Part Decomposition and Refinement Network for Human Parsing
2022-06-25LuYangZhiweiLiuTianfeiZhouandQingSong
Lu Yang, Zhiwei Liu, Tianfei Zhou, and Qing Song
Dear Editor,
This letter is concerned with human parsing based on part-wise semantic prediction. Human body can be regarded as a whole structure composed of different semantic parts, and the mainstream single human parser uses semantic segmentation pipeline to solve this problem. However, the differences between human parsing and semantic segmentation tasks bring some issues that are inevitable to avoid. In this paper, we propose a novel method called part decomposition and refinement network (PDRNet), which adopt partwise mask prediction other than pixel-wise semantic prediction to tackle human parsing task. Specifically, we decompose the human body into different semantic parts and design a decomposition module to learn the central position of each part. The refinement module is proposed to obtain the mask of each human part by learning convolution kernel and convolved feature. In inference stage, the predicted human part masks are combined into a complete human parsing result. Through the decomposition, refinement and combination of human parts, PDRNet greatly reduces the confusion between the target human and the background human, and also significantly improves the semantic consistency of human part.Extensive experiments show that PDRNet performs favorably against state-of-the-art methods on several human parsing benchmarks,including LIP, CIHP and Pascal-Person-Part.
Introduction: The problem of assigning dense semantic labels to a human image, formally known as human parsing, is of great importance in computer vision as it finds many applications,including clothing retrieval, virtual reality, human-computer interaction [1], [2], etc. Generally speaking, the vast majority of the existing human parsing methods follow two paradigms: bottom-up and top-down. The bottom-up [3], [4] treats human parsing as a finegrained semantic segmentation task, predicting the category of each pixel and grouping it into corresponding instances. The top-down[5]-[10] locates each instance in the image plane, and then segments each human part independently. Therefore, an accurate single human parser is particularly important for the top-down method. The mainstream single human parsers map the human body to the same size feature space [5], [7], [11], and use pixel-wise semantic segmentation pipeline to solve the problem. However, there are great differences between human parsing and semantic segmentation tasks.First of all, in the human parsing, all human bodies except the target human are regarded as the background, while semantic segmentation does not distinguish different human instances, but tends to treat the target human and the background human equally (background confusion errors). Secondly, each human part is an instance with boundary, and we need to assign the same semantic label to the whole part. However, semantic segmentation is a pixel-wise classification, which can not guarantee that all pixels in the one part can be predicted the same category (semantic inconsistency errors).
In this work, we are committed to solving the errors caused by the differences between method and objective in human parsing. We abandon the process of semantic segmentation, learn from the idea of instance segmentation [12]-[14], decompose the human body into different semantic parts, segment each part mask independently, and then combine them into a complete human structure. Specifically, we propose a decomposition module to predict the centers and categories of human parts on the feature map. The decomposition module encodes the position information of human parts into the spatial dimension, and encodes the category information into the channel dimension. Therefore, the prior geometric context of the human body is retained in the feature map, which effectively avoids the confusion between the target human and the background human. In order to obtain the mask of each part, we propose a refinement module. The refinement module consists of two branches, one is used to learn the convolution kernel at the center of each part, the other is used to learn the convolved feature. We use dynamic convolution to generate the mask for each part, which converts the traditional pixel-wise semantic segmentation problem into a more concise binary part-wise mask segmentation. In inference stage, we present a human parsing probability map combination method based on the predicted human part categories and masks. The predicted mask with the highest score of each category is sampled and weighted fusion is carried out according to the quality score [11], and finally combined into a complete human parsing result.
As shown in Figs. 1(a)-1(c), we call the proposed method of decomposition, refinement and combination of human body as PDRNet. Experiments show that, PDRNet has achieved state-of-theart performances on four benchmarks, including CIHP [3], Pascal-Person-Part [15] and LIP [16]. Meanwhile, we also verify that PDRNet can significantly reduce background confusion errors and semantic inconsistency errors through qualitative comparison.
