一种基于FPGA的高性能MobileNet加速器
2022-06-24周冠宇
周冠宇
(南京航空航天大学,江苏 南京 210016)
0 引言
目前,深度学习在图像分类、目标检测、机器翻译、语音识别以及其他相关领域都取得了很多成果。卷积神经网络(convolutional nerual network)作为深度学习最具代表性的算法之一,近几年来也取得了极大的发展,一些新的优化算法和改良的卷积神经网络模型结构被不断提出。
MobileNet是谷歌在2017年发布的一种轻量级卷积神经网络模型[1],与传统的卷积神经网络模型相比,它在保证精度损失不大的前提下,弥补了传统卷积神经网络模型过于巨大导致的无法应用于嵌入式设备的不足。目前基于MobileNet的现场可编程门陈列(field programmable gate array, FPGA)实现[2-5]主要集中在通过增加资源的使用量来提高分类速度,很少考虑硬件结构上的优化,对计算资源的浪费情况较为严重。针对上述不足,本文设计了一个高性能的FPGA硬件架构和加速单元,并与现有的MobileNet模型进行了性能及结果分析。
1 方法论述
MobileNet模型的关键点在于使用深度可分离卷积代替了普通的卷积结构。得益于深度可分离卷积的特点,MobileNet在精度损失不大的情况下,大大减少了整个网络中的参数量和计算量。
深度可分离卷积结构如图1所示。它可以被分为两个更小的操作:深度卷积和可分离卷积。深度卷积的输入特征通道数和输出特征通道数数目相等,各个输入通道相互独立。可分离卷积在计算方式上其实就是普通的卷积,只不过采用的是1×1的卷积核,因此它也被称为点卷积。

图1 深度可分离结构
深度卷积的表达公式如式(1)所示。
(1)
式中:K是深度卷积核权重;下标i,j表示作用在通道m上的卷积核像素点的位置;G代表特征图输出;k和l代表输出特征图的大小。
点卷积的表达公式如式(2)所示。
(2)
式中:Yi,N代表第N个输出通道第i个位置的点卷积值;xi代表输入第i个通道输入特征图上的像素点;Wi,N代表输出第N个通道对应于第i个输入通道的权重。
MobileNet的基本结构如图2所示。标准卷积、深度卷积以及点卷积后都会紧跟批量归一化(batch normalization, BN)以及激活函数ReLU层。

图2 MobileNet基本结构
BN主要有加快卷积神经网络的训练和收敛速度、防止过拟合、控制梯度爆炸3个作用。它将所有样本上每个特征的值归一化为平均值为0且方差为1的数据。这使卷积值落入非线性函数有效值区域的中心,从而避免了梯度消失。在网络训练后完成,批量归一化层可由式(3)表示。其中γ与β值为常数。
y=γx+β
(3)
激活函数给卷积神经网络内部带来了非线性,ReLU函数如式(4)所示。
ReLU(x)=max(0,x)
(4)
池化层也被称为下采样层,其具体操作与卷积层的操作基本相同,只不过池化层的运算操作为只取对应窗口内的最大值、平均值等(最大池化、平均池化),即矩阵之间的运算规律不一样,并且不经过反向传播的修改,平均池化过程可用式(5)表示。
(5)
Softmax函数在深度学习中负责将多个神经元的输出,映射到(0,1)区间内,输出的数值可以看成概率,从而来进行图像分类。函数公式如式(6)所示。
(6)
2 硬件加速
2.1 系统架构
本文设计的卷积神经网络加速系统采用“ARM+FPGA”的架构(图3),ARM侧除了初始配置以及最后对结果的处理外,没有参与到系统中间的运算以及数据传输中,这显著降低了系统运行过程中ARM与FPGA通信所需的时间,提供了更高的计算效率。
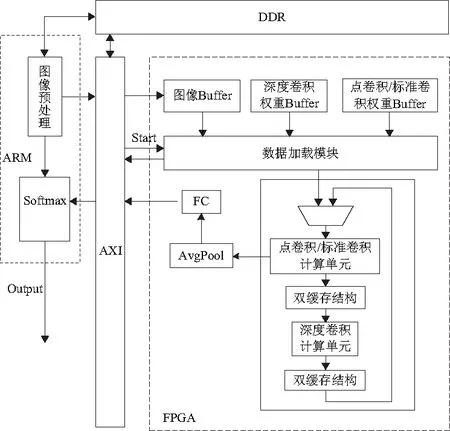
图3 系统架构
卷积运算模块是整个硬件结构的核心,其内部由深度卷积运算单元和点卷积运算单元组成。由于FPGA内部资源有限,不能将整个MobileNet网络模型以平铺式的架构在FPGA上实现,而MobileNet各层之间的计算方式存在极高的相似性。因此采用分时复用单层计算资源的方式来实现整个网络。该模块中的深度卷积运算单元和点卷积运算单元的图像缓冲区域均为双缓冲结构:一个是工作缓冲,负责存储上一层网络的输出特征图;另一个是结果缓冲,负责存储本层网络的中间结果。
2.2 卷积运算单元
1)并行化深度卷积运算单元设计
每一个深度卷积计算单元DWC Unit负责一个输入通道的计算,其结构如图4所示。深度卷积的卷积窗口为3×3,卷积窗口内各个像素点在进行乘累加时相互独立,无依赖关系。因此本文在空间上对该卷积过程展开,进行卷积核内部的并行处理。一个DWC Unit内包括9个乘法单元,mult用来执行乘法操作,mult间通过加法树连接,一个周期就可以计算得出一个像素点,之后计算出来的像素点经过BN层以及ReLU激活函数被送入双缓冲结构中进行暂存。多个DWC Unit同时进行多个输入通道的并行计算也可以加快网络层计算的吞吐量,本文设置4个DWC Unit同时计算,不同DWC Unit计算得出的结果被送至不同的片上缓存区域。

