基于T-Closeness的医疗档案数据脱敏与共享管控技术研究
2022-07-08章晨焱王劼陈斌
章晨焱,王劼,陈斌
(常州市第二人民医院,江苏常州 213003)
国外医疗数据安全防护研究是从医院信息系统和电子病历推广使用后逐步开展实施的,医疗数据在共享前必须满足相关法律法规[1]和匿名化[2],即脱敏处理。任何非法访问与纰漏患者健康信息的单位和个人,均将受到严厉的法律惩罚[3]。在现有应用方案中,美国较为著名的是基于云平台的医疗社区在线系统,其医疗数据主要集中存储在运营商远程服务器中[4]。英国于2012 年建立了家庭医生系统,由于医疗数据共享于全国家庭医生,因此在对外提供数据共享前,先“脱敏”以解除数据间的关联[5]。2013年,韩国建立了首个身份识别系统,规定用户必须完善身份认证后才能开放患者数据[6]。
与发达国家相比,我国医疗建设起步较晚[7],在引进大数据、云计算和云存储[8]后,各医院逐渐开始进行数据加密规划和访问控制的设计。但由于安全数据共享牵涉的技术众多,所以数据在共享前采用脱敏技术进行处理的方案还鲜有涉及[9]。为解决上述问题,该文以医疗档案数据的脱敏设计[10-11]与安全管控为目标,着眼于数据所有权和使用权的确定[12]、系统安全防护边界的划定[13]进行设计。通过对现有医院网络架构的改进,提出了一种增强医疗档案数据脱敏和共享管控的机制。通过对数据采用基于敏感属性的T-Closeness 算法进行脱敏处理,然后结合系统虚拟化设计设定系统安全防护边界,使得敏感数据在访问时仅能够被理解但不能够被直接查阅,从而为共享医疗数据的安全长远发展提供有效的技术支持。
1 T-Closeness数据脱敏理论与方法
T-Closeness 属于匿名化技术,匿名是数据隐私保护技术的基础之一[14-16]。基于敏感属性分组的分布式T-Closeness 算法属于最邻近的等价类重分方法,其基本原则是将语义相近的记录分配到同一等价类种,算法的具体执行可分为3 步:
1)统计敏感属性分布。首先确定每组属性的取值范围,将数据集根据取值分配到不同组中。为便于描述,假设原始数据集包含N条数据,设每个等价类可容纳的数据记录最小为k条,平均每个组可容纳等价类为l个,则原数据可分为N1=组,每组含kl个数据信息。在等价类重分时,数据需要重新分配,划分到上述N1个等价类中。用ei表示第i个等价类容纳的数据个数,b表示分组后的第b组,Cij表示向第i个等价类Ei分配的数据条数,则第i组需要给等价类j分配的数据个数为:
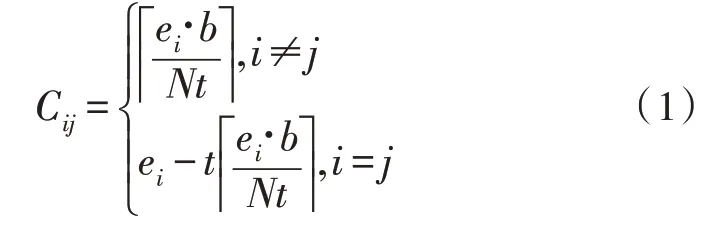
同时,等价类Ei容纳的数据个数ei为:
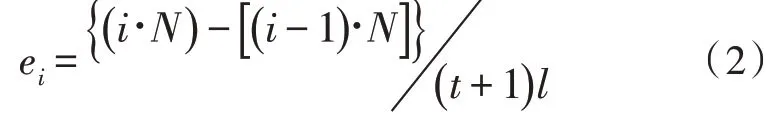
根据式(1)和式(2)的条件对原始数据进行分组,并确定等价类所容纳的信息能够达到参数为t的T-Closeness分布数据隐私约束标准,这也是该文数据脱敏处理用到的主要算法。因此,满足式(1)、式(2)约束的数据脱敏处理算法简称为T-Closeness 算法。
2)根据最邻近等价类重分配。将组内数据对应到多个等价类中,该步将涉及类中数据排序。
3)对每个等价类中的数据泛化和对敏感属性的值做变换,从而得到脱敏后的数据。
2 数据安全共享管控系统设计
安全的数据共享需要确保数据所有权在主体控制权范围内,但传统的访问控制机制不能保障由于数据内容和存储空间的不同导致不同级别的安全需求。因此首先对数据安全共享模型进行分析,确定出决定数据安全的3 个关键因素。
1)主客权限划分。通过将客体信息分成内容和地址两部分,为数据脱敏做准备。
2)数据安全共享规则和管控策略。在数据管理控制过程中,涉及的常用操作为复制和修改,安全共享规则要求在安全存储边界内,主体对客体所作的包括复制和修改在内的操作行为应当具备所有权。此外,用户的访问行为仅限于副本访问,不能改变副本存储位置,即复制到医院现有网络范围外的操作将被禁止。
3)数据的脱敏处理。医疗档案数据涉及病人隐私,具有高敏感度。因此,该文拟采用上述T-Closeness脱敏算法。
3 数据脱敏共享管控系统设计
算法效率和可用性是衡量数据隐私保护系统的两个重要指标,系统设计时应充分考虑这两个指标。此外,改进现有医疗环境的网络架构,设计具有隐私保护的网络框架是数据安全访问的基础。此外,针对不同数据并发规模,还需作相应的系统性能测试。
