个制约条件的损失函数[17-20]:参数制约条件Gpr使估计参数与真实值参数之间的差异最小;运用地标拟合制约条件Glm降低2D人脸图像的对准误差;运用轮廓拟合制约条件Gc强制将估计的3D人脸模型的轮廓与输入图像的轮廓像素进行匹配;运用SIFT配对制约条件Gs以鼓励两张人脸图像的SIFT特征点对对应相同的3D顶点。
由此,构建总体损失函数:
(5)
式中,λlm,λc,λs为权重系数。
本文3D人脸模型构建是通过深度卷积神经网络(DCNN)实现的。网络训练过程中,将初始全局学习率设为e-3,并在训练误差趋于平稳时将学习率降低10倍。将每批训练数据大小设为32,网络衰减系数为0.005,激励函数衰减因子设为0.01。通过多次训练,总体损失函数的权重系数λlm定为5、λc定为1、λs定为1。
其中,参数制约条件Gpr由下式定义为:
(6)

3D形状矩阵A(∶,ilm)投影到2D平面上,将地标拟合制约条件Glm定义为:
(7)
式中,F为下标,表示Frobenius范数;L为预定义地标的数量。
2.3 轮廓拟合制约条件(CFC)
由于轮廓拟合制约条件Gc的描述相对比较复杂,为此专设一小节进行阐述。
轮廓拟合制约条件的目的是使所要重构的3D人脸模型的投影外边界(即轮廓)与输入的2D人脸图像中相应的轮廓像素之间的误差最小。在将2D平面渲染到3D空间上时,可以将其外轮廓看作是背景与三维面之间的边界。
在利用人脸轮廓信息构建制约条件束过程中,需要遵循以下三个步骤:(1)检测2D人脸图像中的真实轮廓;(2)描述估计的3D形状矩阵A(∶,ilm)上的轮廓顶点;(3)确定真实轮廓与估计轮廓的对应关系,并以拟合误差作为反馈。具体步骤如下所述。
在第三步中,通过点对点的通信来评估Ulm和A(∶,ilm)之间的约束。由于二维图像中只能检测出部分轮廓像素,而三维形状轮廓则通常是完整的,因此需要将二维图像上的轮廓像素与三维形状轮廓上的最近点进行匹配,从而计算出最小距离。由此,将这所有最小距离的总和定义为轮廓拟合制约条件Gc:
(8)
为了使轮廓拟合制约条件可微,对式(8)进行改写,计算图像中最近轮廓投影点的顶点指数,即k0=argmink∈ilm‖A(∶,ilm)-Ulm(∶,j)‖2。
Ulm(∶,j)‖2
(9)
2.4 SIFT配对制约条件(SPC)
运用尺度不变特征变换(SIFT)配对制约条件(SPC)对密集形状进行预测,使其能够预先定义的标志(如边缘、皱纹和痣等)以外的重要面部点上保持一致。
尺度不变特征变换(SIFT)描述是一种经典的局部表示方法,它对图像尺度、噪声和光照都是不变的,被广泛应用于许多基于回归的人脸对齐方法中以提取局部信息。
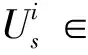
(10)
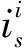
(11)
3 实验分析
对于本文提出的算法,在训练过程中将DCNN的学习率设为恒定的0.0001,各神经网络模块参数如图4所示。
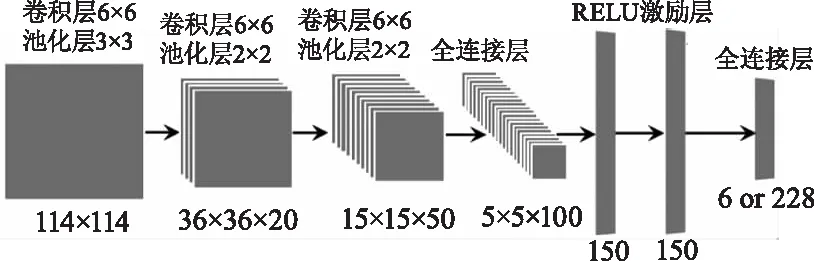
图4 算法神经网络参数设置
考虑到人脸重构算法的重点是对2D人脸图像的轮廓对齐的训练,因此算法训练中选择了两个公开可用的人脸图像数据集。
AFLW数据集[24]是一个25K 2D人脸图像数据集,每个图像都事前有多达21处标记,每个标记都有一个可见性标签。例如文献[24]选择了一个偏航角均衡分布的AFLW子集,包括3,901张用于训练的图像和1,299张用于测试的图像。因此,本文也使用相同的子集对算法进行训练和测试。
AFW数据集[25]包含205张图像,每个人脸图像都被事前标记6处标记,每个地标都有一个可见性标签。对于每个人脸图像,提供检测到的包围框。由于图像数量相对较少,本文仅使用该数据集进行测试。
根据表1所示,为检验本文算法的对比优势,选择了最新的人脸对准算法(PIFA[26]、RCPR[27])与本文算法进行仿真对比,仿真效果如图5所示。

