基于YOWO的课堂学习行为实时识别*
2022-06-21陶亚平周东波
谢 伟 陶亚平 高 洁 周东波 王 溦
基于YOWO的课堂学习行为实时识别*
谢 伟1,2陶亚平1,2高 洁3[通讯作者]周东波4王 溦1,2
(1.华中师范大学 人工智能与智慧学习湖北省重点实验室,湖北武汉 430079;2.华中师范大学 计算机学院,湖北武汉 430079;3.华中师范大学 信息管理学院,湖北武汉 430079;4.华中师范大学 人工智能教育学部,湖北武汉 430079)
当前,课堂学习行为研究一般仅针对单帧图像分析学生的行为,而忽视了行为的连续性,无法利用视频信息准确刻画学生的课堂学习行为。为了解决这一问题,文章实时识别真实课堂环境中学生的学习行为,首先采集某重点大学多个真实课堂教学中的授课视频,归纳出7种典型的课堂行为;随后,将行为识别中的YOWO模型迁移至课堂学生的学习行为识别场景中;最后,通过与基于图片数据集的VGG16网络模型、基于视频数据集的YOLO-V2网络模型进行实验对比,验证了YOWO模型对课堂视频中的学生学习行为具有较高的行为识别准确率。上述研究表明,使用YOWO模型识别课堂中典型的学生行为,可以促进教师及时了解学生的学习状态,进而优化教学过程,并能为课堂教学的过程化评价提供依据。
学习行为;行为识别;视频分析;深度学习;YOWO模型
人工智能助推教育信息化不断发展,科大讯飞轮值总裁吴晓如曾说:“人工智能将教学变为大数据分析以及人工智能辅助的以学生为中心的个性化学习,为每个学生提供个性化、定制化的学习内容和方法,从而激发学生深层次的学习欲望。而且,在教育资源均衡化方面,人工智能也可以发挥很大的作用,可以有效解决以前远程教学中师生不能进行有效互动和教师不了解学情的问题。”[1]在此背景下,智慧教室开始逐渐被广泛应用。课堂教学视频中包含丰富的教学信息,故可利用智慧教室中的摄像头获取完整的授课视频信息。以往的分析课堂教学信息大多来源于相关专业人员观察录制的授课视频和手动记录相应的学生表现,这种方式的效率较低。因此,如何有效、实时地自动识别授课视频中学生的课堂动作信息,进而分析其学习行为,最终改善教与学的互动关系,是当前教育中亟待解决的问题。然而,目前的学生课堂行为识别研究大多基于单帧图像识别学生行为,忽略了行为的时序性。YOWO(You Only Watch One)网络模型可以利用学生行为的时序特征[2],自动实时地识别学生课堂行为,并通过检测框观察学生所在的空间位置。因此,本研究基于YOWO网络模型,通过检测视频中学生行为的时序性识别学生课堂行为,一方面让教师了解学情,及时改进教学方法,优化教学过程;另一方面便于学生及时做出调整,提高学习效率,最终改善教与学的互动关系,助力智慧课堂的发展。
一 研究现状
