随机森林方法支持下Sentinel-2A MSI多种特征的冬小麦识别分析
2022-06-23朱永基殷飞笺陶新宇李新伟刘吉凯
朱永基, 殷飞笺, 王 晗, 陶新宇, 李新伟*, 刘吉凯
(1. 安徽科技学院 资源与环境学院,安徽 凤阳 233100; 2. 山东省气候中心,山东 济南 250031)
遥感技术的高速发展促使农业生产管理从传统粗放式管理阶段进入精细化、定量化和智能化阶段[1-2],如何实现作物类别的准确分类已经成为当前农业遥感的热点问题之一。
在作物遥感识别方面,常规的方法多是基于影像的光谱特征,但由于“同物异谱、异物同谱”的存在,对于生育期相似的作物识别效果较差[3]。植被指数可以在不同程度上扩大反射波段间的差距,增加作物与其易混淆地物间的可分离性,同时能有效抑制背景信息,成为作物识别研究不可或缺的重要特征,被广泛应用于各级农情遥感监测的业务化系统中。此外,研究表明纹理特征可以兼顾作物的宏观特征和微观细节,具有较强的稳定性,能够弥补基于影像光谱特征和植被指数分类的缺陷,可以有效地区分作物类别及其耕作方式(如行播)[4]。
近年来,机器学习分类方法在农作物类别提取中广受关注[5]。在众多机器学习算法中,随机森林方法具有训练速度快、实现简单、精度高、易实现并行化、抗噪声能力强的优点,目前在国内外各领域中得到了广泛的应用[6]。李长春等[7]利用多源多生育期Sentinel遥感数据,构建光谱特征、植被特征和极化特征的多模态特征数据集,采用随机森林算法对县域冬小麦种植面积进行提取,发现单生育期的光学影像和融合影像在成熟期的识别精度最高。刘杰等[6]利用多时相Landsat8 OLI数据,融合光谱、纹理和植被指数等多维特征信息,采用随机森林方法实现了多种作物类型的精细识别。虽然多时相光学遥感数据在作物信息识别研究取得了大量的研究成果[3],但光学遥感数据易受云雨雾等天气因素的影响,在区域应用时难以获得作物生长季节的完整数据。另外,考虑到多时相数据运算时的成本开销,对作物关键生育期遥感影像信息的深度挖掘显得尤为重要。因此,本文以安徽省冬小麦主产县——怀远县为研究区,利用冬小麦关键生育期(2018年4月17日)的Sentinel-2A MSI数据,基于研究区冬小麦的光谱反射率、植被指数和纹理特征,采用随机森林算法实现多种特征支持下的冬小麦识别分析,以期为冬小麦精准识别的进一步研究提供参考。
