Loop Closure Detection With Reweighting NetVLAD and Local Motion and Structure Consensus
2022-06-25KainingZhangJiayiMaandJunjunJiang
Kaining Zhang, Jiayi Ma,, and Junjun Jiang,
Dear Editor,
Loop closure detection (LCD) is an important module in simultaneous localization and mapping (SLAM). In this letter, we address the LCD task from the semantic aspect to the geometric one.To this end, a network termed as AttentionNetVLAD which can simultaneously extract global and local features is proposed. It leverages attentive selection for local features, coupling with reweighting the soft assignment in NetVLAD via the attention map for global features. Given a query image, candidate frames are first identified coarsely by retrieving similar global features in the database via hierarchical navigable small world (HNSW). As global features mainly summarize the semantic information of images and lead to compact representation, information about spatial arrangement of visual elements is lost. To provide fine results, we further propose a feature matching method termed as local motion and structure consensus (LMSC) to conduct geometric verification between candidate pairs. It constructs local neighborhood structures of local features through motion consistency and manifold representation, and formulates the matching problem into an optimization model, enabling linearithmic time complexity via a closed-form solution. Experiments on several public datasets demonstrate that LMSC performs well in feature matching, and the proposed LCD system can yield satisfying results.
Related work: LCD aims to lessen the cumulative error of the pose estimation in the SLAM system by identifying reobservations during the navigation [1]. It is achieved by 1) first searching a connection between the current and the historic observations and 2)then regarding the recovered SE(3)/Sim(3) pose as a constraint to optimize the pose graph. In this letter, we focus on the former step in the visual SLAM system. Namely, we mainly solve how to find reliable image pairs to constitute loop-closing pairs.
The first step of LCD is commonly studied as an image retrieval task. But differently, the reference database in LCD is incremental while the size of that in image retrieval is generally fixed for a short period of time. In this step, it is important to determine how to generate a global descriptor for image representation. Notable early global image descriptors are dominated by keypoint detection coupling with aggregation of associated local descriptors, such as BoVW [2], VLAD [3] or ASMK [4]. These approaches rely on a visual dictionary, which can be trained off-line [5], [6], or on-line [7], [8].Compared with the off-line manner, on-line ones are more sceneagnostic and become increasingly popular during recent years. In these aggregation-based approaches, inverted index [6] or voting [8], [9]technique is commonly exploited to accelerate the searching process.Recently, deep approaches gain increasing popularity in the context of image representation. These CNN models are trained based on ranking triplet [10], [11] or classification [12] losses, which can acquire deep semantic information of images and perform well even with large viewpoint changes. It is demonstrated that LCD approaches built on deep global representation can yield good performance [13]-[16]. In these approaches, HNSW [17] is always selected as a technique for searching acceleration.
After candidate pairs being identified in the first step, a geometric verification process is followed to guarantee precision. It is roughly achieved by first building the putative set based on the similarity between local descriptors and then rejecting false matches (i.e.,outliers). Later, the preserved true matches (i.e., inliers) are exploited to recover fundamental or essential matrix. Little LCD literature has discussed this step, and most approaches use RANSAC [18] to achieve it. It assumes the transformation between image pairs is rigid, and the parametric model can be acquired by alternating between sampling and verification. RANSAC is vulnerable to dominated outliers and non-rigid deformation. Numerous non-parametric approaches have been extensively studied to address this issue,ranging from graph matching [19], generalized geometric constraints [20] to locality consistency assumptions [21], [22].

The weights of common parts between our AttentionNetVLAD and DELG are initialized by the official pre-trained model (R50-DELG)and the whole AttentionNetVLAD is trained via knowledge distillation [14]. Specifically, the teacher network is VGG16+NetVLAD and has been released in [10]. We train the student by minimizing the mean square error loss between its predictions and target global descriptors exported by the teacher on GLDv2 [23]. The number of cluster centersJis set to 64, and an FC layer is introduced additionally to make the dimension of the output of the student network equal to that of the teacher network (4 096). Training details involving the input image size, batch size, learning rate, etc. are all referred to [12]. In this way, the new model can inherit the property of the teacher, i.e., being able to capture time-invariant visual clues at a high structural level, meanwhile with the training time being reduced drastically.
