A Triangulation-Based Visual Localization for Field Robots
2022-06-25JamesLiangYuxingWangYingjieChenBaijianYangSeniorandDongfangLiu
James Liang, Yuxing Wang, Yingjie Chen,,Baijian Yang, Senior, and Dongfang Liu
Dear Editor,
Visual localization relies on local features and searches a prestored GPS-tagged image database to retrieve the reference image with the highest similarity in feature spaces to predict the current location [1]-[3]. For the conventional methods [4]-[6], local features are generally explored by multiple-stage feature extraction which first detects and then describes key-point features [4], [7]. The multiple-stage feature extraction is redundantly implemented, which is not memory and run-time efficient. Its performance degrades with challenging conditions such as poor lighting and weather variations(as shown in Fig. 1(a)) because the multiple-stage design may lose information in the quantization step which produces inadequately key-point features for matching. Another critical issue for existing visual localization is that most of the conventional methods are onedirectional-based approaches, which only use one-directional images(front images) to search and match GPS-tag references [4], [8]. With the increase of database size, one-directional inputs can be homogeneous which makes it difficult for the localization algorithms to work robustly (as shown in Fig. 1(b)).
To address aforementioned problems, we propose a novel visual localization method that uses triangulation (front, left, and right) to robustly perform localization for the robotic system (as shown in Fig. 1(c). For the local feature extraction, we use a one-stage approach: an efficient implementation that can simultaneously detect and describe the key-point features of the input images to establish pixel-level correspondences. Since the one-stage method couples the detector and the descriptor closely, we keep the feature information untouched without the quantization step which improves the feature representations. In addition, we implement a generalized minimum clique graphs (GMCP) approach for feature matching, to organically manage features from all directions and triangulate the location prediction. Since the left and right scenes change more drastically than the front scene when a field robot is in linear motion, adding left and right images for feature matching is more informative to differentiate similar location references.
Related work: A line of work has developed different strategies to improve localization accuracy. For instance, [9] use ground texture features to compute the mobile robot positioning; [6] and [10]attempt to extract denser local features for key-point matching.Alternatively, [11] and [12] employ different types of global features,such as color histogram, GIST, and GPS coordinates to predict the final inference. However, the above improvements gain from extra features come at the price of longer matching times and higher memory consumption, and the results are still sub-optimal [4], [8]. In contrast to the existing one-directional-based method, we use threedirectional views to triangulate a location, which is arithmetically effective and systematically intuitive.

Fig. 1. (a) and (b) demonstrate the challenges to one-directional-based visual localization, such as lighting changes and similar appearances. The images for query (blue ones) and predicted locations (red ones) are shown for comparison. (c) illuminates our triangulation-based method. The images from the left and right cameras change quickly and they can be used to effectively identify different locations. We use camera inputs at t and t+1 for comparison.
Proposed approach: The working pipeline for our approach is demonstrated in Fig. 2. The top part of Fig. 2 shows the reference library construction pipeline. The first step is to collect GPS-tagged image data and store them as the reference library. We use the data from the reference library to train the location search engine. The bottom part of Fig. 2 shows the working procedures of the trained location search engine. Local features are first extracted from the query inputs. Then, the extracted features are compared with the reference library. The GPS-tag references with the closest distance to the query inputs are retrieved to predict the robot location.
Reference library construction: We collect image data under GPSshadowed areas to build the reference library. Three high-resolution cameras are mounted in the front, left, and right directions of the field robot to record the scenes along the robot’s trajectories. We slice images from the recorded video and label them with the corresponding GPS tags. All the GPS-tagged images are stored in the reference library.
Location search engine: The location search engine has two major working steps. First, query inputs are extracted for key-point features. Then, we use a modified GMCP [13] for feature matching to retrieve the most similar reference for localization prediction.

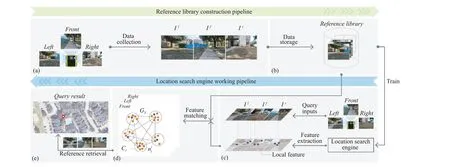
Fig. 2. The working pipeline for our approach. To construct the reference library, we first conduct (a) data collection, and then (b) data storage. After training,the location search engine can take the query image as input and perform (c) feature extraction, then (d) feature matching, and finally (e) reference retrieval.



Experiments and evaluations: We purposefully select different university campus as well as some inner city areas under different weathers and seasons, where GPS signals are frequently denied due to the surrounding of dense buildings and vegetation. In order to have reliable GPS tags under GPS denied or partially shadowed areas,using Google location offers us a convenient access to the ground truth. More concretely, the GPS of each waypoint is manually selected and calibrated using Google Earth Map. A jackal robot platform is employed to collect the image data of each corresponding location. There are three Logitech C615 HD webcams mounted on the jackal robot that continuously video-record the scenes along the robot’s trajectory. The jackal robot moves forward with a constant speed of 0.6 meters from one waypoint to another. After recording,we slice the video every second to obtain the reference images.
