一种基于U-Net的图像去模糊方法
2022-06-24张乾俊廉佐政赵红艳
张乾俊,廉佐政,赵红艳
一种基于U-Net的图像去模糊方法
张乾俊,廉佐政,赵红艳
(齐齐哈尔大学 计算机与控制工程学院,黑龙江 齐齐哈尔 161006)
针对现有深度学习的图像去模糊方法存在网络接受域小、制约去模糊效果的问题,提出了一种改进的U-Net(U形卷积神经网络)模型,该模型使用深度可分离卷积实现标准卷积操作,以减少模型计算和参数.模型中嵌入小波变换,分离图像的上下文和纹理信息,降低模型训练的难度.设计的密集多接受域通道模块可以提取图像细节信息,从而提高小波重构图像的质量.实验表明,该方法在峰值信噪比(PSNR)和结构相似性(SSIM)方面具有较好的性能,模型参数较少,图像恢复时间较短.
深度可分离卷积;U-Net模型;密集多接受域通道模块;小波变换
目前,模糊图像广泛存在,引起图像模糊的原因很多,如光学系统的像差、成像过程中目标的相对运动、低光照、环境噪声等.这些模糊图像不仅主观上影响视觉体验,而且影响了目标检测等后续的视觉任务.因此,图像去模糊是计算机视觉中的一个关键性问题.图像模糊问题的解决方法主要包括非盲和盲去模糊两大类,前者需要已知图像的模糊过程,来确定模糊核函数,后者则不需要.在实际应用中,模糊图像的模糊过程大多是未知的,因此盲去模糊方法应用广泛.传统的盲去模糊方法大多采用正则化和手工制作图像先验来估计模糊核,再用迭代优化的方式逐步恢复清晰图片,这就涉及复杂模糊核的估计,导致去模糊的过程繁琐,实时性差,算法的性能不高.随着深度学习快速发展,基于深度学习的盲去模糊方法[1]已逐步得到应用.欧阳宁[2]等基于对抗网络提出一种基于自适应残差的运动图像去模糊方法,能够重建出纹理细节丰富的高质量图像.Nah[3]等提出基于深度学习端到端去除图像模糊,用多尺度卷积神经网络直接从模糊图像恢复到清晰图像.毛勇[4]等用生成对抗网络设计车牌去运动模糊模型,有效去除合成运动模糊图像和真实场景下运动模糊图像中存在的运动模糊.Tao[5]等提出一种基于高分辨率特征保持的图像去模糊网络,并行连接由高至低各分辨率特征子网络,无需由低分辨率到高分辨率的重建过程.Zhang[6]等使用卷积神经网络(Convolutional Neural Networks,CNN)学习每个位置的循环神经网络(Recurrent Neural Networks,RNN)的像素权重,来增加接受域.用RNN或CNN只能捕获小部分领域信息,无法有效获得全局上下文依赖信息.Zeng[7]等采用了密集网络来进行图像的去模糊,可以避免梯度消失问题.
文献[1-7]的方法存在网络的接受域较小的问题,不能获取更多的图像信息,影响了图像的去模糊效果.本文针对这些问题,提出新的方法,即构建了U-Net(U-shaped Convolutional Neural Network)模型,分析了去模糊原理,并通过实验进行效果评估,验证了该方法具有良好的去模糊效果.
1 基于U-Net的去图像运动模糊方法
1.1 模型设计
本文设计的模型见图1.该模型由深度可分离卷积、深度可分离残差卷积、哈尔小波变换、密集多接受域通道模块组成.模型左侧为编码器,右侧为解码器.为了减少网络模型中参数,编码器用深度可分离卷积实现卷积操作,用深度可分离残差卷积完成残差卷积.使用二维离散哈尔小波来实现下采样,以获取到图像不同频率的上下文和纹理信息,降低计算复杂性,减少训练难度.在深层编码时使用了密集多接受域通道模块,来获取不同尺度的图像信息,缓解梯度消失、重用特性的出现.在解码阶段,用哈尔小波的逆变换来实现上采样过程,减少图像信息的损失.再通过深度可分离卷积和深度可分离残差卷积对图像进行有效重建.对模型的关键部分小波变换及其逆变换、密集多接受域通道模块进行分析.