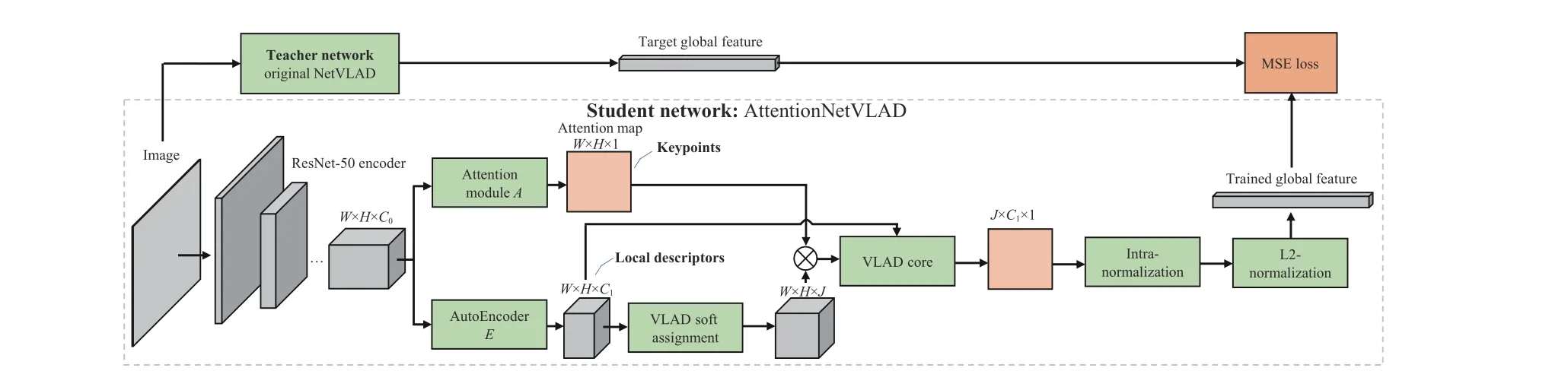
Fig. 1. AttentionNetVLAD and its training process.

Fig. 2. Illustration of local inter-distance and intra-distance in LMSC. The example is shown in an ideal situation, i.e., no outliers existing in the local neighborhood ( K =4 ) . In the source image, xinlier , xoutlier, Nxinlier and Nxoutlier are presented. In the reference image, yinlier , youtlier, Cxinlier and Cxoutlier are presented.



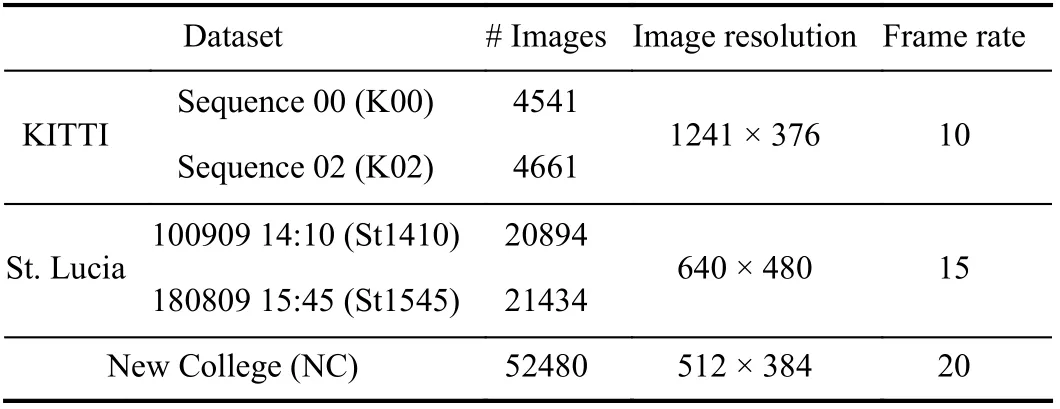
Table 1.Dataset Information. “# Images” Means the Number of Images
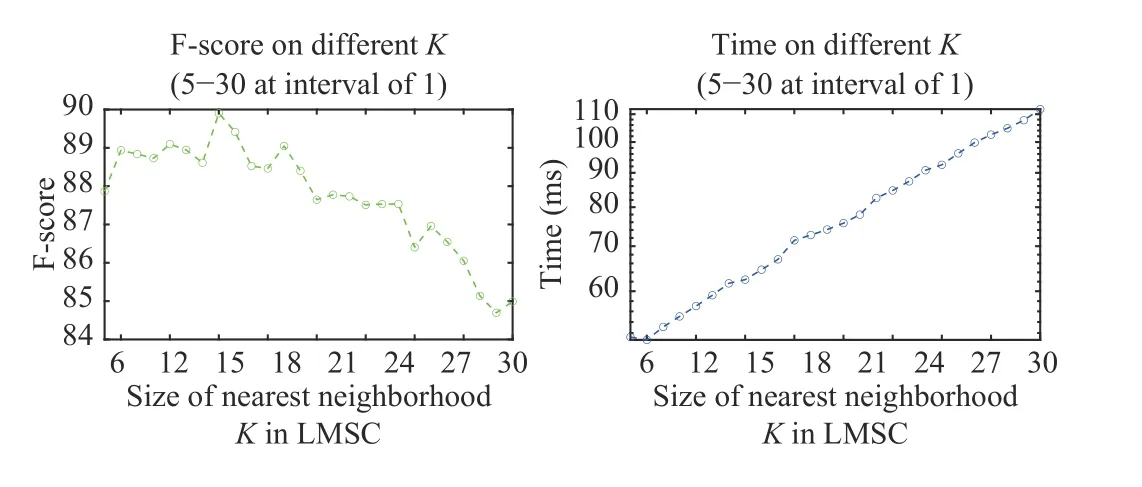
Fig. 3. The choice of the optimal K.
