基于分布式文件系统电力大数据存储实现
2022-06-21陈行滨王周郑飘飘林德威刘青
陈行滨 王周 郑飘飘 林德威 刘青


摘要:基于Hadoop存储架构设计了电网非结构化数据管理平台,主要包括存储分析与搜索读取2大模块,整合HDFS、Hbase等存储设备,利用HDFS实现海量数据的快速读写,采用基于ZooKeeper及Solr搭建的开源分布式搜索引擎SolrCloud实现数据检索,提供了高效便捷的智能化管理手段。
关键词:电网管理;Hadoop存储;分布式;数据检索
中图分类号:TP311.13
文献标识码:B文章编号:1001-5922(2022)06-0172-04
Realization of power big data storage based on distributed file system
CHEN Xingbin WANG Zhou ZHENG Piaopiao LIN Dewei LIU Qing
(1. State Grid Fujian Electric Power Co., Ltd., Fuzhou 350000, China; 2. Information and Telecommunication Branch, State Grid Fujian Electric Power Co., Ltd., Fuzhou 350000, China; 3. State grid Xintong Yili Technology Co., Ltd., Fuzhou 350000, China
)
Abstract:This paper designs an unstructured data management platform for power grids based on the Hadoop storage architecture. It mainly includes two modules: storage analysis and search and reading. It integrates storage devices such as HDFS and Hbase. It uses HDFS to achieve rapid reading and writing of massive data and adopts an open-source distributed search engine SolrCloud built by ZooKeeper and Solr to implement data retrieval, providing an effective and convenient method for smart management.
Key words:power grid management; Hadoop storage; distributed; data retrieval
電力行业的非结构化数据存储的内容包括图像、视频、报表、网页等不同格式,其中70%以上源自人与人之间的协作,可以说是以人为中心产生的数据。其中蕴含着各类经验与操作方法,是很珍贵的数据资产,如何将所有的非结构化信息加以管理是衡量企业信息化水平以及数据充分利用率的关键指标。
1电网非结构化数据管理
1.1电网非结构化数据管理现状
电网非结构化数据的管理包括存储、管理以及检索。由于电力行业数据增长非常快,大部分企业是采用BLOB字段进行存储,这种方式访问速度快、维护也比较简单;但是随着海量数据的增长,系统性能跟不上,数据共享也存在问题。因此,要实现电网非结构化数据的管理,必须考虑海量数据的存储方式、安全措施、备份办法以及检索机制。
1.2电网非结构化数据管理
(1)提升业务运行效率,实现数字资产管理:将非结构化数据文档的标准化、规范化统一管理;
(2)降低开发成本,发挥整合效应:在物理存储层面通过统一存储使各业务系统不用单独购买存储设备,降低实施成本;
(3)体现深度价值,助力智能决策:不仅实现非结构化数据的管理,还可以实现对数据深度挖掘与分析;而统一存储、统一管理是实现深度利用的前提[1-2]。