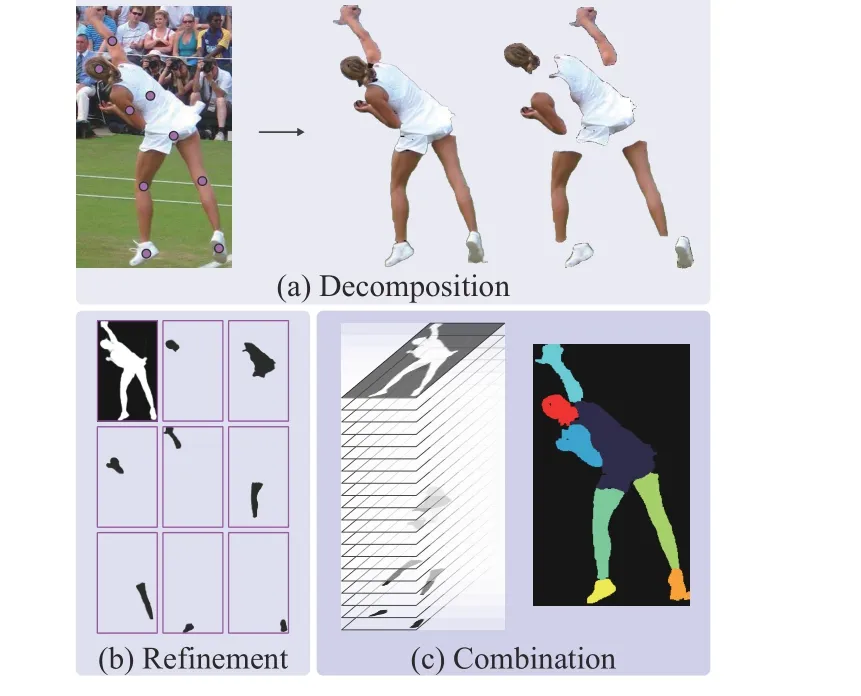
Fig. 1. Illustration of proposed PDRNet for human parsing. We decompose the human body into different semantic parts, segment each part mask independently, and then combine them into a complete human structure.
Related work:
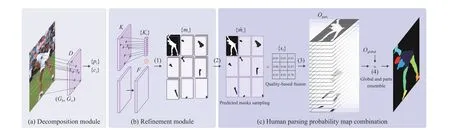
Fig. 2. Illustration of proposed decomposition module, refinement module and human parsing probability map combination.
· Human parsing: Human parsing has attracted a lot of research efforts in recent years [3], [15], [16]. Most of them regard it as a special case of semantic segmentation, and improve the performance by introducing attention mechanism [10], [17], auxiliary supervision[5], [15], [18], [19], human hierarchical structure [7], [8], [20] or quality estimation methods [9], [11]. Some earlier studies introduced human structure prior knowledge by designing hand-crafted features[21] or grammar model [22]. Attention mechanism [10] is then adopted to construct the geometric context of the human body, which promotes the development of the community. In order to improve the ability of semantic segmentation network to understand human structure, some researchers uses keypoints [15] and edge [5]supervision to improve the model representation. Graph transfer learning [23], graph networks [7], [8] and semantic neural tree [20]are used to exploit the human representational capacity. However, it is difficult to eliminate the differences between the semantic segmentation method and the human parsing objective through these efforts. Urgently need a new perspective to solve the human parsing problem. Guided by this intuition, we try to decompose the human body into parts, segment each part mask independently, and combine them into a complete structure, which make a further step towards the consistency of method and objective in human parsing.
· Instance segmentation: Instance segmentation is a more challenging view of dense pixel prediction. It not only needs to predict the semantic categories at pixel level, but also distinguish different instances in the image simultaneously. According to whether the object proposal is explicitly adopted, the instance segmentation method can be divided into proposal-based [12] and proposal-free [13,] [14]. The first successful attempt is the proposalbased method, the milestone work is Mask R-CNN [12], which learns from the two-stage object detection framework by detecting the object box first and then segmenting the object mask in the box.The proposal-free methods attempt a more direct idea, using pixel grouping, object contour and other strategies [24] to obtain the object mask. Some pioneering efforts [13], [14] segment the mask directly without the box supervision, which has advantages in efficiency and performance. Our work is inspired by this idea, which can be viewed as a groundbreaking attempt to explore the method beyond semantic segmentation pipeline in the area of human parsing.