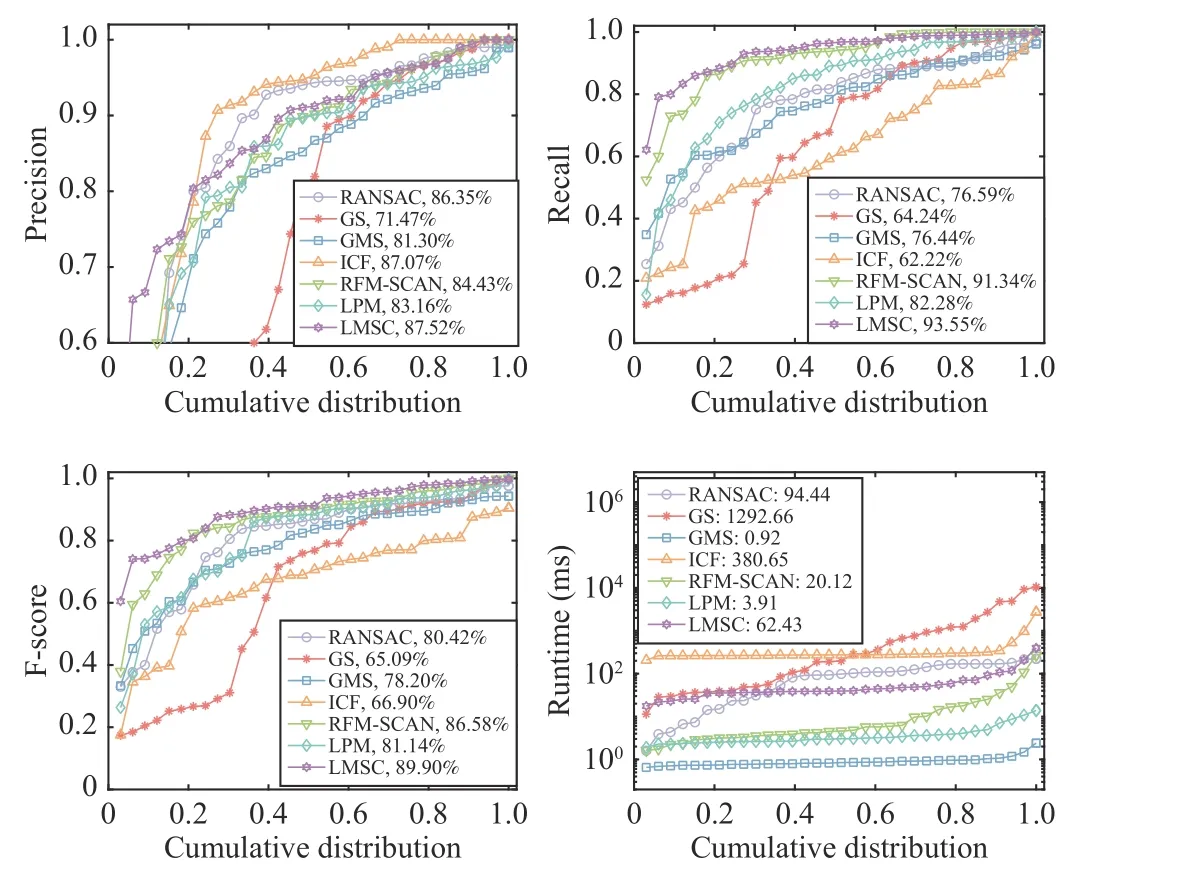
Fig. 4. Quantitative results of LMSC. From left to right: Precision, Recall, Fscore and Runtime (ms) with respect to the cumulative distribution. The coordinate (x,y) on the curves means that there are 100*x percent of image pairs which have precisions, recalls or runtime no more than y.
