基于数据驱动的地下车站能耗预测模型对比研究
2022-06-28苏子怡李晓锋
王 岩,苏子怡,李晓锋,王 斌
(1. 无锡地铁集团有限公司,江苏无锡 214000;2. 清华大学建筑学院,北京 100084)
1 研究背景
“十三五”期间,城市轨道交通累计新增运营线路4 351.7 km,年均增长率17.1%,创历史新高。截至2020 年底,中国大陆地区共有45 座城市开通城市轨道交通线路244 条,运营总长达7 969.7 km,其中地铁占比78.8%。2020 年,城轨交通总用电量172.4 亿kW·h,其中车站能耗88.4 亿kW·h,随着新建线路的增加,能耗持续增长[1]。
当前地铁车站的运行存在巨大的节能潜力。常用的反馈控制软件自适应力不强,无法及时应对地铁环境的复杂变化,主要存在的问题包括车站公共区温度控制振荡严重、无法及时应对活塞风效应导致的环境变化等,导致能源浪费[2]。因此,有必要研究地铁车站能耗预测模型,准确预测用能负荷,这对于指导车站设备选型和节能运行具有至关重要的意义。
数据驱动算法是建筑能耗预测的常用方法,多种大数据技术被广泛应用于各类型建筑不同时间尺度的能耗预测中[3-5]。赵海湉等探究了室内环境、室外环境、在室人员数量等使用需求参数对建筑大数据能耗预测的影响[6];Kim 等对比了线性回归、随机森林、决策树回归、卷积神经网络等算法在住宅用电量预测中的表现[7];何明秀以上海市多栋公共建筑为例,对比了支持向量机、随机森林等多种方法的能耗预测效果[8];孙劭波研究了政府办公建筑能耗的大数据预测算法[9];韩连华基于逐步回归和决策树方法,建立了建筑能耗预测和基准评价集成模型[10]。上述研究表明,数据驱动算法在建筑能耗预测领域应用广泛,但缺乏针对地铁车站建筑能耗预测的数据驱动算法研究。