2管理需求分析
2.1业务需求概述
电网非结构化数据管理平台需要负责数据采集、存储、综合管理、发布、查阅等功能,具体描述如下:
(1)存储统一需求:电力企业各部门拥有多个业务应用系统,不同的数据库、不同的服务器,为提高利用率需要进行统筹管理,整合存储资源,优化系统配置;
(2)集中管理需求:遵循全局访问标准,以统一的方式标准实现访问与交互,提高集约化水平;
(3)数据分析需求:对基础数据进行再加工,分析数据之间的关联性,提供检索以及决策支持。
2.2关键业务流程
2.2.1存储流程
用户需要进行非结构化数据存储时,首先要通过客户端选择需要处理的文件,封装为“上传请求”发送至数据服务层,接收到请求后根据服务器状态判断是否将参数信息转发服务器代理;在负载均衡的基础上,对文件进行分片及分布处理之后形成决策结果发送至数据访问层。数据访问层结合自身需上传文件与决策信息对文件进行再次处理形成文件片;封装后传输至数据存储层,返回结果信息,完成存储流程。
2.2.2[STBZ]读取流程
主服务器根据数据访问层下载的命令分析请求消息后,将各项参数传递给服务器代理,代理会通过分析元数据来对文件位置进行定位;数据访问层将其发给数据服务层,最终合并还原为完整的文件,完成读取流程[3-4]。
2.3安全要求
(1)数据库安全:采用目前通用的大型关系型数据库,双击备份,出现异常可自动切换;采用先进的软硬件技术、模块化的程序结构,制定备份与恢复机制,提升容灾性;038469DC-DEA8-4810-A22F-9D82C38F3B98
(2)网络安全:支持多种网络协议、维持原有网络架构、基于网络拓扑进行系统功能模块开发,提高网络安全防护,采用权威认证的安全产品;
(3)应用安全:系统需具备高安全性,利用现有数据及组件支持多用户访问,具有异常事故处理能力,确保系统稳定运行。
2.4[STBZ]性能要求
系统在使用性能方面,需要至少满足300用户并发访问、确保存储数据量每年120 TB、页面响应速度小于2 s、确保可7×24 h连续工作,出现故障恢复时间不超出1 h。
2.5设计原则
(1)实用性:架构设计需充分考虑实用性,方便管理与掌握;
(2)标准化:提升系统扩展性,也为数据共享提供便利;
(3)可靠性:通过用户认证、权限管控、数据加密等多种方式确保系统安全、数据安全;
(4)可扩展:避免重复开发,确保各个功能模块的延展性,适应发展规划[5]。
3涉及的主要技术
3.1Hadoop存储
本文设计的管理平台利用Hadoop实现数据存储,基于HDFS进行搭建。Hadoop平台有很多分布式的数据库服务器采用集群方式进行部署,Hadoop由HDFS、MapReduce、Hbase、Hive以及ZooKeeper构成。
(1)HDFS:分布式文件存储系统,将文件随机存储在不同空间,可以大幅提高存储空间的利用率,适合用于数据备份;
(2)MapReduce:分布式处理模型,可以建立快速检索索引,解决并发计算问题;
(3)Hbase:基于HDFS开发的面向列的分布式数据库,将水平表划分为多个区域,用归属表、起始行以及结尾行进行标识;每个分区都是最小的数据存储单元。
3.2Lucene检索
Lucene是一项开源检索技术,通过嵌入系统中进行全文检索,支持通用的API扩展接口,小批量缓冲式读取结果集,支持高负载模糊查询;对加快搜索效率有极大帮助[6]。
3.3SolrCloud分布式搜索
SolrCloud是基于ZooKeeper和Solr的分布式搜索方案,也可以说是Solr基于ZooKeeper的部署方式,具有集中配置、自动容错、近实时搜索、自动负载均衡、自动分发索引及索引分片的优点;对电网系统主要大规模,需要容错的分布式索引来说再合适不过。
4总体设计
4.1总体架构
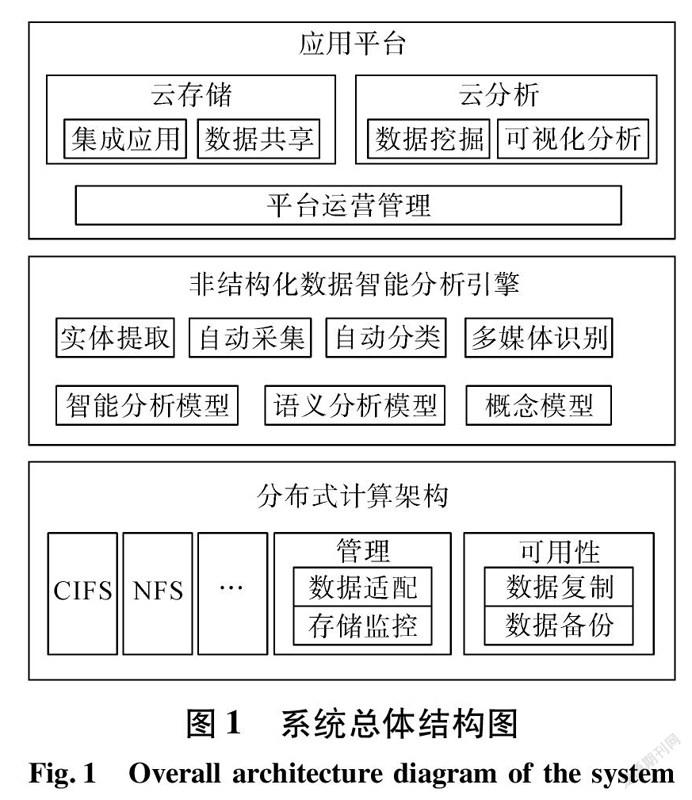
为适应电网非结构化数据日益增长的趋势,并满足两级部署多级应用,本文设计平台总体结构如图1所示。
