基于深度强化学习的网络路由优化方法
2022-06-25孟泠宇郭秉礼张欣伟赵柞青黄善国
孟泠宇, 郭秉礼,*, 杨 雯, 张欣伟, 赵柞青, 黄善国
(1. 北京邮电大学电子工程学院, 北京 100876; 2. 信息光子学与光通信国家重点实验室, 北京 100876)
0 引 言
目前,随着光通信技术、大数据以及云计算的高速发展,网络的规模逐渐扩大其丰富的应用也不断出现,用户的需求也是日新月异,通信网络正经历着爆发式的流量增长。传统的路由优化方法通常需要提前收集大量的网络的流量信息,并根据这些流量计算路由策略最后进行路由配置。基于最短路径算法的传统路由优化方法在整个路由计算的过程中非常耗时,存在收敛缓慢等问题并且需要巨大的网络资源开销。传统优化方法最大的不足是对于网络实时复杂的变化情况无法及时做出调整,泛化能力较弱。当网络流量呈指数级增长,不同业务产生的流量也使得网络流量状态越来越多样化,依靠人工和传统方法来运维现有复杂的网络环境导致其承载上的业务性能恶化严重。在此背景下,对网络路由优化的性能和收敛速度都提出了更高的要求。因此,智能化、自动化是网络控制的必然选择。
随着软件定义网络(software defined network, SDN), IPv6, IPv6+等技术的发展,业界致力于实现算力网络与IP网络的融合、云网融合等全新的架构,但现在还存在许多技术难题:如何实现最优的路由、如何最优地分布算力、如何保障算力的服务质量。这都需要借助人工智能等技术克服难题,但目前相关研究也还处于初级阶段。近些年来,机器学习成为了人工智能发展的热门领域,尤其是在大数据处理、聚类以及智能决策方面有着不错的表现。随着 AlphaGo在围棋大战中击败李世石使得深度强化学习(deep reinforcement learning, DRL)引起了学术界重视,这样的趋势也指导着人们使用机器学习来控制和运营网络。很多人工智能的方法被用在了路由优化方面,但这些算法的表现在网络状态改变的情况下也是不容乐观。文献[7]设计并使用了启发式算法例如蚁群算法、模拟退火法等来进行网络路由的优化,但由于启发式算法的求解结果可能千变万化并且其自身的局限性,只能针对特殊的问题。当网络状态发生变化时,其参数就需要调整,泛化能力差,并且在应对大规模的网络时,为了寻找最优的路径会需要大量的时间成本。文献[8-9]使用了深度Q学习(deep Q learning, DQN)算法,将增强学习引入到了路由优化的应用中来,实验结果表明DRL在路由选路的问题中有着独特的优势,可以实现降低网络时延和自适应路由,但是DQN算法本身存在着缺陷,不仅自身收敛困难并且只能解决离散时间的优化问题,与网络的动态属性并不吻合。文献[10]针对动态的网络提出了使用深度确定性策略梯度(deep deterministic policy gradient, DDPG)算法来进行路由的优化。DDPG是一种主要解决连续动作空间的DRL算法,更易针对动态性与实时性较强的网络系统,弥补了DQN算法无法处理连续控制任务的空白。尽管DDPG解决了很多连续动作空间问题,但是在高维度的动作空间上寻求一个最优的动作仍是一件困难的事情,尤其是在面对大型的网络拓扑和高维度动作空间的复杂任务中DDPG算法的性能表现出了不稳定、收敛慢的缺点。
因此本文中,在使用DDPG算法解决网络路由优化的问题方法上提出了两种优化方法。应对大型的网络拓扑,在知识定义网络(knowledge-defined networking, KDN)架构上,提出了一种全新的动态权重构造策略降低了神经网络的输入状态维度。利用流量矩阵直接构造动态链路权重,通过对原始数据的预处理,使得流量矩阵预加工为模型想要学习到的动作权重,进而增加了状态和动作的相关性使得在训练的过程中神经网络更易从经验中获取到两者潜在的关联即策略。通过该方法,智能体能够在初始的构造策略上进行二次学习,提升了模型的学习效率和智能体在训练时的稳定性。另一种优化方法是在针对路由优化问题上进行了动作空间的离散化,极大降低了动作空间的复杂度,减小了无效的动作空间探索,使得算法学习经验时更利于通过梯度下降的更新方法找到最优的更新策略的方向,从而加快了算法的收敛速度。本文设计了一套完整的训练和测试方案,并验证了增强后的算法在该方案下对于网络性能的影响。
本文第1节介绍了DRL的一般原理和如何应用在具体的网路路由优化问题上;第2节详细描述了DDPG算法原理与现存的缺陷讨论了现有的动作选择复杂度高和泛化性不强的问题和改进办法,针对网络路由优化问题提出了一套动态链路策略,能够利用网络当前的流量状态生成各条链路权重。同时提出了动态空间离散化的方法,将连续动作映射到相对应的离散空间上。第3节对以上理论在仿真环境下进行验证并对仿真结果做进一步的分析。
1 DRL学习机制和基于KDN的路由框架
DRL是将深度学习的感知能力和强化学习的决策能力相结合,是一种更具有智能化的更接近人类思维方式的学习方法。DRL是一种智能体和环境的交互系统,有着很强的普适性,所有用DRL解决问题的目标都可以被描述成智能体找到一组动作来最大化奖励值。在时刻,智能体利用深度学习方法来感知并反馈给当前智能体具体的状态特征,之后智能体通过策略将当前的状态生成一个确定的动作,并对环境施加该动作并返回给智能体新一轮的状态特征+1和及时奖励值。智能体和环境持续不断的交互最终会使得智能体生成了一个最优策略使得环境反馈的累积奖励值最大化。
本文将利用人工智能技术来控制和操作网络,使用了文献[15]提出的KDN,其容纳并利用SDN、网络分析和人工智能,提出了互联网知识平面的概念,这是一种依靠机器学习和认知技术操作网路的新构造。知识平面使用机器学习和深度学习来收集当前网络状态,利用收集当前网络的信息使用SDN提供的集中控制性来控制网络。图1显示了KDN的功能平面三层结构:数据平面负责存储、转发和处理数据包;控制平面负责监视网络流量情况并下发流表规则和最上层的知识平面。KDN中的控制平面管理数据平面上网络的路由流表,同时通过数据信息搜集模块监控网络中的流量情况、网络时延、丢包率、吞吐量等性能信息上发给知识平面。在知识平面中具有深度强化学习的智能体,用于利用底层上发的有效网络信息生成有效的网络策略,从而寻找到当前网络流量状态下的链路权值信息,下发给控制平面使用路径规划模块生成路由流表并更新到拓扑交换机中,实现了KDN的全局、实时的网络控制。同时,在知识平面中存在两个模块:动作离散化模块和状态预处理模块,分别用于知识平面接收数据平面的信息的状态优化和下发数据平面的动作优化。