本研究以地下2 层标准车站为例,建立了基于数据驱动的通风空调、垂直交通和照明系统能耗的预测模型,对比了多种常用的大数据技术,包括最小二乘多元线性回归(LR)、岭回归(Ridge)、Lasso 回归、随机森林(RF)、XGBoost,从预测精度、计算成本的角度分析了各算法的优缺点,为地下车站能耗的预测提供了数据驱动算法参考。
2 能耗预测模型
2.1 车站用能系统
本研究的对象为地下2 层的非换乘、屏蔽门系统车站,冷源为变频螺杆冷水机组。
地铁车站的主要用能系统包括通风空调系统(约占55%)、垂直交通系统(约占15%)和照明系统(约占22%)[11]。其中,照明系统形式相对简单、能耗易算,本研究推荐采用基于运行原理的模型进行计算。该模型采用车站照明功率密度、照明面积、照明时长进行计算,预测模型的均方根误差的变异系数CV-RMSE为2.9%[12]。而车站通风空调、垂直交通系统能耗的影响因素复杂,所以笔者对其进行重点研究,对比常用的数据驱动模型,对其能耗进行预测研究。
2.2 输入参数选择
已有研究通过敏感性分析指出,地下车站通风空调系统能耗的关键影响因素包括室内外环境、机械新风量、设备能效、无组织渗风量、客流量等相关的14个参数,垂直交通系统能耗的关键影响因素包括发车对数、客流量、设备功率、设备数量等相关的13 个输入参数,如表1 所示[13]。本研究建立的数据驱动模型,以各系统能耗的关键影响因素作为输入参数。

表1 车站能耗模型关键影响因素 Table 1 Key inputs of energy models for underground stations
