课程级时间序列分析模型研究*
2022-06-21刘林枚李宜羲
谢 涛 张 领 刘林枚 李宜羲
课程级时间序列分析模型研究*
谢 涛 张 领 刘林枚 李宜羲
(西南大学 教育学部,重庆 400715)
教育时间序列能够展现学习过程随时间的变化与波动趋势,是近年来的研究热点。其中,课程级时间序列是个体级时间序列在课程层面的汇总,使用课程级时间序列可以获得比个体级时间序列更为丰富的信息。基于此,文章首先综述了教育时间序列的主流研究方法,对课程级时间序列的形成与有用性进行了分析,并提出了相应的数据分析模型。随后,文章以在线教育中的视频学习作为场景,将7341个学生所产生的个体级时间序列转换为课程级时间序列,通过实验分析了课程访问的“潮汐”现象、有潜力的辍学率预测、清晰的认知搜索意图、内容消耗的时间结构和课程聚类模式,验证了文章所提出模型的可用性。文章提出的课程级时间序列分析模型是数据驱动智慧课程建设的一项探索性试验,未来可应用于大规模在线学习中的课程搜索、分类和评价,以发现具有相似时间模式的候选课程集合。
课程级时间序列;个体级时间序列;时间模式;课程聚类;视频学习
教育数据挖掘是当前的热点研究方向,但是大部分研究使用静态截面数据作为教育数据挖掘的输入,为学习情况的实时掌握和动态预测带来了极大挑战,且这种挑战在日益复杂的学习情境(如线上线下、虚实融合教学环境)中变得愈加复杂。面对数据的无序性和复杂性,亟需以时间为基本单位进行规整。教育教学过程中产生的时间序列(下文简称教育时间序列)作为一种重要的数据组织形式,因其能展现学习过程随时间变化的趋势和规律,而对学习过程有效解释、学习资源个性化分发和学习绩效精准预测具有重要意义。然而,已有的教育时间序列挖掘研究主要关注个体级时间序列,而忽略了课程级时间序列。个体级时间序列一般是系统连续记录的直接数据,主要用于表示个体学习行为的时间轨迹。虽然个体级时间序列可以刻画单个学生行为随时间的变化,但是无法从课程层面显示学生群体对课程访问、内容消耗的时间偏好。因此,本研究探索课程级时间序列的形成与有用性,并设计其数据分析模型,试图从课程层面挖掘教育时间序列中潜藏的信息,从而拓展教育时间序列的研究视野。
一 教育时间序列
由于时间的单调递增性质,任何活动和事件都可以打上唯一的时间标签。一段连续的活动和事件按其发生的时间先后顺序排列,所构成的序列就称为时间序列[1]。从统计学角度来看,时间序列是与时间相关的一组随机变量,是在相等间隔时间段内按照给定的采样率对某种潜在过程进行观测的结果[2]。时间序列在教育领域的研究主要包括预测风险学生、学习效果、相似学生、学习轨迹、课程类别等,其使用的数据一般分为两类:①静态数据,包括人口学信息、先前上传的学习材料、学习风格、特有的教学模式、学习的历史记录和已提交的成绩报告等;②包含时间维度的动态数据,包括学习行为、情感状态、学习方法、兴趣与偏好等过程性数据。本研究认为可将学习视为对知识和技能的累积,体现学生先前已掌握的知识和被遗忘的知识之间的动态平衡;忽略时间维度,会低估情绪或日常压力等因素对学习过程的影响[3]。学习过程可被视为一系列随时间变化的学习状态测量的集合,而学习状态是个体在学习过程中一系列可变化的行为属性,涉及与学习有关的思维、情感状态以及学生为完成特定学习任务所开展的活动。
