基于抛物面焦点麦克风预处理和迁移学习的语音增强方法
2022-07-04王泽宇胡梦雪刘赣俊耿彦章
张 涛,王泽宇,胡梦雪,赵 鑫,刘赣俊,耿彦章
基于抛物面焦点麦克风预处理和迁移学习的语音增强方法
张 涛1,王泽宇2,胡梦雪2,赵 鑫1,刘赣俊1,耿彦章1
(1. 天津大学电气自动化与信息工程学院,天津 300072;2. 天津大学国际工程师学院,天津 300072)
背景噪声会严重影响语音的质量和可懂度,从一段带噪语音中分离出目标语音,尽可能地降低背景噪声对目标语音的影响,是语音增强技术的目标.语音增强技术在自动语音识别、电话通信等领域有着广泛的应用,近年来,该技术也受到了学者的关注.在真实噪声环境中,带噪语音的背景噪声往往十分复杂,传统的语音增强方式无法很好地适应各类噪声场景.针对复杂的非线性问题,基于深度学习的语音增强方法具有很强的适应能力.然而,对于真实噪声环境,模型的增强性能往往因为泛化性不足而下降.为了进一步提升语音增强模型在真实噪声环境下的增强性能,提出了一种基于抛物面焦点麦克风预处理和迁移学习的语音增强方法.该方法利用抛物面焦点麦克风采集带噪语音和噪声,通过物理汇聚增强的方式,对带噪语音进行预处理.再利用迁移学习方法,小样本微调训练LSTM-convolutional-BLSTM编解码(LSTM-convolutional-BLSTM encoder-decoder,LCLED)网络的编码器和输出层,冻结解码器,通过算法模型,适应真实噪声环境特性,进一步增强语音.所提出的方法通过物理途径和算法途径两个方面,构建了一整套端到端的语音增强系统,提升了整个系统的语音增强性能,降低了深度神经网络算法模型的复杂度.实验结果表明,所提出的方法可以有效地增强真实噪声环境下的带噪语音.
迁移学习;神经网络;语音增强;真实噪声场景;抛物面焦点麦克风
在语音信号处理系统中,背景噪声会严重影响语音的质量和可懂度.语音增强技术是指从带噪语音中分离出目标语音,是语音信号处理中重要的前端处理模块.对带噪语音的噪声进行抑制并对干净语音进行增强,是语音增强任务的核心目标.同时语音增强技术也具有广泛的应用领域,如助听器的设计、自动语音识别、电话通信等.因此,语音增强技术具有较高的研究价值.
目前,许多语音增强技术已经被提出,包括基于信号处理的方法和基于模型训练的方法.在基于语音信号处理的方法中,谱减法[1]和维纳滤波法[2]是两种经典的语音增强方法.当背景噪声可以被计算估计时,这两种方法表现出较好的增强性能.然而,因为在现实环境中的噪声是更加复杂的、非线性的,所以很难去准确估计预测背景噪声.为解决该问题,近年来深度学习的方法被运用到语音增强任务中.
深度学习方法是典型的基于模型训练的方法,针对复杂的非线性问题,其具有很强的特征建模能力.文献[3]首次提出将深度神经网络(deep neural network,DNN)运用到语音分离任务中,将DNN视为二值分类器去预测理想二值掩蔽(ideal binary mask,IBM)目标.文献[4]中提出了理想比值掩蔽(ideal ratio mask,IRM)目标,并且取得了更好的语音质量.文献[5]提出基于受限玻耳兹曼机(restricted Boltzmann machine,RBM)预训练的DNN模型,预测干净语音的对数功率谱(log power spectra,LPS)特征,该方法通过混合语音的对数功率谱特征去映射(mapping)干净语音的对数功率谱特征.除此之外,卷积神经网络(convolutional neural network,CNN)也是一种典型的深度学习网络结构,其在计算机视觉领域的应用取得了较大的成果,包括目标检测、乐谱识别[6]等场景.最近,CNN结构也被运用到了语音增强任务中.文献[7]中提出了基于全卷积神经网络(fully convolutional neural network,FCN)和复数谱的语音增强,其中,FCN由一维(1-D)卷积和二维(2-D)卷积构成,二维卷积采用了空洞卷积来增大接受域.文献[8]中提出了基于最大输出卷积神经网络(convolu-tional maxout neural network,CMNN)的IRM目标估计,结果表明,CMNN取得了比DNN更高的语音质量感知评价(perceptual evaluation of speech quality,PESQ)指标.另外一些研究中[9-10]同样也提出了基于卷积神经网络结构的语音增强,均取得了优于DNN结构的增强性能.在上述提到的卷积神经网络结构中,通常使用2-D卷积或1-D卷积来提取输入特征的频率维度信息,并使用1-D卷积提取输入特征的时间维度信息(上下文信息);但是,卷积结构往往会分离语音的上下文信息,这会丢失部分语音的时间维度信息.