在以往的教学过程中,教师大多通过弗兰德斯互动分析系统(Flanders Interaction Analysis System,FIAS)[3]、基于信息技术的交互分析系统(improved Flanders Interaction Analysis System,iTIAS)[4]等方法分析学生的课堂行为,但是这些方法属于人工分析的范畴,耗时耗力,无法实现持续、大规模的测量。因此,一些学者针对如何自动化捕捉学生在课堂上的动作信息进而分析其学习行为展开了研究。如在国外,Zhang等[5]将YOLO算法应用于学生面部运动检测,预测学生是否参与课堂,在所构建的四个视频数据集中检测脸部后,成功识别出打哈欠、笑、闭眼、向左看、向右看五种常见面部运动,识别准确率最高达到95.46%。在国内,蒋沁沂等[6]基于残差网络,利用构建的课堂学习行为数据集,成功识别出上课、玩手机、记笔记、东张西望、看书、睡觉六种常见课堂行为,其平均识别率达到了91.91%;魏艳涛等[7]通过对VGG16网络进行迁移学习,利用构建的课堂学习行为数据集,识别出听课、看书、书写、站立、举手、睡觉、左顾右盼七种行为,其准确率为93.33%;何秀玲等[8]基于人体骨架模型,利用构建的课堂学习行为数据集,成功识别出东张西望、举手、听课、阅读、睡觉、起立、书写七种常见课堂学习行为,其平均识别率达到了97.92%;徐家臻等[9]基于人体骨架模型,利用构建的课堂学习行为数据集,成功识别出听讲、看书、站立、举手、写字五种常见课堂学习行为,并分别探讨了这些学习行为在GBDT模型、XGBoost模型、卷积神经网络中的VGG16和ResNet50、Inception-V3网络模型下的准确率,其中XGBoost模型的识别准确率最高,其平均准确率为85.49%。前文提到的研究者构建的课堂学习行为数据集都是图片数据集,但是图片数据集无法准确刻画学生的课堂行为,因此一些研究者从视频角度研究学生的课堂行为。例如,刘新运等[10]基于YOLO网络检测课堂学习行为,平均精准度为40.7%;谭斌等[11]通过Fast R-CNN网络检测课堂视频中学生的玩手机、睡觉、学习三种行为,平均精准度为54.6%;廖鹏等[12]用背景差分的方法提取目标区域数据,并将数据输入VGG网络模型中,成功识别出睡觉、玩手机、听讲三种常见的课堂行为,其平均识别率达到了85.28%。以上根据视频数据集分析学生课堂学习行为的研究成果虽然成功识别了学生的课堂行为,但依然都是针对单帧图像分析学生的学习行为,而忽略了视频中行为的时序性,没有利用行为的时序性准确刻画学生的课堂学习行为。
总的来说,目前课堂学习行为识别研究存在两个难点:①很难获取课堂中的学生学习行为数据,而在公开的行为识别数据集中恰好缺乏该类数据,在此需要研究人员专门采集课堂视频数据,并对视频依次进行筛选划分、视频分割和标注,这是一个十分耗时的工作;②学者研究的课堂学习行为识别,大部分是基于检测,仅关注空间信息(只考虑单帧图像就判断其行为属于某一类别),没有充分考虑学习行为具有时序性(很多行为由连续的多帧图像共同组成),不能很好地识别、分析学习行为。当然,空间信息可以识别部分课堂行为,如睡觉行为是学生趴在桌子上,全程不动或者身体变化幅度较小,对此研究人员只需考虑空间信息,因为单帧图像可以较好地描述该行为。但是,大部分行为不能仅依赖单帧图像进行描述,如学生从坐着到站立、从站立到坐下这两个行为在时间顺序上呈负相关,如果只考虑空间信息而忽略时序性,那么检测结果就是一个行为;可从时序角度考虑,这是两个截然相反的行为。