2.3 数据驱动模型
笔者选择了最小二乘回归、岭回归、Lasso 回归、随机森林、XGBoost 模型,对比各模型在地下车站能耗预测上的效果。采用的数据库为车站分项能耗原理模型模拟得到的10 000 条数据,预测步长为1 h。
2.3.1 多元线性回归
多元线性回归模型Y 考虑了输入参数的交互作用项,即Xi包括N 个关键影响因素及其两两乘积,有

2.3.2 岭回归
岭回归是一种替代最小二乘的压缩估计拟合方法,通过正则化减少方差,能够将系数往零的方向进行压缩,在多元回归模型中实现变量重要性的筛选。岭回归的系数估计值通过最小化式(3)得到
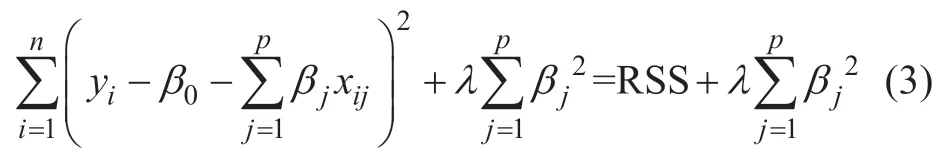
式中,λ≥0 是调节参数,选择合适的λ 对模型十分重要,可用交叉验证进行参数寻优。
2.3.3 Lasso 回归
Lasso 回归也是通过正则化减少方差,与岭回归的差异在于Lasso 可以将系数压缩至零,能够实现变量的筛选,得到输入参数较少的稀疏模型。Lasso 回归的系数估计值通过最小化式(4)得到
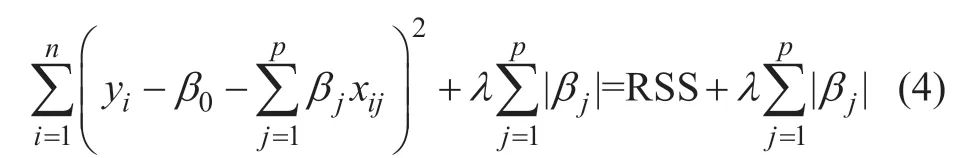
式中,λ≥0 是调节参数,选择合适的λ 对模型十分重要,可用交叉验证进行参数寻优。
2.3.4 随机森林
随机森林是一种常用的以决策树为基础的分析方法,随机采样有放回的抽取k 个样本并进行N次采样生成的N 个训练集,用训练集拟合模型并求得预测值。每考虑树上的一个分裂点,都要从全部预测变量中选出一个包含部分预测变量的随机样本作为候选变量,这个分裂点所用的预测变量只能从候选变量中选择,在每个分裂点处都重新抽样。最后,对所有预测值求平均,得到模型。随机森林方法由于在训练过程中引入了随机性,所以能够避免过拟合,且能够处理高维数据,训练速度快。