针对教育时间序列所采用的技术主要包括分类和聚类等:①在教育时间序列分类任务中,Tarhini等[4]基于学生与课程的交互构建时间序列,研究学生离开课程的时间规律;针对Moodle系统中的行为序列,Calvo-Flores等[5]、Gamulin等[6]将行为类型分为资源浏览、课程浏览、用户浏览、上传、更新、添加和论坛参与,并用来预测学生最终的学业成绩;Padrón-Rivera等[7]研究了情感状态序列及其对学习结果的影响;Chen等[8]将学生在线时间行为分为有风险和无风险两类。②在教育时间序列聚类任务中,学生人口学信息、历史行为和成绩记录被认为是静态数据,不会随着时间的变化而变化,而学生学习的时间模式可以体现个体学习随着时间的动态变化、循环规律和波动趋势。教育时间序列聚类可以把表现为类似时间模式的学生聚在一起,同时区分具有不同时间模式的学生。Hung等[9]使用时间序列聚类来预测风险学生,并给予相应的早期预警和干预策略。在构建时间序列时,一般会使用课程材料访问、论坛浏览、参与讨论、论坛回帖等以天为单位的累计交互次数,而聚类的实现一般基于对时间序列的相似性测量。Reilly等[10]进行了基于动作的时间序列相似性测量,显示了学习活动和学习体验随时间变化的模式。Park等[11]通过聚类将612门混合式课程分为4类,即被动学习型、沟通与协作型、分发与讨论型、分享与提交型。Van等[12]收集了师生交互数据,将学生聚类为高分、中分、分数波动和低分4类,进一步解释了教师提供的教学支持和学生理解水平之间的关系。
由此可见,现有研究主要针对个体级时间序列,还没有对课程级时间序列进行系统探索,既缺少课程级时间序列的形成机制,也缺少课程级时间序列的多维度分析模型,限制了教育时间序列挖掘的研究视野。
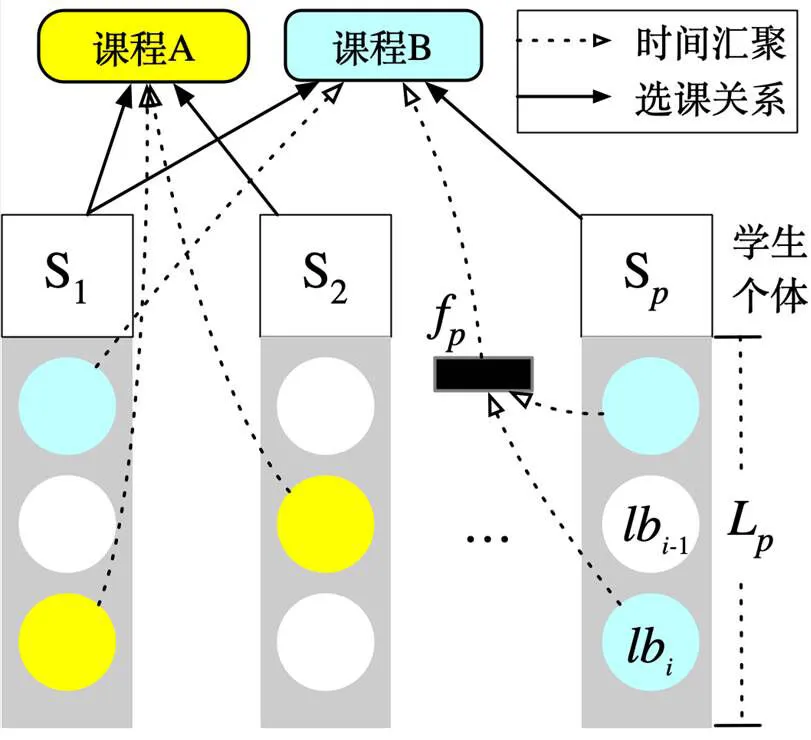
图1 课程级时间序列的形成过程
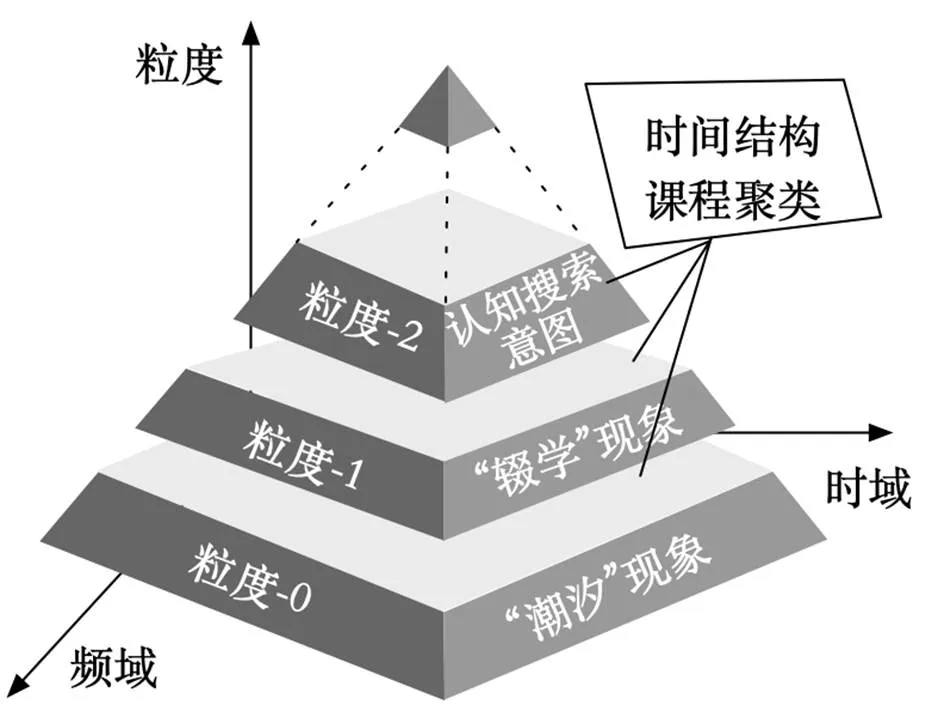
图2 课程级时间序列分析模型
二 课程级时间序列
1 课程级时间序列的形成
课程是教育机构开展教学工作的基础,而学生是课程的主要消费群体。典型的“学生—课程”关系是在一定时间区间内,一个学生可以同时选择多门课程,一门课程也可以同时被多个学生选择。学生与课程的不断交互,将产生教育时间序列。由于课程级别的数据来源于个体学习过程中数据的累积,因此本研究先从课程学习日志中抽取个体级时间序列,然后构建课程级时间序列,其形成过程如图1所示。
当学生每次操作学习系统时,系统将自动产生一个学习交互。令O={o, o, …, o}代表操作所属的类别集合,T={t, t, …, t}表示原子时间单位。,,记录一个操作发生在时刻。一个对应一个操作类型,以解释该发生的意图或情境。一个操作发生在时间区间[t, t]中表示为,其中t表示操作的开始时间,t表示操作的结束时间,为操作的持续时间(=t-t0),为在一段时间中的操作。
个体级时间序列表示为L=<(d, s), (d, s), … (d, s)>,其中d代表序列产生的时间单位(如天或小时);s=<,, …,>表示在时间单位内的学习交互序列。在本研究中,f表示课程学习时间,它是在课程学习期间学生端总是处于活跃状态的时间总和,代表课程内容的实际消耗长度。令三元组表示一次视频观看活动,其中表示操作类型,表示持续的时间;={0, 1}表示播放条的状态,0为静止状态的编码,1为活跃状态的编码。对于学生S,其课程学习时间用公式(1)计算。相应地,课程级时间序列被定义为所有注册该课程学生学习时间的有序排列<f, f, …, f>。