表1 算法设定

图5 算法比对仿真效果
如图6所示,展示了三种算法每次迭代的测试误差。仿真结果表明,三种算法虽然都能经过训练直到收敛,但相比较RCPR不能很好地模拟拟合误差,且收敛于一个不令人满意的结果。PIFA算法虽优于RCPR算法,但病理曲率问题[27]使其只关注一小组参数,限制了性能。本文算法能够明确地对2D人脸图像的每个参数的优先级进行重构,得到了更好的结果。
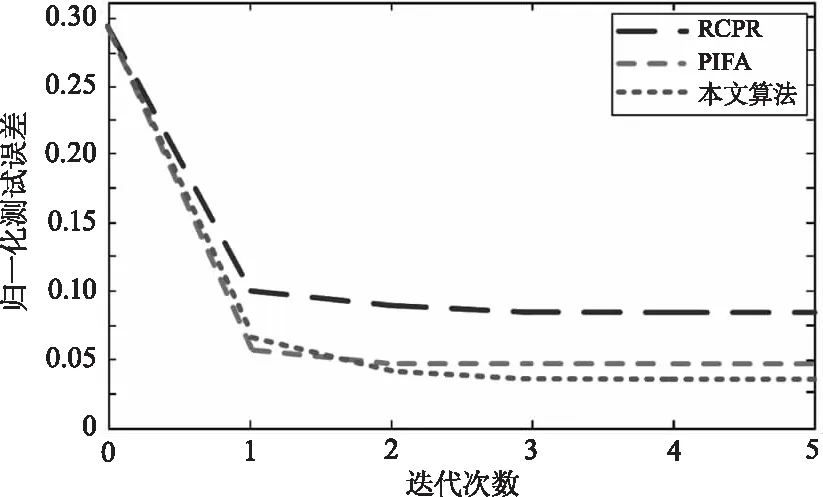
图6 算法测试误差对比
为了进一步检验本文算法在不同人脸方位和数据集中的性能,分别计算了三种算法在第一阶段训练后在AFLW和AFW数据集上不同人脸姿态的测试NME值,比较结果分别如表2和表3所示。NME值虽能够对比不同算法的精度,但用于3D人脸重构的评价却可能因为图像标记信息较多而第一阶段神经网络训练不充分,存在边缘模糊现象。由此,在AFLW数据测试中,本文算法相较而言对于[0°,30°)和[30°,60°)存在NME值较高的现象。而对于AFW数据集,由于其较少的图像标记,本文算法仅仅通过第一阶段的训练就能获得较其他两种算法更低的NME值。通过继续仿真发现,随着神经网络训练的深入,本文算法能够不断修正边缘模糊现象,并最终获得比另外两种算法更低的NME值。通过对比仿真可以看出,本文算法在AFLW和AFW数据集中总体取得了较低的NME值,从而验证了本文算法在单张二维图像向3D人脸重构运用中的有效性。

表2 不同算法在AFLW数据集上的测试结果
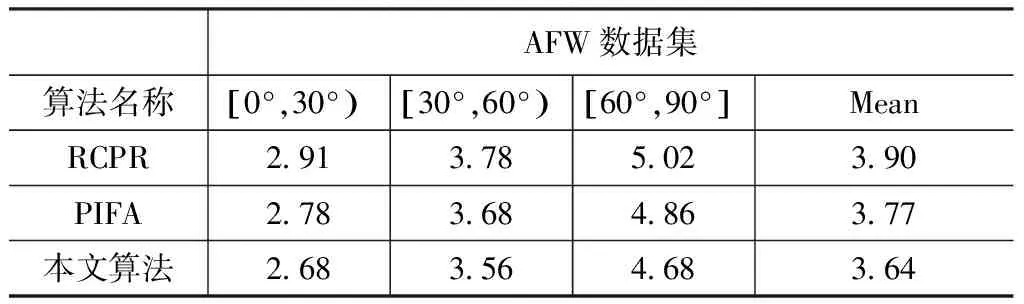
表3 不同算法在AFW数据集上的测试结果

图7 单张图片向3D人脸重构
对于3D人脸模型重构可以分别在人脸区域和外部区域进行,但对精度的要求不同。对于如图7(a)所示的单张2D人脸图像,在3D人脸区域,通过第1节提出的DCNN架构来进行拟合,如图7(b)所示。在外部区域,仅采用三角剖分(Delaunay triangulation)[28],标记出人脸区域之外的一些锚点,用2D人脸原图替换,然后叠加3D模型从而构成完整的3D人脸模型,如图7(c)所示。
当深度信息被估计后,所重构的3D人脸模型可以在三维空间中旋转,以生成更大姿态的外观,如图8所示。可见,外部人脸区域对于真实的轮廓图像是必要的。在此仿真实验中,将3D人脸模型空间旋转范围由30°的放大到90°,由此不仅可以获得大姿态下的3D人脸模型,而且还可以对数据集进行扩充,这意味着即使给定一个视角有限的2D人脸图像,DCNN网络也可以得到很好的训练。

图8 3D人脸模型空间旋转效果
4 结 论
针对目前算法复杂度较高、运算量较大且存在局部最优解和初始化不良等问题,本文首先基于3D转换模型来提取2D人脸图像的密集信息,然后构建深度卷积神经网络架构、设计总体损失函数,提出了一种基于深度卷积神经网络的单张图片向3D人脸自动重构算法。从算法比对和仿真实验结果来看,本文算法具有更低误差的比较优势,3D人脸模型还原度高,面部表情保留完好,支持多角度三维旋转,没有盲区,在各类场景中将具备较高的应用优势。