Methodology:



Experiments:

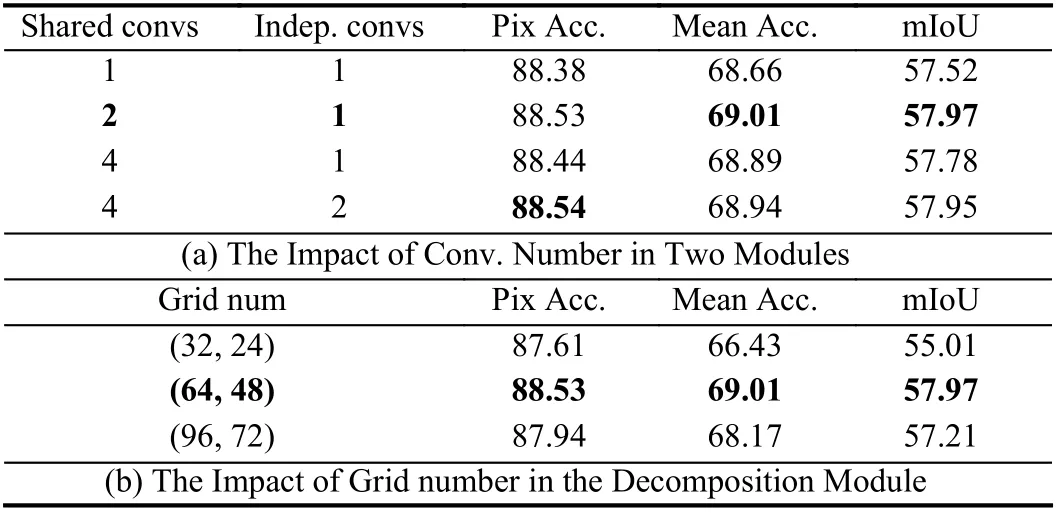
Table 1.The Impact of Conv. Number (Top), grid Number (Bottom) of PDRNet on LIP val Set
· Human parsing probability map combination: Table 2 shows sampling the highest score mask (denoted as Top-1) can achieve higher performance than the NMS-based sampling [14]. We argue this is because each part of human body is unique, so there is no need for complex duplicate removal method. The core of probability map combination is to fuse the sampled part masks into a complete probability map. As shown in Table 3, the quality-base fusion is 0.75 points mIoU higher than direct fusion and 1.50 points mIoU higher than score-based fusion. By comparing direct fusion and quality-base fusion, we find that it is necessary to weight the mask quality, where some low quality predictions can be suppressed. Table 4 illustrates the influence of ensemble factorαon human parsing performance.Note that, it is not the best choice to use only the global probability map Oglobal(α= 0.0) or the part probability map Opart(α= 1.0). It can be observed that settingα= 0.75 achieves the best performance with 88.53% pix Acc., 69.01% mean Acc. and 57.97% mIoU.


Table 2.Performance Comparison of Different Kinds of Predicted Masks Sampling on LIP val Set
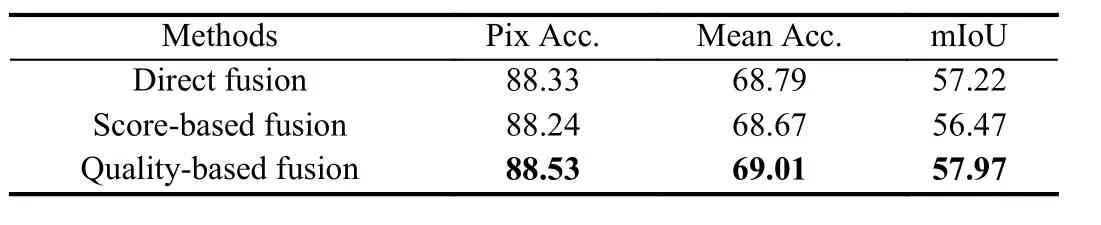
Table 3.Performance Comparison of Different Kinds of Human Parts Fusion on LIP val Set
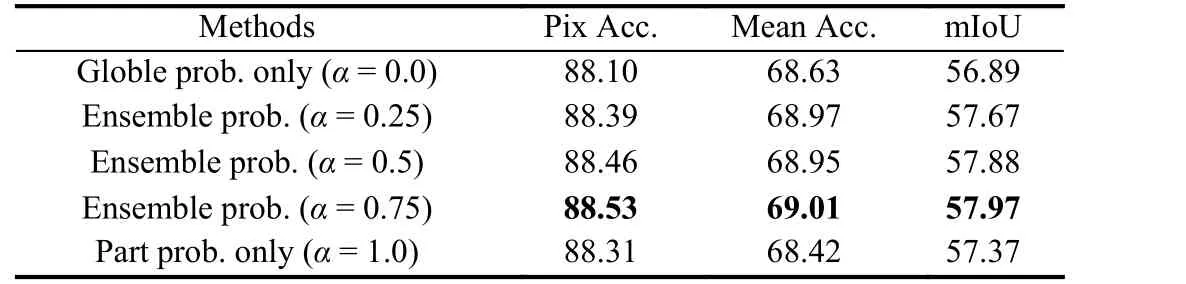
Table 4.Ablation Study of Global and Parts Ensemble Factor α on LIP val Set

· CIHP [3]: In the upper part of Table 6, we compare our method against 11 recent methods on CIHP val PDRNet achieves the best results in all metrics; specifically, 65.1% mIoU, 63.5% APpand 57.5% APr. Compare with previous state-of-the-art QANet [11],PDRNet yields 1.3 points mIoU and 1.7 points APpimprovements.