对随机森林模型预测效果影响显著的参数需要进行调优,利用Python 的RandomForestRegressor 和GridSearchCV 函数进行模型参数的调优,包含的参数如表2 所示。

表2 各算法的最优的参数估计 Table 2 Results of k-fold cross-validation
2.3.5 XGBoost
XGBoost 是一种改进的决策树方法:每训练一个决策树模型,都会按照偏差来调整样本的权重,通过不断学习前一个决策树的偏差,最终得到预测模型。利用Python 的XGBRegressor 和GridSearchCV 函数进行参数调优,包含的参数如表2 所示。
2.4 模型训练及评价
将原始数据集拆分为训练集、验证集和测试集。
在训练集和验证集上,采用网格搜寻算法和k 折交叉验证对模型进行训练,得到模型最优的参数估计。网格搜寻算法通过遍历给定的参数组合来搜寻模型最优的参数取值。对于每种参数取值,采用k 折交叉验证对模型的效果进行评分:将样本数据分为k 个子集,每次令一个子集作为验证集,其余k-1 个子集作为训练集;对于每种参数取值,执行k 次模型训练和验证评分,以平均评分作为该参数取值下模型的最终评分(见图1)。通过网格搜寻算法和k 折交叉验证得到模型的最优参数估计,进而在训练集和验证集的全部数据上进行训练,从而得到最优模型。
在测试集上评价模型表现。采用均方根误差(RMSE)和均方根误差的变异系数(CV-RMSE),作为模型预测效果的评价指标。RMSE 能够综合衡量预测值与实际值之间的偏差[14],CV-RMSE 可将预测误差归一化,是便于多个模型比较的无单位度量[15]。