为了更好地提取语音的上下文信息,长短时记忆网络(LSTM)作为典型的循环神经网络(recurrent neural network,RNN)被运用到了语音增强任务中.文献[11]提出了基于LSTM的IRM目标估计来进行语音增强.文献[12]中提出了基于LSTM的多目标联合学习准则框架.文献[13]提出了基于双向LSTM (bi-directional LSTM,BLSTM)的抑制风噪模型.文献[14]提出了基于残差LSTM(residual LSTM,ResLSTM)的声学模型.尽管LSTM在语音增强任务中展现了很好的增强性能,但是,全LSTM神经网络模型的负载消耗(模型空间复杂度)非常大.
作为基于有监督模型训练的语音增强方法,除了神经网络模型本身结构的差异,选择一个合适的训练目标对模型的训练和泛化性有重要意义.最近许多研究采用以IRM[15]为训练目标,或直接采用以语音的功率谱或幅值谱为映射目标.2019年,Nicolson 等[16]证明基于ResBLSTM估计先验信噪比(a priori SNR)的最小均方误差(minimum mean-square error,MMSE)的语音增强方法,相比最近提出的基于深度学习的掩蔽目标估计和映射目标估计,可以获得更好的语音质量和可懂度,除此之外,文中也证明了在基于ResBLSTM神经网络训练下,先验信噪比的训练目标比IRM训练目标可以获得更好的语音质量.在文献[17]中,笔者提出了一种基于LSTM-convolu-tional-BLSTM编解码(LSTM-convolutional-BLSTM encoder-decoder,LCLED)网络,采用语音的先验信噪比作为训练目标并用最小均方误差做后处理的语音增强方法,实验结果表明,相比于全LSTM结构,提出的LCLED不仅降低了模型复杂度,并且增强后的语音具有更好的语音质量和语音可懂度.
然而,因为神经网络的训练数据规模较小、训练数据泛化性不足等原因,在真实场景下的语音增强性能往往不如人意.文献[18]中提出了一种基于特征注意力多核最大均值差异(feature-attention multi-kernel maximum mean discrepancy,FA-MK-MMD)的迁移学习语音增强方法,提升模型在未标记噪声情况下的泛化性.文献[19]提出了一种引入注意力机制的生成对抗网络(generative adversarial network,GAN)语音增强迁移学习模型,其实验结果表明,对训练集外噪声可以进行有效的降噪.
除此之外,如何高效采集真实场景下的带噪语音也十分重要.在文献[20]中,笔者采用抛物面模型对带噪语音进行采集,其本身对带噪语音已经进行了部分增强.通过抛物面模型预处理模块,在真实环境下可以得到更好的语音增强效果.
为了进一步提升在真实环境下即未标记噪声的语音增强性能,本文提出了一种基于抛物面焦点麦克风模型预处理和迁移学习的语音增强方法.首先,笔者采用抛物面焦点麦克风模型[20],采集真实环境中空调风机的带噪语音和噪声;然后,采用文献[16]中的方法搭建并训练LCLED网络;最后,通过迁移学习方法对该真实场景进行模型微调迁移,获得更好的语音质量.
1 抛物面焦点麦克风模型预处理
在真实环境中,利用深度学习模型去解决语音增强任务,首先要利用某种采集装置对带噪语音进行采集.为了使神经网络的输入语音尽可能不受硬件设备的采集而受损,进一步地还能在采集过程中对语音进行部分增强预处理,本文引入了抛物面焦点麦克风模型,该预处理模块通过抛物线旋转面的几何聚焦原理,利用抛物面能在焦点处放大声压的特性,进行语音信号的预处理.
1.1 抛物面模型原理

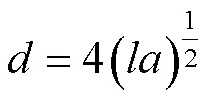
图1 抛物面反射器的侧截面
Fig.1 Sectional view of a parabolic reflector
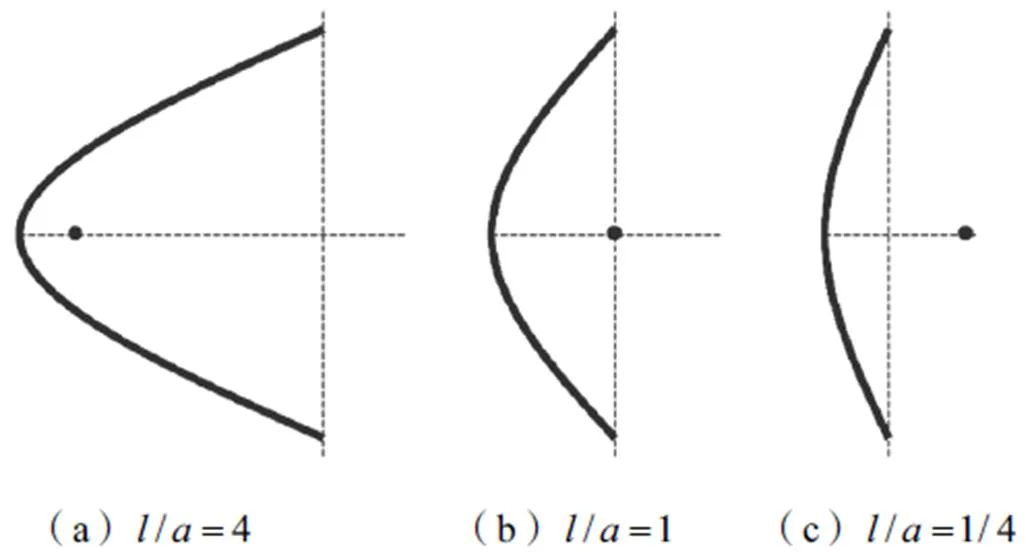
图2 不同下的抛物面反射器示意
1.2 抛物面模型分析和参数设置
根据文献[21]可知,声波沿中轴线进入抛物面时焦点处的放大系数为

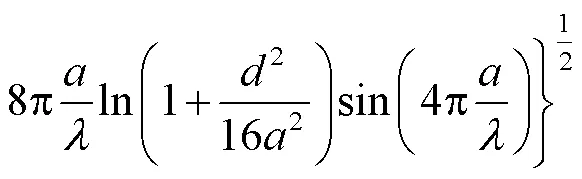
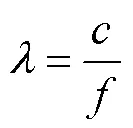

图3 焦点声压放大图
Fig.3 Amplification factor of sound pressure

由以上分析可知,抛物面焦点麦克风模型具有增强语音的效果,但抛物面模型在放大语音的同时也将噪声放大.针对这个问题,笔者利用抛物面焦点麦克风作为前端模块,对语音进行预处理,然后再利用迁移学习算法模型进一步增强语音,从信号采集的物理增强和迁移学习的算法增强两个维度,进一步提升整个语音增强系统的性能.