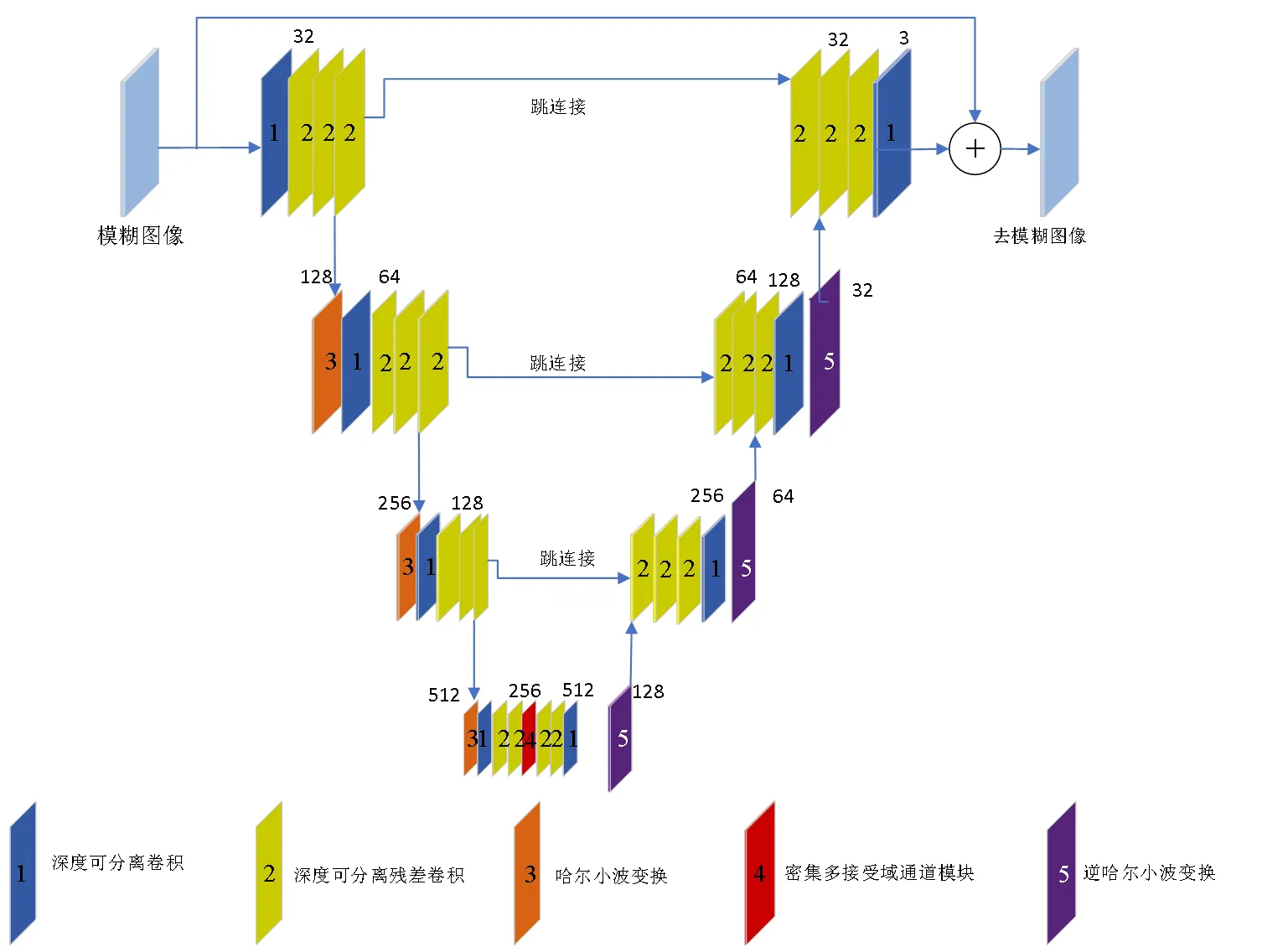
图1 模型设计
1.2 哈尔小波变换及其逆变换
哈尔小波是小波变换中最易于实现、操作简单的一种变换,因此本文用二维离散哈尔小波变换及其逆变换实现图像下采样和上采样操作,即实现图像的分解和重构,其过程见图2.图2左半部完成小波变换,首先沿着列方向进行行滤波,再进行下采样,然后将得到的滤波结果沿着行方向进行列滤波,再下采样,从而获得4个不同的频带,一个近似分量A,水平、垂直、对角等方向的3个细节分量H,V,D.图2右半部完成小波逆变换,首先对D,V进行上采样,再沿着列方向进行行滤波,H,A也做同样的操作.然后将其结果进行上采样,再沿着行方向进行列滤波,最后将滤波结果融合,得到重构的去模糊图像.这个过程中不仅避免图像信息丢失,且会生成更多的高频信息.因此,可以获得清晰的图像.
