投诉工单聚类算法在问答系统中的研究
2022-07-09李洪巍莫建坡曲荣胜孙浩苏明
李洪巍 莫建坡 曲荣胜 孙浩 苏明
(北京宝兰德软件股份有限公司 北京市 100089)
1 研究背景
电信运营商的工单系统每日从全国各个地市汇总大规模用户投诉的工单数据,系统中存在大量重复,相似的工单需要进行合并归类,引入机器学习可以智能化的对工单进行处理。采用自然语言处理技术可以更好的理解工单之间的语义信息,再通过聚类算法归并相似工单。将处理后的工单沉淀到知识库中,通过对接问答系统可以为用户提供工单解决方案的查询,相似工单查找等功能。能极大减少客服人员的工作量,提高工作效率。
大规模工单聚类场景在应用落地过程中主要面对两个技术难题:一个是低资源的训练样本,另一个是聚类算法效果欠佳。人工标注的相似投诉工单的数据量较少,如何在此情况下保证聚类算法效果是需要解决的问题。近些年在文本聚类领域一般从词向量表征和聚类算法两种角度进行优化。
词向量表征方面,针对BERT 进行微调是近些年流行方案,在中文场景下BERT-wwm模型引入全词掩码机制(whole word masking,wwm),在中文分词后进行掩码;NEZHA 模型引入相对位置编码函数,混合精度训练等优化方式。TSDAE模型采用AE 网络架构对输入的文本加入噪声,并在输出阶段进行文本重建。在文本匹配领域有基于孪生网络结构的优秀模型,Sentence-BERT 采用了BERT 做为encoder 层,通过相似样本(正样本)和非相似样本(负样本)训练整个模型。SimCSE 提供了有监督和无监督两种训练方式,利用预训练模型中自带的Dropout mask 作为数据增强的手段得到更多的Sentence Embeddings。ESimCSE 针对SimCSE 的不足提出采用Word Repetition 的方式随机复制句子中的一些单词来改变相似语句的句子长度,它还引入了动量对比学习扩展负样本对,该思路来源于CV 领域的Moco模型。
近些年聚类算法在深度学习领域有了不错的发展。DEC算法由两部分组成,第一部分会预训练一个AE 网络;第二部分选取AE 模型中的Encoder 部分,加入聚类层使用KL 散度进行训练聚类。DeepCluster 模型对特征进行聚类,然后基于聚类的结果作为伪标签,更新网络的参数预测这些伪标签,两个过程依次进行。
2 算法设计
2.1 投诉工单问答系统架构
本文设计的投诉工单问答系统架构示意图如图1 所示,系统分为3 部分。首先,针对标注样本不足的问题,本文设计了基于BERT-wwm 的数据增强算法流程;其次,扩展后的工单数据经过TSD-DEC 深度学习聚类算法进行聚类。最后,将聚类后的工单沉淀入知识库中,搭建问答系统支持用户对相似工单和解决方案的查询。此外,知识库中聚类工单还可以应用于其他下游应用场景,如辅助新工单的类别标注。

图1: 整体流程架构图示意图
2.2 数据增强
投诉工单数据源于电信运营商的工单系统,人工标注时按照投诉类别进行。为保证后续模型效果,标注需要在同一个类别中尽量多的标注出相似的投诉语句。标注后的数据结构见表1,如“手机停机”类别中包含4 条投诉内容,它们按照“处理意见”字段分为2 组。需要注意的是,相似的投诉内容可能对应不同的处理意见。