图1 基于KDN的网络路由控制框架Fig.1 KDN-based network routing control framework
将DRL的思想引入网络控制中来解决路由优化问题最重要的是智能体和环境中交互的3个变量,分别是状态、动作和奖励值。其中的一个优化方法是在智能体的学习过程中,不再是直接利用由网络层收集到的状态信息——流量矩阵作为状态,而是通过动态权重策略使用当前网络的流量矩阵构造出输入神经网络的链路权重信息作为先验知识。动作表示的是一个目的到源的链路权重的集合,智能体通过动作来改变网络中的路由规划。本文中,设置智能体的网络优化策略为最小化网络的平均时延,因此奖励值代表平均网络时延。在知识平面中还加入了动作离散器,在输入状态为流量矩阵时,将智能体的连续动作空间区域化成离散的动作空间,并将生成的连续动作空间上的动作映射到离散动作空间上再下发到控制平面中,实现了智能体对于网络实时分析和优化。本文重点关注连续动作空间下的路由优化和离散动作空间下的路由优化的区别,并提出了一个新的动态权重策略,使用状态预处理模块通过网络流量直接构造动态链路权重,在对原始数据的状态进行预训练后,生成先验知识观察智能体在解决路由优化问题训练时的影响。
2 DDPG原理与优化策略
2.1 DDPG原理
DDPG不像传统的强化学习算法只能解决离散动作问题,结合了DQN方法和确定性策略梯度的策略函数,同时使用了Actor-Critic(AC)模型的双重网络框架。其中,神经网络用于拟合策略函数和Q函数。DDPG成为了求解连续动作空间的稳定算法,和分别表示神经网络拟合的策略函数和Q函数。Actor网络使用确定性策略梯度方法,Critic网络使用DQN方法。Actor和Critic网络都是由两个神经网络所组成的,用于训练学习的策略网络和减少每条经验相关性的目标网络。目标网络和策略网络在神经网络的结构上是一模一样的,但其参数会将Online网络参数软更新给target网络:

(1)
式中:为Actor网络中在线网络参数;′为Actor模块中目标神经网络参数;′为Critic模块的目标神经网络参数;为Critic模块的在线神经网络参数;为远小于1的常数值。
在更新DDPG算法参数的过程中,Actor模块中神经网络使用反向传输的策略梯度进行更新,策略梯度更新公式如下所示:
∇()=grad[]*grad[]≈
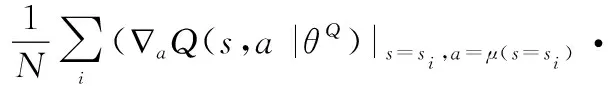
(2)
式中:为衡量策略的性能参数;grad[]是从Critic模块中在线网络中得到的动作梯度,指导Actor中在线网络如何执行动作才能获得更大的值;grad[]是从Actor中在线网络中生成,指导Actor修改自身参数使得神经网络有着更高的概率执行这个动作。式(2) 能使Actor模块中在线神经网络向着能获得更高回报的概率方向上不断修改其参数。
Critic网络反向传输更新参数为TD_error,TD_error为在线网络和目标网络值的均方误差。
=

(3)
式中:为当前的即时奖励;为学习时的衰减因子。
式(3)前半部分为Critic模块中目标网络基于下一步状态+1和动作+1生成的值。其中,动作+1是由Actor模块中目标网络利用下一步状态+1和参数′所生成的。式(3)后半部分则是对于Critic模块的在线网络值则是对当前状态和由Actor模块的在线网络对当前状态生成的动作评估并生成值。将式(3)两部分取均方差用于反向传递使其更新Critic模块在线网络的参数。
2.2 动态权重优化策略
强化学习算法优化的目标是奖励的长期累计收益最大化。神经网络的作用是将原始状态信息经过层层非线性提炼后转化为与长期收益高度关联的形式,并进一步指导生成动作决策。理想情况下,状态空间应该完全由筛选出的相关信息组成。某个状态信息所代表的事件在越短时间内得到反馈,神经网络就越容易学会到如何对其进行加工并建立起决策相关性。在利用深度强化学习解决问题时,往往会因为问题本身设计的状态和生成动作关联度不高导致神经网络在策略学习的时候难度增大,反映出智能体学习效果不稳定。在学习过程中,原始信息都要经过神经网络的提炼才能转化为动作输出,提炼难度与学习效率和最终性能呈反向相关。为了降低神经网络训练难度,提前对原始信息做些二次加工,人为提炼出与学习目标更相关的因素从而生成先验知识。
在利用DRL解决路由优化问题时,定义状态为初始权重,动作为优化权重,奖励为全网平均时延。当前网络环境的流量矩阵上发给智能体时对流量矩阵作为原始状态进行预处理生成初始权重。可以通过动态权重策略得到满足当前网络拓扑下的当前流量矩阵的初始权值。

(4)
式中:表示流量矩阵。


(5)
计算出中所有路径中各自对应的链路权值集合,,从,中找到各条链路的最小权值,从而生成源目的对(,)所对应的链路权值集合(, )(,=1,2,…,)。该策略保证了两点之间最短路径优先的原则使得跳数越小的链路优先级越高权值越小,通过拓扑可直接求出所有源目的对(,)的链路权值集合。利用拓扑生成的源目的节点对的权值集合和流量矩阵进行运算,通过式(6)与对应节点对进行相乘并累加生成初始权重做用于神经网络输入端。

(6)
该方法使得业务量大的端到端的所经过的链路权重小,确保了大流量业务的稳定性。整体流程如算法1所示。

算法 1 获取当前拓扑topologyL=DFS(topology),由DFS生成该拓扑下所有点到点的链路集合L;wni,nj=hop10,wni,nj⊂lij,得到wni,nj的权值并生成集合Wni,nj;Sraw=TM,流量矩阵作为原始状态[w1,w2,…,wn]=∑Ni,j=1WTM(i,j)=TM(i,j)*W(i,j),生成初始权值St;[w1,w2,…,wn]=πθ(w1,w2,…,wn),初始权重通过Actor网络生成优化权重。
在知识平面上将状态传入Actor网络,而Actor会根据当前的状态选择合适的动作,影响策略神经网络参数的迭代更新。而DDPG为确定性策略算法,不像随机性策略一样是在同一个状态时采用的动作是基于一个概率分布的。而是取最大概率的动作,去掉随机分布,在一个状态下,动作是唯一确定的,即策略为
π()=
(7)
DDPG的策略决策直接受到Critic网络的价值函数的影响,价值函数表示了在不同状态下的选择的不同的动作所对应的价值。一般情况下,价值函数是一个参数函数,在该算法中则是状态和动作为Critic全连接神经网络(deep neural networks, DNN)的输入端,该神经网络则利用价值函数计算出当前状态所执行动作的价值(,,),为Critic价值神经网络参数。在利用DNN搭建网络时,将Actor网络输入端的维度设置为状态维度,输出端设置为动作维度,而Critic网络输入端为状态维度加上动作维度。DDPG算法是基于两组神经网络进行训练和拟合的,神经网络拟合的速度反映了算法的质量。策略神经网络参数θ决定了策略函数,通过神经网络进行反向的策略梯度更新寻找到状态空间和动作空间潜在关联。
如图2所示,在路由优化中状态预处理过程,利用从网络产生的流量矩阵作为原始状态,使用策略生成当前流量状态下的初始权值作为状态输入到Actor网络中。此时输入神经网络中状态维度等于动作维度,在减少了神经网络的状态维度后,使得Actor网络在低维状态中更容易找到潜在的规则。并且,使用策略通过对流量矩阵构造初始权值作为状态值输入到神经网络中提升了状态和动作之间的相关性,使得Actor模块中的DNN更容易找到从当前流量矩阵中映射到优化权重的最优策略,进而提高了DDPG算法的收敛速度和学习效率。