1 材料与方法
1.1 研究区概况
怀远县(116°45′-117°09′E,32°43′-33°19′N)位于淮北平原和江淮丘陵的交接地带,地形以平原为主,地势西北高,东南低,自然坡降约为万分之一,部分地区分布有少量的丘陵和台地;属亚热带季风气候,年平均温度15.4 ℃,年降雨量900 mm。怀远县资源丰富,是全国产粮百强县。全县常用耕地面积220万亩,常年小麦种植面积180万亩,粮食总产在粮食主产县中居全国前20位,全省前5位。研究区主要种植作物为冬小麦、玉米和油菜等,其中冬小麦一般10月中下旬播种,11月出苗,次年3月返青,4月上旬孕穗,4月中下旬抽穗,5月上旬灌浆,5月下旬乳熟,6月上旬收割。
1.2 数据源与预处理
4月中旬,研究区内冬小麦长势旺盛,与其他作物农事历区别明显,本研究选择2018年4月17日的Sentinel-2A MSI数据,L1C级别,下载自ESA SciHub(https://scihub.copernicus.eu/dhus/#/home)。Sentinel-2AMSI数据覆盖13个光谱波段,幅宽达290 km,地面分辨率分别为10、20和60 m,重访周期为10 d,其中含有3个红边波段(表1)[8],可以敏锐地感应作物波谱特征,目前已成为开展农作物分类研究的主要数据源之一[9]。
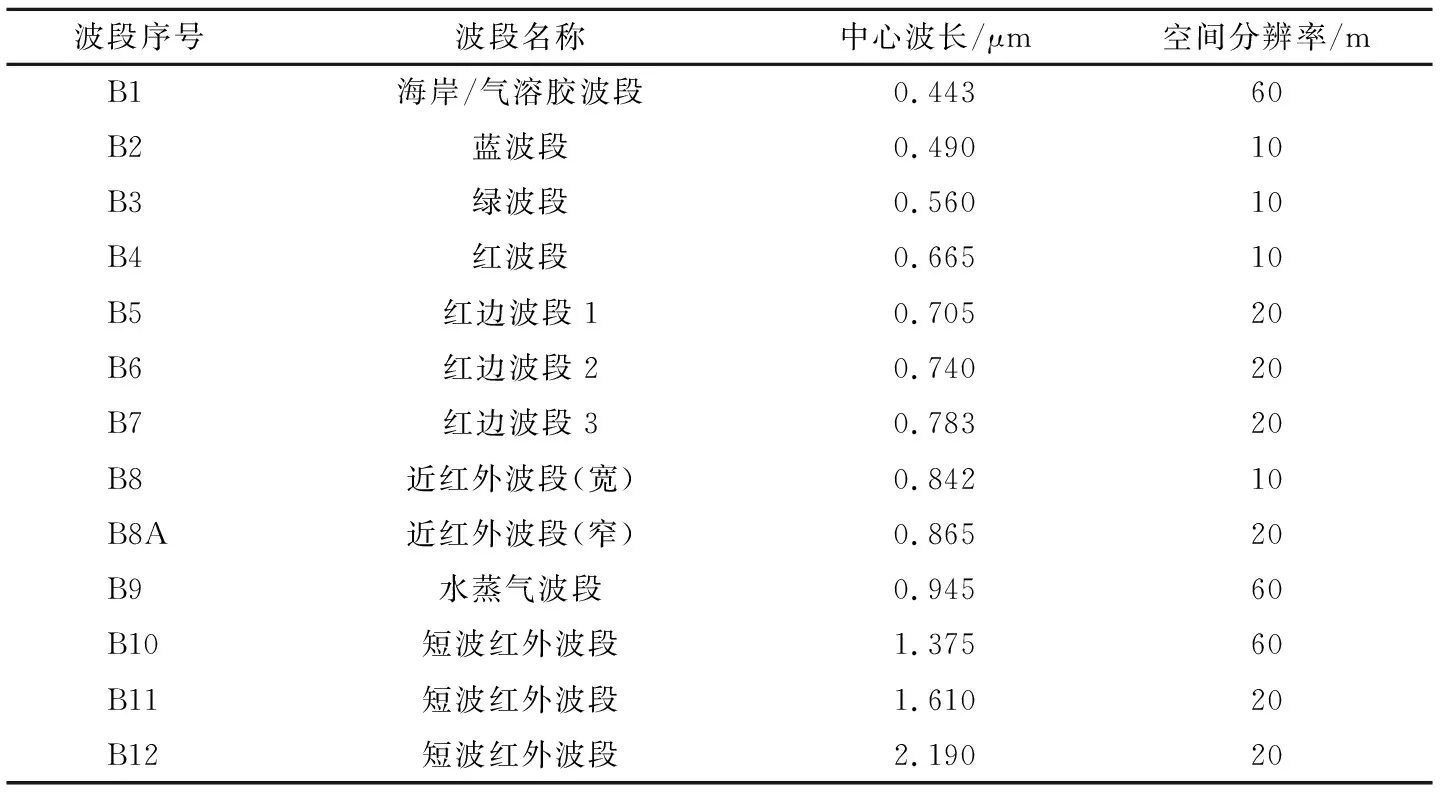
表1 Sentinel-2A卫星波段信息
L1C级数据是经过正射校正的产品,本文仅对其进行辐射定标和大气校正,其中大气校正采用ENVI软件的FLAASH模块,FLAASH模块参数设置均参考相关文献[10-14]。因原始数据具有3种空间分辨率,为统一分辨率,降低分辨率不一致带来的误差,本文采用双线性内插法统一空间分辨率为20 m。对重采样后的影像进行主成分分析,利用第一主成分采用灰度共生矩阵(Gray-level Co-occurrence Matrix, GLCM)的方法提取纹理特征。