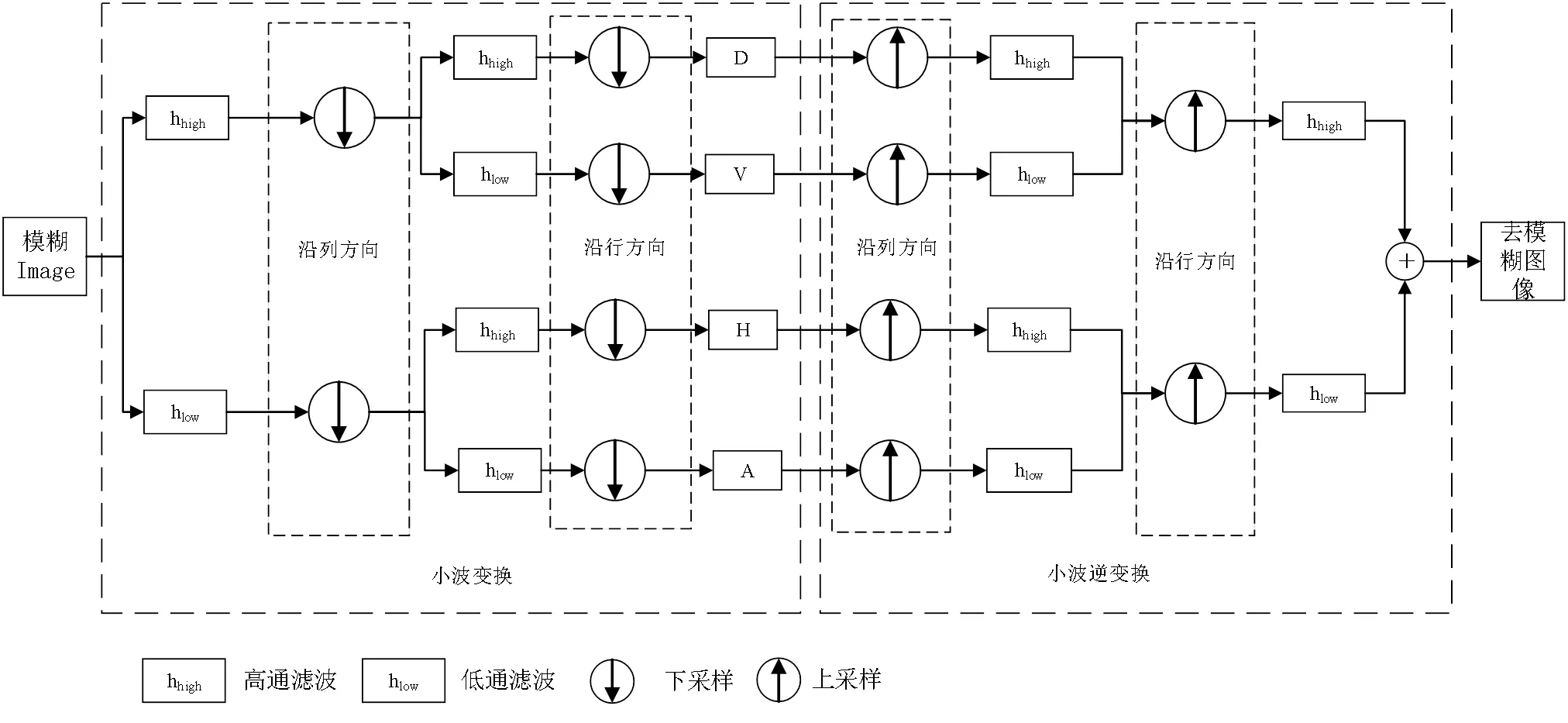
图2 小波变换及其逆变换
1.3 密集多接受域通道模块
为提取图像的深层语义信息,提高图像去模糊的性能,提出密集多接受域模块.密集多接受域通道模块,由4个多接受域通道块和1个瓶颈层组成(见图3).通过多接受域通道块来提取图像的语义特征,再用瓶颈层来减少特征输入的数量,来提高模型的紧凑性和计算效率.用密集连接的方式,来加强图像特征的传递,更加有效地利用图像特征.密集多接受域通道模块表示为
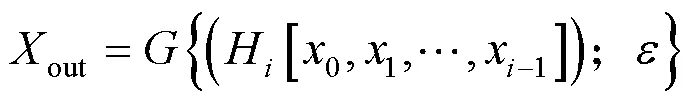
式中:表示串联层混合的接受域块所产生的特征图;表示将多个输入张量转化为单个张量;表示瓶颈层的输出;为瓶颈层的超参数,瓶颈层采用的滤波器大小为1×1.
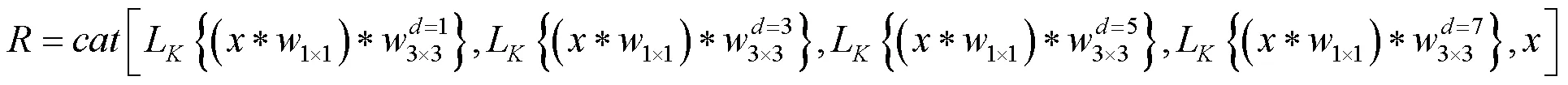