Implementation details: In the end, we obtain 146 828 images of 42 589 locations for the reference library. Our collected images generate ×4 triplets (402 628 triplets). We split the data, using 340 230 triplets for training and 62 398 for validation. Our training and evaluation are performed on a workstation with an Intel Core i7-7820X CPU and one NVIDIA GeForce GTX 1080Ti GPU. We use the collected dataset to construct the reference library and train the location search engine. For the one-stage feature extraction, we employ MobileNet [14] which is pretrained on ImageNet [15]. We remove the FC layers and only use convolution layers to initialize the feature extraction network Next. In training, we use the marginM=0.1 and perform 60 epochs with Adam [16], the learning rates of 10-3and decay rate of 10-4in every 6 epochs. In addition, we compare our method with three state-of-the-art methods, CRN [17], NetVLAD[18], and SARE [4], which are trained using both three and onedirectional features for comparisons.
Evaluation metrics: Our work focuses on robotics operation so we evaluate our method based on the top one retrieval. We use the threshold of 7.8 meters for the true positive predictions. Namely, in our experiment, a predicted location is considered as a true positive if the top one retrieval from our reference library is located within 7.8 meters of the ground truth (GT) position. Average precision (AP) is reported for evaluation.
Field test results: We conduct field tests to examine the proposed method under three different conditions: 1) the daytime; 2) the nighttime; and 3) a snowy day. Table 1 shows the comparisons of our methods with state-of-the-art methods under different environmental conditions. For all methods using three-directional features, our methods outperform the compared methods by a significant margin.When compared to the methods using only one-directional features,our results exhibit better performance in accuracy, while achieving approximately 2× faster. Finally, we use a box plot to visualize the distance distribution to ground truths based on the predictions (see Fig. 3). Our triangulation-based method is more robust under different conditions compared to its counterparts.
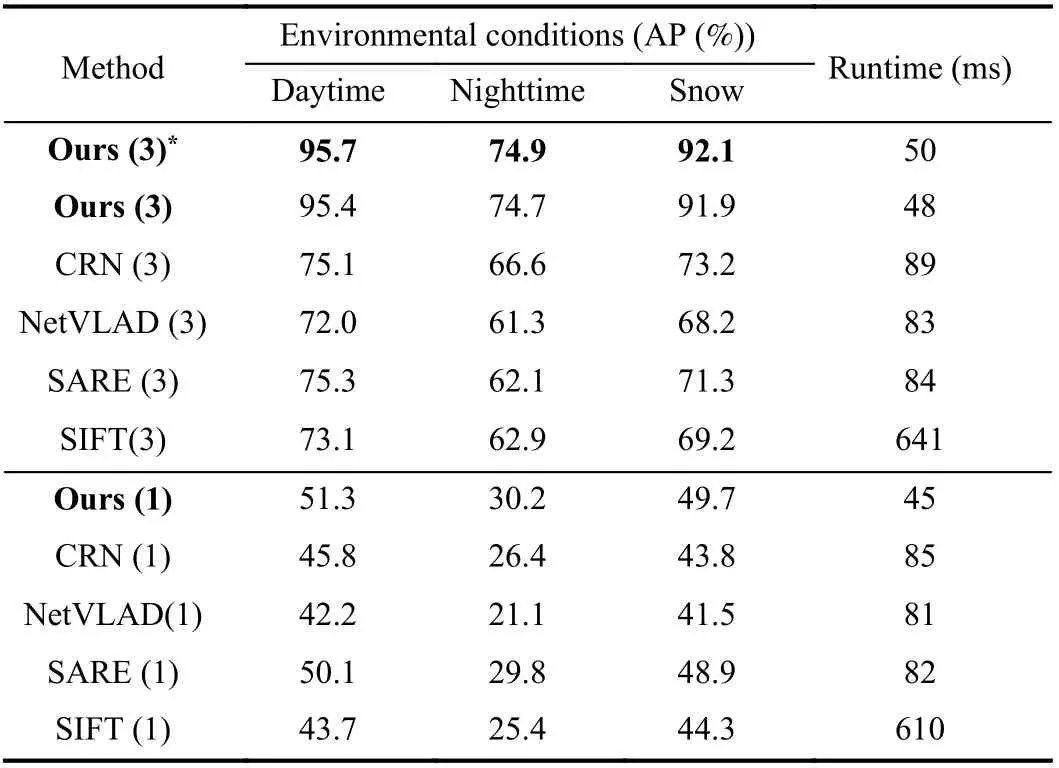
Table 1.Performance Comparisons (3) and (1) Indicates Using Three- and One-Directional Features Respectively. * Indicates Using the Adaptive Weights Over the Average Weights
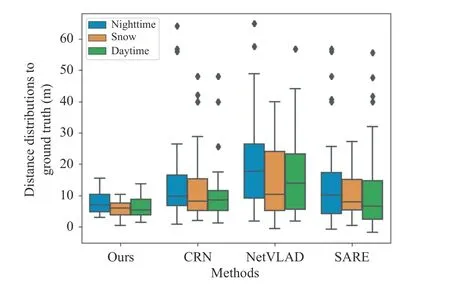
Fig. 3. Comparison with the state-of-the-art methods under different conditions. All methods use three-directional features.