1.3 样本数据
本研究以经地理配准后的4米高分辨率16级Google Earth影像为基础,根据前期调查资料和历史文献数据,通过目视解译方式确定4月中旬研究区的5种典型地物:冬小麦、休耕地(已播种未出苗和尚未播种地)、草地、灌木林地、裸地、建筑物。因休耕地和裸地地块光谱特征相似,为减少误差,将二者统一为裸地。共获取样本地块93块,3 672像元,其中冬小麦地块29块,像元数1 357。获取初始样本后,利用J-M距离(Jeffreys-Matusita距离)评价样本的可分离性,保留可分离性大于1.8的样本。为了测试随机森林方法的普适性,将获取的样本数据按照3∶7分为训练集和验证集。
1.4 特征提取
光谱反射率是地物对某一波段光谱反射量与入射量的比值,不同地物对光谱的反射性能不同,构成了识别地物的物理基础。植被指数(Vegetable Indices,VIs)是当前作物分类识别研究中的重要特征之一[15]。本研究选取在作物识别中常用14种植被指数(表2)。近年来,纹理特征被广泛应用于作物识别研究中,具有光谱特征无法比拟的优点。通过GLCM提取第一主成分的8个纹理特征[16],如表3所示。综合特征集是包含上述3种特征的融合数据集。

表2 植被指数

表3 纹理特征
1.5 随机森林分类方法
RF是由美国科学家Breiman提出的新型分类算法,能够高效处理多维特征的数据集,通过样本特征的交叉验证寻求类别归属的最优解,具有训练速度快、对样本量不敏感、分类精度高和抗噪声能力强的优点,是广泛应用于农业遥感大数据智能学习的机器算法之一[17-18]。本研究中的RF算法在EnMAP-Box (Https://www.enmap.org/news/2021-10-29)工具箱中实现。
1.6 精度评价