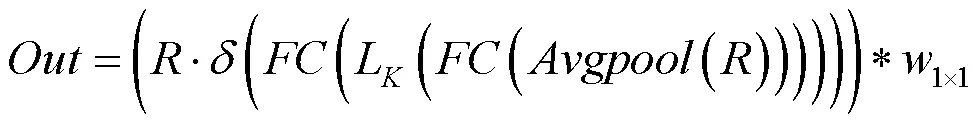
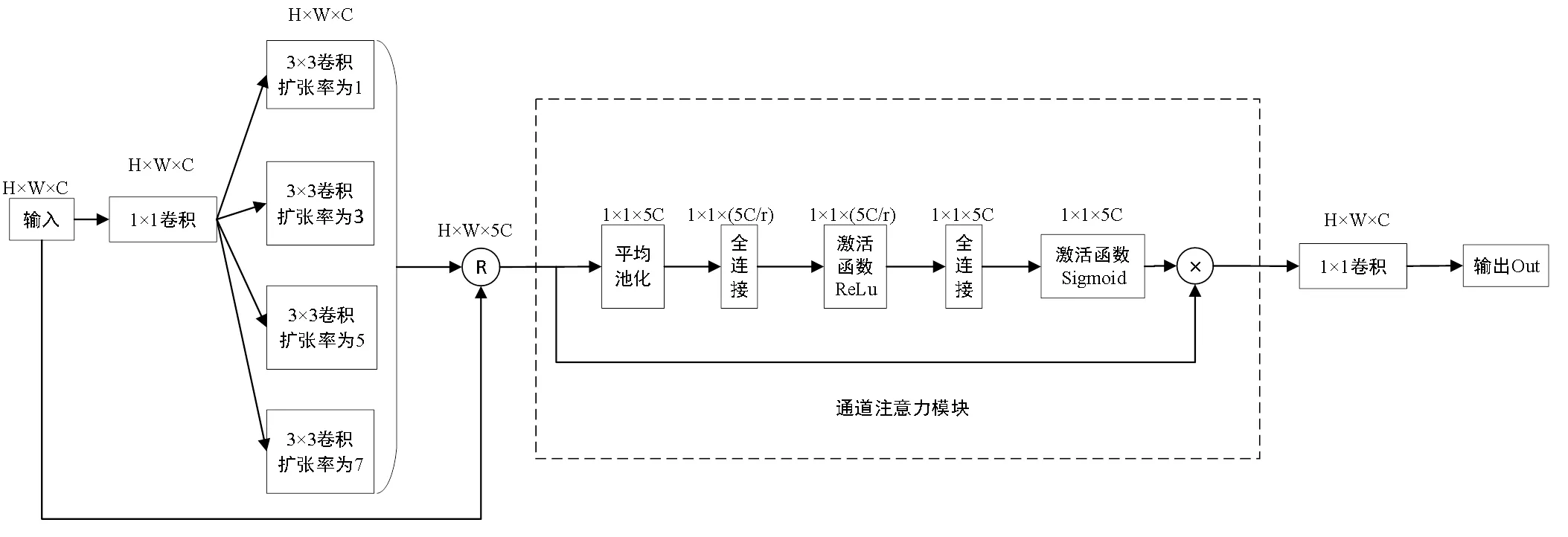
图4 多接收域通道块
2 实验分析
2.1 实验准备
本文使用了GOPRO数据集[8]来训练本文的模型,它由3 214模糊清晰图像对组成,包含了22个不同的场景.选用2 103对图像作为训练集,1 111对图像作为测试集.为了提高模型的泛化能力,对训练集进行数据增强操作,分别采用随机旋转,随机左右、上下翻转,高斯噪声,旋转角度为90°,180°,270°,噪声均值为0,方差为0.000 1.
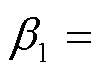
2.2 损失函数
图像去模糊采用均方误差(MSE)损失作为常用指标,通过使用欧式距离来测量预测值与实际值之间的差值