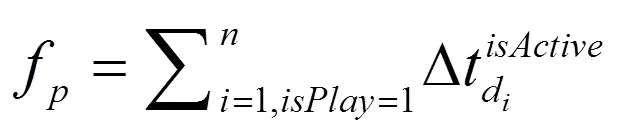
2 课程级时间序列的有用性分析
①已有MOOC方面的研究表明,可以通过视频观看、了解学生的行为和每个操作的认知意义。播放、暂停、重放、拖动等操作,可以从某种程度上反映特定的学习状态[13]。例如,播放状态表示内容消耗;暂停状态可以表示学习中断,也可以表示学生对当前页面的认知参与,从而将该页面知识标注为难点,而对暂停状态学生真实意图的识别取决于其自我报告或内容测评;重放状态表示学生对知识的兴趣或对难点的再度消化;拖动状态则表示对知识不感兴趣或跳过简单学习内容的认知搜索意图。课程级时间序列将这些学习状态作为基础单元,并在课程层面上进行汇总,体现其系统性和整体性。
②课程内容的实际消耗长度是学生认知参与量的有效指标,也是学业成绩的预测器[14]。教师可以洞悉学生是否在学习以及学习的程度;如果学生在课程上投入更多的时间,则有可能获得更高的成绩,因此延长课程的有效学习时长有利于最大化学习输出。课程级时间序列以课程作为观察对象,能折射出学生群体的总体时间投入和内容消耗习惯。目前,许多远程教育机构将学生登录和退出系统作为学习的关键点,以此来计算学习时长,忽略学生中途通过投机行为获得在线时长的累积,因此难以准确检测学生真实的学习状况。显然,这样的数据误差太大,在预测学生学习成绩时无法达到令人满意的效果。不少学者建议采用会话失效阈值来减少这一误差,即学生在给定时间内不活跃就停止计时,但这种方式的缺点是迫使学生频繁登录系统,而降低了学生的使用体验。相反,课程级时间序列将个体的时间片段进行汇总,可以较好地降低因记录误差而导致的不良后果。有研究认为,使用学生在学习平台中活跃状态的时间总和表示知识的吸收量比简单地估计时间更加精准,更能在学习时长与学习成绩之间建立强关联[15]。课程内容的实际消耗长度可被建模为在线生存模型,通过比例风险函数模拟学生从初次登录系统到末次使用系统(类似于机器零件从投入使用到失效)的全过程,从而解释退课风险值如何随单位协变量的变化而变化。最终,教师可以根据学生的不同退课程度提供相应的教学干预,如提供元认知工具、推荐个性化材料和学习同伴、弹出个性化提示、优化课程内容设计、提高师生互动水平等,使学习平台更具有吸引力。
三 课程级时间序列分析模型
随着大数据、人工智能等技术的发展,数据分析成为教育技术研究的一个重要分支。教育数据科学作为一个新的交叉学科,对使用的传统问卷测量和标准化统计分析等方法进行了很大扩展。课程级时间序列是个体级时间序列在课程层面的汇聚,它既区别于个体级时间序列、又与之紧密相关。本研究假设课程级时间序列包含比个体级时间序列更丰富的信息,而非个体级时间序列模式的简单叠加。课程级时间序列更关注课程,而非学生个体。为了得到比个体时间序列更丰富的信息,本研究对课程级时间序列采取“时域—频域—粒度”的交互式数据分析模型,如图2所示。其中,时域包含课程层级的时间信息,频域是相关时间信息出现的频率特征,粒度是指分析视角的精细程度。在该模型中,纵轴表示分析粒度的分层,最底层是数据的探索性分析,越往上分析粒度越精细。