图4 抛物面反射器实物图
2 LCLED迁移学习模型
迁移学习是指把在先前任务中模型学习到的知识,迁移应用到新的任务中.迁移学习从一个或多个源任务中提取经验,并把学习经验应用到目标任务中.目前,迁移学习在数据挖掘、机器学习、深度学习等领域均有应用[22].本文采用基于LCLED迁移学习的语音增强算法,进一步提高语音增强系统的整体 性能.
2.1 语音特征和训练目标
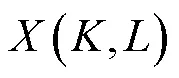
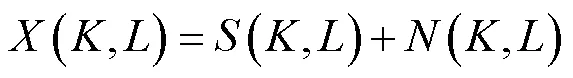
文献[16]中提出把语音信号先验信噪比的累积分布函数作为训练目标,并用MMSE-LSA估计器做后处理,可以获得更高的语音质量.需要注意的是,计算先验信噪比的方法已被改变[23].笔者在文献[17]中给出了详细的计算方式.将经过深度神经网络模型预测的语音先验信噪比与MMSE-LSA增益函数相乘可以得到增强后语音的对数功率谱.
2.2 基于LCLED迁移学习模型的语音增强
LSTM-convolutional-BLSTM编解码(LSTM-convolutional-BLSTM encoder-decoder,LCLED)网络利用LSTM部分提取语音信号的时域信息(上下文信息),利用CNN部分提取语音信号的频域信息.LCLED由两大模块组成,编码模块通过LSTM对输入特征的时域信息进行学习,利用反卷积层将频域信息编码为更高的维度和更大的面积;解码模块利用卷积层和BLSTM对编码后的信息进行解码.其中跳跃连接(skip connection)用来解决随着网络深度加深、导致较浅层特征信息丢失的问题.除此之外,模型利用eLU激活单元代替常见ReLU激活单元,以适应具有负数部分的对数功率谱特征[17].如图5所示,本文对训练好的LCLED的解码部分进行冻结,利用真实风机噪声场景下的噪声进行小样本训练,微调模型的编码部分.
图6为基于抛物面模型预处理和迁移学习的语音增强系统.在第1阶段使用TIMIT和NOISEX-92数据集对模型进行训练;在迁移训练阶段利用采集到的噪声以及干净语音对模型进行微调,得到最终的LCLED模型;在增强阶段,利用抛物面焦点麦克风模型采集并预处理带噪语音,利用LCLED迁移学习模型和MMSE-LSA估计器增强语音.
本文在迁移学习阶段对LCLED模型的编码器和输出层进行训练微调,针对真实环境下的噪声场景进行适应,使系统获得更好的语音增强效果.同时,编码器的训练参数也远远小于解码器的训练参数,在小样本的条件下,更适合于迁移学习模型.