本研究使用到的精度评价指标为:总体精度(Overall Accuracy,OA)、Kappa系数、生产者精度(Producer’s Accuracy,PA)和用户精度(User’s Accuracy,UA)。总体精度指所有类别正确分类的像元数占总类别像元数的百分比。Kappa系数是表示分类结果比随机分类好多少的指标。生产者精度是某类别正确分类的像元数占真实类别像元数的百分比。用户精度是某类别正确分类的像元数占该类别分类像元数的百分比[14]。
2 结果与分析
2.1 基于多种特征的随机森林分类结果
构建研究区的4种分类特征数据集:光谱反射率、植被指数、纹理特征和综合特征集[19-20]。首先利用30%的训练集进行多次随机森林分类以确定RF的最佳参数设置:树数量为100,节点分裂的特征变量数为所有特征数量的平方根。然后利用调参后的随机森林方法对4种分类特征集执行分类,得到研究区的主要地物分类结果(图1)。最后,利用70%的验证样本建立分类地物的混淆矩阵,计算4种精度评价指标(表4)。

图1 基于4种分类特征集的随机森林方法分类结果
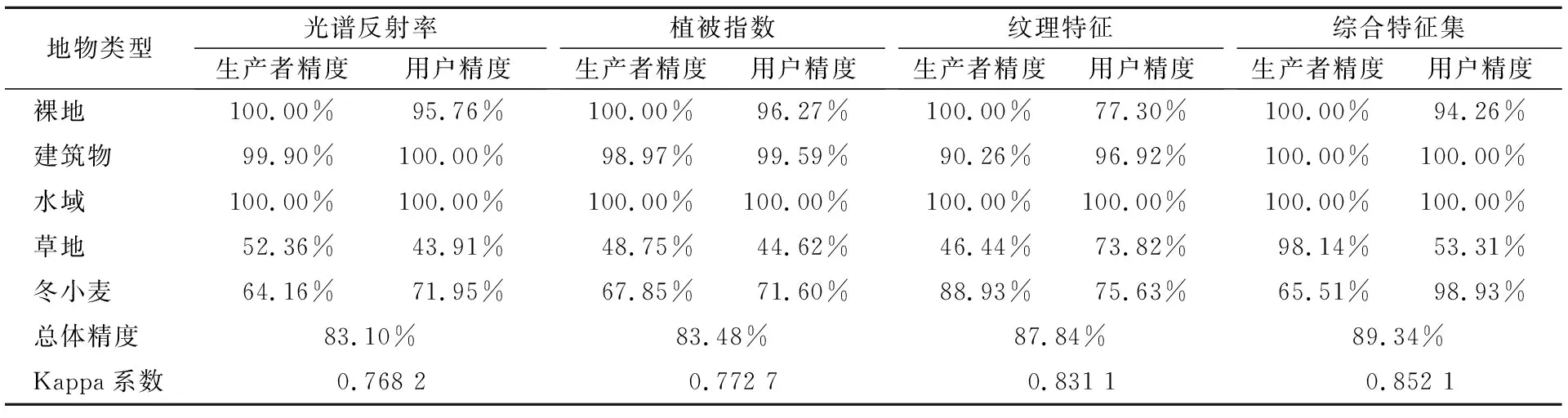
表4 基于4种分类特征集的随机森林分类精度评价
根据图1和表4可知,基于综合特征集的总体精度和Kappa系数最高,为89.34%和0.852 1,比精度最低的光谱反射率分别高了6.24%和0.083 9。基于纹理特征的随机森林分类效果仅次于综合特征集,总体精度和Kappa系数分别为87.84%和0.831 1。基于光谱反射率和植被指数的分类总体精度差异不明显,总体精度分别为83.10%和83.48%,Kappa系数分别为0.768 2和0.772 7。
对于冬小麦识别,用户精度最高的是综合特征集,为98.93%;最低的是植被指数,为71.60%。生产者精度最高的是纹理特征,为88.93%;最低的是光谱反射率,仅为64.16%。
利用综合特征集可以有效区分植被与其他地物,但对于植被内部类别的区分效果不佳,易将冬小麦与草地混淆。基于纹理特征集的冬小麦识别效果最佳,用户精度和生产者精度都大于75%,可以有效区分冬小麦与草地,因为二者的纹理差异较为明显。植被指数的整体分类精度略高于光谱反射率。
综上所述,基于植被指数与光谱反射率的随机森林方法对冬小麦的分类精度大致相同,但加入纹理特征后,冬小麦的分类精度显著地升高。