为此,在进行课堂行为识别时,研究人员需要更多地考虑连续多帧图像,而不仅仅是单帧图像。本研究着重从视频数据集出发,应用结合行为时序性的YOWO网络模型来识别学生的课堂行为,且使用3D-CNN提取学生学习行为的时序特征、使用2D-CNN提取学生学习行为的空间特征,同时采用注意力机制融合时空特征,由边框盒回归输出所属类别、置信度和空间坐标信息。
二 基于YOWO实时识别课堂学习行为的框架
1 YOWO的网络结构
YOWO模型由德国慕尼黑工业大学人机通信研究所提出,是目前流行的行为识别网络模型之一。对比双流[13]、多流[14][15]等行为识别网络模型,YOWO模型能较好地通过检测框观察目标的所在空间位置;对比光流模型[16],YOWO模型改用3D卷积提取时序特征,极大地减少了额外计算费用,且可以达到实时识别的效果。YOWO模型主要由2D-CNN分支、3D-CNN分支、通道融合、边框盒回归四部分组成,如图1所示。YOWO模型首先同时使用2D-CNN和3D-CNN提取时空特征,随后使用自注意力机制将所提取的时空特征进行通道融合,最后由边框盒回归并输出分类结果。
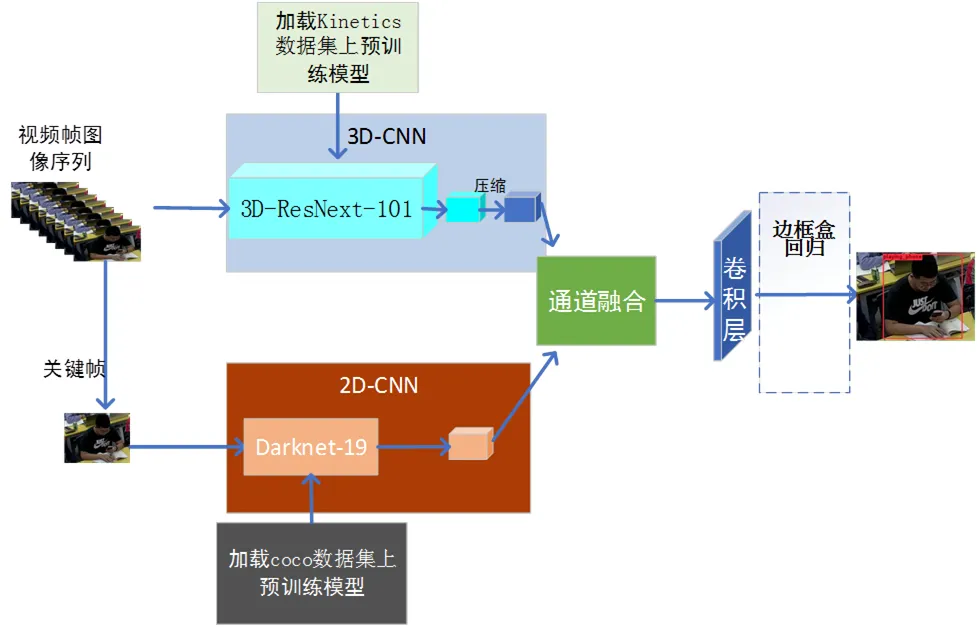
图1 YOWO模型的网络结构图
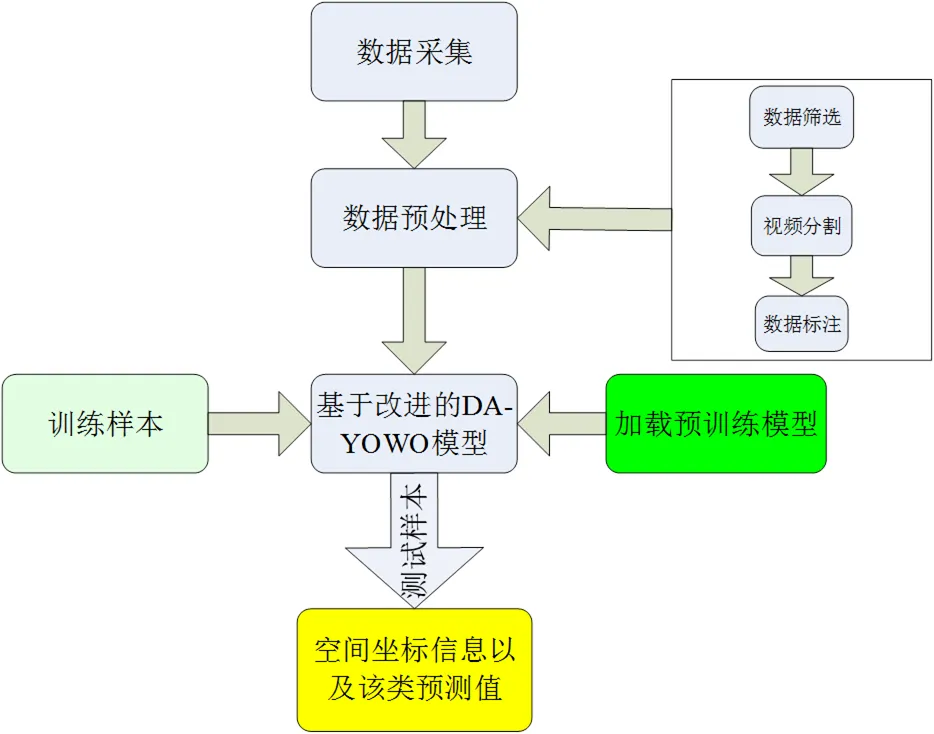
图2 基于YOWO模型的学生课堂行为识别流程
本研究采用2D-CNN分支提取空间特征时,通过Darknet-19网络模型分析学生行为的空间信息,并加强空间信息特征。在整个学习过程中,Darknet-19网络模型多次使用3×3、1×1两个滤波器,输入的初始特征大小为C×H×W(C表示通道数,这里为3;H、W分别为帧图像的高、宽,这里分别为224、224),通过由32、64、128、256、512、1024、425组成的多个卷积模块来提取特征,中间嵌有最大池化层、归一化操作BN与激活函数LeakyReLU。其中,最大池化层用来减少中间数据的空间信息;归一化操作BN可以减轻训练模型对参数初始化的依赖,提升训练速度,从而允许使用学习率较高的训练模型,并在一定程度上增加训练模型的泛化能力;在反向传播过程中,输入小于零的部分,激活函数LeakyReLU可以通过计算得到梯度a,如公式(1)所示。在本次实验中,a取值为0.1。
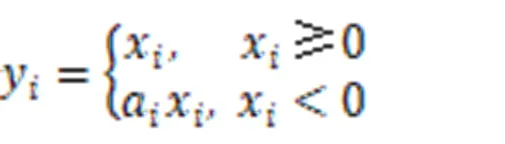
这里之所以采用3D-CNN分支,是因为视频流中行为的前后帧信息对该行为的识别具有关键作用。该分支通过3D-ResNext-101网络模型,在空间和时序上同时提取学习行为特征,从而加强对行为的捕获,用以分析学生行为的时序信息。在整个学习过程中,3D-ResNext-101多次使用7×7×7、1×1×1、3×3×3三个滤波器,输入的初始特征大小为C×T×H×W(C、H、W的含义与数值与在Darknet-19网络模型中相同;T表示连续的帧数,这里为16),通过由64、128、256、512、1024、2048组成的多个卷积模块来提取特征,中间嵌有最大池化层、归一化操作BN与激活函数ReLU。其中,最大池化层与归一化操作BN的作用与在Darknet-19网络模型中相似。激活函数ReLU在计算过程中收敛速度快、计算梯度时求解简单,如公式(2)所示。