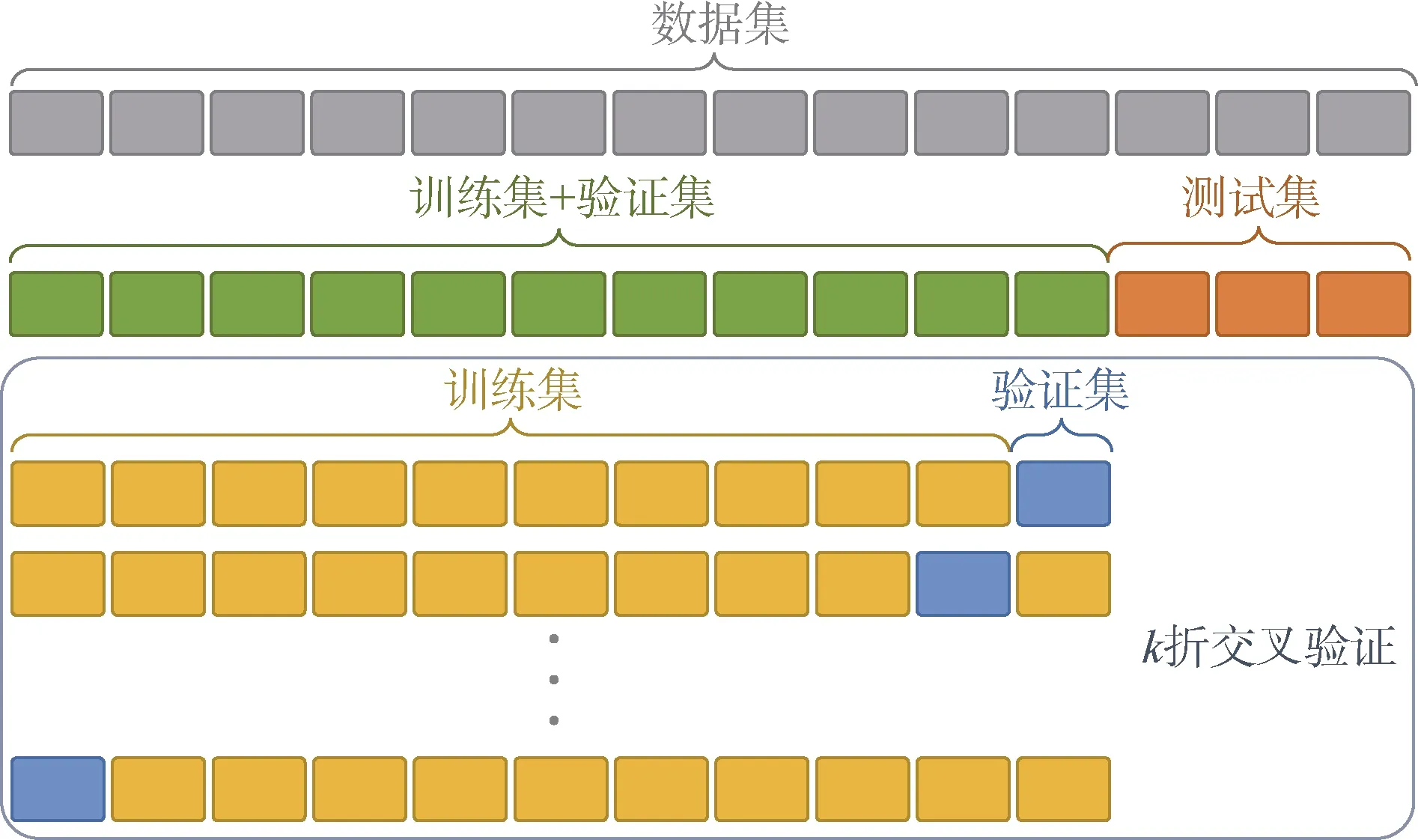
图1 数据集划分及k 折交叉验证示意 Figure 1 Data set and k fold cross-validation
3 模型调节参数
在训练集和验证集上采用网格搜寻法和k 折交叉验证进行参数的优化,得到每种算法的最优的参数估计,如表2 所示。
4 模型对比分析
4.1 预测精度
4.1.1 车站通风空调系统
分别采用最小二乘回归、岭回归、Lasso 回归、随机森林、XGBoost 算法,建立地下车站通风空调系统能耗模型,将其预测值与测试集的实际值进行对比,如图2 所示。可以发现,在全部模型中,XGBoost 模型在测试集上的能耗预测值更接近实际值,预测效果最好。
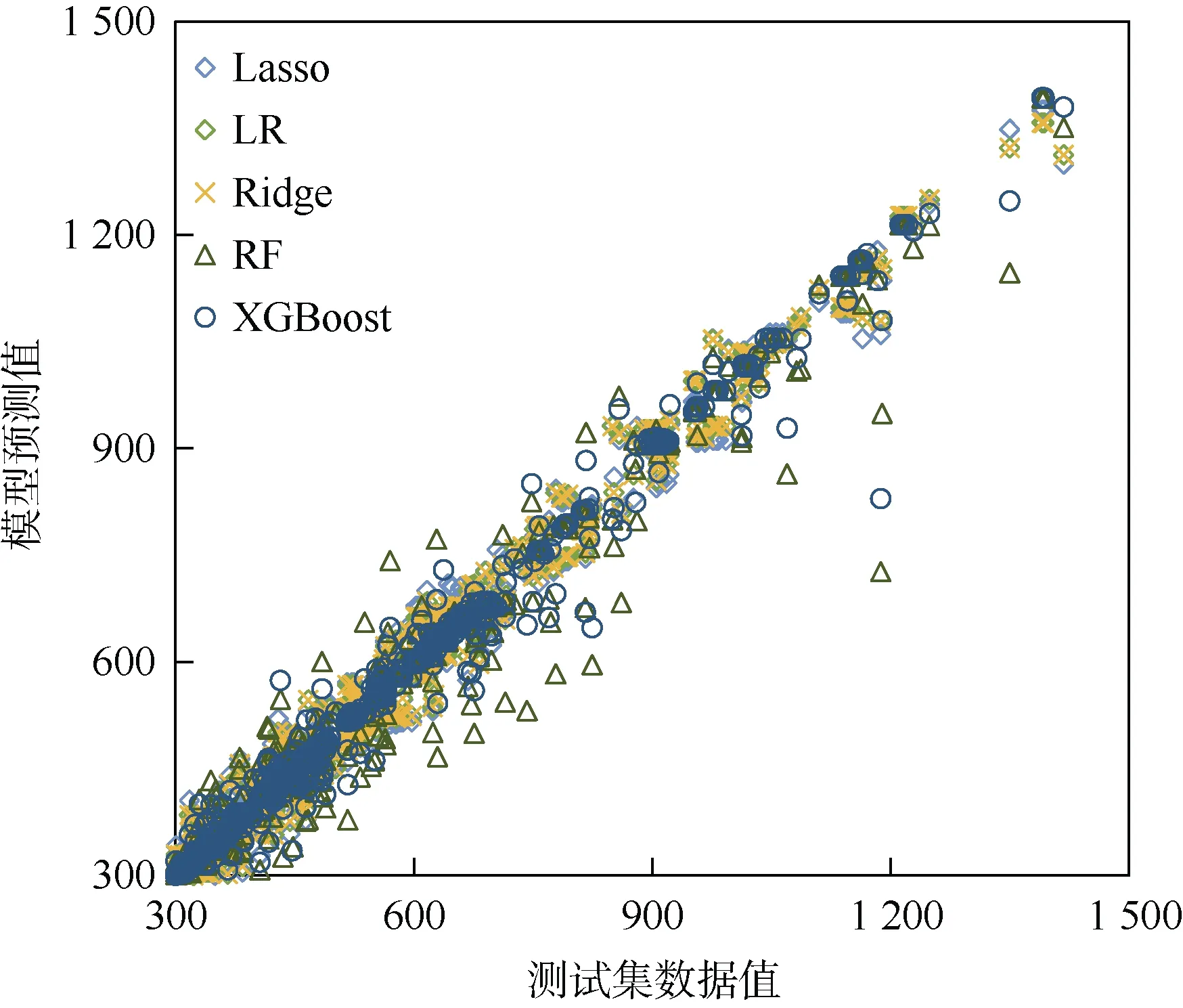
图2 通风空调模型预测效果对比 Figure 2 Comparison on the prediction performance of VAC models
统计各算法在通风空调能耗数据测试集上的预测值与实际值,给出了各算法能耗预测效果的评价指标(见表3 和图3)。可以看出,各算法的均方根误差变异系数在5.1%~8.5%之间,均可达到工程应用的精度要求。其中,XGBoost 算法在预测精度上优于其他算法,预测值的均方根误差为20.5 kW·h,其他算法预测值的均方根误差在30.3~33.8 kW·h 之间。

表3 各算法通风空调能耗预测效果的评价指标统计 Table 3 Evaluation indices of the VAC energy models