图5 基于LCLED的迁移学习模型
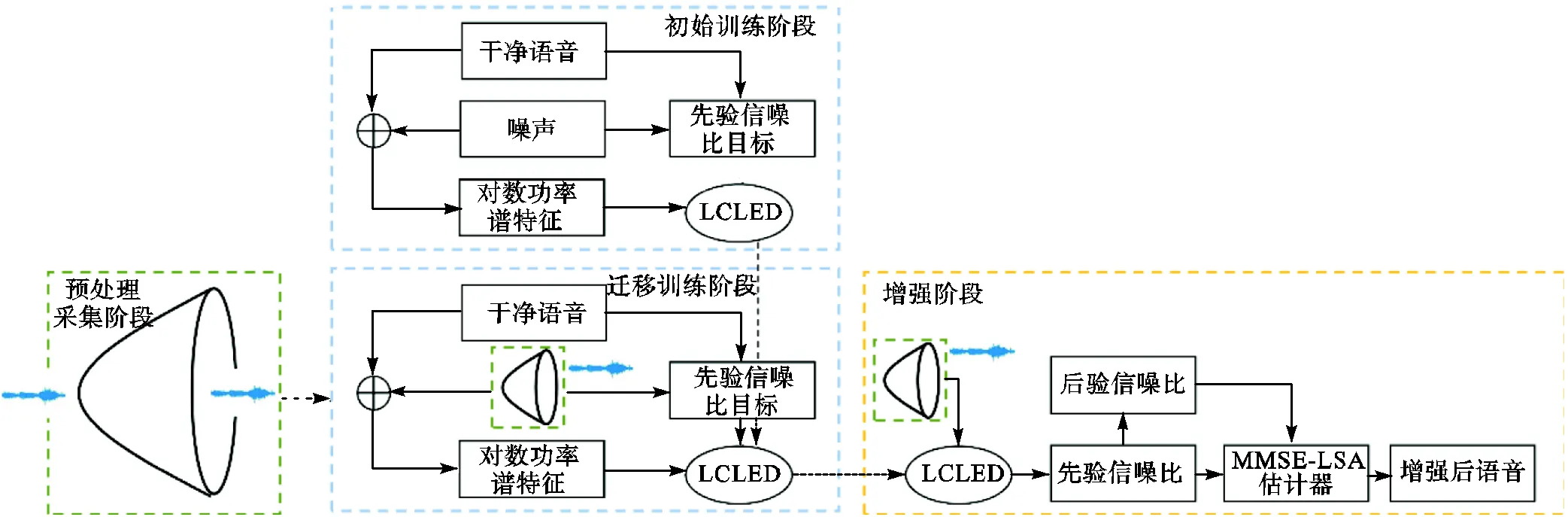
图6 基于抛物面焦点麦克风预处理和迁移学习的语音增强系统框图
3 实验与结果
本文设计了一系列实验来评价语音增强系统的性能.首先介绍了数据的处理方法和训练超参数;接着对模型的性能进行了评价,包括语音质量、模型复杂度和语谱图的直观对比.
3.1 数据准备和训练超参数
1) 初始训练阶段
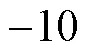
2) 迁移训练阶段
在迁移训练阶段,训练集的纯净语音选自TIMIT语音库训练集中的500段语音,噪声利用抛物面焦点麦克风模型进行现场真实采集.本文中,干净语音被重采样为16Hz,噪声的采样频率为16Hz,混合带噪语音的方式与初始训练阶段相同.在语音的预处理阶段,以32ms进行分帧,帧移为16ms,并对其利用汉明窗函数进行加窗处理.
微调训练采用交叉熵损失函数和Adam优化器,批大小设置为32,训练25代.学习率每10代乘0.1动态下降.
3) 增强阶段
在增强阶段,本文利用抛物面焦点麦克风模型,在距离噪声源(空调鼓风机)和干净语音1.5m处现场采集100段带噪语音,然后利用迁移学习模型增强语音.
3.2 实验结果和分析
语音质量感知评价(perceptual evaluation of speech quality,PESQ)是广泛使用的客观评价方法,可以评估增强语音的整体质量,其得分位于-0.5~4.5之间,得分越高表示语音质量越好[24-25].文献[16]中验证了基于先验信噪比目标的语音增强算法可以获得更高PESQ分数.文献[16]中的实验结果也表明,增强后语音的PESQ分数有更明显的提升.除此之外,相比于仿真情况下,利用已知信噪比混合语音和噪声进行测试,本文直接采集真实环境下的带噪语音进行测试,带噪语音的信噪比是未知的.故本文采用PESQ分数和信噪比作为评价增强后语音质量好坏的指标.实验结果如表1所示,训练好的LCLED模型在真实环境下即未标记噪声的场景中,也可以取得较好的增强性能,增强后语音PESQ分数提高24%;经过迁移学习模型微调增强后,PESQ分数进一步提升接近5%.而信噪比的提升则更加明显.

表1 不同模型下PESQ分数比较
为了进一步分析本文提出的语音增强系统,对100段语音增强前与增强后的PESQ分数和信噪比进行比较.如图7所示,相比直接用抛物面焦点麦克风模型采集并物理预处理增强的方式,迁移学习模型能进一步对采集的语音进行算法角度的增强,尤其在采集语音质量很低的情况下.图中在采集语音质量较高的情况下出现了经过迁移学习模型增强后PESQ反而降低的情况,是因为神经网络模型在预测干净语音时,会在某些情况下存在对语音破坏的情况,但是,从整体的增强效果来看,增强语音的PESQ分数在大部分情况下得到了提升.由图8可以明显看出,增强后语音的信噪比得到了明显提升.