Experimental setup: We implement AttentionNetVLAD with TensorFlow, and run on an Intel(R) Core(TM) i9-9920X CPU @3.50 GHZ machine with three TITAN RTX GPUs. The information of six sequences selected for evaluation is presented in Table 1. The frame rates of St1410 and St1545 are downsampled to 3 Hz, meanwhile the right measurements of NC with the frame rate of 1 Hz are adopted.Ground truth (GT) which is present in the form of binary matrices and preserves the image-wise correspondence of datasets is provided by Anet al.[13].
Results on feature matching: We select 33 loop-closing pairs according to GT from the datasets shown in Table 1 to evaluate LMSC. The putative set of each image pair is established based on SIFT [27], followed by GT generation through manual check of each putative match, which results in the average number of putative matches and the inlier ratio are 345 and 51.28%, respectively. As Fig. 3 shows, the runtime of LMSC scales up with the increase ofKdue to the linearithmic time complexity and F-score =(2·Precision·Recall)/(Precision + Recall) in the left plot is applied for comprehensive evaluation in feature matching. On the whole,K= 12 outperforms other cases with a relatively low time cost, thus we choose it for subsequent experiments.
We report the quantitative performance of LMSC in Fig. 4,involving six feature matching methods (i.e., RANSAC [18], GS [19],GMS [22], ICF [28], RFM-SCAN [29] and LPM [21]) for comparison. It can be seen that compared with Precision, LMSC is better at Recall, and outperforms other methods in F-score with relatively high efficiency.
Results on loop closure detection: We adopt maximum recall rate at 100% precision (MR) to evaluate the performance of LCD. Firstly,we perform it based on DELG, NetVLAD (teacher) and AttentionNetVLAD (student) respectively, along with LMSC for geometric check. Results are shown in Table 2. DELG is tailored for the instance recognition task, thus the performance of it degenerates with the similar structures occured in LCD scenes. NetVLAD is oflow efficiency due to the requirement of additional local feature extraction. Its coupling with AL outperforms that with SURF may be caused by the fact that SURF cannot ignore redundant information in scenes [26], which reduces the accuracy of feature matching.Through training with knowledge distillation, our AttentionNetVLAD can at the same time learn prior knowledge of perceptual changes in NetVLAD, and be efficient enough for real-time requirements.
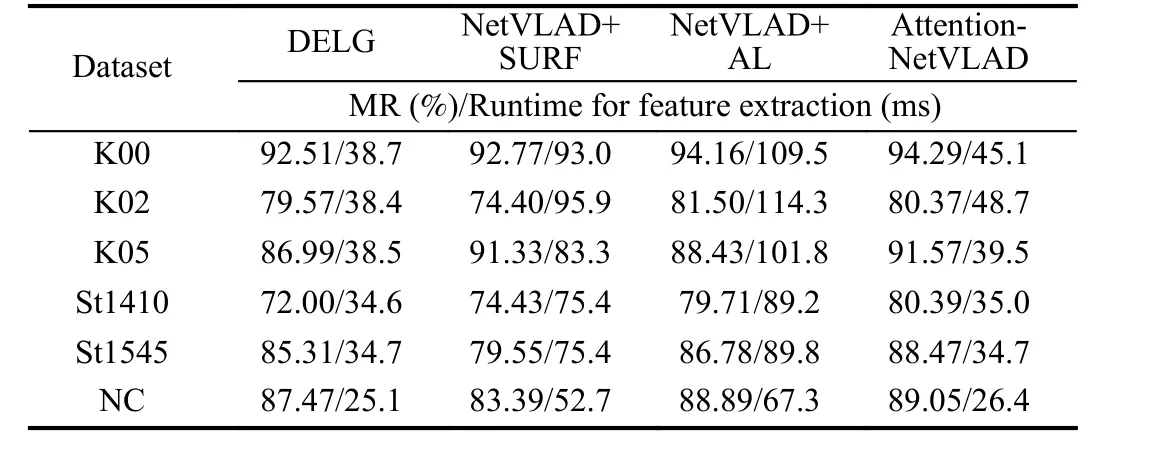
Table 2.LCD Results on Different Feature Extraction Approaches. “AL”Means the Local Part in AattentionNetVLAD
Secondly, on the basis of AttentionNetVLAD, different feature matching methods involving RANSAC, LPM and LMSC are embedded into our LCD pipeline, and the results are shown in Table 3.Records of runtime in the table exclude the process of putative set construction. Obviously, the pipeline with LMSC yields better performance on MR than RANSAC and LPM. This is because RANSAC performs poor when resampling in putative sets with low inlier ratio, while LPM cannot separate inliers from relatively lowprecision noisy matches due to its weak local geometric constraint.When the process of geometric verification is considered, the average runtime of our system on the dataset with the maximum image resolution (K00) is about 116.14 ms/frame.