· PASCAL-person-part [15]: PASCAL-person-part is a classic multiple human parsing benchmark with only 7 semantic categories.The lower part of Table 6 summarizes the quantitative comparison results with 9 competitors on PASCAL-person-part test set. Our PDRNet with HRNet-W48 backbone yields 73.3% mIoU, 63.9% APpand 59.1% APr, which again demonstrates our superior performance.
Conclusions: Using traditional semantic segmentation pipeline to process human parsing task will bring unavoidable semantic inconsistency and background confusion errors. This work draws on the idea of instance segmentation and proposes a new human parsing method to addresses these issues. Firstly, a decomposition module is designed to encode the human geometry prior and predict the center position of each part. Then, the refinement module is proposed to predict the part masks. In inference stage, combining the predicted human part masks into a complete human parsing probability map.We verify the superiority of our method on several benchmarks, and further prove that it can be flexibly combined with the existing human parsing frameworks.
Acknowledgments: This work was supported by the National Key Research and Development Program of China (2021YFF0500900).
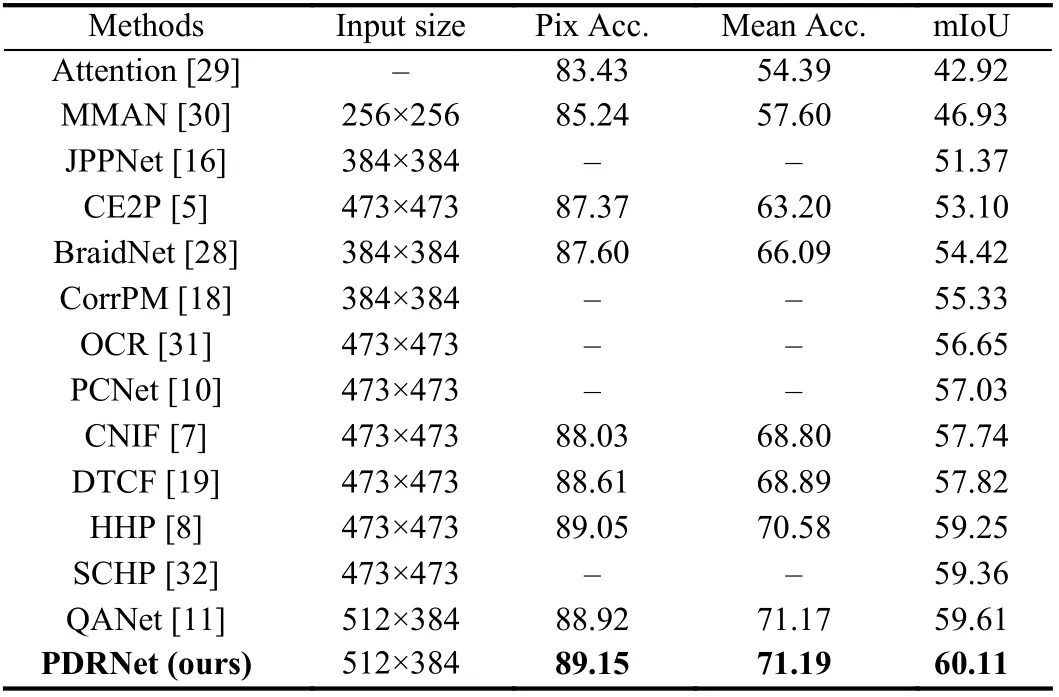
Table 5.Comparison of Pixel Accuracy, Mean Accuracy and mIoU on LIP val Set
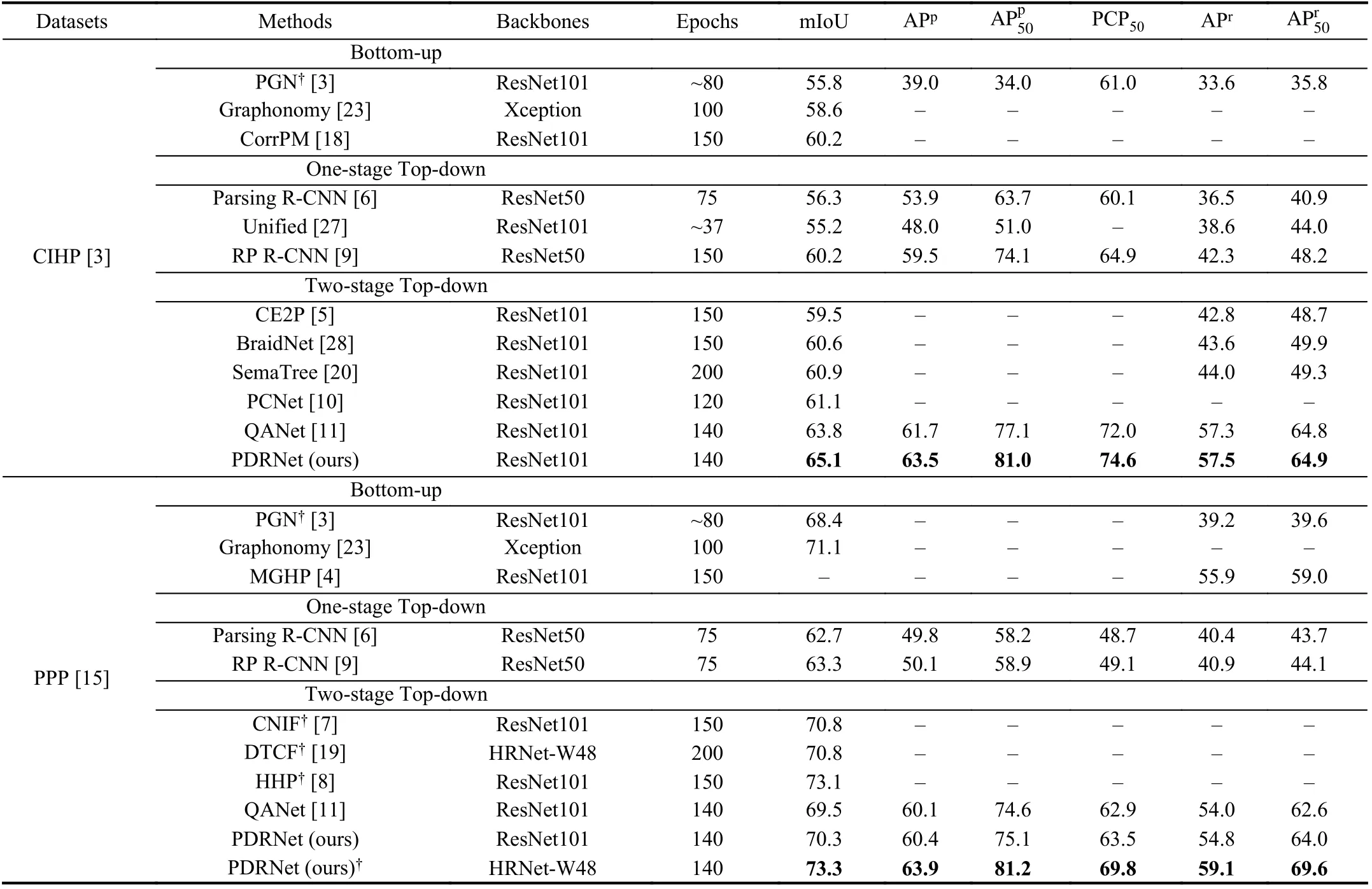
Table 6.Comparison With Previous Methods on Multiple Human Parsing on CIHP val and PASCAL-Person-Part Sets. Bold Numbers are State-of-the-Art on Each Dataset, † Denotes Using Multi-Scale Test Augmentation
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Exponential Continuous Non-Parametric Neural Identifier With Predefined Convergence Velocity
- Exploring Image Generation for UAV Change Detection
- Wearable Robots for Human Underwater Movement Ability Enhancement: A Survey
- A Scalable Adaptive Approach to Multi-Vehicle Formation Control with Obstacle Avoidance
- Fuzzy Set-Membership Filtering for Discrete-Time Nonlinear Systems
- Distributed Fault-Tolerant Consensus Tracking of Multi-Agent Systems Under Cyber-Attacks