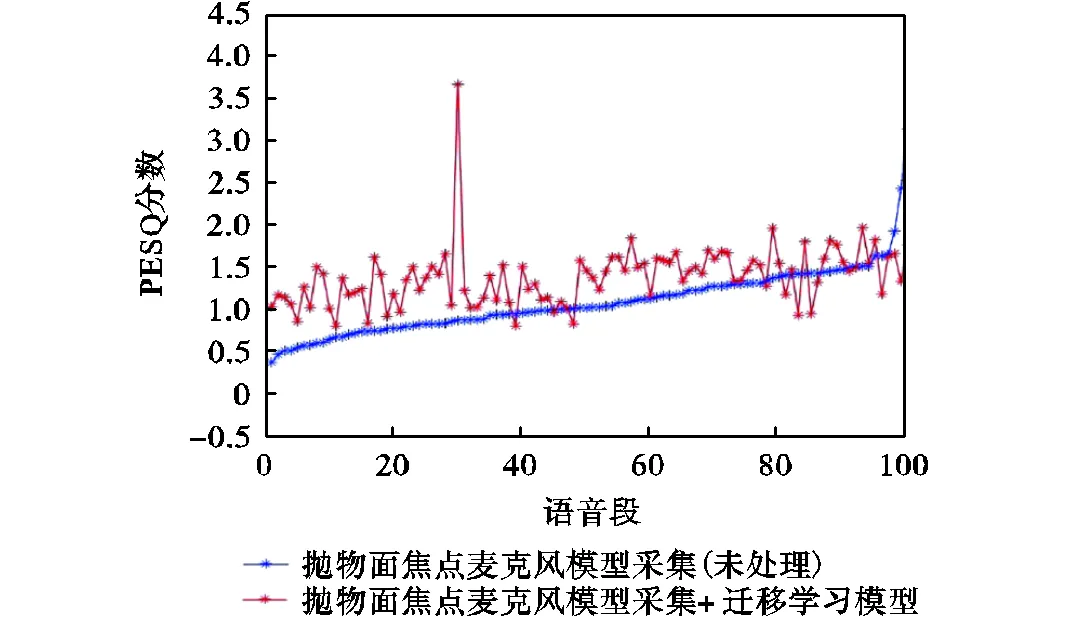
图7 100段语音的PESQ比较

图8 100段语音的信噪比比较
模型复杂度是评价深度神经网络算法的重要一环.模型复杂度可以通过训练参数量和训练时间来进行评价.表2为不同模型下的参数量和运行时间对比,不难看出,迁移学习模型需要微调训练的参数量远远少于整个LCLED模型的参数量.所以,针对真实环境下即未标记噪声的场景中,可以更容易得到对应的语音增强模型.

表2 两个模型的训练参数量和运行时间
语谱图可以直观反映语音增强的效果.本文随机从100段语音中抽取1段作为样本分析.图9和图10为干净语音和带噪语音的时域波形和语谱图,图11和图12分别为两种不同模型增强后的时域波形和语谱图.如图10所示,噪声对低于4000Hz部分的语音造成明显破坏.相比与抛物面焦点麦克风和LCLED模型的语音增强系统(图11),基于抛物面焦点麦克风采集和迁移学习模型的语音增强系统(图12)在中频部分更好地还原了语音细节,在低频部分抑制了噪声.
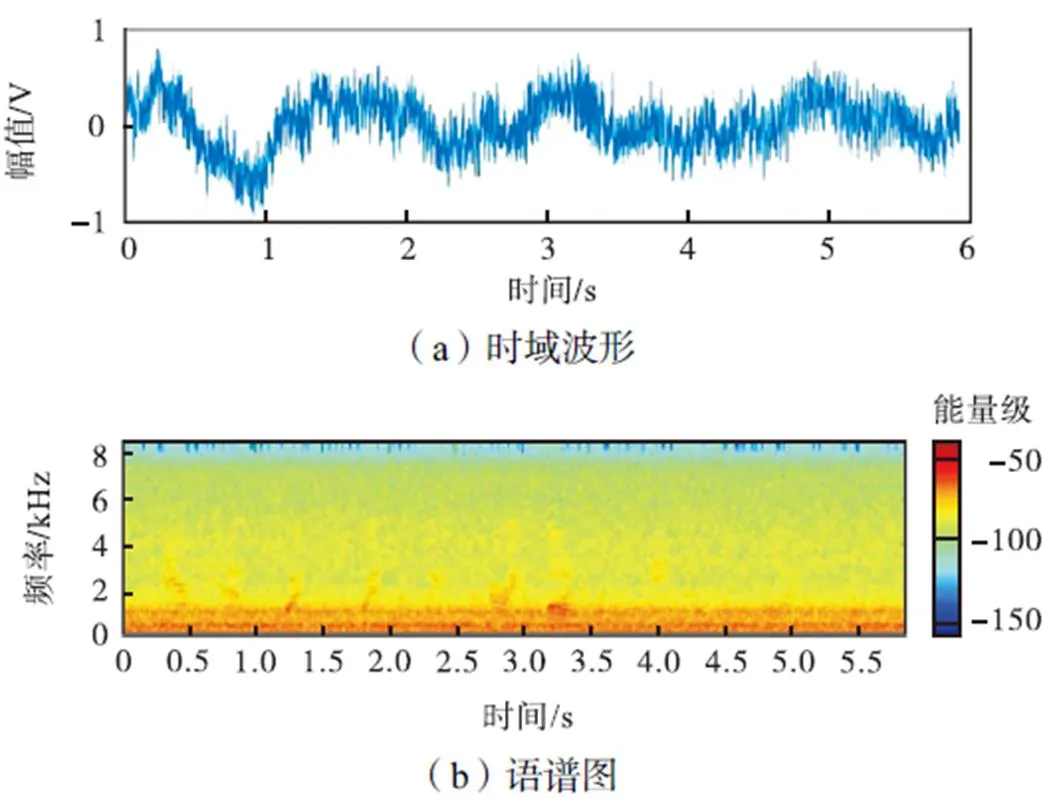
图10 采集带噪语音的时域波形和语谱图
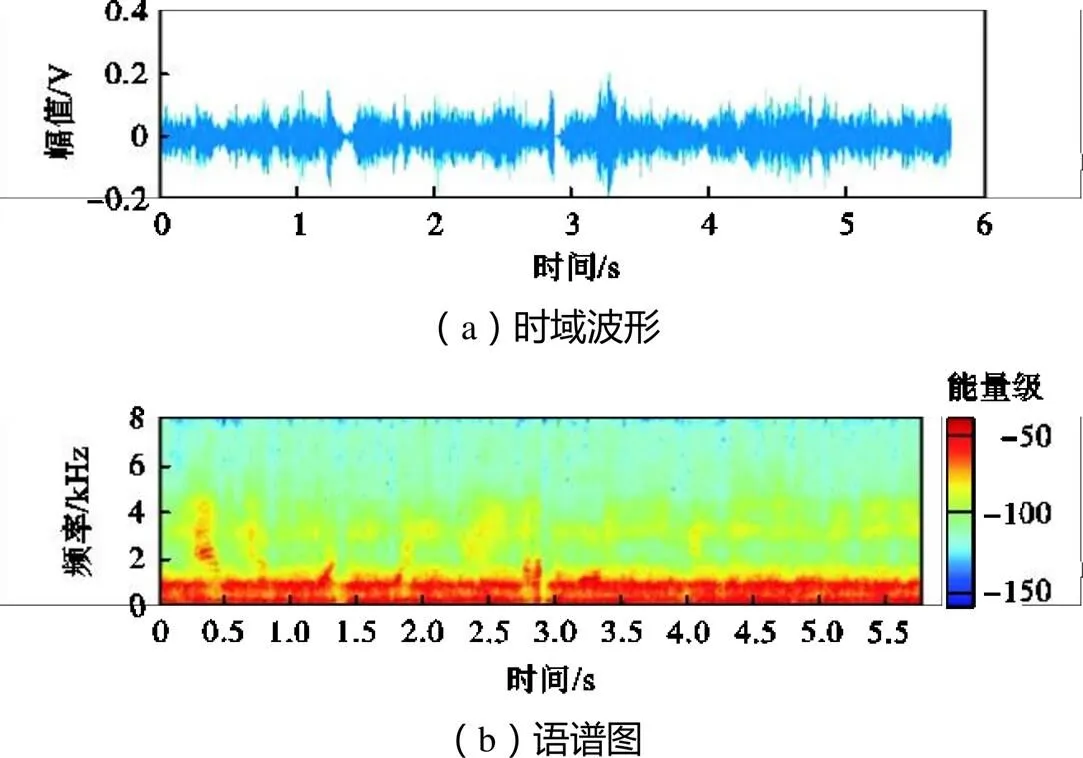
图11 基于抛物面焦点麦克风和LCLED模型增强后语音的时域波形和语谱图
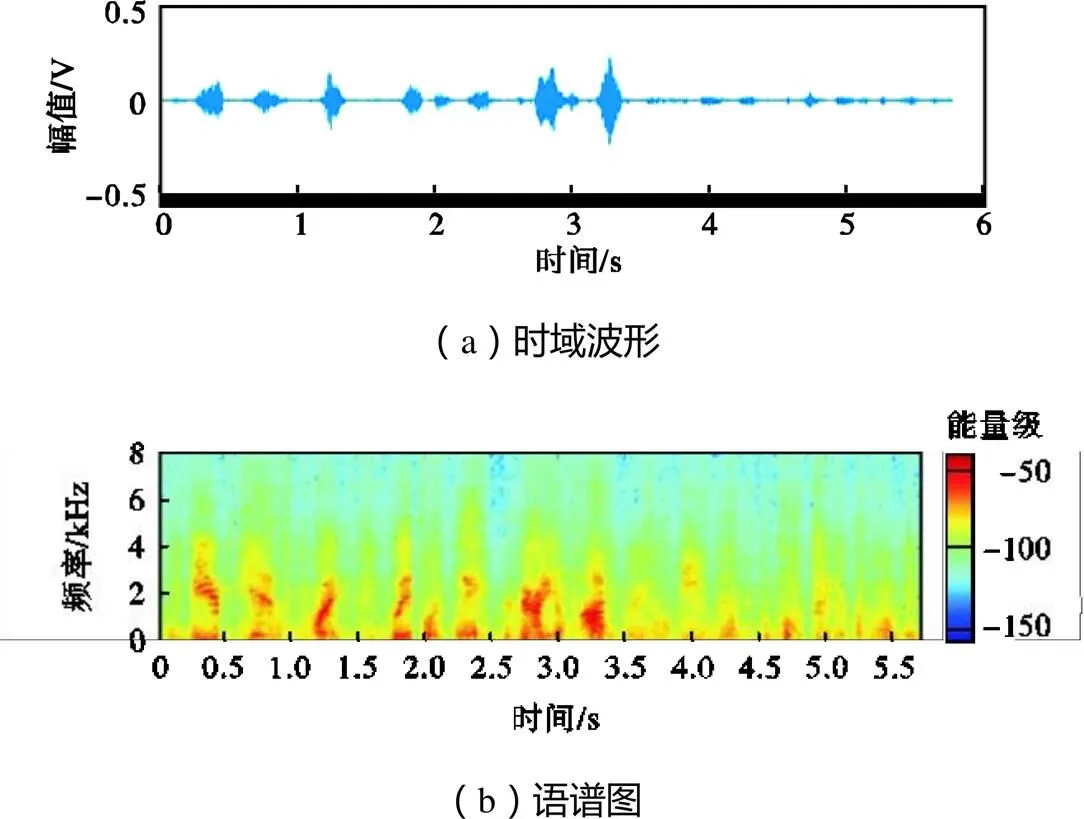
图12 基于抛物面焦点麦克风和迁移学习模型增强后语音的时域波形和语谱图
4 结 语
针对语音增强性能在真实噪声环境中下降的问题,本文提出了一种基于抛物面焦点麦克风预处理和迁移学习的语音增强方法,搭建了一套从语音采集到算法增强的系统.抛物面焦点麦克风模型采集语音,可以在采集的同时对带噪语音做增强预处理.迁移学习方法利用小样本微调训练网络,在真实噪声环境下更容易得到对应的算法模型,且进一步提升了深度神经网络模型的增强性能.实验结果表明,本文提出的语音增强方法可以适应真实噪声环境,有效地增强真实噪声环境下的带噪语音,但本方法对语音质量的提升更加明显,如何在先验信噪比作为训练目标的情况下,进一步提升语音可懂度,这也是下一步研究重点要解决的问题.
[1] Boll S F. Suppression of acoustic noise in speech using spectral subtraction[J]. IEEE Transactions on Acous-tics,Speech,and Signal Processing,1979,27(2):113-120.