2.2 基于随机森林的分类特征选择
通过随机森林方法可以根据特征重要性实现对所有参与分类的特征的性能评价[21-22],重要性排序结果如表5所示。对分类贡献度最大的光谱波段、纹理特征、植被指数分别是B1(Deep Blue)、Variance和PSRI;贡献度最小的光谱特征、纹理特征、植被指数分别是B8(NIR)、Correlation和RVI[23-25]。
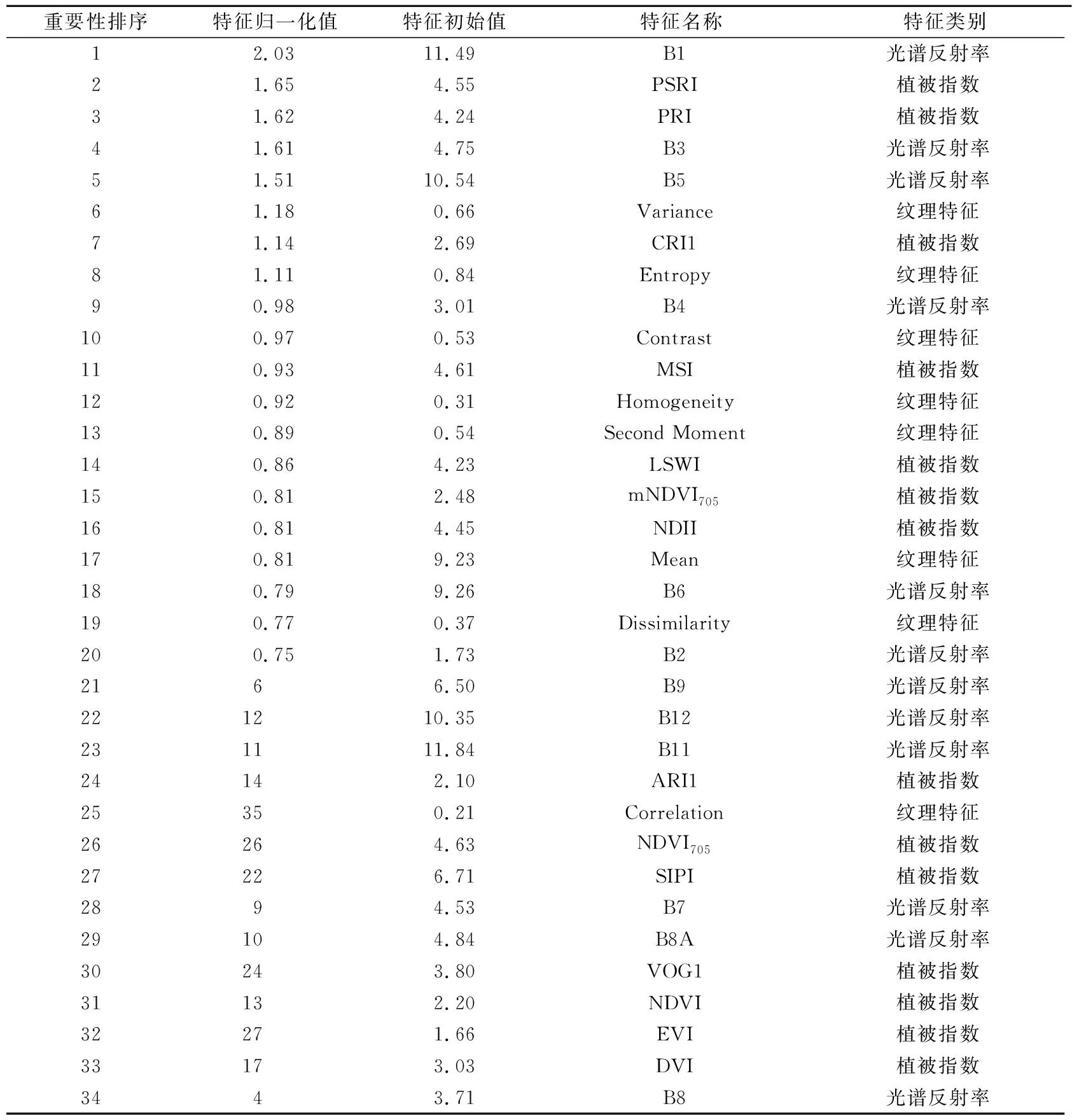
表5 不同分类特征对RF分类的贡献度
3 结论与讨论
本研究利用蚌埠市怀远县冬小麦关键生育期的Sentinel-2A MSI影像,对比分析了4种分类特征集支持下的随机森林算法对冬小麦的分类效果,得到了以下主要结论:
(1) 对于地物识别综合所有分类特征集的识别效果最好,其次是纹理特征,基于光谱反射率的识别效果最差。对于冬小麦识别,生产者精度最高的是纹理特征,最低的是光谱反射率;用户精度最高的是综合特征集,最低的是植被指数。基于光谱反射率和植被指数的分类精度差异较小。
(2)所有参与分类的特征中,对分类贡献度最大的光谱波段、纹理特征、植被指数分别是B1(Deep Blue)、Variance和PSRI;贡献度最小的光谱特征、纹理特征、植被指数分别是B8(NIR)、Correlation和RVI。
本研究基于关键生育期的单时相Sentinel-2A多光谱数据识别冬小麦信息,取得了较好的效果,虽然识别精度不如李长春等[7]以相同数据源与相似空间尺度的研究结果,但后者使用了时序数据,覆盖冬小麦生长的整个生育时期,在数据处理量、处理难度和运算效率上难以与本文相比。阚志毅等[15]基于2017年关键生育期的Landsat8 OLI数据利用神经网络模型获取了怀远县的冬小麦分布信息,取得了较高的识别精度,但文中使用了融合后的遥感数据,空间分辨率高于本文数据的分辨率。综合考虑数据获取成本、处理效率和精度需求,研究认为A/B星组网后具有5天重返周期的Sentinel-2卫星数据可以作为中等尺度区域作物信息识别的优异数据源之一,在未来作物信息识别中发挥重要的作用。