3.1 系统设计原理
确保医疗数据所有权主体地位不改变,也就是确保数据使用者对数据客体副本进行诸如修改、复制等操作时,不能脱离医院主体的管辖范围,即数据在访问空间上具有一定的安全边界,要求赋予用户操作和修改的权限仅限于数据在医院数据服务器集群范围内,该范围即为数据安全边界。
3.2 系统建立
确保网络中的医疗数据安全可控,系统整体架构可分为3 部分:
1)数据集中化管理平台。其关键在于缩小管控数据的安全边界,即数据可有限访问和浏览,但不能保存、下载到客户端。
2)安全边界设计。为确保数据存储控制范围有效,防止数据非法流出、丧失平台对其的掌控力,可采用数据网关。
3)基于T-Closeness 数据脱敏处理。数据的匿名化处理有助于提升数据泄露概率,拟采用细粒度表现力良好的、敏感属性分组的T-Closeness 算法进行处理。
3.3 数据脱敏处理的医疗网络架构的改进
现有医疗网络架构通常采用的是如图1 所示的内外网隔离机制,外网用户需经过网闸来访问内网数据。然而这种硬件物理隔离严重影响了数据访问的实时性,而且经网闸到达外网的数据安全将无法保障。
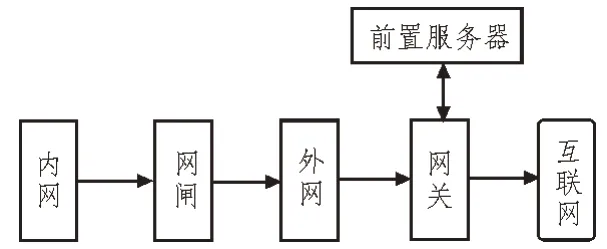
图1 现有医疗档案数据共享网络架构
因此,需要对现有网络架构进行改进。改进后的医疗数据网络共享架构如图2 所示。其关键点在于访问内网共享数据时,用户是在虚拟化环境下进行访问,数据访问操作被限制在安全边界内,且被访问数据已进行脱敏处理。
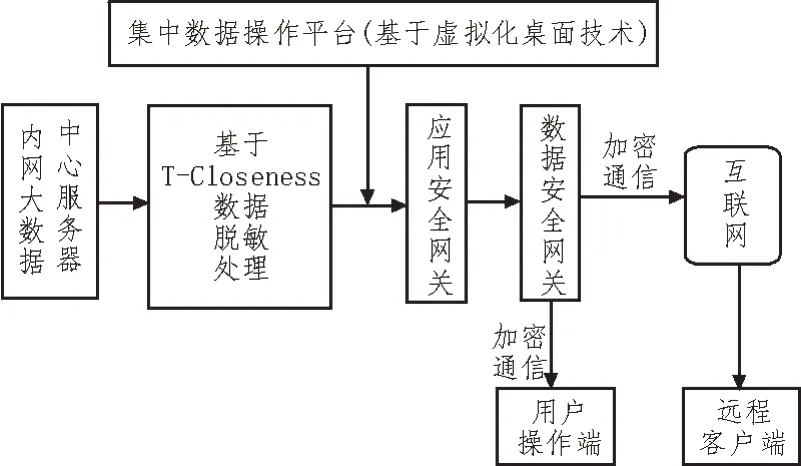
图2 基于数据脱敏处理的医疗档案数据共享网络架构
4 系统实现
上文所提出的医疗档案数据安全共享系统框架中各个模块技术均已成熟,工程应用的实现不存在技术限制。
4.1 系统实现模块