[2] Loizou P C. Speech Enhancement:Theory and Prac-tice[M]. Boca Raton:CRC Press,2013.
[3] Wang Yuxuan,Wang Deliang. Towards scaling up classification-based speech separation[J]. IEEE Transac-tions on Audio,Speech,and Language Processing,2013,21(7):1381-1390.
[4] Wang Yuxuan,Narayanan A,Wang Deliang. On train-ing targets for supervised speech separation[J]. IEEE/ACM Transactions on Audio,Speech,and Lan-guage Processing,2014,22(12):1849-1858.
[5] Xu Yong,Du Jun,Dai Lirong,et al. An experimental study on speech enhancement based on deep neural networks[J]. IEEE Signal Processing Letters,2014,21(1):65-68.
[6] 黄志清,贾 翔,郭一帆,等. 基于深度学习的端到端乐谱音符识别[J]. 天津大学学报(自然科学与工程技术版),2020,53(6):653-660.
Huang Zhiqing,Jia Xiang,Guo Yifan,et al. End-to-end music note recognition based on deep learning[J]. Journal of Tianjin University(Science and Technol-ogy),2020,53(6):653-660(in Chinese).
[7] Ouyang Zhiheng,Yu Hongjiang,Zhu Weiping,et al. A fully convolutional neural network for complex spec-trogram processing in speech enhancement[C]// IEEE International Conference on Acoustics,Speech and Sig-nal Processing(ICASSP). Brighton,UK,2019:5756-5760.
[8] Hui Like,Cai Meng,Guo Cong,et al. Convolutional maxout neural networks for speech separation[C]// IEEE International Symposium on Signal Processing and Information Technology(ISSPIT). Abu Dhabi,UAE,2015:24-27.
[9] Kounovsky T,Malek J. Single channel speech enhancement using convolutional neural network[C]// IEEE International Workshop of Electronics,Control,Measurement,Signals and their Application to Mecha-tronics(ECMSM). Donostia,Spain,2017:1-5.
[10] Chandna P,Miron M,Janer J,et al. Monoaural audio source separation using deep convolutional neural networks[C]//13th International Conference on Latent Variable Analysis and Signal Separation(LVA/ICA). Grenoble,France,2017:258-266.
[11] Chen Jitong,Wang Deliang. Long short-term memory for speaker generalization in supervised speech separa-tion[J]. The Journal of the Acoustical Society of America,2017,141(6):4705-4714.
[12] Sun Lei,Du Jun,Dai Lirong,et al. Multiple-target deep learning for LSTM-RNN based speech enhancement [C]//Hands-free Speech Communications and Micro-phone Arrays(HSCMA). San Francisco,USA,2017:136-140.