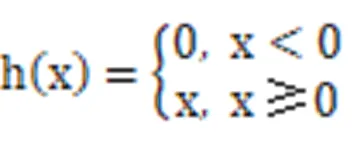
本研究中的通道融合采用自注意力机制突出前后帧之间的关系,增强了特征的可分辨性。边框盒回归是参考YOLO的思想,在最后一层使用1×1卷积核产生目标通道数。最后,输出学生的坐标框信息、所属行为类别和置信度。
2 基于YOWO模型的学生课堂行为识别流程
本研究拟基于YOWO模型识别学生在课堂中的行为,其流程如图2所示,具体包括:①采集学生的学习行为数据,即利用智慧课堂中前、后七个摄像头,采集学生的实际课堂学习行为视频。②数据预处理。首先,进行数据筛选与视频分割,根据采集的课堂学习行为视频,将包含要研究的部分学习行为分割成短视频;然后,进行数据标注,将短视频转化成连续多帧的图像,对帧图像中的学习行为进行标注,并划分训练集、验证集和测试集。③加载COCO数据集上预训练的Darknet-19模型参数和Kinetics数据集上3D-ResNext-101模型参数,利用训练样本精调YOWO模型。④将测试样本输入精调后的YOWO模型中,输出测试的识别结果。
三 实验设计
为了验证YOWO模型对学生课堂行为识别的有效性,本研究分别使用YOWO模型、基于图片数据集的VGG16网络模型(基于相关经典深度学习,方法类似)、基于视频数据集的YOLO-V2网络模型(识别速度更快,可以达到实时检测效果),在学生课堂行为视频数据集上进行实验对比。
1 学生课堂行为视频数据集的构建
由于目前国内没有公开的学生课堂行为数据集,故本研究以2020~2021年湖北省武汉市某重点大学真实课堂教学环节中的授课视频为原始数据,通过分析学生的课堂行为特点,归纳出7种具有代表性的学生课堂行为(即书写、站立、睡觉、听讲、翻书、玩手机、左顾右盼),构建相应的学生课堂行为视频数据集,每种行为的说明如表1所示。学习行为中的书写、站立、听讲、翻书表示学生上课的积极行为,而睡觉、玩手机、左顾右盼表示学生上课的消极行为,以比较全面地反映学生在课堂中的学习状态。
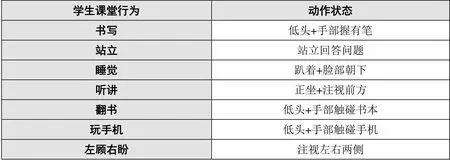
表1 学生课堂学习行为说明
本研究采集的原始数据是约6000分钟的上课视频,其中包含2门必修课、4门选修课,共计60个课堂场景。每个课堂场景为两节课,共计时90~100分钟。本研究采集的真实课堂场景是设有七个摄像头的智慧课堂,摄像头分布在教室的前、后(教室前方有4个、后方有3个),如图3所示。由于实验需要识别学生的课堂行为,因此实验数据均为上课学生的正面信息,但是会存在学习行为部分遮挡的特点,如图3(c)所示。

(a)书写(b)站立(c)睡觉(d)听课 (e)翻书(f)玩手机(g)左顾右盼