安全虚拟桌面可采用KVM 虚拟化和Windows信任链传递机制来实现。应用访问控制规则可以以现有防火墙技术为基础,结合虚拟桌面管理平台,实时获取虚拟桌面系统资源的分配情况。通过对用户标识和访问控制进行一致性解释,从而生成访问控制规则。面向医疗档案数据共享管控安全防护应用系统的总体设计如图3 所示。系统安全边界可通过虚拟桌面与用户终端虚拟桌面建立安全网关来实现,移动终端和医院数据通讯可采用适用于专网的无线VPDN 业务。
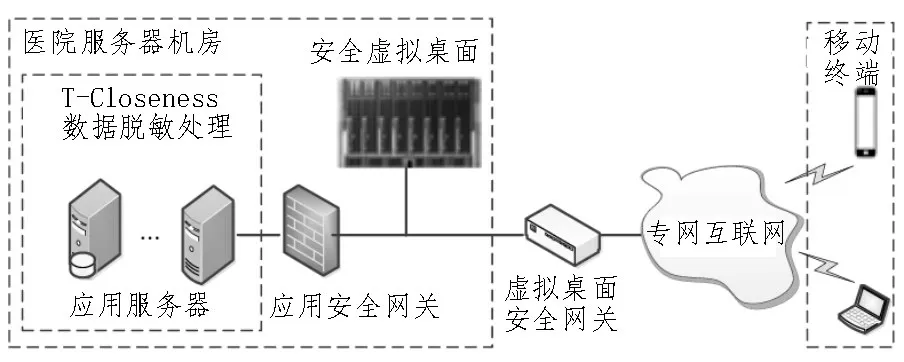
图3 面向医疗档案数据共享管控安全防护应用系统的总体设计
4.2 脱敏环境部署
数据脱敏系统搭建所涉及的环境部署如下:采用Ubuntu 21.04,集群环境为5 台服务器、单机16 核CPU、64 GB 内存。设置其中一台服务器为主节点,其余4 台为工作节点。分布式计算框架采用Spark-2.4 和Hadoop3,实现语言为Java。消息队列为基于内置的ZooKeeper 框架,服务绑定2081 端口,Kafka消息队列节点绑定9192 端口。
4.3 系统测试
该节重点分析数据脱敏处理方面的性能,并与未进行数据脱敏处理的系统作功能和非功能对比分析。
4.3.1 系统功能需求
改进后的医疗档案数据脱敏与共享管控系统需要实现的功能需求有以下4 个方面:用户主客体分离管理、数据脱敏处理、泛化树隐私配置、用户权限管理策略。这些功能是系统实现的基本功能,因此该测试主要考虑非功能需求。
4.3.2 系统非功能需求与测试
在系统的非功能需求分析中,主要涉及脱敏算法运行效率、稳定性和更新效果,具体如下:
1)建立脱敏任务表单的稳定性测试
系统稳定性通常是通过压力测试来完成的,为体现系统在脱敏处理方面的性能,分别对500、1 000、1 500 3 种用户规模经过200 次并发测试,模拟建立脱敏任务表单所消耗的平均响应时间、服务器平均CPU 利用率、服务器峰值CPU 利用率、服务器平均内存利用率4 个性能指标,如表1 和图4所示。
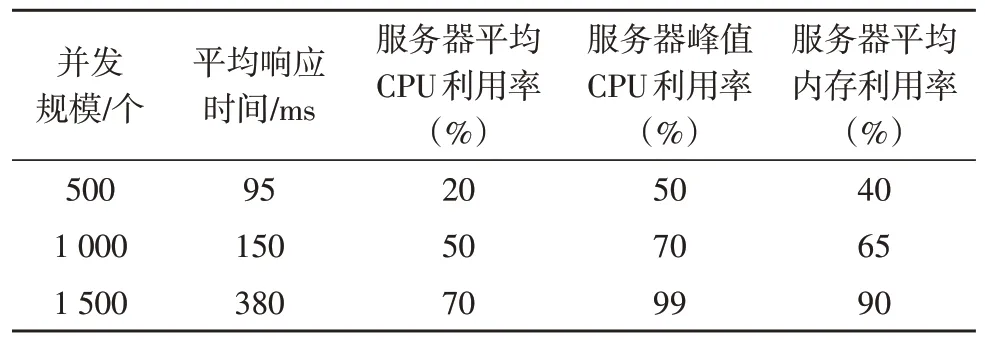
表1 服务器在建立脱敏任务表单的各项指标
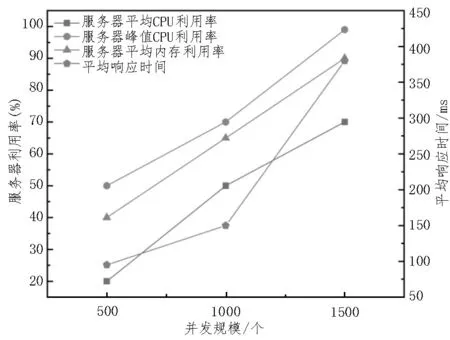
图4 建立脱敏任务表单对应的系统各项指标