(1)“潮汐”现象
“潮汐”现象是课程级时间序列探索性分析的基础,体现课程级时间序列的周期变化、波动规律。“潮汐”原本的含义是在月球和太阳引力作用下形成的海水周期性涨落现象。“潮汐”现象隐藏着在兴趣时间单位(如某周中的特定天或某天中的特定时段)下学生的行为模式和时间偏好等信息,可为教育者提供初始数据画像。
(2)“辍学”现象
辍学率是在线教育近年来关注的热点,体现课程的粘度和吸引力。许多研究从机器学习的视角,提出了大量的辍学率预测方法。与基于个体级时间序列的辍学率预测不同,课程级时间序列更关注学生群体的“辍学”现象,它是个体“辍学”现象在课程级别的高度抽象。辍学率预测的精准性取决于模型对数据拟合的程度,也称拟合优度。以前的研究大多假设时间序列数据服从特定分布(如正态分布),但使用简单的模型无法拟合真实的复杂数据,甚至可能误导数据分析的过程。因此,本研究建议采用非标准分布拟合课程级时间序列。
(3)认知搜索意图
从外显行为到内隐认知的映射是教育数据挖掘的难点,而学生触发的行为序列(如跳过、重复播放等)可以反映特定的认知轨迹、学习动机和信息需求。认知搜索意图是指学生有意识地寻找感兴趣的课程片段,对认知搜索意图的估计有利于优化学习系统、个性化推送教学材料等。例如,当大部分学生有意识地请求同一课程内容时,可能意味着该课程存在系统错误或出现了高难度、备受关注的作业等。
(4)时间结构
时间结构是关联个体与课程的桥梁,用来刻画学生群体访问所选课程特定内容的时间分配。对于某些课程,学生愿意投入更多的时间,对于其他课程则相反。这种随机的意愿在某种程度上体现了学生对课程内容片段的兴趣程度。此外,受认知需求的驱动,学生更愿意在课程内容的重、难点处花费更多的时间,而对于不感兴趣的学习材料会花费更少的时间。因此,从这个意义上来说,时间结构分布的合理与否是课程重、难点内容分配合理性的表现。
(5)课程聚类
课程聚类是一个新兴研究课题。随着课程体量的爆炸式增长,以人工方式对数以千计的课程一一进行评价几乎不可能。课程聚类能够将相似特征的课程划分到同一个组、将不同特征的课程划分到不同的组,从而产生组间同质、组内异质的课程簇群。聚类技术依赖于对课程相似性的测量。已有的研究主要收集各种关于课程的属性信息,如课程类别、学时和内容简介等,但这些属性基本都是预定义的,无法体现全体学生对课程的动态学习过程。
度量时间序列相似性的方法大体可分为两类,第一类基于内容的相似性进行度量,第二类基于概率的相似性进行度量[16]。其中,基于内容的相似性受限于特定的领域模型,要求数据存于一种网状结构中。例如,学生浏览两份电子文档所构成的时间数据时,文档需具有某种相关性,并可通过数值型的特征向量表示。此外,基于内容的相似性测量使用时也会受到许多限制,如欧式距离受到序列齐整度的限制。因此,基于内容的相似性方法在许多实际问题中的可用性并不高。而基于概率的相似性因使用起来更加方便,得到了许多研究者的青睐,提出了如基于概率密度函数和基于K-L散度等相似性测量方法。