表1: 标注数据格式
针对投诉内容中的相似句子对进行样本增强,将标注的句子对做为正样本,不同类别间的非相似句子对做为负样本。
将正负样本输入到BERT-wwm 模型中进行微调,算法整体流程如图2 所示。微调后的模型对非标注的数据进行语义表征获得句向量。表征后的向量与标注样本向量进行基于语义相似度的检索排序。本文采用参数Top-N 来控制新标注样本数量。最后,将新产生的标注样本与人工标注样本结合成为扩展后的样本。
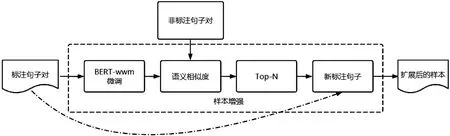
图2: 样本增强算法流程
预训练模型采用针对中文优化的BERT-wwm,该模型引入了全词Mask 机制,在全词Mask 中,如果一个完整词的部分WordPiece 子词被mask,则同属该词的其他部分也会被mask。在BERT-wwm 模型微调时,构建输入格式为sentence 1 与sentence 2,将正例样本输出类别为设为class为1,负例样本class 为0。图3 为BERT-wwm 微调示意图。
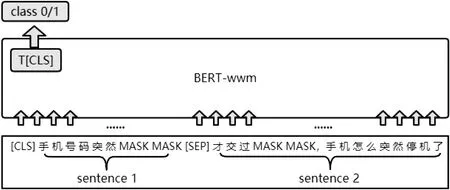
图3: BERT-wwm 示意图
BERT-wwm 模型将输入的每个字转换为一维向量与段落向量和位置向量进行相加得出输入序列I=([CLS],se ntence1,[SEP],sentence2),再经过编码器处理后输出向量T=(T,T,T,...,T,T)。此时,输出的向量T包含了sentence 1 与sentence 2 的交互信息,基于T计算其0/1 分类,公式如(1)所示。其中softmax 函数可将输出结果映射为置信度0~1 的概率值,W∈R为隐藏层权重,b∈R为偏执项。
y=softmax(TW+b) (1)
在得到微调的BERT-wwm 模型后,将未标注的数据按顺序和已标注样本拼接成句子对输入到模型中进行推理,设定最相似的Top-N 数据进行扩展。显而易见,N 值越小扩展样本质量越高,扩展样本数量则越小。最后,这些新标记的样本结合已有的人工标注样本一起做为后续聚类的训练样本。
2.3 深度聚类算法
传统文本聚类算法将文本表征过程与聚类过程分开计算,而深度学习聚类算法将深度网络与聚类过程联合训练。学习到的高质量文本表征有助于提高聚类算法性能,聚类结果的训练也可以引导深度网络学习到更好的表征。DEC 深度聚类算法采用两个步骤进行模型训练,首先构造AE 网络获得良好的样本向量表征,其次采用AE 网络的encoder 部分结合K-Means 组成联合网络进行聚类训练。网络结构如图4 所示。
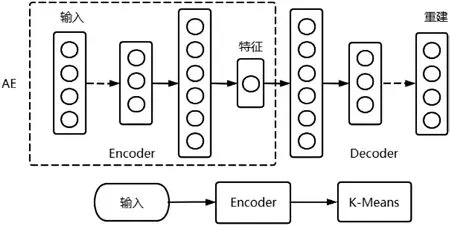
图4: DEC 算法架构图
本文受TSDAE 算法启发,对AE 网络进行了改进。TSDAE 整体网络结构采用AE 架构,在训练时TSDAE 对输入的语句加入噪声并要求Decoder 从该句子表征中重建原始句子。为了获得良好的重建质量,就要求在Encoder 端很好地捕获语义。在后续推理时只使用Encoder 来编码句子向量,这和DEC 是相同的。本文提出TSD-DEC 网络结构,将两种算法相结合,其中TSDAE 网络结构中的Encoder 与Decoder 选用上一节中微调后的BERT-wwm 模型。TSDDEC 算法架构如图5 所示。
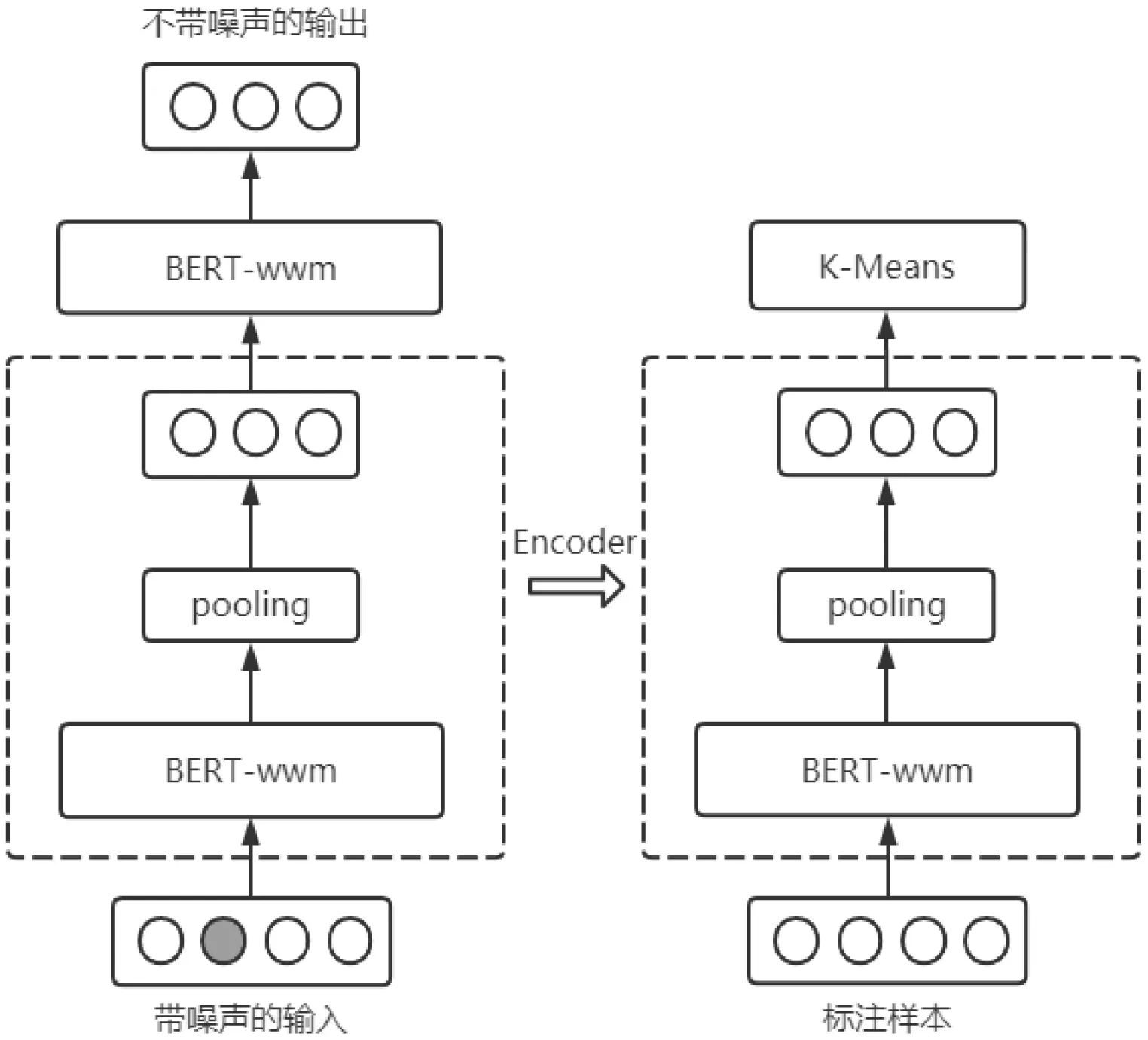
图5: TSD-DEC 算法架构图
在对数据文本加噪声的过程中,本文结合工单领域关键词字典增强效果。对每一种类别的工单数据采用TextRank算法提取Top-N 个关键词,N 一般选择2。通过算法初筛后的关键词字典再经过人工进行细筛。
2.4 问答系统