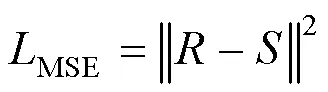
同时为获得图像边缘细节信息,使用了SSIM损失函数[10]
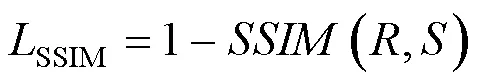
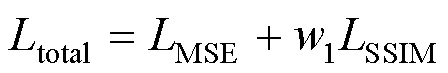
2.3 效果评价
使用峰值信噪比(PSNR)和结构相似度(SSIM)来作为评价指标,它们的值越大,代表图像的质量就越好,计算公式
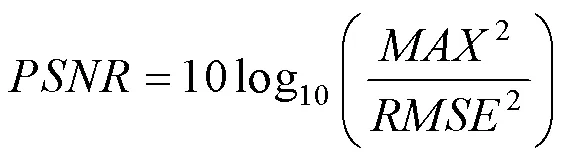
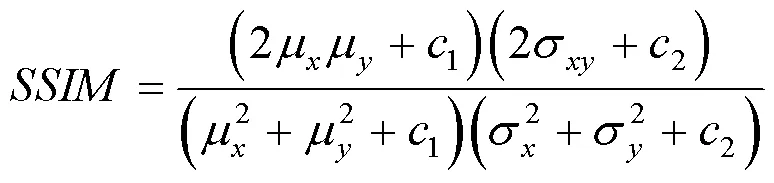
本文方法的平均PSNR和平均SSIM与其它方法的比较情况见表1.通过比较发现,本文方法在PSNR和SSIM方面优于其他方法,比文献[5]的PSNR高0.59,SSIM高0.014.