Based on the results, we argue that our gains in accuracy stem from three sources. First, our method exploits triangulation-based features(three directional features) which effectively add the dimension of the image representations for location predictions. Second, our feature matching strategy can organically manage features from each direction in a flexible and general manner, rather than simply averaging feature contributions from each direction, which also brings improvement for our method (see Table 1).
Table 2 shows the comparison of our method with GPS signals in terms of AP and median error to the ground truth. Instead of using lighting and weather conditions, we categorize our data into two conditions: 1) open spaces, where only one side of sidewalks are closed off by buildings or trees; and 2) blocked spaces, where both sides of sidewalks are bordered by dense buildings or vegetation. The results indicate that our method outperforms GPS signals in AP and in average distance to ground truth under both conditions.Specifically, we observe that our method is more robust because the conditions of open spaces and blocked spaces have little impact on its performance, while GPS performs poorly in the blocked spaces where dense buildings or vegetation compromise its access. Our method performs consistently under either condition.
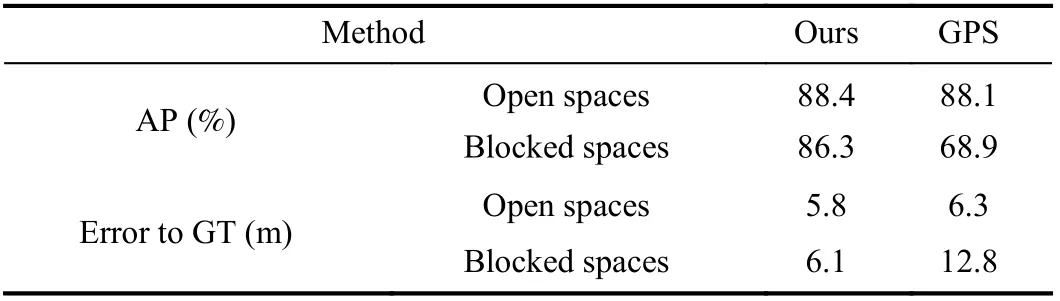
Table 2.Comparisons With GPS
Adaptive weight evaluation: We visualize the adaptive weight selection in order to achieve optimal performance (see Fig. 4). The three different color bars (blue, orange, and green) indicate the adaptive weight for the right, front, and left direction respectively,which also indirectly reflects the scenery change in each direction (a larger value means a bigger change). In the given example, the left scene has the fastest-moving scenes, while the left and the front have the approximately same moving pattern. These empirical observations corroborate the strategy of our adaptive weight selection that each weight is determined by the ratio of the scenery changes in (8).
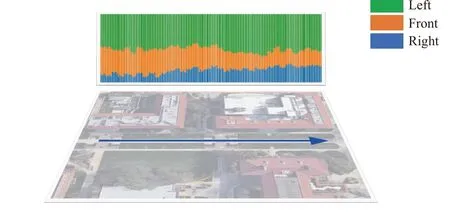
Fig. 4. Adaptive weight evaluation.
Conclusion: Localization under GPS shadowed areas is an important yet challenging task for field robot operation. In this study, we propose a novel visual localization method for field robots. Our method leverages triangulation views to accurately locate the robot in motion. We use one-stage feature extraction to effectively preserve local features for image representation and use a GMCP with flexible adaptive weights to manage features to triangulate the location prediction. The extensive experimental results indicate that our method is competitive with the existing state-of-the-art approaches and GPS.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Exponential Continuous Non-Parametric Neural Identifier With Predefined Convergence Velocity
- Exploring Image Generation for UAV Change Detection
- Wearable Robots for Human Underwater Movement Ability Enhancement: A Survey
- A Scalable Adaptive Approach to Multi-Vehicle Formation Control with Obstacle Avoidance
- Fuzzy Set-Membership Filtering for Discrete-Time Nonlinear Systems
- Distributed Fault-Tolerant Consensus Tracking of Multi-Agent Systems Under Cyber-Attacks