图2 状态预处理Fig.2 State preprocessing
2.3 动作空间的离散化
在网络路由优化方法中,一般利用Actor网络生成的各条链路上的权重矩阵作为动作,从而通过Dijkstra算法求出最优的流表再下发给网络层。虽然DDPG可以解决连续动作空间问题,但在动作维数过高、动作连续区间过大构成的高维度连续动作空间上利用批处理梯度下降法寻找最优动作增加了难度,而基于价值的策略网络是通过评估和优化参数来学习的,动作维度过高导致了参数函数的评估过程复杂,利用DNN评估的复杂度会随着动作维度和量级的增加呈指数型上升。策略网络的梯度更新完全由Critic网络输出,Q函数的拟合误差会直接传递给策略网络导致DDPG稳定性不足。降低动作空间复杂度对于AC网络参数的评估是必要的。

:→′,()=′
(8)

图3 动作离散化过程Fig.3 Action discretization process
映射到离散动作空间后,通过减少动作空间的取值范围从而降低了动作空间的复杂度,使得Critic网络在拟合最优函数时更易找到最优参数并反馈给Actor网络,有利于策略网络的参数更新。动作空间离散区块化后,动作空间自由度大大降低,算法稳定,同时加快收敛速度。在路由问题中,该方法减小了智能体探索无效动作空间的可能性,提升了神经网络策略更新参数时的效率。
3 实验结果与性能分析
3.1 试验平台设置
本节对优化算法进行了网络路由优化的性能评估与测试。所用操作系统为Ubuntu18.04,同时使用机器学习框架Keras+Tensorflow搭建了学习环境,并在基于OMNet++离散时间仿真器上构建了目标网络环境,实现了两个平台的交互仿真。对于网络拓扑,采用了14个节点和21条链路的拓扑节点度为3的网络拓扑,并假设各条链路带宽相同,链路上无时延。实验中设置了分别占据全网总带宽不同的10种流量强度从12.5%到125%,对于每个流量强度在相同的流量总量情况下使用重力模型生成了100个二维14×14的流量矩阵。从而生成了具有差异化的流量总量与不同流量分布的1 000个流量矩阵用于智能体的训练与测试。此外,设计了一套完整的训练和测试方案使得智能体在10种混合网络负载下的训练集合进行训练。通过对训练后模型的性能测试验证了算法优化的有效性与收敛性。首先验证了在不同流量强度等级下DDPG算法动作空间离散化的性能优势,之后评估了智能体在使用了动态权重策略下进行原始信息处理后的优化性能。
3.2 动作空间离散化训练测试
使用10种不同流量分布的流量矩阵分别在连续动作空间上智能体和离散化动作空间的智能体进行10万步的训练。算法的批量梯度下降值设置为256,并利用占总网络容量分别为25%,50%,75%,100%的4种流量强度重新利用重力模型分别生成100个TM进行测试。在智能体进行10万步的训练过程中,每隔2 000步则会记录下当前智能体神经网络参数用于测试。由OMNet++离散仿真环境返回的网络时延作为奖励值。为保证数据的可靠性,相同训练步数和相同负载下的流量矩阵所得的测试结果取平均值,作为优化算法的测试标准。通过不同的动作离散化程度进行了测试结果的比较。该仿真中设置了Δ=0.2和Δ=0.1用于对比分析其性能。
实验结果如图4所示,在不同的网络负载下,智能体通过训练后可以有效地降低网络的平均时延,并随着训练步数增大网络时延不断减少。在不同网络负载的情况下利用动作空间离散化方法相较初始算法性能上有了巨大的提升,当Δ取值越小时划分的动作空间越精细其空间离散化维度越高,则需要更多步数训练来使智能体收敛。在中低网络负载下,由于整体网络状态空闲,网络性能优化空间有限需要在更精细动作空间上探索,当Δ=0.1时有利于在优化空间较小的网络拓扑中寻找到最优链路权值,在网络负载25%的情况下全网平均时延优化提升了9%。当网络负载较高时网络优化空间大,需要从网络整体上把控主要缓解个别拥堵的链路,此时用Δ=0.2划分动作空间,智能体极大程度上减少了无效动作的探索,同时防止了陷入局部最优和降低向回报值小的梯度方向更新的概率,利于最优策略探索并且加速了智能体收敛速度,在网络负载75%和100%的情况下全网平均时延优化分别提升了5.41%和6.85%。