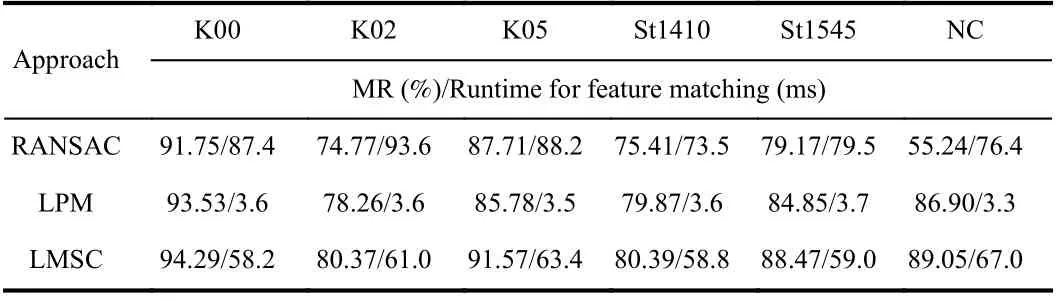
Table 3.LCD Results on Different Feature Matching Approaches
Finally, we report the comparative results of our method with stateof-the-art LCD approaches in Table 4. The results of ESA-VLAD[14] and Zhanget al.are cited from [26], while others are cited from[13]. Overall, our pipeline has satisfying performance on all datasets. Albeit our results are marginally worse than Zhanget al.[26],the runtime of our pipeline is about one time faster than them.Meanwhile, they need a pretrained visual dictionary to conduct candidate frame selection, while ours is completely operated online.
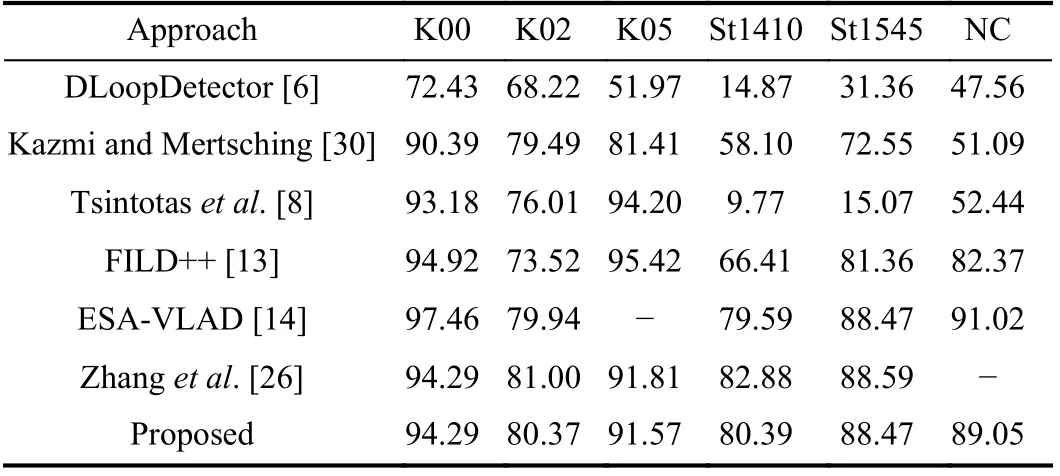
Table 4.Comparative Results
Conclusions: In this work, we conduct LCD in a semantic-togeometric, coarse-to-fine manner. We first propose Attention-NetVLAD to achieve global and local feature extraction simultaneously. The global feature is used to perform candidate frame selection via HNSW, while the local one is exploited for geometric verification via LMSC. LMSC is the proposed feature matching method, which is able to identify reliable matches efficiently by imposing from-weak-to-strong local geometric constraints. Based on the above two components, the whole LCD system is at the same time high-performance and efficient compared with state-of-the-art approaches.
Acknowledgments: This work was supported by Key Research and Development Program of Hubei Province (2020BAB113), and the Natural Science Fund of Hubei Province (2019CFA037).
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Exponential Continuous Non-Parametric Neural Identifier With Predefined Convergence Velocity
- Exploring Image Generation for UAV Change Detection
- Wearable Robots for Human Underwater Movement Ability Enhancement: A Survey
- A Scalable Adaptive Approach to Multi-Vehicle Formation Control with Obstacle Avoidance
- Fuzzy Set-Membership Filtering for Discrete-Time Nonlinear Systems
- Distributed Fault-Tolerant Consensus Tracking of Multi-Agent Systems Under Cyber-Attacks