为了实现对课程级时间序列的聚类,本研究提出了一种基于熵的相似性度量方法,特点主要如下:该方法重新构建的时间序列是一个针对课程层面的时间序列,而非以个体时间序列为观察对象;该方法基于信息量,与具体的数据分布无关,从而弱化了对数据分布假设的依赖,使其适应于任何形状的时间序列数据;该方法将课程级时间序列的分布转化为概率密度曲线,并将曲线分为个不相交的时间窗口,且时间窗口跨度越小,时间窗口的个数越多。时间窗口t和t的相似性与其概率分布的公共部分成正比,即t和t的公共部分越多,两个时间窗口的概率分布越相似。因此,可以用t和t的信息量衡量t和t的公共部分,记为。在信息论中,事件(tt)的信息量(tt))=-logp(t∨t)),其中表示时间窗口t和t共有部分的概率。据此,t和t的相似性可计算为t和t共有部分的信息量与t和t的信息量之和。
具体来说,课程级时间序列的相似性度量方法可按以下三步进行应用:①将概率密度曲线分为个不相交的时间窗口,表示为<t, t, …, t>。②对于任意一门课程,对应概率密度曲线的相邻时间窗口t和t(1≤≤)的概率分布相似性计算如公式(2)所示。③对于任意两门课程和,分别构建课程的概率分布相似性向量<1,2, …,-1>和课程的概率分布相似性向量<1,2, …,-1>,则和的课程级时间序列分布的相似性可计算为两课程概率分布相似性向量的余弦夹角,如公式(3)表示。
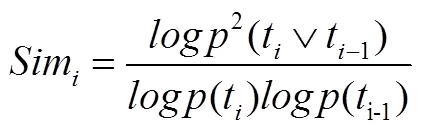
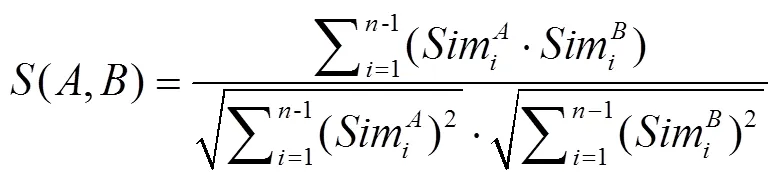
四 实验验证
为验证课程级时间序列分析模型的可用性,本研究选择一个在线教育场景作为测试案例,将个体级时间序列转化为课程级时间序列,分别从模型的五个维度进行测试。
1 场景选择
考虑到几乎所有教育场景都能产生时间序列,本研究选取最易获取数据的MOOC视频学习场景开展实验。MOOC的盛行,将基于Web的学习迁移至基于视频的学习。而基于视频的学习包含更丰富的交互序列,在远程教育中的影响越来越深远。得益于教育视频的云存储技术、网络分发技术和终端设备的性能改善,学生可以在任何时间、地点以任何步调请求教育视频资源,学生与视频资源的交互都将被轻松记录到日志数据库,这为教育时间序列的研究提供了方便。基于此,本实验基于视频学习日志数据库,验证前文提出的课程级时间序列分析模型的可用性。
2 数据收集与预处理
基于某大学在线MOOC平台,本实验共收集57717个学生的1400万条视频学习日志,并选取学生与课程交互数量最多的7门课程(“毛泽东思想概论”“政治经济学”“线性代数”“企业财务管理”“市场营销”“微机原理”“健康评估”,分别编码为MS、PE、LA、EF、MM、MI、HA)的时间数据作为样本,时间跨度为一学年(2018秋至2019春)。课程信息主要包含课程录制时长和课程观看时长。去除异常和缺失数据,本实验最终保留7341个学生所产生的时间数据。其中,最小视频长度为1.5分钟、最长为78分钟(=35.59,=12.29),而最小视频观看时长为0.03分钟、最长为60.07分钟(=14.10,=10.39)。实验定义的操作类型集合包括:播放、暂停、拖动播放条位置、中途退出章、永久离开课程。其中,中途退出章是指学生结束当前章学习,并在未来一段时间处于离线状态或不再学习该章,但过段时间学生将继续学习课程其他章的内容;而永久离开课程是指学生退出该课程所有章节的学习,并在未来不再学习该课程。