表1 各算法在数据集上的定量评估
本文方法在GOPRO测试数据集上所用的时间、模型参数大小见表2.本文比文献[3]和文献[5]的所需的时间更少,模型参数更小.

表2 各算法在数据集上的运行时间和网络模型大小
3 结语
本文提出了一种基于改进U-Net模型的图像去模糊方法,该方法引入了二维离散哈尔小波,并设计了密集多接受域通道块.模型中的下采样采用小波变换,上采样采用小波逆变换,从而获得了更多的图像细节,降低了计算复杂度.密集多接受域通道块以密集连接方式连接多个接收通道块,增强了网络的传输能力.本文的方法不仅可以显著降低模型的参数,而且可以减少模型恢复清晰图像的运行时间,达到良好的图像去模糊效果.
[1] 潘金山.基于深度学习的图像去模糊方法研究进展[J].计算机科学,2021,48(3):9-13.
[2] 欧阳宁,邓超阳,林乐平.基于自适应残差的运动图像去模糊[J].计算机工程与设计,2021,42(6):1684-1690.
[3] Nah S,Kim T H,Lee K M.Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring[C]// IEEE Computer Society.2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu,USA:IEEE,2017.
[4] 毛勇,陈华华.基于深度学习的车牌图像去运动模糊技术[J].杭州电子科技大学学报,2018,38(5):33-37.
[5] Tao X,Gao H,Wang Y,et al.Scale-recurrent Network for Deep Image Deblurring[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,USA:IEEE,2018.
[6] Zhang J,Pan J,Ren J,et al.Dynamic Scene Deblurring Using Spatially Variant Recurrent Neural Networks[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Salt Lake City,USA:IEEE,2018.
[7] Zeng Tao,Diao Changyu.Single Image Motion Deblurring Based On Modified DenseNet[C]//2020 2nd International Conference on Machine Learning,Big Data and Business Intelligence(MLBDBI).Chengdu:Institute of Electrical and Electronics Engineers Inc,2020.
[8] 黄彦宁,李伟红,崔金凯,等.强边缘提取网络用于非均匀运动模糊图像盲复原[J].自动化学报,2021,47(11):1-17.
[9] Liu H L,Tian X.AEGD:Adaptive Gradient Decent with Energy[J/OL].arXiv preprint arXiv 2020,1(1):1-25. https://arxiv.org/abs/2010.05109.
[10] Wang Z,Bovik A C,Sheikh H R,et al.Image quality assessment:from error visibility to structural sim-ilarity[J]. IEEETransactions on Image Processing,2004,13(4):600-612.
An image deblurring method based on U-Net
ZHANG Qianjun,LIAN Zuozheng,ZHAO Hongyan
(School of Computer and Control Engineering,Qiqihar University,Qiqihar 161006,China)
The existing deep learning image deblurring methods have the problems of small network receptive field and restricting the deblurring effect,an improved U-Net(U-shaped Convolutional Neural Network)model is proposed.The model uses depth-wise separable convolution to archive standard convolution operation to reduce model calculations and parameters.The wavelet transform is embedded in the U-Net model to separate the context and texture information of the image and reduce the difficulty of model training.In order to improve the image quality of wavelet reconstruction,dense multi-receptive field channel module is used to extract image detail information.Experiments show that the image deblurring method has better performance in PSNR(peak signal-to-noise ratio)and SSIM(structural similarity),with fewer model parameters and shorter recovery time.
depth-wise separable convolution;U-Net model;dense multi-receptive field channel module;wavelet transform
1007-9831(2022)05-0047-05
TP391
A
10.3969/j.issn.1007-9831.2022.05.008
2022-01-20
黑龙江省高等教育教学改革研究项目(SJGY20200770,SJGY20190710);齐齐哈尔大学教育科学研究项目(ZD201802)
张乾俊(1996-),男,陕西汉中人,在读硕士,从事深度学习应用研究.E-mail:1123495150@qq.com
廉佐政(1977-),男,黑龙江海伦人,副教授,硕士,从事机器学习与人工智能应用研究.E-mail:lianzuozheng@163.com