本研究对采集的视频依次进行了以下处理:①筛选与裁剪分割。首先,对采集的全过程长视频进行筛选;随后,选取视频中包含七大典型课堂行为的时间段,将其裁剪分割为单个320×240的短视频。②数据标注。根据筛选出的短视频,按照每秒30帧进行分割,生成jpg格式的帧图像,共计得到约75400张帧图像;然后,对所得的帧图像按照七个类别进行行为标注,标注框为矩形框,部分标注帧图像如图3所示,即每张帧图片用矩形框标注学生所在空间信息,矩形的左上角标注为该学生的行为类别,其中writing表示书写、stand表示站立、sleeping表示睡觉、attend_a_lecture表示听课、open_the_book表示翻书、playing_phone表示玩手机、glance_right_and_left表示左顾右盼。最后,导出的数据标签文件以json文件进行保存,数据标签文件由图像文件信息、标注框坐标信息和所对应的标签组成。
2 实验环境
①硬件环境配置:本次实验的主要设备配置为GeForce RTX 3080(GPU)10G显存和i9-10920X(CPU)。②软件环境配置:本次实验所用的编程语言为Python,使用的框架为PyTorch。
3 实验步骤
本实验的具体步骤为:①录制学生在真实课堂中的学习行为视频,采集学生的课堂行为视频。②将采集的视频长、宽统一裁剪为320px×240px,每秒钟按照30帧均匀划分生成jpg格式的图像帧并进行标注。③加载COCO数据集上训练的Darknet-19模型参数作为2D分支的预训练模型,Kinetics数据集上训练的3D-ResNext-101模型参数作为3D分支的预训练模型。④将已标注的实验数据随机分割成训练集、验证集和测试集,比例近似为3:1:1 ;将其中的训练集和验证集输入YOWO模型进行精调,其中使用具有动量和权值衰减策略的小批量随机梯度下降算法优化损失函数。⑤将测试集输入已训练好的YOWO模型,评估其算法性能。本研究以行为的分类准确率为评价标准,同时也能获得该类别的置信度及其目标学生的坐标信息。
四 实验结果与分析
在相同的实验环境和超参数情况下,本研究分别对比YOWO模型、基于图片数据集的VGG16网络模型、基于视频数据集的YOLO-V2网络模型在学生课堂行为视频数据集上的准确率,实验结果如表2所示。

表2 不同网络模型下学习行为结果的准确率对比

图4 课堂中某一时刻学生行为的实时识别
由表2的实验结果可知,站立行为是从坐到站的一个连续性过程,而VGG16、YOLO-V2忽略了学习行为的时序性,不能准确识别学生的课堂行为,因此在该性能上表现不佳;在实际的采集过程中,左顾右盼行为不可能持续发生,当学生的头部偏转到一定角度时,其角度不再会发生移动,所以较为复杂的YOLO-V2网络模型的性能会高于VGG16网络模型、低于YOWO模型。总的来说,VGG16网络模型适用于原作者构建的、标准简单的学生行为图片数据集,而不太适用于较为复杂的场景;YOLO-V2网络模型虽然基于视频数据集检测,但该模型主要分析单张帧图片,没有很好地利用视频相邻帧之间的时序性,故总体性能不佳;本研究迁移的YOWO模型充分利用了视频相邻帧之间的时序性,该模型识别七个学习行为的平均准确率为91.1%,适用于分析较为复杂的真实课堂场景,尤其适用于识别具有明显时序性的左顾右盼与站立两个学习行为。