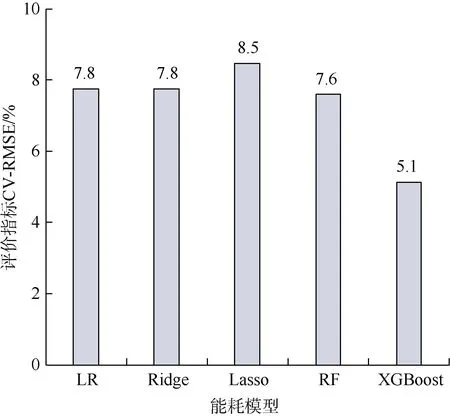
图3 通风空调模型评价指标CV-RMSE Figure 3 CV-RMSE of VAC models
4.1.2 车站垂直交通系统
图4 所示为各算法在垂直交通能耗数据上的预测值与实际值的对比。与通风空调模型类似,XGBoost算法在测试集上的能耗预测值更接近实际值,预测效果最好。
统计各算法在垂直交通能耗数据测试集上的预测值与实际值,模型评价指标如表4 和图5 所示。可以看出,各算法的均方根误差变异系数在5.4%~9.4%之间,均可达到工程应用要求的精度。其中,XGBoost算法在预测精度上明显优于其他算法,预测值的均方根误差仅为1.9 kW·h;其次为随机森林算法,预测值的均方根误差为2.5 kW·h。
4.2 计算成本
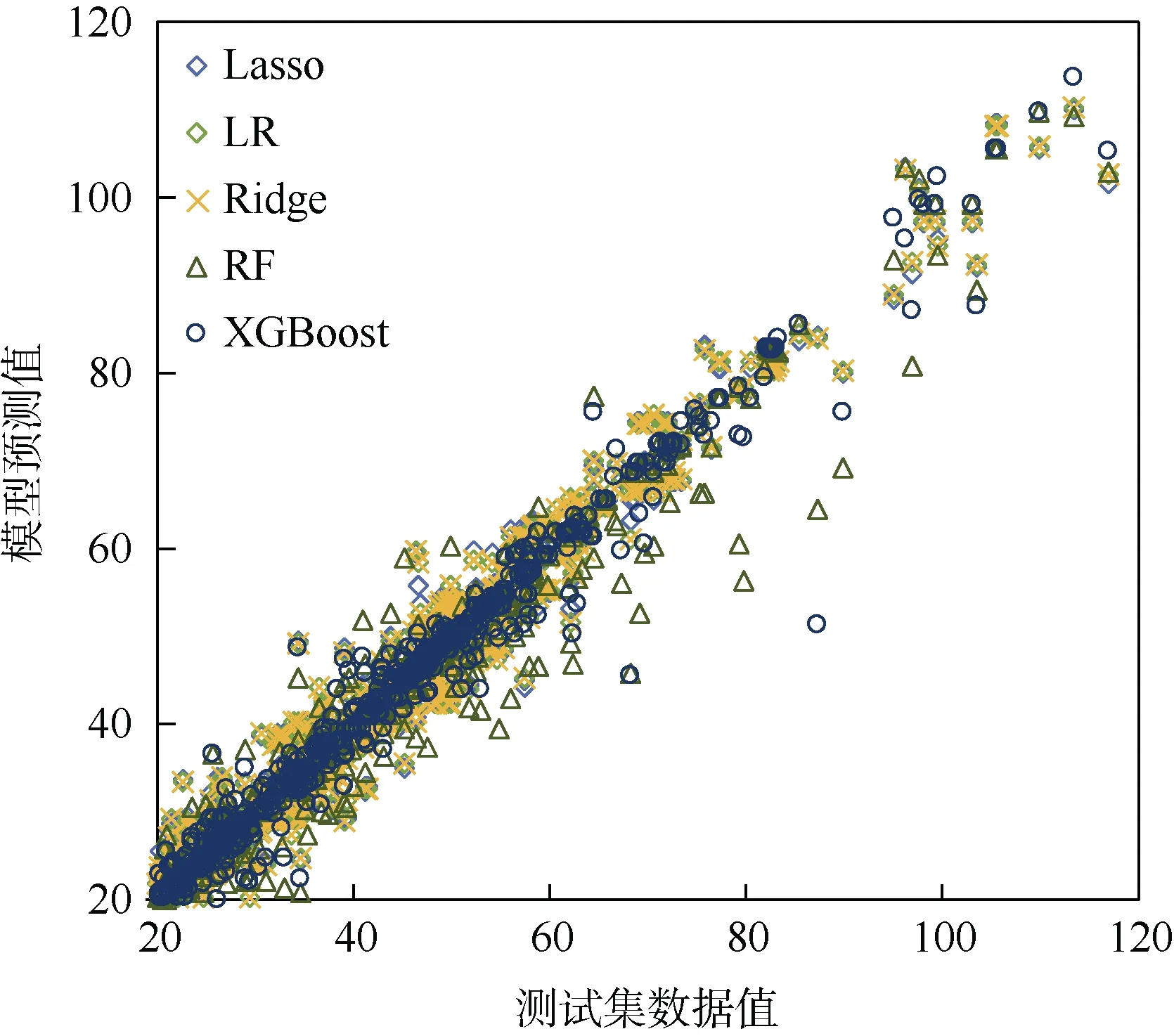
图4 垂直交通模型预测效果的对比 Figure 4 Comparison on the prediction performance of TRANS models
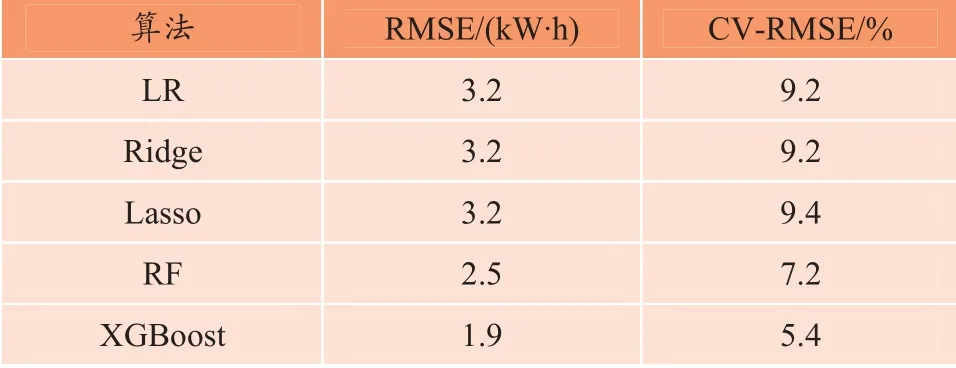
表4 各算法垂直交通能耗预测效果的评价指标统计 Table 4 Evaluation indices of the TRANS energy models
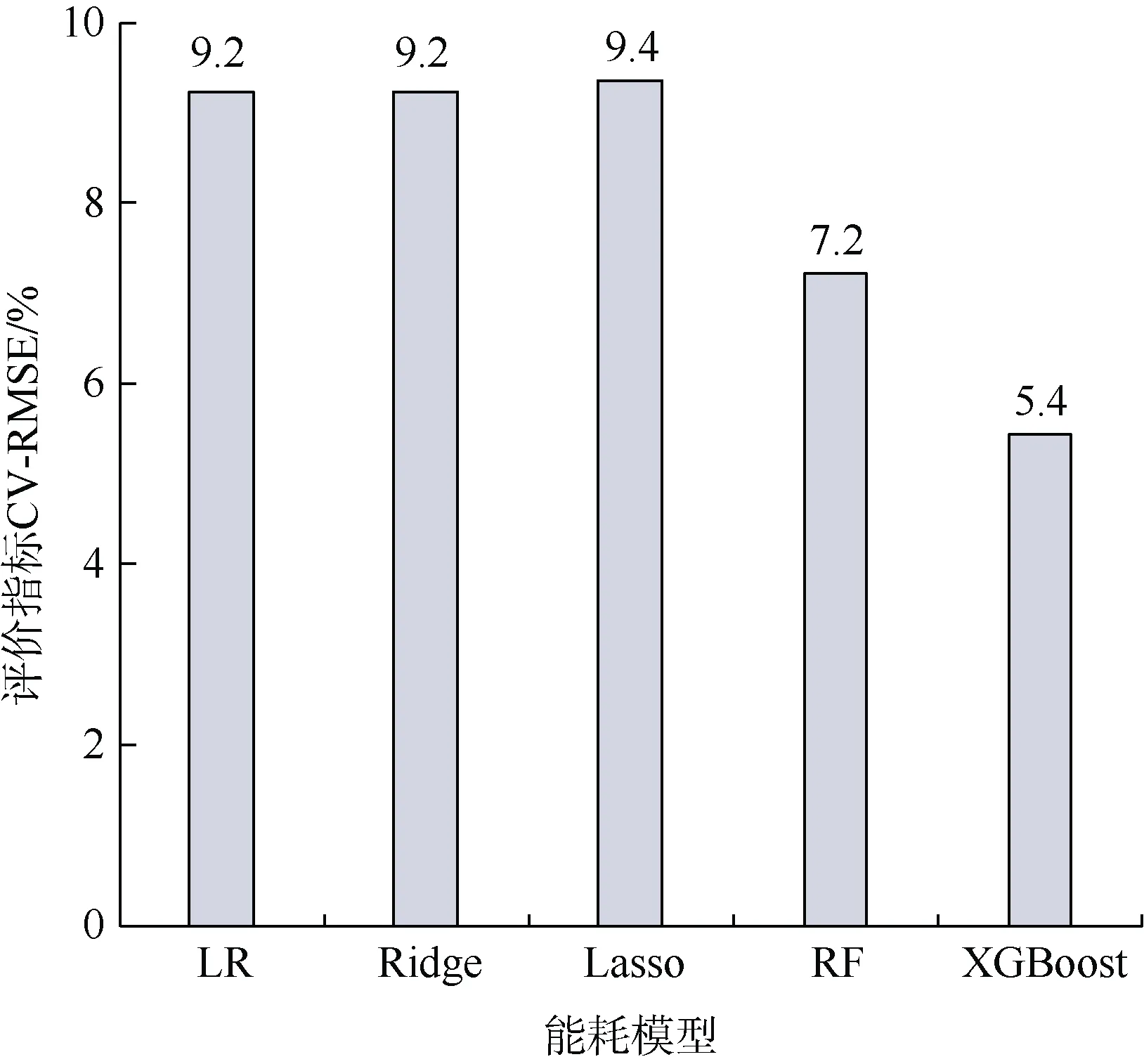
图5 垂直交通模型评价指标CV-RMSE Figure 5 CV-RMSE of TRANS models