图4 优化模型性能测试Fig.4 Optimize model performance test
3.3 状态预处理训练测试
在进行状态预处理模型测试时,使用重力模型生成十种流量负载下的1 000个流量矩阵分别用在已训练10万步的两个模型上,模型可以依据当前流量矩阵在不同训练步数下通过一步预测输出符合当前网络流量状况的理想路由,之后对所有的时延数据构造箱型图用于数据分析。矩阵模块中的上部与底部分别代表的是所得时延观测到数据的上四分位数和下四分位数值,并且矩形中间横线所代表的时延观测数据的平均值数,而由矩阵延伸出来的直线的上端与下端分别代表了在上四分位数和下四分位数的1.5·IQR(IQR为四分位数范围:上四分位数-下四分位数)内的最低和最高的数据值,在上端和下端之间为外限,外限之外的数字为异常值并显示为一个小型菱形。
如图5所示,在进行了状态预处理的智能体能够随着训练步数的增加而不断减小全网的平均时延,训练10万步后的智能体比第2千步有了巨大的提升。在进行了状态预处理过程后的智能体在学习的过程中表现得更加平稳,减小了神经网络向错误梯度更新方向概率整个学习效果呈现逐步变优的趋势。表1展现了不同流量负载下8种测试步数下的异常值总数,使用网络流量矩阵训练的模型在测试过程中异常值总数为91个,而在经过状态预处理后测试过程中为43个,异常情况大量减少验证了预训练后智能体的模型有着更强的稳定性和鲁棒性。

图5 DRL训练过程Fig.5 DRL training process

表1 异常值数据对比统计
由于状态动作信息的非相关性导致利用流量矩阵学习网络链路权重的训练过程过于复杂,尽管其优化效果明显但是训练过程表现出了不稳定的情况,智能体在训练的后期无法稳定在已学习到的优秀策略上如图6所示。在智能体学习过程中,流量矩阵的状态复杂性使得没有经过状态处理过的智能体并未充分学习到在当前流量状况下的最优路由,在测试模型的后期仍有往不好策略探索的趋势。而在减少了神经网络输入的状态维度并对输入的网络流量状态进行了预训练后,增强了状态与动作的关联度,输入的状态信息和动作信息成为了直接相关信息,降低了寻找最优策略的难度。在流量强度过高的情况下超过负载75%情况下,经过状态预处理的智能体有着更强的稳定性和可靠性并相较于未预处理模型能学到更优的路由策略网络平均时延的收敛值更低。

图6 智能体性能对比Fig.6 Agent performance comparison
4 结束语
针对高维度大规模的网络的路由优化,在原有深度强化学习DDPG算法上进行了提升和改进,使得增强后的DDPG算法更适合解决网络路由优化的问题。本文提出了动态权重策略,可利用当前网络流量构造出符合当前网络流量状态的链路权重,提前对原始信息做了二次加工生成了智能体的先验知识,增强了神经网络中动作状态的潜在关联度。神经网络在初始权重上继续学习,降低了其学习依据流量状态到路由策略动作的困难,减少了朝向错误策略参数梯度更新的概率,增强了模型学习的稳定性。并针对高纬度大规模网络的连续动作空间进行了动作空间离散化处理,有效降低了动作空间的复杂度加快了收敛速度。实验表明:与原有的DDPG算法相比,两种优化方法对于路由优化和训练的稳定性有着良好的提升,在网络拥塞、网络负载大的情况下尤为突出。该优化方法与训练方法可以适应不断变化的流量和链路状态,提升了强化学习训练模型后应对不同网络状态的稳定性,降低了网络平均的时延,提升了网络性能。