将数据转化为课程级时间序列后,本实验对每一门课程进行K-S检验,得到课程级时间序列偏离正态分布(1D统计量反映了经验的正态分布曲线与拟合的正态分布曲线的最大距离。>0.075,=0.000),发现其偏斜和长尾突出。为了使曲线看起来更加规整,本实验对数据做间距压缩处理,使长尾部分的间距压缩更快、短尾的部分压缩较慢;随后用二次开方对数据进行对称处理,用二次光滑局部线性回归核函数进行平滑。
3 数据分析工具
根据描述性学习分析范式,既可以采用现成的数据分析工具,也可以针对数据的特点开发新的数据分析工具,具体如何操作依赖于数据分析的目的和效果。基于此,本实验对“潮汐”现象的分析采用时域、频域统计方法,对“辍学”现象的分析采用非标准分布拟合方法,对认知搜索意图的分析采用频繁子序列挖掘方法,对时间结构的分析采用基尼系数评价方法——这些方法在MATLAB和Python库中有现成的工具箱。而考虑到课程级时间序列的特殊性,本实验对课程聚类采用前文提出的基于熵的相似性度量方法。另外,由于课程数量较少,本实验对最终聚类采用人工判别方式,但对大规模课程仍然采用k-means和谱聚类算法来实现。
4 实验结果
(1)课程访问的“潮汐”现象
当年11月到次年1月学生观看视频最为活跃,而在寒、暑假观看视频不活跃;学生活跃的学习时间是工作日而非周末,每日学习时段集中在早上9点至下午6点之间,且在饭点和夜晚学习较少;学生使用移动终端观看的时段主要在晚上8点至11点之间,白天较少。
(2)有潜力的辍学率预测
通过大量统计模型测试,本实验发现高斯混合模型适用于建模课程辍学率。高斯混合模型可以看作由个正态分布函数组合而成的模型。简单起见,本实验设=2,并与单正态分布(=1)进行拟合优度比较,评估度量包括均方根误差RMSE、调整的R和Akaike信息准则(AIC),结果显示:RMSE<RMSE,R2>R2,AIC<AIC。本实验重点考虑AIC指标,因为它对模型的复杂性施加了更严格的惩罚力度,使所选择的模型既具有最少参数,又可以防止过拟合。结果显示,使用双正态分布拟合改进较大的前两门课程是HA(-4.6)和MI(17.7),而改进最小的是MS(172.9)。由此可见,对于不同的课程,学生表现出不同的课程辍学和维持模式;单、双分布拟合优度差异越大的课程(如LA、MM),维持率越高;而单、双分布拟合优度差异越小的课程(如MS),其辍学风险越高。对于辍学风险高的课程,应予以高度重视。
(3)清晰的认知搜索意图
认知搜索意图可分为单次观看(One-pass)、两次观看(Two-pass)、重复观看(Repetitive)和跳跃观看(Zapping)四种模式,可分别解释为线性、详述、持续性复述、跳跃四种观看风格。某些学生累积播放视频的时间超过了视频本身的长度,据此可以推测这些学生播放了完整视频或重复观看了视频的特定片段,其认知搜索意图可归为“重复观看”模式;某些学生在视频观看过程中频繁拖动播放条,且每次停留时间非常短,其认知搜索意图可归为“跳跃观看”模式。重复观看体现了学习的重、难点或学生的兴趣,跳跃观看则表明处于困境的学生没有很强的学习动机,认知力度较浅。
(4)课程内容消耗的时间结构
本实验采用基尼系数作为时间结构的评价指标。基尼系数原本用来衡量一个地区人口的收入贫富差距,值越小表示差距越小,反之表示差距越大。本实验得到基尼系数较大的前3门课程是EF(0.252)、MM(0.244)、MI(0.246),而基尼系数最小的课程是LA(0.223),这表明学生对课程EF、MM和MI内容消耗的时间结构不及课程LA,在决策前应予以更多观察。