经实验测试,该文系统在1 500 用户数量规模的情况下,仍能较好地承受并发压力,且具有较快的响应速度和运行稳定性。
2)运行效率测试
该文选用Firefox 浏览器作为客户端向数据脱敏系统发送请求。测试中选取100 次测试均值作为响应时间,所有项目测试时间均是从该任务提交到执行完毕,相关时间测试如表2 所示。可以看出,系统与用户相关的接口均在450 ms 内返回数据,且以系统总耗时450 ms计,脱敏任务的建立约占总耗时的33%。

表2 系统非功能对应的响应时间
3)有无脱敏任务权限管理更新性能测试
考虑到权限管理模块由数据权限管理子模块和数据下载请求权限校验子模块组成,则脱敏数据的下载会影响文件下载与权限的管理、校验。为了对比脱敏算法对系统更新耗时的影响,分别对500、1 000、1 500 这3 种用户规模经200 次实验进行并发测试,对比测试“数据表权限请求”,相关测试指标不变,详细数据如表3 所示。

表3 有无脱敏处理的系统各项指标
为了得到更直观的对比,对数据进行重新整合,分别得到图5(包含脱敏处理步骤)和图6(不包含数据脱敏处理步骤)的数据。
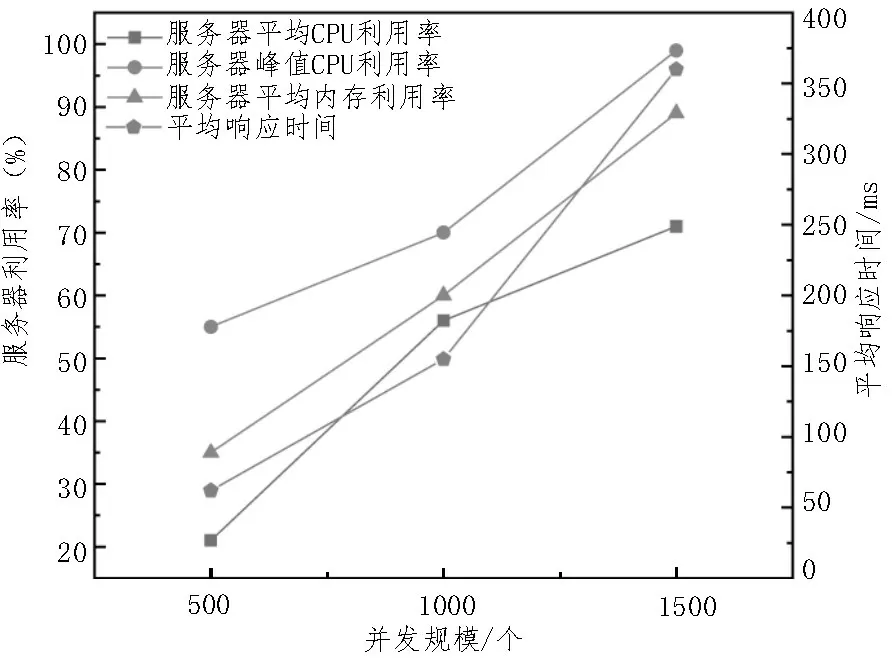
图5 基于T-Closeness数据脱敏处理的各项指标测试
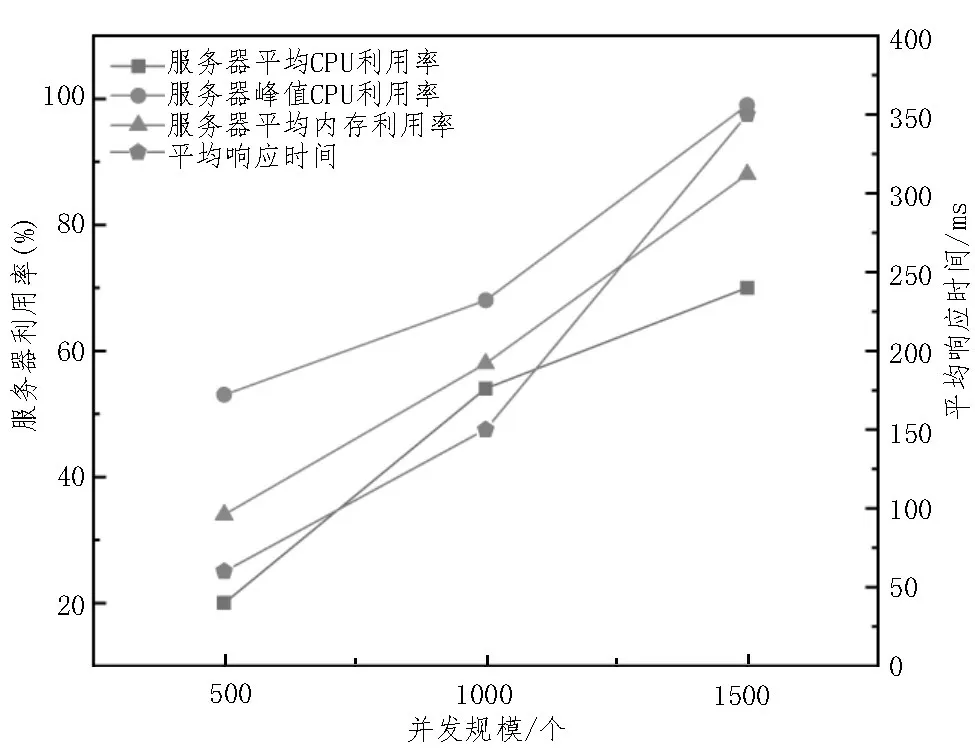
图6 无数据脱敏处理的各项指标测试
上述数据表明,相对于无脱敏处理的同等条件的系统,该算法在服务器峰值CPU 利用率仅增加了约3%。类似的,服务器平均CPU 利用率的增幅未超过2%,服务器平均内存利用率的增加低于1%,时间增长也在合理的范围内。
5 结束语
基于医疗数据的隐私保护需求,该文提出了一种增强医疗档案数据脱敏与共享管控的机制。在系统整体架构设计中,通过对数据作基于敏感分组的T-Closeness 数据匿名隐私处理,确立数据所有权的主客体访问范围。系统设计综合运用了可信计算技术、匿名化技术及边界安全防护技术。最终针对不同数据规模,对系统性能进行评测分析。实验结果表明,在大规模并发访问控制下,系统仍具有良好的性能。