表4: 噪音实验结果
聚类后的工单数据存贮在知识库中供下游任务的使用,本文对接知识库搭建了工单问答系统,命名为“智能工单机器人”,支持用户对工单处理意见的检索。用户输入投诉工单内容,问答系统会在知识库中检索相似的N 个工单并返回它们的处理意见。本文采用Elasticsearch 7.5(ES)版本构建知识库,采用dense_vector 创建向量索引,支持查询向量与文档向量之间线性计算相似度并排序。创建dense_vector 索引部分代码如图6 所示。

图6: ES 索引创建
本文基于K-Means 聚类结果构建了向量检索加速流程。首先,针对K-Means 的聚类核心点创建索引,用户输入的查询语句先与若干核心点进行相似度计算,这里设置参数Top-K,即检索K 个最相似核心点;其次,在被选中的核心点类别中线性计算查询语句与每一条候选向量的相似度并排序。显而易见,通过这种检索方式检索速度相比ES 本身的线性计算有了大幅提升。智能工单机器人示意图如图7 所示。
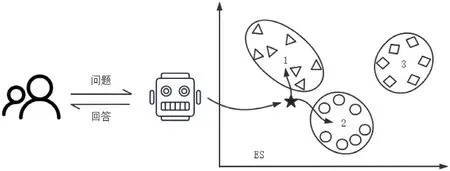
图7: 智能工单机器人示意图
图中在二维空间展示ES 中聚类工单分布,共有3 种类别,中心的五角星代表问题向量所在位置,参数选择K=2。图中最相似的类别核心点为类别1 与类别2,查询语句线性计算两种类别中的所有候选语句,找出最相似的N 个工单,最终会在问答系统界面展示所有N 个工单的处理意见。
3 实验分析
3.1 数据准备
从原始工单表中筛选出对模型有用的字段,删除无用字段如“采集设备”,“设备编号”等。经过去重,滤空,删除电话号码等预处理操作,有效的原始投诉工单数据总量约3.2 万条。对投诉内容进行文本长度的直方图统计,基于统计结果将投诉内容过长及过短的数据进行删除,保留字符长度介于5 到40 之间的数据,约占总数据的95%。人工标注的数据样本共2720 条数据分为12 个类别。在2720 条数据中,人工标注相似句子对2028 条。工单数据集描述如表2 所示。