(5)课程聚类模式
课程聚类依赖于课程之间的相似性矩阵。根据本研究提出的相似性度量方法,为自定义时间窗口数量,值越大,时间序列划分越精细。显然,的取值会影响相似性计算结果。为呈现方便,本实验设=30,得到相似性矩阵如表1所示,可以看出:相似性较大的课程对是PE-LA、EF-MI、LA-MS、PE-MS,而相似性较小的课程对是MS-EF、LA-EF。将最相似的课程进行组合得到两个课程聚类MS-LA-PE、MI-EF,这与课程内容消耗的时间结构所得出的结果吻合。
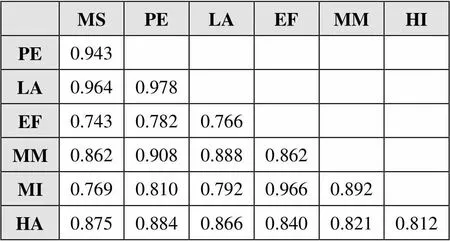
表1 相似性矩阵
五 结语
针对个体级时间序列包含信息的有限性问题,本研究采用“时域—频域—粒度”交互式分析方法,将时间信息置于立体的网状结构中,提出了课程级时间序列分析模型,并在基于视频的学习场景中进行实验,分析了课程访问的“潮汐”现象、有潜力的辍学率预测、清晰的认知搜索意图、内容消耗的时间结构和课程聚类模式,验证了该模型的可用性。课程级时间序列分析模型可以应用于具有复杂时间结构的混合式学习环境,在课程层面呈现有意义的学习规律。此外,由于时间是系统日志记录的基本元素,因此该模型也适用于其他学习场景。除了本研究提到的五个维度,未来课程级时间序列分析模型还可以结合人工智能、机器学习等技术实现课程的自动归类和自适应推荐,并作为数据驱动智慧课程评价的探索性发现,将其应用于大规模在线学习中的课程搜索、分类和评价,以发现具有相似时间模式的候选课程集合。
[1]杨海民,潘志松,白玮.时间序列预测方法综述[J].计算机科学,2019,(1):21-28.
[2]Büyükşahin Ü Ç, Ertekin Ş. Improving forecasting accuracy of time series data using a new ARIMA-ANN hybrid method and empirical mode decomposition[J]. Neurocomputing, 2019,361:151-163.
[3]Schmitz B, Wiese B S. New perspectives for the evaluation of training sessions in self-regulated learning: Time-series analyses of diary data[J]. Contemporary Educational Psychology, 2006,(1):64-96.
[4]Tarhini A, Hone K, Liu X. Measuring the moderating effect of gender and age on e-learning acceptance in England: A structural equation modeling approach for an extended technology acceptance model[J]. Journal of Educational Computing Research, 2014,(2):163-184.