对比各算法的模型训练所需的计算时间,结果如图6 所示。最小二乘回归、岭回归、Lasso 回归的模型 调参简单,计算成本较低。随机森林和XGBoost 模型需要调整的参数较多,交叉验证和网格搜寻需要的计算成本远高于其他几种方法,随机森林算法训练模型所需的计算时间约为415 s,而XGBoost 算法训练模型所需的计算时间超过1 000 s。

图6 各算法模型训练的计算成本 Figure 6 Calculation costs of the data-driven methods
5 结语
笔者研究了最小二乘多元线性回归、岭回归、Lasso 回归、随机森林、XGBoost 算法在地下车站通风空调和垂直交通能耗预测中的表现,对比了各算法的预测精度和计算成本。结果显示,对于地下车站通风空调和垂直交通的能耗预测,各算法的CV-RMSE都在10%以下,均可达到工程应用要求的精度。其中,XGBoost 算法在通风空调能耗预测中的CV-RMSE 仅为5.1%,在垂直交通能耗预测中的CV-RMSE 仅为5.4%,预测效果明显优于其他算法。从计算成本来看,最小二乘回归、岭回归、Lasso 回归的计算成本较低,随机森林和XGBoost 模型这两个基于树的非线性模型需要调整的参数较多,交叉验证和网格搜寻需要的计算成本远高于其他几种方法。综合考虑计算成本和预测精度,在工程应用中推荐采用最小二乘多元线性回归(精度可接受,计算成本最低),如对精度有较高要求,推荐采用XGBoost 算法(精度高,计算成本可接受)。
本研究介绍了能耗预测领域常用数据驱动算法的原理及各算法需要寻优的参数。以地下2 层的标准车站为例,对比了多种基于数据驱动算法在通风空调和垂直交通系统能耗预测中的表现,为工程应用中地下车站能耗预测模型的搭建和算法调参提供了方法参考。