表2: 工单数据集描述
3.2 数据扩展实验
数据扩展选择BERT-wwm 的base 版本进行微调,与BERT-base 模型规模保持一致:12-layer,768-hidden,12-heads。正样本为人工标注的句子对2028 条,负样本用不同类别的句子对组成5000 条。每一条标注样本都会和所有非标注样本拼接成句子对输入到微调后的BERT-wwm 中进行计算,得到的结果按照置信度降序排序,筛选出Top-N 条数据。新增样本情况如表3 所示。

表3: 新增样本
分析表格中的数据可以看到,当N=1 时,因不同的标注样本会匹配到相同的候选语句,原始新增样本数量2028条经过去重之后剩下911 条。随着N 的增加,新增样本增长幅度降低,原始新增样本中重复样本数量也开始增加。通过人工判定发现在N 大于2 时新增样本中会出现明显不相似的样本,为保证新增样本质量,本文选择N=2。
3.3 TSD-DEC算法实验
3.3.1 TSDAE 实验
本文结合关键词字典以不同的方式来制造输入数据的噪声。其中,针对Delete 和Replace 的方式,不允许改动关键词字典中存在的词语,如“停机”,“欠费”等词语。噪声占比参数选择0.3,池化方法选择平均池化,评价指标选择斯皮尔曼等级相关系数。相关系数ρ 如公式(2)所示。

3.3.2 TSD-DEC 聚类实验
本文设计了5 组实验来验证算法流程的性能优越性。首先基于所有的31840 条数据训练得到传统的TF-IDF 模型与经典分布式词向量Word2Vec 模型。它们产生的句向量输入到K-Means 中进行聚类。在深度聚类算法上,原始DEC 算法做为基础参照标准,算法参数与算法原论文保持一致,对比没有经过数据增强的TSD-DEC 与数据增强的TSD-DEC算法性能。评价指标选择纯度(Purity)与轮廓系数(Silhouette Coefficient)。聚类结果如表5 所示。
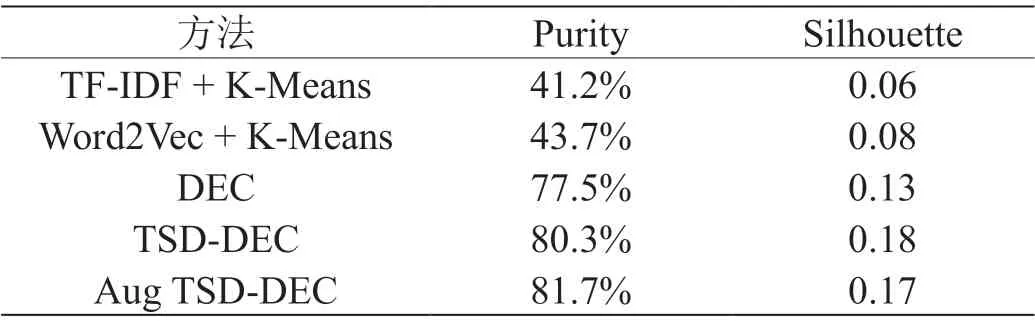
表5: 聚类实验结果
从表格中的实验结果可以看出,本文设计的TSD-DEC算法相比于原始的DEC 算法有一定的性能提升。而经过数据增强后,模型的性能得到了进一步的提升。
3.4 问答系统性能
为测试大规模数据场景下的检索响应速度,本文采用EDA 方法扩展工单数据到70 万条。模拟现场实际环境搭建3 个节点分布式ES 集群,每个节点硬件配置充足(16GB 内存,4 核i7-8700 CPU @ 3.20GHz)。问答耗时采用10 个问题的平均耗时计算。实验结果如表6 所示。

表6: 问答响应时间
耗时增长基本呈现线性增长,但面对工单数据百万级别数据量来说,响应完全满足实际应用。
4 结论
针对电信运营商的投诉工单数据,本文设计了工单数据增强算法与改进的TSD-DEC 深度聚类算法。对聚类后的工单数据,本文搭建了高性能的智能问答机器人,以供用户对工单解决方案的查询。实验表明,经过数据增强的TSDDEC 算法相比于原有的算法性能有了明显提升,而文本设计的智能工单机器人对用户的查询也可以做到快速响应。