图4 并行化深度卷积计算单元结构
2)并行化点卷积运算单元设计
从第二节的分析中可以看出,标准卷积层与点卷积层的结构类似,只是卷积核窗口大小不同。而整个MobileNet网络结构中只有第一层为标准卷积结构,如果单独设计标准卷积结构,那么在第一层计算完毕后,用于进行标准卷积的计算单元会进入空闲状态,造成较大的资源浪费。因此,本文设计了PWC Unit计算单元,使其能够实现标准卷积以及点卷积两种网络层的运算,节省了资源,同时优化了数据流向,更有利于流水线的形成。PWC Unit计算单元结构如图5所示,每一个PWC Unit中只包含一个mult用来进行3×3或者1×1的卷积运算,不再考虑卷积核内部的并行处理。卷积结果经过BN和ReLU后经过加法树后送入数据分散模块。由于深度卷积层与点卷积层之间存在数据依赖性,因此深度卷积与点卷积计算单元的个数需要保持一致。而点卷积的结果计算后需要经过数据分散模块分散存储在不同的片上缓存区域中才能满足深度卷积计算单元的计算要求。
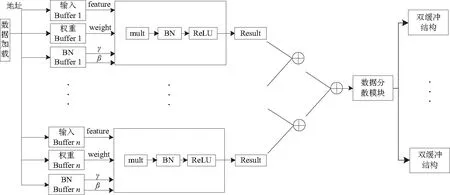
图5 并行化点卷积计算单元结构
2.3 时序策略设计
本文时序策略分为两块,整个方案采用分时复用卷积计算模块的方式实现,网络模型中的各卷积层都通过一个卷积计算模块进行实现。而在深度卷积与点卷积计算单元之间,采用层间流水的方式进行两者的并行运算。当ARM侧向FPGA侧发出启动信号后,标准卷积开始进行计算。当标准卷积计算得出深度卷积需要的第一个卷积窗口时,深度卷积开始启动并与标准卷积同时进行运算。由于点卷积和标准卷积共用一个计算模块,因此当标准卷积层计算完毕,解除对计算模块的占用后,深度卷积和点卷积才会同时进行运算,在标准卷积计算完成之前,深度卷积的结果会暂存在片上缓存中。缓存区域均采用双缓存结构,当第n层深度卷积正在进行运算时,由于本文采用了层间并行运算的设计方式,此时点卷积计算单元正在进行n-1层的运算,它的输入是n-1层深度卷积的计算结果,因此深度卷积计算单元得到的结果需要被存放在结果缓冲中,点卷积计算单元需要的输入特征图则是从工作缓冲中读取,这种结构保证了当前层正在参与计算的数据结果不会被计算出来的输出特征图覆盖,同时减少了对外部存储的访问,提高了整个网络的运行速度。
3 实验结果
3.1 实验平台
本文采用的PYNQ板卡作为加速器验证平台,内嵌Xilinx XC7Z020 FPGA芯片。整个硬件系统架构为ARM+FPGA的异构架构。硬件开发使用的是某公司提供的Vivado 2017.4开发环境,软件开发环境为Xilinx SDK 2017.4。
3.2 实验结果
在100MHz工作频率下,本文设计的加速器资源使用情况如表1所示。通过分析可以发现DSP48E和BRAM是使用最多的两种资源,这主要是因为模型中存在大量的乘法运算以及中间结果被全部缓存在BRAM。
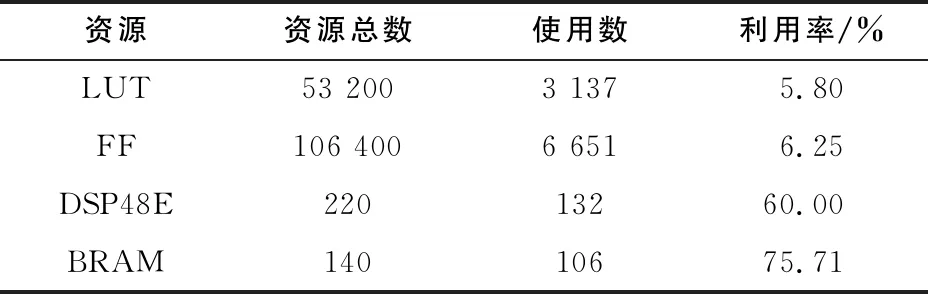
表1 资源使用数量
与其他文献的工作对比如表2所示。

表2 本设计与现有成果对比
对表2分析可知,与文献[2]和文献[3]相比,本设计使用的资源较少,同时实现了较高的分类速度。
4 结语
本文针对MobileNet的网络结构,提出了深度流水化的加速器优化方案。设计了一种时序控制策略,使得深度卷积层和点卷积层能够同时计算来减少两者之间的计算等待时间;设计了一种系统架构来有效地减少处理器与FPGA的通信次数;设计了能够同时支持标准卷积与点卷积计算的计算单元,节省了资源。本文提出的加速器在工作频率为100MHz的情况下,FPS可以达到135.2。