但考虑到YOWO模型不能同时准确识别一个视频中多个学生的行为,在实际应用过程中可以将视频中多个学生的视频先分割成单人视频后再进行识别。图4为课堂中某一时刻学生行为的实时识别,可以看出:分割成单人视频后再进行识别的YOWO模型可有效排除学生课上的着装、小部分遮挡、教室背景等无关因素的影响,成功识别出玩手机6人、睡觉3人、翻书1人,说明该时间段的学生大部分脱离学习状态,由此可以推断该时间段为休息时间;而根据当时上课教师的反馈,该时间段的确属于休息时间。可见,可以采用YOWO模型自动识别学生的课堂学习行为。
五 总结
本研究基于YOWO模型实时识别学生的课堂行为,不仅考虑了行为的时序性,而且能在自主构建的学生课堂行为数据中识别七种学生典型的课堂行为。此外,通过对比其他课堂学生行为识别论文中的相关算法,本研究验证了YOWO模型对于课堂这一场景下学习行为识别的有效性:其平均识别准确率达到了91.1%,同时在真实课堂场景下学生课上的着装、小部分遮挡、教室背景等无关因素的干扰下,依然有较好的识别效果。在实践中,通过YOWO模型自动实时识别某一时刻单个学生的典型课堂学习行为,并分析其在该时刻的学习专注度,进而统计整个课堂学生在该时刻的学习专注度,教师便可以及时了解学生学习的整体情况,这为进一步改善课堂教学策略提供了参考依据,有助于提高课堂教与学的效率。后续研究可以扩大数据的多样性,如丰富学生的学习行为种类、增加同一行为的不同学生数量,以进一步提高识别的准确率;也可以修改相应的算法来研究学生的课堂学习行为,以更好地推动自动化实时分析课堂教学信息,进而优化课堂教学策略。
[1]中国教育报.人工智能来了,教育当未雨绸缪[OL].
[2]Köpüklü O, Wei X, Rigoll G. You only watch once: A unified CNN architecture for real-time spatiotemporal action localization[OL].
[3]Flanders N A. Analyzing teacher behavior[M]. Massachusetts: Addison-Wesley, 1970:107.
[4]顾小清,王炜.支持教师专业发展的课堂分析技术新探索[J].中国电化教育,2004,(7):18-21.
[5]Zhang Y, Qiu C Z, Zhong N, et al. AI education based on evaluating concentration of students in class: Using machine vision to recognize students' classroom behavior[A]. 2021 The 5th International Conference on Video and Image Processing[C].NY: Association for Computing Machinery,2021:126-133.