[13] Lee J,Kim K,Shabestary T,et al. Deep bi-directional long short-term memory based speech enhancement for wind noise reduction[C]// Handsfree Speech Communi-cations and Microphone Arrays(HSCMA). San Fran-cisco,USA,2017:41-45.
[14] Kim J,EL-Khamy M,Lee J. Residual LSTM:Design of a deep recurrent architecture for distant speech recognition[C]//Annual Conference of the International Speech Communication Association. Stockholm,Swe-den,2017:1591-1595.
[15] Luo Yi,Mesgarani N. TaSNet:Time-domain audio separation network for real-time,single-channel speech separation[C]//IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP). Calgary,Canada,2018:696-700.
[16] Nicolson A,Paliwal K K. Deep learning for minimum mean-square error approaches to speech enhancement[J]. Speech Communication,2019,111:44-45.
[17] Wang Zeyu,Zhang Tao,Shao Yangyang,et al. LSTM-convolutional-BLSTM encoder-decoder network for minimum mean-square error approach to speech enhancement[J]. Applied Acoustics,2021,172:107647.
[18] Liang Ruiyu,Liang Zhenlin,Cheng Jiaming,et al. Transfer learning algorithm for enhancing the unlabeled speech[J]. IEEE Access,2020,8:13833-13844.
[19] 曹中辉,黄志华,葛文萍,等. 注意力机制对生成对抗网络语音增强迁移学习模型的影响[J]. 声学技术,2021,40(1):77-81.
Cao Zhonghui,Huang Zhihua,Ge Wenping,et al. In-fluence of attention mechanism on generative adversarial network speech enhancement transfer learning model[J]. Technical Acoustics,2021,40(1):77-81 (in Chi-nese).
[20] Zhang Tao,Geng Yanzhang,Sun Jianhong,et al. A unified speech enhancement system based on neural beamforming with parabolic reflector[J]. Applied Sci-ence,2020,10(7):1-13.
[21] Sten Wahlstrom. The parabolic reflector as an acoustical amplifier[J]. Journal of the Audio Engineering Society,1985,33(6):418-429.
[22] Pan S J,Yang Qiang. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering,2010,22(10):1345-1359.
[23] Plapous C,Marro C,Scalart P. Improved signal-to-noise ratio estimation for speech enhancement[J]. IEEE Transactions on Audio,Speech,and Language Processing,2006,14(6):2098-2108.
[24] ITU-T,Rec.P.862. Perceptual Evaluation of Speech Quality(PESQ). An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs[S]. International Telecommunication Union-Telecommunication Standardiza-tion Sector,2001.
[25] 张卫强,张 乔,Johnson Michael T,等. 一种基于计算听觉场景分析的语音增强算法[J]. 天津大学学报(自然科学与工程技术版),2015,48(8):663-669.
Zhang Weiqiang,Zhang Qiao,Johnson Michael T,et al. A speech enhancement algorithm based on computational auditory scene analysis[J]. Journal of Tianjin University(Science and Technology),2015,48(8):663-669(in Chinese).
A Speech Enhancement Method Based on a Parabolic Center-Microphone Preprocessing and Transfer Learning
Zhang Tao1,Wang Zeyu2,Hu Mengxue2,Zhao Xin1,Liu Ganjun1,Geng Yanzhang1
(1. School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China;2. Tianjin International Engineering Institute,Tianjin University,Tianjin 300072,China)
Background noise damages the quality and intelligibility of speech. The goal of speech enhancement is to separate the target speech from noisy speech,reducing the influence of background noise on the target speech. Speech enhancement has a wide range of applications,such as automatic speech recognition and telecommunication. It attracts frequent attention from scholars.In a real noise environment,the background noise of speech is complex. The traditional speech enhancement method cannot adapt well to all types of noise scenes. A deep learning model improves the enhanced performance because of its excellent abstracting ability. However,the enhanced performance will be degraded because of the generalization in a real noise environment. To improve the enhanced performance in this environment,we proposed a speech enhancement method based on a parabolic reflector center-microphone and transfer learning. The key idea was to use a parabolic reflector center-microphone to collect noisy speech and noise,and the speech was preprocessed by a parabolic reflector. Furthermore,to improve the generalization of the model,the transfer learning method was applied to train the LSTM-convolutional-BLSTM encoder decoder neural network with few samples. The proposed method builds a speech enhancement system through equipment and an algorithm. The enhanced performance of the system is improved,and the model complexity is reduced. The results indicate that the proposed approach improves the quality of enhanced speech in a real noise environment.
transfer learning;neural network;speech enhancement;real noise environment;parabolic center-microphone
TK448.21
A
0493-2137(2022)10-1053-08
10.11784/tdxbz202107021
2021-07-11;
2021-12-07.
张 涛(1975— ),男,博士,副教授,zhangtao@tju.edu.cn.
耿彦章,824803007@qq.com.
国家自然科学基金资助项目(62001323);天津市研究生科研创新项目(人工智能专项)资助项目(2020YJSZXB10).
the National Natural Science Foundation of China(No. 62001323),the Research and Innovation Project for Postgraduates in Tianjin(Artificial Intelligence)(No. 2020YJSZXB10).
(责任编辑:孙立华)