由图1可以看出,系统总体架构包括:分布式计算、智能分析引擎、应用平台3部分内容。分布式计算主要包括CIFS、NFS、SCP等通用协议、数据适配及存储监控管理以及数据复制、数据备份等系统可用性部分;智能分析引擎主要包括实体提取、自动采集、分类、智能分析等;应用平台主要包括云存储、云分析以及平台运营管理。
4.2技术架构
本平台的技术结构主要采用全虚拟文件服务器、支持各类标准协议、支持存储控制、增长预测等功能,支持数据分层存储、自动去重以及数据备份。
(1)分布式计算:将繁杂、计算量大的问题细分,分散进行运算,提高并行计算能力及速率,最终再进行整合;
(2)分布式存储:分布式存储可以将分散存储空间进行整合,完成存储服务。
4.3系统模块
将电网非结构化数据管理平台划分为存储和检索2个子模块,存储模块实现数据采集、存储、分析与备份。检索模块支持索引构建、智能识别、数据搜索[7]。系统功能模块组成,具体如图2所示。
5系統详细设计
5.1存储分析模块
5.1.1[STBZ]存储对象
电网企业的非结构化数据主要包括:网页、图片、视频、文档等,这些均可以作为元数据采用feature+xmlBlob模式存储,将常用特征存储在feature中,语义信息存储在xmlBlob中。
(1)网页:包括类别、内容、标题、关键词等属性;
(2)视频:包括字母、所在网址、节目名称、标题、关键词、上传者、镜头信息等属性;
(3)图片:包括图片的标题、来源、相关描述等属性。
5.1.2模块功能
本文选用Hadoop作为数据存储,建立数据节点,降低成本,并给数字资源提供通用接口,整合HDFS、Hbase、XmlDB等存储设施。其中HDFS作为分布式计算的核心可以支持海量数据的快速读写。系统功能如图3所示。
5.1.3[STBZ]功能结构
(1)数据采集:采用开放上传接口方式被动采集数据,采用二进制流进行传输,支持压缩打包、支持分类解码存储;
(2)数据存储:文件备注上传业务平台标识,生产文件信息数据存储到Hbase中;
(3)数据分析:分析数据量、数据高峰周期,进而适当调整存储策略。
5.2搜索读取模块
5.2.1技术方案
非结构化数据的搜索与传统搜索有很大区别,一般是对标题、具体内容或文字描述进行检索。SolrCloud是基于ZooKeeper及Solr搭建的开源分布式搜索引擎,具有很好的扩展性,通过配置就可以完成环境部署,是非结构化数据检索的最优选择。
5.2.1架构设计
本文设计的搜索模块通过统一接口进行文件上传,形成索引;借助SolrCloud引擎实现搜索功能,应用架构如图4所示。
5.2.3功能结构
(1)索引搭建:利用Solr索引机制,提供标准HTTP接口,使每天数据在管理平台中生产目录项,提高搜索效率;
(2)智能识别:利用Lucene、ICR等技术识别隐藏信息;
(3)数据搜索:提供对外接口,支持输入关键字搜索。
6结语
本文采用Hadoop框架的分布式文件系统HDFS及Hbase实现数据存储,SolrCloud实现数据搜索,实现了电网非结构化数据的集中存储与实时管理,为相关人员提供了高效便捷的智能化管理手段。但在检索算法、安全产品选型、业务流程优化等方面还需进一步提高与改进,在结合日常运营情况提供智能分析解决方案方面还需进一步探索研究。
【参考文献】
[1]付婷,蔡宇翔,李宏发,等.智能电网中非结构化数据可视化技术研究[J].电网与清洁能源,2019(1):44-48.
[2]冯国平,古明生,吉小恒.电网非结构化数据管理平台研究与实现[J].南方能源建设,2015(S1):222-225.
[3]张福铮,黄文琦,赵继光,等.基于Hadoop的电网非结构化数据智能分析云平台[J].信息技术与信息化,2020(5):222-225.
[4]冯宇.非结构化数据管理平台研究与建设[J].电力信息化,2012(2):69-72.
[5]高明,陆宏治,梁雪青.电力系统非结构化数据处理方法研究[J].现代信息科技,2019(17):9-11.
[6]崔立真,史玉良,刘磊,等.面向智能电网的电力大数据存储与分析应用[J].大数据,2017(6):42-54.
[7]谢光.数据库大数据量存储结构的探索[J].通讯世界,2017(11):29-30.038469DC-DEA8-4810-A22F-9D82C38F3B98