[6]蒋沁沂,张译文,谭思琪,等.基于残差网络的学生课堂行为识别[J].现代计算机,2019,(20):23-27.
[7]魏艳涛,秦道影,胡佳敏,等.基于深度学习的学生课堂行为识别[J].现代教育技术,2019,(7):87-91.
[8]何秀玲,杨凡,陈增照,等.基于人体骨架和深度学习的学生课堂行为识别[J].现代教育技术,2020,(11):105-112.
[9]徐家臻,邓伟,魏艳涛.基于人体骨架信息提取的学生课堂行为自动识别[J].现代教育技术,2020,(5):108-113.
[10]刘新运,叶时平,张登辉.改进的多目标回归学生课堂行为检测方法[J].计算机工程与设计,2020,(9):2684-2689.
[11]谭斌,杨书焓.基于Faster R-CNN的学生课堂行为检测算法研究[J].现代计算机(专业版),2018,(33):45-47.
[12]廖鹏,刘宸铭,苏航,等.基于深度学习的学生课堂异常行为检测与分析系统[J].电子世界,2018,(8):97-98.
[13]Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[A]. Proceedings of the 27th International Conference on Neural Information Processing Systems[C]. Cambridge: MIT Press, 2014:568-576.
[14]Tu Z, Xie W, Qin Q, et al. Multi-stream CNN: Learning representations based on human-related regions for action recognition[J]. Pattern Recognition, 2018,79:32-43.
[15]Tu Z, Xie W, Dauwels J, et al. Semantic cues enhanced multimodality multistream CNN for action recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019,(5):1423-1437.
[16]Tu Z, Xie W, Zhang D, et al. A survey of variational and CNN-based optical flow techniques[J]. Signal Processing-Image Communication, 2019,72:9-24.
YOWO Based Real-time Recognition of Classroom Learning Behaviors
XIE Wei1,2TAO Ya-ping1,2GAO Jie3[Corresponding Author]ZHOU Dong-bo4WANG Wei1,2
At present, classroom learning behavior generally only analyzes students’ behavior in single-frame images, but ignores the continuity of behavior, and cannot accurately describe students’ classroom learning behaviors using video information. In order to solve this problem, this paper identified students’ learning behaviors in a real environment in real time. Firstly, lecture videos from multiple real classroom teaching in a key university were collected, and further 7 typical classroom behaviors were summarized. Subsequently, the YOWO (You Only Watch One) network model in behavior recognition was transferred to the scene of classroom students’ learning behavior recognition. Finally, through experimental comparison with the VGG-16 network model based on the picture dataset and the YOLO-V2 network model based on the video dataset, it was verified that the YOWO network model had a high behavior recognition accuracy rate for students’ learning behaviors in classroom videos. The above research showed that using the YOWO model to identify typical students’ behaviors in classrooms could not only help teachers to understand students’ learning status in a timely manner, further optimize the teaching process, but also provide a basis for the procedural evaluation of classroom teaching.
learning behavior; behavior recognition; video analysis; deep learning; YOWO model

G40-057
A
1009—8097(2022)06—0107—08
10.3969/j.issn.1009-8097.2022.06.012
本文受“信息化与基础教育均衡发展省部共建协同创新”中心重点项目“基于视频分析的乡村学校‘专递课堂’学生注意力获取与绩效关系建模研究”(项目编号:xtzd2021-004)、科技创新2030新一代人工智能重大项目“混合增强在线教育关键技术与系统研究”(项目编号:2020AAA0108804)、中央高校基本科研业务费项目“基于视频人体动作识别的课堂学习行为建模与分析”(项目编号:CCNU20TS028)、华中师范大学教学改革研究项目“基于课堂学习行为分析与统计的教学方法优化研究”(项目编号:202013)资助。
谢伟,教授,博士,研究方向为人工智能及其教育应用,邮箱为xw@ccnu.edu.cn。
2021年10月22日
编辑:小时