[5]Calvo-Flores M D, Galindo E G, Jiménez M C P, et al. Predicting students’ marks from Moodle logs using neural network models[J]. Current Developments in Technology-Assisted Education, 2006,1:586-590.
[6]Gamulin J, Gamulin O, Kermek D. Using Fourier coefficients in time series analysis for student performance prediction in blended learning environments[J]. Expert systems, 2016,(2):189-200.
[7]Padrón-Rivera G, Rebolledo-Mendez G. Identifying affective trajectories in relation to learning gains during the interaction with a tutoring system[A]. The 17th International Conference on Artificial Intelligence in Education[C]. Madrid:Springer, Cham, 2015:756-759.
[8]Chen F, Cui Y. Utilizing student time series behaviour in learning management systems for early prediction of course performance[J]. Journal of Learning Analytics, 2020,(2):1-17.
[9]Hung J L, Wang M C, Wang S, et al. Identifying at-risk students for early interventions—A time-series clustering approach[J]. IEEE Transactions on Emerging Topics in Computing, 2015,(1):45-55.
[10]Reilly J M, Dede C. Differences in student trajectories via filtered time series analysis in an immersive virtual world[A]. The 9th International Conference on Learning Analytics & Knowledge[C]. New York: Association for Computing Machinery, 2019:130-134.
[11]Park Y, Yu J H, Jo I H. Clustering blended learning courses by online behavior data: A case study in a Korean higher education institute[J]. The Internet and Higher Education, 2016,29:1-11.
[12]Van der Steen S, Steenbeek H W, Den Hartigh R J R, et al. The link between micro development and long-term learning trajectories in science learning[J]. Human Development, 2019,(1):4-32.
[13]Sinha T. “Your click decides your fate”: Leveraging clickstream patterns from MOOC videos to infer students’ information processing & attrition behavior[J]. ArXiv E-prints, 2014:1407.7143.
[14]Moreno R. Constructing knowledge with an agent-based instructional program: A comparison of cooperative and individual meaning making[J]. Learning and Instruction, 2009,(5):433-444.
[15]Xie T, Zheng Q, Zhang W, et al. Modeling and predicting the active video-viewing time in a large-scale E-learning system[J]. IEEE Access, 2017,5:11490-11504.
[16]Aghabozorgi S, Shirkhorshidi A S, Wah T Y. Time-series clustering–a decade review[J]. Information Systems, 2015,53:16-38.
Research on the Analysis Model of Course-level Time Series
XIE Tao ZHANG Ling LIU Lin-mei LI Yi-xi
Educational time series could exhibit the variation and fluctuation trend of the learning process with time, and is a research hotspot in recent years. Among them, the course-level time series is the summary of the individual-level time series at the course level, and using the course-level time series could obtain more abundant information than using the individual-level time series. Based on this, this paper firstly summarized the mainstream research methods of educational time series, analyzed the formation and usefulness of course-level time series, and proposed corresponding data analysis models. Subsequently, taking the video learning in online education as the scene, this paper converted the individual-level time series generated by 7341 students into course-level time series, analyzed through an experiment the “tidal” phenomenon of course visits, the potential dropout rate prediction, clear cognitive search intent, the time structure of content consumption, and the course clustering patterns, and accordingly verified the usability of the proposed model. The course-level time series analysis model proposed in this paper was an exploratory experiment in the construction of data-driven smart courses, and could be applied in the course search, classification, and evaluation in the large-scale online learning in the future, so as to further discover the candidate course collection with similar time patterns.
course-level time series; individual-level time series; temporal pattern; course clustering; video learning

G40-057
A
1009—8097(2022)06—0098—09
10.3969/j.issn.1009-8097.2022.06.011
本文受重庆市社会科学规划项目“大数据促进我国教育公平的机制研究”(项目编号:2018BS100)、重庆市高等教育教学改革研究项目“OpenX智能视频分析技术的一体化教学应用路径探索”(项目编号:213082)资助。
谢涛,副教授,博士,研究方向为智能教育关键技术,邮箱为xietao@swu.edu.cn。
2021年10月15日
编辑:小时
